GPU 还是 CPU?文本分析、LLM 微调、多模态各自怎么选
本文对比了GPU和CPU的特点及其适用场景,指出GPU凭借并行计算优势更适用于深度学习和大模型任务。针对经济金融研究需求,文章提供了三档GPU配置建议:入门级RTX4060适合教学演示和小规模实验;主力级RTX4070/4070SUPER可支持7B级LLM微调;重度级RTX4090适用于13B级模型训练。同时强调传统计量分析通常只需CPU即可完成。最后指出,GPU在文本分析、LLM微调和多模态任务
温馨提示:若页面不能正常显示数学公式和代码,请阅读原文获得更好的阅读体验。
作者: 连小白 (连享会)
邮箱: lianxhcn@163.com
- Title: GPU 还是 CPU?文本分析、LLM 微调、多模态各自怎么选
- Keywords: 深度学习, Deep Learning, 大语言模型, LLM, 显卡, 图形处理器, 多模态
1. GPU 到底是什么?
简单说:GPU 就是一块「特别擅长并行算很多小任务」的计算芯片,最早用来画图,现在被我们拿来做深度学习、数值运算。
GPU 的全称是 Graphics Processing Unit,中文一般叫 “图形处理器” 或 “独立显卡”。喜欢打游戏的朋友应该比较熟悉。
- 它是一块专门负责计算的芯片,就像 CPU 一样,也是“处理器”;
- 但它最初是为了在屏幕上画图、渲染 3D 游戏设计的,比如计算每个像素的颜色、亮度、阴影等;
- 这些任务有一个特点:同样的计算,要对成千上万个像素、顶点重复做,非常适合“同时并行算很多份”。
于是,GPU 的设计思路就是:
- 不追求“单核算得多快”,
- 而是追求“有成百上千个小核心,一次把成千上万个小任务一起算完”。
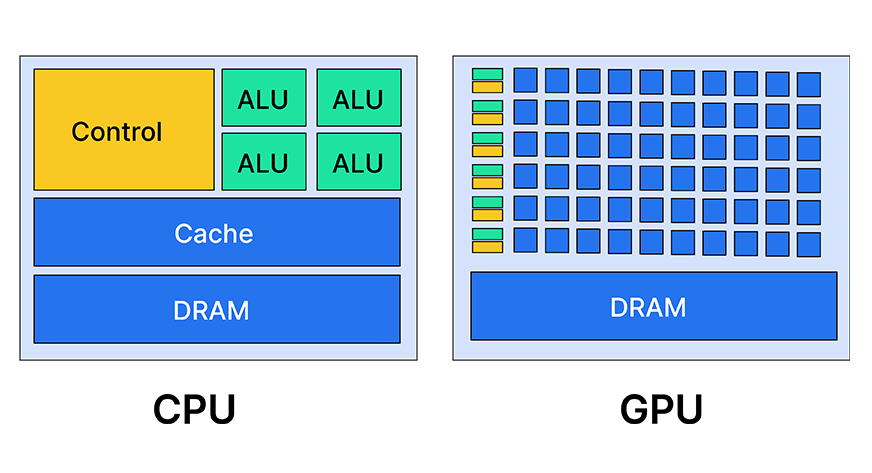
GPU 和 CPU 有什么区别?
通俗而言,
- CPU 像一个非常聪明、经验丰富的总厨,会做各种复杂的菜谱、决策、流程控制,但厨师数量不多(核心数少)。
- GPU 像一个拥有几百上千个学徒的大厨房,每个学徒只会做 1–2 个简单动作,但可以一起上手、同时干活。
更技术一点:
-
CPU:
- 核心少(一般 4–32 个核)
- 每个核心很强,适合复杂逻辑、条件判断、系统调度
- 优点:单线程性能强,适合通用计算
-
GPU:
- 核心特别多(上千甚至上万个所谓「CUDA cores」「流处理器」)
- 每个核心相对简单,但可以在同一时间并行处理大量数据
- 优点:大规模并行计算能力极强,适合“同一种运算做很多遍”
为什么深度学习需要用 GPU?
以人工神经网络为基础的深度学习,其运算中涉及大量的矩阵乘法、向量加法,且同一种简单运算,需要对成千上万个元素重复执行。
比如,一个简单的矩阵乘法:C=A×BC=A×B,本质上就是对很多元素重复做“乘加”。CPU 可以做,但要一小块一小块地算,而 GPU 则可以把每个元素、每一行、每一列的计算都分给不同的核心,同时算,所以会快很多倍,有时快几十倍甚至上百倍。
因此,现在训练大模型(比如 LLM)要用大量 GPU,做图像识别、机器翻译、推荐系统等也需要 GPU。
2. 现实需求:个人电脑和小型工作站怎么配 GPU?
如果我们日常主要是经济/金融研究、上课演示、少量本地实验,则可以按需选购 GPU。
2.1 台式机/工作站:三档现实配置
大部分高校老师、研究生,其实更适合台式机或小型工作站插一块独立显卡,而不是一上来就买「服务器」。
下面按“轻量–主力–重度”三档来讲(价格是近期国内电商的典型区间,具体型号和活动价会有波动):
A. 入门级:RTX 4060(8GB 显存)
- 大致价位:新卡大约2000–2500元区间。
- 能做什么:
- 小批量 BERT/FinBERT 文本分类、句向量提取;
- 中小规模图像任务的训练和推理;
- 教学演示深度学习基本流程完全够用。
- 不足:
- 显存偏小,遇到稍大一点的模型/批量,就需要非常小的 batch size 或强行量化。
适合人群:以「教学 + 小规模实验」为主,对 LLM、本地大模型微调没有强烈刚需。
B. 主力研究级:RTX 4070/4070 SUPER(12GB 显存)
-
参考价格:
- 首发时国行 4070 常见价位在 4799 元起步(DIY之家);
- 经历几轮降价后,电商平台部分品牌会在 4000–4500 元左右波动。
-
能做什么:
- 7B 级别开源 LLM(LLaMA 系、Qwen 7B 等)的推理与轻量 LoRA 微调(配合4bit/8bit 量化);
- 比较大规模的 BERT/FinBERT 文本向量抽取(几十万–上百万句);
- 中等规模的多模态模型推理(图文匹配、表格+文本等)。
-
配机建议(供学院采购或自己组装时参考):
- CPU:i7/Ryzen 7 这一档;
- 内存:32–64GB;
- 硬盘:2TB SSD 起步(数据多的话再加机械盘做归档);
- 电源:650–750W;
- 显卡:RTX 4070/4070 SUPER。
这档是非常适合经济/金融系老师的“甜点位”:
教学够用,本地做一点 LLM 微调、文本/多模态实证也比较顺手。
C. 重度模型级:RTX 4090(24GB 显存)及以上
-
价格区间:单卡普遍在1.2–1.8万元(甚至更高),整体工作站轻松到2万+。
-
能做什么:
- 13B 级别模型的微调、复杂多模态训练;
- 大规模仿真、复杂强化学习。
-
问题:
- 功耗与噪音都明显上去;
- 对电源、散热、机箱空间要求更高;
- 对于“偶尔训练”的老师来说,利用率可能严重不足。
这档更像是“实验室级别”的投资,除非你准备做一系列方法论文或长期大模型实验,否则不一定划算。
2.2 笔记本和 eGPU 简评
-
游戏本/创作本里自带的 RTX 4060/4070,其实就是笔记本版 GPU,适合:
- 上课现场演示;
- 外出开会简单跑一下模型。
-
eGPU 盒子(雷电接口外接桌面显卡):
- 价格高、折腾多、性能打折,不建议作为第一方案;
- 有特殊移动需求时可以考虑,但大多数老师不太需要。
3. 经济与金融领域:哪些任务真的需要 GPU?
绝大多数传统计量任务(回归、DID、面板模型、Bootstrap、GMM 等),CPU 完全够用,不需要 GPU。
GPU 真正发挥优势的,是深度学习和大模型相关的情形。
3.1 基本不需要 GPU 的日常工作
- 截面/时间序列/面板回归、DID、事件研究、RDD 等;
- 传统机器学习(Logit/Probit、随机森林、GBM)在中等样本量下也多半够用;
- 使用 Stata/R/Python 做一般的金融计量(资产定价、波动率建模、风险管理);
这些更依赖CPU 性能、内存容量和磁盘 IO,GPU 的作用有限。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献88条内容
已为社区贡献88条内容

所有评论(0)