ToT与ReAct:突破大模型推理能力瓶颈
当前,大语言模型的核心瓶颈已从“知识储备”转向“推理能力”。Tree-of-Thoughts (ToT) 与 ReAct 框架代表了突破此瓶颈的两种革命性路径。ToT 通过模拟人类“三思而后行”的决策过程,将线性推理链拓展为树状结构,引入了生成多种思路、评估其前景、并通过搜索算法进行前瞻与回溯的机制,从而在数学推理、创意写作等需要战略规划的任务中取得质的飞跃。 ReAct 则通过交织“推理”与“行
大模型知识渊博,却时常“有知识,欠智慧”。传统的推理方式如同单线程的直线,限制了其解决复杂问题的潜力。
Tree of Thoughts (ToT) 与 ReAct 框架的诞生,标志着大模型推理范式的一次根本性转向:
ToT 将“线性链”升级为“决策树”,赋予模型战略规划与多路径探索的能力;
ReAct 则构建了“推理”与“行动”的飞轮,让模型能在与现实世界的交互中动态思考与学习。
目录
1. Tree of Thoughts ToT 思维树(思维链的优化)
1. Tree of Thoughts ToT 思维树(思维链的优化)
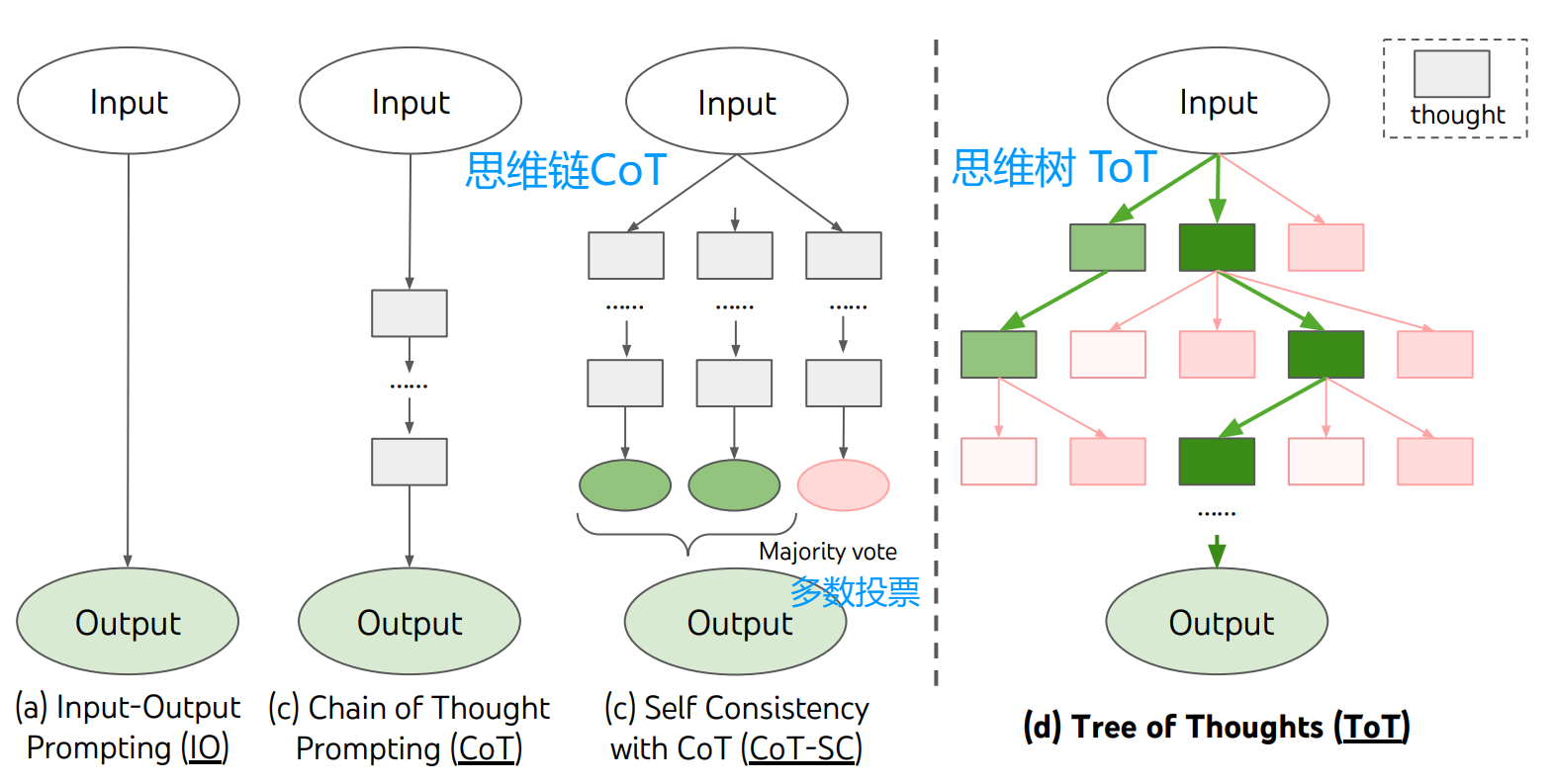
传统 LLM 包括思维链CoT痛点:自回归文本生成机制—— 即逐一词元、从左到右地做出决策。
这意味着在需要探索、策略性前瞻,或初始决策起关键作用的任务中,语言模型可能表现不佳。
考虑多条不同的推理路径、自我评估选择以确定下一步行动,并在必要时前瞻或回溯以做出全局决策。
实验:24 点游戏、创意写作、填字游戏。
A genuine problem-solving process involves the repeated use of available information to initiate exploration, which discloses, in turn, more information until a way to attain the solution is finally discovered.—— Newell
真正的问题解决过程,涉及反复利用已有信息启动探索,而探索又会揭示更多信息,
直至最终找到达成解决方案的路径。(探索 + 获取信息 交替)
现有语言模型通用问题解决方法的两大核心缺陷:
- 局部层面:未探索思维过程中的不同延续路径 —— 即树的分支;
- 全局层面:未融入任何规划、前瞻或回溯机制来评估这些不同选项。
1.1 四大步骤
1. 思维分解:一个 “思维” 需满足:
- 足够 “小”,使语言模型能生成有前景且多样的样本(比如一本书 就太多太难生成了)
- 足够 “大”,使语言模型能评估其对问题解决的进展(比如一个词 就太短没区分度)
2. 思维生成:
若思维空间维度大(像写作),k次独立同分布采样(调用k次) 确保候选思维的多样性。
若思维空间维度小(像24点),k个不同的方案 (调用1次)防止重复 尽量包含所有可能。
3. State Evaluator 状态评估器 V
“评估状态对最终解决问题的‘前景’” —— 即 “从当前状态出发,后续步骤能成功找到答案的概率。
无需绝对准确,只需 “相对有效”(能区分优质 / 劣质状态)为搜索算法提供导航。
通过推理状态 s 生成标量值 v(如 1-10 分);
策略 (a):独立评估每个状态
快速往后模拟1-2步,验证其潜力;
利用领域知识(比如算24点 状态(1,2,3)的数字太小)
策略 (b):在状态间进行投票
当问题的“成功”标准非常抽象、难以直接量化时(例如,评估一段文本的“连贯性”)
直接比较哪个更好,比给每个单独打分更容易。(可以给最佳状态打 1 分,其余都 0 分)
4. 搜索算法(Search Algorithm)
BFS 和 DFS(也可以模块化地 使用其他搜索算法)

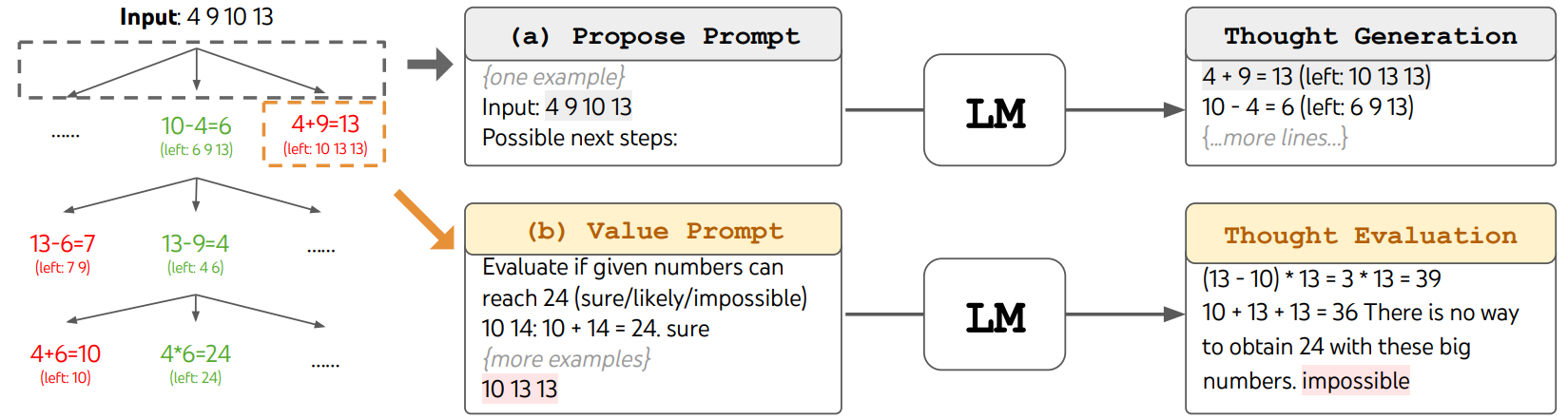
1.2 两组实验
24点例:
(左)思维生成 (右)状态评估
创意写作例:
-
输入:4个随机句子
-
输出:一个连贯的段落,包含4个段落,分别以4个输入句子结尾
-
特点:开放性强、探索性高,需要创造性思维和高层次规划
先写若干个思路,票数最高的思路,实现成段落

双重评估体系
1. GPT-4自动评分:使用零样本提示给出1-10分的连贯性评分
每个任务输出采样5个分数取平均 分数一致性高(标准差约0.56)
2. 人工盲审对比:作者团队在100个输入上对比CoT vs ToT的输出
随机调换段落顺序以避免偏见
(ToT需要更多资源,对于LLM已经表现很好的许多现有任务,ToT可能不是必需的。)
2. ReAct 推理 + 行动
-
核心问题:当前LLMs的研究将“思考”(推理)和“动手”(行动)分开了。
-
解决方案:提出 ReAct 范式,让模型在解决问题时,边想边做,边做边想。
-
当模型不确定时,它可以去“查资料”(调用Wikipedia API),用事实证据来支撑推理,减少了胡说八道。
(a) 标准形 IO (b) CoT只推理 (c) 只行动 (d) ReAct 推理+行动
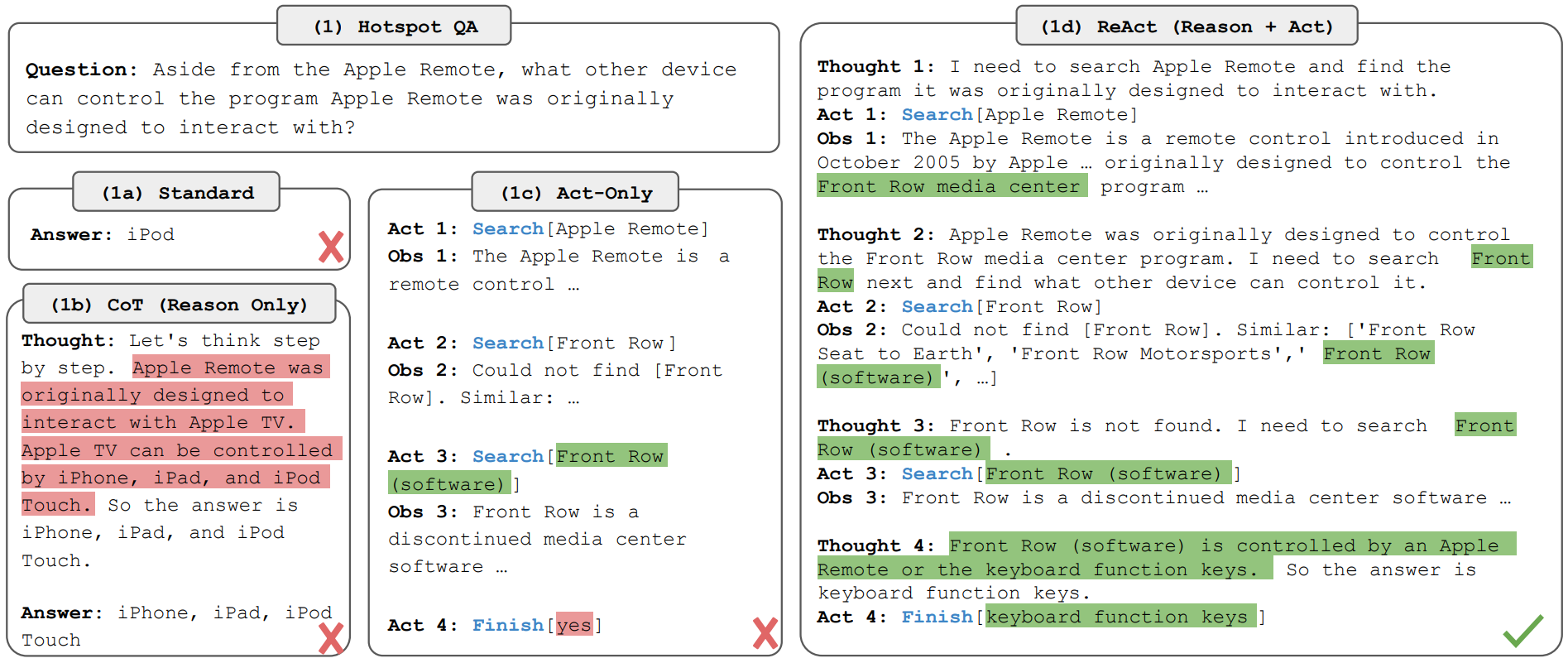
2.1 简要原理
智能体 - 环境交互的 “观测obs - 动作a - 上下文c”
核心问题:复杂任务中 ct→at 的映射隐式且需推理,传统策略学习失效;
原始动作空间 A:领域特定动作 ; 需要变成 ct -> 中间推理 -> at;
创新:新增语言空间 L:自然语言构成的 “推理轨迹(reasoning trace)” 或 “思考(thought)”;
思考与动作的区别:无环境交互 -- 执行思考动作时,环境不会产生新的观测 obs。
- 推理功能:基于当前上下文 ct 进行推理(如分解任务、提取信息、验证事实)整合有用信息;
- 上下文传递:将思考结果 ât 加入原上下文,生成新上下文 ct+1 = (ct, ât)—— 使得后续动作(无论是思考还是领域动作)都能基于 “原始轨迹 + 中间推理” 进行决策,解决了传统方法 “跳过中间推理” 的问题。
2.2 实现方法
语言空间 L 是无限的,依赖强大的语言先验知识,必须借助大语言模型(LLM)的预训练语言能力。
LLM 需同时生成两种动作:①领域特定动作(A);②自由形式的语言思考(L)。
1. 对于推理主导性任务(如事实核查):
强制 “思考 - 动作” 交替生成:轨迹结构为观测→思考→动作→观测→思考→动作→...
交替模式能确保每一步动作都有推理支撑,避免跳过关键逻辑。
2. 动作密集型决策任务(如游戏):
稀疏思考生成:不强制交替,让 LLM 自主决定何时生成思考、何时生成动作;
很多动作是机械性的,无需推理。仅在关键节点(如决策分支、信息缺失时)需要思考,稀疏模式能提高效率。
2.3 实验
两个问题:
-
HotpotQA: 多跳问答。需要模型串联多个维基百科文档中的信息才能找到答案。
-
FEVER: 事实核查。需要模型根据维基百科证据判断一个陈述是“支持”、“反驳”还是“信息不足”。
设计了一个简化的维基百科API,包含三个核心操作:
-
search[entity]: 搜索实体,返回摘要或相似实体建议。 -
lookup[string]: 在页面内查找包含特定字符串的下一句话(模拟Ctrl+F)。 -
finish[answer]: 提交最终答案。
思考的范例:
-
任务分解(“我需要先搜索X,再找Y”)
-
信息提取(“这段提到X成立于1844年”)
-
常识/数学推理(“1844 < 1989”)
-
搜索策略调整(“也许我应该换搜X试试”)
-
答案合成(“所以答案是X”)
ReAct:极大改善CoT的幻觉问题。得益于外部知识库的 grounding,它的推理轨迹更可信。
但由于被“思考-行动-观察”的结构所约束,推理灵活性相比CoT下降(容易出现循环)
SC 指 self-consistency 投票自洽性;根据上者优缺点,结合CoT-SC 和 ReAct。
-
ReAct → CoT-SC: 当ReAct在限定步数内找不到答案时,回退到使用CoT-SC来依靠内部知识给出答案。
-
CoT-SC → ReAct: CoT-SC结果显示内部知识不一致、信心不足时(例如,多个推理路径得出的答案不统一),回退到ReAct去外部检索信息。
-
ReAct微调: 让模型学习“如何获取知识”的技能。这是一种更通用、更可迁移的能力。
-
如果能有更多高质量的人类标注的“思-行”轨迹数据,ReAct模式的潜力将会被进一步释放。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)