当语音融入对话框:ChatGPT 一体化多模态交互长什么样?
【摘要】ChatGPT将语音功能深度整合进主聊天界面,标志着AI交互从孤立模式转向统一的多模态体验。这不仅是UI更新,更是底层架构与交互逻辑的根本性重塑。
【摘要】ChatGPT将语音功能深度整合进主聊天界面,标志着AI交互从孤立模式转向统一的多模态体验。这不仅是UI更新,更是底层架构与交互逻辑的根本性重塑。
引言
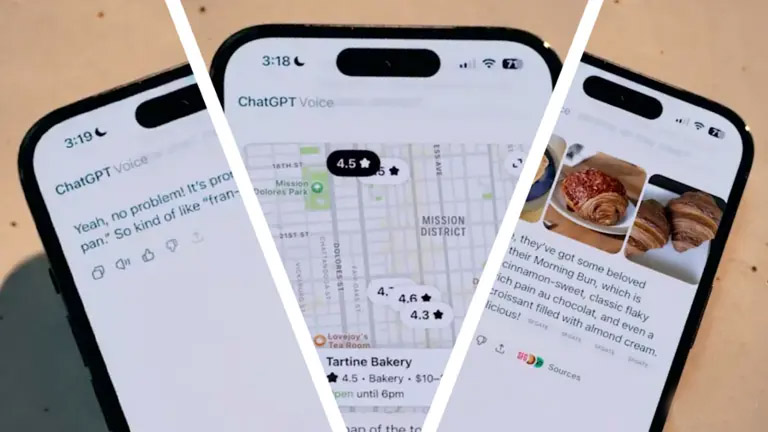
技术演进的常态,是于无声处听惊雷。OpenAI近期对ChatGPT的更新便属此类。没有盛大的发布会,仅凭一则简短的推文,便宣告了一场交互革命的开始。语音功能,这个曾被禁锢在独立“浮动球体”界面中的“特效”,如今被直接嵌入了主聊天窗口。
这一改变看似微小,实则意义深远。它标志着AI交互的核心逻辑,正从以文本为中心的单通道模式,向语音、文本、视觉无缝融合的多模态统一场迁移。这不仅是用户体验的优化,更是底层模型能力、系统架构与产品哲学的一次集体跃迁。作为一名从业多年的架构师,我将从技术视角出发,拆解这次更新背后的交互范式变革、核心技术机制,并探讨其对未来AI应用形态的深远影响。
一、🌀 交互范式的重塑:从孤立到融合

交互范式的演进,是人机关系变迁最直观的体现。ChatGPT此次更新的核心,正是对既有交互范式的颠覆性重构。
1.1 旧范式:情境割裂的“浮动球体”
在本次更新前,ChatGPT的语音模式是一种沉浸式、排他性的体验。
-
情境中断与抽离:激活语音功能,用户会被强制带离当前的文本聊天流。整个界面被一个跳动的球体占据,所有上下文、历史记录均被隐藏。这种设计在物理上和心理上都制造了强烈的割裂感,仿佛进入了另一个独立的应用程序。
-
交互通道单一:在“浮动球体”模式下,唯一的输入方式是语音。用户无法使用键盘进行补充、修正或精细化操作。输出也仅限于语音播报,缺乏文本的持久性和可追溯性。
-
操作负担:每次切换都需要用户做出“进入/退出”的明确决策,增加了操作链路的长度和认知负荷。这种模式更像是一个附属的“语音朗读器”,而非一个原生的交互层。
这种设计反映了早期多模态整合的一种朴素思路,即功能叠加而非原生融合。语音和文本被视为两个独立的系统,通过一个生硬的开关进行切换。
1.2 新范式:统一对话流中的多模态输入
新的整合模式彻底打破了上述壁垒,构建了一个统一、协同、灵活的交互场。
-
情境的连续性:语音功能成为主聊天界面的一部分,与文本输入框并列。用户可以在不离开当前对话流的情况下,随时启用语音。所有的交互,无论是语音转录的文本,还是AI生成的图文回复,都统一呈现在同一个时间线上。
-
交互通道的互补:用户可以在一次交互中自由切换输入方式。例如,用语音提出一个复杂问题,然后用键盘输入一个精确的代码片段或专有名词。这种灵活性极大地提升了复杂场景下的沟通效率。
-
操作的轻量化:语音的启用和停止仅需一次点击,操作路径被缩短至极致。它不再是一个需要“进入”的模式,而是一个与键盘同等地位的、**“召之即来,挥之即去”**的输入工具。
1.3 底层架构的变迁:从“管道拼接”到“原生多模态”
UI层面的融合,源于底层模型与架构的深刻变革。
-
旧架构推测:早期的语音模式,其后端架构很可能是一个**“管道式” (Pipeline) 的串联系统**。
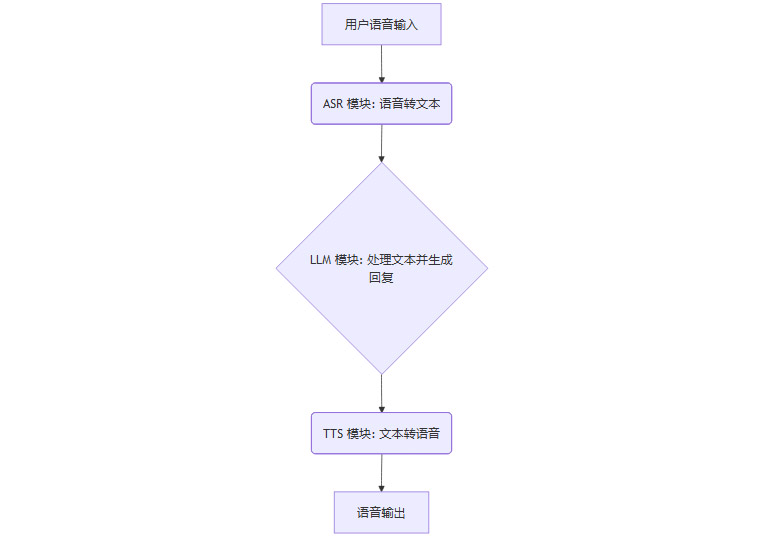
这个架构的弊端显而易见。每个模块各自为政,错误会在管道中逐级累积。更重要的是,LLM模块无法直接感知语音中的非文本信息,如语调、情绪、停顿等,导致交互缺乏人性化。延迟也是一个难以逾越的障碍。
-
新架构解析:如今的整合体验,尤其是在GPT-4o模型发布后,强烈指向一个端到端的原生多模态架构。
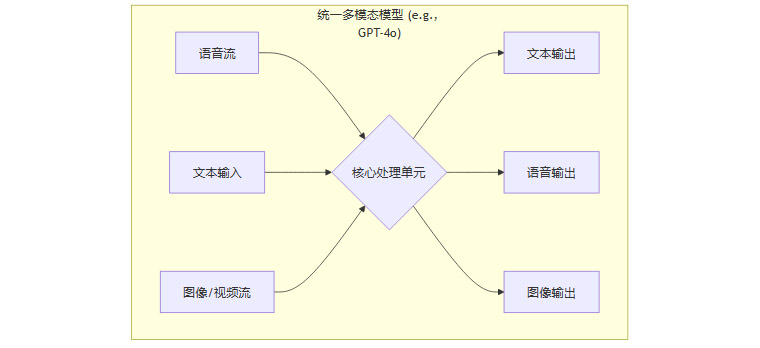
在这个新架构中,一个单一的模型能够同时接收并理解来自不同模态的输入流。它不再需要中间的转换步骤。模型可以直接从音频波形中提取语义和情感信息,实现更低的延迟和更富有人情味的交互。UI上的无缝切换,正是这种底层原生整合能力的直接体现。
二、⚙️ 一体化交互的核心机制与技术拆解
实现流畅的一体化交互,依赖于一系列关键技术的支撑。
2.1 实时转写与端点检测 (Real-time Transcription & Endpointing)
用户体验的流畅感,首先来自于低延迟的实时语音转写。
-
流式自动语音识别 (Streaming ASR):系统并非等待用户说完一整句话再进行识别,而是采用流式ASR技术。音频数据以小数据块(chunk)的形式被持续发送到服务器,服务器同步返回识别结果。这使得文字几乎在用户说话的同时就出现在屏幕上。
-
端点检测 (Voice Activity Detection, VAD):系统需要准确判断用户何时开始说话、何时结束。VAD算法通过分析音频信号的能量、频谱等特征,实时检测语音活动的起止点。这对于控制监听状态、减少不必要的计算资源消耗至关重要。一个精准的VAD可以避免过早切断或过长等待,提升对话的自然度。
2.2 可控监听与隐私架构
隐私是所有语音交互产品必须面对的核心议题。新版ChatGPT通过明确的UI设计,增强了用户的可控感和安全感。
-
显式控制:语音监听的启动和停止,完全由用户通过点击按钮来触发。界面上有清晰的视觉状态(如跳动的波纹)来指示“正在监听”。这种**“即按即说” (Push-to-Talk)** 的交互模式,有效打消了用户对于“AI是否在后台持续监听”的疑虑。
-
客户端与服务器的协同:从架构上看,VAD等轻量级处理可能在客户端完成,只有在检测到语音活动后,音频流才会被发送到服务器。这在一定程度上可以在保障功能的同时,最小化数据传输,保护用户隐私。
2.3 语音驱动的工具调用 (Tool Calling)
新版语音交互的强大之处,在于它不仅仅是聊天,更是一个通过自然语言驱动复杂任务的控制中枢。这背后是大模型作为代理 (Agent) 的工具调用能力。
其工作流程可以抽象为以下几个步骤:
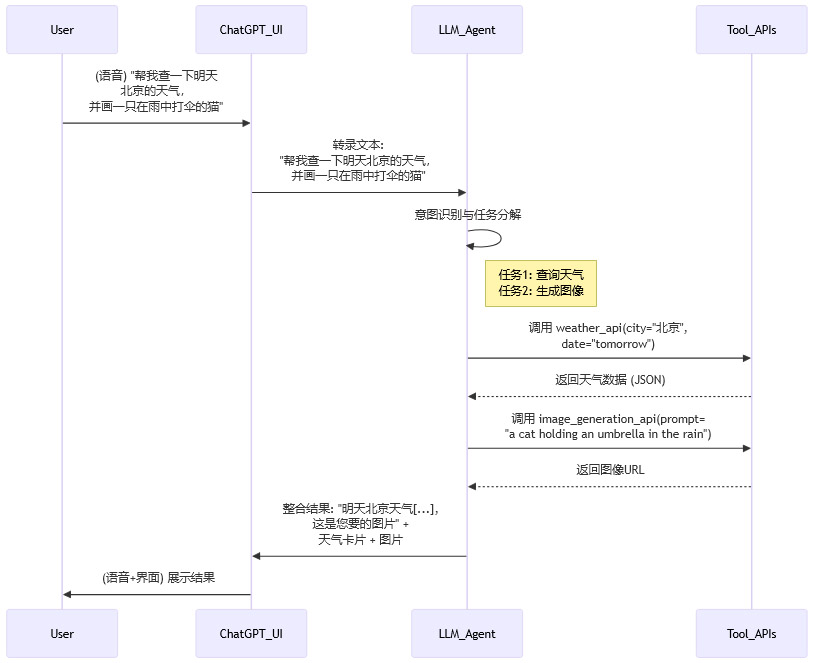
这个流程展示了LLM如何从一句模糊的自然语言指令中,解析出多个具体意图,并自主选择、调用合适的外部工具(API)来完成任务。最终,它还将不同工具返回的结构化数据,重新组织成对用户友好的自然语言和可视化组件。这是实现复杂任务自动化的关键。
2.4 多模态输出的呈现策略
AI的回复不再局限于单一的文本或语音。系统会根据信息类型,智能选择最优的呈现方式。
|
信息类型 |
主要输出模态 |
辅助输出模态 |
设计目的 |
|---|---|---|---|
|
天气预报 |
语音播报概要 |
结构化图表卡片 |
兼顾快速获取(听)与详细查阅(看) |
|
新闻摘要 |
语音播报要点 |
可点击的新闻链接 |
满足“听”新闻的需求,同时提供深度阅读入口 |
|
地图导航 |
语音说明路径 |
静态地图图片 |
提供直观的空间概念,但尚未实现动态导航 |
|
图像生成 |
语音确认与反馈 |
直接展示生成的图片 |
将创造性任务的结果即时、直观地呈现 |
|
复杂解释 |
语音分点阐述 |
格式化的文本(列表、代码块) |
语音适合传递思路,文本适合精确记录和复制 |
这种策略化的多模态输出,充分利用了不同媒介的优势,使得信息传递的效率和丰富度都达到了新的高度。
三、🚀 应用场景剖析:语音驱动下的新工作流

一体化的交互模式催生了许多全新的、高效的工作流。
3.1 高效的信息获取与整理
-
场景一:会议纪要与思路整理
在进行头脑风暴或复盘会议时,可以全程开启语音模式。用户通过口述记录要点、分配任务、梳理逻辑。ChatGPT实时将语音转为结构化的文本,并可根据指令(如“总结刚才的三个要点”、“把任务按负责人列个表格”)进行即时整理。这将记录与思考两个过程合二为一,极大地提升了效率。 -
场景二:移动中的信息助理
在通勤或驾车等不便操作手机的场景,语音成为主要的交互入口。用户可以口头查询邮件、安排日程、听取报告摘要,甚至让AI朗读一篇长文并随时就其中内容提问。AI真正成为了一个解放双手的“随行秘书”。
3.2 跨模态的内容创作与编辑
-
场景三:语音驱动的编程与调试
开发者可以口述代码逻辑(“创建一个Python函数,接收一个列表作为参数,返回其中所有偶数的平方和”),ChatGPT生成代码。当遇到问题时,可以用手机摄像头对准屏幕上的错误信息,同时口述问题(“这个报错是什么意思?帮我看看哪里错了”)。AI结合视觉信息和语音提问,给出调试建议。这打通了物理世界(屏幕)和数字世界(代码)的壁垒。 -
场景四:即时灵感的视觉化
设计师或内容创作者可以随时将脑海中闪现的画面通过语音描述出来(“我想要一个赛博朋克风格的城市夜景,霓虹灯要多,色调偏冷”),AI立即生成视觉草图。这种**“所言即所见”**的创作模式,极大地缩短了从灵感到原型的距离。尽管当前图像生成功能尚有不稳定性,但这无疑指明了未来的方向。
3.3 现实世界的感知与交互
-
场景五:实时的视觉问答
在旅行中,可以打开摄像头对准一栋不认识的建筑,问道:“这是什么地方?给我讲讲它的历史。” 在修理家电时,可以拍下复杂的内部线路,问道:“这根红色的线应该接到哪里?” AI成为了一个无所不知的、能够“看见”世界的向导和专家。
这些场景展示了,当语音、视觉、文本被无缝整合后,AI不再仅仅是一个聊天机器人,它正在演变为一个能够深度嵌入用户真实生活与工作流的、强大的情境感知与执行工具。
四、🔭 行业坐标与未来展望

ChatGPT的这次更新,为整个AI助手行业树立了新的标杆。
4.1 超越传统语音助手
与Siri、Alexa等传统语音助手相比,ChatGPT的优势是降维打击。
|
对比维度 |
传统语音助手 (Siri, Alexa 1.0) |
ChatGPT (新版语音模式) |
|---|---|---|
|
核心能力 |
基于指令匹配和预设技能 (Skill) |
基于大模型的深度理解与生成 |
|
对话模式 |
单轮、任务导向的“一问一答” |
多轮、上下文感知的“开放式对话” |
|
交互自由度 |
难以打断,需严格遵循指令格式 |
支持随时打断、切换话题,交互自然 |
|
任务复杂度 |
局限于查询、控制等封闭域任务 |
可处理写作、编程、分析等开放域复杂任务 |
|
多模态能力 |
有限的屏幕信息展示 |
语音、视觉、文本原生融合,协同理解与生成 |
传统助手更像是一个**“语音遥控器”,而ChatGPT则是一个“会话式通用问题解决器”**。
4.2 与同代竞品的比较
谷歌的Gemini Live同样是实时多模态交互的有力竞争者。两者在技术路径上相似,都强调低延迟和跨模态理解。但在当前阶段,ChatGPT在产品化整合上似乎更胜一筹。
-
生态整合度:ChatGPT将语音、图像生成(DALL-E)等能力更紧密地集成在统一的对话产品中,用户体验更为连贯。
-
工具链成熟度:ChatGPT的工具调用(联网、代码解释器等)经过了更长时间的迭代,在处理需要外部工具的复杂任务时,表现相对更稳定。
竞争的核心,将围绕模型原生多模态能力的强弱、工具生态的丰富度、以及与操作系统的深度集成能力展开。
4.3 AI界面的终极形态:走向“环境智能”
这次更新预示了AI交互界面的未来趋势。
-
从“显式”到“隐式”:AI功能正从一个需要用户主动打开、学习、适应的“应用程序”,演变为一个常驻后台、无处不在、按需响应的环境能力。就像Wi-Fi一样,我们平时感觉不到它的存在,只有在需要时它总是在那里,并且只有在它失效时我们才会注意到。
-
多模态成为默认:未来的主流交互将不再是单一模态的。键盘、触摸、语音、视觉将成为平等的输入通道,系统会根据用户所处的环境和任务的性质,智能地偏好或组合使用它们。
-
操作系统级的融合:最终,这种多模态AI助手将深度融入操作系统层面,成为连接用户与所有数字服务的统一入口。届时,我们将不再需要打开一个个独立的App,而是通过与一个统一的AI代理对话,来完成所有任务。
结论
ChatGPT将语音融入对话框,绝非一次简单的功能迭代。它是一次深刻的交互范式革命,背后是原生多模态模型的技术成熟与产品化落地。它将AI从一个“聊天对象”提升为一个能够看、听、说、做的“全能伙伴”,极大地拓宽了AI应用的边界。
通过实现语音、文本、视觉在统一对话流中的无缝切换,ChatGPT不仅优化了用户体验,更重要的是,它为我们展示了下一代人机交互的清晰蓝图。在这个蓝图中,技术正变得越来越“隐形”,而服务则越来越智能和无处不在。我们正处在一个AI从“工具”向“环境”演变的关键节点,而这次更新,无疑是这个进程中一个坚实而响亮的足迹。
📢💻 【省心锐评】
这次更新让AI的交互界面,终于追上了其智能模型的进化速度。语音不再是附属品,多模态成为新常态。AI正从一个你需要对话的“程序”,变为一个时刻伴你左右的“伙伴”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献543条内容
已为社区贡献543条内容

所有评论(0)