大模型激活函数:从ReLU到GLU的进化之路
在任意一层前馈网络里,最基本的计算形式是hfWxbhfWxb。其中WxbWxb是线性变换,而激活函数f⋅f(\cdot)f⋅决定了这一层是不是只是另一层线性变换。如果没有激活函数,那么无论叠多少层,本质都等价于一个大线性变换,模型只能拟合线性关系。加入非线性激活函数,网络才能逼近任意复杂的非线性函数,这是深度学习真正有用的地方。前馈网络(FFN):形如FFNxW2fW1xb1b2FFNxW2fW
激活函数从一条小小的曲线,演化成决定大模型能看多远、想多深的关键设计。
1 激活函数实践选型
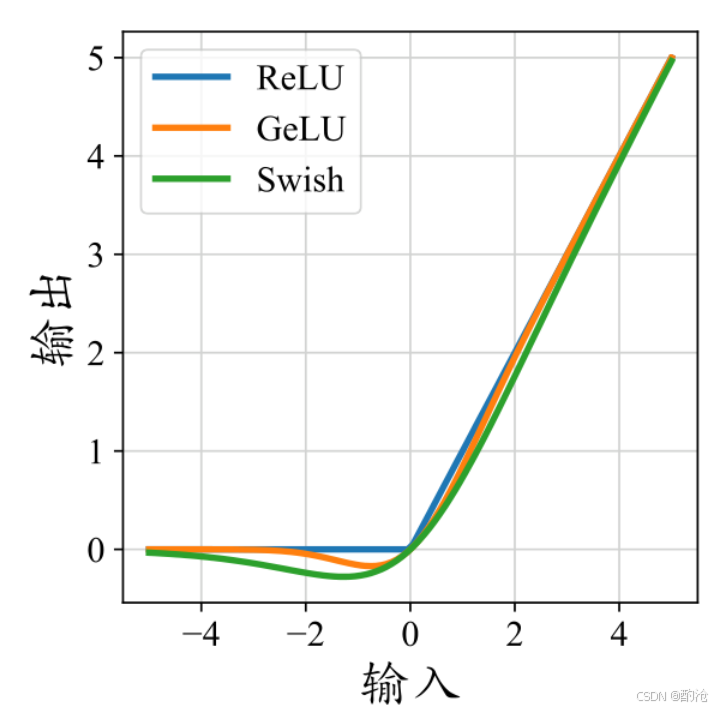
图示为ReLU、GeLU(近似)和Swish激活函数的比较。从ReLU到GeLU再到Swish,平滑度逐渐增加。
ReLU:实现简单、计算便宜。适用:算力紧张、模型不太深、不追求极致性能的场景。
GELU / Swish:收敛更平滑,最终效果常优于 ReLU;尤其适合大规模预训练。许多 GPT/Transformer 变体默认使用 GELU。
SwiGLU / GeGLU 等 GLU 变体:追求更高的参数效率和 SOTA 指标。使用 GLU 结构替换 FFN 中的简单激活。通过减小 FFN 隐藏维度来控制总参数量和算力。
2 什么是激活函数
在任意一层前馈网络里,最基本的计算形式是h=f(Wx+b)\mathbf{h} = f(W\mathbf{x} + \mathbf{b})h=f(Wx+b)。其中 Wx+bW\mathbf{x}+\mathbf{b}Wx+b 是线性变换,而激活函数 f(⋅)f(\cdot)f(⋅)决定了这一层是不是只是另一层线性变换。
如果没有激活函数,那么无论叠多少层,本质都等价于一个大线性变换,模型只能拟合线性关系。加入非线性激活函数,网络才能逼近任意复杂的非线性函数,这是深度学习真正有用的地方。
在 Transformer 里,激活函数主要出现在两处:前馈网络(FFN):形如 FFN(x)=W2f(W1x+b1)+b2\mathrm{FFN}(\mathbf{x}) = W_2f(W_1\mathbf{x} + \mathbf{b}_1) + \mathbf{b}_2FFN(x)=W2f(W1x+b1)+b2 激活函数决定了每个 token 经过 FFN 层后被如何弯曲和筛选。各种变体模块中的门控结构(如 GLU 系列):通过激活函数控制信息通过与否。
激活函数是模型的世界观曲线,决定它认为输入什么时候重要、什么时候该被压制。
3 修正线性单元ReLU
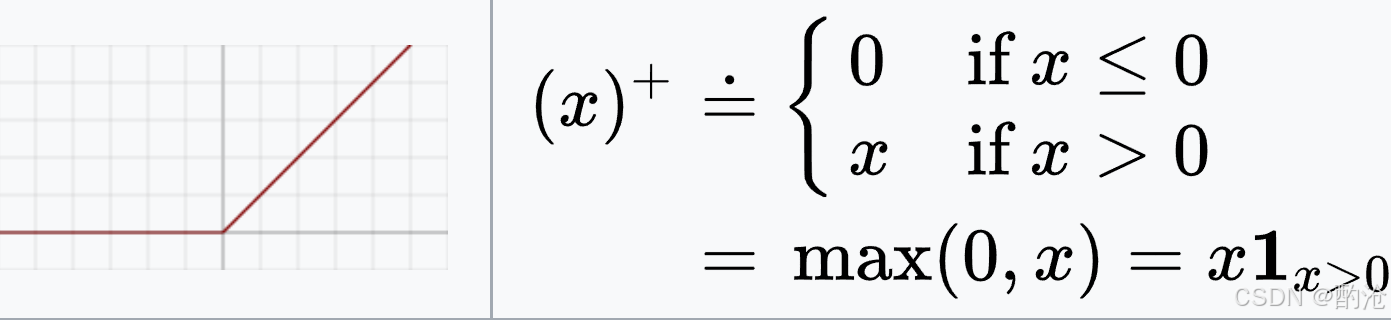
ReLU(Rectified Linear Unit) 是深度学习时代的标志性激活函数
优点
计算便宜:只需要和 0 比较。缓解梯度消失:在 (x>0) 区域,导数为 1,梯度不会像 Sigmoid 那样被压扁。稀疏性:很多神经元输出被截断为 0,带来稀疏表示,有助于泛化。
缺点
对于 x≤0x \le 0x≤0, ReLU(x)=0,ddxReLU(x)=0\mathrm{ReLU}(x) = 0,\quad \frac{d}{dx}\mathrm{ReLU}(x) = 0ReLU(x)=0,dxdReLU(x)=0 梯度为 0,这些神经元的参数不再更新。若训练早期因学习率过大或初始化问题,某些神经元大量输入落在负区间,就可能永远输出 0,彻底死亡。大规模死亡神经元会有效降低可用容量,间接影响性能。
4 Swish:自门控平滑ReLU
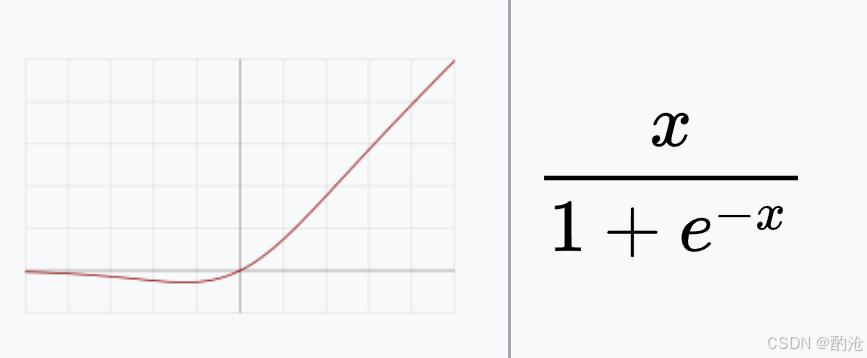
当 (x) 很大时,输出接近 (x) 本身(类似 ReLU 正半轴)。
当 (x) 很小时,输出接近 0,但仍然是连续的小负值,不是彻底归零。
这带来几个效果:在 (x<0) 区域仍有小梯度,不像 ReLU 那样死透。函数在 0 附近连续可导,优化地形更平滑,训练更稳定。本质是自己 gate 自己:输入 (x) 用自己的 Sigmoid 结果给自己开关。
5 高斯误差线性单元GeLU
外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传
Φ(x)\Phi(x)Φ(x) 可以看作一个标准正态随机变量小于 (x) 的概率。
GELU(x)=xΦ(x)\mathrm{GELU}(x) = x \Phi(x)GELU(x)=xΦ(x):以概率 Φ(x)\Phi(x)Φ(x) 让 (x) 通过,否则衰减为接近 0。
大的 (x) 几乎完全通过,小的 (x) 被柔和抑制,比 ReLU 的硬阈值更自然。
完全平滑可导,0 附近没有折角。强调按值大小软选择信息,而不是简单正值通过,负值截断。
6 基本 GLU:线性+门控
GLU(x)=(WUx)⊙σ(WGx)\mathrm{GLU}(\mathbf{x}) = (W_U\mathbf{x}) \odot \sigma(W_G\mathbf{x})GLU(x)=(WUx)⊙σ(WGx)
x\mathbf{x}x:输入向量。WUW_UWU:主干线性层,产生候选输出。 WGW_GWG:门线性层,经 Sigmoid 变成门向量(元素在 0–1)。⊙\odot⊙:逐元素相乘:门控主干输出。
模型不再是统一一条曲线对所有输入一视同仁,而是学一组门信号按位置决定该不该放大/抑制对应特征。
相比单一 FFN 激活,GLU 引入两套权重 (W_U, W_G),参数更多,计算量更大。
7 SwiGLU 与 GeGLU:高级曲线
在实践中,把 GLU 里的 Sigmoid 门换成更强的 Swish/GELU,效果更好。常见的两种变体:
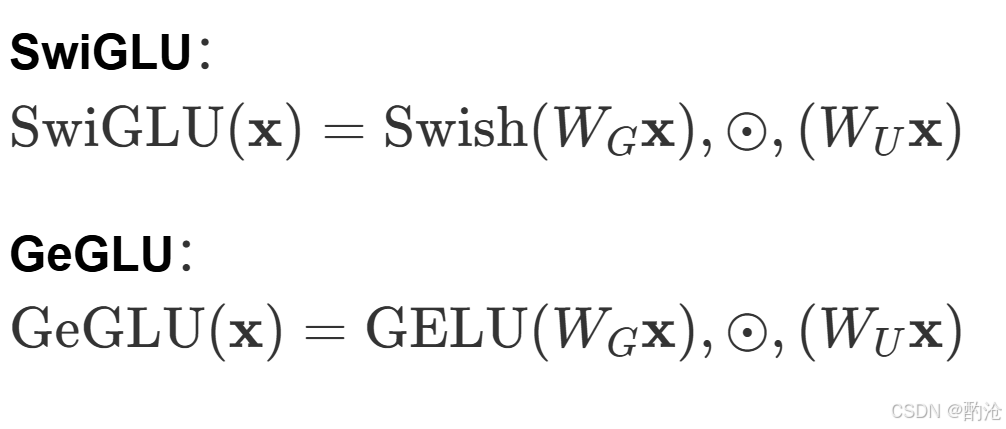
门不再是简单 Sigmoid,而是 Swish / GELU 这种更灵活的非线性,门控本身也变得更聪明。
在相同或相似参数预算下,SwiGLU / GeGLU 通常比传统 ReLU / GELU FFN 有更低的困惑度、更好的效果
大型语言模型(如 PaLM、LaMDA、T5、LLaMA 等)已广泛采用这类 GLU 变体作为 FFN 激活层核心结构。
8 激活函数的认知哲学
从 ReLU → Swish/GELU → GLU 的演化,本质是在回答:怎样让网络更精细地控制信息流?
非线性:承认世界是弯的:线性层只能表达世界是一张平面。激活函数让模型承认:现实里有拐弯、阈值、饱和、局部敏感区域。
ReLU:硬门槛思维:小于 0 的全部忽略,大于 0 的全部放行。这种二元判断简单粗暴,容易带来 Dead ReLU。
Swish / GELU:连续概率思维:不再是要么全要,要么全无,而是按大小和概率软选择。跟人类思考更像:弱证据不会被完全忽略,而是被弱化。
GLU 系列:条件计算与选择性注意:把门控从单点激活上升到向量级条件计算:不同特征维度可以有不同门控策略。更接近大脑中只让重要信号占用带宽的机制。
全无,而是按大小和概率软选择。跟人类思考更像:弱证据不会被完全忽略,而是被弱化。
GLU 系列:条件计算与选择性注意:把门控从单点激活上升到向量级条件计算:不同特征维度可以有不同门控策略。更接近大脑中只让重要信号占用带宽的机制。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)