【动手学UNet】(4)UNet 模型的训练
本文介绍了【动手学UNet】系列教程中的模型训练部分,详细讲解了UNet图像分割模型的完整训练流程。内容包括训练脚本模块core/train_unet.py的功能实现,如数据加载、模型构建、损失计算和参数更新等关键环节。文章展示了如何通过测试程序验证训练链路的正确性,并介绍了训练过程中集成验证集评估、模型保存及TensorBoard日志记录等优化措施。
欢迎关注『youcans动手学 AI』系列
【动手学UNet】(1)创建 UNet项目
【动手学UNet】(2)数据加载
【动手学UNet】(3)UNet 模型的实现
【动手学UNet】(4)UNet 模型的训练
【动手学UNet】(5)保存,加载与可视化
【动手学UNet】(6)模型推理与评估
【动手学UNet】(7)主程序
【动手学UNet】(4)UNet 模型的训练
欢迎来到【动手学UNet】系列教程!本系列将带你从零开始,一步步深入理解和实现经典的UNet图像分割模型。无论你是深度学习初学者,还是有一定经验的开发者,这个系列都将为你提供全面而实用的UNet知识。
8. 模型的训练(train_unet.py)
core/train_unet.py 是项目的训练脚本模块,用于组织数据加载、模型构建、损失计算与参数更新等完整训练流程。
其主要功能如下:
- 基于 config.py 中的全局配置,构建训练集 DataLoader,统一管理 batch 大小、图像尺寸和路径等参数;
- 实例化 U-Net 模型与损失函数(如 BCEDiceLoss),并配置优化器等训练相关组件;
- 实现按 epoch 的训练循环,计算并打印每个 batch 及每个 epoch 的平均损失和 Dice 指标;
- 在训练过程中定期保存模型权重(如 last_model.pth),为后续的评估、推理和继续训练提供基础。
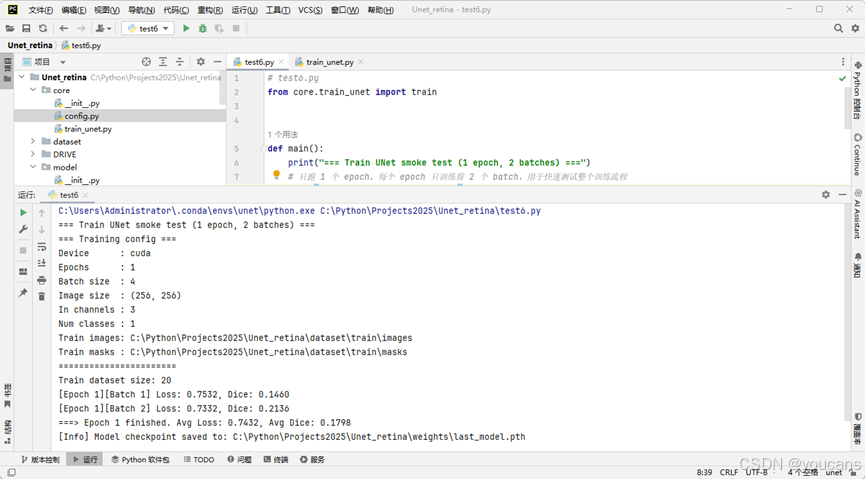
在项目的根目录编写测试程序 test6.py,对训练流程做“烟雾运行”,测试DataLoader → UNet → Loss → Optimizer 的训练链路。
控制台首先打印训练配置(Training config)如设备、batch 大小、路径等,然输入如下训练信息后正常结束,并保存 weights/last_model.pth。
=== Training config ===
Device : cuda
Epochs : 1
Batch size : 4
Image size : (256, 256)
In channels : 3
Num classes : 1
...
=======================
Train dataset size: 20
[Epoch 1][Batch 1] Loss: 0.7532, Dice: 0.1460
[Epoch 1][Batch 2] Loss: 0.7332, Dice: 0.2136
===> Epoch 1 finished. Avg Loss: 0.7432, Avg Dice: 0.1798
[Info] Model checkpoint saved to: C:\Python\Projects2025\Unet_retina\weights\last_model.pth
如果看到这些输出,没有异常报错,就说明烟雾测试已完成。
- DataLoader → UNet → Loss → Optimizer 的整个训练链条已打通;
- U-Net 项目已经具备一个完整的、可训练的最小闭环了。
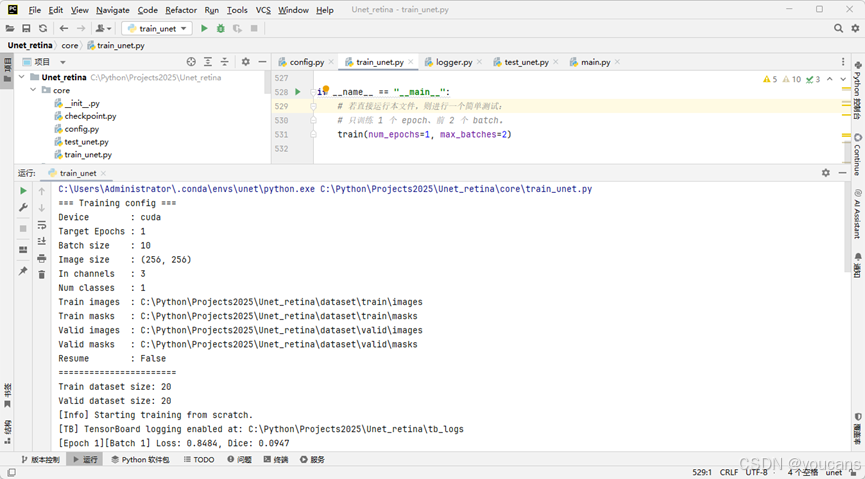
进一步地,可以在训练流程中集成了独立验证集 DataLoader,并在每个 epoch 的训练结束后自动运行一次验证(evaluation)。这样可以实时监控模型在验证集上的表现,从而判断模型是否真正泛化,而不是仅仅在训练集上变好。
训练循环在每个 epoch 将按如下顺序执行:
- 训练阶段(Train)
- 计算批级 loss / dice
- 记录 train/loss、train/dice 到 TensorBoard
- 计算整个 epoch 的平均 loss / dice(train/epoch_loss、train/epoch_dice)
- 验证阶段(Valid, Eval)
- 在完整验证集上运行前向推理
- 计算平均 val_loss、val_dice、val_iou
- 写入 TensorBoard:eval/dice, eval/iou
- 根据验证集性能(val_dice)更新 best_model
- 若当前 val_dice 超过历史最好值:
- 自动保存 best_modelYYMMDDHHMM.pth
- 同时更新 best_model.pth
- 在所有 epoch 完成后自动保存 last_model
- 保存为 last_modelYYMMDDHHMM.pth
- 同时更新稳定别名 last_model.pth
core/train_unet.py 的完整代码如下。
# core/train_unet.py
from pathlib import Path
from typing import Optional
from datetime import datetime
import torch
from torch.utils.data import DataLoader
from core.config import cfg
from core.checkpoint import save_model, load_model
from model.unet import UNet
from model.loss import BCEDiceLoss
from utils.data_utils import RetinaDataset
from utils.metrics import dice_coef, iou_coef
from utils.logger import create_tb_logger, TensorboardLogger
def create_dataloader(train: bool = True) -> DataLoader:
"""
构建训练集或验证集的 DataLoader。
:param train: True 则使用训练集路径,False 则使用验证集路径。
"""
if train:
image_dir = cfg.train_image_dir
mask_dir = cfg.train_mask_dir
shuffle = True
tag = "Train"
else:
image_dir = cfg.valid_image_dir
mask_dir = cfg.valid_mask_dir
shuffle = False
tag = "Valid"
dataset = RetinaDataset(
image_dir=str(image_dir),
mask_dir=str(mask_dir),
img_size=cfg.img_size,
in_channels=cfg.in_channels,
transform=None, # 后续可接入数据增强
)
if len(dataset) == 0:
print(f"[Warning] {tag} dataset is empty: {image_dir}")
else:
print(f"{tag} dataset size: {len(dataset)}")
dataloader = DataLoader(
dataset,
batch_size=cfg.batch_size if train else 1, # 验证时通常 batch=1 更方便可视化
shuffle=shuffle,
num_workers=cfg.num_workers,
pin_memory=True if cfg.device == "cuda" else False,
)
return dataloader
def train_one_epoch(
model: UNet,
dataloader: DataLoader,
optimizer: torch.optim.Optimizer,
device: str,
loss_fn: BCEDiceLoss,
epoch: int = 0,
max_batches: Optional[int] = None,
logger: Optional[TensorboardLogger] = None, # 用于记录 TensorBoard 日志
global_step: int = 0, # 累计的 batch 计数器
) -> tuple[int, float, float]:
"""
训练单个 epoch,并在控制台打印平均 loss 和 Dice。
:param max_batches: 若不为 None,则只训练前 max_batches 个 batch(用于测试/调试)
:param logger: 若不为 None,则在训练过程中写入 TensorBoard 日志
:param global_step: 当前全局 step(跨 epoch 累加)
:return: (更新后的 global_step, avg_loss, avg_dice)
"""
model.train()
running_loss = 0.0
running_dice = 0.0
num_batches = 0
for batch_idx, (images, masks) in enumerate(dataloader):
if max_batches is not None and batch_idx >= max_batches:
break
images = images.to(device)
masks = masks.to(device)
optimizer.zero_grad()
logits = model(images)
loss = loss_fn(logits, masks)
loss.backward()
optimizer.step()
# 计算训练时的 Dice 指标(使用 logits)
with torch.no_grad():
dice = dice_coef(logits, masks)
running_loss += loss.item()
running_dice += dice.item()
num_batches += 1
# 记录到 TensorBoard
if logger is not None:
logger.log_train_step(global_step=global_step, loss=loss.item(), dice=dice.item())
global_step += 1
print(
f"[Epoch {epoch}][Batch {batch_idx+1}] "
f"Loss: {loss.item():.4f}, Dice: {dice.item():.4f}"
)
if num_batches > 0:
avg_loss = running_loss / num_batches
avg_dice = running_dice / num_batches
print(
f"===> Epoch {epoch} finished. "
f"Avg Loss: {avg_loss:.4f}, Avg Dice: {avg_dice:.4f}"
)
# 记录 epoch 级别的平均指标
if logger is not None:
logger.log_train_epoch(epoch=epoch, avg_loss=avg_loss, avg_dice=avg_dice)
else:
avg_loss, avg_dice = 0.0, 0.0
print(f"[Epoch {epoch}] No batches were processed.")
return global_step, avg_loss, avg_dice
def eval_one_epoch(
model: UNet,
dataloader: DataLoader,
device: str,
loss_fn: BCEDiceLoss,
epoch: int = 0,
logger: Optional[TensorboardLogger] = None,
) -> tuple[float, float, float]:
"""
在验证集上计算平均 Loss / Dice / IoU。
返回:avg_loss, avg_dice, avg_iou
"""
model.eval()
running_loss = 0.0
running_dice = 0.0
running_iou = 0.0
num_batches = 0
with torch.no_grad():
for batch_idx, (images, masks) in enumerate(dataloader):
images = images.to(device)
masks = masks.to(device)
logits = model(images)
loss = loss_fn(logits, masks)
dice = dice_coef(logits, masks)
iou = iou_coef(logits, masks)
running_loss += loss.item()
running_dice += dice.item()
running_iou += iou.item()
num_batches += 1
print(
f"[Valid][Epoch {epoch}][Batch {batch_idx+1}] "
f"Loss: {loss.item():.4f}, Dice: {dice.item():.4f}, IoU: {iou.item():.4f}"
)
if num_batches > 0:
avg_loss = running_loss / num_batches
avg_dice = running_dice / num_batches
avg_iou = running_iou / num_batches
print(
f"===> [Valid] Epoch {epoch} finished. "
f"Avg Loss: {avg_loss:.4f}, Avg Dice: {avg_dice:.4f}, Avg IoU: {avg_iou:.4f}"
)
if logger is not None:
# 这里的 step 直接用 epoch
logger.log_eval_epoch(step=epoch, avg_dice=avg_dice, avg_iou=avg_iou)
else:
avg_loss, avg_dice, avg_iou = 0.0, 0.0, 0.0
print(f"[Valid][Epoch {epoch}] No batches were processed.")
return avg_loss, avg_dice, avg_iou
def train(
num_epochs: int = None,
max_batches: Optional[int] = None,
resume: bool = False,
) -> None:
"""
U-Net 训练入口函数(训练 + 验证 + TensorBoard + 断点续训 + best/last 保存)。
:param num_epochs: 训练目标 epoch 数;为 None 时使用 cfg.epochs。
:param max_batches: 若不为 None,则每个 epoch 只训练前 max_batches 个 batch(仅作用于训练集)。
:param resume: 是否从已有 checkpoint(cfg.last_model_path)恢复训练。
"""
device = cfg.device
if num_epochs is None:
num_epochs = cfg.epochs
print("=== Training config ===")
print(f"Device : {device}")
print(f"Target Epochs : {num_epochs}")
print(f"Batch size : {cfg.batch_size}")
print(f"Image size : {cfg.img_size}")
print(f"In channels : {cfg.in_channels}")
print(f"Num classes : {cfg.num_classes}")
print(f"Train images : {cfg.train_image_dir}")
print(f"Train masks : {cfg.train_mask_dir}")
print(f"Valid images : {cfg.valid_image_dir}")
print(f"Valid masks : {cfg.valid_mask_dir}")
print(f"Resume : {resume}")
print("=======================")
# 1. DataLoader:训练 & 验证
train_loader = create_dataloader(train=True)
valid_loader = create_dataloader(train=False)
# 2. 模型 & 优化器 & 损失函数
model = UNet(
in_channels=cfg.in_channels,
num_classes=cfg.num_classes,
base_channels=64,
bilinear=True,
).to(device)
loss_fn = BCEDiceLoss(bce_weight=0.5, dice_weight=0.5)
optimizer = torch.optim.Adam(model.parameters(), lr=cfg.lr)
# 3. 是否从 checkpoint 恢复训练
if resume and cfg.last_model_path.exists():
print(f"[Resume] Trying to load checkpoint from: {cfg.last_model_path}")
model, optimizer, last_epoch = load_model(
cfg.last_model_path,
model,
optimizer,
)
if last_epoch is not None:
start_epoch = last_epoch + 1
print(f"[Resume] Checkpoint epoch = {last_epoch}, "
f"training will continue from epoch {start_epoch}.")
else:
start_epoch = 1
print("[Resume] Checkpoint has no epoch info, start from epoch 1.")
else:
start_epoch = 1
if resume:
print(f"[Resume] last_model.pth not found, start training from scratch.")
else:
print("[Info] Starting training from scratch.")
if start_epoch > num_epochs:
print(f"[Info] start_epoch ({start_epoch}) > num_epochs ({num_epochs}), "
f"nothing to train. Exit.")
return
# 4. 创建 TensorBoard logger
enable_logger = True
logger = create_tb_logger(cfg.tb_log_dir, enable=enable_logger)
global_step = 0
cfg.weights_dir.mkdir(parents=True, exist_ok=True)
# 记录“当前最好的验证集 Dice”
best_dice = -1.0
best_epoch = None
try:
# 5. 训练 + 验证循环
for epoch in range(start_epoch, num_epochs + 1):
# --- 5.1 训练 ---
global_step, train_loss, train_dice = train_one_epoch(
model=model,
dataloader=train_loader,
optimizer=optimizer,
device=device,
loss_fn=loss_fn,
epoch=epoch,
max_batches=max_batches,
logger=logger,
global_step=global_step,
)
# --- 5.2 验证 ---
if len(valid_loader.dataset) > 0:
val_loss, val_dice, val_iou = eval_one_epoch(
model=model,
dataloader=valid_loader,
device=device,
loss_fn=loss_fn,
epoch=epoch,
logger=logger, # 验证阶段也写 TensorBoard:eval/dice, eval/iou
)
else:
val_loss, val_dice, val_iou = 0.0, 0.0, 0.0
print(f"[Valid][Epoch {epoch}] Skip validation (valid dataset empty).")
# --- 5.3 根据验证集 Dice 更新 best model ---
if val_dice > best_dice and len(valid_loader.dataset) > 0:
best_dice = val_dice
best_epoch = epoch
timestamp = datetime.now().strftime("%y%m%d%H%M")
# 带时间戳的 best_model
best_ts_path = cfg.weights_dir / f"best_model{timestamp}.pth"
save_model(model, best_ts_path, optimizer=optimizer, epoch=epoch)
# 覆盖稳定别名 best_model.pth
save_model(model, cfg.best_model_path, optimizer=optimizer, epoch=epoch)
print(
f"[Best] New best model at epoch {epoch} "
f"(Val Dice={best_dice:.4f}), saved to:\n"
f" {best_ts_path}\n"
f" {cfg.best_model_path}"
)
# 6. 训练结束后保存“最后模型”
timestamp = datetime.now().strftime("%y%m%d%H%M")
last_ts_path = cfg.weights_dir / f"last_model{timestamp}.pth"
save_model(model, last_ts_path, optimizer=optimizer, epoch=num_epochs)
save_model(model, cfg.last_model_path, optimizer=optimizer, epoch=num_epochs)
print(
f"[Last] Final model at epoch {num_epochs} saved to:\n"
f" {last_ts_path}\n"
f" {cfg.last_model_path}"
)
if best_epoch is not None:
print(
f"[Summary] Best Val Dice={best_dice:.4f} at epoch {best_epoch} "
f"(checkpoint: {cfg.best_model_path})"
)
finally:
if logger is not None:
logger.close()
# if __name__ == "__main__":
# # 若直接运行本文件,则进行一个简单测试:
# # 只训练 1 个 epoch、前 2 个 batch。
# train(num_epochs=1, max_batches=2)
【本节完】
版权声明:
欢迎关注『youcans动手学 AI』系列
转发请注明原文链接:
【动手学UNet】(4)UNet 模型的训练
Copyright 2025 youcans
Crated:2025-11


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)