深入解析 LlamaIndex 评估体系:从响应质量到检索性能的全链路优化指南
LlamaIndex 作为当前最流行的 RAG 开发框架之一,在评估体系方面提供了丰富而系统化的工具:它不仅能够评估生成结果的质量,也能独立评估检索器的性能,并支持自动生成问题集与接入主流社区评估系统。本文将对 LlamaIndex 的评估能力进行深入分析,从设计理念、核心功能到典型使用场景,帮助你全面理解为何它能成为构建高质量 RAG 系统的重要组件。
目录
前言
随着大语言模型(LLM)被广泛应用于问答系统、企业知识库、智能客服等场景,评估其性能的需求变得愈加重要。然而,评估一个 RAG(Retrieval-Augmented Generation)系统并非只关注最终生成的回答质量,而是必须同时关注 检索 与 生成 两个核心环节的表现。
LlamaIndex 作为当前最流行的 RAG 开发框架之一,在评估体系方面提供了丰富而系统化的工具:它不仅能够评估生成结果的质量,也能独立评估检索器的性能,并支持自动生成问题集与接入主流社区评估系统。
本文将对 LlamaIndex 的评估能力进行深入分析,从设计理念、核心功能到典型使用场景,帮助你全面理解为何它能成为构建高质量 RAG 系统的重要组件。
1 LlamaIndex 评估体系概述
LlamaIndex 的评估能力可以概括为两个关键维度:
- 响应评估(Response Evaluation):衡量 LLM 生成答案的质量。
- 检索评估(Retrieval Evaluation):衡量检索模块返回上下文的相关性与准确性。
这两个部分构成一个闭环,帮助开发者不断迭代和优化 RAG 系统。一个系统的最终表现通常由两项能力共同决定:检索是否找对内容、生成是否回答到位。因此,构建一个可量化、可追踪、可持续优化的评估体系尤为关键。
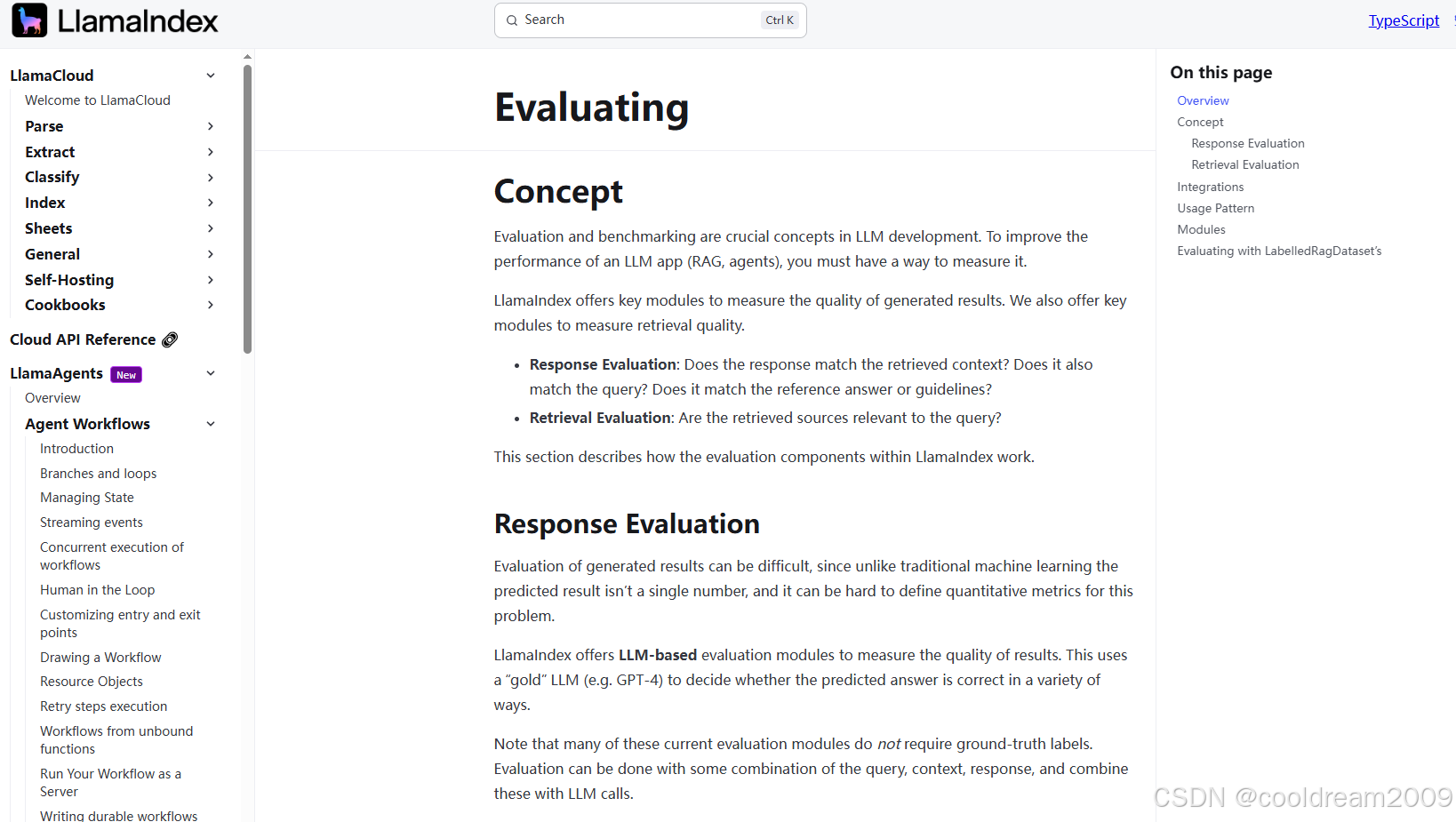
2 响应评估(Response Evaluation)
2.1 响应评估的角色与挑战
在 RAG 系统中,最终呈现给用户的是模型生成的答案,而答案是否“可靠、准确、清晰”决定了整个系统的体验。然而,传统的 NLP 评估方式(如 BLEU、ROUGE)对 LLM 的自由生成文本不再适用。
LlamaIndex 采用了一种新思路:用大模型评估大模型的输出。它通过 LLM 作为评估器(Evaluator LLM)对回答质量进行更符合语义层面的判断,例如判断是否产生幻觉、是否忠实于上下文等。
更重要的是,许多评估维度不需要参考答案(ground truth),这使评估的门槛更低,适用范围更大。
2.2 主要评估维度
LlamaIndex 提供的评估维度丰富而细致,下表对核心指标进行了总结:
| 评估维度 | 是否需要标签 | 说明 |
|---|---|---|
| 忠实性(Faithfulness) | 否 | 判断回答是否忠实于检索到的上下文,避免幻觉 |
| 回答相关性(Answer Relevance) | 否 | 回答是否正面响应了用户查询 |
| 上下文相关性(Context Relevance) | 否 | 检索到的上下文与问题是否相关,也可用于检索评估 |
| 指南遵循性(Guideline Adherence) | 否 | 是否遵从特定格式或风格要求 |
| 正确性(Correctness) | 是 | 回答是否与黄金答案一致 |
| 语义相似性(Semantic Similarity) | 是 | 在语义层面评估回答与参考答案的相似程度 |
其中,“忠实性”与“回答相关性”常用于识别幻觉,是优化生成模块的关键指标。
2.3 无标签评估的优势
传统评估往往要求标注大量参考答案,但 RAG 系统的数据多来源于真实业务文档,标注成本极高。LlamaIndex 的无标签评估能力提供了显著优势:
- 大幅降低评估成本
- 能自动对新数据进行评估
- 可快速发现幻觉或低质量回答
这使得开发者可以以更低成本实现持续评估和迭代。
3 检索评估(Retrieval Evaluation)
3.1 检索评估的重要性
一个 RAG 系统的核心能力是“找到正确的文档”。如果检索不到正确内容,即便 LLM 再强大,也无法回答正确的问题。检索评估的目标是衡量:
- 是否检索到相关文档
- 相关文档的排序是否合理
- 检索器在不同问题集上的整体性能如何
因此,检索评估常作为优化向量数据库、embedding 模型、检索策略的重要依据。
3.2 核心评估指标
检索评估使用广泛采用的排名类指标,包括:
- MRR(Mean Reciprocal Rank):关注正确结果的排名位置
- Hit Rate(命中率):检索结果中是否包含正确文档
- Precision(精确率):检索结果的相关文档比例
这些指标能够客观反映检索模块的真实性能。
3.3 数据集生成能力
评估检索效果的前提是拥有带标签的“问题-上下文对”。LlamaIndex 支持自动从语料库生成类似如下的数据集:
- 由 LLM 生成一系列与文档内容相关的问题
- 自动将文档分段作为正确上下文
- 对问题进行语义校验避免偏题
这套能力可帮助开发者快速构建适用于自己语料库的测试数据集,显著减少人工构造成本。
4 自动问题生成(Question Generation)
4.1 为什么需要自动出题?
在真实项目中,我们希望通过大规模的问题集验证系统性能,但人工构建上百甚至上千条问题几乎不现实。
LlamaIndex 的 QuestionGenerator 模块可以:
- 根据文档内容自动生成符合语义的问题
- 覆盖不同难度和类型(事实类、解释类、细节类等)
- 让开发者可以快速构建评估集
生成的问题可直接用于响应评估与检索评估,形成完整的测试闭环。
4.2 应用示例
自动生成的问题非常适合以下场景:
- 企业知识库上线前的全面测试
- 新增文档后的增量评估
- 用于自动化流水线的定期质量回归
从而确保 RAG 系统走向“可量化”“可监控”等工程化方向。
5 多工具集成能力(Integrations)
5.1 为什么需要与社区工具集成?
虽然 LlamaIndex 自带的评估能力已经很强,但开发者在不同环境中可能使用不同的生态工具。例如:
- 需要更丰富的可视化(如 Web UI)
- 需要测试更多指标
- 需要统一模型监控平台
因此,LlamaIndex 对外提供了评估结果的统一接口,并允许接入第三方工具。
5.2 支持的主要工具
以下工具均已与 LlamaIndex 集成,可直接使用其输出结果进行更丰富的评估与可视化(下面是全文中唯一一次无序列表):
- UpTrain
- Tonic Validate(提供图形化 Web UI)
- DeepEval
- Ragas
- RAGChecker
- Cleanlab
其中 Ragas 是目前最流行的 RAG 评估框架之一,而 Tonic Validate 则支持面向业务用户的可视化评估界面。
6 构建完整评估流程的实践路径
为了更直观地说明上述能力如何融合,下面给出一个典型的 RAG 系统评估流程示例。
6.1 步骤 1:准备文档与生成问题
- 载入企业知识库文档
- 使用 QuestionGenerator 自动生成全面的问题集
- 对问题进行筛选与校验(可选)
6.2 步骤 2:检索器评估
- 使用生成的问题
- 运行检索模块
- 评估 MRR、Hit Rate、Precision
- 调整 embedding、索引、检索参数
6.3 步骤 3:响应质量评估
- 对每个问题调用 LLM 得到回答
- 使用 LLM 评估器判断忠实性、回答相关性等
- 识别幻觉产生的原因(例如检索不准或模型误解)
6.4 步骤 4:可视化与结果分析
- 将评估结果导入 Ragas 或 Tonic Validate
- 分析失败的案例
- 输出优化策略与修正方案
整个流程构成一条完整的质量监控路径,让 RAG 系统能够持续迭代与优化,提高稳定性与可信度。
结语
在 RAG 系统越来越广泛的当下,仅凭生成结果判断系统好坏已经远远不够。LlamaIndex 提供了一套完整的评估体系,覆盖:
- 生成结果质量
- 检索性能
- 自动问题生成
- 与第三方评估生态的深度集成
这种设计理念让开发者能够真正做到“测试驱动开发(TDD)”式地构建 RAG,持续发现问题、定位瓶颈、量化提升。
如果你正在构建一个面向真实业务场景的知识库问答或企业智能助手,LlamaIndex 的评估能力将成为你打造高可靠、高质量系统的重要工具。
参考资料
- LlamaIndex 官方文档:Evaluation Modules
- LlamaIndex GitHub 仓库
- Ragas:RAG 评估框架
- Tonic Validate 产品文档

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 30
30 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)