【值得收藏】vLLM大模型推理引擎:从单进程到多进程分布式架构详解
文章详细介绍了vLLM推理引擎从单进程(UniprocExecutor)到多进程(MultiProcExecutor)的架构演进,阐述了多进程环境下vLLM如何通过张量并行和流水线并行扩展处理能力,以及分布式系统中的无头服务器与API服务器实现机制。同时分析了延迟与吞吐量的平衡关系,提供了vLLM性能测试与调优指南,帮助读者理解大模型推理引擎的分布式架构设计与优化策略。
从单进程到多进程
UniprocExecutor到MultiProcExecutor的转变,就像从自行车换成了跑车。它不仅让 vLLM 可以通过多进程来控制多个 GPU ,也可以让 vLLM 扩展到多个服务器中同步处理! 相信随着技术的不断演进,我们还可以逐步实现不同规格或品牌的 GPU 基于相同标准来协同工作。

现在开始,我们逐步扩展理解多进程下的 vLLM 环境。首先假设您的模型权重不再适合单个 GPU 的 VRAM。
第一个选项是使用张量并行(例如,TP=8 ,将 Tenser Parallelism 设为8个并行)将模型分片到同一节点上的多个 GPU 上。如果模型仍然无法适应,下一步是跨节点的流水线并行。
注意:
节点内带宽明显高于节点间带宽,且此时的节点内带宽是可以通过PCI通信;以NVIDIA GPU为例,vLLM 的张量并行依赖 NCCL(NVIDIA Collective Communications Library) 处理 GPU 间通信,其通信路径优先级为 NVLink 优先,PCIe 作为 fallback;而如果使用 AMD GPU 则需要 RCCL 和 ROCm 库来实现对 RoCE(RDMA over Converged Ethernet)网络的支持;不论选择那条技术线,跨节点都是需要不低的额外成本的。这就是为什么张量并行 (TP,tensor parallelism) 通常比流水线并行 (PP,pipeline parallelism) 更受欢迎的原因。(但同时,PP 传输的数据量其实比 TP 少。)由于我们关注的是标准 Transformer 而不是 MoE,且 TP 和 PP 在实践中最常用。因此我即不打算讨论专家并行 (EP,expert parallelism)也不打算讨论序列并行 (sequence parallelism)。
在此阶段,我们需要多个 GPU 进程(工作进程)和一个编排层来协调它们。这正是 MultiProcExecutor 所提供的。
MultiProcExecutor 在 TP=8 设置下(驱动工作进程的等级为 0)
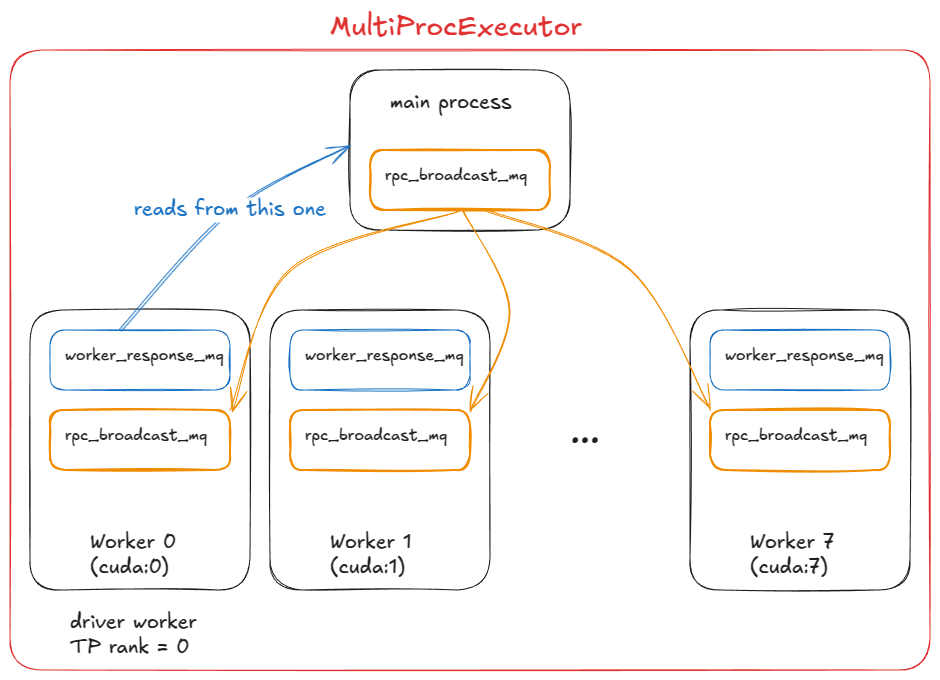
vLLM 中实现 MultiProcExecutor 的工作原理:
第一步,MultiProcExecutor 初始化一个 rpc_broadcast_mq 消息队列(底层使用共享内存实现)。
第二步,构造函数循环遍历 world_size(例如,TP=8 ⇒ world_size=8),并通过 WorkerProc.make_worker_process 为每个等级生成一个守护进程。
第三步,对于每个工作进程,父进程首先创建一个读写管道。
第四步,新进程运行 WorkerProc.worker_main,它会实例化一个工作进程(与 UniprocExecutor 中一样,会经历相同的“初始化设备 init device”、“加载模型 load model”等步骤)。
第五步,每个工作进程都会确定自己是驱动进程 driver(TP 组中的等级为 0)还是普通工作进程 worker 。每个工作进程都会设置两个队列:
- rpc_broadcast_mq(与父进程共享)用于接收工作。
- worker_response_mq 用于发回响应。
第六步,在初始化期间,每个子进程通过管道将其 worker_response_mq 句柄发送给父进程。所有句柄接收完毕后,父进程解除阻塞——协调完成。
第七步,然后,工作进程进入繁忙循环,阻塞在 rpc_broadcast_mq.dequeue 上。当一个工作项到达时,它们会执行它(就像在 UniprocExecutor 中一样,但现在具有特定于 TP/PP 的分区工作)。结果通过 worker_response_mq.enqueue 发回。
第八步,在运行时,当请求到达时,MultiProcExecutor 会将其入队到 rpc_broadcast_mq(非阻塞)队列中,供所有子进程使用。然后,它等待指定输出等级的 worker_response_mq.dequeue 来收集最终结果。
从引擎的角度来看,没有任何变化——所有这些多处理复杂性都通过调用模型执行器的 execute_model 函数抽象出来。
- 在 UniProcExecutor 的情况下:execute_model 直接导致在工作器上调用 execute_model
- 在 MultiProcExecutor 的情况下:execute_model 间接导致通过 rpc_broadcast_mq 在每个工作器上调用 execute_model
此时,我们可以使用相同的引擎接口运行资源允许的最大规模的模型。
基于 MultiProcExecutor 我们可以实现 TP 的并行,下一步是服务器级别扩展 scale out :启用数据并行 data parallelism (DP > 1),跨节点复制模型,添加轻量级 DP 协调层,引入跨副本的负载均衡,并在前端放置一个或多个 API 服务器来处理传入流量。
分布式系统如何为vLLM服务
设置服务基础设施的方法有很多,但为了更具体,我们举一个例子:假设我们有两个 H100 节点,并希望在它们上运行四个 vLLM 引擎。
如果模型需要 TP=4,我们可以像这样配置节点。
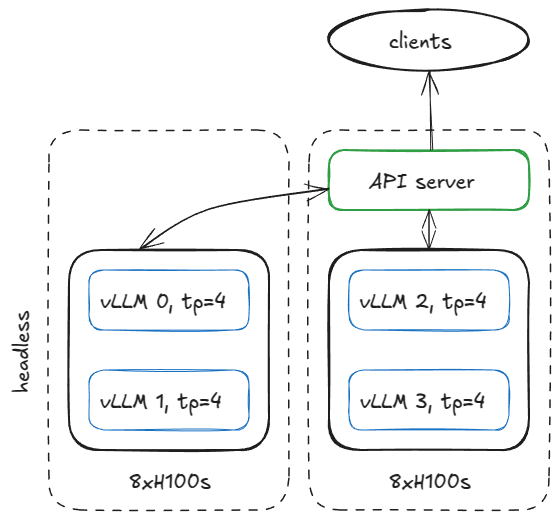
图 14:包含 2 个 8xH100 节点(1 个无头服务器,1 个 API 服务器)的服务器配置
在第一个节点上,使用以下参数以无头模式(无 API 服务器)运行引擎:
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 0
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
--headless
在另一个节点上运行相同的命令,并进行一些调整: no --headless 修改 DP 起始等级
vllm serve <model-name>
--tensor-parallel-size 4
--data-parallel-size 4
--data-parallel-size-local 2
--data-parallel-start-rank 2
--data-parallel-address <master-ip>
--data-parallel-rpc-port 13345
注意 这假设网络已配置(这里所谈及的网络就绪不是普通网络,而是需要高通讯能力的 RDMA 网络,如前面所描述,它们是需要不低的额外成本的。包括技术成本与财力成本),所有节点都可以访问指定的 IP 和端口。
那么,这在 VLLM 中是如何实现的呢,我们就需要进一步了解无头服务器节点与 API 服务器节点?
无头服务器节点的秘密
在无头节点上,CoreEngineProcManager 会启动两个进程(每个 --data-parallel-size-local 参数),每个进程都运行 EngineCoreProc.run_engine_core。每个函数都会创建一个 DPEngineCoreProc(引擎核心),然后进入其繁忙循环。
DPEngineCoreProc 会初始化其父级 EngineCoreProc(EngineCore 的子级),它会:
第一步,创建一个输入队列 (input_queue) 和一个输出队列 (output_queue) (queue.Queue)。
第二步,使用 DEALER ZMQ 套接字(异步消息库,ZeroMQ 消息队列库的通信端点(如 tcp://*:5555),用于进程 / 节点间的消息传递)与另一个节点上的前端进行初始握手,并接收协调地址信息。
第三步,初始化 DP 组(例如,使用 NCCL 后端)。
第四步,使用 MultiProcExecutor 初始化 EngineCore(如前所述,在 4 个 GPU 上 TP=4)。
第五步,创建一个 ready_event (threading.Event)。
第六步,启动一个输入守护线程 (threading.Thread),运行
process_input_sockets(…, ready_event)。类似地,启动一个输出线程。
第七步,仍然在主线程中,等待 ready_event,直到所有 4 个进程(跨越 2 个节点)的所有输入线程都完成协调握手,最终执行 ready_event.set()。
第八步,一旦解除阻塞,就向前端发送一个包含元数据(例如,分页键值缓存中可用的 num_gpu_blocks)的“ready”消息。
第九步,然后,主线程、输入线程和输出线程进入各自的忙循环。
简而言之:我们最终有 4 个子进程(每个 DP 副本一个),每个子进程运行一个主线程、输入线程和输出线程。它们与 DP 协调器和前端完成协调握手,然后每个进程的所有三个线程都进入稳定状态的忙循环。
运行 4 个 DP 副本的分布式系统,包含 4 个 DPEngineCoreProc
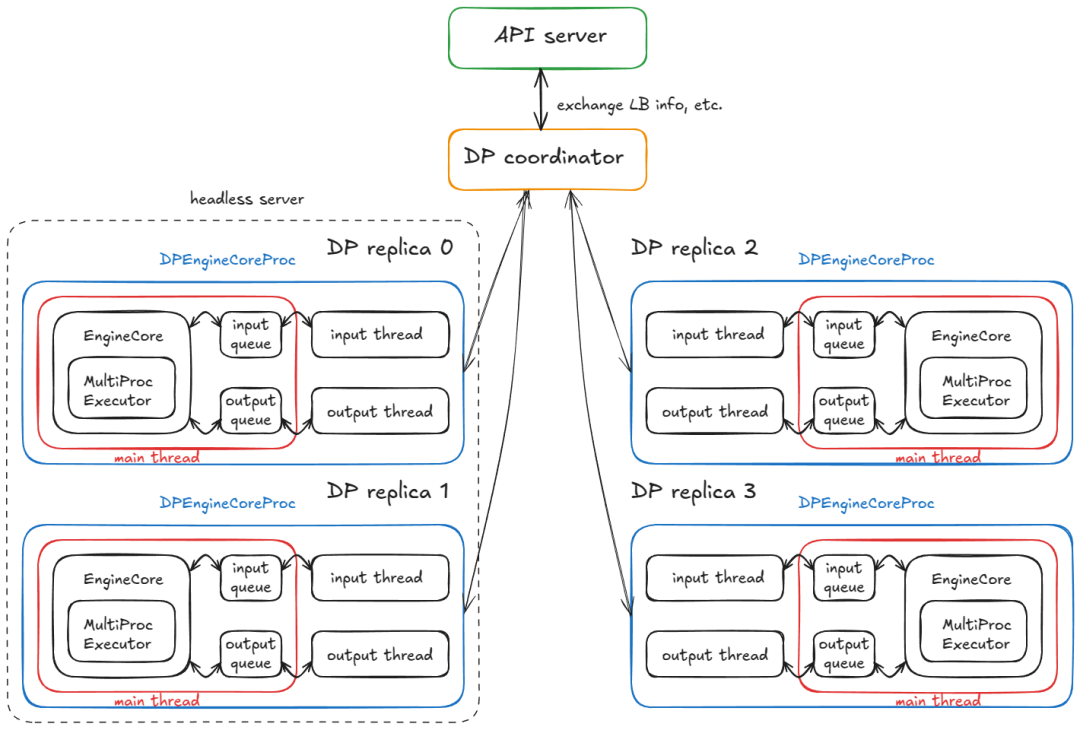
当前稳定状态:
- 输入线程:阻塞在输入套接字上,直到从 API 服务器路由请求;收到请求后,它会解码有效负载,通过 input_queue.put_nowait(…) 将工作项入队,然后返回到套接字上的阻塞状态。
- 主线程:在 input_queue.get(…) 上唤醒并将请求提供给引擎。 MultiProcExecutor 运行前向传递并将结果入队到 output_queue。
- 输出线程:在 output_queue.get(…) 上唤醒,将结果发送回 API 服务器,然后恢复阻塞状态。
其他机制:
- DP 波动计数器 — 系统跟踪“波动”;当所有引擎都空闲时,它们会停止运行,而计数器会在新工作到达时递增(这对于协调/指标很有用)。
- 控制消息——API 服务器可以发送的不仅仅是推理请求(例如,中止和实用程序/控制 RPC)。
- 用于锁步的虚拟步骤——如果任何 DP 副本有工作,则所有副本都会执行向前步骤;没有请求的副本会执行虚拟步骤以参与所需的同步点(避免阻塞活动副本)。

注意
锁步 (Lockstep) 说明:这实际上仅适用于 MoE 模型,其中专家层组成 EP 或 TP 组,而注意力层 (attention layers ) 仍然是 DP。目前它始终通过 DP 完成——这只是因为 “built-in” 非 MoE DP 的用途有限,因为您可以运行多个独立的 vLLM 并以正常方式在它们之间进行负载平衡。
现在进入第二部分,API 服务器节点上会发生什么?
API服务器节点的门道
API server node就是vLLM对外的门面。请求从这里进,结果从这里出。听起来简单?背后可是暗藏玄机!
首先,我们实例化一个 AsyncLLM 对象(LLM 引擎的异步I/O包装器 (asyncio wrapper))。这将在内部创建一个 DPLBAsyncMPClient 对象(负责数据并行、负载均衡、异步、多处理客户端)。
在 MPClient 的父类中,launch_core_engines 函数运行并执行以下操作:
- 创建用于启动握手的 ZMQ 地址( 与无头节点上实现的握手过程相同)。
- 生成一个 DPCoordinator 进程。
- 创建一个 CoreEngineProcManager(与无头节点上的相同)。
在 AsyncMPClient(MPClient 的子类)中,我们执行以下操作:
- 创建一个 outputs_queue (asyncio.Queue)。
- 我们创建一个 asyncio 任务 process_outputs_socket,它通过输出套接字与所有 4 个 DPEngineCoreProc 的输出线程通信 ( 这里的4个是因为之前无头服务器的例子描述中是 4 DP 实例),并将数据写入 outputs_queue。
- 随后,AsyncLLM 的另一个异步任务 output_handler 从该队列读取数据,并最终将信息发送到 create_completion 函数。
在 DPAsyncMPClient 对象内部,我们创建了一个异步 I/O任务 run_engine_stats_update_task,用于与 DP 协调器 ( DPCoordinator 进程 ) 通信 。
DP 协调器在前端(API 服务器)和后端(引擎核心)之间进行协调。它:
- 定期向前端的 run_engine_stats_update_task 发送负载均衡信息(队列大小、等待/运行的请求)。
- 通过动态更改引擎数量来处理来自前端的 SCALE_ELASTIC_EP 命令(仅适用于 Ray 后端,目前 --distributed-executor-backend 参数的可选后端有,1. external_launcher:通过外部工具(如 MPI、Slurm)启动和管理分布式进程,vLLM 仅负责推理逻辑,不参与进程调度;2. mp:“multiprocessing” 基于 Python 原生多进程模块管理分布式 worker ; 3. ray:基于 Ray 框架管理分布式 worker;4. uni:单进程模式,所有推理逻辑在单个进程中运行,不启用分布式)。
- 向后端发送 START_DP_WAVE 事件(由前端触发),并报告 wave 状态更新。
回顾一下,前端 (AsyncLLM) 运行多个异步任务(记住:是并发,而不是并行):
- 一类任务通过生成路径处理输入请求(每个新的客户端请求都会生成一个新的异步任务)。
- 两个任务(process_outputs_socket 和 output_handler)处理来自底层引擎的输出消息。
- 一个任务(run_engine_stats_update_task)与动态扩展协调器保持通信:发送 wave 触发器、轮询负载均衡器状态以及处理动态扩展请求。
最后,主服务器进程创建一个 FastAPI 应用并挂载 OpenAIServingCompletion 和 OpenAIServingChat 等端点,这些端点会暴露 /completion、/chat/completion 等访问端点。然后,该堆栈通过 Uvicorn 提供服务(Uvicorn 是一个高性能的 ASGI (Asynchronous Server Gateway Interface) 服务器,专为运行异步 Python Web 应用,如 FastAPI、Starlette 等而设计)。
综上所述,这就是完整的请求生命周期!
您从终端发送:
curl -X POST https://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{
"model": "TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"prompt": "The capital of France is",
"max_tokens": 50,
"temperature": 0.7
}'
接下来会发生什么:
-
该请求到达 API 服务器上 OpenAIServingCompletion 的 create_completion 路由。
-
该函数异步标记提示,并准备元数据(请求 ID、采样参数、时间戳等)。
-
然后,它调用 AsyncLLM.generate,该流程与同步引擎相同,最终调用 DPAsyncMPClient.add_request_async。
-
这反过来会调用 get_core_engine_for_request,它会根据 DP 协调器的状态在各个引擎之间进行负载平衡(选择得分最低/负载最低的引擎:得分 = len(waiting) * 4 + len(running))。
-
ADD 请求会被发送到所选引擎的 input_socket。
-
在该引擎上:
-
输入线程 — 解除阻塞,解码来自输入套接字的数据,并将工作项放入主线程的 input_queue 中。
-
主线程 — 解除对 input_queue 的阻塞,将请求添加到引擎,并重复调用 engine_core.step(),将中间结果放入 output_queue 队列,直到满足停止条件。
注意:step() 会调用调度器、模型执行器(也可能是 MultiProcExecutor!)等。我们已经见过这些了!
-
输出线程 — 解除对 output_queue 的阻塞,并通过输出套接字将结果发送回。
这些结果会触发 AsyncLLM 的输出异步任务(process_outputs_socket 和 output_handler),这些任务会将令牌传播回 FastAPI 的 create_completion 路由。
FastAPI 会附加元数据(完成原因、日志概率、使用信息等),并通过 Uvicorn 向你的终端返回 JSONResponse!
补充说明:
添加更多 API 服务器时,负载均衡在操作系统/套接字级别进行处理。从应用程序的角度来看,没有什么重大变化——复杂性被隐藏了。
使用 Ray 作为 DP 后端,你可以公开一个 URL 端点 (/scale_elastic_ep),以自动扩展或缩减引擎副本数量。
总结来说,请求队列管理和流量控制是关键技能。高峰期怎么防止系统被压垮?如何优雅地拒绝过多请求?因此API设计在考虑扩展性的同时还需要考虑稳定性与处理有效性,因为说不定哪天用户量就爆了。
延迟与吞吐量的永恒博弈
Benchmarks和auto-tuning就像调音师,让系统在延迟和吞吐量之间找到最佳平衡点。想要速度快?可能牺牲吞吐量。想要处理量大?可能增加延迟。

到目前为止,我们一直在分析“内部细节”—— 即请求在引擎 / 系统内部的流转机制。现在是时候拉远视角,从整体审视系统,并思考一个问题:如何衡量推理系统的性能?
在最高层面,有两个相互影响的核心指标:
- 延迟(Latency):从请求提交到 token 返回所需的时间
- 吞吐量(Throughput):系统每秒可生成 / 处理的 token 数或请求数
延迟对交互式应用至关重要,这类场景中用户需要等待响应;而吞吐量则在离线工作负载中发挥关键作用,例如训练前 / 后流程中的合成数据生成、数据清洗 / 处理,以及各类离线批量推理任务。
在解释延迟和吞吐量为何相互竞争之前,让我们先定义一些常见的推理指标:
| 指标 | 定义 | |
| TTFT | (首令牌生成时间) | 从提交请求到接收首个输出令牌的时间。 |
| ITL | (令牌间延迟) | 两个连续令牌之间的时间间隔(例如,从第 i-1 个令牌到第 i 个令牌的时间)。 |
| TPOT | (每输出令牌耗时) | 一个请求中所有输出令牌的平均 ITL(即所有令牌间延迟的平均值)。 |
| Latency / E2E | (延迟 / 端到端延迟) | 处理一个请求的总时间,即 “首令牌生成时间(TTFT)+ 所有令牌间延迟(ITL)的总和”;也等价于 “从提交请求到接收最后一个输出令牌的时间”。 |
| Throughput | (吞吐量) | 每秒处理的总令牌数(可指输入令牌、输出令牌,或两者之和);也可指每秒处理的请求数。 |
| Goodput | (有效吞吐量) | 符合服务级别目标(SLO)的吞吐量,这些 SLO 包括 “最大首令牌生成时间(TTFT)”“最大每输出令牌耗时(TPOT)” 或 “最大端到端延迟” 等。例如,仅统计满足这些 SLO 的请求所产生的令牌数量。 |
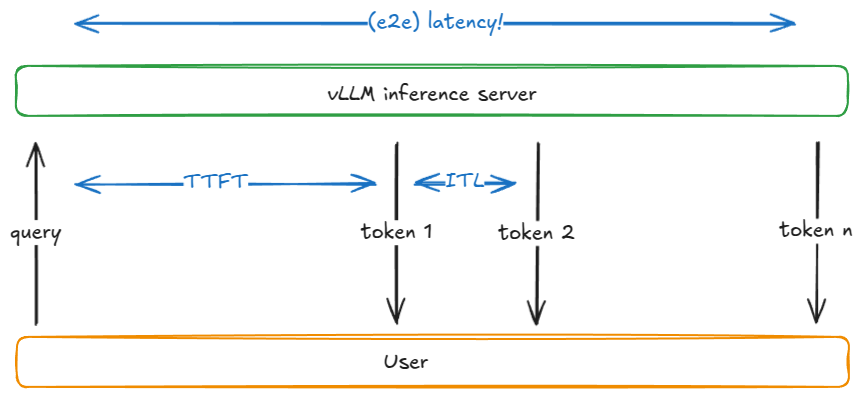
通过这个图示可以更清晰的理解表格中的各项指标。
以下是一个简化的模型,解释了这两个指标之间的竞争关系。
假设: 权重 I/O 而非键值缓存 I/O 占主导地位;也就是说,我们处理的是短序列。 当观察批处理大小 B (以下都通过定义B来代表批处理大小)如何影响单个解码步骤时,这种权衡关系就变得清晰起来。随着 B 趋近于 1,ITL 下降:每步的工作量减少,并且该标记与其他标记之间不存在“竞争”。随着 B 趋近于无穷大,ITL 上升,因为每步执行的 FLOP 次数更多——但吞吐量会提高(直到达到峰值性能),因为权重 I/O 被分摊到更多标记上。
峰值性能模型(Roofline Model)有助于理解这一现象:在批次量未达到饱和批次量 Bₛₐₜ(saturation batch Bₛₐₜ)之前,步长时间(step time)主要受 HBM 带宽(高带宽内存带宽)限制 —— 需将权重逐层传输到片上内存(on-chip memory),因此步长延迟(step latency)几乎保持稳定,计算 1 个 token 与 10 个 token 所耗时间相近;当批次量超过 Bₛₐₜ后,内核(kernels)进入计算受限(compute-bound)状态,步长时间大致随批次量 B 增长,每额外增加一个令牌,都会导致令牌间延迟(ITL)增加。
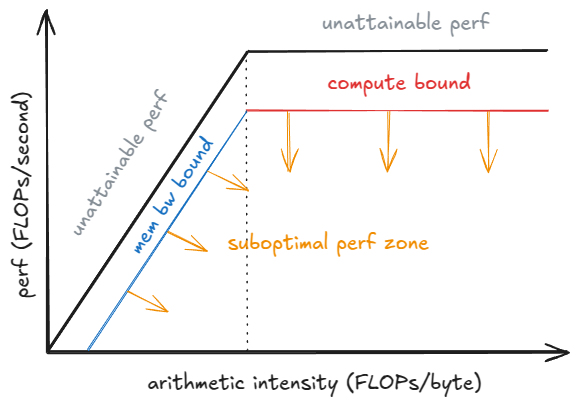
注: 为了更严谨地处理,我们必须考虑内核自动调优:随着 B 的增长,运行时可能会切换到更高效的内核,从而改变达到的性能 P_kernel。步长延迟为 t = FLOPs_step / P_kernel,其中 FLOPs_step 是该步的计算量。可以看出,当 P_kernel 接近 P_peak 时,每步计算量的增加将直接导致延迟的增加。
关键技术术语补充说明
- 峰值性能模型(Roofline Model):一种用于分析硬件性能瓶颈的工具,通过 “计算峰值” 和 “带宽峰值” 两条上限线,判断系统当前受 “计算能力” 还是 “数据传输带宽” 限制,是推理系统性能调优的核心分析方法。
- 饱和批次量 Bₛₐₜ(saturation batch Bₛₐₜ):系统性能瓶颈从 “带宽受限” 转为 “计算受限” 的临界批次规模 —— 批次量小于 Bₛₐₜ时,数据传输速度(如权重从 HBM 到片上内存)是瓶颈;大于 Bₛₐₜ时,计算速度(如 GPU 浮点运算)成为瓶颈。
- 片上内存(on-chip memory):GPU 等硬件中集成的高速内存(如 NVIDIA GPU 的 SRAM),容量小但访问速度远快于 HBM,用于暂存计算过程中频繁调用的数据(如权重、中间张量),减少对 HBM 带宽的依赖。
- 计算受限(compute-bound):系统性能受限于计算单元(如 GPU CUDA 核心)的运算速度,而非数据传输速度,此时增加批次量会直接增加计算工作量,导致延迟上升。
无论什么样的系统,调参都是门艺术。我们除了需要随时关注实时负载,还需要关注每个参数对负载处理的影响趋势。 vLLM 的使用风格注定了它需要随着模型的不同,负载的不同来动态调整参数。维护 vLLM 的性能就像老司机开车,需要知道什么时候该踩油门,什么时候该刹车。只知道踩油门通常不能最快抵达终点。
vLLM中的性能测试指南
想在vLLM中做benchmark?光跑几个测试可不够。测试环境要一致,测试数据要多样,测试指标要全面。
vLLM 提供了一个 vllm bench {serve,latency,throughput} 命令行界面,它封装了 vllm / benchmarks / {server,latency,throughput}.py 文件。
以下是这些脚本的功能:
- latency — 使用较短的输入(默认 32 个 token),并以较小的批次(默认 8 个)对 128 个输出 token 进行采样。它会运行多次迭代,并报告该批次的端到端延迟。
- throughput — 一次性提交一组固定数量的提示(默认:1000 个 ShareGPT 样本)(也称为 QPS=Inf 模式),并报告运行期间的输入/输出/总 token 数和每秒请求数。
- serve — 启动一个 vLLM 服务器,并通过从泊松分布(或更一般地,伽马分布)中采样请求到达间隔时间来模拟真实世界的工作负载。它会在指定时间窗口内发送请求,测量我们讨论过的所有指标,并且可以选择性地强制执行服务器端最大并发数(例如,通过信号量将服务器的并发请求数限制为 64)。
以下是如何运行延迟脚本的示例:
vllm bench latency
--model <model-name>
--input-tokens 32
--output-tokens 128
--batch-size 8
注: 持续集成 (CI) 中使用的基准测试配置位于 .buildkite/nightly-benchmarks/tests 目录下。
此外,还有一个自动调优脚本,用于驱动服务器基准测试,以找到满足目标服务级别目标 (SLO) 的参数设置(例如, “maximize throughput while keeping p99 e2e < 500 ms”),并返回建议的配置。
压力测试和稳定性测试一个都不能少。系统在极端情况下的表现如何?长时间运行会不会内存泄漏?这些问题都要通过严谨的测试来回答。
写在最后
我们的讲解从基础引擎核心(单进程执行器 UniprocExecutor)开始,逐步加入推测解码(speculative decoding)、前缀缓存(prefix caching)等高级特性,再纵向扩展到多进程执行器(MultiProcExecutor,支持张量并行 / 流水线并行 TP/PP > 1),最终实现横向扩展 —— 将所有组件封装到异步引擎与分布式服务栈中,最后以系统性能的衡量方法收尾。
此外,vLLM 还包含一些我未提及的专项处理能力,例如:
- 多样化硬件后端:张量处理单元(TPU)、AWS Neuron 加速芯片(Trainium/Inferentia,分别为训练型 / 推理型)等;
- 架构与技术:多查询注意力变体(MLA)、混合专家模型(MoE)、编码 - 解码架构(如 Whisper 模型)、池化 / 嵌入模型、EPLB(注:特定技术缩写,需结合具体语境,此处暂保留原名)、改进型旋转位置编码(m-RoPE)、低秩适应(LoRA)、注意力线性偏置(ALiBi)、无注意力机制变体、滑动窗口注意力、多模态大语言模型(multimodal LMs),以及状态空间模型(如 Mamba/Mamba-2、Jamba);
- 并行策略:张量并行(TP)、流水线并行(PP)、稀疏并行(SP);
- 其他能力:混合 KV 缓存逻辑(Jenga,具体实现名)、束搜索采样(beam sampling)等更复杂的采样方法;
- 实验性特性:异步调度(async scheduling)。
好在这些特性大多与前文所述的核心流程相互独立 —— 几乎可以将它们视为 “插件”(当然,实际应用中难免存在一定耦合)。
普通人如何抓住AI大模型的风口?
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。
AI大模型开发工程师对AI大模型需要了解到什么程度呢?我们先看一下招聘需求:

知道人家要什么能力,一切就好办了!我整理了AI大模型开发工程师需要掌握的知识如下:
大模型基础知识
你得知道市面上的大模型产品生态和产品线;还要了解Llama、Qwen等开源大模型与OpenAI等闭源模型的能力差异;以及了解开源模型的二次开发优势,以及闭源模型的商业化限制,等等。

了解这些技术的目的在于建立与算法工程师的共通语言,确保能够沟通项目需求,同时具备管理AI项目进展、合理分配项目资源、把握和控制项目成本的能力。
产品经理还需要有业务sense,这其实就又回到了产品人的看家本领上。我们知道先阶段AI的局限性还非常大,模型生成的内容不理想甚至错误的情况屡见不鲜。因此AI产品经理看技术,更多的是从技术边界、成本等角度出发,选择合适的技术方案来实现需求,甚至用业务来补足技术的短板。
AI Agent
现阶段,AI Agent的发展可谓是百花齐放,甚至有人说,Agent就是未来应用该有的样子,所以这个LLM的重要分支,必须要掌握。
Agent,中文名为“智能体”,由控制端(Brain)、感知端(Perception)和行动端(Action)组成,是一种能够在特定环境中自主行动、感知环境、做出决策并与其他Agent或人类进行交互的计算机程序或实体。简单来说就是给大模型这个大脑装上“记忆”、装上“手”和“脚”,让它自动完成工作。
Agent的核心特性
自主性: 能够独立做出决策,不依赖人类的直接控制。
适应性: 能够根据环境的变化调整其行为。
交互性: 能够与人类或其他系统进行有效沟通和交互。

对于大模型开发工程师来说,学习Agent更多的是理解它的设计理念和工作方式。零代码的大模型应用开发平台也有很多,比如dify、coze,拿来做一个小项目,你就会发现,其实并不难。
AI 应用项目开发流程
如果产品形态和开发模式都和过去不一样了,那还画啥原型?怎么排项目周期?这将深刻影响产品经理这个岗位本身的价值构成,所以每个AI产品经理都必须要了解它。

看着都是新词,其实接触起来,也不难。
从0到1的大模型系统学习籽料
最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师(吴文俊奖得主)
给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。
- 基础篇,包括了大模型的基本情况,核心原理,带你认识了解大模型提示词,Transformer架构,预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门AI大模型
- 进阶篇,你将掌握RAG,Langchain、Agent的核心原理和应用,学习如何微调大模型,让大模型更适合自己的行业需求,私有化部署大模型,让自己的数据更加安全
- 项目实战篇,会手把手一步步带着大家练习企业级落地项目,比如电商行业的智能客服、智能销售项目,教育行业的智慧校园、智能辅导项目等等

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。
600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。
AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

AI时代,企业最需要的是既懂技术、又有实战经验的复合型人才,**当前人工智能岗位需求多,薪资高,前景好。**在职场里,选对赛道就能赢在起跑线。抓住AI这个风口,相信下一个人生赢家就是你!机会,永远留给有准备的人。
如何获取?
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 24
24 0
0- 0



 已为社区贡献318条内容
已为社区贡献318条内容

所有评论(0)