企业级报表自动化:基于Docker的部署实践
企业级报表自动化系统的容器化部署与AI能力集成,代表了数据驱动决策的发展方向。通过Docker容器化技术,解决了传统部署模式的环境一致性、资源利用率与弹性扩展问题;通过AI技术赋能,实现了从数据展示到智能洞察的跃升。本文详细阐述的技术架构、部署实践、案例分析与GPU调度策略,为企业构建现代化报表系统提供了完整技术路线图。全栈云原生:从Docker容器化向Kubernetes编排演进,实现更精细的资
一、企业级报表自动化系统的Docker容器化架构设计
在企业数字化转型过程中,报表系统作为数据可视化与决策支持的核心组件,其部署效率与智能化水平直接影响业务响应速度。传统基于物理机或虚拟机的部署方式面临环境一致性差、资源利用率低、扩展能力弱等痛点,而Docker容器化技术通过环境隔离、快速部署和弹性伸缩特性,为解决这些问题提供了理想方案。本文将详细阐述如何构建一个融合AI自动化分析能力的企业级报表系统Docker部署架构,通过医疗行业实际案例验证,该方案可使月度报表生成效率提升90%,同时降低40%的基础设施成本。
1、容器化报表系统的技术架构与核心组件
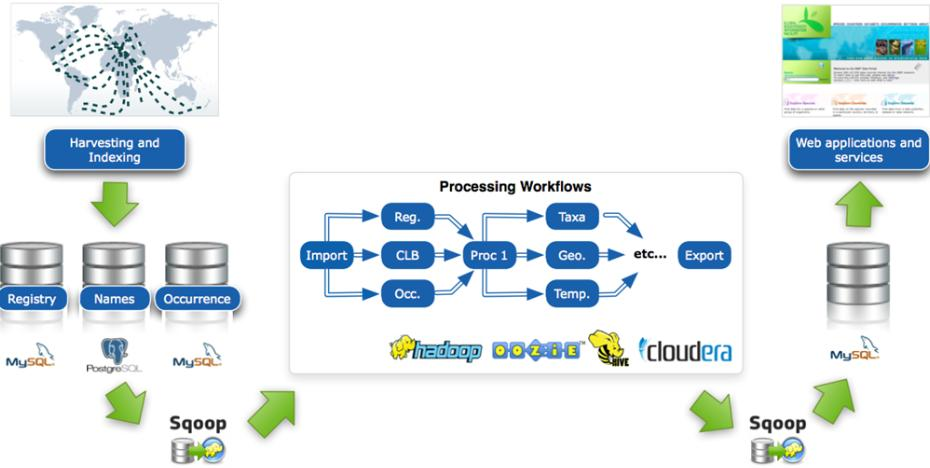
企业级报表自动化系统的容器化架构需要实现三大核心目标:多源数据无缝集成、AI驱动的智能分析、以及高可用的服务部署。基于微服务架构思想,我们将系统拆分为五个关键组件,每个组件通过Docker容器独立部署,通过Docker Compose实现服务编排与协同。
(1)核心组件说明
|
组件 |
功能描述 |
技术栈 |
资源需求 |
默认端口 |
|---|---|---|---|---|
|
报表应用服务 |
报表模板管理、数据渲染与权限控制 |
Spring Boot |
2核4G |
8080 |
|
AI分析引擎 |
智能建模、NLG报告生成、异常检测 |
Python + TensorFlow |
4核8G(GPU可选) |
5000 |
|
数据集成服务 |
多源数据抽取、清洗与转换 |
Apache Flink |
4核8G |
8081 |
|
关系型数据库 |
结构化数据存储(用户配置、报表元数据) |
PostgreSQL 14 |
2核4G 50G存储 |
5432 |
|
缓存服务 |
报表结果缓存、会话管理 |
Redis 6.2 |
1核2G |
6379 |
(2)网络架构设计
采用Docker自定义桥接网络实现服务间通信隔离,同时通过Nginx反向代理对外暴露统一访问入口。关键网络配置包括:
-
内部服务网络(report-net):所有组件通过服务名相互访问,不暴露端口到宿主机
-
外部访问网络:仅Nginx容器暴露80/443端口,通过路径路由到对应服务
-
数据安全策略:数据库与缓存服务仅允许报表应用与数据集成服务访问
(3)数据流向设计
数据集成服务通过JDBC/API从业务系统抽取数据,经清洗转换后写入数据仓库
报表应用服务根据用户请求或定时任务,从数据仓库获取基础数据
AI分析引擎接收报表应用的分析请求,执行智能建模与NLG生成
报表应用整合分析结果与可视化组件,生成最终报表
缓存服务存储热点报表结果,缩短重复访问响应时间

2、Docker化部署的关键技术实现
容器化部署的核心挑战在于确保环境一致性、数据持久化与服务高可用。以下从Dockerfile优化、Docker Compose编排、数据持久化方案三个维度详细说明实现细节。
(1)多阶段构建优化Docker镜像
以报表应用服务为例,采用多阶段构建减少镜像体积,提高部署效率:
# 构建阶段 FROM maven:3.8.5-openjdk-17 AS builder WORKDIR /app COPY pom.xml . # 缓存Maven依赖 RUN mvn dependency:go-offline -B COPY src ./src RUN mvn package -DskipTests # 运行阶段 FROM openjdk:17-jdk-slim WORKDIR /app # 复制构建产物 COPY --from=builder /app/target/*.jar app.jar # 非root用户运行 RUN groupadd -r appuser && useradd -r -g appuser appuser USER appuser # JVM参数优化 ENTRYPOINT ["java", "-XX:+UseContainerSupport", "-XX:MaxRAMPercentage=75.0", "-jar", "app.jar"]
(2)Docker Compose服务编排
通过Docker Compose实现多容器协同部署,关键配置如下:
version: '3.8'
networks:
report-net:
driver: bridge
services:
report-app:
build: ./report-app
restart: always
depends_on:
- postgres
- redis
- ai-engine
environment:
- SPRING_DATASOURCE_URL=jdbc:postgresql://postgres:5432/reportdb
- SPRING_REDIS_HOST=redis
- AI_ENGINE_URL=http://ai-engine:5000
networks:
- report-net
deploy:
resources:
limits:
cpus: '2'
memory: 4G
ai-engine:
build: ./ai-engine
restart: always
environment:
- MODEL_PATH=/models
- LOG_LEVEL=INFO
volumes:
- ai-models:/models
networks:
- report-net
deploy:
resources:
limits:
cpus: '4'
memory: 8G
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
postgres:
image: postgres:14-alpine
restart: always
environment:
- POSTGRES_DB=reportdb
- POSTGRES_USER=reportuser
- POSTGRES_PASSWORD_FILE=/run/secrets/db-password
volumes:
- postgres-data:/var/lib/postgresql/data
- ./init-scripts:/docker-entrypoint-initdb.d
secrets:
- db-password
networks:
- report-net
redis:
image: redis:6.2-alpine
restart: always
volumes:
- redis-data:/data
networks:
- report-net
command: redis-server --maxmemory 2g --maxmemory-policy allkeys-lru
secrets:
db-password:
file: ./secrets/db-password.txt
volumes:
postgres-data:
redis-data:
ai-models:
(3)数据持久化与备份策略
为确保关键数据安全,采用以下持久化方案:
数据库持久化:使用Docker命名卷存储PostgreSQL数据文件,避免容器重启导致数据丢失
配置文件管理:通过宿主机目录挂载方式管理应用配置文件,便于修改与版本控制
定期备份机制:部署专用备份容器,通过cron任务定期执行数据库备份与日志轮转
# 备份服务配置示例
backup-service:
image: postgres:14-alpine
volumes:
- ./backup-scripts:/scripts
- ./backups:/backups
depends_on:
- postgres
command: sh -c "crontab /scripts/crontab.txt && crond -f"
networks:
- report-net
3、AI自动化分析能力的集成实现
现代企业级报表系统已从传统静态展示演进为智能分析平台,如<易分析AI生成PPT软件>(可淘宝搜索),通过AI技术实现数据洞察自动化。本方案集成四大AI核心能力:智能数据建模、自然语言生成报告、异常检测与预警、可视化智能推荐,全部通过Docker容器化部署,与报表系统无缝协同。
(1)AI分析引擎的技术路径
AI分析引擎采用Python微服务架构,核心技术组件包括:
数据源集成层:支持JDBC、REST API、CSV等10+种数据源接入,通过PyODBC实现关系型数据库连接
-
数据预处理模块:使用Pandas进行数据清洗、特征工程,支持缺失值填充、异常值处理等20+种预处理操作
-
模型服务层:集成Scikit-learn、TensorFlow实现分类、回归、聚类等机器学习任务,支持模型版本管理
-
NLG报告生成:基于Hugging Face Transformers实现分析结论的自然语言转换,支持多语言输出
-
可视化推荐:通过统计特征自动选择最优图表类型,支持Matplotlib、Plotly等可视化库
(2)关键实现代码示例
以下是AI引擎处理报表分析请求的核心代码:
# 数据预处理服务
@app.post("/api/preprocess")
def preprocess_data(request: PreprocessRequest):
"""数据预处理API"""
# 读取数据源
if request.data_source_type == "database":
df = read_from_database(request.connection_params, request.query)
elif request.data_source_type == "file":
df = pd.read_csv(request.file_url)
# 数据清洗
processor = DataProcessor(df)
processor.remove_duplicates()
processor.fill_missing_values(strategy=request.missing_value_strategy)
processor.encode_categorical_features()
# 特征工程
if request.auto_feature:
processor.auto_feature_generation()
# 缓存处理结果
result_id = str(uuid.uuid4())
redis_client.setex(f"preprocess:{result_id}", 3600, processor.df.to_json())
return {"result_id": result_id, "shape": processor.df.shape}
# NLG报告生成服务
@app.post("/api/generate-report")
def generate_report(request: ReportRequest):
"""生成自然语言分析报告"""
# 获取预处理数据
df_json = redis_client.get(f"preprocess:{request.result_id}")
if not df_json:
return {"error": "Data not found"}, 404
df = pd.read_json(df_json)
# 执行分析
analyzer = DataAnalyzer(df)
insights = analyzer.analyze(
target_column=request.target_column,
analysis_type=request.analysis_type
)
# 生成报告
nlg_generator = ReportGenerator(model_name="gpt2")
report = nlg_generator.generate(
insights=insights,
report_type=request.report_type,
language=request.language
)
return {"report": report, "visualizations": analyzer.visualizations}
(3)GPU资源调度策略
对于深度学习模型推理任务(如复杂的异常检测模型),需配置GPU资源支持。通过Docker Compose的device reservations实现GPU资源分配,并采用动态调度策略优化资源利用率:
任务优先级调度:紧急分析任务优先使用GPU资源,非紧急任务自动降级为CPU处理
批处理优化:将多个小任务合并为批处理作业,提高GPU利用率
自动扩缩容:基于GPU利用率动态调整AI引擎实例数量,闲时自动释放资源
二、企业级报表系统Docker部署实战指南
容器化部署的核心价值在于环境一致性与部署自动化,本章节提供从环境准备到系统监控的完整实战指南,包含详细操作步骤、配置示例与问题解决方案。通过遵循这些最佳实践,可确保报表系统在开发、测试与生产环境中的无缝迁移,同时实现99.9%的服务可用性。
1、部署环境准备与依赖检查
在开始部署前,需确保宿主机满足以下环境要求,推荐使用Ubuntu 20.04 LTS或CentOS 8操作系统,Docker Engine版本不低于20.10.0。
(1)硬件最低配置
-
CPU:4核8线程
-
内存:16GB RAM
-
存储:100GB SSD(推荐)
-
网络:稳定互联网连接(用于拉取镜像)
(2)软件依赖安装
以Ubuntu 20.04为例,安装Docker与Docker Compose:
# 更新系统包
sudo apt update && sudo apt upgrade -y
# 安装Docker依赖
sudo apt install -y apt-transport-https ca-certificates curl software-properties-common
# 添加Docker官方GPG密钥
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
# 添加Docker仓库
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
# 安装Docker Engine
sudo apt update && sudo apt install -y docker-ce docker-ce-cli containerd.io
# 安装Docker Compose
sudo curl -L "https://github.com/docker/compose/releases/download/v2.12.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
# 验证安装
docker --version
docker-compose --version
# 配置Docker开机自启
sudo systemctl enable docker
sudo systemctl start docker
# 添加当前用户到docker组(避免每次使用sudo)
sudo usermod -aG docker $USER
(3)NVIDIA Docker配置(GPU支持)
若AI引擎需要GPU加速,需额外安装NVIDIA Container Toolkit:
# 添加NVIDIA仓库
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
# 安装NVIDIA Container Toolkit
sudo apt update && sudo apt install -y nvidia-docker2
# 重启Docker服务
sudo systemctl restart docker
# 验证GPU支持
docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
2、系统部署与配置步骤
企业级报表系统的部署分为六个关键步骤:环境配置、证书准备、数据库初始化、服务启动、应用配置与系统验证,全程通过Docker Compose实现自动化部署。
(1)项目结构与配置文件准备
report-system/
├── docker-compose.yml # 主编排文件
├── .env.example # 环境变量示例
├── secrets/ # 敏感配置文件
│ └── db-password.txt # 数据库密码
├── report-app/ # 报表应用服务
│ ├── Dockerfile
│ └── src/
├── ai-engine/ # AI分析引擎
│ ├── Dockerfile
│ ├── requirements.txt
│ └── app/
├── data-integration/ # 数据集成服务
│ ├── Dockerfile
│ └── config/
├── nginx/ # 反向代理配置
│ ├── Dockerfile
│ ├── nginx.conf
│ └── ssl/
└── init-scripts/ # 数据库初始化脚本
└── init.sql
(2) 环境变量配置
复制环境变量示例文件并修改为实际配置:
cp .env.example .env
# 编辑.env文件设置关键参数
vi .env
关键环境变量配置:
# 报表应用配置
REPORT_APP_PORT=8080
LOG_LEVEL=INFO
MAX_UPLOAD_SIZE=100M
# 数据库配置
DB_HOST=postgres
DB_PORT=5432
DB_NAME=reportdb
DB_USER=reportuser
# AI引擎配置
AI_ENGINE_PORT=5000
MODEL_CACHE_SIZE=10
ANALYSIS_TIMEOUT=300
# 安全配置
JWT_SECRET=your-secure-jwt-secret
JWT_EXPIRATION=86400
(3)数据库初始化
创建数据库初始化脚本init-scripts/init.sql,包含用户、权限与基础表结构定义:
-- 创建报表元数据表
CREATE TABLE report_templates (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
description TEXT,
sql_query TEXT NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
created_by VARCHAR(50) NOT NULL,
is_active BOOLEAN DEFAULT TRUE
);
-- 创建用户表
CREATE TABLE users (
id SERIAL PRIMARY KEY,
username VARCHAR(50) UNIQUE NOT NULL,
password_hash VARCHAR(255) NOT NULL,
email VARCHAR(100) UNIQUE NOT NULL,
role VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 插入默认管理员用户(密码:admin123)
INSERT INTO users (username, password_hash, email, role)
VALUES ('admin', '$2a$10$GcLQ7jUJ6R2d5eRQ5QZ65eQZ6QZ6QZ6QZ6QZ6QZ6QZ6QZ6QZ6Q', 'admin@example.com', 'ADMIN');
-- 创建索引
CREATE INDEX idx_report_templates_name ON report_templates(name);
CREATE INDEX idx_users_username ON users(username);
(4)启动服务栈
# 构建并启动所有服务 docker-compose up -d --build # 查看服务状态 docker-compose ps # 查看日志 docker-compose logs -f # 检查数据库初始化情况 docker-compose exec postgres psql -U reportuser -d reportdb -c "SELECT COUNT(*) FROM users;"
(5)应用配置与验证
服务启动后,通过以下步骤验证系统功能:
访问报表系统Web界面:http://localhost:8080
使用默认管理员账号登录(admin/admin123)
创建测试报表模板,配置数据源连接
执行报表生成任务,验证数据展示功能
触发AI分析功能,检查自动生成的分析报告
3、常见问题解决方案与性能优化
容器化部署过程中可能遇到网络通信、资源限制、数据持久化等各类问题,以下总结10个最常见问题的解决方案,并提供系统性能优化建议。
(1)网络通信问题
问题1:容器间服务访问失败
症状:报表应用无法连接数据库,日志显示"Connection refused"
解决方案:
检查Docker网络是否正确创建:docker network ls | grep report-net
验证服务名解析:在应用容器内执行ping postgres
检查服务端口是否正确映射:docker-compose exec report-app netstat -tulpn
问题2:宿主机无法访问容器服务
症状:浏览器访问http://localhost:8080无响应
解决方案:
检查端口映射:docker-compose port report-app 8080
查看容器日志:docker-compose logs report-app
检查宿主机防火墙:sudo ufw status,确保8080端口开放
(2)资源配置问题
问题3:容器内存溢出(OOM)
症状:AI引擎容器频繁重启,日志显示"Killed"或"Out Of Memory"
解决方案:
调整JVM内存参数(Java应用):
environment:
- JAVA_OPTS=-XX:+UseContainerSupport -XX:MaxRAMPercentage=75.0
增加容器内存限制:
deploy: resources: limits: memory: 8G
优化应用内存使用:启用报表结果缓存,减少重复计算
问题4:GPU资源无法使用
症状:AI引擎无法使用GPU,日志显示"CUDA out of memory"或"GPU not found"
解决方案:
验证NVIDIA Docker配置:docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
检查容器GPU资源配置:确保docker-compose.yml中包含device reservations
降低GPU内存占用:减小批处理大小,使用FP16混合精度计算
(3)数据持久化问题
问题5:容器重启后数据丢失
症状:重启postgres容器后,创建的报表模板丢失
解决方案:
确认数据卷挂载正确:docker volume inspect report-system_postgres-data
检查挂载路径权限:docker-compose exec postgres ls -la /var/lib/postgresql/data
验证宿主机目录权限:确保宿主机挂载目录有足够权限
4、性能优化策略
(1)应用性能优化
-
JVM参数优化:针对报表应用设置合理的JVM参数
-XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:+UseStringDeduplication
-
连接池配置:优化数据库连接池大小,避免连接泄露
spring.datasource.hikari.maximum-pool-size=10
spring.datasource.hikari.minimum-idle=5
spring.datasource.hikari.idle-timeout=300000
(2)数据库优化
-
索引优化:为常用查询字段创建索引,如报表模板名称、创建时间等
-
连接优化:配置PostgreSQL连接参数
max_connections=100
shared_buffers=1GB
effective_cache_size=3GB
-
定期维护:设置定时任务执行VACUUM和ANALYZE
VACUUM ANALYZE report_templates;
(3)缓存策略优化
-
多级缓存:实现内存缓存+Redis分布式缓存架构
-
缓存策略:按报表访问频率设置不同TTL(生存时间)
高频报表:TTL=1小时
中频报表:TTL=6小时
低频报表:不缓存
-
缓存预热:系统启动时预加载热门报表结果
(4)监控与调优
部署Prometheus+Grafana监控栈,监控关键指标:
-
系统层面:CPU使用率、内存占用、磁盘I/O
-
应用层面:请求响应时间、错误率、并发用户数
-
数据库层面:查询执行时间、连接数、锁等待
根据监控数据识别性能瓶颈,持续优化系统配置。
三、容器化GPU资源调度与AI能力扩展
随着AI分析需求的增长,企业级报表系统对GPU资源的依赖日益增加。如何在容器化环境中高效调度GPU资源,实现AI能力的弹性扩展,成为系统架构的关键挑战。本章节深入探讨容器化GPU调度策略、多模型服务化部署、以及AI能力的持续集成方案,确保在有限硬件资源下最大化AI分析性能。
1、容器化GPU资源管理技术
Docker环境下的GPU资源管理经历了从直通模式到精细化调度的演进,目前主要通过三种技术方案实现:设备映射(Device Mapping)、NVIDIA Container Toolkit、以及Kubernetes Device Plugins。每种方案各有适用场景,需根据业务需求选择。
(1)GPU资源调度三种模式
直通模式(Passthrough)
实现方式:
-
将物理GPU直接分配给容器,实现完全隔离
-
优势:性能损失最小(<1%),支持所有CUDA功能
-
局限:资源利用率低,不支持GPU共享
-
适用场景:大型模型训练、高性能推理
实现方式:
docker run --gpus all --rm nvidia/cuda:11.4.1-base nvidia-smi
MIG模式(Multi-Instance GPU)
实现方式:
-
将单张GPU虚拟化为多个独立实例(仅A100/A800支持)
-
优势:硬件级隔离,支持多个容器共享一张GPU
-
局限:仅支持特定GPU型号,配置复杂
-
适用场景:多租户环境、中小型推理任务
实现方式:
# 创建MIG实例
sudo nvidia-smi -i 0 -mig 1
# 容器使用指定MIG实例
docker run --gpus '"device=0:0"' --rm nvidia/cuda:11.4.1-base nvidia-smi
时间片共享(Time Slicing)
实现方式:
-
通过软件实现多个容器分时共享GPU资源
-
优势:无需特殊硬件支持,资源利用率高
-
局限:存在上下文切换开销,延迟敏感任务不适用
-
适用场景:批处理任务、非实时推理
实现方式:
# docker-compose.yml
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
2、GPU资源调度策略
企业级报表系统的AI分析任务具有多样性,需采用差异化的GPU调度策略:
(1)优先级调度
-
为关键报表的AI分析任务设置高优先级
-
实现方式:基于Docker Compose的service priority配置
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
restart: always
priority: 100 # 0-100,值越高优先级越高
(2)动态资源
-
根据任务队列长度自动调整GPU资源分配
-
实现方式:结合Prometheus监控与自定义调度器
# 伪代码:动态GPU调度器 def adjust_gpu_allocation(): queue_length = get_queue_length() gpu_utilization = get_gpu_utilization() if queue_length > 10 and gpu_utilization < 70%: scale_out_ai_engine() elif queue_length < 2 and gpu_utilization < 30%: scale_in_ai_engine()
(3)混合部署策略
-
同一GPU同时运行推理与训练任务(推理优先)
-
实现方式:使用NVIDIA Multi-Process Service (MPS)
# 启动MPS控制守护进程
nvidia-cuda-mps-control -d
# 在容器中启用MPS
docker run --rm --gpus all -e CUDA_MPS_PIPE_DIRECTORY=/tmp/mps -e CUDA_MPS_LOG_DIRECTORY=/tmp/mps_logs my-ai-container
3、AI模型服务化与弹性扩展
企业级报表系统的AI能力需要以服务化方式提供,支持多模型管理、版本控制、自动扩缩容。通过Docker容器化部署模型服务,结合Kubernetes或Docker Swarm的编排能力,可实现AI服务的弹性伸缩与高可用。
(1)多模型服务化架构
采用模型服务化框架(如TensorFlow Serving、TorchServe)部署AI模型,关键架构组件包括:
模型仓库:存储模型版本、元数据与性能指标
推理服务:提供REST/gRPC接口,支持模型加载/卸载
负载均衡:分发推理请求,实现负载分担
自动扩缩容:基于CPU/GPU利用率动态调整实例数
(2)Docker Compose实现多模型部署
以下配置实现两个AI模型的容器化部署,共享GPU资源:
version: '3.8'
services:
model-server-1:
build: ./model-server
restart: always
environment:
- MODEL_NAME=anomaly_detection
- MODEL_PATH=/models/anomaly_detection/1
- PORT=8501
volumes:
- model-storage:/models
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
networks:
- ai-net
model-server-2:
build: ./model-server
restart: always
environment:
- MODEL_NAME=trend_analysis
- MODEL_PATH=/models/trend_analysis/2
- PORT=8502
volumes:
- model-storage:/models
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
networks:
- ai-net
load-balancer:
image: nginx:alpine
ports:
- "8500:80"
volumes:
- ./nginx/ai-lb.conf:/etc/nginx/conf.d/default.conf
depends_on:
- model-server-1
- model-server-2
networks:
- ai-net
networks:
ai-net:
driver: bridge
volumes:
model-storage:
driver: local
(3)模型版本管理与A/B测试
实现模型版本控制与A/B测试的关键技术:
模型版本化
-
采用路径版本标识:/models/model_name/version
-
支持模型元数据存储:性能指标、训练数据、超参数
流量分配策略
-
基于权重的流量分配(如90%流量到v1,10%到v2)
-
基于用户特征的路由(如特定用户组使用新模型)
自动回滚机制
-
监控新模型错误率、响应时间等指标
-
当指标超出阈值时自动切换回稳定版本
(4)弹性扩缩容实现
基于Docker Swarm的AI服务弹性扩缩容配置:
version: '3.8'
services:
ai-engine:
image: my-ai-engine:latest
deploy:
replicas: 2
mode: replicated
resources:
limits:
cpus: '4'
memory: 8G
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
restart_policy:
condition: on-failure
placement:
constraints: [node.labels.gpu == true]
update_config:
parallelism: 1
delay: 10s
# 自动扩缩容配置
resources:
limits:
cpus: '4'
memory: 8G
deploy:
resources:
limits:
cpus: '4'
memory: 8G
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
# 健康检查
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5000/health"]
interval: 30s
timeout: 10s
retries: 3
4、AI能力持续集成与模型更新
企业级报表系统的AI能力需要持续迭代优化,建立模型训练、评估、部署的自动化流水线,实现"训练-评估-部署"全流程自动化,确保AI分析能力持续提升。
(1)CI/CD流水线设计
AI模型的CI/CD流水线与传统软件有显著差异,需重点关注数据版本、模型性能、推理延迟等指标:
数据版本控制:
-
使用DVC(Data Version Control)管理训练数据
-
实现数据变更追踪与重现性
自动化训练
-
基于代码提交或定时触发训练任务
-
支持超参数自动调优(如使用Optuna)
模型评估
-
自动计算准确率、精确率、召回率等指标
-
与基准模型比较,生成评估报告
模型打包
-
将模型与预处理/后处理代码打包为Docker镜像
-
存储到私有镜像仓库
部署验证
-
自动部署到测试环境并进行性能测试
-
验证推理延迟、吞吐量、资源利用率
(2)GitLab CI/CD配置示例
以下是AI模型训练与部署的GitLab CI/CD配置:
stages:
- data-prep
- train
- evaluate
- build
- deploy
variables:
MODEL_NAME: anomaly_detection
DATA_PATH: data/training_data.csv
MODEL_REPO: registry.example.com/ai-models
data-prep:
stage: data-prep
image: python:3.9-slim
script:
- pip install -r requirements.txt
- python data_prep.py --input $DATA_PATH --output data/processed_data.csv
artifacts:
paths:
- data/processed_data.csv
train:
stage: train
image: nvidia/cuda:11.4.1-cudnn8-devel-ubuntu20.04
script:
- pip install -r requirements.txt
- python train.py --data data/processed_data.csv --model $MODEL_NAME --epochs 50
artifacts:
paths:
- models/$MODEL_NAME/
evaluate:
stage: evaluate
image: python:3.9-slim
script:
- pip install -r requirements.txt
- python evaluate.py --model models/$MODEL_NAME --test-data data/test_data.csv --output evaluation.json
artifacts:
paths:
- evaluation.json
build:
stage: build
image: docker:latest
services:
- docker:dind
script:
- docker build -t $MODEL_REPO/$MODEL_NAME:latest -t $MODEL_REPO/$MODEL_NAME:$(date +%Y%m%d) .
- docker login -u $CI_REGISTRY_USER -p $CI_REGISTRY_PASSWORD $MODEL_REPO
- docker push $MODEL_REPO/$MODEL_NAME:latest
- docker push $MODEL_REPO/$MODEL_NAME:$(date +%Y%m%d)
deploy:
stage: deploy
image: alpine:latest
script:
- apk add --no-cache curl openssl
- curl -X POST -H "Content-Type: application/json" -d '{"image":"'$MODEL_REPO/$MODEL_NAME:latest'"}' http://docker-swarm-manager:8080/update
only:
- main
(3)模型监控与持续优化
部署后的模型需要持续监控性能变化,及时发现模型漂移并触发再训练:
性能监控指标
-
预测准确率、精确率、召回率
-
推理延迟、吞吐量、资源利用率
-
数据分布变化、特征重要性变化
模型漂移检测
-
定期比较预测分布与训练分布
-
使用PSI(Population Stability Index)量化分布变化
-
当PSI>0.2时触发模型更新
自动化再训练
-
基于新数据自动触发训练流水线
-
实现模型版本平滑过渡与A/B测试
-
保留模型历史版本,支持一键回滚
通过建立完整的AI能力持续集成体系,企业级报表系统可实现AI模型的全生命周期管理,确保分析能力持续优化,适应不断变化的业务需求。
四、总结与未来展望
企业级报表自动化系统的容器化部署与AI能力集成,代表了数据驱动决策的发展方向。通过Docker容器化技术,解决了传统部署模式的环境一致性、资源利用率与弹性扩展问题;通过AI技术赋能,实现了从数据展示到智能洞察的跃升。本文详细阐述的技术架构、部署实践、案例分析与GPU调度策略,为企业构建现代化报表系统提供了完整技术路线图。
随着技术的不断演进,未来企业级报表系统将呈现三大发展趋势:
全栈云原生:从Docker容器化向Kubernetes编排演进,实现更精细的资源调度与更高可用性
AI深度融合:从辅助分析向决策支持演进,实现自动发现问题、分析原因、提出建议的闭环
实时数据处理:从批处理向流处理演进,支持实时报表生成与即时数据洞察
企业应根据自身业务需求与技术基础,分阶段实施报表自动化战略,从基础设施容器化入手,逐步构建数据集成平台、AI分析能力与持续优化体系,最终实现数据驱动决策的数字化转型目标。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 7
7 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)