【前瞻创想】想让你的集群像航母舰队一样听话?带你深度揭秘 Kurator 这一套云原生“大杀器”的底层逻辑和实操指南
【前瞻创想】想让你的集群像航母舰队一样听话?带你深度揭秘 Kurator 这一套云原生“大杀器”的底层逻辑和实操指南
Kurator 就像是一个超级舰队的指挥官。它不是简单的把几个集群捏在一起,而是从全局视角出发,把计算、网络、存储这些资源全给“格式化”了,让你感觉管理成百上千个集群就像管一个集群那么简单。咱们今天不聊那些虚头巴脑的 PPT 概念,就实打实地掏心窝子聊聊这玩意儿到底是怎么设计的,以及怎么把它给耍起来。
一、 别再对着一堆集群抓耳挠腮了,带你看看 Kurator 这套“航母舰队”是怎么排兵布阵的 🏗️
这是Kurator官方文档的组成部分页面,展示了其如何通过预置任务简化Karmada、ArgoCD、Istio等主流云原生工具的集成与部署:
咱们先聊聊云原生“舰队”管理到底是啥高端操作
以前咱们管集群,那是“放羊式”管理,一个集群就是一个山头。但现在的趋势是“云原生舰队管理(Fleet Management)”。啥叫舰队?你看航母出海,有驱逐舰、护卫舰、潜艇,它们各司其职,但都听航母指挥。Kurator 搞的就是这一套,它把所有的 Kubernetes 集群看作是一个整体,不管你的集群是在阿里云、腾讯云还是你自己家里的服务器上,只要进了这个“舰队”,就得听统一的调度。这种管理方式的核心就是消除异构性,让你不再去纠结每个集群底层到底是啥样。
揭秘 Kurator 的核心骨架:这套总体架构到底长啥样?
这是Kurator平台的总体架构图,展示了控制平面、集群网络、成员集群及应用层在统一管理框架下的数据流与组件关系: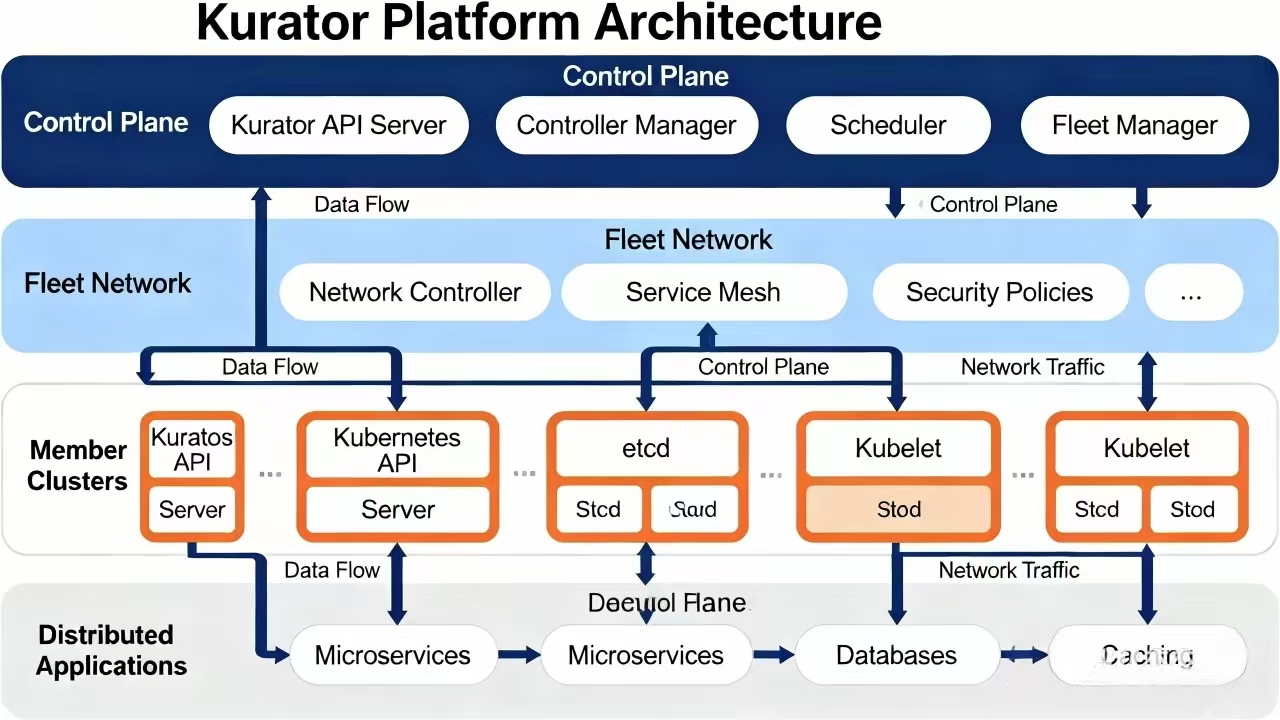
说起 Kurator 平台的总体架构,其实逻辑挺清晰的。它在最上面搞了一层控制平面,也就是咱们常说的“大脑”。这个大脑下面挂着各种 Operator,比如负责集群生命周期的、负责网络治理的、负责存储的。它最牛的地方在于,它把分布在各地的集群抽象成了“成员集群”,然后通过一个中心控制点来下发指令。你不需要登录到具体的某个集群去敲命令,所有的操作都在中心侧完成。这种架构设计最大的好处就是解耦,哪怕某个成员集群挂了,整个舰队的指挥系统还是稳如泰山。
集群里的“总管家”:Cluster Operator 又是怎么干活的?
在 Kurator 内部,有一个非常关键的角色叫 Cluster Operator。你可以把它理解成舰队里的“轮机长”。咱们平时创建一个 K8s 集群,得装各种组件、配网络、调参数,麻烦得要死。Cluster Operator 的实现就是为了把这些脏活累活给自动化了。它基于声明式 API,你只需要告诉它:“我要一个长什么样的集群”,它就会自动去调用底层的接口,帮你把集群给“造”出来,并维护它的健康状态。如果集群里的某个节点宕机了,它能自动感知并尝试修复,这就是所谓的自愈能力,完全不需要人工去盯着。
这张图展示了Cluster Operator的实现细节,其实就是用户通过声明一个CRD,触发API Server事件,然后由Operator监听并调度多个管理worker去自动对接和管理不同的本地集群,整个过程用无密码认证打通,既安全又高效: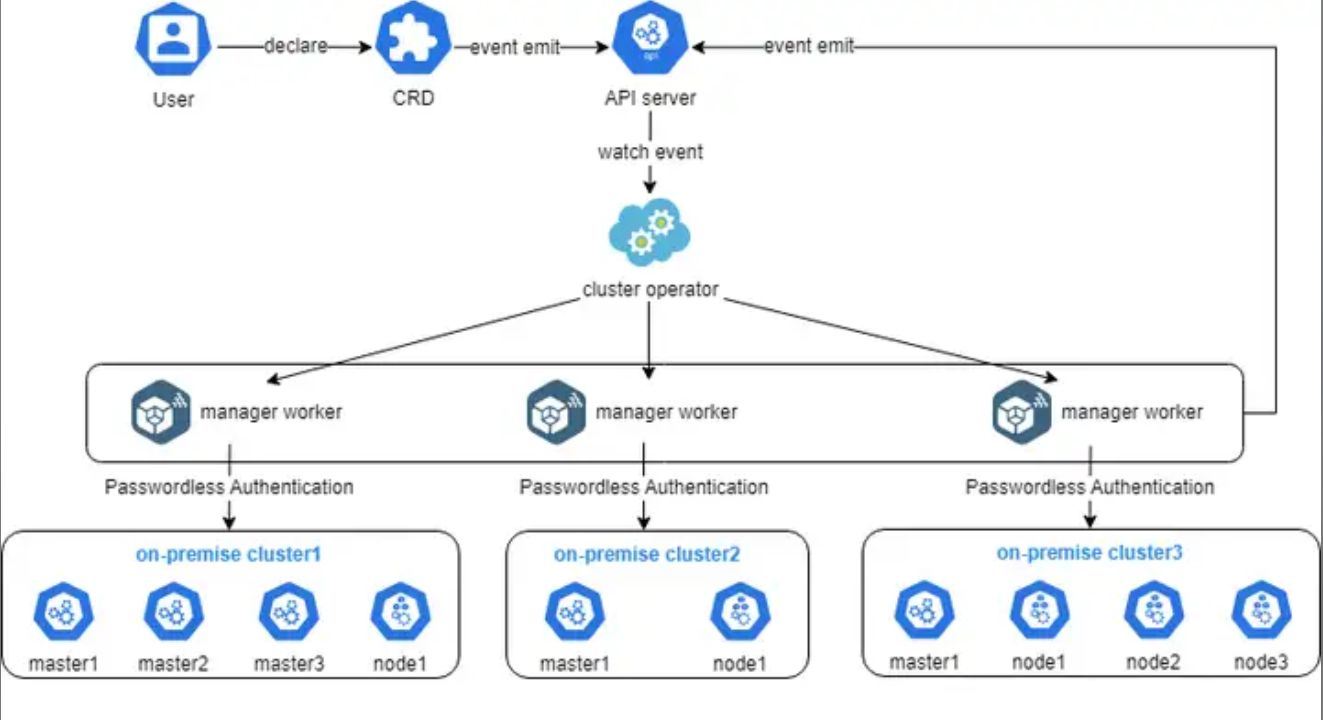
二、 集群多了怎么管?标准架构和 Karmada 联手给你的 K8s 穿上“统一制服” 💂
别乱搞,咱先得把 Kubernetes 集群的标准架构给统一了
这是Kubernetes集群的标准架构参考图,展示了包含控制平面组件、工作节点及云平台集成的完整集群部署模型: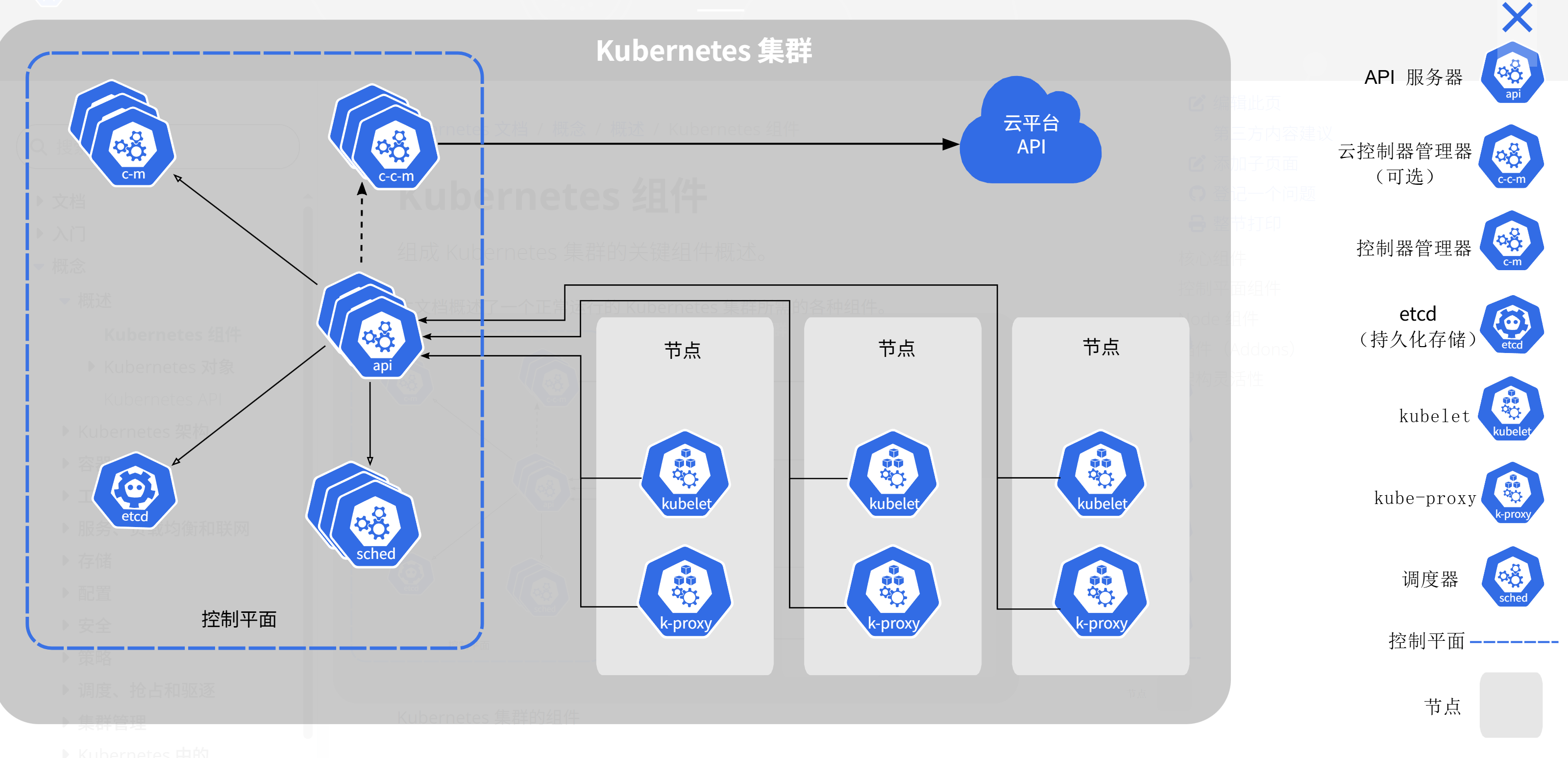
很多人搞多集群失败,就是因为每个集群长得都不一样。有的集群用 Calico 组网,有的用 Flannel,有的版本高,有的版本低。Kurator 强调的是 Kubernetes 集群的标准架构。它推崇一种“模板化”的思路,通过预定义的配置,确保你拉起来的每一个集群从 API Server 到 Kubelet 的配置都是符合行业最佳实践的。这种标准化是多集群管理的前提,如果底座都是歪的,上面的房子(应用)肯定盖不稳。
Karmada 进场:它是怎么在 Kurator 里大显身手的?
聊到多集群调度,就不得不提 Karmada。Kurator 深度集成了 Karmada 实践,把它当作多集群编排的核心引擎。Karmada 的逻辑特别有意思,它允许你把资源定义在中心集群上,然后通过它那套牛掰的调度策略,把这些资源分发到不同的成员集群里。它可以根据集群的剩余资源、地理位置甚至是标签来做调度。在 Kurator 里,你只需要跟 Karmada 的 API 打交道,至于应用最后跑在哪个集群,Karmada 会帮你算得明明白白的。
实战演练:怎么把这些集群真正地集成在一起?
要把一堆散沙一样的集群集成进 Kurator,其实就是个“握手”的过程。Kurator 利用了 Karmada 的多集群管理能力,通过注册机制把成员集群的凭证交给中心集群。在这个过程中,Kurator 还会顺手把一些必要的辅助组件给装上,比如监控代理、日志收集器什么的。这样一来,新加入的集群立马就能进入工作状态,这就叫“开箱即用”。
这是Kurator官网的组件集成页面,展示了其如何简化Karmada、ArgoCD、Istio等主流云原生工具的安装与多集群集成流程。
三、 这就教你上手:先把环境搭起来,再聊聊那套行云流水般的 GitOps 工作流 🚀
手把手教你拉代码:咱们先从 git clone 开始整
我们可以从github上面下载源码,我把源码标注出来啦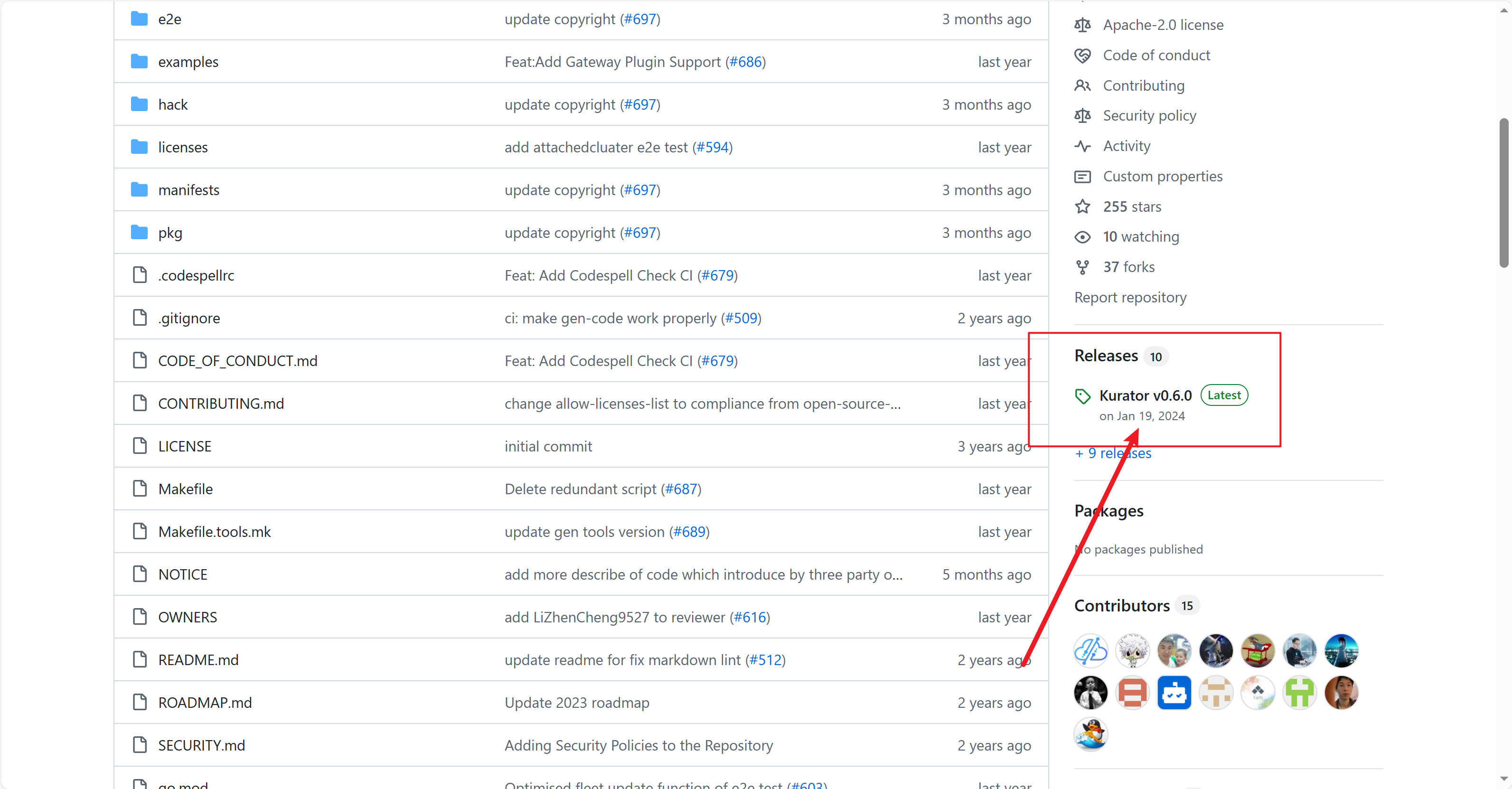
点击后拉到最下面就可以看到源码压缩包啦,不同需求的朋友可以下载不同平台的源码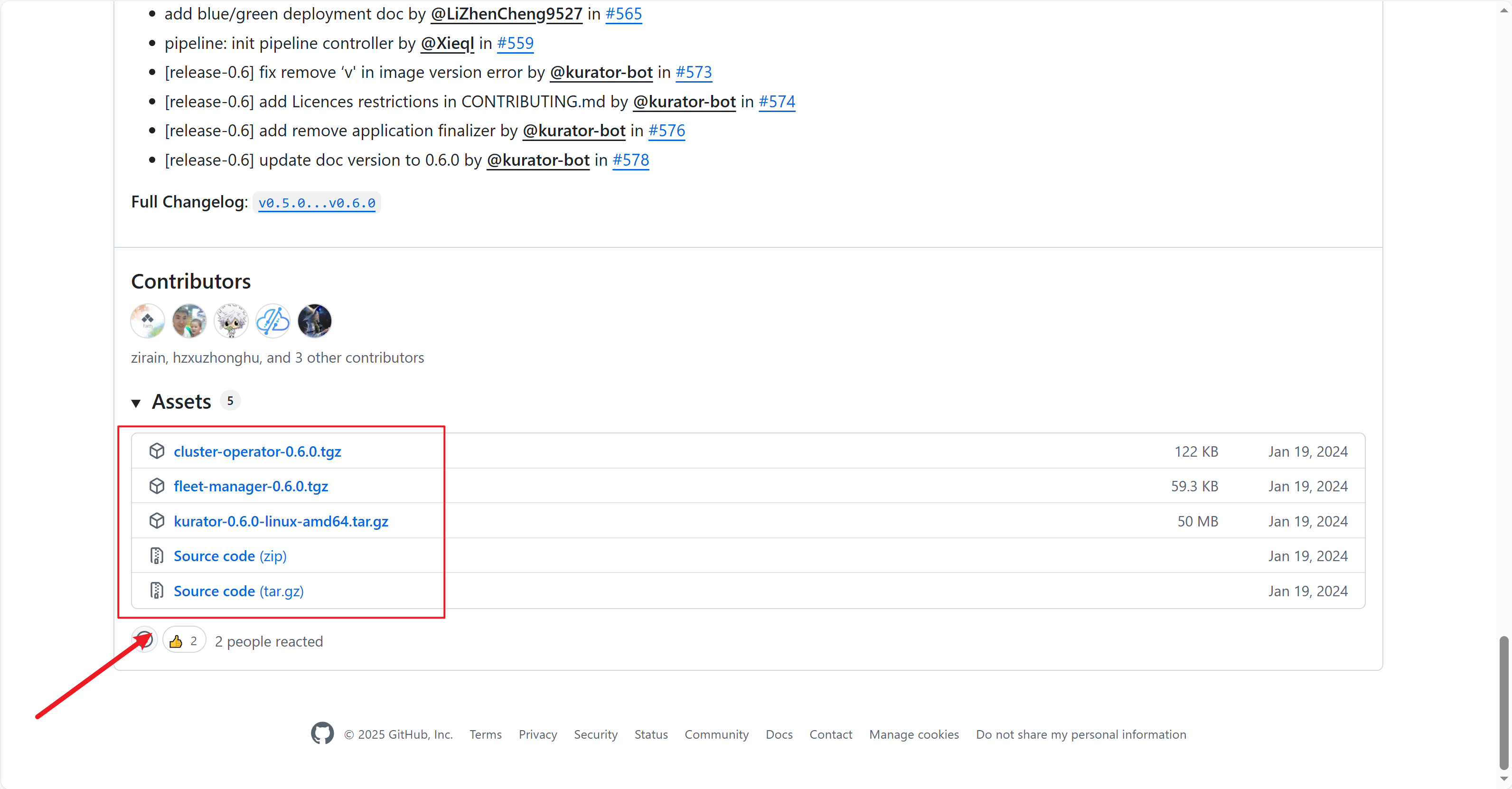
下载下来解压就可以看到源码文件啦
拉下来之后,你会发现里面有一堆目录。别慌,咱们主要是看它的 charts 和 artifacts 目录,那里面藏着部署用的所有宝贝。进入目录后,你会看到一些初始化脚本,按照文档指引跑一下,一个基本的 Kurator 控制平面就能在你的本地集群里立起来了。
GitOps 这套工作流,用了你就再也不想手动改配置了
这是GitOps工作流的官方参考图,展示了从代码提交到镜像构建,最终由GitOps控制器实现集群自动部署的完整流程: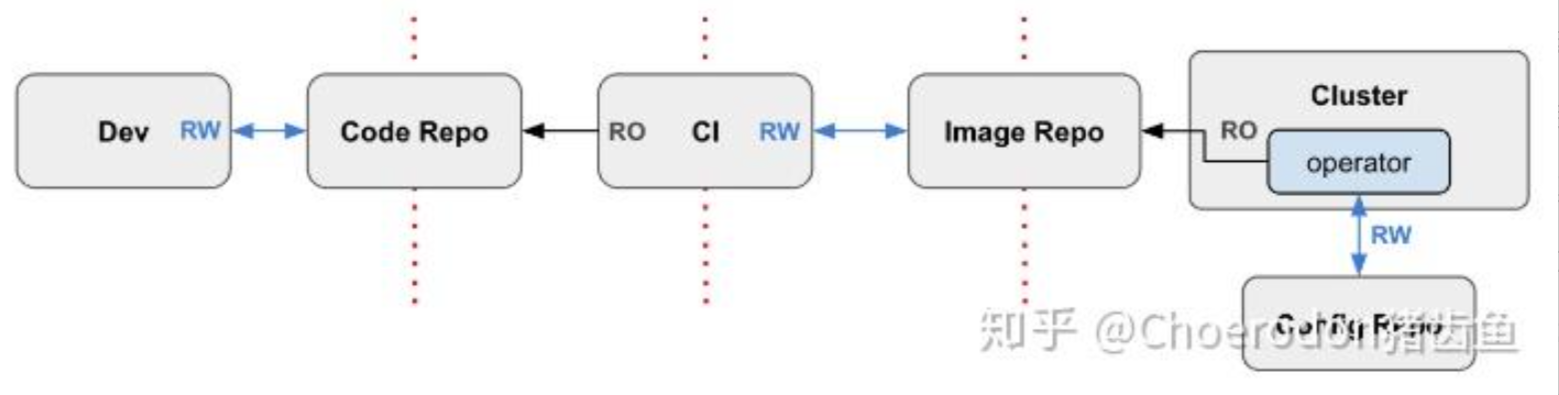
环境搭好后,咱们得聊聊怎么发应用。Kurator 特别推崇 GitOps 工作流。以前咱们发应用,那是手敲 kubectl apply -f,这种方式最大的问题是没记录,万一谁手一抖改错了,想回滚都难。GitOps 的思路是:Git 仓库就是你的“唯一真理来源”。你想改集群配置?去 Git 里提交个 MR(合并请求)。Kurator 内部集成了像 Flux 或者 ArgoCD 这样的工具,它会一直盯着你的 Git 仓库,只要发现代码变了,它就自动把变化同步到集群里。
代码示例 1:手搓一个简单的 GitOps 同步逻辑(伪代码逻辑)
为了让大家理解这个同步过程,我写了一段逻辑,大概意思就是模拟 Kurator 是怎么监听 Git 变化并更新集群的。这部分代码虽然简单,但能让你看清底层的道道:
// 这是一个模拟 GitOps 同步逻辑的小片段
// 主要是演示怎么检测 Git Hash 的变化并触发集群更新
func syncGitToCluster(repoURL string, currentClusterState string) {
// 1. 模拟从 Git 仓库拉取最新的 Commit ID
latestCommit := fetchLatestCommit(repoURL)
fmt.Printf("检测到最新代码版本: %s\n", latestCommit)
// 2. 对比当前集群里跑的版本
if latestCommit != currentClusterState {
fmt.Println("发现版本不一致,开始启动自动同步程序...")
// 3. 模拟解析 YAML 文件
manifests := parseManifestsFromGit(repoURL)
// 4. 将配置应用到多个集群中
for _, cluster := range fleet.GetClusters() {
fmt.Printf("正在向集群 [%s] 推送最新配置...\n", cluster.Name)
applyToCluster(cluster, manifests)
}
fmt.Println("同步任务圆满完成!")
} else {
fmt.Println("集群状态与 Git 仓库一致,不需要折腾。")
}
}
四、 应用分发和网络治理:怎么让服务在成百上千个集群里“指哪打哪” 🌐
Kurator 统一应用分发的管理架构:不管多少集群,一挥手全搞定
这张图展示了Kurator统一应用分发的管理架构,实现跨多集群的一致化部署和管理,整个流程简单又可控: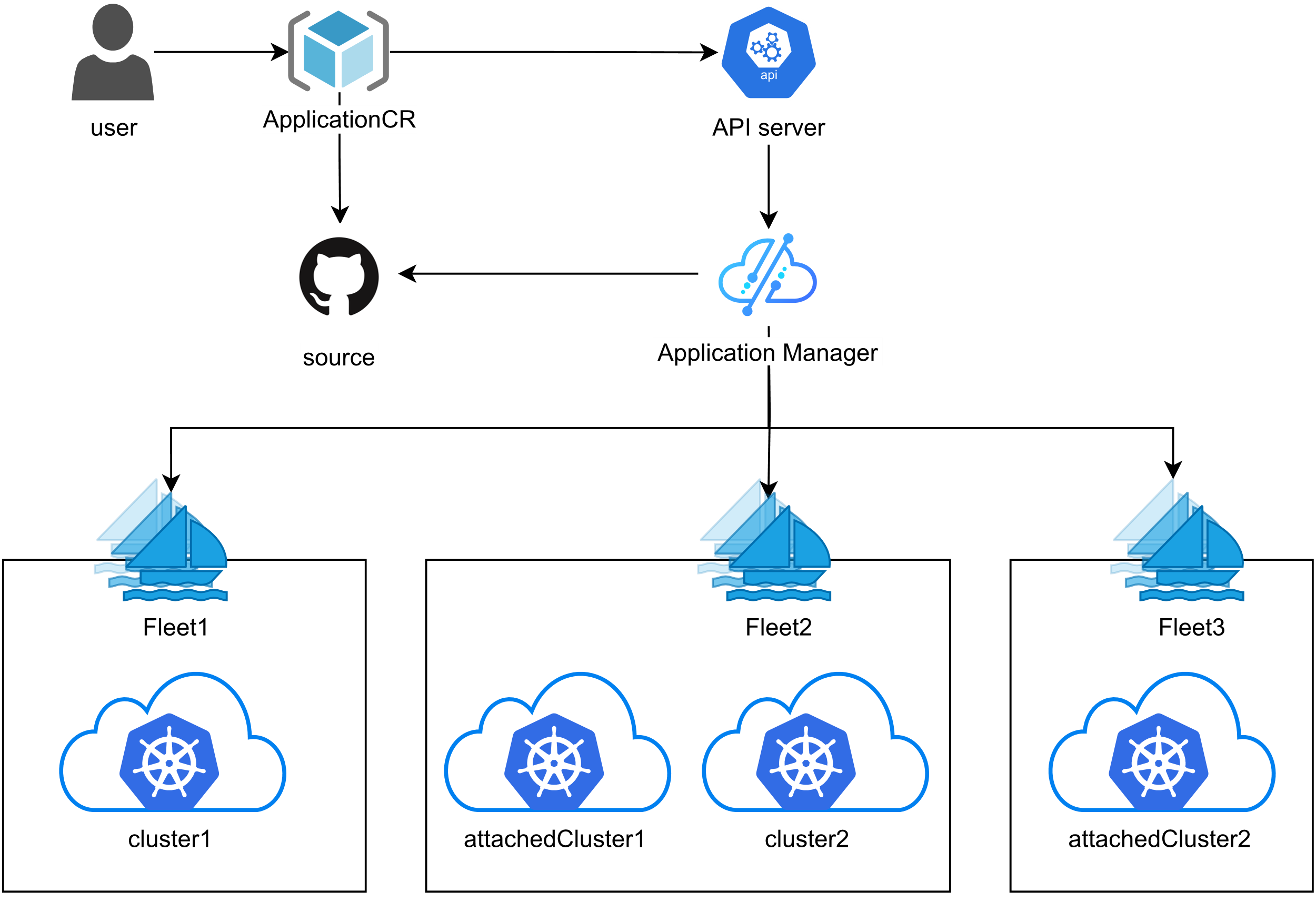
在多集群环境下,发应用是个技术活。Kurator 搞了一套统一应用分发的管理架构。它把应用定义抽象成了一个“多集群应用”对象。你只需要定义一次,它就能帮你分发到北京、上海、甚至美国的集群里。而且它还支持差异化配置,比如北京的集群规格高,你可以配多几个副本;上海的集群规格低,就配少一点。这一套动作下来,完全不需要你去关心底层的差异。
Fleet 队列里的“服务相同性”:为什么我们要让服务长得一模一样?
这块儿是个硬核知识点——Fleet 队列中服务相同性(Service Sameness)。在舰队管理里,我们希望 namespace-a 里的 service-b 无论在哪个集群,它代表的都是同一个逻辑服务。这样当一个服务想调用另一个服务时,它不需要知道对方在哪个集群,只需要按名字调就行。Kurator 通过这一机制,把所有的集群连成了一个巨大的服务网格,真正实现了地理位置透明。
Istio 服务网格:这套网络架构是怎么把所有服务串起来的?
为了搞定复杂的跨集群通信,Istio 服务网格的完整架构被塞进了 Kurator。它不仅处理流量转发,还负责安全加密(mTLS)和可观测性。在 Kurator 里,Istio 是以多集群网格的模式运行的。这意味着你可以跨集群做负载均衡。比如你发现 A 集群的某个服务压力太大了,你可以直接通过 Istio 把一部分流量导到 B 集群去,这种灵活性在以前是想都不敢想的。
代码示例 2:用 Istio 配置个 A/B 测试路由(手搓感)
既然有了 Istio,咱们不玩点高级的 A/B 测试都对不起这配置。下面这段 YAML 是我手搓的,用来演示怎么在 Kurator 管理的舰队里,给不同的用户展示不同的版本。
# 这是一个用于 A/B 测试的 Istio 虚拟服务配置
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: user-service-route
spec:
hosts:
- user-service
http:
- match:
- headers:
user-type:
exact: "vip" # 咱们的 VIP 用户优先体验新版本
route:
- destination:
host: user-service
subset: v2-new-feature # 对应新版镜像
- route:
- destination:
host: user-service
subset: v1-stable # 普通用户还是用老版本,稳一点
五、 不只是应用,存储也得“大一统”:聊聊基于 Rook 的分布式存储架构 💾
Kurator 的存储野心:怎么把分布式存储整成统一的一盘棋?
应用能漂移了,网络通了,那数据怎么办?如果你的数据死死地绑在某一台机器上,那你的多集群架构就是半吊子。Kurator 的统一分布式存储架构就是为了解决这个问题。它认为存储不应该只是某个集群的私产,而应该是整个舰队共享的资源池。这样不管你的应用漂移到哪,数据都能像影子一样跟过去。
基于 Rook 构建的 Fleet 统一分布式存储的架构,到底稳在哪?
为了实现这个野心,Kurator 选择了 Rook。Rook 这玩意儿特别聪明,它把 Ceph 这种复杂的分布式存储给搬到了 Kubernetes 里。在 Kurator 的设计中,Fleet 基于 Rook 构建统一分布式存储的架构。它在整个舰队层面去编排存储节点。简单说,就是把所有集群里闲置的磁盘全给抠出来,整合成一个巨大的存储池。这样做的好处是显而易见的:第一是稳,数据多副本存放,坏几个盘没压力;第二是快,本地读写性能杠杠的;第三是省心,全自动化管理。
代码示例 3:定义一个存储池的配置逻辑(手搓感)
最后,我写了一小段配置逻辑,演示一下咱们是怎么在 Kurator 里通过 Rook 把存储资源给“整活”的。这部分虽然看起来像配置,但其实是定义了整个存储系统的灵魂。
// 模拟定义一个 Rook 存储池的逻辑块
// 主要是为了控制副本数和存储性能
type StoragePoolConfig struct {
PoolName string
ReplicaNum int // 副本数,为了安全咱们一般整 3 个
DiskType string // SSD 还是 HDD,得看业务需不需要起飞
}
func provisionFleetStorage() {
// 实例化一个金牌存储池配置
myGoldPool := StoragePoolConfig{
PoolName: "fleet-data-pool",
ReplicaNum: 3,
DiskType: "NVMe-SSD", // 用最好的盘,跑最猛的数据
}
fmt.Printf("正在初始化舰队统一存储池: %s...\n", myGoldPool.PoolName)
// 模拟调用 Rook Operator 的接口去创建存储池
if err := rookOperator.CreatePool(myGoldPool); err != nil {
fmt.Println("存储池创建失败,检查一下磁盘是不是没插好?")
return
}
fmt.Println("分布式存储架构已就绪,现在应用可以随便写数据了!")
}
写到这儿,估计你对 Kurator 已经有个大概的轮廓了。其实云原生这事儿,说白了就是想尽一切办法把复杂的东西变简单。Kurator 做的就是把多集群管理这头怪兽给关进笼子里,通过标准化的架构、自动化的 Operator、还有 GitOps 这种时髦的玩法,让咱们这些苦哈哈的运维和开发能过上几天安生日子。
以后别再说多集群难管了,先把环境搭起来,按我上面说的这些点去琢磨琢磨。Kurator 的坑虽然也不少,但比起你自己手搓一套多集群系统,那绝对是省了老命了。怎么样,有没有兴趣回头去试试?如果你在配置 A/B 测试或者搞 Rook 存储的时候遇到了什么奇葩问题,记得来找我聊聊,咱们一起填坑。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)