【RAG全栈】Task05:项目实战一
本文介绍了基于RAG(检索增强生成)技术的菜谱问答系统实现方案。系统采用树形结构处理菜谱数据,将完整菜谱(父文档)分割为多个子块(介绍、原料、步骤等),检索时精确匹配子块,生成时整合父文档保证上下文完整。技术实现包括:1)使用FAISS构建向量索引并实现缓存机制;2)结合向量检索和BM25检索的RRF混合排序算法;3)支持元数据过滤检索;4)集成大语言模型生成回答。系统能智能处理"推荐简
1.环境准备
1.1安装虚拟环境
python -m venv G:\env_py\rag1.2安装依赖
cd rag
pip install -r requirements.txt1.3申请key
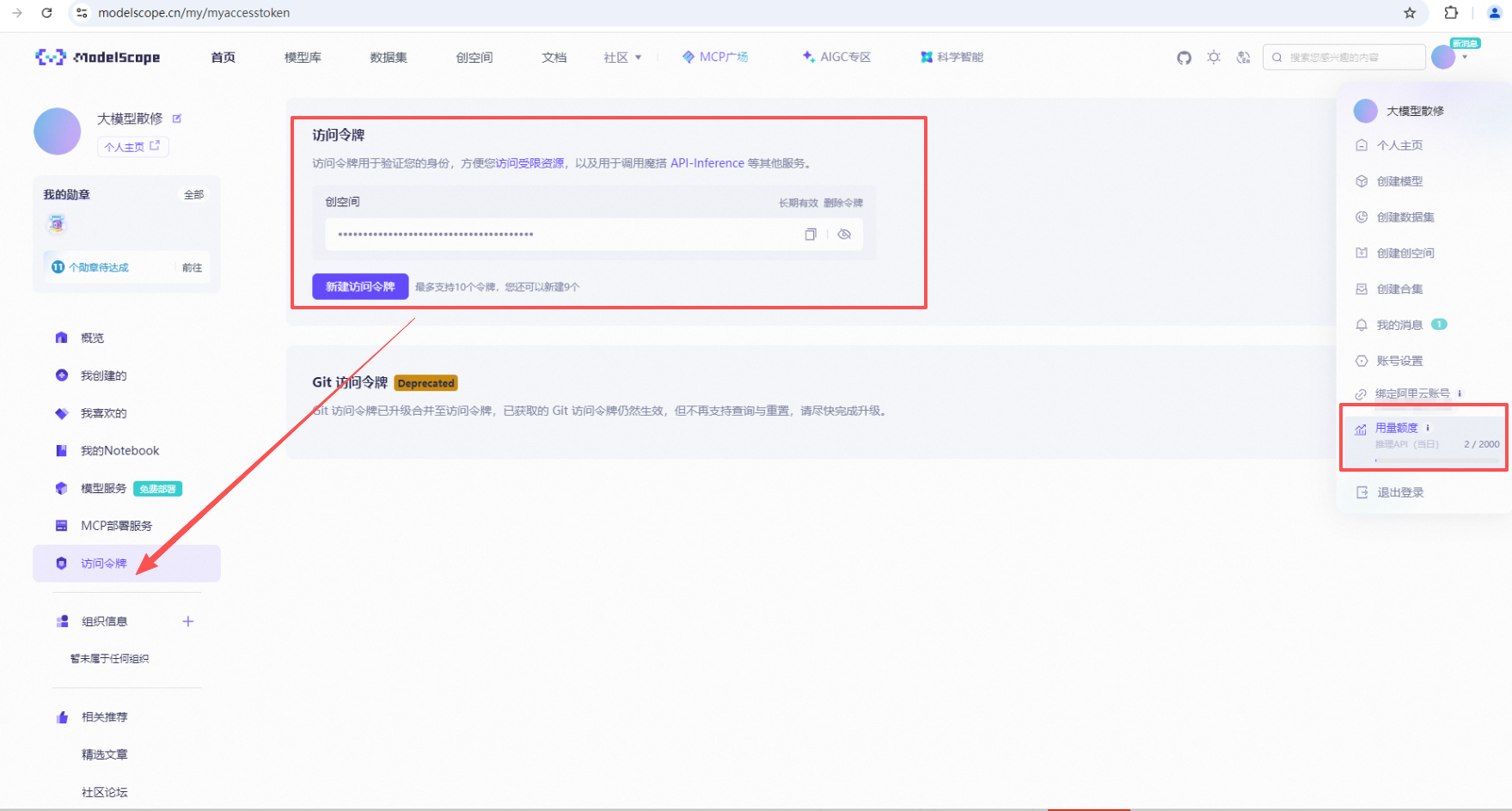
从modelscope获取key,每天免费2000次调用
1.4项目结构
code/C8/
├── config.py # 配置管理
├── main.py # 主程序入口
├── requirements.txt # 依赖列表
├── rag_modules/ # 核心模块
│ ├── __init__.py
│ ├── data_preparation.py # 数据准备模块
│ ├── index_construction.py # 索引构建模块
│ ├── retrieval_optimization.py # 检索优化模块
│ └── generation_integration.py # 生成集成模块
└── vector_index/ # 向量索引缓存(自动生成)2.数据准备
2.1数据结构
构建有父子节点关系的树形结构数据
父文档(完整菜谱)
├── 子块1:菜品介绍 + 难度评级
├── 子块2:必备原料和工具
├── 子块3:计算(用量配比)
├── 子块4:操作(制作步骤)
└── 子块5:附加内容(变化做法)基本流程:
检索阶段:使用小的子块进行精确匹配,提高检索准确性
生成阶段:传递完整的父文档给LLM,确保上下文完整性
智能去重:当检索到同一道菜的多个子块时,合并为一个完整菜谱
元数据增强:
菜品分类:从文件路径推断(荤菜、素菜、汤品等)
难度等级:从内容中的星级标记提取
菜品名称:从文件名提取
文档关系:建立父子文档的ID映射关系
2.2Markdown结构分块
Markdown标题分割器
- 三级标题分割: 按照
#、##、###进行层级分割 - 保留标题: 设置
strip_headers=False,保留标题信息便于理解上下文 - 父子关系: 每个子块都记录其父文档的
parent_id - 唯一标识: 每个子块都有独立的
child_id
def _markdown_header_split(self) -> List[Document]:
"""使用Markdown标题分割器进行结构化分割"""
# 定义要分割的标题层级
headers_to_split_on = [
("#", "主标题"), # 菜品名称
("##", "二级标题"), # 必备原料、计算、操作等
("###", "三级标题") # 简易版本、复杂版本等
]
# 创建Markdown分割器
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=False # 保留标题,便于理解上下文
)
all_chunks = []
for doc in self.documents:
# 对每个文档进行Markdown分割
md_chunks = markdown_splitter.split_text(doc.page_content)
# 为每个子块建立与父文档的关系
parent_id = doc.metadata["parent_id"]
for i, chunk in enumerate(md_chunks):
# 为子块分配唯一ID并建立父子关系
child_id = str(uuid.uuid4())
chunk.metadata.update(doc.metadata)
chunk.metadata.update({
"chunk_id": child_id,
"parent_id": parent_id,
"doc_type": "child", # 标记为子文档
"chunk_index": i # 在父文档中的位置
})
# 建立父子映射关系
self.parent_child_map[child_id] = parent_id
all_chunks.extend(md_chunks)
return all_chunks2.3智能去重
去重逻辑:
- 统计相关性: 计算每个父文档被匹配的子块数量
- 按相关性排序: 匹配子块越多的菜谱排名越靠前
- 去重输出: 每个菜谱只输出一次完整文档
def get_parent_documents(self, child_chunks: List[Document]) -> List[Document]:
"""根据子块获取对应的父文档(智能去重)"""
# 统计每个父文档被匹配的次数(相关性指标)
parent_relevance = {}
parent_docs_map = {}
# 收集所有相关的父文档ID和相关性分数
for chunk in child_chunks:
parent_id = chunk.metadata.get("parent_id")
if parent_id:
# 增加相关性计数
parent_relevance[parent_id] = parent_relevance.get(parent_id, 0) + 1
# 缓存父文档(避免重复查找)
if parent_id not in parent_docs_map:
for doc in self.documents:
if doc.metadata.get("parent_id") == parent_id:
parent_docs_map[parent_id] = doc
break
# 按相关性排序并构建去重后的父文档列表
sorted_parent_ids = sorted(parent_relevance.keys(),
key=lambda x: parent_relevance[x], reverse=True)
# 构建去重后的父文档列表
parent_docs = []
for parent_id in sorted_parent_ids:
if parent_id in parent_docs_map:
parent_docs.append(parent_docs_map[parent_id])
return parent_docs3.索引构建与检索优化
3.1向量索引构建
使用FAISS作为向量数据库,它的检索速度很快,同时保存了文本内容和元数据信息,支持大规模向量的高效检索。
def build_vector_index(self, chunks: List[Document]) -> FAISS:
"""构建向量索引"""
if not chunks:
raise ValueError("文档块列表不能为空")
# 提取文本内容
texts = [chunk.page_content for chunk in chunks]
metadatas = [chunk.metadata for chunk in chunks]
# 构建FAISS向量索引
self.vectorstore = FAISS.from_texts(
texts=texts,
embedding=self.embeddings,
metadatas=metadatas
)
return self.vectorstore3.2索引缓存机制
索引缓存的效果很明显:首次运行时构建索引需要几分钟,但后续运行时加载索引只需几秒钟。索引文件通常只有几十MB,存储效率很高。
def save_index(self):
"""保存向量索引到配置的路径"""
if not self.vectorstore:
raise ValueError("请先构建向量索引")
# 确保保存目录存在
Path(self.index_save_path).mkdir(parents=True, exist_ok=True)
self.vectorstore.save_local(self.index_save_path)
def load_index(self):
"""从配置的路径加载向量索引"""
if not self.embeddings:
self.setup_embeddings()
if not Path(self.index_save_path).exists():
return None
self.vectorstore = FAISS.load_local(
self.index_save_path,
self.embeddings,
allow_dangerous_deserialization=True
)
return self.vectorstore3.3检索器设置
def setup_retrievers(self):
"""设置向量检索器和BM25检索器"""
# 向量检索器
self.vector_retriever = self.vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": 5}
)
# BM25检索器
self.bm25_retriever = BM25Retriever.from_documents(
self.chunks,
k=5
)3.4RRF混合检索
def hybrid_search(self, query: str, top_k: int = 3) -> List[Document]:
"""混合检索 - 结合向量检索和BM25检索,使用RRF重排"""
# 分别获取向量检索和BM25检索结果
vector_docs = self.vector_retriever.get_relevant_documents(query)
bm25_docs = self.bm25_retriever.get_relevant_documents(query)
# 使用RRF重排
reranked_docs = self._rrf_rerank(vector_docs, bm25_docs)
return reranked_docs[:top_k]
def _rrf_rerank(self, vector_results: List[Document], bm25_results: List[Document]) -> List[Document]:
"""RRF (Reciprocal Rank Fusion) 重排"""
# RRF融合算法
rrf_scores = {}
k = 60 # RRF参数
# 计算向量检索的RRF分数
for rank, doc in enumerate(vector_results):
doc_id = id(doc)
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank + 1)
# 计算BM25检索的RRF分数
for rank, doc in enumerate(bm25_results):
doc_id = id(doc)
rrf_scores[doc_id] = rrf_scores.get(doc_id, 0) + 1 / (k + rank + 1)
# 合并所有文档并按RRF分数排序
all_docs = {id(doc): doc for doc in vector_results + bm25_results}
sorted_docs = sorted(all_docs.items(),
key=lambda x: rrf_scores.get(x[0], 0),
reverse=True)
return [doc for _, doc in sorted_docs]两种检索方式各有优势:
向量检索的优势:
- 理解语义相似性,如"简单易做的菜"能匹配到标记为"简单"的菜谱
- 处理同义词和近义词,如"制作方法"和"做法"、"烹饪步骤"
- 理解用户意图,如"适合新手"能找到难度较低的菜谱
BM25检索的优势:
- 精确匹配菜名,如"宫保鸡丁"能准确找到对应菜谱
- 匹配具体食材,如"土豆丝"、"西红柿"等关键词
- 处理专业术语,如"爆炒"、"红烧"等烹饪手法
RRF算法能综合两种检索方式的排名信息,既保证了语义理解的准确性,又确保了关键词匹配的精确性。当然还可以用路由的方式,根据查询类型智能选择使用向量检索还是BM25检索。这种方法针对性强,能为不同类型的查询选择最优的检索方式;不足是路由规则的设计和维护比较复杂,边界情况难以处理,而且通常需要调用LLM来判断查询类型,会增加延迟和成本。
3.5元数据过滤检索
过滤检索应用场景:
- 用户询问"推荐几道素菜"时,可以按菜品分类过滤,只检索素菜相关的内容
- 新手用户问"有什么简单的菜谱"时,可以按难度等级过滤,只返回标记为"简单"的菜谱
- 想做汤品时询问"今天喝什么汤",可以按分类过滤出所有汤品菜谱
def metadata_filtered_search(self, query: str, filters: Dict[str, Any],
top_k: int = 5) -> List[Document]:
"""基于元数据过滤的检索"""
# 先进行向量检索
vector_retriever = self.vectorstore.as_retriever(
search_type="similarity",
search_kwargs={"k": top_k * 3, "filter": filters} # 扩大检索范围
)
results = vector_retriever.invoke(query)
return results[:top_k]4.生成集成与系统整合
参考代码:https://github.com/datawhalechina/all-in-rag/tree/main/code/C8
使用最新langchainV1.0版本修改以下代码:
retrieval_optimization.py
vector_docs = self.vector_retriever.get_relevant_documents(query)
bm25_docs = self.bm25_retriever.get_relevant_documents(query)
改成:
vector_docs = self.vector_retriever.invoke(query)
bm25_docs = self.bm25_retriever.invoke(query)使用modelscope魔搭社区免费key替换代码:
config.py
llm_model: str = "Qwen/Qwen3-235B-A22B-Instruct-2507"
base_url:str="https://api-inference.modelscope.cn/v1/"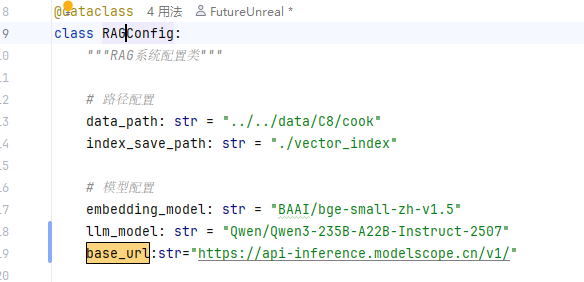
main.py注释以下代码
# 检查API密钥
# if not os.getenv("MOONSHOT_API_KEY"):
# raise ValueError("请设置 MOONSHOT_API_KEY 环境变量")generation_integration.py 替换代码:
from langchain_community.chat_models.moonshot import MoonshotChat
# self.llm = MoonshotChat(
# model=self.model_name,
# temperature=self.temperature,
# max_tokens=self.max_tokens,
# moonshot_api_key=api_key
# )
改成以下代码:
from langchain_openai import ChatOpenAI
self.llm=ChatOpenAI(
model='deepseek-ai/DeepSeek-V3.1',
api_key=api_key,
max_tokens=10,
base_url="https://api-inference.modelscope.cn/v1")运行main.py效果如下:
已连接到 pydev 调试器(内部版本号 251.26927.74)============================================================
🍽️ 尝尝咸淡RAG系统 - 交互式问答 🍽️
============================================================
💡 解决您的选择困难症,告别'今天吃什么'的世纪难题!
🚀 正在初始化RAG系统...
初始化数据准备模块...
初始化索引构建模块...
2025-11-29 00:25:25,113 - rag_modules.index_construction - INFO - 正在初始化嵌入模型: BAAI/bge-small-zh-v1.5
2025-11-29 00:25:45,645 - sentence_transformers.SentenceTransformer - INFO - Load pretrained SentenceTransformer: BAAI/bge-small-zh-v1.5
2025-11-29 00:25:52,077 - rag_modules.index_construction - INFO - 嵌入模型初始化完成
2025-11-29 00:25:52,077 - rag_modules.generation_integration - INFO - 正在初始化LLM: Qwen/Qwen3-235B-A22B-Instruct-2507
🤖 初始化生成集成模块...
2025-11-29 00:25:59,807 - rag_modules.generation_integration - INFO - LLM初始化完成
2025-11-29 00:25:59,815 - faiss.loader - INFO - Loading faiss with AVX2 support.
✅ 系统初始化完成!
正在构建知识库...
2025-11-29 00:25:59,842 - faiss.loader - INFO - Successfully loaded faiss with AVX2 support.
2025-11-29 00:25:59,894 - rag_modules.index_construction - INFO - 向量索引已从 ./vector_index 加载
2025-11-29 00:25:59,894 - rag_modules.data_preparation - INFO - 正在从 ../../data/C8/cook 加载文档...
✅ 成功加载已保存的向量索引!
加载食谱文档...
2025-11-29 00:26:00,613 - rag_modules.data_preparation - INFO - 成功加载 323 个文档
2025-11-29 00:26:00,613 - rag_modules.data_preparation - INFO - 正在进行Markdown结构感知分块...
进行文本分块...
2025-11-29 00:26:00,774 - rag_modules.data_preparation - INFO - Markdown结构分割完成,生成 1764 个结构化块
2025-11-29 00:26:00,775 - rag_modules.data_preparation - INFO - Markdown分块完成,共生成 1764 个chunk
2025-11-29 00:26:00,776 - rag_modules.retrieval_optimization - INFO - 正在设置检索器...
初始化检索优化...
2025-11-29 00:26:01,365 - rag_modules.retrieval_optimization - INFO - 检索器设置完成
📊 知识库统计:
文档总数: 323
文本块数: 1764
菜品分类: ['水产', '早餐', '调料', '饮品', '荤菜', '其他', '汤品', '主食', '素菜', '甜品']
难度分布: {'困难': 78, '中等': 115, '非常简单': 27, '简单': 83, '非常困难': 20}
✅ 知识库构建完成!
交互式问答 (输入'退出'结束):
您的问题: >
输入问题:推荐几道简单的素菜?
您的问题: >? 推荐几道简单的素菜
是否使用流式输出? (y/n, 默认y): >? y
回答:
❓ 用户问题: 推荐几道简单的素菜
2025-11-29 00:28:00,790 - httpx - INFO - HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 200 OK"
🎯 查询类型: list
📝 列表查询保持原样: 推荐几道简单的素菜
🔍 检索相关文档...
应用过滤条件: {'category': '素菜', 'difficulty': '简单'}
2025-11-29 00:28:20,407 - rag_modules.retrieval_optimization - INFO - RRF重排完成: 向量检索5个文档, BM25检索5个文档, 合并后10个文档
2025-11-29 00:28:20,408 - rag_modules.data_preparation - INFO - 从 2 个子块中找到 2 个去重父文档: 素炒豆角(1块), 凉拌豆腐(1块)
找到 2 个相关文档块: 素炒豆角(素炒豆角的做法
巨下饭的家常菜
预估烹饪难度:★), 凉拌豆腐(必备原料和工具
- 豆腐 (推荐选用北豆腐或老豆腐)
- 小葱
- 大蒜
- 生抽
- 香油
- 醋(可选)
- 白糖(可选)
- 辣椒油(可选)
📋 生成菜品列表...
找到文档: 素炒豆角, 凉拌豆腐
为您推荐以下菜品:
1. 素炒豆角
2. 凉拌豆腐
输入问题:宫保鸡丁怎么做?
您的问题: >? 宫保鸡丁怎么做?
是否使用流式输出? (y/n, 默认y): >? y
回答:
❓ 用户问题: 宫保鸡丁怎么做?
2025-11-29 02:07:36,410 - httpx - INFO - HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 200 OK"
🎯 查询类型: detail
🤖 智能分析查询...
2025-11-29 02:07:36,979 - httpx - INFO - HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 200 OK"
🔍 检索相关文档...
2025-11-29 02:07:36,997 - rag_modules.generation_integration - INFO - 查询已重写: '宫保鸡丁怎么做?' → '宫保鸡丁怎么做'
2025-11-29 02:07:48,160 - rag_modules.retrieval_optimization - INFO - RRF重排完成: 向量检索5个文档, BM25检索5个文档, 合并后10个文档
2025-11-29 02:07:48,162 - rag_modules.data_preparation - INFO - 从 3 个子块中找到 2 个去重父文档: 宫保鸡丁(2块), 咖喱炒蟹(1块)
找到 3 个相关文档块: 宫保鸡丁(宫保鸡丁的做法
老派川菜的简单做法分享
预估烹饪难度:★★★), 咖喱炒蟹(咖喱炒蟹的做法
第一次吃咖喱炒蟹是在泰国的建兴酒家中餐厅,爆肉的螃蟹挂满有蟹黄味道的咖喱,味道真的绝,喜欢吃海鲜的程序员绝对不能错过。操作简单,对沿海的程序员非常友好。
预估烹饪难度:★★★), 宫保鸡丁(操作
### 简易版本
- 手枪腿用剪刀去骨,鸡肉面用刀背拍打一遍,切条后切至 1.5cm 见方肉丁;泡于清水 10 分钟,捞出控干备用(若是鸡胸脯肉,则可以直接进行切丁以及之后的动作)
- 取大葱葱绿与姜片 5g 于碗中,倒入 50g 开水备用;葱白切 1.5cm 圆粒备用;取花生放入微波炉高火 5 分钟焙干备用
- 鸡丁中加入盐 2g,老抽酱油 5g,料酒 15g,淀粉 15g 搅拌均匀,至微微发干;缓慢加入部分葱姜水,搅拌鸡丁至粘手;保鲜膜密封,放入冰箱腌制 1 小时
- 干辣椒切段;起锅,大火烧热转小火;放入干辣椒焙干至微微发糊,捞起备用;花椒焙干至有香味,捞起备用
- 转大火,倒入 20g 植物油,7 成热(竹筷子起泡)下入鸡丁,煎至上面开始发白,用锅铲翻面,煎 30s 后翻炒均匀
- 下入葱粒翻炒,加入余下葱姜水不够 100g 再加一点清水(务必是热水);盖上锅盖,转中小火焖 2 分钟;
- 转大火,下入熟花生,干辣椒和花椒;加入鸡精 2g,香醋 5g,白糖 2g,翻炒均匀;
- 淀粉 10g 加 50g 清水调成水淀粉,加入锅中,翻炒均匀,收汁到自己想要的浓度
- 关火,淋入芝麻油 10g,即可出)
获取完整文档...
找到文档: 宫保鸡丁, 咖喱炒蟹
✍️ 生成详细回答...
2025-11-29 02:07:48,758 - httpx - INFO - HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 200 OK"
## 🥘 菜品介绍
宫保鸡丁是一道经典川菜,以鸡肉的嫩滑、花生的香脆和麻辣酸甜的复合口味著称。传统做法注重"糊辣味型",需控制火候和调味平衡,难度较高(★★★★),但家庭版可适当简化。
---
## 🛒 所需食材(2人份)
**主料**:
- 鸡腿肉(或鸡胸肉)350g
- 大葱1根(约180g)
- 熟花生150g
- 干辣椒10g(或二荆条4根)
**腌料**:
- 盐2g、老抽5g、料酒15g、淀粉15g
**调味汁**:
- 生抽10g、香醋5g、白糖2g、鸡精2g
- 水淀粉(淀粉10g + 清水50g)
- 芝麻油10g
**可选增香**:
- 花椒5g、豆瓣酱10g、莴笋丁250g
---
## 👨🍳 制作步骤
### ✅ 步骤1:预处理食材(15分钟)
- 鸡腿去骨,刀背拍松肉纤维,切1.5cm丁,泡清水10分钟去腥,沥干备用。
- 大葱取葱白切1.5cm段,葱绿与5g姜片加50g开水泡成葱姜水。
- 干辣椒剪段,花生微波高火5分钟焙香(生花生则需炒香)。
### ✅ 步骤2:腌制鸡肉(1小时,含静置)
- 鸡丁加盐、老抽、料酒、淀粉抓匀至发干。
- 分次加入葱姜水,搅拌至粘手,密封冷藏腌1小时(急用可缩至30分钟)。
### ✅ 步骤3:焙香调料(3分钟)
- 干辣椒、花椒分别小火焙干至微糊,盛出备用(激发糊辣味)。
### ✅ 步骤4:炒制鸡肉(5分钟)
- 热锅倒20g油,七成油温(筷子冒泡)下鸡丁,煎至表面发白后翻炒1分钟。
- 加葱段、剩余葱姜水(补热水至100g),盖锅盖中小火焖2分钟。
### ✅ 步骤5:调味收汁(2分钟)
- 加花生、焙好的辣椒/花椒、糖、醋、鸡精,大火翻炒。
- 淋水淀粉勾芡至汤汁浓稠,关火拌入芝麻油。
---
## 💡 制作技巧
1. **鸡肉嫩滑关键**:鸡腿肉更耐炒,拍松+泡水+腌制冷藏锁住水分。
2. **糊辣味控制**:辣椒/花椒焙至微糊即可,避免焦苦。
3. **酸甜平衡**:糖醋比例1:2.5(糖2g:醋5g),起锅前加醋保持酸香。
4. **勾芡注意**:芡汁需预调匀,沿锅边淋入快速翻炒防结块。
> 可选加莴笋增加清脆口感,或豆瓣酱提鲜辣味,根据口味灵活调整辣椒用量。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 21
21 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)