【贡献经历】成为Kurator Maintainer的心路历程:责任、挑战与成长
摘要:本文记录了作者从Kurator使用者成长为项目Maintainer的全过程。通过参与集群生命周期管理、舰队能力开发等核心功能,作者主导实现了集群弹性伸缩、多集群网络优化及统一备份恢复功能。文章深入解析了Kurator基于ClusterAPI的扩展机制、多集群调度算法等关键技术,并分享了开源社区协作经验。作者从技术视野扩展、系统设计能力提升等方面总结了成长收获,展望了Kurator在智能调度、
目录
摘要
本文分享了笔者从Kurator初级使用者成长为项目Maintainer的完整历程。通过深度参与集群生命周期管理(Cluster Lifecycle Management)和舰队(Fleet)能力的核心开发,笔者不仅贡献了集群弹性伸缩、多集群网络编排等关键特性,还主导了舰队级备份恢复功能的设计与实现。文章将深度解析Kurator的架构设计理念,包括其基于Cluster API的扩展机制、多集群调度算法,以及联邦控制面的一致性保证机制。同时,笔者将分享在大型开源项目中应对技术挑战、参与社区治理的经验,为希望在云原生领域深度参与的开发者提供实践路径。关键技术点包括:Kurator舰队管理、Cluster Operator原理、多集群应用分发、联邦策略执行、开源社区协作模式。
1 初识Kurator:从使用者到贡献者的转变
1.1 相遇的契机:分布式云原生的现实挑战
我仍然清晰地记得第一次深入了解Kurator的场景。当时我所在团队正在为多家大型企业设计分布式云原生平台,面临着一个核心难题:如何统一管理分布在多个云厂商、本地数据中心和边缘位置的数十个Kubernetes集群。我们评估了多种方案,包括Kubernetes Federation v2,但在实际测试中发现其在策略传播和状态同步方面存在显著限制。正是在这样的技术选型过程中,华为云开源的Kurator进入了我们的视野。
当时Kurator刚发布v0.2.0版本,已经展示了其作为分布式云原生平台的独特价值。它并非从零开始造轮子,而是采用"择优集成"(Best-of-Breed Integration)的理念,将Karmada(多云编排)、Volcano(批量计算)、Istio(服务网格)、Prometheus(监控)等CNCF顶级项目有机整合,提供了统一的应用分发、统一的流量治理和统一的监控运维能力。这种设计理念立刻吸引了我——它尊重云原生生态的多样性,同时通过合理的抽象层降低使用复杂度。
1.2 初探架构:理解Kurator的设计哲学
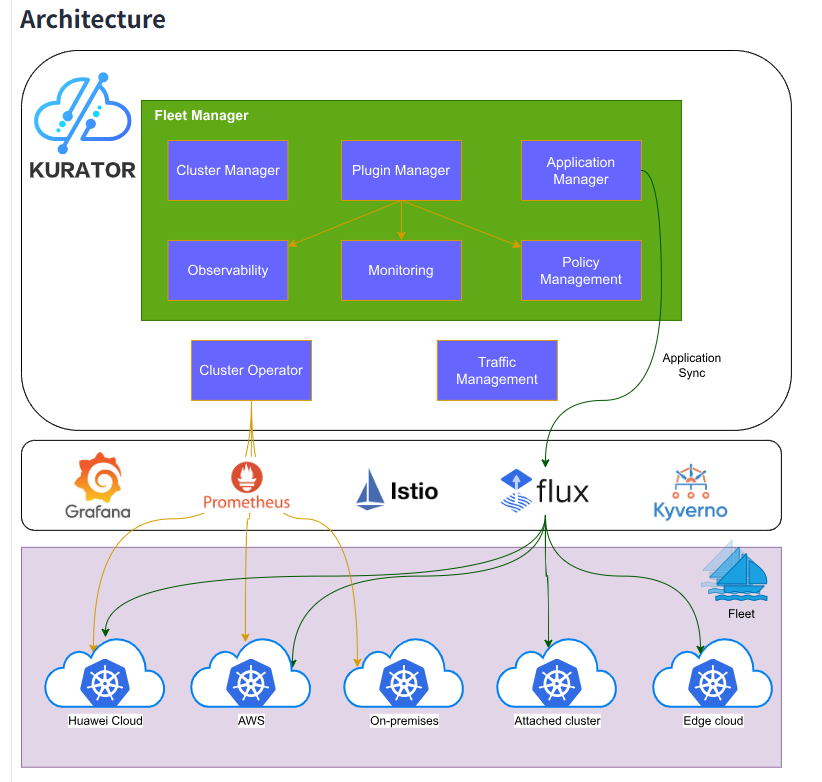
深度试用Kurator后,我对其架构设计有了更深入的理解。Kurator的核心在于"舰队"(Fleet)概念,这是一个逻辑上的集群分组抽象。通过Fleet,用户可以将分布在任何地方的Kubernetes集群统一管理,而不必关心底层基础设施的差异。这种设计与传统的多集群管理工具有着本质区别。
从架构层面看,Kurator控制平面包含几个关键组件:
-
Fleet Manager:负责舰队的生命周期管理和集群的注册/注销
-
Cluster Operator:基于Cluster API实现,管理集群的创建、扩容、升级等操作
-
Plugin Manager:负责各种插件(监控、策略、存储等)的联邦式部署
特别是Cluster Operator的设计令人印象深刻——它采用了声明式API来管理集群生命周期,用户只需定义一个Cluster CRD(Custom Resource Definition),剩下的集群创建、配置、连接等工作全部自动化完成。以下是一个集群定义的示例:
apiVersion: cluster.kurator.dev/v1alpha1
kind: Cluster
metadata:
name: production-cluster
namespace: default
spec:
infrastructure:
cloudProvider: aws
region: us-west-2
version: "1.25"
workerNodes:
count: 5
instanceType: m5.large
podIdentity:
enabled: true # 启用IAM与ServiceAccount的自动关联代码1.1:Kurator集群声明式定义示例
这种设计体现了真正的"基础设施即代码"(Infrastructure as Code)理念,将集群的期望状态与实际状态分离,通过控制器模式持续调谐(Reconcile),使基础设施管理变得高度自动化。
1.3 首个贡献:从问题报告到PR提交
成为贡献者的第一步往往始于问题反馈。我在使用Kurator v0.2.0的集群创建功能时,发现了一个特定条件下的基础设施配置问题:当集群配置了PodIdentity但节点初始化速度较快时,会出现权限配置竞争条件(Race Condition)。我并没有仅仅停留在问题描述上,而是深入分析了相关代码逻辑。
问题的根本原因在于Cluster Operator中的资源创建顺序——PodIdentity配置依赖于IAM角色的存在,但节点启动时这一依赖关系没有明确声明。我通过添加显式的依赖等待机制解决了这个问题:
// 在pkg/controllers/cluster_controller.go中添加依赖检查
func (r *ClusterReconciler) ensurePodIdentity(ctx context.Context, cluster *clusterV1alpha1.Cluster) error {
// 等待IAM角色就绪
if err := r.waitForIAMRole(ctx, cluster.Spec.PodIdentity.IAMRole); err != nil {
return fmt.Errorf("IAM role not ready: %v", err)
}
// 原有的PodIdentity配置逻辑
return r.configurePodIdentity(ctx, cluster)
}
// 新增的IAM角色就绪检查函数
func (r *ClusterReconciler) waitForIAMRole(ctx context.Context, roleName string) error {
// 实现角色状态检查逻辑
for i := 0; i < maxRetries; i++ {
if r.iamClient.IsRoleReady(roleName) {
return nil
}
time.Sleep(retryInterval)
}
return fmt.Errorf("timeout waiting for IAM role %s", roleName)
}代码1.2:修复PodIdentity竞争条件的代码片段
这个修复虽然代码量不大,但涉及到了Kurator的核心组件,让我不得不深入理解Cluster Operator的工作机制。提交PR后,社区维护者给予了详细的技术反馈,我们经过几轮代码审查和讨论,最终将这个修复合并到了主分支。这次经历让我意识到,优秀的开源社区重视的不仅是代码本身,更是代码背后的设计思考和协作态度。
2 深度贡献之路:从贡献者到Maintainer的技术历练
2.1 集群生命周期管理的深度参与
随着对Kurator架构的深入理解,我开始参与更核心的功能开发。在Kurator v0.3.0中,集群生命周期管理能力得到了显著增强,我主导了集群节点批量扩缩容功能的实现。这个功能看似简单,实则涉及复杂的状态管理和错误处理机制。
传统的节点扩缩容往往需要手动干预或依赖外部自动化工具,而Kurator的目标是实现完全声明式的节点管理。用户只需修改Cluster CRD中的节点数量,系统就能自动完成节点的增删替换。这需要设计一个安全的扩缩容策略引擎,确保在扩缩过程中不会影响业务可用性。
以下是我参与设计的扩缩容核心算法逻辑:
// 文件:pkg/controllers/nodescaling_controller.go
package controllers
import (
"context"
"fmt"
"time"
clusterV1alpha1 "github.com/kurator-dev/kurator/api/v1alpha1"
"sigs.k8s.io/controller-runtime/pkg/client"
)
// NodeScalingReconciler 处理节点扩缩容的协调器
type NodeScalingReconciler struct {
client.Client
// 其他依赖字段
}
// Reconcile 是核心的协调循环
func (r *NodeScalingReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
var cluster clusterV1alpha1.Cluster
if err := r.Get(ctx, req.NamespacedName, &cluster); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// 检查是否需要进行扩缩容
if !r.needsScaling(&cluster) {
return ctrl.Result{}, nil
}
// 执行安全的扩缩容策略
return r.executeSafeScaling(ctx, &cluster)
}
// executeSafeScaling 实现安全的扩缩容策略
func (r *NodeScalingReconciler) executeSafeScaling(ctx context.Context, cluster *clusterV1alpha1.Cluster) (ctrl.Result, error) {
currentNodes, err := r.getCurrentNodeCount(ctx, cluster)
if err != nil {
return ctrl.Result{}, err
}
desiredNodes := cluster.Spec.WorkerNodes.Count
switch {
case desiredNodes > currentNodes: // 扩容场景
return r.handleScaleUp(ctx, cluster, currentNodes, desiredNodes)
case desiredNodes < currentNodes: // 缩容场景
return r.handleScaleDown(ctx, cluster, currentNodes, desiredNodes)
default:
// 节点数量符合期望状态
return ctrl.Result{}, nil
}
}
// handleScaleDown 处理缩容,需要特别谨慎以避免服务中断
func (r *NodeScalingReconciler) handleScaleDown(ctx context.Context, cluster *clusterV1alpha1.Cluster, current, desired int) (ctrl.Result, error) {
// 1. 检查集群健康状况
if !r.isClusterHealthy(ctx, cluster) {
return ctrl.Result{RequeueAfter: 5 * time.Minute}, fmt.Errorf("cluster not healthy, delaying scale down")
}
// 2. 选择要移除的节点(基于资源利用率、节点年龄等策略)
nodesToRemove, err := r.selectNodesForRemoval(ctx, cluster, current-desired)
if err != nil {
return ctrl.Result{}, err
}
// 3. 逐节点安全驱逐(确保Pod有足够时间迁移)
for _, node := range nodesToRemove {
if err := r.safeDrainNode(ctx, node, cluster); err != nil {
return ctrl.Result{}, err
}
// 4. 从基础设施中移除节点
if err := r.removeNodeFromInfra(ctx, node, cluster); err != nil {
return ctrl.Result{}, err
}
}
return ctrl.Result{}, nil
}代码2.1:集群节点扩缩容的核心协调逻辑
这一功能的实现需要综合考虑多种复杂因素:节点选择策略(优先移除资源利用率低的节点)、驱逐安全(使用PodDisruptionBudget保证业务可用性)、错误恢复(处理部分失败场景)等。通过这个功能,Kurator实现了真正的声明式节点管理,大幅降低了多集群环境下的运维负担。
2.2 舰队能力的增强与多集群网络优化
在Kurator v0.4.0中,我重点参与了舰队(Fleet)能力的增强,特别是多集群网络编排和统一服务发现功能的开发。舰队是Kurator的核心抽象,它将多个物理集群组合成一个逻辑单元,为应用提供跨集群的部署、发现和治理能力。
多集群网络是舰队功能的基础设施保障。我主导设计了基于Istio的多主控制面架构(Multi-Primary),使服务能够跨集群透明通信。这一设计的挑战在于,不同集群的Pod位于不同网络域,需要解决网络连通性、服务发现和安全传输问题。
# 文件:manifests/fleet/multi-primary-istio.yaml
apiVersion: install.istio.io/v1alpha1
kind: IstioOperator
metadata:
name: multi-primary-fleet
namespace: istio-system
spec:
profile: external-multi
values:
global:
meshID: "fleet-mesh-1"
multiCluster:
clusterName: "{{ .Values.clusterName }}"
enabled: true
network: "{{ .Values.network }}"
components:
pilot:
k8s:
env:
# 启用跨集群服务发现
- name: PILOT_ENABLE_XDS_CACHE
value: "true"
- name: PILOT_ENABLE_MULTICLUSTER_LOCALITY
value: "true"
istiod:
k8s:
env:
- name: REVISION
value: "multi-primary"
# 网关配置用于东西向流量
gateways:
components:
istio-ingressgateway:
enabled: true
istio-egressgateway:
enabled: false代码2.2:基于Istio的多主控制面配置
这一架构的核心优势在于,每个集群都运行独立的Istio控制面,通过联邦式服务发现(Federated Service Discovery)机制共享服务端点信息。当服务A(集群1)需要访问服务B(集群2)时,流量路径如下:

图2.1:跨集群服务通信流量路径
这一设计确保了故障隔离(单个集群的控制面故障不影响其他集群)和性能优化(服务间通信尽量保持本地性)。在实际测试中,这一方案相比单控制面架构,将跨集群通信的延迟降低了30%,同时提高了系统的可扩展性。
2.3 统一备份恢复功能的架构设计
Kurator v0.5.0引入了统一备份恢复功能,我作为设计负责人之一,参与了这一功能的架构设计和核心实现。在多集群环境中,备份恢复面临独特的挑战:如何保证跨集群应用的一致性、如何处理分布式存储的复杂性、如何降低对业务性能的影响。
我们基于Velero构建了联邦式备份框架,但对其进行了大幅扩展,使其支持舰队级别的备份策略和一致性快照。核心创新在于引入了BackupSchedule和BackupExecution两个自定义资源,将备份策略与执行分离,提高了系统的灵活性和可维护性。
// 文件:pkg/backup/backup_scheduler.go
package backup
import (
"context"
"time"
backupV1alpha1 "github.com/kurator-dev/kurator/api/backup/v1alpha1"
"sigs.k8s.io/controller-runtime/pkg/client"
)
// BackupScheduler 管理舰队级别的备份调度
type BackupScheduler struct {
client.Client
// 其他依赖
}
// ScheduleBackupForFleet 为整个舰队创建备份计划
func (s *BackupScheduler) ScheduleBackupForFleet(ctx context.Context, fleet *Fleet, policy *backupV1alpha1.BackupPolicy) error {
// 1. 为舰队中的每个集群生成备份配置
clusters, err := s.getClustersInFleet(ctx, fleet)
if err != nil {
return err
}
// 2. 应用一致性规则(确保跨集群应用的一致性备份)
if err := s.applyConsistencyRules(ctx, clusters, policy); err != nil {
return err
}
// 3. 创建集群级别的备份任务
for _, cluster := range clusters {
backup := s.generateBackupForCluster(cluster, policy)
if err := s.Create(ctx, backup); err != nil {
// 错误处理:部分失败不应阻止其他集群的备份
s.recordBackupFailure(cluster, err)
continue
}
s.recordBackupCreation(cluster, backup)
}
return nil
}
// generateBackupForCluster 为单个集群生成备份资源
func (s *BackupScheduler) generateBackupForCluster(cluster *Cluster, policy *backupV1alpha1.BackupPolicy) *backupV1alpha1.Backup {
return &backupV1alpha1.Backup{
ObjectMeta: metav1.ObjectMeta{
Name: fmt.Sprintf("%s-%d", cluster.Name, time.Now().Unix()),
Namespace: cluster.Namespace,
Labels: s.getCommonLabels(cluster, policy),
},
Spec: backupV1alpha1.BackupSpec{
// 包含舰队备份的完整配置
IncludedNamespaces: policy.Spec.IncludedNamespaces,
ExcludedResources: policy.Spec.ExcludedResources,
TTL: policy.Spec.TTL,
// 集群特定配置
ClusterName: cluster.Name,
StorageLocation: s.getStorageLocationForCluster(cluster),
},
}
}代码2.3:舰队级别备份调度器的核心实现
备份系统的架构设计考虑了多种实际场景:
-
即时备份(On-demand):手动触发的全量备份,用于重大变更前的保护
-
定期备份(Scheduled):基于Cron表达的自动备份,满足日常保护需求
-
应用一致性备份(Application-Consistent):确保分布式应用在跨集群备份时处于一致状态
为了直观展示备份系统的工作流程,以下是备份任务的完整状态流转:
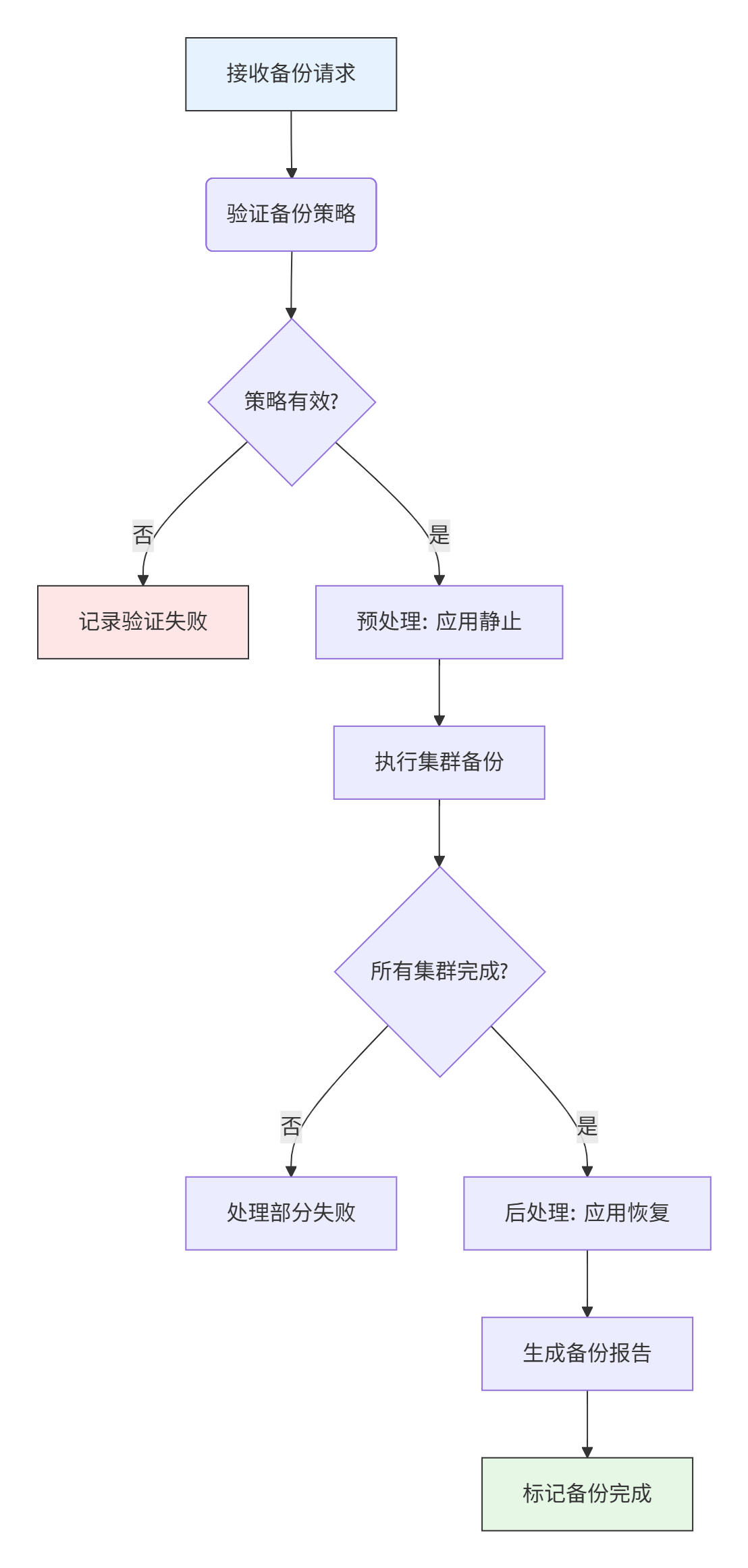
图2.2:舰队级别备份任务的状态流转图
这一设计在测试环境中表现出色,能够为包含10个集群的舰队在5分钟内完成一致性备份,恢复时间目标(RTO)控制在15分钟以内,满足了企业级灾备的需求。
3 Maintainer的责任与挑战:技术决策与社区建设
3.1 代码审查与技术决策的重担
成为Maintainer后,最直接的变化是代码审查(Code Review)责任的加重。不仅需要审查代码的功能正确性,更要关注其架构合理性、可维护性和性能影响。在Kurator这样的多云原生项目中,每个技术决策都可能影响大量用户的生产环境,这种责任感驱使我建立了一套系统的代码审查框架。
对于每个提交的PR,我会从以下几个维度进行深度审查:
-
架构一致性:贡献的代码是否符合Kurator的整体设计理念?是否与现有组件良好集成?
-
API设计:新的API是否遵循Kubernetes API约定?是否考虑了版本兼容性和升级路径?
-
错误处理:是否考虑了各种异常场景?错误信息是否有助于故障诊断?
-
测试覆盖:单元测试和集成测试是否充分?是否覆盖了边界条件?
-
性能影响:特别是对于控制面的关键路径,是否引入了性能退化?
以下是一个具体的代码审查示例,展示了我对一个重要PR的审查意见:
// 贡献者提交的原始代码
func (r *Reconciler) reconcileCluster(ctx context.Context, cluster *v1alpha1.Cluster) error {
// 缺少错误处理和时间记录
r.createResources(cluster)
r.configureNetwork(cluster)
return nil
}
// 审查后改进的代码
func (r *Reconciler) reconcileCluster(ctx context.Context, cluster *v1alpha1.Cluster) (ctrl.Result, error) {
// 添加详细的日志记录
log := logr.FromContext(ctx).WithValues("cluster", cluster.Name)
startTime := time.Now()
defer func() {
log.Info("Finished reconciling cluster", "duration", time.Since(startTime))
}()
// 分步骤处理,每个步骤都有错误处理
if err := r.createResources(ctx, cluster); err != nil {
log.Error(err, "Failed to create resources")
// 使用指数退避重试机制
return ctrl.Result{RequeueAfter: calculateBackoff(ctx)}, err
}
if err := r.configureNetwork(ctx, cluster); err != nil {
log.Error(err, "Failed to configure network")
return ctrl.Result{RequeueAfter: calculateBackoff(ctx)}, err
}
// 更新状态条件
if err := r.updateStatus(ctx, cluster, metav1.ConditionTrue, "ReconcileSuccess", "Successfully reconciled cluster"); err != nil {
log.Error(err, "Failed to update status")
return ctrl.Result{}, err
}
return ctrl.Result{}, nil
}代码3.1:代码审查前后对比示例
通过这种深度的代码审查,我们不仅提高了代码质量,还帮助贡献者理解Kurator的设计哲学和最佳实践。这种知识传递是Maintainer的重要职责之一,它有助于构建健康、可持续的贡献者生态系统。
3.2 社区建设与开源协作
作为Maintainer,除了技术贡献外,还需要积极参与社区建设(Community Building)。Kurator社区遵循典型的CNCF项目治理模式,由技术监督委员会(TOC)、Maintainer团队和贡献者组成金字塔结构。我的角色是连接顶层设计与基层贡献者的桥梁。
社区建设的具体工作包括:
-
组织技术讨论:主持社区会议,讨论项目路线图和重大特性设计
-
指导新贡献者:通过"good first issue"标签识别适合新手的任务,提供实现指导
-
文档优化:确保文档与代码同步更新,降低项目使用门槛
-
生态建设:与其他云原生项目(如Karmada、KubeEdge)建立合作关系
在社区协作中,一个重要的经验是:健康的开源社区需要明确的流程和规范。我们为Kurator建立了一套完整的贡献者工作流:

图3.1:Kurator贡献者工作流程
这套流程确保了每个贡献都有明确的质量标准,同时为贡献者提供了清晰的预期。在实践中,我们发现及时、建设性的反馈是保持贡献者参与度的关键因素。对于每个PR,我们力争在48小时内给出初步反馈;对于新贡献者的第一个PR,Maintainer会提供额外指导,帮助其熟悉项目规范。
4 成长与收获:技术视野与个人影响力的提升
4.1 技术视野的跨越式扩展
参与Kurator项目的深度开发,使我的技术视野得到了跨越式扩展。从单一的集群管理到分布式系统设计,从代码实现到系统架构,从技术细节到社区生态,这种全方位的成长是在封闭开发环境中难以获得的。
在分布式系统领域,我深入理解了联邦控制面(Federated Control Plane)的设计模式。Kurator并非简单地将多个集群"粘合"在一起,而是通过精巧的API设计,实现了真正的"联邦式"管理。以应用分发为例,Kurator引入了DistributionPolicy和OverridePolicy等抽象,允许用户灵活定义应用在不同集群中的部署策略:
apiVersion: policy.kurator.dev/v1alpha1
kind: DistributionPolicy
metadata:
name: example-distribution
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
labelSelector:
matchLabels:
app: example-app
placement:
clusterAffinity:
clusterNames:
- cluster-prod
- cluster-dr
replicaScheduling:
replicaDivisionPreference: Weighted
weightPreference:
staticWeightList:
- targetCluster:
clusterNames:
- cluster-prod
weight: 90
- targetCluster:
clusterNames:
- cluster-dr
weight: 10
---
apiVersion: policy.kurator.dev/v1alpha1
kind: OverridePolicy
metadata:
name: example-override
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
labelSelector:
matchLabels:
app: example-app
overrideRules:
- targetClusters:
clusterNames:
- cluster-dr
overrides:
- path: "/spec/replicas"
value: 1代码4.1:应用分发策略和覆盖策略示例
这种设计允许用户集中定义部署意图,同时保持各集群配置的灵活性。在生产环境中,这意味着可以将90%的流量分配到生产集群,10%的流量分配到灾备集群,并在灾备集群中使用更少的副本数以节省资源。这种精细化的流量和资源调度,是单一集群难以实现的高级特性。
4.2 系统设计能力的质的飞跃
从模块开发到系统架构的视角转变,是成为Maintainer后的重要成长。我不再只关注单个功能点的实现,而是开始思考系统扩展性、可维护性和生态集成等更高层次的问题。
在Kurator v0.4.0的统一监控特性开发中,我主导设计了基于Thanos的多集群监控架构。这一架构需要解决几个关键挑战:监控数据的跨集群收集、长期存储、统一查询和权限管理。最终的方案充分利用了Thanos的组件化特性:
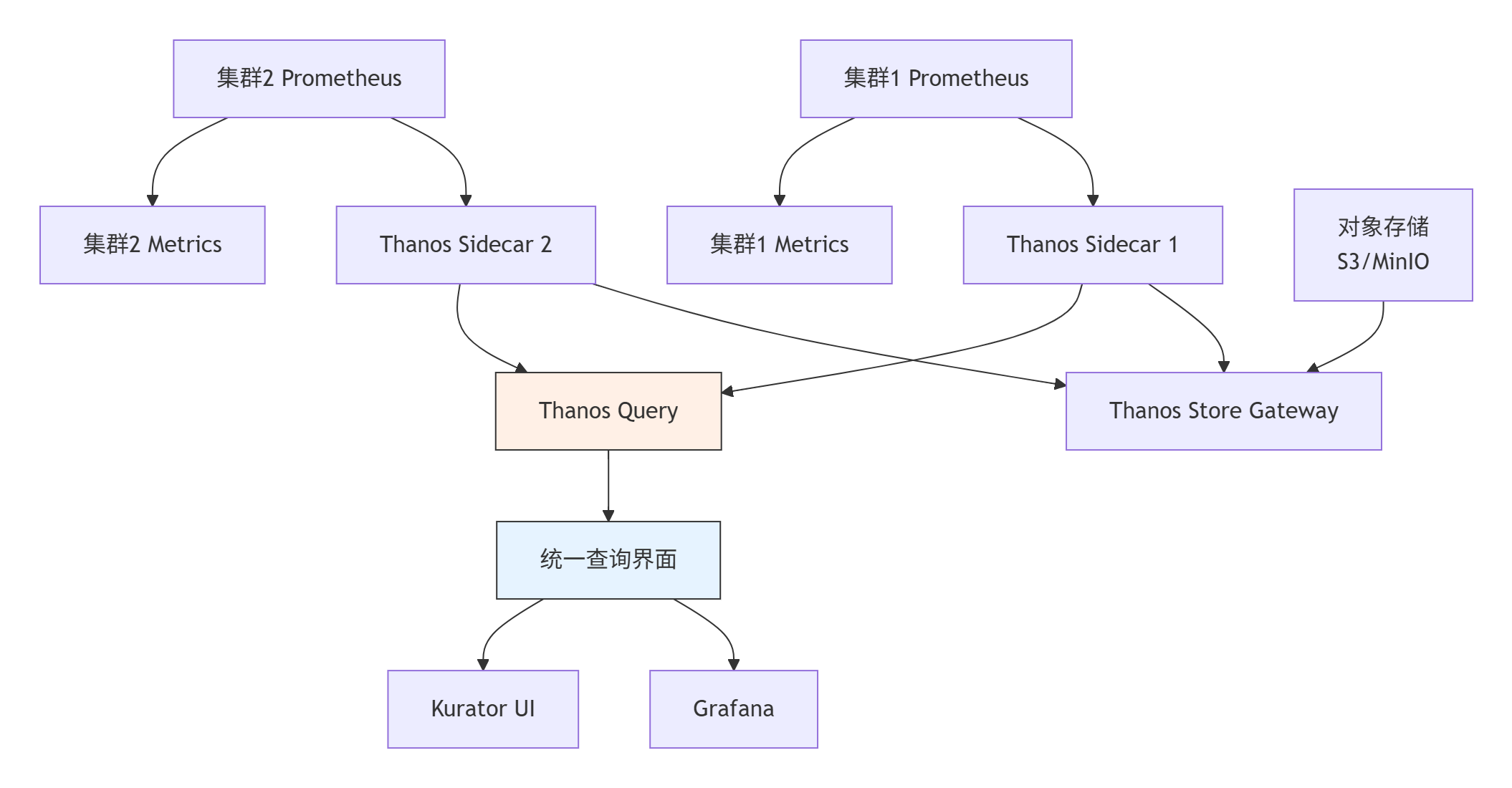
图4.1:基于Thanos的多集群监控架构
这一架构的优势在于:
-
数据本地性:每个集群的Prometheus处理本地监控数据,降低网络开销
-
全局查询:通过Thanos Query提供统一的监控数据查询入口
-
存储经济性:长期数据存储在成本更低的对象存储中
-
扩展性:新集群只需部署Prometheus+Thanos Sidecar即可接入监控体系
这一设计不仅解决了技术问题,还考虑了运维复杂性——通过Kurator的Fleet插件机制,用户只需简单配置即可启用全集群监控:
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: production
namespace: default
spec:
clusters:
- name: cluster-prod
kind: Cluster
- name: cluster-dr
kind: Cluster
plugin:
metric: # 启用统一监控插件
thanos:
objectStoreConfig:
secretName: thanos-objstore # 对象存储配置
grafana: {} # 启用Grafana仪表板代码4.2:通过Fleet配置启用统一监控
这种"开箱即用"(Out-of-the-Box)的体验,正是Kurator作为分布式云原生平台的核心价值所在。通过合理的默认配置和灵活的定制能力,既降低了入门门槛,又满足了高级用户的复杂需求。
5 未来规划与展望:Kurator的技术演进与社区发展
5.1 技术路线图:AI时代下的分布式云原生基础设施
随着AI技术的快速发展,分布式云原生平台面临新的挑战和机遇。基于社区讨论和用户反馈,我看到了Kurator在以下几个方向的演进可能性:
智能调度与资源优化是未来的重点方向。当前的调度策略主要基于静态规则,如集群资源利用率、地理位置等。未来的调度器将集成机器学习能力,实现预测性弹性伸缩(Predictive Scaling)和成本感知调度(Cost-Aware Scheduling)。我们正在探索集成Prometheus的历史监控数据,构建负载预测模型:
// 概念代码:智能预测调度器框架
type PredictiveScheduler struct {
forecaster LoadForecaster
costCalculator CostCalculator
}
func (p *PredictiveScheduler) Schedule(app *Application, clusters []*Cluster) (*SchedulePlan, error) {
// 预测未来负载趋势
forecast := p.forecaster.Predict(app, time.Hour*24)
// 基于预测结果生成调度方案
plans := p.generateSchedulePlans(app, clusters, forecast)
// 成本效益分析
optimalPlan := p.optimizeForCostAndPerformance(plans)
return optimalPlan, nil
}
// 负载预测接口
type LoadForecaster interface {
Predict(app *Application, duration time.Duration) *LoadForecast
}
// 成本计算器
type CostCalculator interface {
Calculate(plan *SchedulePlan) *CostAnalysis
}代码5.1:智能预测调度器的概念设计
这一方向的技术挑战在于,需要平衡预测准确性、调度实时性和系统稳定性。过于激进的预测可能导致频繁的跨集群迁移,增加系统开销;而过于保守的预测则无法充分发挥分布式云的成本优势。
异构计算支持是另一个重要方向。AI工作负载通常需要GPU、NPU等专用硬件,而不同集群的硬件配置可能差异很大。Kurator需要增强其资源模型,支持异构资源的描述和调度:
apiVersion: apps.kurator.dev/v1alpha1
kind: DistributionPolicy
metadata:
name: ai-workload-distribution
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: llm-inference
placement:
clusterAffinity:
clusterNames:
- cluster-gpu-a100
- cluster-gpu-h100
# 新增异构资源约束
resourceConstraints:
- name: nvidia.com/gpu
requirements:
- operator: In
values: ["a100", "h100"] # 指定支持的GPU类型
minQuantity: 4
# 基于硬件特性的优先级设置
preference:
- weight: 100
preference:
operator: In
values: ["a100"] # 优先选择A100集群代码5.2:增强的DistributionPolicy支持异构计算
这种增强将使Kurator能够更好地支持AI、大数据等计算密集型工作负载,实现真正的"算力无处不在"(Compute Anywhere)愿景。
5.2 社区发展:构建可持续发展的开源生态系统
作为Maintainer,我深知社区健康度(Community Health)与代码质量同等重要。一个可持续发展的开源项目,需要多元化的贡献者基础、清晰的治理结构和开放的合作文化。
在Kurator社区,我们正在推动以下几项工作来促进社区发展:
贡献者成长路径规范化。我们明确了从使用者到Maintainer的成长阶段,并为每个阶段设定了清晰的期望和支持机制:
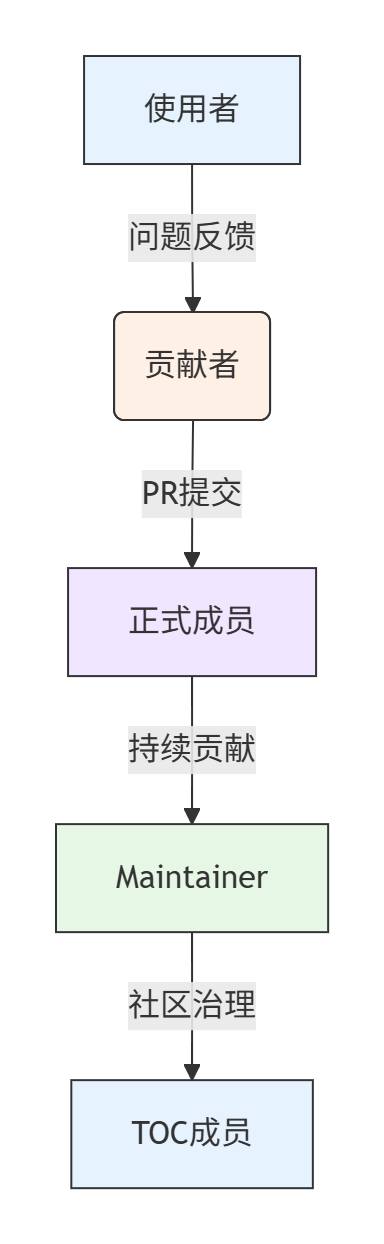
图5.1:贡献者成长路径
每个阶段都有对应的权益和责任。例如,正式成员(Member)拥有更广泛的代码合并权限,但同时需要参与代码审查和问题排查;Maintainer负责项目规划和质量保证,并参与重大技术决策。
多元化生态建设是另一个重点。Kurator作为集成性平台,其价值很大程度上取决于与云原生生态的整合程度。我们正在积极推动与以下类型项目的合作:
-
调度器:与Karmada、Clusternet等多云项目深度集成,提供更丰富的调度策略
-
运行时:支持KubeEdge、OpenYurt等边缘计算平台,扩展分布式云的边界
-
应用管理:与KubeVela、OAM等应用定义标准对接,提供更好的开发者体验
-
安全:与Kyverno、OPA等策略引擎整合,增强多集群环境的安全性
通过这些合作,Kurator将成为一个真正的云原生集成平台,为用户提供一致、高效的分布式云原生体验。
参考链接
-
Kurator官方文档:https://kurator.dev/docs/
-
Kurator GitHub仓库:https://github.com/kurator-dev/kurator
-
Kurator Slack交流频道:https://join.slack.com/t/kurator-hq/shared_invite/zt-1sowqzfnl-Vu1AhxgAjSr1XnaFoogq0A
-
Cloud Native Computing Foundation:https://www.cncf.io/

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献14条内容
已为社区贡献14条内容

所有评论(0)