【探索实战】从 AI & 数据平台 / MLOps 视角看 Kurator:让分布式云原生成为“训练—推理—边缘”一体化底座
metadata:spec:clusters:Fleet:把训练/推理/边缘变成统一治理单元Volcano:让 AI 作业成为可全局排队/溢出的资源消费者GitOps:让模型与服务一次提交多域同步Istio:让推理灰度、A/B、多活策略可版本化统一监控:把训练—推理链路纳入同一指标口径统一策略:让 AI 合规与资源边界自动生效模型跑在哪、怎么发、怎么灰、怎么回、怎么省钱,全都不再是“多集群手工活”
1. 视角切换:为什么要从 AI/MLOps 看 Kurator?
如果你回忆过去 2~3 年企业云原生的升级路线,会发现一个趋势很明显:
“分布式云原生”不再只服务于 Web/微服务,而是越来越被 AI & 数据工作负载牵着走。
AI 时代的基础设施有三个典型特征:
-
训练集中、推理分布
- 训练(Batch/AI Job)多在云上或算力中心
- 推理(Serving)要贴近用户,可能分布在多云、IDC、边缘
-
任务类型混合
- 微服务(在线)
- 批处理 / ETL(离线)
- GPU/AI 训练(重计算)
- 边缘推理(低延迟)
-
资源/成本敏感
- GPU 贵、跨云流量贵、训练窗口有限
- 调度、统一观测、统一策略,直接决定钱烧得快不快
Kurator 的定位是“开源分布式云原生平台”,用 Fleet(舰队)统一多集群治理,并集成 Kubernetes、Istio、Prometheus、Karmada、KubeEdge、Volcano、Kyverno、FluxCD 等主流开源栈,提供统一编排、统一交付、统一流量、统一监控、统一策略等能力。
从 AI/MLOps 的角度看,Kurator 值得关注的点不是“又一套多集群平台”,而是:
它能把 AI 的“训练—推理—边缘”链路,变成可统一交付、统一调度、统一治理的一张网。
而且,Kurator也在热门开源项目之一:
2. AI 时代的分布式云原生痛点:不是“多集群”,是“多形态”
对 AI/数据平台团队来说,真实问题往往长这样:
2.1 训练集群与在线集群割裂
- 训练在 GPU 集群(云 A)
- Serving 在在线集群(云 B / IDC)
- 数据处理在离线集群(云 C)
结果是:
- 版本不一致
- 监控不统一
- 模型发布跨集群靠手工搬运
2.2 训练作业调度缺乏全局视角
- 每个集群自己排队、自己抢 GPU
- AI 作业无法跨集群“挑便宜算力/空闲算力”
- 峰值期 GPU 空转与拥塞并存
2.3 边缘推理规模化困难
- 边缘节点多、网络差
- 升级、回滚、策略下发要逐集群做
- 推理服务在边缘与云上的配置经常漂移
2.4 观测与策略无法一体化
- 训练、Serving、边缘三套监控
- 安全合规策略手工同步
- 成本指标与性能指标无法统一对比/归因
这些痛点的根源不是“集群多”,而是“工作负载形态多且分散”。Kurator 的 Fleet 抽象与一栈式集成,就是应对“多形态分布式云原生”的一条路。
3. Kurator 在 AI 场景里的“关键能力重命名”
为了更贴近 MLOps 语言,我们把 Kurator 的功能重新映射一下:
| Kurator 能力 | AI/MLOps 语境里的价值 |
|---|---|
| Fleet 多集群编组 | “训练域/服务域/边缘域”的统一抽象 |
| Cluster Operator 生命周期 | GPU/边缘集群批量创建、升级、回收 |
| GitOps + FleetApplication | 模型/服务“一次提交,多域发布” |
| Istio 统一流量治理 | 多地域推理灰度、A/B、蓝绿 |
| Prometheus + Thanos 统一监控 | 训练与推理的全局观测、对比、归因 |
| Kyverno + FleetPolicy | 训练/推理/边缘的安全与资源合规基线 |
| Volcano(内置集成) | AI/批处理作业的队列化调度(关键!) |
| Karmada / KubeEdge(内置集成) | 跨集群调度与边缘治理的底座能力 |
如下是该Kurator的开源截图:
4. 入门体验:搭一个“训练—推理—边缘” Kurator 实验室
这一段用最小可跑拓扑帮你“入门体验 + 明确架构脑图”。
4.1 最小拓扑
- 管理集群(host):部署 Fleet Manager、统一监控控制面
- 成员集群 1:train-gpu(云上 GPU 集群)
- 成员集群 2:serve-online(云/IDC 在线推理集群)
- 成员集群 3:edge-infer(边缘推理集群)
它们被 Kurator 编组到一个 Fleet:ai-fleet。
4.2 一条 Fleet 定义三域
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: ai-fleet
namespace: kurator-system
spec:
clusters:
- name: train-gpu
- name: serve-online
- name: edge-infer
4.3 安装时的小坑(AI 场景特有)
-
GPU 驱动 / device plugin 版本差异
- train-gpu 往往先装了 NVIDIA Operator
- Kurator 内置 addon 若重复装容易冲突
建议:在 Kurator 安装参数里关闭 GPU 相关重复组件,只保留治理逻辑。
-
边缘 API 连通性
边缘节点网络不稳时,Fleet 状态会抖动。
做法:- 网络层做 VPN/专线或边缘网关汇聚
- 边缘集群加入 Fleet 前,先通过健康检查脚本验证 API 连通。
-
CRD 版本兼容
AI/批处理常用 CRD(Volcano、KServe、Kubeflow)版本必须与 Kurator 一栈式组件的版本矩阵对齐。
评估阶段尽量统一升级到 Kurator 推荐主线版本。
5. 单功能深用 ①:Volcano + Fleet —— AI 训练作业的“全局队列调度”
Kurator 集成 Volcano 用于批处理和 AI 任务调度,这是 AI 场景最核心的“加速器”能力之一。
5.1 场景:同一模型训练要跨集群抢 GPU
假设你有两类 GPU 资源:
- 云上 train-gpu(A100,贵但强)
- IDC-gpu(V100,便宜但稍慢)
你希望:
- 训练任务优先用空闲的 IDC-gpu
- 队列拥塞时再溢出到云上
- 并且这套逻辑对平台透明、可复用
5.2 Volcano Queue(示例)
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: train-queue
spec:
weight: 1
reclaimable: true
capability:
cpu: "200"
memory: "800Gi"
nvidia.com/gpu: "64"
5.3 训练 Job(VolcanoJob 示例)
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
metadata:
name: resnet50-train
namespace: ml
spec:
queue: train-queue
minAvailable: 1
tasks:
- name: trainer
replicas: 4
template:
spec:
containers:
- name: trainer
image: registry.internal/ml/resnet-trainer:v2
resources:
limits:
nvidia.com/gpu: 1
cpu: "8"
memory: "32Gi"
restartPolicy: OnFailure
5.4 Kurator 的加成是什么?
在没有 Kurator 时,Volcano 只能在单集群内调度。
有了 Kurator + Fleet +(Karmada 多集群能力)后,你可以:
- 在 Fleet 级定义“训练域队列”
- 通过 GitOps 一次分发到多个 GPU 集群
- 用 Fleet 标签(如
gpu-tier=cheap/fast)做跨集群溢出策略
这意味着:
你的训练平台第一次有了“全局 GPU 池”的可能性。

6. 单功能深用 ②:FleetApplication + GitOps —— 模型与推理服务“一次提交,多域发布”
Kurator 的 Fleet + FluxCD GitOps 机制,天然适合做 MLOps 的 模型发布流水线。
6.1 Git 仓库结构:训练产物 + Serving 产物同源
mlops-gitops/
models/
resnet50/
version.yaml
artifact-uri.txt
serving/
resnet50/
base/
deployment.yaml
service.yaml
overlays/
serve-online/
edge-infer/
fleets/
resnet50-serving-fleetapp.yaml
6.2 FleetApplication:推理服务跨集群发布
apiVersion: fleet.kurator.dev/v1alpha1
kind: FleetApplication
metadata:
name: resnet50-serving
namespace: kurator-system
spec:
fleetRef:
name: ai-fleet
gitRepositoryRef:
name: mlops-gitops
targets:
- cluster: serve-online
path: ./serving/resnet50/overlays/serve-online
- cluster: edge-infer
path: ./serving/resnet50/overlays/edge-infer
syncPolicy:
automated:
prune: true
selfHeal: true
6.3 发布模型的动作变成什么?
- 训练完成 => 往 Git 写入新模型版本文件
- PR 合并 => FleetApplication 自动扩散 Serving
- 回滚 => revert 模型版本文件,推理服务自动回滚
这就是“模型即代码(Model as Code)”的工程实践。
7. 单功能深用 ③:Istio + Fleet —— 推理灰度、A/B 与多地域路由
Kurator 内置 Istio 做统一流量治理,可用于推理服务的 Canary / A/B。
7.1 场景:线上推理要跑 A/B Test
你要对比 resnet50 v2 与 v3 的业务效果:
- 线上集群分 90/10 给 v3
- 边缘集群先不给 v3(观察稳定性)
Istio VirtualService(示例):
apiVersion: networking.istio.io/v1beta1
kind: VirtualService
metadata:
name: resnet50
namespace: ml
spec:
hosts:
- resnet50.ml.svc.cluster.local
http:
- route:
- destination:
host: resnet50
subset: v2
weight: 90
- destination:
host: resnet50
subset: v3
weight: 10
DestinationRule(示例):
apiVersion: networking.istio.io/v1beta1
kind: DestinationRule
metadata:
name: resnet50
namespace: ml
spec:
host: resnet50
subsets:
- name: v2
labels:
version: v2
- name: v3
labels:
version: v3
通过 Fleet 扩散:
serve-online集群应用 A/B 规则edge-infer集群保持 100% v2
一旦 v3 验证通过,再把同一规则扩散到边缘 Fleet。
8. 单功能深用 ④:Prometheus/Thanos + Fleet —— 训练与推理的统一可观测
Kurator 一栈式监控(Prometheus+Thanos+Grafana)把多集群指标统一归集,便于训练/推理联动分析。
8.1 你终于可以回答这些 AI 平台问题
- 训练完成后,推理 P95 延迟有没有恶化?
- 不同集群 GPU 利用率对比如何?
- 模型 v3 在边缘上的错误率是不是更高?
- 训练/推理链路的成本与效果有没有关联?
这些都需要“全局统一指标口径 + 多集群对比”,Kurator 给了默认能力。
9. 单功能深用 ⑤:Kyverno + FleetPolicy —— AI 场景的安全/资源基线一次套齐
Kurator 的 Fleet 策略管理基于 Kyverno。
9.1 示例:强制训练作业必须声明 GPU/资源限制
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: require-gpu-limits
spec:
validationFailureAction: enforce
rules:
- name: validate-gpu
match:
any:
- resources:
kinds: ["Pod"]
namespaces: ["ml"]
validate:
message: "ML pods must request GPU and set cpu/memory limits."
pattern:
spec:
containers:
- resources:
requests:
nvidia.com/gpu: "?*"
cpu: "?*"
memory: "?*"
limits:
nvidia.com/gpu: "?*"
cpu: "?*"
memory: "?*"
9.2 FleetPolicy 扩散到训练域 + 推理域
apiVersion: policy.kurator.dev/v1alpha1
kind: FleetPolicy
metadata:
name: ml-baseline
namespace: kurator-system
spec:
fleetRef:
name: ai-fleet
policies:
- name: require-gpu-limits
source:
gitRepositoryRef:
name: mlops-gitops
path: ./policies/require-gpu-limits.yaml
10. 案例实战:某智能制造企业的“训练—推理—边缘” Kurator 落地纪实
企业与数据为合理虚构,但情节高度贴近真实项目。
10.1 背景
“启星制造”是一家智能制造企业:
- 工厂有 40+ 边缘站点(摄像头/传感器)
- 云上有 2 套 GPU 训练集群(不同云)
- IDC 有生产在线推理集群
- 目标:把缺陷检测模型从“月更”提升到“周更/日更”
10.2 关键问题
- 边缘站点推理版本经常落后
- 模型训练与上线链路断裂
- GPU 算力成本高且利用率低
- 观测无法覆盖训练->推理全链路
- 合规要求(镜像源、特权容器)落地慢
10.3 Kurator 落地路径(四阶段)
阶段 1:Fleet 分域
fleet-train:两个云上 GPU 集群fleet-serve:IDC 推理集群fleet-edge:40+ 工厂边缘集群fleet-canary:2 个边缘站点做灰度池
阶段 2:训练调度全局化
- Fleet-train 下统一下发 Volcano Queue
- 训练任务优先走低价云/空闲云
- 高峰溢出到昂贵云
- 训练等待时间下降明显
阶段 3:模型 GitOps 化
- 每次训练产出进入 Git 仓库
- FleetApplication 自动扩散到 serve/edge
- 灰度站点先验证,再全量边缘扩散
阶段 4:全局观测与策略基线
- Thanos 聚合训练 + 推理 + 边缘指标
- Kyverno 策略全域 enforce
- SLA/SLO 用 Fleet 大盘统一核算
10.4 成果(虚构但合理)
- 模型发布周期:30 天 => 5 天
- 边缘版本一致率:78% => 99%
- GPU 利用率提升:+22%
- 单次训练成本下降:约 15%
- 事故回滚耗时:40 分钟 => 5 分钟(Git revert + Fleet 扩散)
10.5 生态与商业价值
- 工厂侧缺陷漏检率下降,带来直接质量收益
- “模型周更能力”成为企业数字化卖点
- 平台团队能与 Kurator 社区协同演进
11. Kurator 前瞻创想(AI 方向):从“统一治理”走向“智能化全局调度”
Kurator 已经把多集群 AI 基础能力“凑齐并统一体验”。
下一步,我认为 AI 场景有三条清晰路标:
- 成本/功耗感知训练调度
- 边缘自治推理
- 模型效果闭环调度
Kurator 依托 Karmada/KubeEdge/Volcano 等优秀项目的集成框架,本质上给这些方向留了很大的演进空间。
最后,我们纵观下Kurator产品的架构图:
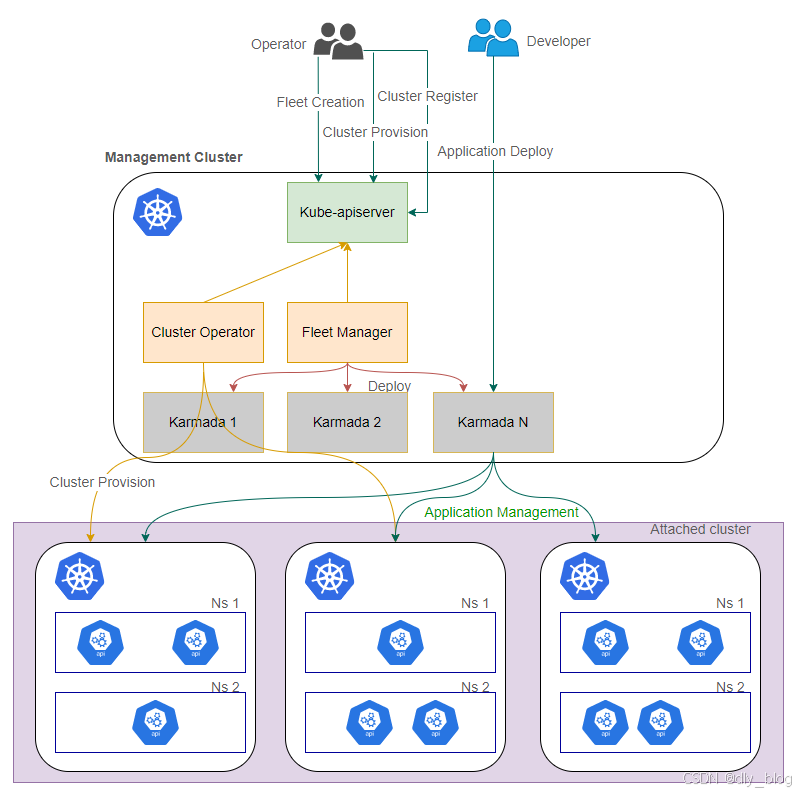
12. 结语:Kurator 让 AI 分布式云原生“从可用到好用,再到可持续”
从 AI/MLOps 角度回看 Kurator 的价值链:
- Fleet:把训练/推理/边缘变成统一治理单元
- Volcano:让 AI 作业成为可全局排队/溢出的资源消费者
- GitOps:让模型与服务一次提交多域同步
- Istio:让推理灰度、A/B、多活策略可版本化
- 统一监控:把训练—推理链路纳入同一指标口径
- 统一策略:让 AI 合规与资源边界自动生效
最终实现一句话:
模型跑在哪、怎么发、怎么灰、怎么回、怎么省钱,全都不再是“多集群手工活”,而是 Fleet 级工程默认值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)