ICLR2025 源码论文大全集+算法流程图+思维导图+逐篇可视化解读 (Part-1)
ICLR2025 源码论文大全集+算法流程图+思维导图+逐篇可视化解读 (Part-1)
访问下述每篇论文的链接即可看到每篇论文的可视化解读以及各个大模型对这篇论文的全方位解读
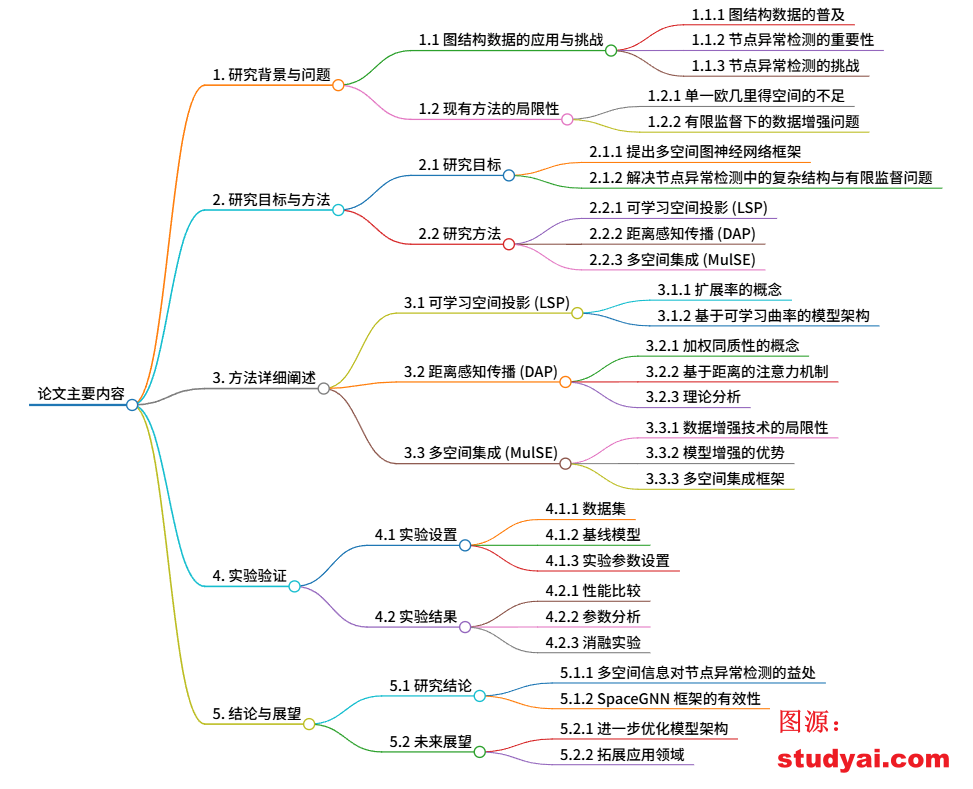
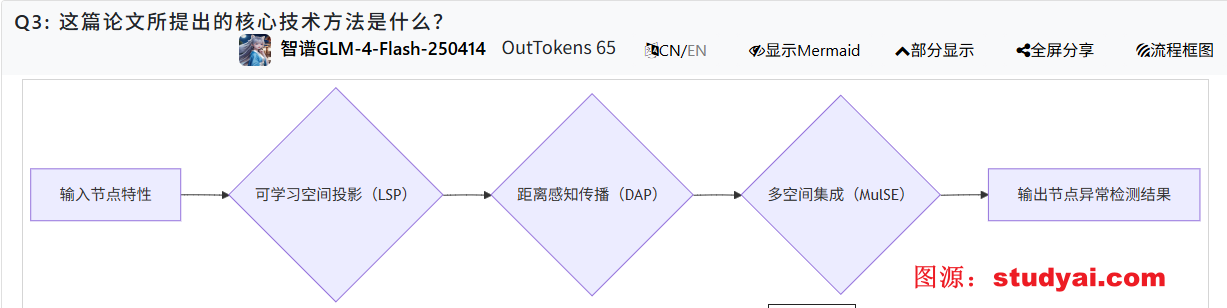
SpaceGNN: Multi-Space Graph Neural Network for Node Anomaly Detection with Extremely Limited Labels
SpaceGNN:用于节点异常检测的多空间图神经网络,标签极其有限
文章解读: SpaceGNN:用于节点异常检测的多空间图神经网络,标签极其有限
http://www.studyai.com/xueshu/paper/detail/1020602336
RetroInText: A Multimodal Large Language Model Enhanced Framework for Retrosynthetic Planning via In-Context Representation Learning
RetroInText:一种通过情境表征学习进行逆合成规划的多模态大语言模型增强框架
文章解读: RetroInText:一种通过情境表征学习进行逆合成规划的多模态大语言模型增强框架
http://www.studyai.com/xueshu/paper/detail/1023185159
Shared-AE: Automatic Identification of Shared Subspaces in High-dimensional Neural and Behavioral Activity
共享自动编码器:高维神经和行为活动中的共享子空间自动识别
文章解读: 共享自动编码器:高维神经和行为活动中的共享子空间自动识别
http://www.studyai.com/xueshu/paper/detail/1027768129
Efficient Inference for Large Language Model-based Generative Recommendation
基于大语言模型的生成式推荐的高效推理
文章解读: 基于大语言模型的生成式推荐的高效推理
http://www.studyai.com/xueshu/paper/detail/1036383651
The Labyrinth of Links: Navigating the Associative Maze of Multi-modal LLMs
链接迷宫:在多模态LLMs的关联迷宫中导航
文章解读: 链接迷宫:在多模态LLMs的关联迷宫中导航
http://www.studyai.com/xueshu/paper/detail/1038087909
Diffusion Bridge Implicit Models
扩散桥隐式模型
文章解读: 扩散桥隐式模型
http://www.studyai.com/xueshu/paper/detail/1065097516
Boosting the visual interpretability of CLIP via adversarial fine-tuning
通过对抗微调提升CLIP的可视化可解释性
文章解读: 通过对抗微调提升CLIP的可视化可解释性
http://www.studyai.com/xueshu/paper/detail/1065267281
APE: Faster and Longer Context-Augmented Generation via Adaptive Parallel Encoding
APE:通过自适应并行编码实现更快、更长的上下文增强生成
文章解读: APE:通过自适应并行编码实现更快、更长的上下文增强生成
http://www.studyai.com/xueshu/paper/detail/1066872133
Zero-cost Proxy for Adversarial Robustness Evaluation
零成本代理模型用于对抗鲁棒性评估
文章解读: 零成本代理模型用于对抗鲁棒性评估
http://www.studyai.com/xueshu/paper/detail/1068803313
Discrete Diffusion Schrödinger Bridge Matching for Graph Transformation
离散扩散薛定谔桥匹配用于图变换
文章解读: 离散扩散薛定谔桥匹配用于图变换
http://www.studyai.com/xueshu/paper/detail/1069731769
Group-robust Sample Reweighting for Subpopulation Shifts via Influence Functions
基于影响函数的子群体偏移的组鲁棒样本重加权
文章解读: 基于影响函数的子群体偏移的组鲁棒样本重加权
http://www.studyai.com/xueshu/paper/detail/1070851321
Rare-to-Frequent: Unlocking Compositional Generation Power of Diffusion Models on Rare Concepts with LLM Guidance
稀有到频繁:利用LLM指导解锁扩散模型在稀有概念上的组合生成能力
文章解读: 稀有到频繁:利用LLM指导解锁扩散模型在稀有概念上的组合生成能力
http://www.studyai.com/xueshu/paper/detail/1076253595
Local Patterns Generalize Better for Novel Anomalies
局部模式对新颖异常泛化效果更好
文章解读: 局部模式对新颖异常泛化效果更好
http://www.studyai.com/xueshu/paper/detail/1077888870
TaskGalaxy: Scaling Multi-modal Instruction Fine-tuning with Tens of Thousands Vision Task Types
任务星系:使用数万个视觉任务类型扩展多模态指令微调
文章解读: 任务星系:使用数万个视觉任务类型扩展多模态指令微调
http://www.studyai.com/xueshu/paper/detail/1083382158
Robust Root Cause Diagnosis using In-Distribution Interventions
基于分布内干预的鲁棒根本原因诊断
文章解读: 基于分布内干预的鲁棒根本原因诊断
http://www.studyai.com/xueshu/paper/detail/1083985939
Uni 2 ^2 2Det: Unified and Universal Framework for Prompt-Guided Multi-dataset 3D Detection
Uni 2 ^2 2Det:统一且通用的引导式多数据集三维检测框架
文章解读: Uni 2 ^2 2Det:统一且通用的引导式多数据集三维检测框架
http://www.studyai.com/xueshu/paper/detail/1089966019
Adaptive teachers for amortized samplers
用于分摊采样器的自适应教师
文章解读: 用于分摊采样器的自适应教师
http://www.studyai.com/xueshu/paper/detail/1090861259
SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models
SPaR:使用树搜索改进策略的自博弈以提升大语言模型的指令遵循能力
文章解读: SPaR:使用树搜索改进策略的自博弈以提升大语言模型的指令遵循能力
http://www.studyai.com/xueshu/paper/detail/1095759380
Q-Adapter: Customizing Pre-trained LLMs to New Preferences with Forgetting Mitigation
Q-适配器:通过遗忘缓解技术定制预训练大语言模型的新偏好
文章解读: Q-适配器:通过遗忘缓解技术定制预训练大语言模型的新偏好
http://www.studyai.com/xueshu/paper/detail/1108231909
ParFam – (Neural Guided) Symbolic Regression via Continuous Global Optimization
ParFam – (神经引导) 符号回归通过连续全局优化
文章解读: ParFam – (神经引导) 符号回归通过连续全局优化
http://www.studyai.com/xueshu/paper/detail/1112330398
MuseGNN: Forming Scalable, Convergent GNN Layers that Minimize a Sampling-Based Energy
MuseGNN:构建可扩展、收敛的GNN层以最小化基于采样的能量
文章解读: MuseGNN:构建可扩展、收敛的GNN层以最小化基于采样的能量
http://www.studyai.com/xueshu/paper/detail/1123832372
MrSteve: Instruction-Following Agents in Minecraft with What-Where-When Memory
MrSteve:在Minecraft中具有What-Where-When记忆的指令跟随代理
文章解读: MrSteve:在Minecraft中具有What-Where-When记忆的指令跟随代理
http://www.studyai.com/xueshu/paper/detail/1129760285
When Attention Sink Emerges in Language Models: An Empirical View
当注意力机制在语言模型中出现:一种实证观点
文章解读: 当注意力机制在语言模型中出现:一种实证观点
http://www.studyai.com/xueshu/paper/detail/1165787972
ConFIG: Towards Conflict-free Training of Physics Informed Neural Networks
ConFIG:面向物理信息神经网络的冲突消除训练
文章解读: ConFIG:面向物理信息神经网络的冲突消除训练
http://www.studyai.com/xueshu/paper/detail/1175556016
Second-Order Fine-Tuning without Pain for LLMs: A Hessian Informed Zeroth-Order Optimizer
为LLMs进行无痛苦的二阶微调:一种基于Hessian信息的零阶优化器
文章解读: 为LLMs进行无痛苦的二阶微调:一种基于Hessian信息的零阶优化器
http://www.studyai.com/xueshu/paper/detail/1180729337
LongMamba: Enhancing Mamba’s Long-Context Capabilities via Training-Free Receptive Field Enlargement
LongMamba:通过无训练感受野扩大增强Mamba的长期上下文能力
文章解读: LongMamba:通过无训练感受野扩大增强Mamba的长期上下文能力
http://www.studyai.com/xueshu/paper/detail/1182068353
MA-RLHF: Reinforcement Learning from Human Feedback with Macro Actions
MA-RLHF:基于宏观动作的人类反馈强化学习
文章解读: MA-RLHF:基于宏观动作的人类反馈强化学习
http://www.studyai.com/xueshu/paper/detail/1183798801
Score Forgetting Distillation: A Swift, Data-Free Method for Machine Unlearning in Diffusion Models
遗忘分数蒸馏:扩散模型中机器无学习的快速、无数据方法
文章解读: 遗忘分数蒸馏:扩散模型中机器无学习的快速、无数据方法
http://www.studyai.com/xueshu/paper/detail/1198029165
Towards Domain Adaptive Neural Contextual Bandits
面向领域自适应神经上下文 bandit
文章解读: 面向领域自适应神经上下文 bandit
http://www.studyai.com/xueshu/paper/detail/1209175718
Score-based Self-supervised MRI Denoising
基于分数的自监督MRI去噪
文章解读: 基于分数的自监督MRI去噪
http://www.studyai.com/xueshu/paper/detail/1210986336
Field-DiT: Diffusion Transformer on Unified Video, 3D, and Game Field Generation
Field-DiT:统一视频、3D和游戏场景生成的扩散Transformer
文章解读: Field-DiT:统一视频、3D和游戏场景生成的扩散Transformer
http://www.studyai.com/xueshu/paper/detail/1213607033
TC-MoE: Augmenting Mixture of Experts with Ternary Expert Choice
TC-MoE:使用三元专家选择增强专家混合模型
文章解读: TC-MoE:使用三元专家选择增强专家混合模型
http://www.studyai.com/xueshu/paper/detail/1215785629
Diffusion On Syntax Trees For Program Synthesis
程序合成中的语法树扩散
文章解读: 程序合成中的语法树扩散
http://www.studyai.com/xueshu/paper/detail/1220795568
Robust Simulation-Based Inference under Missing Data via Neural Processes
基于神经过程的缺失数据下的鲁棒仿真推理
文章解读: 基于神经过程的缺失数据下的鲁棒仿真推理
http://www.studyai.com/xueshu/paper/detail/1225030910
Generative Representational Instruction Tuning
生成式表征指令微调
文章解读: 生成式表征指令微调
http://www.studyai.com/xueshu/paper/detail/1229108181
Scalable Bayesian Learning with posteriors
可扩展的贝叶斯学习与后验分布
文章解读: 可扩展的贝叶斯学习与后验分布
http://www.studyai.com/xueshu/paper/detail/1230001517
NNsight and NDIF: Democratizing Access to Open-Weight Foundation Model Internals
NNsight和NDIF:使开放权重基础模型内部更加普及
文章解读: NNsight和NDIF:使开放权重基础模型内部更加普及
http://www.studyai.com/xueshu/paper/detail/1231002753
Advancing Prompt-Based Methods for Replay-Independent General Continual Learning
推进基于提示的方法以实现重放无关的通用持续学习
文章解读: 推进基于提示的方法以实现重放无关的通用持续学习
http://www.studyai.com/xueshu/paper/detail/1250285592
DICE: Data Influence Cascade in Decentralized Learning
DICE:去中心化学习中的数据影响级联
文章解读: DICE:去中心化学习中的数据影响级联
http://www.studyai.com/xueshu/paper/detail/1252527125
Selective Aggregation for Low-Rank Adaptation in Federated Learning
联邦学习中的低秩自适应选择性聚合
文章解读: 联邦学习中的低秩自适应选择性聚合
http://www.studyai.com/xueshu/paper/detail/1271810126
DebGCD: Debiased Learning with Distribution Guidance for Generalized Category Discovery
DebGCD:基于分布引导的偏差学习,用于广义类别发现
文章解读: DebGCD:基于分布引导的偏差学习,用于广义类别发现
http://www.studyai.com/xueshu/paper/detail/1275918277
A Multiscale Frequency Domain Causal Framework for Enhanced Pathological Analysis
一种用于增强病理分析的跨尺度频域因果框架
文章解读: 一种用于增强病理分析的跨尺度频域因果框架
http://www.studyai.com/xueshu/paper/detail/1276568216
Accelerating Goal-Conditioned Reinforcement Learning Algorithms and Research
加速目标条件强化学习算法与研究
文章解读: 加速目标条件强化学习算法与研究
http://www.studyai.com/xueshu/paper/detail/1278258133
LASeR: Towards Diversified and Generalizable Robot Design with Large Language Models
LASeR:基于大语言模型的多样化与泛化机器人设计
文章解读: LASeR:基于大语言模型的多样化与泛化机器人设计
http://www.studyai.com/xueshu/paper/detail/1285269137
DartControl: A Diffusion-Based Autoregressive Motion Model for Real-Time Text-Driven Motion Control
DartControl:一种基于扩散的自回归运动模型,用于实时文本驱动的运动控制
文章解读: DartControl:一种基于扩散的自回归运动模型,用于实时文本驱动的运动控制
http://www.studyai.com/xueshu/paper/detail/1286672719
DiTTo-TTS: Diffusion Transformers for Scalable Text-to-Speech without Domain-Specific Factors
DiTTo-TTS:用于可扩展文本到语音的扩散Transformer,无需特定领域因素
文章解读: DiTTo-TTS:用于可扩展文本到语音的扩散Transformer,无需特定领域因素
http://www.studyai.com/xueshu/paper/detail/1295350378
Permute-and-Flip: An optimally stable and watermarkable decoder for LLMs
置换与翻转:一种针对LLMs的最优稳定且可加水的解码器
文章解读: 置换与翻转:一种针对LLMs的最优稳定且可加水的解码器
http://www.studyai.com/xueshu/paper/detail/1299230378
SoundCTM: Unifying Score-based and Consistency Models for Full-band Text-to-Sound Generation
SoundCTM:统一基于分数和一致性模型的全频段文本到语音生成
文章解读: SoundCTM:统一基于分数和一致性模型的全频段文本到语音生成
http://www.studyai.com/xueshu/paper/detail/1302362302
AFlow: Automating Agentic Workflow Generation
AFlow:自动化代理工作流生成
文章解读: AFlow:自动化代理工作流生成
http://www.studyai.com/xueshu/paper/detail/1303307528
Diff-2-in-1: Bridging Generation and Dense Perception with Diffusion Models
Diff-2-in-1:通过扩散模型连接生成与密集感知
文章解读: Diff-2-in-1:通过扩散模型连接生成与密集感知
http://www.studyai.com/xueshu/paper/detail/1303839651
LiNeS: Post-training Layer Scaling Prevents Forgetting and Enhances Model Merging
LiNeS:训练后层缩放防止遗忘并增强模型合并
文章解读: LiNeS:训练后层缩放防止遗忘并增强模型合并
http://www.studyai.com/xueshu/paper/detail/1305895512
Continuous Autoregressive Modeling with Stochastic Monotonic Alignment for Speech Synthesis
带随机单调对齐的连续自回归建模用于语音合成
文章解读: 带随机单调对齐的连续自回归建模用于语音合成
http://www.studyai.com/xueshu/paper/detail/1306550251
EgoSim: Egocentric Exploration in Virtual Worlds with Multi-modal Conditioning
EgoSim:多模态条件下的虚拟世界中的第一人称探索
文章解读: EgoSim:多模态条件下的虚拟世界中的第一人称探索
http://www.studyai.com/xueshu/paper/detail/1310776918
Continuous Diffusion for Mixed-Type Tabular Data
混合类型表格数据的连续扩散
文章解读: 混合类型表格数据的连续扩散
http://www.studyai.com/xueshu/paper/detail/1320182969
Neural Eulerian Scene Flow Fields
神经欧拉场景流场
文章解读: 神经欧拉场景流场
http://www.studyai.com/xueshu/paper/detail/1323293879
Vision-RWKV: Efficient and Scalable Visual Perception with RWKV-Like Architectures
视觉-RWKV:基于类似RWKV架构的高效可扩展视觉感知
文章解读: 视觉-RWKV:基于类似RWKV架构的高效可扩展视觉感知
http://www.studyai.com/xueshu/paper/detail/1357729762
Sparse Autoencoders Do Not Find Canonical Units of Analysis
稀疏自动编码器不会找到分析的单位
文章解读: 稀疏自动编码器不会找到分析的单位
http://www.studyai.com/xueshu/paper/detail/1360819883
Fast and Slow Streams for Online Time Series Forecasting Without Information Leakage
用于在线时间序列预测的无信息泄露快速流和慢速流
文章解读: 用于在线时间序列预测的无信息泄露快速流和慢速流
http://www.studyai.com/xueshu/paper/detail/1362823731
TimeKAN: KAN-based Frequency Decomposition Learning Architecture for Long-term Time Series Forecasting
TimeKAN:基于KAN的频率分解学习架构用于长期时间序列预测
文章解读: TimeKAN:基于KAN的频率分解学习架构用于长期时间序列预测
http://www.studyai.com/xueshu/paper/detail/1368709121
HeadMap: Locating and Enhancing Knowledge Circuits in LLMs
HeadMap:定位和增强大语言模型中的知识回路
文章解读: HeadMap:定位和增强大语言模型中的知识回路
http://www.studyai.com/xueshu/paper/detail/1375051771
SORRY-Bench: Systematically Evaluating Large Language Model Safety Refusal
SORRY-Bench:系统评估大语言模型安全拒绝
文章解读: SORRY-Bench:系统评估大语言模型安全拒绝
http://www.studyai.com/xueshu/paper/detail/1375819797
Towards Robust Multimodal Open-set Test-time Adaptation via Adaptive Entropy-aware Optimization
基于自适应熵感知优化实现鲁棒多模态开放集测试时适应
文章解读: 基于自适应熵感知优化实现鲁棒多模态开放集测试时适应
http://www.studyai.com/xueshu/paper/detail/1396061780
LANTERN: Accelerating Visual Autoregressive Models with Relaxed Speculative Decoding
LANTERN:通过放松推测解码加速视觉自回归模型
文章解读: LANTERN:通过放松推测解码加速视觉自回归模型
http://www.studyai.com/xueshu/paper/detail/1398719656
3DTrajMaster: Mastering 3D Trajectory for Multi-Entity Motion in Video Generation
3DTrajMaster:掌握视频生成中多实体运动的3D轨迹
文章解读: 3DTrajMaster:掌握视频生成中多实体运动的3D轨迹
http://www.studyai.com/xueshu/paper/detail/1506171698
PnP-Flow: Plug-and-Play Image Restoration with Flow Matching
PnP-Flow:即插即用图像复原与流匹配
文章解读: PnP-Flow:即插即用图像复原与流匹配
http://www.studyai.com/xueshu/paper/detail/1507893029
Efficient and Trustworthy Causal Discovery with Latent Variables and Complex Relations
基于潜变量和复杂关系的有效且可信的因果发现
文章解读: 基于潜变量和复杂关系的有效且可信的因果发现
http://www.studyai.com/xueshu/paper/detail/1513106660
Knowing Your Target: Target-Aware Transformer Makes Better Spatio-Temporal Video Grounding
了解你的目标:目标感知Transformer使时空视频定位更精准
文章解读: 了解你的目标:目标感知Transformer使时空视频定位更精准
http://www.studyai.com/xueshu/paper/detail/1539270051
Learning to Contextualize Web Pages for Enhanced Decision Making by LLM Agents
通过LLM代理对网页进行情境化学习以增强决策能力
文章解读: 通过LLM代理对网页进行情境化学习以增强决策能力
http://www.studyai.com/xueshu/paper/detail/1551921982
SimPER: A Minimalist Approach to Preference Alignment without Hyperparameters
SimPER:一种无需超参数的偏好对齐最小化方法
文章解读: SimPER:一种无需超参数的偏好对齐最小化方法
http://www.studyai.com/xueshu/paper/detail/1563179633
Graph Sparsification via Mixture of Graphs
基于图的混合稀疏化
文章解读: 基于图的混合稀疏化
http://www.studyai.com/xueshu/paper/detail/1582198856
Stabilizing Reinforcement Learning in Differentiable Multiphysics Simulation
在不同iable多物理场仿真中稳定强化学习
文章解读: 在不同iable多物理场仿真中稳定强化学习
http://www.studyai.com/xueshu/paper/detail/1582226582
Achieving Dimension-Free Communication in Federated Learning via Zeroth-Order Optimization
通过零阶优化在联邦学习中实现无维通信
文章解读: 通过零阶优化在联邦学习中实现无维通信
http://www.studyai.com/xueshu/paper/detail/1582697639
AutoG: Towards automatic graph construction from tabular data
AutoG:从表格数据自动构建图
文章解读: AutoG:从表格数据自动构建图
http://www.studyai.com/xueshu/paper/detail/1587303557
Probabilistic Language-Image Pre-Training
概率性语言-图像预训练
文章解读: 概率性语言-图像预训练
http://www.studyai.com/xueshu/paper/detail/1591789363
Generating Likely Counterfactuals Using Sum-Product Networks
使用和积网络生成可能的反事实
文章解读: 使用和积网络生成可能的反事实
http://www.studyai.com/xueshu/paper/detail/1611758939
AstroCompress: A benchmark dataset for multi-purpose compression of astronomical data
AstroCompress:一个用于多用途天文数据压缩的基准数据集
文章解读: AstroCompress:一个用于多用途天文数据压缩的基准数据集
http://www.studyai.com/xueshu/paper/detail/1617289980
Radar: Fast Long-Context Decoding for Any Transformer
雷达:适用于任何 Transformer 的快速长上下文解码
文章解读: 雷达:适用于任何 Transformer 的快速长上下文解码
http://www.studyai.com/xueshu/paper/detail/1621516006
MoDGS: Dynamic Gaussian Splatting from Casually-captured Monocular Videos with Depth Priors
MoDGS:基于深度先验的单目视频非正式捕捉动态高斯喷溅
文章解读: MoDGS:基于深度先验的单目视频非正式捕捉动态高斯喷溅
http://www.studyai.com/xueshu/paper/detail/1629082313
CFG++: Manifold-constrained Classifier Free Guidance for Diffusion Models
CFG :基于流形约束的分类器自由引导的扩散模型
文章解读: CFG :基于流形约束的分类器自由引导的扩散模型
http://www.studyai.com/xueshu/paper/detail/1638906978
Improving Generalization and Robustness in SNNs Through Signed Rate Encoding and Sparse Encoding Attacks
通过符号率编码和稀疏编码攻击提高SNNs的泛化性和鲁棒性
文章解读: 通过符号率编码和稀疏编码攻击提高SNNs的泛化性和鲁棒性
http://www.studyai.com/xueshu/paper/detail/1670288917
Preference Diffusion for Recommendation
推荐系统的偏好扩散
文章解读: 推荐系统的偏好扩散
http://www.studyai.com/xueshu/paper/detail/1676130695
TabWak: A Watermark for Tabular Diffusion Models
TabWak:表格扩散模型的数字水印
文章解读: TabWak:表格扩散模型的数字水印
http://www.studyai.com/xueshu/paper/detail/1683216636
SAM-CP: Marrying SAM with Composable Prompts for Versatile Segmentation
SAM-CP:将SAM与可组合提示结合,实现多功能分割
文章解读: SAM-CP:将SAM与可组合提示结合,实现多功能分割
http://www.studyai.com/xueshu/paper/detail/1683888371
ClawMachine: Learning to Fetch Visual Tokens for Referential Comprehension
爪机:学习获取视觉标记以实现指代理解
文章解读: 爪机:学习获取视觉标记以实现指代理解
http://www.studyai.com/xueshu/paper/detail/1689039059
ReMoE: Fully Differentiable Mixture-of-Experts with ReLU Routing
ReMoE:全微分专家混合模型与ReLU路由
文章解读: ReMoE:全微分专家混合模型与ReLU路由
http://www.studyai.com/xueshu/paper/detail/1695307976
Deep Kernel Relative Test for Machine-generated Text Detection
深度核相对测试用于机器生成文本检测
文章解读: 深度核相对测试用于机器生成文本检测
http://www.studyai.com/xueshu/paper/detail/1717279509
BEEM: Boosting Performance of Early Exit DNNs using Multi-Exit Classifiers as Experts
BEEM:利用多出口分类器作为专家来提升早期退出DNN的性能
文章解读: BEEM:利用多出口分类器作为专家来提升早期退出DNN的性能
http://www.studyai.com/xueshu/paper/detail/1718771335
DAWN: Dynamic Frame Avatar with Non-autoregressive Diffusion Framework for Talking head Video Generation
DAWN:用于Talking head视频生成的动态帧虚拟人,采用非自回归扩散框架
文章解读: DAWN:用于Talking head视频生成的动态帧虚拟人,采用非自回归扩散框架
http://www.studyai.com/xueshu/paper/detail/1725232813
FreCaS: Efficient Higher-Resolution Image Generation via Frequency-aware Cascaded Sampling
FreCaS:基于频率感知级联采样的高分辨率图像高效生成
文章解读: FreCaS:基于频率感知级联采样的高分辨率图像高效生成
http://www.studyai.com/xueshu/paper/detail/1753161200
DiffGAD: A Diffusion-based Unsupervised Graph Anomaly Detector
DiffGAD:一种基于扩散的无监督图异常检测器
文章解读: DiffGAD:一种基于扩散的无监督图异常检测器
http://www.studyai.com/xueshu/paper/detail/1768987955
Learning to Generate Diverse Pedestrian Movements from Web Videos with Noisy Labels
从含噪声标签的网页视频中学习生成多样化的行人运动
文章解读: 从含噪声标签的网页视频中学习生成多样化的行人运动
http://www.studyai.com/xueshu/paper/detail/1790273368
SuperCorrect: Advancing Small LLM Reasoning with Thought Template Distillation and Self-Correction
SuperCorrect:通过思维模板蒸馏和自我纠正推进小型LLM推理
文章解读: SuperCorrect:通过思维模板蒸馏和自我纠正推进小型LLM推理
http://www.studyai.com/xueshu/paper/detail/1790337180
Efficient Diffusion Transformer Policies with Mixture of Expert Denoisers for Multitask Learning
具有专家去噪器的混合扩散Transformer策略用于多任务学习
文章解读: 具有专家去噪器的混合扩散Transformer策略用于多任务学习
http://www.studyai.com/xueshu/paper/detail/1797553519
3D-MolT5: Leveraging Discrete Structural Information for Molecule-Text Modeling
3D-MolT5:利用离散结构信息进行分子-文本建模
文章解读: 3D-MolT5:利用离散结构信息进行分子-文本建模
http://www.studyai.com/xueshu/paper/detail/1800350086
Wayward Concepts In Multimodal Models
多模态模型中的离经叛道概念
文章解读: 多模态模型中的离经叛道概念
http://www.studyai.com/xueshu/paper/detail/1817856205
Diffusion Generative Modeling for Spatially Resolved Gene Expression Inference from Histology Images
基于扩散生成模型的组织学图像空间分辨基因表达推断
文章解读: 基于扩散生成模型的组织学图像空间分辨基因表达推断
http://www.studyai.com/xueshu/paper/detail/1838925197
OmniSep: Unified Omni-Modality Sound Separation with Query-Mixup
OmniSep:统一多模态声音分离与查询混合
文章解读: OmniSep:统一多模态声音分离与查询混合
http://www.studyai.com/xueshu/paper/detail/1850635536
Stealthy Shield Defense: A Conditional Mutual Information-Based Approach against Black-Box Model Inversion Attacks
隐蔽盾防御:一种基于条件互信息的方法,用于对抗黑盒模型反演攻击
文章解读: 隐蔽盾防御:一种基于条件互信息的方法,用于对抗黑盒模型反演攻击
http://www.studyai.com/xueshu/paper/detail/1852829738
On Scaling Up 3D Gaussian Splatting Training
关于扩展3D高斯splatting训练
文章解读: 关于扩展3D高斯splatting训练
http://www.studyai.com/xueshu/paper/detail/1853051801
Bridging the Gap between Database Search and \emph {De Novo} Peptide Sequencing with SearchNovo
通过SearchNovo弥合数据库检索与\emph {从头}肽测序之间的差距
文章解读: 通过SearchNovo弥合数据库检索与\emph{从头}肽测序之间的差距
http://www.studyai.com/xueshu/paper/detail/1859676869
ImDy: Human Inverse Dynamics from Imitated Observations
ImDy:从模仿观察中的人体逆动力学
文章解读: ImDy:从模仿观察中的人体逆动力学
http://www.studyai.com/xueshu/paper/detail/1861937720
BrainOOD: Out-of-distribution Generalizable Brain Network Analysis
BrainOOD:分布外泛化脑网络分析
文章解读: BrainOOD:分布外泛化脑网络分析
http://www.studyai.com/xueshu/paper/detail/1870865353
HD-Painter: High-Resolution and Prompt-Faithful Text-Guided Image Inpainting with Diffusion Models
HD-Painter:基于扩散模型的分辨率高且响应迅速的文本引导图像修复技术
文章解读: HD-Painter:基于扩散模型的分辨率高且响应迅速的文本引导图像修复技术
http://www.studyai.com/xueshu/paper/detail/1879508187
Adversarial Attacks on Data Attribution
数据归因中的对抗性攻击
文章解读: 数据归因中的对抗性攻击
http://www.studyai.com/xueshu/paper/detail/1880912398
Offline Model-Based Optimization by Learning to Rank
基于学习的离线模型优化
文章解读: 基于学习的离线模型优化
http://www.studyai.com/xueshu/paper/detail/1896859103
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
AgentHarm:一个用于衡量LLM代理有害性的基准
文章解读: AgentHarm:一个用于衡量LLM代理有害性的基准
http://www.studyai.com/xueshu/paper/detail/1908887122
Smoothing the Shift: Towards Stable Test-Time Adaptation under Complex Multimodal Noises
平滑转换:在复杂多模态噪声下实现稳定的测试时自适应
文章解读: 平滑转换:在复杂多模态噪声下实现稳定的测试时自适应
http://www.studyai.com/xueshu/paper/detail/1912315109
Gaussian Ensemble Belief Propagation for Efficient Inference in High-Dimensional, Black-box Systems
高维黑盒系统中的高效推理的高斯集成信念传播
文章解读: 高维黑盒系统中的高效推理的高斯集成信念传播
http://www.studyai.com/xueshu/paper/detail/1927762913
VideoShield: Regulating Diffusion-based Video Generation Models via Watermarking
VideoShield:通过水印技术对基于扩散的视频生成模型进行调控
文章解读: VideoShield:通过水印技术对基于扩散的视频生成模型进行调控
http://www.studyai.com/xueshu/paper/detail/1928035673
Distilled Decoding 1: One-step Sampling of Image Auto-regressive Models with Flow Matching
蒸馏解码1:流匹配图像自回归模型的单步采样
文章解读: 蒸馏解码1:流匹配图像自回归模型的单步采样
http://www.studyai.com/xueshu/paper/detail/1935318267
GI-GS: Global Illumination Decomposition on Gaussian Splatting for Inverse Rendering
GI-GS:高斯 splatting 中的全局光照分解用于逆向渲染
文章解读: GI-GS:高斯 splatting 中的全局光照分解用于逆向渲染
http://www.studyai.com/xueshu/paper/detail/1936825533
A Benchmark for Semantic Sensitive Information in LLMs Outputs
LLMs输出中语义敏感信息的基准
文章解读: LLMs输出中语义敏感信息的基准
http://www.studyai.com/xueshu/paper/detail/1950985890
Autoregressive Pretraining with Mamba in Vision
基于Mamba的视觉自回归预训练
文章解读: 基于Mamba的视觉自回归预训练
http://www.studyai.com/xueshu/paper/detail/1960801210
Booster: Tackling Harmful Fine-tuning for Large Language Models via Attenuating Harmful Perturbation
助推器:通过减弱有害扰动来解决大语言模型的危害性微调
文章解读: 助推器:通过减弱有害扰动来解决大语言模型的危害性微调
http://www.studyai.com/xueshu/paper/detail/1961795697
Drama: Mamba-Enabled Model-Based Reinforcement Learning Is Sample and Parameter Efficient
戏剧:基于Mamba的模型强化学习是样本和参数高效的
文章解读: 戏剧:基于Mamba的模型强化学习是样本和参数高效的
http://www.studyai.com/xueshu/paper/detail/1963923565
What Makes a Good Diffusion Planner for Decision Making?
什么是决策制定的良好扩散规划器?
文章解读: 什么是决策制定的良好扩散规划器?
http://www.studyai.com/xueshu/paper/detail/1982553132
Consistency Models Made Easy
一致性模型变得简单
文章解读: 一致性模型变得简单
http://www.studyai.com/xueshu/paper/detail/2006157263
Offline Hierarchical Reinforcement Learning via Inverse Optimization
基于逆优化的离线分层强化学习
文章解读: 基于逆优化的离线分层强化学习
http://www.studyai.com/xueshu/paper/detail/2006237992
MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
MonST3R:一种在存在运动时估计几何的方法
文章解读: MonST3R:一种在存在运动时估计几何的方法
http://www.studyai.com/xueshu/paper/detail/2032280782
RegMix: Data Mixture as Regression for Language Model Pre-training
RegMix:数据混合作为语言模型预训练的回归
文章解读: RegMix:数据混合作为语言模型预训练的回归
http://www.studyai.com/xueshu/paper/detail/2039595135
Mini-Monkey: Alleviating the Semantic Sawtooth Effect for Lightweight MLLMs via Complementary Image Pyramid
迷你猴子:通过互补图像金字塔减轻轻量级MLLM的语义锯齿效应
文章解读: 迷你猴子:通过互补图像金字塔减轻轻量级MLLM的语义锯齿效应
http://www.studyai.com/xueshu/paper/detail/2053236585
A Large-scale Dataset and Benchmark for Commuting Origin-Destination Flow Generation
一个大规模通勤起讫点流量生成数据集与基准
文章解读: 一个大规模通勤起讫点流量生成数据集与基准
http://www.studyai.com/xueshu/paper/detail/2058061205
SVDQuant: Absorbing Outliers by Low-Rank Component for 4-Bit Diffusion Models
SVDQuant:通过低秩分量吸收异常值以用于4位扩散模型
文章解读: SVDQuant:通过低秩分量吸收异常值以用于4位扩散模型
http://www.studyai.com/xueshu/paper/detail/2060911716
Law of the Weakest Link: Cross Capabilities of Large Language Models
最弱环节定律:大语言模型的跨能力
文章解读: 最弱环节定律:大语言模型的跨能力
http://www.studyai.com/xueshu/paper/detail/2066119869
Scale-aware Recognition in Satellite Images under Resource Constraints
资源受限下卫星图像的尺度感知识别
文章解读: 资源受限下卫星图像的尺度感知识别
http://www.studyai.com/xueshu/paper/detail/2067756750
Accelerating Auto-regressive Text-to-Image Generation with Training-free Speculative Jacobi Decoding
使用无训练推测雅可比解码加速自回归文本到图像生成
文章解读: 使用无训练推测雅可比解码加速自回归文本到图像生成
http://www.studyai.com/xueshu/paper/detail/2070117006
Build-A-Scene: Interactive 3D Layout Control for Diffusion-Based Image Generation
构建场景:基于扩散模型的图像生成的交互式3D布局控制
文章解读: 构建场景:基于扩散模型的图像生成的交互式3D布局控制
http://www.studyai.com/xueshu/paper/detail/2080999885
Block Diffusion: Interpolating Between Autoregressive and Diffusion Language Models
块扩散:在自回归和扩散语言模型之间插值
文章解读: 块扩散:在自回归和扩散语言模型之间插值
http://www.studyai.com/xueshu/paper/detail/2081329600
Evaluating Semantic Variation in Text-to-Image Synthesis: A Causal Perspective
对文本到图像合成中的语义变化进行评估:一种因果视角
文章解读: 对文本到图像合成中的语义变化进行评估:一种因果视角
http://www.studyai.com/xueshu/paper/detail/2082107593
Large Language Models Meet Symbolic Provers for Logical Reasoning Evaluation
大语言模型与符号证明器在逻辑推理评估中的结合
文章解读: 大语言模型与符号证明器在逻辑推理评估中的结合
http://www.studyai.com/xueshu/paper/detail/2088562058
DRESSing Up LLM: Efficient Stylized Question-Answering via Style Subspace Editing
为LLM着装:通过风格子空间编辑实现高效的风格化问答
文章解读: 为LLM着装:通过风格子空间编辑实现高效的风格化问答
http://www.studyai.com/xueshu/paper/detail/2092955760
Resolution Attack: Exploiting Image Compression to Deceive Deep Neural Networks
对抗攻击:利用图像压缩欺骗深度神经网络
文章解读: 对抗攻击:利用图像压缩欺骗深度神经网络
http://www.studyai.com/xueshu/paper/detail/2102930763
Few-Class Arena: A Benchmark for Efficient Selection of Vision Models and Dataset Difficulty Measurement
少数类竞技场:用于高效选择视觉模型和数据集难度测量的基准
文章解读: 少数类竞技场:用于高效选择视觉模型和数据集难度测量的基准
http://www.studyai.com/xueshu/paper/detail/2112680606
Timer-XL: Long-Context Transformers for Unified Time Series Forecasting
Timer-XL:用于统一时间序列预测的长上下文Transformer
文章解读: Timer-XL:用于统一时间序列预测的长上下文Transformer
http://www.studyai.com/xueshu/paper/detail/2115225681
SVBench: A Benchmark with Temporal Multi-Turn Dialogues for Streaming Video Understanding
SVBench:一个用于流视频理解的包含时间多轮对话的基准
文章解读: SVBench:一个用于流视频理解的包含时间多轮对话的基准
http://www.studyai.com/xueshu/paper/detail/2121321589
DisPose: Disentangling Pose Guidance for Controllable Human Image Animation
DisPose:解耦姿态引导的可控人体图像动画
文章解读: DisPose:解耦姿态引导的可控人体图像动画
http://www.studyai.com/xueshu/paper/detail/2122270215
Learning stochastic dynamics from snapshots through regularized unbalanced optimal transport
从快照中通过正则化非平衡最优传输学习随机动力学
文章解读: 从快照中通过正则化非平衡最优传输学习随机动力学
http://www.studyai.com/xueshu/paper/detail/2123088050
Poison-splat: Computation Cost Attack on 3D Gaussian Splatting
毒点:3D高斯喷溅的计算成本攻击
文章解读: 毒点:3D高斯喷溅的计算成本攻击
http://www.studyai.com/xueshu/paper/detail/2128037239
Scaling Large Language Model-based Multi-Agent Collaboration
基于大语言模型的多人协作的扩展
文章解读: 基于大语言模型的多人协作的扩展
http://www.studyai.com/xueshu/paper/detail/2131328133
Palu: KV-Cache Compression with Low-Rank Projection
帕卢:基于低秩投影的KV缓存压缩
文章解读: 帕卢:基于低秩投影的KV缓存压缩
http://www.studyai.com/xueshu/paper/detail/2158265010
Towards counterfactual fairness through auxiliary variables
通过辅助变量实现反事实公平
文章解读: 通过辅助变量实现反事实公平
http://www.studyai.com/xueshu/paper/detail/2167189226
Geometry-aware RL for Manipulation of Varying Shapes and Deformable Objects
基于几何感知的强化学习用于可变形状和可变形物体的操作
文章解读: 基于几何感知的强化学习用于可变形状和可变形物体的操作
http://www.studyai.com/xueshu/paper/detail/2179818137
Interpreting Emergent Planning in Model-Free Reinforcement Learning
在无模型强化学习中解释涌现规划
文章解读: 在无模型强化学习中解释涌现规划
http://www.studyai.com/xueshu/paper/detail/2191581220
PeriodWave: Multi-Period Flow Matching for High-Fidelity Waveform Generation
周期波:多周期流匹配用于高保真波形生成
文章解读: 周期波:多周期流匹配用于高保真波形生成
http://www.studyai.com/xueshu/paper/detail/2192070279
TorchTitan: One-stop PyTorch native solution for production ready LLM pretraining
TorchTitan:适用于生产环境的LLM预训练的一站式PyTorch原生解决方案
文章解读: TorchTitan:适用于生产环境的LLM预训练的一站式PyTorch原生解决方案
http://www.studyai.com/xueshu/paper/detail/2208086965
Iterative Label Refinement Matters More than Preference Optimization under Weak Supervision
在弱监督下,迭代标签细化比偏好优化更重要
文章解读: 在弱监督下,迭代标签细化比偏好优化更重要
http://www.studyai.com/xueshu/paper/detail/2219710872
Progressive Token Length Scaling in Transformer Encoders for Efficient Universal Segmentation
Transformer编码器中的渐进式标记长度扩展以实现高效通用分割
文章解读: Transformer编码器中的渐进式标记长度扩展以实现高效通用分割
http://www.studyai.com/xueshu/paper/detail/2238725336
Exact Certification of (Graph) Neural Networks Against Label Poisoning
对(图)神经网络进行精确的对抗标签中毒认证
文章解读: 对(图)神经网络进行精确的对抗标签中毒认证
http://www.studyai.com/xueshu/paper/detail/2251107135
ADBM: Adversarial Diffusion Bridge Model for Reliable Adversarial Purification
ADBM:对抗扩散桥模型用于可靠的对抗纯化
文章解读: ADBM:对抗扩散桥模型用于可靠的对抗纯化
http://www.studyai.com/xueshu/paper/detail/2256606903
Learning to Discretize Denoising Diffusion ODEs
学习离散化去噪扩散常微分方程
文章解读: 学习离散化去噪扩散常微分方程
http://www.studyai.com/xueshu/paper/detail/2260616308
Exposure Bracketing Is All You Need For A High-Quality Image
曝光包围是获得高质量图像的全部所需
文章解读: 曝光包围是获得高质量图像的全部所需
http://www.studyai.com/xueshu/paper/detail/2263253682
TRACE: Temporal Grounding Video LLM via Causal Event Modeling
TRACE:基于因果事件建模的时间 grounding 视频LLM
文章解读: TRACE:基于因果事件建模的时间 grounding 视频LLM
http://www.studyai.com/xueshu/paper/detail/2263685971
Physics-aligned field reconstruction with diffusion bridge
与物理对齐的场重建与扩散桥
文章解读: 与物理对齐的场重建与扩散桥
http://www.studyai.com/xueshu/paper/detail/2276362893
Fast and Accurate Blind Flexible Docking
快速精确的非视域柔性对接
文章解读: 快速精确的非视域柔性对接
http://www.studyai.com/xueshu/paper/detail/2277927103
gRNAde: Geometric Deep Learning for 3D RNA inverse design
gRNAde:用于3D RNA逆向设计的几何深度学习
文章解读: gRNAde:用于3D RNA逆向设计的几何深度学习
http://www.studyai.com/xueshu/paper/detail/2286516902
GIFT: Unlocking Full Potential of Labels in Distilled Dataset at Near-zero Cost
GIFT:以近乎零成本解锁蒸馏数据集中标签的完全潜力
文章解读: GIFT:以近乎零成本解锁蒸馏数据集中标签的完全潜力
http://www.studyai.com/xueshu/paper/detail/2287030185
MOS: Model Synergy for Test-Time Adaptation on LiDAR-Based 3D Object Detection
MOS:基于激光雷达的3D目标检测的测试时自适应模型协同
文章解读: MOS:基于激光雷达的3D目标检测的测试时自适应模型协同
http://www.studyai.com/xueshu/paper/detail/2288181662
Optimal Brain Apoptosis
最佳脑细胞凋亡
文章解读: 最佳脑细胞凋亡
http://www.studyai.com/xueshu/paper/detail/2291529397
Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
时-专家混合模型:具有专家混合的十亿规模时间序列基础模型
文章解读: 时-专家混合模型:具有专家混合的十亿规模时间序列基础模型
http://www.studyai.com/xueshu/paper/detail/2293965956
Autoregressive Video Generation without Vector Quantization
无需向量量化的自回归视频生成
文章解读: 无需向量量化的自回归视频生成
http://www.studyai.com/xueshu/paper/detail/2297595856
Investigating Pattern Neurons in Urban Time Series Forecasting
探究城市时间序列预测中的模式神经元
文章解读: 探究城市时间序列预测中的模式神经元
http://www.studyai.com/xueshu/paper/detail/2308123287
TDDBench: A Benchmark for Training data detection
TDDBench:用于训练数据检测的基准
文章解读: TDDBench:用于训练数据检测的基准
http://www.studyai.com/xueshu/paper/detail/2315976802
I2VControl-Camera: Precise Video Camera Control with Adjustable Motion Strength
I2VControl-相机:可调节运动强度的精确视频相机控制
文章解读: I2VControl-相机:可调节运动强度的精确视频相机控制
http://www.studyai.com/xueshu/paper/detail/2326257558
Track-On: Transformer-based Online Point Tracking with Memory
Track-On:基于Transformer的在线点跟踪与记忆
文章解读: Track-On:基于Transformer的在线点跟踪与记忆
http://www.studyai.com/xueshu/paper/detail/2330635726
Does Refusal Training in LLMs Generalize to the Past Tense?
LLMs中的拒绝训练是否泛化到过去时?
文章解读: LLMs中的拒绝训练是否泛化到过去时?
http://www.studyai.com/xueshu/paper/detail/2331297052
Online Reinforcement Learning in Non-Stationary Context-Driven Environments
非平稳情境驱动环境下的在线强化学习
文章解读: 非平稳情境驱动环境下的在线强化学习
http://www.studyai.com/xueshu/paper/detail/2333550680
Edge Prompt Tuning for Graph Neural Networks
图神经网络的边缘提示微调
文章解读: 图神经网络的边缘提示微调
http://www.studyai.com/xueshu/paper/detail/2357777676
Influence-Guided Diffusion for Dataset Distillation
基于影响力引导的扩散数据集蒸馏
文章解读: 基于影响力引导的扩散数据集蒸馏
http://www.studyai.com/xueshu/paper/detail/2383227222
FLIP: Flow-Centric Generative Planning as General-Purpose Manipulation World Model
FLIP:以流为中心的生成式规划作为通用操作世界模型
文章解读: FLIP:以流为中心的生成式规划作为通用操作世界模型
http://www.studyai.com/xueshu/paper/detail/2391322717
STBLLM: Breaking the 1-Bit Barrier with Structured Binary LLMs
STBLLM:使用结构化二进制LLM打破1比特障碍
文章解读: STBLLM:使用结构化二进制LLM打破1比特障碍
http://www.studyai.com/xueshu/paper/detail/2391572130
Spectral-Refiner: Accurate Fine-Tuning of Spatiotemporal Fourier Neural Operator for Turbulent Flows
光谱细化器:用于湍流的时空傅里叶神经算子的精确微调
文章解读: 光谱细化器:用于湍流的时空傅里叶神经算子的精确微调
http://www.studyai.com/xueshu/paper/detail/2399707395
From Attention to Activation: Unraveling the Enigmas of Large Language Models
从注意力到激活:揭开大语言模型的谜团
文章解读: 从注意力到激活:揭开大语言模型的谜团
http://www.studyai.com/xueshu/paper/detail/2503005025
SIM: Surface-based fMRI Analysis for Inter-Subject Multimodal Decoding from Movie-Watching Experiments
基于表面的fMRI分析:用于电影观看实验中跨被试多模态解码的SIM
文章解读: 基于表面的fMRI分析:用于电影观看实验中跨被试多模态解码的SIM
http://www.studyai.com/xueshu/paper/detail/2503009673
Towards a Theoretical Understanding of Synthetic Data in LLM Post-Training: A Reverse-Bottleneck Perspective
面向LLM微调后合成数据的理论理解:逆向瓶颈视角
文章解读: 面向LLM微调后合成数据的理论理解:逆向瓶颈视角
http://www.studyai.com/xueshu/paper/detail/2507523920
Revisit the Open Nature of Open Vocabulary Semantic Segmentation
重新审视开放词汇语义分割的开放性
文章解读: 重新审视开放词汇语义分割的开放性
http://www.studyai.com/xueshu/paper/detail/2510971980
Physics-Informed Diffusion Models
物理信息扩散模型
文章解读: 物理信息扩散模型
http://www.studyai.com/xueshu/paper/detail/2528826009
HALL-E: Hierarchical Neural Codec Language Model for Minute-Long Zero-Shot Text-to-Speech Synthesis
HALL-E:用于分钟级零样本文本到语音合成的分层神经编解码语言模型
文章解读: HALL-E:用于分钟级零样本文本到语音合成的分层神经编解码语言模型
http://www.studyai.com/xueshu/paper/detail/2539232660
COMBO: Compositional World Models for Embodied Multi-Agent Cooperation
COMBO:用于具身多智能体合作的组合式世界模型
文章解读: COMBO:用于具身多智能体合作的组合式世界模型
http://www.studyai.com/xueshu/paper/detail/2551901026
RepoGraph: Enhancing AI Software Engineering with Repository-level Code Graph
RepoGraph:以代码库级代码图增强人工智能软件工程
文章解读: RepoGraph:以代码库级代码图增强人工智能软件工程
http://www.studyai.com/xueshu/paper/detail/2553038098
Adaptive Camera Sensor for Vision Models
用于视觉模型的自适应相机传感器
文章解读: 用于视觉模型的自适应相机传感器
http://www.studyai.com/xueshu/paper/detail/2569903107
DPaI: Differentiable Pruning at Initialization with Node-Path Balance Principle
DPaI:初始化时的可微分剪枝,基于节点路径平衡原则
文章解读: DPaI:初始化时的可微分剪枝,基于节点路径平衡原则
http://www.studyai.com/xueshu/paper/detail/2585560863
Beyond Autoregression: Discrete Diffusion for Complex Reasoning and Planning
超越自回归:用于复杂推理和规划的离散扩散
文章解读: 超越自回归:用于复杂推理和规划的离散扩散
http://www.studyai.com/xueshu/paper/detail/2592069590
LaMP: Language-Motion Pretraining for Motion Generation, Retrieval, and Captioning
LaMP:用于运动生成、检索和描述的语言-运动预训练
文章解读: LaMP:用于运动生成、检索和描述的语言-运动预训练
http://www.studyai.com/xueshu/paper/detail/2597533586
Unveiling the Magic of Code Reasoning through Hypothesis Decomposition and Amendment
通过假设分解和修正揭示代码推理的奥秘
文章解读: 通过假设分解和修正揭示代码推理的奥秘
http://www.studyai.com/xueshu/paper/detail/2611212075
Agent-to-Sim: Learning Interactive Behavior Models from Casual Longitudinal Videos
从因果纵向视频中学习交互行为模型:Agent-to-Sim
文章解读: 从因果纵向视频中学习交互行为模型:Agent-to-Sim
http://www.studyai.com/xueshu/paper/detail/2611376918
Test-time Adaptation for Cross-modal Retrieval with Query Shift
测试时自适应跨模态检索中的查询偏移
文章解读: 测试时自适应跨模态检索中的查询偏移
http://www.studyai.com/xueshu/paper/detail/2626070002
OccProphet: Pushing the Efficiency Frontier of Camera-Only 4D Occupancy Forecasting with an Observer-Forecaster-Refiner Framework
OccProphet:通过观察者-预测者-精炼者框架推动仅使用相机4D占用预测的效率前沿
文章解读: OccProphet:通过观察者-预测者-精炼者框架推动仅使用相机4D占用预测的效率前沿
http://www.studyai.com/xueshu/paper/detail/2629882066
STAR: Stability-Inducing Weight Perturbation for Continual Learning
STAR:用于持续学习的稳定诱导权重扰动
文章解读: STAR:用于持续学习的稳定诱导权重扰动
http://www.studyai.com/xueshu/paper/detail/2636599333
YOLO-RD: Introducing Relevant and Compact Explicit Knowledge to YOLO by Retriever-Dictionary
YOLO-RD:通过检索器-词典为YOLO引入相关且紧凑的显式知识
文章解读: YOLO-RD:通过检索器-词典为YOLO引入相关且紧凑的显式知识
http://www.studyai.com/xueshu/paper/detail/2650763851
WeatherGFM: Learning a Weather Generalist Foundation Model via In-context Learning
WeatherGFM:通过情境学习学习天气通才基础模型
文章解读: WeatherGFM:通过情境学习学习天气通才基础模型
http://www.studyai.com/xueshu/paper/detail/2656093082
SonicSim: A customizable simulation platform for speech processing in moving sound source scenarios
SonicSim:适用于移动声源场景中语音处理的可定制模拟平台
文章解读: SonicSim:适用于移动声源场景中语音处理的可定制模拟平台
http://www.studyai.com/xueshu/paper/detail/2663762897
PWM: Policy Learning with Multi-Task World Models
PWM:多任务世界模型的政策学习
文章解读: PWM:多任务世界模型的政策学习
http://www.studyai.com/xueshu/paper/detail/2667181229
Diffusing to the Top: Boost Graph Neural Networks with Minimal Hyperparameter Tuning
向顶层扩散:通过极少的超参数调整提升图神经网络
文章解读: 向顶层扩散:通过极少的超参数调整提升图神经网络
http://www.studyai.com/xueshu/paper/detail/2668667286
AI Sandbagging: Language Models can Strategically Underperform on Evaluations
AI沙袋策略:语言模型可以在评估中策略性地表现不佳
文章解读: AI沙袋策略:语言模型可以在评估中策略性地表现不佳
http://www.studyai.com/xueshu/paper/detail/2672028899
Semantic Image Inversion and Editing using Rectified Stochastic Differential Equations
使用修正随机微分方程进行语义图像反转和编辑
文章解读: 使用修正随机微分方程进行语义图像反转和编辑
http://www.studyai.com/xueshu/paper/detail/2680096826
On Generalization Across Environments In Multi-Objective Reinforcement Learning
跨环境泛化于多目标强化学习
文章解读: 跨环境泛化于多目标强化学习
http://www.studyai.com/xueshu/paper/detail/2683095180
Prioritized Generative Replay
优先生成式重放
文章解读: 优先生成式重放
http://www.studyai.com/xueshu/paper/detail/2698882938
Tackling Data Corruption in Offline Reinforcement Learning via Sequence Modeling
通过序列建模解决离线强化学习中的数据损坏问题
文章解读: 通过序列建模解决离线强化学习中的数据损坏问题
http://www.studyai.com/xueshu/paper/detail/2702903029
ChemAgent: Self-updating Memories in Large Language Models Improves Chemical Reasoning
ChemAgent:大语言模型中的自更新记忆改进化学推理
文章解读: ChemAgent:大语言模型中的自更新记忆改进化学推理
http://www.studyai.com/xueshu/paper/detail/2706151952
PhysBench: Benchmarking and Enhancing Vision-Language Models for Physical World Understanding
PhysBench:用于物理世界理解的视觉-语言模型的基准测试与增强
文章解读: PhysBench:用于物理世界理解的视觉-语言模型的基准测试与增强
http://www.studyai.com/xueshu/paper/detail/2707566720
Open-YOLO 3D: Towards Fast and Accurate Open-Vocabulary 3D Instance Segmentation
Open-YOLO 3D:迈向快速准确的开放词汇3D实例分割
文章解读: Open-YOLO 3D:迈向快速准确的开放词汇3D实例分割
http://www.studyai.com/xueshu/paper/detail/2711286209
Multi-Reward as Condition for Instruction-based Image Editing
基于指令的多奖励图像编辑条件
文章解读: 基于指令的多奖励图像编辑条件
http://www.studyai.com/xueshu/paper/detail/2727515163
Hotspot-Driven Peptide Design via Multi-Fragment Autoregressive Extension
基于热点驱动的多片段自回归扩展肽设计
文章解读: 基于热点驱动的多片段自回归扩展肽设计
http://www.studyai.com/xueshu/paper/detail/2728205167
CBraMod: A Criss-Cross Brain Foundation Model for EEG Decoding
CBraMod:一种用于脑电图解码的交叉脑基础模型
文章解读: CBraMod:一种用于脑电图解码的交叉脑基础模型
http://www.studyai.com/xueshu/paper/detail/2738763971
Distilling Dataset into Neural Field
将数据集蒸馏为神经场
文章解读: 将数据集蒸馏为神经场
http://www.studyai.com/xueshu/paper/detail/2755152709
Trivialized Momentum Facilitates Diffusion Generative Modeling on Lie Groups
平凡化动量促进李群上的扩散生成建模
文章解读: 平凡化动量促进李群上的扩散生成建模
http://www.studyai.com/xueshu/paper/detail/2761815029
Proxy Denoising for Source-Free Domain Adaptation
无源域适应中的代理去噪
文章解读: 无源域适应中的代理去噪
http://www.studyai.com/xueshu/paper/detail/2762369908
IGL-Bench: Establishing the Comprehensive Benchmark for Imbalanced Graph Learning
IGL-Bench:建立不平衡图学习的综合基准
文章解读: IGL-Bench:建立不平衡图学习的综合基准
http://www.studyai.com/xueshu/paper/detail/2763902123
JudgeBench: A Benchmark for Evaluating LLM-Based Judges
JudgeBench:一个用于评估基于大语言模型的裁判的基准
文章解读: JudgeBench:一个用于评估基于大语言模型的裁判的基准
http://www.studyai.com/xueshu/paper/detail/2772752963
MarS: a Financial Market Simulation Engine Powered by Generative Foundation Model
MarS:一个由生成式基础模型驱动的金融市场模拟引擎
文章解读: MarS:一个由生成式基础模型驱动的金融市场模拟引擎
http://www.studyai.com/xueshu/paper/detail/2778892317
SAGEPhos: Sage Bio-Coupled and Augmented Fusion for Phosphorylation Site Detection
SAGEPhos:基于生物耦合和增强融合的磷酸化位点检测
文章解读: SAGEPhos:基于生物耦合和增强融合的磷酸化位点检测
http://www.studyai.com/xueshu/paper/detail/2789303209
Guided Score identity Distillation for Data-Free One-Step Text-to-Image Generation
基于引导分数身份蒸馏的无数据一步式文本到图像生成
文章解读: 基于引导分数身份蒸馏的无数据一步式文本到图像生成
http://www.studyai.com/xueshu/paper/detail/2793592308
Framer: Interactive Frame Interpolation
Framer:交互式框架插值
文章解读: Framer:交互式框架插值
http://www.studyai.com/xueshu/paper/detail/2800938969
TEOChat: A Large Vision-Language Assistant for Temporal Earth Observation Data
TEOChat:一个用于时间序列地球观测数据的大规模视觉语言助手
文章解读: TEOChat:一个用于时间序列地球观测数据的大规模视觉语言助手
http://www.studyai.com/xueshu/paper/detail/2809008759
Unposed Sparse Views Room Layout Reconstruction in the Age of Pretrain Model
无约束稀疏视图房间布局重建——预训练模型时代
文章解读: 无约束稀疏视图房间布局重建——预训练模型时代
http://www.studyai.com/xueshu/paper/detail/2816531599
Generative Flows on Synthetic Pathway for Drug Design
在合成路径上用于药物设计的生成流
文章解读: 在合成路径上用于药物设计的生成流
http://www.studyai.com/xueshu/paper/detail/2839263050
Filtered not Mixed: Filtering-Based Online Gating for Mixture of Large Language Models
过滤而非混合:基于过滤的在线门控混合大语言模型
文章解读: 过滤而非混合:基于过滤的在线门控混合大语言模型
http://www.studyai.com/xueshu/paper/detail/2851262801
ASTrA: Adversarial Self-supervised Training with Adaptive-Attacks
ASTrA:具有自适应攻击的对抗自监督训练
文章解读: ASTrA:具有自适应攻击的对抗自监督训练
http://www.studyai.com/xueshu/paper/detail/2860727322
Metric-Driven Attributions for Vision Transformers
基于度量的视觉Transformer归因
文章解读: 基于度量的视觉Transformer归因
http://www.studyai.com/xueshu/paper/detail/2871786219
GMValuator: Similarity-based Data Valuation for Generative Models
GMValuator:基于相似性的生成模型数据评估
文章解读: GMValuator:基于相似性的生成模型数据评估
http://www.studyai.com/xueshu/paper/detail/2872762610
Decoupling Angles and Strength in Low-rank Adaptation
低秩自适应中的解耦角度和强度
文章解读: 低秩自适应中的解耦角度和强度
http://www.studyai.com/xueshu/paper/detail/2873718202
SAVA: Scalable Learning-Agnostic Data Valuation
SAVA:可扩展的、与学习无关的数据估值
文章解读: SAVA:可扩展的、与学习无关的数据估值
http://www.studyai.com/xueshu/paper/detail/2877050958
LVSM: A Large View Synthesis Model with Minimal 3D Inductive Bias
LVSM:一种具有极小3D归纳偏置的大视图合成模型
文章解读: LVSM:一种具有极小3D归纳偏置的大视图合成模型
http://www.studyai.com/xueshu/paper/detail/2880108716
Graph Transformers Dream of Electric Flow
图变换器梦想着电流动
文章解读: 图变换器梦想着电流动
http://www.studyai.com/xueshu/paper/detail/2882373819
NVS-Solver: Video Diffusion Model as Zero-Shot Novel View Synthesizer
NVS-Solver:视频扩散模型作为零样本新视角合成器
文章解读: NVS-Solver:视频扩散模型作为零样本新视角合成器
http://www.studyai.com/xueshu/paper/detail/2885192112
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
LongMemEval:对长期交互记忆的聊天助手进行基准测试
文章解读: LongMemEval:对长期交互记忆的聊天助手进行基准测试
http://www.studyai.com/xueshu/paper/detail/2887252735
Rethinking Multiple-Instance Learning From Feature Space to Probability Space
从特征空间到概率空间的重思多实例学习
文章解读: 从特征空间到概率空间的重思多实例学习
http://www.studyai.com/xueshu/paper/detail/2887263783
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
MLLMs知道该往哪里看:无需训练的多模态LLM对小视觉细节的感知
文章解读: MLLMs知道该往哪里看:无需训练的多模态LLM对小视觉细节的感知
http://www.studyai.com/xueshu/paper/detail/2893069553
ComPC: Completing a 3D Point Cloud with 2D Diffusion Priors
ComPC:使用二维扩散先验完成三维点云
文章解读: ComPC:使用二维扩散先验完成三维点云
http://www.studyai.com/xueshu/paper/detail/2897835788
OGBench: Benchmarking Offline Goal-Conditioned RL
OGBench:离线目标条件强化学习基准测试
文章解读: OGBench:离线目标条件强化学习基准测试
http://www.studyai.com/xueshu/paper/detail/2909509679
FIG: Flow with Interpolant Guidance for Linear Inverse Problems
图:具有插值引导的线性逆问题流
文章解读: 图:具有插值引导的线性逆问题流
http://www.studyai.com/xueshu/paper/detail/2922796591
IFORMER: INTEGRATING CONVNET AND TRANSFORMER FOR MOBILE APPLICATION
IFORMER:将卷积网络与Transformer集成用于移动应用
文章解读: IFORMER:将卷积网络与Transformer集成用于移动应用
http://www.studyai.com/xueshu/paper/detail/2927192328
Halton Scheduler for Masked Generative Image Transformer
掩码生成图像Transformer的Halton调度器
文章解读: 掩码生成图像Transformer的Halton调度器
http://www.studyai.com/xueshu/paper/detail/2931099716
Dynamic-SUPERB Phase-2: A Collaboratively Expanding Benchmark for Measuring the Capabilities of Spoken Language Models with 180 Tasks
动态-SUPERB Phase-2:一个包含180项任务的协作扩展基准,用于衡量语音语言模型的能力
文章解读: 动态-SUPERB Phase-2:一个包含180项任务的协作扩展基准,用于衡量语音语言模型的能力
http://www.studyai.com/xueshu/paper/detail/2958575503
Recovery of Causal Graph Involving Latent Variables via Homologous Surrogates
通过同构代理恢复涉及潜变量的因果图
文章解读: 通过同构代理恢复涉及潜变量的因果图
http://www.studyai.com/xueshu/paper/detail/2978800992
SynCamMaster: Synchronizing Multi-Camera Video Generation from Diverse Viewpoints
SynCamMaster:从不同视角同步多摄像机视频生成
文章解读: SynCamMaster:从不同视角同步多摄像机视频生成
http://www.studyai.com/xueshu/paper/detail/2979215602
Budgeted Online Continual Learning by Adaptive Layer Freezing and Frequency-based Sampling
基于自适应层冻结和基于频率的采样进行预算化的在线持续学习
文章解读: 基于自适应层冻结和基于频率的采样进行预算化的在线持续学习
http://www.studyai.com/xueshu/paper/detail/2982131883
Improving Instruction-Following in Language Models through Activation Steering
通过激活引导提升语言模型的指令遵循能力
文章解读: 通过激活引导提升语言模型的指令遵循能力
http://www.studyai.com/xueshu/paper/detail/3000581853
The Case for Cleaner Biosignals: High-fidelity Neural Compressor Enables Transfer from Cleaner iEEG to Noisier EEG
清洁生物信号的理由:高保真神经压缩器实现从清洁的iEEG到嘈杂的EEG的转换
文章解读: 清洁生物信号的理由:高保真神经压缩器实现从清洁的iEEG到嘈杂的EEG的转换
http://www.studyai.com/xueshu/paper/detail/3001593018
Diff-Prompt: Diffusion-Driven Prompt Generator with Mask Supervision
差分提示:基于掩码监督的扩散驱动提示生成器
文章解读: 差分提示:基于掩码监督的扩散驱动提示生成器
http://www.studyai.com/xueshu/paper/detail/3017168153
Do Egocentric Video-Language Models Truly Understand Hand-Object Interactions?
主观视角视频-语言模型是否真正理解手-物体交互?
文章解读: 主观视角视频-语言模型是否真正理解手-物体交互?
http://www.studyai.com/xueshu/paper/detail/3036157076
LLMOPT: Learning to Define and Solve General Optimization Problems from Scratch
LLMOPT:从零开始学习定义和解决通用优化问题
文章解读: LLMOPT:从零开始学习定义和解决通用优化问题
http://www.studyai.com/xueshu/paper/detail/3038737668
Two Sparse Matrices are Better than One: Sparsifying Neural Networks with Double Sparse Factorization
两个稀疏矩阵胜过一个:使用双重稀疏分解稀疏化神经网络
文章解读: 两个稀疏矩阵胜过一个:使用双重稀疏分解稀疏化神经网络
http://www.studyai.com/xueshu/paper/detail/3039580185
HarmAug: Effective Data Augmentation for Knowledge Distillation of Safety Guard Models
HarmAug:安全防护模型知识蒸馏的有效数据增强方法
文章解读: HarmAug:安全防护模型知识蒸馏的有效数据增强方法
http://www.studyai.com/xueshu/paper/detail/3058835626
ConMix: Contrastive Mixup at Representation Level for Long-tailed Deep Clustering
ConMix:表示层对比混合用于长尾深度聚类
文章解读: ConMix:表示层对比混合用于长尾深度聚类
http://www.studyai.com/xueshu/paper/detail/3068150839
Revealing and Reducing Gender Biases in Vision and Language Assistants (VLAs)
揭示和减少视觉与语言助手(VLAs)中的性别偏见
文章解读: 揭示和减少视觉与语言助手(VLAs)中的性别偏见
http://www.studyai.com/xueshu/paper/detail/3072202129
InstantSplamp: Fast and Generalizable Stenography Framework for Generative Gaussian Splatting
InstantSplamp:快速且可泛化的生成高斯splatting速记框架
文章解读: InstantSplamp:快速且可泛化的生成高斯splatting速记框架
http://www.studyai.com/xueshu/paper/detail/3072707893
ParaSolver: A Hierarchical Parallel Integral Solver for Diffusion Models
ParaSolver:一种用于扩散模型的层次并行积分求解器
文章解读: ParaSolver:一种用于扩散模型的层次并行积分求解器
http://www.studyai.com/xueshu/paper/detail/3080868690
Interpretable Vision-Language Survival Analysis with Ordinal Inductive Bias for Computational Pathology
具有序数归纳偏置的可解释视觉语言生存分析在计算病理学中的应用
文章解读: 具有序数归纳偏置的可解释视觉语言生存分析在计算病理学中的应用
http://www.studyai.com/xueshu/paper/detail/3081139002
SaRA: High-Efficient Diffusion Model Fine-tuning with Progressive Sparse Low-Rank Adaptation
SaRA:基于渐进式稀疏低秩自适应的高效扩散模型微调
文章解读: SaRA:基于渐进式稀疏低秩自适应的高效扩散模型微调
http://www.studyai.com/xueshu/paper/detail/3088151335
Rethinking Diffusion Posterior Sampling: From Conditional Score Estimator to Maximizing a Posterior
重新思考扩散后采样:从条件分数估计器到最大化后验
文章解读: 重新思考扩散后采样:从条件分数估计器到最大化后验
http://www.studyai.com/xueshu/paper/detail/3107200890
Predicting the Energy Landscape of Stochastic Dynamical System via Physics-informed Self-supervised Learning
通过物理信息自监督学习预测随机动力系统的能量景观
文章解读: 通过物理信息自监督学习预测随机动力系统的能量景观
http://www.studyai.com/xueshu/paper/detail/3115813101
Model merging with SVD to tie the Knots
基于SVD的模型合并以解决纠葛问题
文章解读: 基于SVD的模型合并以解决纠葛问题
http://www.studyai.com/xueshu/paper/detail/3125955217
PFDiff: Training-Free Acceleration of Diffusion Models Combining Past and Future Scores
PFDiff:结合过去和未来分数的无训练扩散模型加速方法
文章解读: PFDiff:结合过去和未来分数的无训练扩散模型加速方法
http://www.studyai.com/xueshu/paper/detail/3131757006
CAKE: Cascading and Adaptive KV Cache Eviction with Layer Preferences
CAKE:基于层级偏好的级联自适应键值缓存驱逐
文章解读: CAKE:基于层级偏好的级联自适应键值缓存驱逐
http://www.studyai.com/xueshu/paper/detail/3132818013
HelpSteer2-Preference: Complementing Ratings with Preferences
HelpSteer2-Preference:用偏好补充评分
文章解读: HelpSteer2-Preference:用偏好补充评分
http://www.studyai.com/xueshu/paper/detail/3136262322
Beyond Surface Structure: A Causal Assessment of LLMs’ Comprehension ability
超越表面结构:对大语言模型理解能力的因果评估
文章解读: 超越表面结构:对大语言模型理解能力的因果评估
http://www.studyai.com/xueshu/paper/detail/3137008952
PaCA: Partial Connection Adaptation for Efficient Fine-Tuning
PaCA:部分连接自适应,用于高效微调
文章解读: PaCA:部分连接自适应,用于高效微调
http://www.studyai.com/xueshu/paper/detail/3159126015
Context-Alignment: Activating and Enhancing LLMs Capabilities in Time Series
上下文对齐:激活和增强时间序列中LLM的能力
文章解读: 上下文对齐:激活和增强时间序列中LLM的能力
http://www.studyai.com/xueshu/paper/detail/3172123501
Quality Measures for Dynamic Graph Generative Models
动态图生成模型的质量度量
文章解读: 动态图生成模型的质量度量
http://www.studyai.com/xueshu/paper/detail/3173888778
Personality Alignment of Large Language Models
大语言模型的性格一致性
文章解读: 大语言模型的性格一致性
http://www.studyai.com/xueshu/paper/detail/3188959379
Unveiling the Secret Recipe: A Guide For Supervised Fine-Tuning Small LLMs
揭开秘密配方:指导监督微调小型LLM的指南
文章解读: 揭开秘密配方:指导监督微调小型LLM的指南
http://www.studyai.com/xueshu/paper/detail/3196357215
Beyond Next Token Prediction: Patch-Level Training for Large Language Models
超越下一词预测:大语言模型的基于块的训练
文章解读: 超越下一词预测:大语言模型的基于块的训练
http://www.studyai.com/xueshu/paper/detail/3197503901
ToddlerDiffusion: Interactive Structured Image Generation with Cascaded Schrödinger Bridge
ToddlerDiffusion:交互式结构化图像生成与级联薛定谔桥
文章解读: ToddlerDiffusion:交互式结构化图像生成与级联薛定谔桥
http://www.studyai.com/xueshu/paper/detail/3209260173
DynAlign: Unsupervised Dynamic Taxonomy Alignment for Cross-Domain Segmentation
DynAlign:跨领域分割的无监督动态分类体系对齐
文章解读: DynAlign:跨领域分割的无监督动态分类体系对齐
http://www.studyai.com/xueshu/paper/detail/3209526115
Probabilistic Neural Pruning via Sparsity Evolutionary Fokker-Planck-Kolmogorov Equation
基于稀疏性演化的福克-普朗克-柯尔莫哥洛夫方程的概率神经网络剪枝
文章解读: 基于稀疏性演化的福克-普朗克-柯尔莫哥洛夫方程的概率神经网络剪枝
http://www.studyai.com/xueshu/paper/detail/3211633072
Learning Structured Representations by Embedding Class Hierarchy with Fast Optimal Transport
通过嵌入类层次结构来学习结构化表示,使用快速最优传输
文章解读: 通过嵌入类层次结构来学习结构化表示,使用快速最优传输
http://www.studyai.com/xueshu/paper/detail/3211760326
Enhancing Clustered Federated Learning: Integration of Strategies and Improved Methodologies
增强集群联邦学习:策略集成与改进方法
文章解读: 增强集群联邦学习:策略集成与改进方法
http://www.studyai.com/xueshu/paper/detail/3225821389
Node Identifiers: Compact, Discrete Representations for Efficient Graph Learning
节点标识符:用于高效图学习的紧凑、离散表示
文章解读: 节点标识符:用于高效图学习的紧凑、离散表示
http://www.studyai.com/xueshu/paper/detail/3232056326
ElasticTok: Adaptive Tokenization for Image and Video
ElasticTok:图像和视频的自适应分词
文章解读: ElasticTok:图像和视频的自适应分词
http://www.studyai.com/xueshu/paper/detail/3236202103
An Empirical Analysis of Uncertainty in Large Language Model Evaluations
对大语言模型评估中不确定性的实证分析
文章解读: 对大语言模型评估中不确定性的实证分析
http://www.studyai.com/xueshu/paper/detail/3258531009
Complementary Label Learning with Positive Label Guessing and Negative Label Enhancement
带正例猜测和负例增强的互补标签学习
文章解读: 带正例猜测和负例增强的互补标签学习
http://www.studyai.com/xueshu/paper/detail/3278856338
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
基于视觉的检索增强生成:多模态文档上的VisRAG
文章解读: 基于视觉的检索增强生成:多模态文档上的VisRAG
http://www.studyai.com/xueshu/paper/detail/3280680010
Graph Neural Networks Are More Than Filters: Revisiting and Benchmarking from A Spectral Perspective
图神经网络不仅仅是过滤器:从频谱角度重新审视和基准测试
文章解读: 图神经网络不仅仅是过滤器:从频谱角度重新审视和基准测试
http://www.studyai.com/xueshu/paper/detail/3283029160
GUI-World: A Video Benchmark and Dataset for Multimodal GUI-oriented Understanding
GUI-World:面向多模态GUI理解的视频基准数据集
文章解读: GUI-World:面向多模态GUI理解的视频基准数据集
http://www.studyai.com/xueshu/paper/detail/3287223868
Vertical Federated Learning with Missing Features During Training and Inference
在训练和推理过程中存在缺失特征的垂直联邦学习
文章解读: 在训练和推理过程中存在缺失特征的垂直联邦学习
http://www.studyai.com/xueshu/paper/detail/3289259731
Reveal Object in Lensless Photography via Region Gaze and Amplification
通过区域注视和无透镜放大揭示无透镜摄影中的物体
文章解读: 通过区域注视和无透镜放大揭示无透镜摄影中的物体
http://www.studyai.com/xueshu/paper/detail/3289888783
Regressing the Relative Future: Efficient Policy Optimization for Multi-turn RLHF
回归相对未来:多轮RLHF的有效策略优化
文章解读: 回归相对未来:多轮RLHF的有效策略优化
http://www.studyai.com/xueshu/paper/detail/3292698600
HERO: Human-Feedback Efficient Reinforcement Learning for Online Diffusion Model Finetuning
HERO:面向在线扩散模型微调的人-反馈高效强化学习
文章解读: HERO:面向在线扩散模型微调的人-反馈高效强化学习
http://www.studyai.com/xueshu/paper/detail/3310855899
Adapting Multi-modal Large Language Model to Concept Drift From Pre-training Onwards
从预训练开始适应多模态大语言模型的概念漂移
文章解读: 从预训练开始适应多模态大语言模型的概念漂移
http://www.studyai.com/xueshu/paper/detail/3332658708
Learning Fine-Grained Representations through Textual Token Disentanglement in Composed Video Retrieval
通过文本标记解耦学习组合视频检索中的细粒度表示
文章解读: 通过文本标记解耦学习组合视频检索中的细粒度表示
http://www.studyai.com/xueshu/paper/detail/3335918859
NoVo: Norm Voting off Hallucinations with Attention Heads in Large Language Models
NoVo:使用注意力头在大语言模型中消除幻觉的规范投票
文章解读: NoVo:使用注意力头在大语言模型中消除幻觉的规范投票
http://www.studyai.com/xueshu/paper/detail/3368829096
CR-CTC: Consistency regularization on CTC for improved speech recognition
CR-CTC:基于CTC的一致性正则化以提高语音识别性能
文章解读: CR-CTC:基于CTC的一致性正则化以提高语音识别性能
http://www.studyai.com/xueshu/paper/detail/3370167811
X-Drive: Cross-modality Consistent Multi-Sensor Data Synthesis for Driving Scenarios
X-Drive:跨模态一致性多传感器数据合成技术用于驾驶场景
文章解读: X-Drive:跨模态一致性多传感器数据合成技术用于驾驶场景
http://www.studyai.com/xueshu/paper/detail/3370692329
Improved Techniques for Optimization-Based Jailbreaking on Large Language Models
基于优化的大语言模型越狱技术的改进方法
文章解读: 基于优化的大语言模型越狱技术的改进方法
http://www.studyai.com/xueshu/paper/detail/3371303297
FaithEval: Can Your Language Model Stay Faithful to Context, Even If “The Moon is Made of Marshmallows”
FaithEval:即使“月亮是由棉花糖制成的”,你的语言模型是否仍能保持对上下文的忠实?
文章解读: FaithEval:即使“月亮是由棉花糖制成的”,你的语言模型是否仍能保持对上下文的忠实?
http://www.studyai.com/xueshu/paper/detail/3373731138
Your Absorbing Discrete Diffusion Secretly Models the Conditional Distributions of Clean Data
您的吸收离散扩散模型在秘密地模拟干净数据的条件分布
文章解读: 您的吸收离散扩散模型在秘密地模拟干净数据的条件分布
http://www.studyai.com/xueshu/paper/detail/3387338168
Scale-Free Graph-Language Models
无标度图语言模型
文章解读: 无标度图语言模型
http://www.studyai.com/xueshu/paper/detail/3387793568
Robust Barycenter Estimation using Semi-Unbalanced Neural Optimal Transport
基于半不平衡神经最优传输的鲁棒质心估计
文章解读: 基于半不平衡神经最优传输的鲁棒质心估计
http://www.studyai.com/xueshu/paper/detail/3387995070
Explanations of GNN on Evolving Graphs via Axiomatic Layer edges
基于公理层边对演化图上GNN的解释
文章解读: 基于公理层边对演化图上GNN的解释
http://www.studyai.com/xueshu/paper/detail/3392156919
Incorporating Visual Correspondence into Diffusion Model for Virtual Try-On
将视觉对应关系融入扩散模型进行虚拟试穿
文章解读: 将视觉对应关系融入扩散模型进行虚拟试穿
http://www.studyai.com/xueshu/paper/detail/3500806189
Gyrogroup Batch Normalization
Gyrogroup 批归一化
文章解读: Gyrogroup 批归一化
http://www.studyai.com/xueshu/paper/detail/3525228065
Preserving Deep Representations in One-Shot Pruning: A Hessian-Free Second-Order Optimization Framework
在单次剪枝中保留深度表示:一种无Hessian的第二阶优化框架
文章解读: 在单次剪枝中保留深度表示:一种无Hessian的第二阶优化框架
http://www.studyai.com/xueshu/paper/detail/3525663189
Learning Harmonized Representations for Speculative Sampling
学习协同表示以进行推测采样
文章解读: 学习协同表示以进行推测采样
http://www.studyai.com/xueshu/paper/detail/3526570683
Scalable and Certifiable Graph Unlearning: Overcoming the Approximation Error Barrier
可扩展且可认证的图知识蒸馏:克服近似误差障碍
文章解读: 可扩展且可认证的图知识蒸馏:克服近似误差障碍
http://www.studyai.com/xueshu/paper/detail/3533663382
Multi-Task Dense Predictions via Unleashing the Power of Diffusion
通过释放扩散的力量实现多任务密集预测
文章解读: 通过释放扩散的力量实现多任务密集预测
http://www.studyai.com/xueshu/paper/detail/3576061357
Fourier Head: Helping Large Language Models Learn Complex Probability Distributions
傅里叶头:助力大语言模型学习复杂概率分布
文章解读: 傅里叶头:助力大语言模型学习复杂概率分布
http://www.studyai.com/xueshu/paper/detail/3592715609
Revisiting Nearest Neighbor for Tabular Data: A Deep Tabular Baseline Two Decades Later
重新审视表格数据的最近邻方法:二十年后的深度表格基线
文章解读: 重新审视表格数据的最近邻方法:二十年后的深度表格基线
http://www.studyai.com/xueshu/paper/detail/3616239813
Standardizing Structural Causal Models
标准化结构因果模型
文章解读: 标准化结构因果模型
http://www.studyai.com/xueshu/paper/detail/3616259135
Bridging Context Gaps: Leveraging Coreference Resolution for Long Contextual Understanding
填补上下文空白:利用共指消解实现长上下文理解
文章解读: 填补上下文空白:利用共指消解实现长上下文理解
http://www.studyai.com/xueshu/paper/detail/3620650095
Spectral Compressive Imaging via Unmixing-driven Subspace Diffusion Refinement
基于解混驱动的子空间扩散精炼的谱压缩成像
文章解读: 基于解混驱动的子空间扩散精炼的谱压缩成像
http://www.studyai.com/xueshu/paper/detail/3628171611
3DMolFormer: A Dual-channel Framework for Structure-based Drug Discovery
3DMolFormer:基于结构的药物发现的双通道框架
文章解读: 3DMolFormer:基于结构的药物发现的双通道框架
http://www.studyai.com/xueshu/paper/detail/3650912713
Training-free Camera Control for Video Generation
无训练相机控制用于视频生成
文章解读: 无训练相机控制用于视频生成
http://www.studyai.com/xueshu/paper/detail/3652589388
SAMRefiner: Taming Segment Anything Model for Universal Mask Refinement
SAMRefiner:驯服Segment Anything模型以实现通用掩码细化
文章解读: SAMRefiner:驯服Segment Anything模型以实现通用掩码细化
http://www.studyai.com/xueshu/paper/detail/3658086300
InverseBench: Benchmarking Plug-and-Play Diffusion Priors for Inverse Problems in Physical Sciences
逆基准:物理科学中逆问题可即插即用扩散先验的基准测试
文章解读: 逆基准:物理科学中逆问题可即插即用扩散先验的基准测试
http://www.studyai.com/xueshu/paper/detail/3660607037
Contractive Dynamical Imitation Policies for Efficient Out-of-Sample Recovery
收缩动态模仿策略用于高效的样本外恢复
文章解读: 收缩动态模仿策略用于高效的样本外恢复
http://www.studyai.com/xueshu/paper/detail/3678570595
Circuit Transformer: A Transformer That Preserves Logical Equivalence
电路变换器:一种保持逻辑等价的变换器
文章解读: 电路变换器:一种保持逻辑等价的变换器
http://www.studyai.com/xueshu/paper/detail/3689988936
Domain Guidance: A Simple Transfer Approach for a Pre-trained Diffusion Model
领域指导:预训练扩散模型的一种简单迁移方法
文章解读: 领域指导:预训练扩散模型的一种简单迁移方法
http://www.studyai.com/xueshu/paper/detail/3700578119
Mitigating Parameter Interference in Model Merging via Sharpness-Aware Fine-Tuning
通过Sharpness-Aware Fine-Tuning减轻模型合并中的参数干扰
文章解读: 通过Sharpness-Aware Fine-Tuning减轻模型合并中的参数干扰
http://www.studyai.com/xueshu/paper/detail/3709817553
Improved Diffusion-based Generative Model with Better Adversarial Robustness
基于扩散模型的改进生成模型,具有更好的对抗鲁棒性
文章解读: 基于扩散模型的改进生成模型,具有更好的对抗鲁棒性
http://www.studyai.com/xueshu/paper/detail/3717627379
Routing Experts: Learning to Route Dynamic Experts in Existing Multi-modal Large Language Models
路由专家:学习在现有多模态大语言模型中路由动态专家
文章解读: 路由专家:学习在现有多模态大语言模型中路由动态专家
http://www.studyai.com/xueshu/paper/detail/3717691509
Controlling Space and Time with Diffusion Models
使用扩散模型控制空间和时间
文章解读: 使用扩散模型控制空间和时间
http://www.studyai.com/xueshu/paper/detail/3718618361
Forgetting Transformer: Softmax Attention with a Forget Gate
遗忘Transformer:带有遗忘门的Softmax注意力
文章解读: 遗忘Transformer:带有遗忘门的Softmax注意力
http://www.studyai.com/xueshu/paper/detail/3728326710
Pursuing Feature Separation based on Neural Collapse for Out-of-Distribution Detection
基于神经坍塌的特征分离方法用于分布外检测
文章解读: 基于神经坍塌的特征分离方法用于分布外检测
http://www.studyai.com/xueshu/paper/detail/3733268731
On Large Language Model Continual Unlearning
大语言模型的持续去学习
文章解读: 大语言模型的持续去学习
http://www.studyai.com/xueshu/paper/detail/3755761310
Policy Decorator: Model-Agnostic Online Refinement for Large Policy Model
策略装饰器:模型无关的在线优化大型策略模型
文章解读: 策略装饰器:模型无关的在线优化大型策略模型
http://www.studyai.com/xueshu/paper/detail/3756075931
McEval: Massively Multilingual Code Evaluation
McEval:多语种代码评估
文章解读: McEval:多语种代码评估
http://www.studyai.com/xueshu/paper/detail/3766883801
Narrowing Information Bottleneck Theory for Multimodal Image-Text Representations Interpretability
缩小多模态图像-文本表示可解释性的信息瓶颈理论
文章解读: 缩小多模态图像-文本表示可解释性的信息瓶颈理论
http://www.studyai.com/xueshu/paper/detail/3770677388
Pyramidal Flow Matching for Efficient Video Generative Modeling
金字塔流匹配高效视频生成模型
文章解读: 金字塔流匹配高效视频生成模型
http://www.studyai.com/xueshu/paper/detail/3772271183
LongPO: Long Context Self-Evolution of Large Language Models through Short-to-Long Preference Optimization
长文模型:通过短到长偏好优化实现大语言模型的长上下文自我进化
文章解读: 长文模型:通过短到长偏好优化实现大语言模型的长上下文自我进化
http://www.studyai.com/xueshu/paper/detail/3776611903
Information Theoretic Text-to-Image Alignment
基于信息的文本到图像对齐
文章解读: 基于信息的文本到图像对齐
http://www.studyai.com/xueshu/paper/detail/3783276560
Beyond Interpretability: The Gains of Feature Monosemanticity on Model Robustness
超越可解释性:特征单义性对模型鲁棒性的增益
文章解读: 超越可解释性:特征单义性对模型鲁棒性的增益
http://www.studyai.com/xueshu/paper/detail/3789752811
Dataset Ownership Verification in Contrastive Pre-trained Models
对比预训练模型中的数据集所有权验证
文章解读: 对比预训练模型中的数据集所有权验证
http://www.studyai.com/xueshu/paper/detail/3795107172
BlueSuffix: Reinforced Blue Teaming for Vision-Language Models Against Jailbreak Attacks
BlueSuffix:针对视觉语言模型的强化蓝队对抗越狱攻击
文章解读: BlueSuffix:针对视觉语言模型的强化蓝队对抗越狱攻击
http://www.studyai.com/xueshu/paper/detail/3796039608
Sufficient Context: A New Lens on Retrieval Augmented Generation Systems
充分语境:检索增强生成系统的新视角
文章解读: 充分语境:检索增强生成系统的新视角
http://www.studyai.com/xueshu/paper/detail/3799890051
Wavelet Diffusion Neural Operator
小波扩散神经算子
文章解读: 小波扩散神经算子
http://www.studyai.com/xueshu/paper/detail/3799897836
A Coefficient Makes SVRG Effective
一个系数使SVRG有效
文章解读: 一个系数使SVRG有效
http://www.studyai.com/xueshu/paper/detail/3802360758
A Simple Framework for Open-Vocabulary Zero-Shot Segmentation
一种开放词汇零样本分割的简单框架
文章解读: 一种开放词汇零样本分割的简单框架
http://www.studyai.com/xueshu/paper/detail/3809169051
BoneMet: An Open Large-Scale Multi-Modal Murine Dataset for Breast Cancer Bone Metastasis Diagnosis and Prognosis
BoneMet:一个用于乳腺癌骨转移诊断和预后的开放性大规模多模态小鼠数据集
文章解读: BoneMet:一个用于乳腺癌骨转移诊断和预后的开放性大规模多模态小鼠数据集
http://www.studyai.com/xueshu/paper/detail/3809701767
Rethinking Invariance in In-context Learning
重新思考情境学习中的不变性
文章解读: 重新思考情境学习中的不变性
http://www.studyai.com/xueshu/paper/detail/3851222190
Uni-Sign: Toward Unified Sign Language Understanding at Scale
Uni-Sign:迈向大规模统一手语理解
文章解读: Uni-Sign:迈向大规模统一手语理解
http://www.studyai.com/xueshu/paper/detail/3859926536
Hierarchical Uncertainty Estimation for Learning-based Registration in Neuroimaging
神经影像学中基于学习的配准的层次不确定性估计
文章解读: 神经影像学中基于学习的配准的层次不确定性估计
http://www.studyai.com/xueshu/paper/detail/3879965635
InCoDe: Interpretable Compressed Descriptions For Image Generation
InCoDe:用于图像生成的可解释压缩描述
文章解读: InCoDe:用于图像生成的可解释压缩描述
http://www.studyai.com/xueshu/paper/detail/3893639035
Steering Large Language Models between Code Execution and Textual Reasoning
在代码执行和文本推理之间引导大语言模型
文章解读: 在代码执行和文本推理之间引导大语言模型
http://www.studyai.com/xueshu/paper/detail/3902257053
Intermediate Layer Classifiers for OOD generalization
用于OOD泛化的中间层分类器
文章解读: 用于OOD泛化的中间层分类器
http://www.studyai.com/xueshu/paper/detail/3905565888
Improved Training Technique for Latent Consistency Models
用于潜在一致性模型的改进训练技术
文章解读: 用于潜在一致性模型的改进训练技术
http://www.studyai.com/xueshu/paper/detail/3935256517
Multiple Heads are Better than One: Mixture of Modality Knowledge Experts for Entity Representation Learning
多头优于单头:模态知识专家混合体用于实体表征学习
文章解读: 多头优于单头:模态知识专家混合体用于实体表征学习
http://www.studyai.com/xueshu/paper/detail/3935927857
Systematic Outliers in Large Language Models
大语言模型中的系统性异常值
文章解读: 大语言模型中的系统性异常值
http://www.studyai.com/xueshu/paper/detail/3959562668
Fine-Tuning Discrete Diffusion Models via Reward Optimization with Applications to DNA and Protein Design
通过奖励优化微调离散扩散模型及其在DNA和蛋白质设计中的应用
文章解读: 通过奖励优化微调离散扩散模型及其在DNA和蛋白质设计中的应用
http://www.studyai.com/xueshu/paper/detail/3970317929
Enhancing Document Understanding with Group Position Embedding: A Novel Approach to Incorporate Layout Information
利用组位置嵌入增强文档理解:一种整合布局信息的新方法
文章解读: 利用组位置嵌入增强文档理解:一种整合布局信息的新方法
http://www.studyai.com/xueshu/paper/detail/3985237390
Federated Few-Shot Class-Incremental Learning
联邦小样本增量学习
文章解读: 联邦小样本增量学习
http://www.studyai.com/xueshu/paper/detail/5008550099
Matcha: Mitigating Graph Structure Shifts with Test-Time Adaptation
抹茶:通过测试时适应减轻图结构变化
文章解读: 抹茶:通过测试时适应减轻图结构变化
http://www.studyai.com/xueshu/paper/detail/5016671362
Towards Synergistic Path-based Explanations for Knowledge Graph Completion: Exploration and Evaluation
面向知识图谱补全的协同路径解释:探索与评估
文章解读: 面向知识图谱补全的协同路径解释:探索与评估
http://www.studyai.com/xueshu/paper/detail/5017106735
TabDiff: a Mixed-type Diffusion Model for Tabular Data Generation
TabDiff:一种用于表格数据生成的混合型扩散模型
文章解读: TabDiff:一种用于表格数据生成的混合型扩散模型
http://www.studyai.com/xueshu/paper/detail/5020106210
Varying Shades of Wrong: Aligning LLMs with Wrong Answers Only
错误的多样性:仅使用错误答案对大语言模型进行校准
文章解读: 错误的多样性:仅使用错误答案对大语言模型进行校准
http://www.studyai.com/xueshu/paper/detail/5020872215
IterGen: Iterative Semantic-aware Structured LLM Generation with Backtracking
IterGen:具有回溯功能的迭代语义感知结构化大语言模型生成
文章解读: IterGen:具有回溯功能的迭代语义感知结构化大语言模型生成
http://www.studyai.com/xueshu/paper/detail/5020958062
LLaRA: Supercharging Robot Learning Data for Vision-Language Policy
LLaRA:为视觉-语言策略超级充电机器人学习数据
文章解读: LLaRA:为视觉-语言策略超级充电机器人学习数据
http://www.studyai.com/xueshu/paper/detail/5025829577
Analytic DAG Constraints for Differentiable DAG Learning
可微有向无环图学习的分析DAG约束
文章解读: 可微有向无环图学习的分析DAG约束
http://www.studyai.com/xueshu/paper/detail/5033356237
CipherPrune: Efficient and Scalable Private Transformer Inference
CipherPrune:高效且可扩展的私有Transformer推理
文章解读: CipherPrune:高效且可扩展的私有Transformer推理
http://www.studyai.com/xueshu/paper/detail/5033950052
XAIguiFormer: explainable artificial intelligence guided transformer for brain disorder identification
XAIguiFormer:用于脑部疾病识别的可解释人工智能指导Transformer
文章解读: XAIguiFormer:用于脑部疾病识别的可解释人工智能指导Transformer
http://www.studyai.com/xueshu/paper/detail/5036156666
Vevo: Controllable Zero-Shot Voice Imitation with Self-Supervised Disentanglement
Vevo:基于自监督解耦的可控零样本语音模仿
文章解读: Vevo:基于自监督解耦的可控零样本语音模仿
http://www.studyai.com/xueshu/paper/detail/5052601063
Spider 2.0: Evaluating Language Models on Real-World Enterprise Text-to-SQL Workflows
蜘蛛2.0:在真实企业文本到SQL工作流程中评估语言模型
文章解读: 蜘蛛2.0:在真实企业文本到SQL工作流程中评估语言模型
http://www.studyai.com/xueshu/paper/detail/5056178125
Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to Advances
对抗图像编辑的鲁棒水印技术:从基准测试到进展
文章解读: 对抗图像编辑的鲁棒水印技术:从基准测试到进展
http://www.studyai.com/xueshu/paper/detail/5060067009
Let Your Features Tell The Differences: Understanding Graph Convolution By Feature Splitting
让你的特征讲述差异:通过特征拆分理解图卷积
文章解读: 让你的特征讲述差异:通过特征拆分理解图卷积
http://www.studyai.com/xueshu/paper/detail/5069191639
Diffusion State-Guided Projected Gradient for Inverse Problems
基于扩散状态引导的投影梯度逆问题求解方法
文章解读: 基于扩散状态引导的投影梯度逆问题求解方法
http://www.studyai.com/xueshu/paper/detail/5070987309
Fugatto 1: Foundational Generative Audio Transformer Opus 1
Fugatto 1:基础生成音频Transformer Opus 1
文章解读: Fugatto 1:基础生成音频Transformer Opus 1
http://www.studyai.com/xueshu/paper/detail/5072252321
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
代理安全基准(ASB):形式化基准测试基于LLM的代理中的攻击与防御
文章解读: 代理安全基准(ASB):形式化基准测试基于LLM的代理中的攻击与防御
http://www.studyai.com/xueshu/paper/detail/5072888557
Data Selection via Optimal Control for Language Models
基于最优控制的语言模型数据选择
文章解读: 基于最优控制的语言模型数据选择
http://www.studyai.com/xueshu/paper/detail/5073653710
Lumina-T2X: Scalable Flow-based Large Diffusion Transformer for Flexible Resolution Generation
Lumina-T2X:可扩展的基于流的大型扩散Transformer,用于灵活分辨率生成
文章解读: Lumina-T2X:可扩展的基于流的大型扩散Transformer,用于灵活分辨率生成
http://www.studyai.com/xueshu/paper/detail/5077788873
ET-SEED: EFFICIENT TRAJECTORY-LEVEL SE(3) EQUIVARIANT DIFFUSION POLICY
ET-SEED:高效的轨迹级SE(3)等变扩散策略
文章解读: ET-SEED:高效的轨迹级SE(3)等变扩散策略
http://www.studyai.com/xueshu/paper/detail/5078250900
3DIS: Depth-Driven Decoupled Image Synthesis for Universal Multi-Instance Generation
3DIS:基于深度驱动的解耦图像合成技术,用于通用多实例生成
文章解读: 3DIS:基于深度驱动的解耦图像合成技术,用于通用多实例生成
http://www.studyai.com/xueshu/paper/detail/5078937891
Mitigating Modality Prior-Induced Hallucinations in Multimodal Large Language Models via Deciphering Attention Causality
通过解析注意力因果关系来缓解多模态大语言模型中的模态先验诱导幻觉
文章解读: 通过解析注意力因果关系来缓解多模态大语言模型中的模态先验诱导幻觉
http://www.studyai.com/xueshu/paper/detail/5080352320
Perm: A Parametric Representation for Multi-Style 3D Hair Modeling
Perm:一种用于多风格3D头发建模的参数化表示
文章解读: Perm:一种用于多风格3D头发建模的参数化表示
http://www.studyai.com/xueshu/paper/detail/5090266362
DiffusionGuard: A Robust Defense Against Malicious Diffusion-based Image Editing
DiffusionGuard:一种针对恶意扩散型图像编辑的鲁棒防御方法
文章解读: DiffusionGuard:一种针对恶意扩散型图像编辑的鲁棒防御方法
http://www.studyai.com/xueshu/paper/detail/5107776291
ThermalGaussian: Thermal 3D Gaussian Splatting
热高斯:热三维高斯喷溅
文章解读: 热高斯:热三维高斯喷溅
http://www.studyai.com/xueshu/paper/detail/5107902718
Visual-O1: Understanding Ambiguous Instructions via Multi-modal Multi-turn Chain-of-thoughts Reasoning
视觉-O1:通过多模态多轮思维链推理理解模糊指令
文章解读: 视觉-O1:通过多模态多轮思维链推理理解模糊指令
http://www.studyai.com/xueshu/paper/detail/5110733093
VideoPhy: Evaluating Physical Commonsense for Video Generation
VideoPhy:评估视频生成中的物理常识
文章解读: VideoPhy:评估视频生成中的物理常识
http://www.studyai.com/xueshu/paper/detail/5111028851
What Are Good Positional Encodings for Directed Graphs?
有哪一些好的有向图位置编码?
文章解读: 有哪一些好的有向图位置编码?
http://www.studyai.com/xueshu/paper/detail/5112002771
Your Weak LLM is Secretly a Strong Teacher for Alignment
你那弱小的LLM实际上是一位秘密的强大教师,用于对齐
文章解读: 你那弱小的LLM实际上是一位秘密的强大教师,用于对齐
http://www.studyai.com/xueshu/paper/detail/5116588050
Mixture of Experts Made Personalized: Federated Prompt Learning for Vision-Language Models
专家混合模型个性化:用于视觉语言模型的联邦提示学习
文章解读: 专家混合模型个性化:用于视觉语言模型的联邦提示学习
http://www.studyai.com/xueshu/paper/detail/5130788365
Semi-Supervised CLIP Adaptation by Enforcing Semantic and Trapezoidal Consistency
基于语义和梯形一致性约束的半监督CLIP适配
文章解读: 基于语义和梯形一致性约束的半监督CLIP适配
http://www.studyai.com/xueshu/paper/detail/5130902995
On Discriminative Probabilistic Modeling for Self-Supervised Representation Learning
关于判别概率模型在自监督表征学习中的应用
文章解读: 关于判别概率模型在自监督表征学习中的应用
http://www.studyai.com/xueshu/paper/detail/5131698533
ARLON: Boosting Diffusion Transformers with Autoregressive Models for Long Video Generation
ARLON:使用自回归模型增强扩散Transformer进行长视频生成
文章解读: ARLON:使用自回归模型增强扩散Transformer进行长视频生成
http://www.studyai.com/xueshu/paper/detail/5132963669
Diversity-Rewarded CFG Distillation
多样性奖励CFG蒸馏
文章解读: 多样性奖励CFG蒸馏
http://www.studyai.com/xueshu/paper/detail/5137116622
Chemistry-Inspired Diffusion with Non-Differentiable Guidance
受化学启发的非可微引导扩散
文章解读: 受化学启发的非可微引导扩散
http://www.studyai.com/xueshu/paper/detail/5137835529
Measuring And Improving Engagement of Text-to-Image Generation Models
测量和改进文本到图像生成模型的参与度
文章解读: 测量和改进文本到图像生成模型的参与度
http://www.studyai.com/xueshu/paper/detail/5156382928
Better than Your Teacher: LLM Agents that learn from Privileged AI Feedback
优于您的老师:从特权AI反馈中学习的LLM代理
文章解读: 优于您的老师:从特权AI反馈中学习的LLM代理
http://www.studyai.com/xueshu/paper/detail/5165503196
ForecastBench: A Dynamic Benchmark of AI Forecasting Capabilities
ForecastBench:一个动态的AI预测能力基准
文章解读: ForecastBench:一个动态的AI预测能力基准
http://www.studyai.com/xueshu/paper/detail/5166889768
Studying the Interplay Between the Actor and Critic Representations in Reinforcement Learning
研究强化学习中演员和评论家表示之间的相互作用
文章解读: 研究强化学习中演员和评论家表示之间的相互作用
http://www.studyai.com/xueshu/paper/detail/5168680172
ChatQA 2: Bridging the Gap to Proprietary LLMs in Long Context and RAG Capabilities
ChatQA 2:在长上下文和RAG能力方面弥合与专有LLM的差距
文章解读: ChatQA 2:在长上下文和RAG能力方面弥合与专有LLM的差距
http://www.studyai.com/xueshu/paper/detail/5170085122
SSOLE: Rethinking Orthogonal Low-rank Embedding for Self-Supervised Learning
SSOLE:重新思考正交低秩嵌入用于自监督学习
文章解读: SSOLE:重新思考正交低秩嵌入用于自监督学习
http://www.studyai.com/xueshu/paper/detail/5175260372
The OMG dataset: An Open MetaGenomic corpus for mixed-modality genomic language modeling
OMG数据集:用于混合模态基因组语言建模的开源元基因组语料库
文章解读: OMG数据集:用于混合模态基因组语言建模的开源元基因组语料库
http://www.studyai.com/xueshu/paper/detail/5181729792
Following the Human Thread in Social Navigation
遵循社交导航中的人类线索
文章解读: 遵循社交导航中的人类线索
http://www.studyai.com/xueshu/paper/detail/5181775559
COME: Test-time Adaption by Conservatively Minimizing Entropy
COME:通过保守地最小化熵进行测试时自适应
文章解读: COME:通过保守地最小化熵进行测试时自适应
http://www.studyai.com/xueshu/paper/detail/5183132115
Interpretable Unsupervised Joint Denoising and Enhancement for Real-World low-light Scenarios
面向真实场景的低光照图像可解释无监督联合去噪与增强
文章解读: 面向真实场景的低光照图像可解释无监督联合去噪与增强
http://www.studyai.com/xueshu/paper/detail/5188017526
TIPS: Text-Image Pretraining with Spatial awareness
提示:具有空间感知的文本-图像预训练
文章解读: 提示:具有空间感知的文本-图像预训练
http://www.studyai.com/xueshu/paper/detail/5191285575
Offline RL with Smooth OOD Generalization in Convex Hull and its Neighborhood
在凸包及其邻域中进行具有平滑OOD泛化的离线强化学习
文章解读: 在凸包及其邻域中进行具有平滑OOD泛化的离线强化学习
http://www.studyai.com/xueshu/paper/detail/5193726595
On the Fourier analysis in the SO(3) space : the EquiLoPO Network
在SO(3)空间中的傅里叶分析:等距位相光网络
文章解读: 在SO(3)空间中的傅里叶分析:等距位相光网络
http://www.studyai.com/xueshu/paper/detail/5195736871
Parameter and Memory Efficient Pretraining via Low-rank Riemannian Optimization
基于低秩黎曼优化的参数和内存高效预训练
文章解读: 基于低秩黎曼优化的参数和内存高效预训练
http://www.studyai.com/xueshu/paper/detail/5198053275
Empowering LLM Agents with Zero-Shot Optimal Decision-Making through Q-learning
通过Q学习赋予LLM代理零样本最优决策能力
文章解读: 通过Q学习赋予LLM代理零样本最优决策能力
http://www.studyai.com/xueshu/paper/detail/5201279120
TANGO: Co-Speech Gesture Video Reenactment with Hierarchical Audio Motion Embedding and Diffusion Interpolation
TANGO:基于层级音频运动嵌入和扩散插值的共话语势视频重演
文章解读: TANGO:基于层级音频运动嵌入和扩散插值的共话语势视频重演
http://www.studyai.com/xueshu/paper/detail/5210913688
MiniPLM: Knowledge Distillation for Pre-training Language Models
MiniPLM:预训练语言模型的知识蒸馏
文章解读: MiniPLM:预训练语言模型的知识蒸馏
http://www.studyai.com/xueshu/paper/detail/5221059735
On Minimizing Adversarial Counterfactual Error in Adversarial Reinforcement Learning
在对抗强化学习中最小化对抗反事实误差
文章解读: 在对抗强化学习中最小化对抗反事实误差
http://www.studyai.com/xueshu/paper/detail/5226055129
DoF: A Diffusion Factorization Framework for Offline Multi-Agent Reinforcement Learning
DoF:离线多智能体强化学习的扩散分解框架
文章解读: DoF:离线多智能体强化学习的扩散分解框架
http://www.studyai.com/xueshu/paper/detail/5227786505
Digi-Q: Learning VLM Q-Value Functions for Training Device-Control Agents
Digi-Q:学习用于训练设备控制代理的VLM Q值函数
文章解读: Digi-Q:学习用于训练设备控制代理的VLM Q值函数
http://www.studyai.com/xueshu/paper/detail/5237160213
A CLIP-Powered Framework for Robust and Generalizable Data Selection
一个基于CLIP的鲁棒且可泛化的数据选择框架
文章解读: 一个基于CLIP的鲁棒且可泛化的数据选择框架
http://www.studyai.com/xueshu/paper/detail/5237169227
Fictitious Synthetic Data Can Improve LLM Factuality via Prerequisite Learning
虚构合成数据可以通过先决学习提高大语言模型的准确性
文章解读: 虚构合成数据可以通过先决学习提高大语言模型的准确性
http://www.studyai.com/xueshu/paper/detail/5253398098
Can One Modality Model Synergize Training of Other Modality Models?
一种模态能否协同训练其他模态模型?
文章解读: 一种模态能否协同训练其他模态模型?
http://www.studyai.com/xueshu/paper/detail/5255128228
Lawma: The Power of Specialization for Legal Annotation
Lawma:法律注释专业化之力量
文章解读: Lawma:法律注释专业化之力量
http://www.studyai.com/xueshu/paper/detail/5255955662
MoS: Unleashing Parameter Efficiency of Low-Rank Adaptation with Mixture of Shards
MoS:释放低秩自适应的参数效率混合碎片
文章解读: MoS:释放低秩自适应的参数效率混合碎片
http://www.studyai.com/xueshu/paper/detail/5258022176
Dynamical Diffusion: Learning Temporal Dynamics with Diffusion Models
动力扩散:使用扩散模型学习时间动态
文章解读: 动力扩散:使用扩散模型学习时间动态
http://www.studyai.com/xueshu/paper/detail/5271210270
Divergence-enhanced Knowledge-guided Context Optimization for Visual-Language Prompt Tuning
基于发散增强的知识引导上下文优化用于视觉语言提示微调
文章解读: 基于发散增强的知识引导上下文优化用于视觉语言提示微调
http://www.studyai.com/xueshu/paper/detail/5278908623
IDArb: Intrinsic Decomposition for Arbitrary Number of Input Views and Illuminations
IDArb:任意数量输入视图和照明的内在分解
文章解读: IDArb:任意数量输入视图和照明的内在分解
http://www.studyai.com/xueshu/paper/detail/5296579795
FreeVS: Generative View Synthesis on Free Driving Trajectory
FreeVS:基于自由驾驶轨迹的生成式视图合成
文章解读: FreeVS:基于自由驾驶轨迹的生成式视图合成
http://www.studyai.com/xueshu/paper/detail/5298109956
Mixture Compressor for Mixture-of-Experts LLMs Gains More
专家混合语言模型混合压缩器获得更多
文章解读: 专家混合语言模型混合压缩器获得更多
http://www.studyai.com/xueshu/paper/detail/5299612931
Probe before You Talk: Towards Black-box Defense against Backdoor Unalignment for Large Language Models
在开口之前先探查:面向大语言模型的后门非对齐黑盒防御
文章解读: 在开口之前先探查:面向大语言模型的后门非对齐黑盒防御
http://www.studyai.com/xueshu/paper/detail/5310205881
On the Adversarial Risk of Test Time Adaptation: An Investigation into Realistic Test-Time Data Poisoning
测试时自适应的对抗风险:对真实测试时数据投毒的调查
文章解读: 测试时自适应的对抗风险:对真实测试时数据投毒的调查
http://www.studyai.com/xueshu/paper/detail/5317501168
Emerging Safety Attack and Defense in Federated Instruction Tuning of Large Language Models
联邦指令微调中涌现的安全攻击与防御
文章解读: 联邦指令微调中涌现的安全攻击与防御
http://www.studyai.com/xueshu/paper/detail/5318577531
Progressive Compression with Universally Quantized Diffusion Models
使用通用量化扩散模型的渐进式压缩
文章解读: 使用通用量化扩散模型的渐进式压缩
http://www.studyai.com/xueshu/paper/detail/5327116877
Intelligent Go-Explore: Standing on the Shoulders of Giant Foundation Models
智能探索:站在巨人基础模型之上
文章解读: 智能探索:站在巨人基础模型之上
http://www.studyai.com/xueshu/paper/detail/5330283205
CAMEx: Curvature-aware Merging of Experts
CAMEx:基于曲率的专家合并
文章解读: CAMEx:基于曲率的专家合并
http://www.studyai.com/xueshu/paper/detail/5368823927
Generalized Behavior Learning from Diverse Demonstrations
基于多样化示教的泛化行为学习
文章解读: 基于多样化示教的泛化行为学习
http://www.studyai.com/xueshu/paper/detail/5370610806
REBIND: Enhancing Ground-state Molecular Conformation Prediction via Force-Based Graph Rewiring
REBIND:基于力导向图重连增强基态分子构象预测
文章解读: REBIND:基于力导向图重连增强基态分子构象预测
http://www.studyai.com/xueshu/paper/detail/5375131729
Learning Graph Quantized Tokenizers
学习图量化分词器
文章解读: 学习图量化分词器
http://www.studyai.com/xueshu/paper/detail/5383300182
Artificial Kuramoto Oscillatory Neurons
人工 Kuramoto 振荡神经元
文章解读: 人工 Kuramoto 振荡神经元
http://www.studyai.com/xueshu/paper/detail/5385887587
FlashMask: Efficient and Rich Mask Extension of FlashAttention
FlashMask:高效且丰富的掩码扩展FlashAttention
文章解读: FlashMask:高效且丰富的掩码扩展FlashAttention
http://www.studyai.com/xueshu/paper/detail/5389932301
Dataset Distillation via Knowledge Distillation: Towards Efficient Self-Supervised Pre-training of Deep Networks
通过知识蒸馏进行数据集蒸馏:迈向深度网络高效自监督预训练
文章解读: 通过知识蒸馏进行数据集蒸馏:迈向深度网络高效自监督预训练
http://www.studyai.com/xueshu/paper/detail/5507805678
Relation-Aware Diffusion for Heterogeneous Graphs with Partially Observed Features
关系感知扩散模型用于具有部分观测特征的异构图
文章解读: 关系感知扩散模型用于具有部分观测特征的异构图
http://www.studyai.com/xueshu/paper/detail/5516109639
E(n) Equivariant Topological Neural Networks
E(n) 对称拓扑神经网络
文章解读: E(n) 对称拓扑神经网络
http://www.studyai.com/xueshu/paper/detail/5521967378
SMITE: Segment Me In TimE
SMITE:在时间中分割我
文章解读: SMITE:在时间中分割我
http://www.studyai.com/xueshu/paper/detail/5533218299
Fiddler: CPU-GPU Orchestration for Fast Inference of Mixture-of-Experts Models
Fiddler:专家混合模型的快速推理CPU-GPU编排
文章解读: Fiddler:专家混合模型的快速推理CPU-GPU编排
http://www.studyai.com/xueshu/paper/detail/5561697716
Open-Set Graph Anomaly Detection via Normal Structure Regularisation
基于正则结构的开集图异常检测
文章解读: 基于正则结构的开集图异常检测
http://www.studyai.com/xueshu/paper/detail/5562088180
You Only Sample Once: Taming One-Step Text-to-Image Synthesis by Self-Cooperative Diffusion GANs
你只采样一次:通过自合作扩散GAN控制一步式文本到图像合成
文章解读: 你只采样一次:通过自合作扩散GAN控制一步式文本到图像合成
http://www.studyai.com/xueshu/paper/detail/5575515856
Find A Winning Sign: Sign Is All We Need to Win the Lottery
找到一个获胜的标志:这个标志是我们赢得彩票的唯一需要。
文章解读: 找到一个获胜的标志:这个标志是我们赢得彩票的唯一需要。
http://www.studyai.com/xueshu/paper/detail/5597150579
AnyTouch: Learning Unified Static-Dynamic Representation across Multiple Visuo-tactile Sensors
AnyTouch:学习跨多个视觉触觉传感器的统一静态动态表示
文章解读: AnyTouch:学习跨多个视觉触觉传感器的统一静态动态表示
http://www.studyai.com/xueshu/paper/detail/5617285665
Biologically Constrained Barrel Cortex Model Integrates Whisker Inputs and Replicates Key Brain Network Dynamics
生物学约束的 barrels 皮层模型整合了触须输入并复制了关键的脑网络动力学
文章解读: 生物学约束的 barrels 皮层模型整合了触须输入并复制了关键的脑网络动力学
http://www.studyai.com/xueshu/paper/detail/5639707726
Periodic Materials Generation using Text-Guided Joint Diffusion Model
基于文本引导的联合扩散模型生成周期性材料
文章解读: 基于文本引导的联合扩散模型生成周期性材料
http://www.studyai.com/xueshu/paper/detail/5661989892
OptionZero: Planning with Learned Options
选项零:基于学习选项的规划
文章解读: 选项零:基于学习选项的规划
http://www.studyai.com/xueshu/paper/detail/5673369228
Collapsed Language Models Promote Fairness
崩溃的语言模型促进公平性
文章解读: 崩溃的语言模型促进公平性
http://www.studyai.com/xueshu/paper/detail/5673607579
MVTokenFlow: High-quality 4D Content Generation using Multiview Token Flow
MVTokenFlow:基于多视角令牌流的高质量4D内容生成
文章解读: MVTokenFlow:基于多视角令牌流的高质量4D内容生成
http://www.studyai.com/xueshu/paper/detail/5687161517
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
MaskGCT:零样本文本到语音生成,基于掩码生成码率转换Transformer
文章解读: MaskGCT:零样本文本到语音生成,基于掩码生成码率转换Transformer
http://www.studyai.com/xueshu/paper/detail/5701993808
Learning to Search from Demonstration Sequences
从演示序列中学习搜索
文章解读: 从演示序列中学习搜索
http://www.studyai.com/xueshu/paper/detail/5706239110
How to Evaluate Reward Models for RLHF
如何评估RLHF中的奖励模型
文章解读: 如何评估RLHF中的奖励模型
http://www.studyai.com/xueshu/paper/detail/5708856780
Cut the Crap: An Economical Communication Pipeline for LLM-based Multi-Agent Systems
砍掉废话:基于LLM的多智能体系统的经济通信管道
文章解读: 砍掉废话:基于LLM的多智能体系统的经济通信管道
http://www.studyai.com/xueshu/paper/detail/5710735273
HART: Efficient Visual Generation with Hybrid Autoregressive Transformer
HART:基于混合自回归Transformer的高效视觉生成
文章解读: HART:基于混合自回归Transformer的高效视觉生成
http://www.studyai.com/xueshu/paper/detail/5712835896
Breaking Class Barriers: Efficient Dataset Distillation via Inter-Class Feature Compensator
打破阶级壁垒:通过类间特征补偿器实现高效数据集蒸馏
文章解读: 打破阶级壁垒:通过类间特征补偿器实现高效数据集蒸馏
http://www.studyai.com/xueshu/paper/detail/5718638320
Self-Supervised Diffusion MRI Denoising via Iterative and Stable Refinement
基于迭代和稳定细化的自监督扩散MRI去噪
文章解读: 基于迭代和稳定细化的自监督扩散MRI去噪
http://www.studyai.com/xueshu/paper/detail/5719656566
GOttack: Universal Adversarial Attacks on Graph Neural Networks via Graph Orbits Learning
GOttack:通过图轨道学习实现图神经网络通用对抗攻击
文章解读: GOttack:通过图轨道学习实现图神经网络通用对抗攻击
http://www.studyai.com/xueshu/paper/detail/5737513250
Boltzmann Semantic Score: A Semantic Metric for Evaluating Large Vision Models Using Large Language Models
玻尔兹曼语义分数:一种使用大语言模型评估大型视觉模型的语义度量
文章解读: 玻尔兹曼语义分数:一种使用大语言模型评估大型视觉模型的语义度量
http://www.studyai.com/xueshu/paper/detail/5760506898
Partial Gromov-Wasserstein Metric
部分Gromov-Wasserstein度量
文章解读: 部分Gromov-Wasserstein度量
http://www.studyai.com/xueshu/paper/detail/5765537398
VICtoR: Learning Hierarchical Vision-Instruction Correlation Rewards for Long-horizon Manipulation
VICtoR:学习长时程操作中层级视觉-指令相关性奖励
文章解读: VICtoR:学习长时程操作中层级视觉-指令相关性奖励
http://www.studyai.com/xueshu/paper/detail/5768306771
A Theoretically-Principled Sparse, Connected, and Rigid Graph Representation of Molecules
一种基于理论原理的稀疏、连通且刚性的分子图表示
文章解读: 一种基于理论原理的稀疏、连通且刚性的分子图表示
http://www.studyai.com/xueshu/paper/detail/5768558993
Small Models are LLM Knowledge Triggers for Medical Tabular Prediction
小型模型是医疗表格预测的LLM知识触发器
文章解读: 小型模型是医疗表格预测的LLM知识触发器
http://www.studyai.com/xueshu/paper/detail/5778950191
Diffusion Models as Cartoonists: The Curious Case of High Density Regions
扩散模型作为漫画家:高密度区域的奇妙案例
文章解读: 扩散模型作为漫画家:高密度区域的奇妙案例
http://www.studyai.com/xueshu/paper/detail/5779889691
Symbolic regression via MDLformer-guided search: from minimizing prediction error to minimizing description length
基于MDLFormer引导搜索的符号回归:从最小化预测误差到最小化描述长度
文章解读: 基于MDLFormer引导搜索的符号回归:从最小化预测误差到最小化描述长度
http://www.studyai.com/xueshu/paper/detail/5799817055
Robustness Reprogramming for Representation Learning
表征学习的鲁棒性重编程
文章解读: 表征学习的鲁棒性重编程
http://www.studyai.com/xueshu/paper/detail/5803500725
Broaden your SCOPE! Efficient Multi-turn Conversation Planning for LLMs with Semantic Space
扩展您的范围!基于语义空间的LLMs高效多轮对话规划
文章解读: 扩展您的范围!基于语义空间的LLMs高效多轮对话规划
http://www.studyai.com/xueshu/paper/detail/5813867596
Polynomial Composition Activations: Unleashing the Dynamics of Large Language Models
多项式组合激活:释放大语言模型的动态
文章解读: 多项式组合激活:释放大语言模型的动态
http://www.studyai.com/xueshu/paper/detail/5818076377
HMoRA: Making LLMs More Effective with Hierarchical Mixture of LoRA Experts
HMoRA:通过分层LoRA专家混合使LLM更有效
文章解读: HMoRA:通过分层LoRA专家混合使LLM更有效
http://www.studyai.com/xueshu/paper/detail/5823568166
GenSE: Generative Speech Enhancement via Language Models using Hierarchical Modeling
GenSE:基于语言模型和分层建模的生成式语音增强
文章解读: GenSE:基于语言模型和分层建模的生成式语音增强
http://www.studyai.com/xueshu/paper/detail/5826801707
RelitLRM: Generative Relightable Radiance for Large Reconstruction Models
RelitLRM:适用于大型重建模型的生成式可重光照辐射
文章解读: RelitLRM:适用于大型重建模型的生成式可重光照辐射
http://www.studyai.com/xueshu/paper/detail/5830958269
StringLLM: Understanding the String Processing Capability of Large Language Models
StringLLM:理解大语言模型的字符串处理能力
文章解读: StringLLM:理解大语言模型的字符串处理能力
http://www.studyai.com/xueshu/paper/detail/5833087877
Regulatory DNA Sequence Design with Reinforcement Learning
基于强化学习的调控DNA序列设计
文章解读: 基于强化学习的调控DNA序列设计
http://www.studyai.com/xueshu/paper/detail/5835287302
Locality Sensitive Avatars From Video
基于视频的局部敏感虚拟形象
文章解读: 基于视频的局部敏感虚拟形象
http://www.studyai.com/xueshu/paper/detail/5838119196
ILLUSION: Unveiling Truth with a Comprehensive Multi-Modal, Multi-Lingual Deepfake Dataset
幻象:通过全面的跨模态、多语言深度伪造数据集揭示真相
文章解读: 幻象:通过全面的跨模态、多语言深度伪造数据集揭示真相
http://www.studyai.com/xueshu/paper/detail/5851253702
Object-Centric Pretraining via Target Encoder Bootstrapping
基于目标编码引导的面向对象预训练
文章解读: 基于目标编码引导的面向对象预训练
http://www.studyai.com/xueshu/paper/detail/5855576092
What Do You See in Common? Learning Hierarchical Prototypes over Tree-of-Life to Discover Evolutionary Traits
你在共同点中看到了什么?在生命之树中学习层次原型以发现进化特征
文章解读: 你在共同点中看到了什么?在生命之树中学习层次原型以发现进化特征
http://www.studyai.com/xueshu/paper/detail/5868167179

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 22
22 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)