一人单挑Transformer神话,RNN卷土重来,Transformer何去何从?
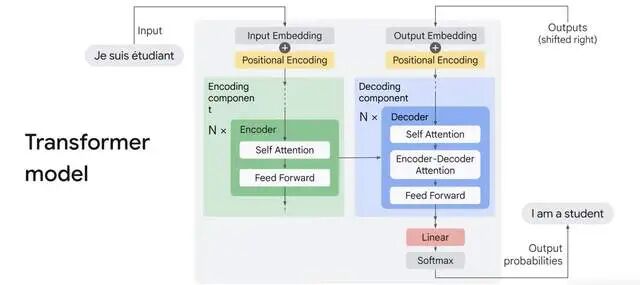
在 Transformer 已统治 AI 世界七年的今天,几乎没人再质疑它的地位。无论是 GPT-5、Claude 4.5,还是 Gemini 2.5,全都建立在同一个信条上——“Attention is all you need.”
在 Transformer 已统治 AI 世界七年的今天,几乎没人再质疑它的地位。无论是 GPT-5、Claude 4.5,还是 Gemini 2.5,全都建立在同一个信条上——“Attention is all you need.”
但一篇由独立研究者 Michael Keiblinger 发表的论文,正面撕开了这个信条的漏洞。论文题为《Recurrence-Complete Frame-based Action Models》(简称 FBAM),作者犀利指出:这玩意儿在长序列代理任务(比如软件工程AI)上,就是个浅层电路,遇到真正需要“串行深度”的问题,直接崩盘!

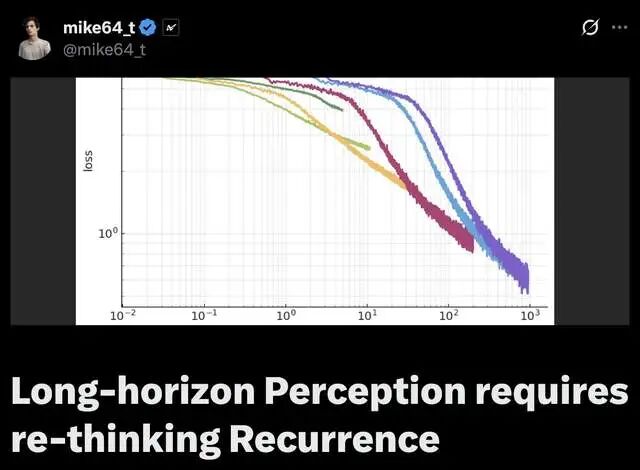
论文用数学证明 + 合成实验 + 海量GitHub数据,证明:真正的递归(RNN/LSTM)才是王道。固定参数下,更长序列训练loss幂律暴跌,wall-time还更高效!作者一句话概括他的反叛理由:
“注意力不是你唯一需要的,你还需要‘真正的深度’。”直接一锤子砸碎了Transformer的“Attention is All You Need”神话!
Transformer的致命伤:并行化=自杀,深度恒定=短命
Transformer神话崩塌现场:
“Attention is All You Need”? 作者直球怼:Need RNN! 论文证明:任何前向/后向全并行化模型(Transformer、Mamba、RWKV、S4等)都不是recurrence-complete(无法模拟任意递归更新)。
为什么? 它们是恒定深度电路(O(1)真深度),序列长n时,n/L(序列/层数)爆炸,输入聚合直接失效!输入聚合关键性(Input Aggregation Criticality):长序列需要Θ(n)串行步骤聚合隐藏状态。Transformer?最多c*L步,超了就崩!(c是常数,L层数固定)。
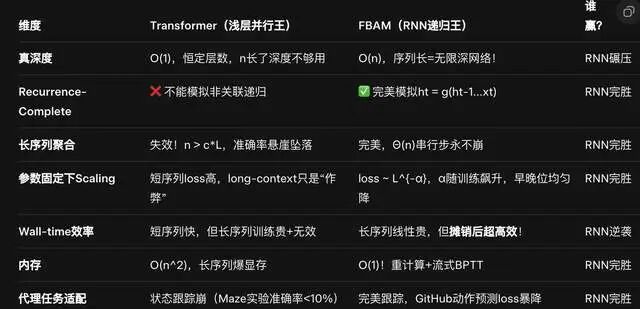
作者吐槽: “Transformer像mean(),简单平均;RNN像reduce(relu(matmul)),层层非线性堆叠。8层Transformer vs. 1层RNN?前者就是1层伪装的!”
证明铁证:
-
No Free Lunch for Parallelism:并行训练=牺牲递归完整性。
-
合成任务(FRJT/Maze):Transformer/Mamba在n=1000崩盘(准确率<5%),1层LSTM稳到n=10k(准确率>95%)。
-
FRJT:前向跳转程序,串行指针追逐,Transformer并行算不出来!
为什么 Transformer 不够“深”?
Keiblinger 的核心论点是:Transformer 其实是一种浅层、恒定深度的电路。
无论输入序列多长,它都在用固定数量的计算层去处理每个 token。这种并行机制虽然高效,却意味着它无法像人类一样“逐步思考”。
论文中,他提出了两个关键概念:
真正的深度(True Depth)
指模型中必须串行执行的运算层数。Transformer 的深度是常数 O(1),而循环神经网络 (RNN) 的深度随序列长度线性增长 O(n)。
递归完备性(Recurrence Completeness)
一个模型只有当它能表达任意递归关系 hₜ = g(hₜ₋₁, xₜ) 时,才能算真正“具备记忆”。
Transformer 及其所有并行化变种(Mamba、S4、RWKV 等)都不满足这一条件。
换句话说:Transformer 在时间维度上是“失忆”的。它靠注意力“回头看”,却从不真正“积累”理解。
作者的新武器:FBAM模型:Transformer+ LSTM的“黄金混血”,专治长序列代理
作者没扔掉Attention! FBAM= Frame-Head (Transformer) + Temporal Backbone (LSTM栈)。Keiblinger 提出的 Frame-based Action Model(帧动作模型),本质上是一个“复合体”:
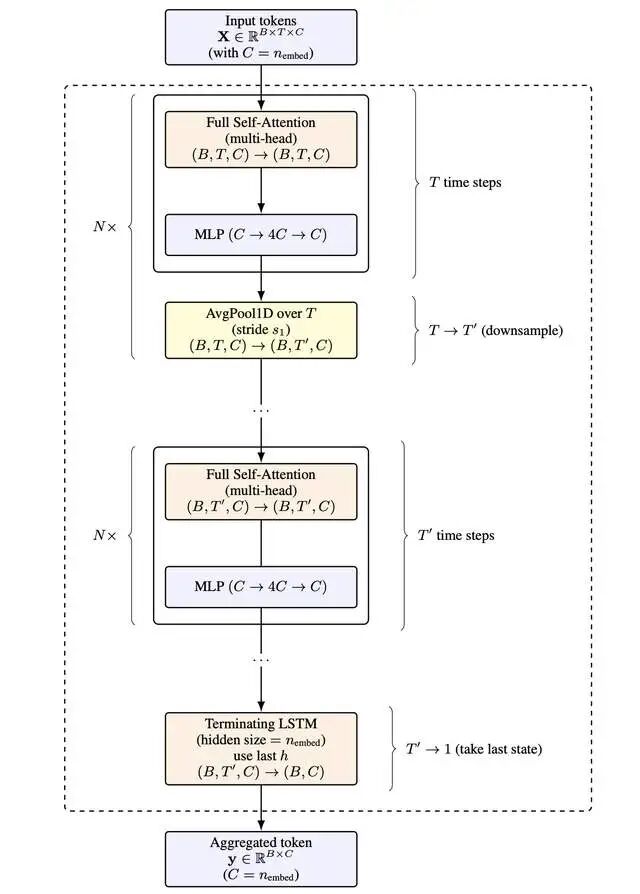
这种架构的思路很大胆:
-
让 Transformer 专注于“空间理解”,
-
让 RNN 重新掌管“时间记忆”。
最终形成一个能随序列长度自动加深的混合模型。作者称其为“递归完备”,可在 O(1) 显存下完成超长序列训练。
Frame-Head:每个“帧”(终端2D网格,像文本视频)用Transformer嵌入+池化。Attention只管局部帧内,高效! 无需分词,下采样原生。Frame Head(帧头),用 Transformer 去理解单帧内容(例如一屏终端文字或一帧视频)。
LSTM积分器:串行聚合帧嵌入,输出下一个动作(keystroke)。深度随序列无限增长!Main Sequence Model(主序模型),用 LSTM 串行整合帧间信息,恢复时间的连续性。
数据神作:
从GitHub历史自动重建编辑器会话,生成10^5+帧序列(termstreamxz格式,终端帧+动作)。覆盖编译器、代码仓库,模拟真人敲代码!
训练黑科技:流式BPTT + 重计算:显存O(1),序列10k无压力。隐藏状态分页到磁盘,NVMe硬盘藏不住传输延迟。
结果爆炸:
-
幂律Scaling:loss(L) ≈ A * L^{-α(s)},α从0.1飙到0.5+!固定参数,L=10k loss降50%。
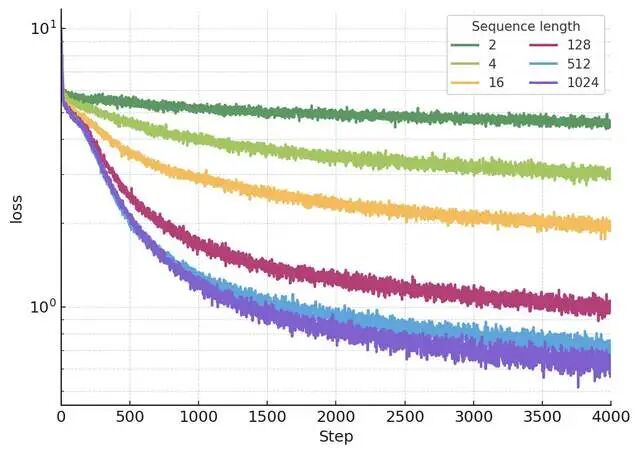
2.Wall-time摊销:短序列(L=1k)起步快,但L=10k后彻底反超,loss/wall-time曲线:长序列永胜!
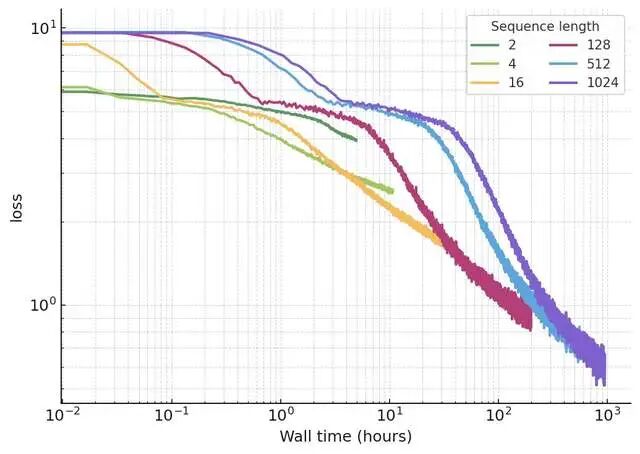
3.均匀提升:不像LM只帮尾巴token,早中晚位全降loss=真状态聚合,非“多token作弊”
为什么RNN卷土重来?代理时代,Transformer已过时
代理任务痛点:AI敲代码、浏览器操作=部分观测+隐藏状态+副作用。文件diff、游标位置?全靠串行簿记!
Chain-of-Thought nuance:文本scratchpad有用,但感知聚合仍靠模型。Transformer长流=瞎聚合。
视频论据:视频帧序列同理,Transformer长视频状态丢了。
任务,TransformerLoss,FBAMLoss,差距
GitHub编译器动作,2.5,1.2,52%降
Diff-Inflate-Bench,3.1,1.8,42%降
技术卓越数据集,2.8,1.4,50%降作者预言: “序列10^5时,FBAM=1024层网络!参数不变,深度无限。Transformer加层=每个token多付钱,算力不够呀”
实验结果:Transformer 输在“时间感”
论文中的两个关键实验堪称痛击 Transformer 的证据:Forward-Referencing Jumps Task(前向跳转任务)模拟程序执行中严格的数据依赖。结果显示:
-
Transformer 在8 层深度后准确率崩塌;
-
Mamba 稍好,但仍需成倍堆层才能维持性能;
-
1 层 LSTM 轻松保持 > 94% 准确率。
Maze Position Tracking(迷宫追踪任务):
当部分移动结果被“隐藏”时(需要记忆状态),Transformer 和 Mamba 的性能急剧下降,只有 LSTM 能稳定追踪到最终位置。Keiblinger 将这类问题称为输入聚合临界点(Input Aggregation Criticality):
当序列长度 n 超过模型的真实串行深度 L 时,Transformer 会失去聚合能力——模型“看得到”,但“记不住”。

结果:序列长度越长,模型越强
在相同参数下,FBAM 的训练损失与序列长度 L 呈现幂律下降:
Loss ≈ A × L^-α,且 α 随训练时间上升到 ≈ 0.3。
更惊人的是:虽然更长序列训练步耗时线性增加,但训练效率反而更高。即在同样的总训练时间下,长序列模型最终损失更低。
作者总结得很直接:“从时间成本角度看,训练短序列模型毫无意义。”
Transformer 并非“终点”,而是“中间产物”
过去七年,Transformer 代表了人工智能的“平面革命”:并行化、统一架构、超大模型。Keiblinger 的工作可能是“立体复兴”的第一声号角:让模型学会沿时间轴逐层积累理解,而不是一次性“扫视全局”。
Keiblinger 的论文不是在否定 Attention,而是在指出一个方向性错误:Transformer 以极端的并行性换取了速度,却牺牲了可递归的思考能力。它像一个超级快的“快照观察者”,而非能真正思考“过程”的智能体。当任务从“生成文本”转向“长程推理”“复杂编程”或“环境交互”时,Transformer 的浅层结构暴露出根本性瓶颈——它不理解时间,只理解相关性。
FBAM 的意义在于:重新让时间回到神经网络的本体,让“深度学习”再次名副其实地“深”。
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 53
53 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)