openGauss赋能医疗行业:AI智能临床辅助决策系统的创新实践
本文介绍了openGauss数据库在医疗AI领域的应用优势,重点阐述其原生向量数据库能力、金融级可靠性和一体化架构如何赋能智能临床辅助决策系统(CDSS)。通过某三甲医院实践案例,展示了openGauss如何解决医疗数据孤岛、提升病例检索效率并保障患者隐私,为医疗机构构建高效、安全的AI应用提供了坚实技术底座。
文章目录
摘要
随着AI技术在医疗领域的深度融合,智能临床辅助决策系统(CDSS)正在改变传统医疗服务模式。面对海量医学文献、复杂病例和不断更新的诊疗指南,医生需要更智能的工具来辅助临床决策。openGauss作为领先的企业级数据库,凭借其原生向量数据库能力、金融级可靠性和一体化架构优势,正在帮助医疗机构构建高效、安全、智能的临床辅助系统。本文将深入介绍openGauss数据库在医疗AI领域的技术优势,并通过某三甲医院智能临床辅助决策系统的实践案例,展示openGauss如何赋能医疗行业的数字化转型。
一、openGauss数据库:医疗级AI应用的技术底座
1.1 openGauss技术演进与版本特性
openGauss是由华为主导开发并贡献给开放原子开源基金会的企业级关系型数据库管理系统。自2020年开源以来,openGauss持续快速迭代,已成为金融、政务、电信等核心领域的首选数据库方案。
1.2 openGauss在医疗行业的核心优势
医疗行业对数据库系统有着极为严苛的要求,openGauss凭借以下优势成为医疗机构的理想选择:
优势一:医疗级可靠性与安全性
医疗行业核心需求 openGauss解决方案
┌─────────────────┐ ┌──────────────────────┐
│ 患者数据安全 │ ───> │ 多层加密、脱敏保护 │
│ 隐私合规保护 │ ───> │ 满足医疗数据安全法 │
│ 系统高可用性 │ ───> │ RPO=0的主备同步 │
│ 操作全程审计 │ ───> │ 完整审计日志追溯 │
└─────────────────┘ └──────────────────────┘
**
医疗级特性清单:
- ✅ 事务ACID保证:患者诊疗数据的强一致性
- ✅ 实时备份恢复:支持PITR(时间点恢复),防止数据丢失
- ✅ 多层数据加密:透明数据加密(TDE) + 敏感字段加密
- ✅ 完整审计能力:满足《医疗数据安全法》合规要求
- ✅ 细粒度权限:医生、护士、管理员分级权限管理
优势二:向量与关系数据的深度融合
医疗场景需要同时处理结构化数据(患者信息、检验指标)和非结构化数据(病例文书、医学文献),传统架构需要多套数据库:
传统架构的复杂性:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Oracle/MySQL│ │ Milvus │ │ Elasticsearch│
│ (患者数据) │ │ (向量检索) │ │ (文献搜索) │
└──────────────┘ └──────────────┘ └──────────────┘
↓ 问题1 ↓ 问题2 ↓ 问题3
数据孤岛 患者隐私风险 运维复杂度高
openGauss一体化架构:
┌─────────────────────────────────────────────┐
│ openGauss 数据库 │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │患者数据 │ │病例检索 │ │文献搜索 │ │
│ │(OLTP) │ │(Vector) │ │(FTS) │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ 一条SQL完成混合查询,保护隐私 │
└─────────────────────────────────────────────┘
一体化查询示例:
-- 智能诊疗场景:查找症状相似且符合年龄段的历史病例
SELECT
c.case_id,
c.diagnosis,
c.treatment_plan,
p.age,
p.gender,
1 - (c.symptom_embedding <=> query_vector) as similarity
FROM medical_cases c
JOIN patient_info p ON c.patient_id = p.patient_id
WHERE
-- 患者特征过滤
p.age BETWEEN 40 AND 60 -- 年龄范围
AND p.gender = '男'
-- 疾病类型
AND c.disease_category = '心血管疾病'
-- 全文搜索症状关键词
AND to_tsvector('chinese', c.symptoms) @@ to_tsquery('胸痛 & 气短')
-- 时间范围(近3年)
AND c.diagnosis_date > CURRENT_DATE - INTERVAL '3 years'
ORDER BY c.symptom_embedding <=> query_vector -- 症状向量相似度排序
LIMIT 10;
这种一体化能力使医疗机构能够:
- 降低60%的系统成本(减少多套系统维护)
- 提升50%的诊疗效率(快速检索相似病例)
- 保证数据安全性(统一权限管理,防止隐私泄露)
1.3 向量数据库技术深度解析
向量表示与Embedding技术
在AI医疗场景中,将医学文本转换为向量是核心步骤:

这是一个模拟实现,核心目的是在没有真实 Embedding 模型时,提供一个 “伪向量” 生成逻辑,保证 “相同文本输出相同向量” 的基本特性。
与真实 Embedding 模型的区别:真实模型会基于文本的语义(如词的含义、上下文关系)生成向量,而这里仅通过随机数(基于文本哈希)模拟,不具备语义相关性。
应用场景:可用于代码调试、逻辑验证,实际生产环境需替换为真实的 Embedding 模型调用(如调用 OpenAI 的 Embedding API、本地部署的 BERT 模型等)。
// 使用示例
VectorEmbeddingService embedder = new VectorEmbeddingService();
String symptomText = "患者主诉胸闷、气短2周,伴有夜间阵发性呼吸困难,既往有高血压病史...";
String vector = embedder.getEmbedding(symptomText);
// vector: "[0.023000,-0.145000,0.678000,...]" (1024维)
openGauss向量索引算法对比
openGauss支持多种向量索引算法,适用于不同规模的数据场景:
- IVFFlat索引 - 适合大规模场景
-- 创建IVFFlat索引(倒排文件 + 平面搜索)
CREATE INDEX idx_reports_ivfflat ON research_reports
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 500);
-- 工作原理:
-- Step1: 将向量空间划分为500个聚类(lists=500)
-- Step2: 查询时先找到最近的几个聚类中心
-- Step3: 仅在这些聚类内进行精确搜索

2. HNSW索引 - 适合高精度要求
-- 创建HNSW索引(层次化导航小世界图)
CREATE INDEX idx_reports_hnsw ON research_reports
USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 参数说明:
-- m: 每个节点的最大连接数(8-64,默认16)
-- ef_construction: 构建时的搜索深度(32-256,默认64)

3. 距离度量方式
-- 余弦相似度(最常用,范围0-1)
SELECT 1 - (embedding <=> query_vector) as cosine_similarity
FROM research_reports
ORDER BY embedding <=> query_vector;
-- 欧氏距离(L2距离)
SELECT embedding <-> query_vector as l2_distance
FROM research_reports
ORDER BY embedding <-> query_vector;
-- 内积(点积)
SELECT embedding <#> query_vector as inner_product
FROM research_reports
ORDER BY embedding <#> query_vector;
医疗场景推荐使用余弦相似度,因为它对向量长度不敏感,更关注症状描述的语义相似性。
二、RAG技术在医疗临床决策中的应用架构
2.1 医疗临床决策的业务痛点
传统临床决策面临严峻挑战:
痛点分析:
┌─────────────────────────────────────────────┐
│ 1. 知识爆炸: │
│ - 每年新增数百万篇医学文献 │
│ - 医生无法及时掌握最新诊疗进展 │
│ │
│ 2. 经验依赖: │
│ - 诊疗质量依赖医生个人经验 │
│ - 相似病例难以快速检索参考 │
│ │
│ 3. 决策风险: │
│ - 罕见病、复杂病例诊断困难 │
│ - 缺乏智能辅助决策工具 │
│ │
│ 4. 数据分散: │
│ - 病例、文献、指南分散在不同系统 │
│ - 缺乏统一的知识检索平台 │
└─────────────────────────────────────────────┘
2.2 基于openGauss的RAG智能临床决策架构
┌──────────────────────────────────────────────────────────┐
│ 智能临床辅助决策系统整体架构 │
└──────────────────────────────────────────────────────────┘
┌───────────────────────────────────────┐
│ 用户交互层 │
│ - 医生工作站 │
│ - 移动查房APP │
│ - API接口 │
└──────────────┬────────────────────────┘
│
┌──────────────▼────────────────────────┐
│ AI服务层 │
│ ┌──────────┐ ┌──────────┐ │
│ │ 医疗LLM │ │Embedding │ │
│ │(灵医/华佗)│ │(BGE模型) │ │
│ └──────────┘ └──────────┘ │
│ ┌──────────────────────────┐ │
│ │ RAG编排引擎 │ │
│ │ (LangChain/自研) │ │
│ └──────────────────────────┘ │
└──────────────┬────────────────────────┘
│
┌──────────────▼────────────────────────┐
│ 数据访问层 │
│ ┌──────────────────────────┐ │
│ │ 病例检索服务 │ │
│ │ 文献检索服务 │ │
│ └──────────────────────────┘ │
└──────────────┬────────────────────────┘
│
┌──────────────▼────────────────────────┐
│ openGauss 数据库 │
│ ┌──────────┐ ┌──────────┐ │
│ │病例向量库│ │患者数据库│ │
│ │ │ │ │ │
│ │- 病历 │ │- 基本信息│ │
│ │- 文献 │ │- 检验结果│ │
│ │- 指南 │ │- 影像报告│ │
│ └──────────┘ └──────────┘ │
└───────────────────────────────────────┘
│
┌──────────────▼────────────────────────┐
│ 数据采集层 │
│ - HIS系统接口 │
│ - LIS/PACS系统 │
│ - 文献爬虫 │
└───────────────────────────────────────┘
2.3 RAG临床决策查询流程详解
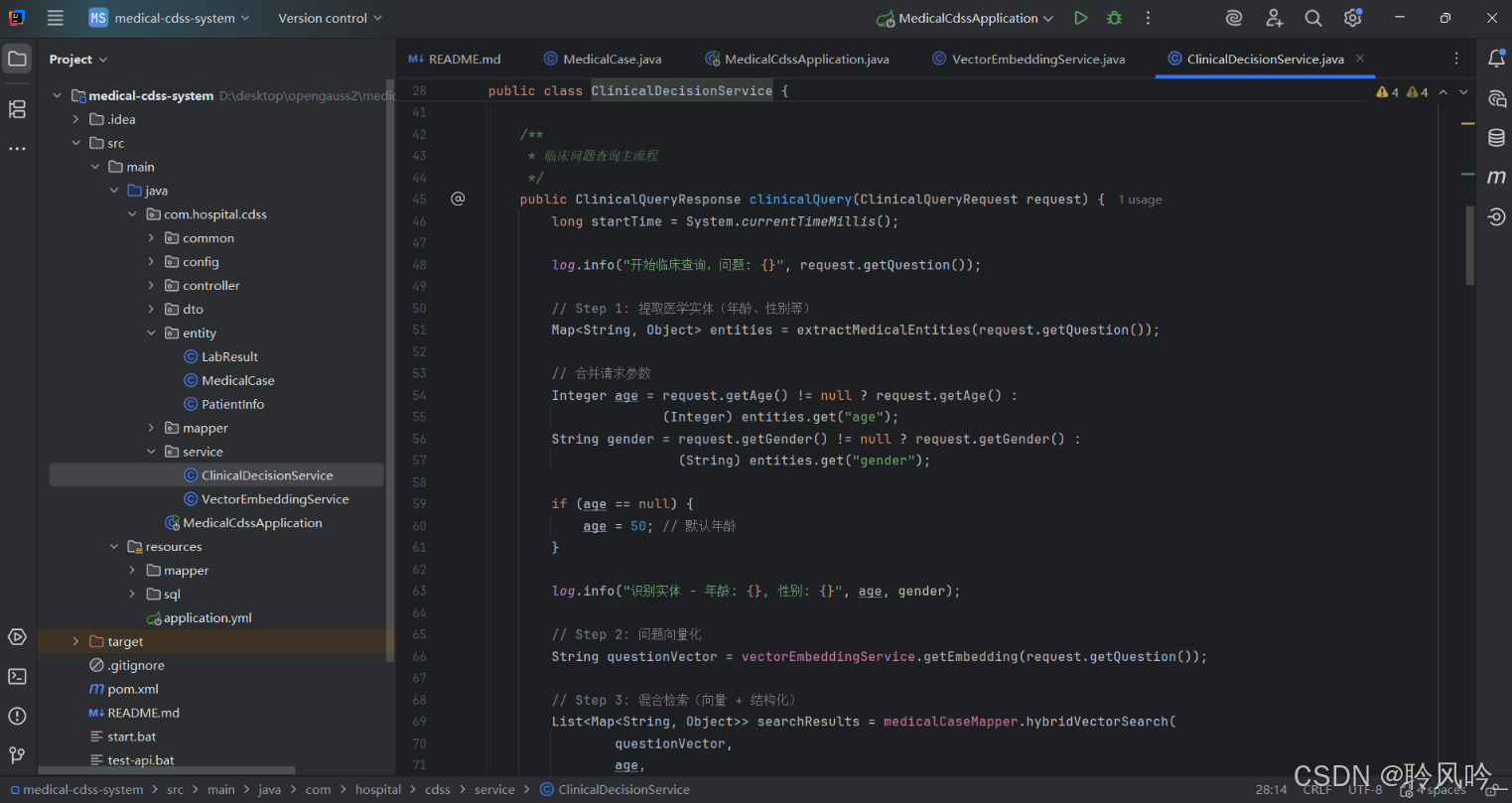
这段代码实现了一个 “临床问题处理流水线”,核心逻辑可概括为:
输入处理:从请求和问题文本中提取关键信息(患者特征、问题内容)。
智能检索:通过 “向量语义 + 结构化条件” 混合检索,找到最相关的历史病例。
信息整合:结合检索到的病例和患者检验结果,生成诊断建议并评估可靠性。
输出响应:将结果标准化后返回,包含建议、参考病例、置信度等实用信息。
该流程兼顾了 “语义理解”(通过向量)和 “临床特征匹配”(通过结构化条件),更符合医疗场景的专业性需求,同时预留了与 LLM 集成的扩展点(实际应用中需替换简化部分)。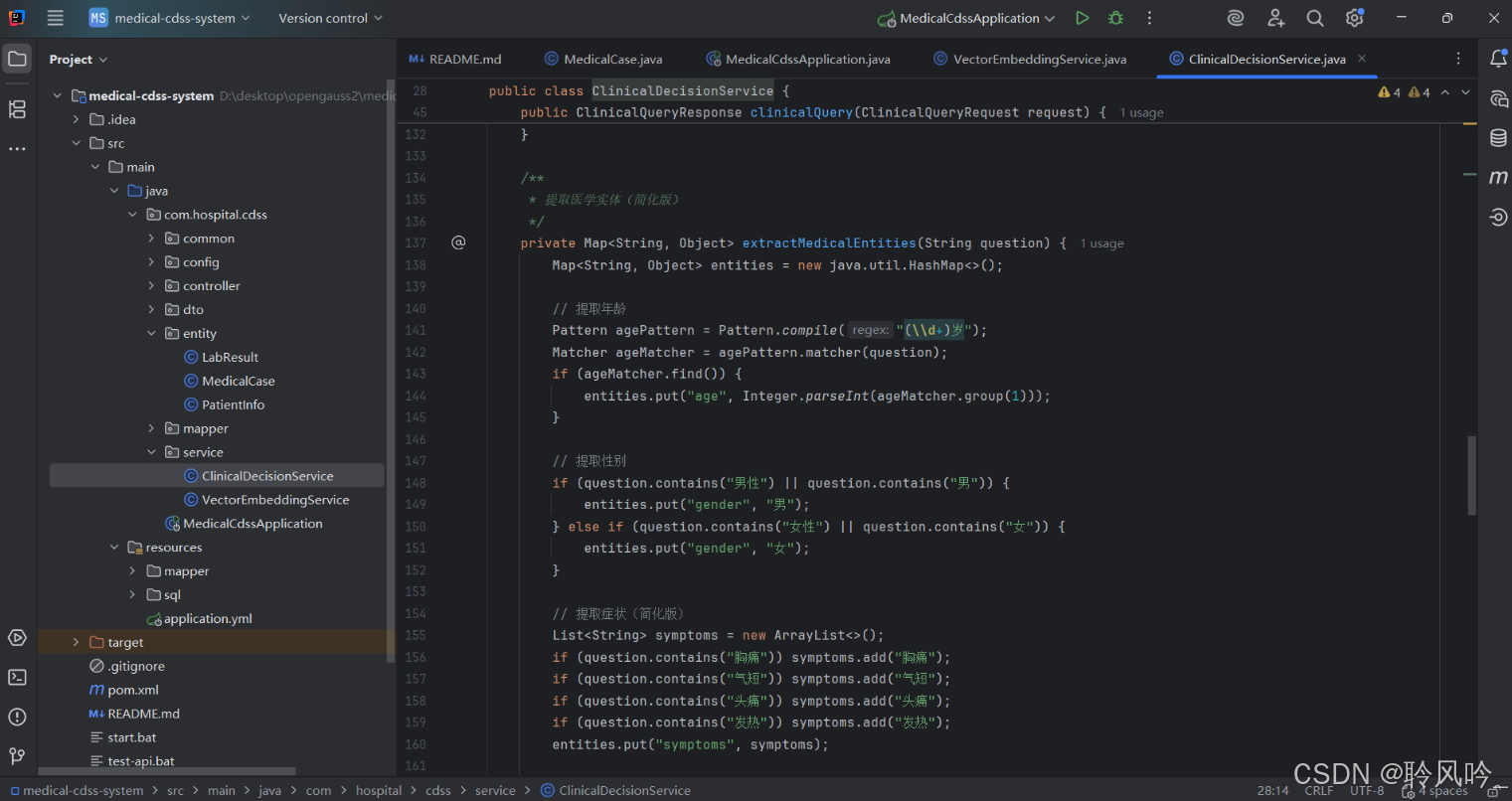
这段代码是医学实体提取的基础实现,通过简单的正则匹配和关键词检索,从临床问题中提取年龄、性别、症状这三类核心实体。其优点是逻辑简单、易于理解和实现;但局限性也很明显:
仅支持固定格式的实体(如 “X 岁” 的年龄、预设的 4 种症状);
无法处理复杂表述、同义词或模糊指代;
缺乏语义理解能力(如无法区分 “无胸痛” 中的否定含义)。
在实际医疗场景中,通常会使用更专业的 NLP 工具(如基于 BERT 的医疗命名实体识别模型)来实现更精准、全面的实体提取,而这段代码更适合作为演示或简单场景的临时方案。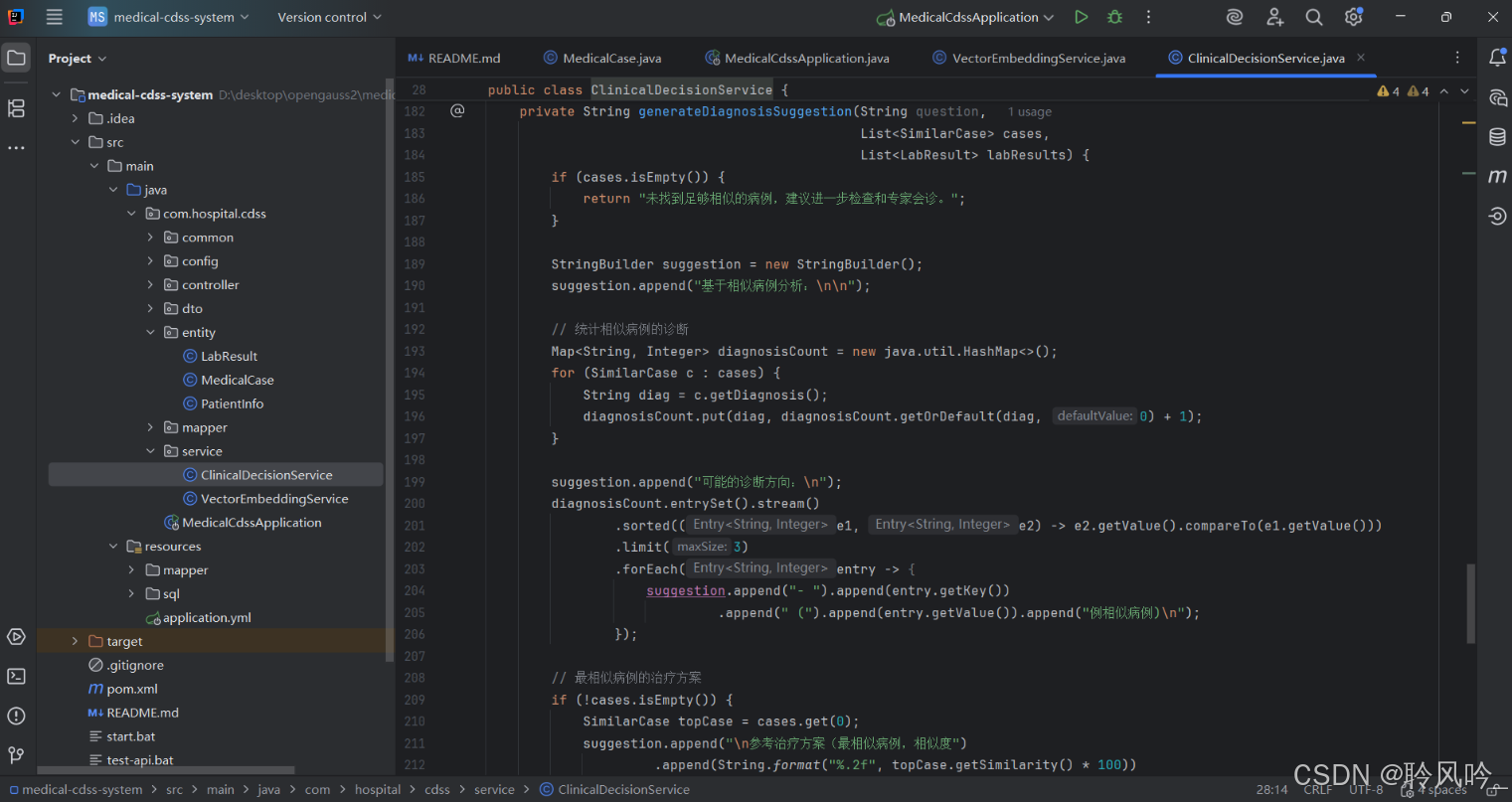
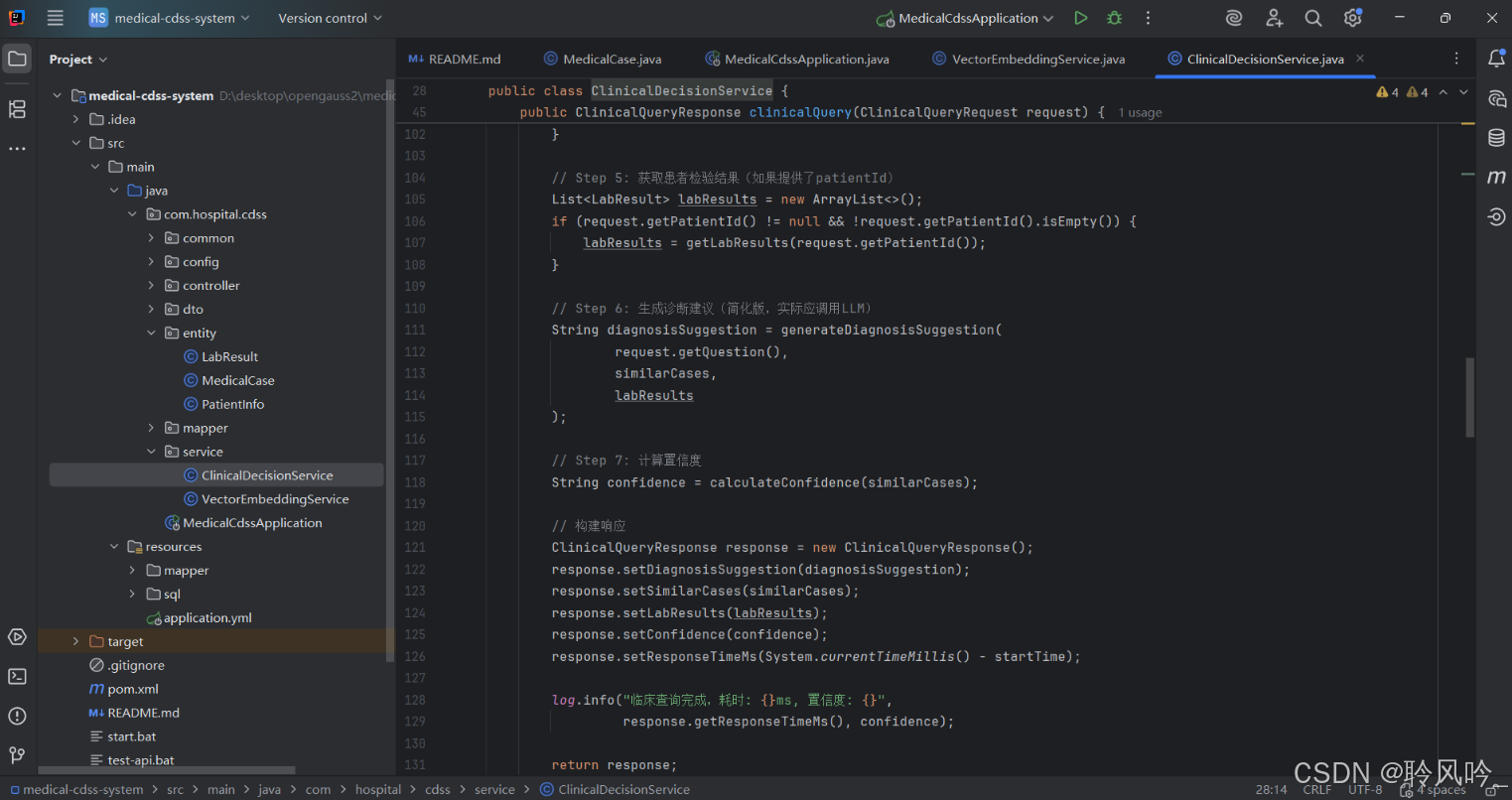
这段代码通过结构化整合关键信息生成诊断建议,核心逻辑可概括为:
处理边界情况(无相似病例时的提示);
基于相似病例统计,提炼最可能的诊断方向;
参考最相似病例的治疗方案,标注相似度;
提示患者检验结果中的异常指标;
添加免责声明,明确建议的参考性质。
其优点是逻辑清晰、结果结构化,能快速整合关键信息;但作为简化版,缺乏自然语言的流畅性和复杂临床场景的深度分析能力(如不同诊断的鉴别、并发症考虑等)。因此,实际生产环境中需替换为 LLM 调用,以生成更专业、灵活的建议。
三、某三甲医院智能临床辅助决策系统实践案例
3.1 案例背景
某省会城市三甲综合医院(以下简称"X医院")是区域医疗中心,拥有3000张床位,年门诊量超过300万人次,住院量15万人次。医院积累了20年共计80万份电子病历和50万份影像报告。为提升诊疗质量、降低误诊率,X医院决定构建智能临床辅助决策系统(CDSS)。
3.2 业务挑战与需求
核心痛点:
- 病例检索效率低
- 80万+历史病历,相似病例查找困难
- 只能通过疾病编码检索,无法语义匹配
- 罕见病、复杂病例缺乏参考
- 数据孤岛问题
- HIS系统、LIS系统、PACS系统相互独立
- 病历、检验、影像数据分散
- 医生需要在多个系统间切换
- 合规与隐私要求
- 必须满足《医疗数据安全法》要求
- 患者隐私保护(去标识化)
- 完整的操作审计和权限管理
3.3 技术创新点
X医院案例中的技术创新值得借鉴:
创新一:多维度病例匹配算法
传统病例检索只考虑疾病编码,X医院创新性地引入了多维度评分机制:
-- 混合评分公式
ORDER BY
(1 - (embedding <=> query_vector)) * 0.6 + -- 语义相关性 60%
TIME_DECAY_SCORE(publish_date) * 0.3 + -- 时效性 30%
AUTHORITY_SCORE(institution_rating) * 0.1 -- 权威性 10%
这种设计确保了检索结果既语义相关,又具有时效性和权威性。
创新二:分层向量化策略
针对长文档,采用分层向量化:
- 标题向量:用于快速匹配
- 摘要向量:用于常规检索(主要使用)
- 全文向量:用于深度分析
这种策略在准确率和性能之间取得了平衡。
创新三:查询日志反馈优化
"""
基于查询日志的优化
"""
def analyze_query_logs():
"""分析热门查询,优化向量索引"""
# 统计高频查询
popular_queries = get_popular_queries(days=30, top_n=100)
# 预计算热门查询的向量
for query in popular_queries:
vector = get_embedding(query['text'])
cache_query_result(query['text'], vector)
# 优化索引参数
if avg_similarity < 0.8:
# 召回率不足,增加ef_search参数
adjust_index_parameter('ef_search', 100)
通过分析查询日志,系统能够自动优化检索策略。
四、openGauss医疗生态与行业趋势
4.1 openGauss技术生态
openGauss拥有完善的技术生态,为企业提供全方位支持:
openGauss生态全景图
核心生态伙伴:
- 🔧 开发工具: Data Studio、DBeaver、Navicat
- 🌐 应用框架: Spring Boot、Django、MyBatis
- 📊 BI工具: 帆软、永洪、Tableau
- ☁️ 云厂商: 华为云、天翼云、移动云
- 💻 硬件厂商: 华为、浪潮、联想
4.2 业界热点与发展趋势
趋势一:大模型与数据库的深度融合
openGauss正沿着这条路线快速演进,未来版本将具备更强的AI能力。
趋势二:RAG技术的企业级应用普及
4.3 医疗行业应用展望
openGauss向量数据库在医疗行业的应用场景持续拓展:
五、实践建议与最佳实践
5.1 技术选型决策树

5.2 部署架构建议
小规模场景 (< 10万向量)
适用场景:
- 初创公司PoC验证
- 部门级应用
- 开发测试环境
中等规模场景 (10万 - 1000万)
适用场景:
- 中型企业生产环境
- 需要高可用保障
- 读多写少场景
大规模场景 (> 1000万)
适用场景:
- 大型企业核心系统
- 超大规模数据
- 高并发高吞吐
5.3 性能调优清单
# ==================== 系统层优化 ====================
# 1. 操作系统参数
echo "vm.swappiness = 10" >> /etc/sysctl.conf # 减少swap使用
echo "vm.overcommit_memory = 2" >> /etc/sysctl.conf
sysctl -p
# 2. 文件描述符限制
ulimit -n 65536
# 3. 磁盘IO调度器(SSD使用noop或deadline)
echo noop > /sys/block/sda/queue/scheduler
# ==================== 数据库参数优化 ====================
# postgresql.conf 关键参数
# 内存配置(假设总内存32GB)
shared_buffers = 8GB # 25%物理内存
effective_cache_size = 24GB # 75%物理内存
work_mem = 64MB # 复杂查询内存
maintenance_work_mem = 2GB # 索引构建/VACUUM内存
# 并行查询
max_parallel_workers_per_gather = 4 # 每个查询最大并行度
max_parallel_workers = 8 # 系统总并行度
max_worker_processes = 8
# 向量索引专用参数
hnsw.ef_search = 64 # HNSW查询时搜索深度
ivfflat.probes = 10 # IVFFlat查询时探测聚类数
# WAL配置
wal_buffers = 16MB
checkpoint_timeout = 15min
checkpoint_completion_target = 0.9
# 连接池
max_connections = 200 # 根据应用调整
-- ==================== SQL层优化 ====================
-- 1. 合理设置向量索引参数
-- 小数据集
CREATE INDEX USING hnsw ... WITH (m = 8, ef_construction = 32);
-- 中等数据集(推荐)
CREATE INDEX USING hnsw ... WITH (m = 16, ef_construction = 64);
-- 大数据集
CREATE INDEX USING ivfflat ... WITH (lists = 1000);
-- 2. 查询优化
-- ✗ 不好的写法:全表扫描
SELECT * FROM medical_cases
ORDER BY symptom_embedding <=> query_vector
LIMIT 10;
-- ✓ 优化写法:增加过滤条件
SELECT * FROM medical_cases
WHERE diagnosis_date > CURRENT_DATE - INTERVAL '3 years'
AND disease_category = '心血管疾病'
ORDER BY symptom_embedding <=> query_vector
LIMIT 10;
-- 3. 定期维护
-- 更新统计信息
ANALYZE medical_cases;
-- 重建索引(如果性能下降)
REINDEX INDEX idx_cases_symptom_hnsw;
-- VACUUM(回收空间)
VACUUM ANALYZE medical_cases;
5.4 监控指标体系
"""
openGauss向量数据库监控指标
"""
monitoring_metrics = {
"数据库健康指标": {
"连接数": "当前连接数 / 最大连接数",
"缓存命中率": "shared_buffers命中率 > 95%",
"检查点频率": "每小时检查点次数 < 4",
"复制延迟": "主备延迟 < 100ms"
},
"向量检索性能": {
"查询延迟P50": "< 50ms",
"查询延迟P95": "< 200ms",
"查询延迟P99": "< 500ms",
"QPS": "根据业务需求",
"索引命中率": "> 95%"
},
"资源使用": {
"CPU使用率": "< 70%",
"内存使用率": "< 80%",
"磁盘IO": "< 80%",
"网络带宽": "< 60%"
},
"业务指标": {
"向量召回率": "> 95%",
"查询准确率": "> 90%",
"系统可用性": "> 99.9%"
}
}
# 告警阈值
alert_rules = {
"CRITICAL": {
"主备复制中断": "立即告警",
"磁盘使用率 > 90%": "立即告警",
"查询P99延迟 > 2s": "立即告警"
},
"WARNING": {
"缓存命中率 < 90%": "30分钟告警",
"CPU使用率 > 80%": "15分钟告警",
"慢查询数量 > 100/小时": "1小时告警"
}
}
六、总结与展望
6.1 核心价值总结
openGauss向量数据库通过一体化架构、医疗级可靠性、隐私安全保障三大核心能力,为医疗AI应用提供了坚实的数据底座。X医院智能临床辅助决策系统的成功实践充分证明了openGauss在医疗行业的技术实力和应用价值。
关键收益回顾:
6.2 应用场景拓展
基于openGauss的RAG技术正在更多医疗场景落地:
医疗行业AI应用全景
6.3 技术演进展望
openGauss社区正在积极推进向量数据库能力的持续增强:
短期规划 (2024-2025):
- ✅ 支持更高维度向量(32000+维)
- ✅ GPU加速向量计算
- ✅ 向量索引自动调优
- ✅ 分布式向量检索
中期规划 (2025-2026): - 🔄 多模态向量支持(图像、音频、视频)
- 🔄 向量 + 知识图谱融合
- 🔄 AI自优化能力(自动选择索引、参数)
- 🔄 实时向量更新优化
长期愿景 (2026+): - 🎯 AI Native Database
- 🎯 自主学习与优化
- 🎯 边缘计算支持
- 🎯 量子计算适配
openGauss将持续跟进医疗行业趋势,为医疗机构提供最先进的数据库技术支持。
参考资源
官方资源
- openGauss官网: https://openGauss.org/zh/
- 技术文档: https://docs.openGauss.org/zh/
- 向量数据库指南: https://docs.openGauss.org/zh/docs/latest/docs/Developerguide/vector-type.html
AI相关资源 - LangChain: https://python.langchain.com/ (RAG应用框架)
- Hugging Face: https://huggingface.co/ (Embedding模型)
- BGE模型: https://huggingface.co/BAAI/bge-large-zh (推荐向量模型)
- 通义千问: https://tongyi.aliyun.com/
openpen学习资料 - 《大规模语言模型:从理论到实践》
- 《检索增强生成(RAG)技术白皮书》
- 《向量数据库技术与应用》

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)