云舟观测智能体系统技术架构解析
随着云原生技术、微服务架构和容器编排体系的普及,IT系统的复杂度持续攀升。传统运维观测手段难以应对高维度数据、复杂链路与快速迭代带来的挑战,诊断效率与交互体验均面临瓶颈。云舟观测智能体系统( GC Agent System)由此推出。系统以自然语言交互为入口,通过统一编排层与标准化工具体系,实现对观测数据的智能分析、故障辅助诊断与知识检索,为企业构建新一代的自动化运维能力。本文聚焦系统架构设计、核
前言
随着云原生技术、微服务架构和容器编排体系的普及,IT系统的复杂度持续攀升。传统运维观测手段难以应对高维度数据、复杂链路与快速迭代带来的挑战,诊断效率与交互体验均面临瓶颈。云舟观测智能体系统( GC Agent System)由此推出。系统以自然语言交互为入口,通过统一编排层与标准化工具体系,实现对观测数据的智能分析、故障辅助诊断与知识检索,为企业构建新一代的自动化运维能力。
本文聚焦系统架构设计、核心模块原理与工程实现,为大家呈现一个完整可靠、可扩展、企业级的监控观测智能体系统技术蓝图。
一、总体架构设计
1.1 架构理念
系统采用 模块化、松耦合、可扩展 的架构体系。上层业务逻辑、中层编排调度与下层执行工具使用标准接口隔离,使系统既能保持稳定性,也能在未来轻松扩展至更多模型、更多场景和更多观测工具。
1.2 分层架构
系统整体分为 用户/网关层、编排层、Agent工具与能力层、协议层、持久层等五个层次,各层职责清晰、边界明确。
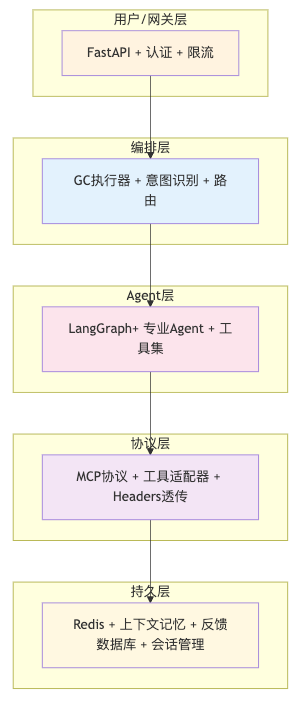
后端核心技术组件主要有以下:
选型以 性能优先、生态成熟、支持异步、运维友好 为原则,核心能力基于langgraph/langchain构建。
1.3 系统任务流程

示例:
一个典型的用户交互请求(如“帮我诊断下主机故障”)在系统中的流转过程如下:
-
请求接入与极速响应:用户发起请求后,API 层立即生成会话 ID,并在进入任何耗时操作之前,通过 SSE 推送首包事件。这种“首包零延迟”机制能够显著减少用户等待时间。
-
纵深防御鉴权:系统基于 Cookie 获取用户态信息,并将其编码到 x-ai Header 中。该凭证会伴随整个请求链路,最终传递到最底层的 MCP 工具,从而实现数据级的权限隔离。
-
智能决策编排:
-
当请求来自明确的指令(例如前端按钮触发),系统会直接进入路由专家模式。
-
当请求为自然语言输入时,系统进入自由探索模式。意图识别组件会对请求进行七类分类(如问候、知识查询、故障排查等),并据此选择最合适的执行策略。
-
-
动态代理构建:系统根据任务类型,通过 MCPLoader 动态构建执行代理,加载所需的 MCP 工具,并配置相应提示模板,使代理具备完成任务的能力。
-
推理与执行循环:代理按照“推理—调用工具—获取结果”的工作方式进行循环。在执行过程中,系统会实时记录关键中间状态并通过 SSE 反馈给前端,以便用户了解任务的执行进度。
-
结果生成与记忆:当任务执行完成后,系统会将最终结果写入 Redis 的会话历史。同时,后台会异步触发标题生成流程,为该轮会话生成简洁、可索引的主题描述,形成完整的交互闭环。
二、核心组件深度解析
2.1 GCExecutor - 核心引擎
GCExecutor是整个系统的核心编排器,负责协调Agent生态系统的运作。它采用了创新的双模式执行策略,能够根据任务特性自动选择最优的执行路径。
2.1.1 路由专家模式(Route Mode)
路由专家模式是为专业任务设计的快速执行通道。当用户明确知道需要哪个专业Agent时,系统会直接路由到对应的Agent,跳过意图识别环节,大幅提升响应速度。适用于需求明确、流程固定的场景。
核心特性:
-
直接路由:通过特定参数指定目标Agent
-
工具精简:只加载Agent配置中定义的5-10个必要工具
-
响应可预测:执行路径固定,便于调试和优化
-
性能优先:减少LLM调用次数,降低延迟
目前适用场景:
-
主机诊断:直接调用主机诊断专家。
-
知识查询:直接调用知识库专家。
-
定向任务:用户明确需要特定功能(待开放)
2.1.2 AI自由探索模式(Explore Mode)
探索模式是系统的智能化体现,适用于复杂、开放性的问题。系统会加载所有可用工具,让AI自主分析问题并选择最优工具组合。
核心特性:
-
全量工具:加载25+可用工具
-
智能选择:AI根据上下文自主决策
-
多轮迭代:支持复杂的多步骤任务
-
动态调整:根据执行结果调整策略
适用场景:
-
复杂故障诊断
-
多维度数据分析
-
探索性问题解决
-
跨领域综合任务
为保障多租户隔离,每次执行均会重新构建执行环境,注入用户级鉴权信息。
2.1.3 意图识别系统
意图识别是探索模式的第一道关卡,通过多级过滤和智能分析,精准理解用户意图。
五级识别流程:
-
输入净化:移除特殊字符,防止注入攻击
-
可疑检测:识别恶意输入模式
-
相关性判断:检查是否属于平台业务范围
-
历史融合:结合对话历史理解上下文
-
LLM分析:深度语义理解,返回7种意图类型
意图类型体系:
-
无效/恶意输入
-
知识查询
-
通用任务
-
问候类输入
-
身份信息询问
-
上下文相关短问
-
可疑/异常输入(防注入)
2.1.4 编排核心逻辑
编排器的核心在于协调各个组件的协同工作,确保请求的高效处理。
执行流程:
-
请求初始化:生成session_id和response_id
-
模式判断:路由模式 vs 探索模式
-
Agent创建:动态创建Agent实例(不使用缓存)
-
工具加载:根据模式加载相应工具集
-
执行监控:实时跟踪执行状态
-
结果聚合:整合多个工具的返回结果
关键实现代码:
class GCExecutor:
"""GC Agent 执行器"""
def __init__(self, redis_url: str = None):
"""初始化执行器"""
# 初始化LLM
self.llm = GCLLMManager.get_llm()
# 获取MCP加载器
self.mcp_loader = get_mcp_loader()
# Agent缓存(注意:实际不使用缓存)
self.agents = {}
# 初始化Redis存储
self.redis_store = GCRedisStore(redis_url=redis_url)
# 初始化反馈服务
self.feedback_service = GCFeedbackService(redis_url=redis_url)
async def execute(self, request: GCRequest, start_sequence: int = 0) -> AsyncIterator[str]:
"""执行请求 - 生成SSE流"""
# 保存headers到实例,供后续工具创建使用
self.current_request_headers = request.headers
# 确定执行模式
if request.direct_agent:
# 直接路由模式 - 使用指定的Agent
agent_id = request.direct_agent
async for event in self._execute_with_agent(
agent_id,
request.message,
session_id,
response_id,
sequence
):
yield event
else:
# AI自由探索模式
async for event in self._execute_explore_mode(
request.message,
session_id,
response_id,
sequence
):
yield event
意图识别的完整实现:
async def _analyze_intent(self, query: str, session_id: str) -> Dict[str, Any]:
"""增强的意图识别方法(带防护机制)"""
# 步骤1:输入净化
cleaned_query = self._sanitize_input(query)
# 步骤2:可疑输入检测
if self._is_suspicious_input(cleaned_query):
return {
"intent_type": "invalid",
"intent_name": "可疑输入",
"confidence": 1.0,
"direct_response": "抱歉,您的输入包含不支持的内容..."
}
# 步骤3:主题相关性检测
if not self._is_observation_related(cleaned_query):
pass # 继续LLM判断
# 步骤4:获取历史对话
history_messages = await self.redis_store.get_conversation_history(
session_id=session_id,
limit=20
)
# 步骤5:LLM意图分析
response = await self.llm.ainvoke([
SystemMessage(content="你是一个意图识别专家..."),
HumanMessage(content=prompt)
])
小结:GCExecutor通过双模式执行策略,既保证了专业任务的高效执行,又提供了复杂问题的智能探索能力。意图识别系统的多级过滤机制确保了系统的安全性和准确性。
2.2 MCP工具加载器和Header透传
MCP(Model Context Protocol)是系统与外部工具交互的统一协议,Headers透传机制确保了认证信息在整个调用链路中的完整传递。
async def _create_tools_for_agent(
self,
agent_config: Dict[str, Any],
explore_mode: bool = False,
request_headers: Optional[Dict[str, str]] = None
) -> List[Tool]:
"""为Agent创建工具"""
# 合并headers,确保所有值都是字符串
final_headers = {}
# 处理配置中的headers
if mcp_server.get("headers"):
for key, value in mcp_server["headers"].items():
final_headers[key] = str(value)
# 处理请求中的headers(包含x-ai认证信息)
if request_headers:
for key, value in request_headers.items():
final_headers[key] = str(value)
# 创建MCP客户端配置
server_config = {
"server": {
"url": url,
"transport": "streamable_http",
"headers": final_headers # Headers透传到MCP服务
}
}
# 每次都创建新客户端,不缓存
client = MultiServerMCPClient(server_config)
# 根据模式过滤工具
if not explore_mode and defined_tools:
# 路由模式:只返回定义的工具
return [t for t in all_tools if t.name in defined_tools]
else:
# 探索模式:返回所有工具
return all_tools
小结:MCP协议的引入统一了工具调用接口,Headers透传机制保证了认证链路的完整性,这是系统安全性的重要保障。
三、技术创新亮点
3.1 双模式执行策略
class ExecutionModeStrategy:
"""
创新的双模式执行策略
"""
async def execute_explore_mode(self, query: str):
"""
探索模式 - 适用于复杂、开放性问题
特点:
1. 加载所有可用工具(20+)
2. AI自主选择最优工具组合
3. 支持多轮工具调用
4. 动态调整执行策略
"""
# 加载完整工具集
all_tools = await self.load_all_tools()
# 创建超级Agent
super_agent = create_react_agent(
llm=self.llm,
tools=all_tools,
prompt=self.exploration_prompt
)
# 智能执行
return await super_agent.astream(query)
async def execute_route_mode(self, query: str, agent_id: str):
"""
路由模式 - 适用于明确、专业的任务
特点:
1. 直接路由到专业Agent
2. 只加载必要工具(5-10个)
3. 执行速度快
4. 响应可预测
"""
# 加载指定Agent
agent = await self.load_agent(agent_id)
# 快速执行
return await agent.astream(query)
3.2 流式响应系统
class StreamingResponseSystem:
"""
SSE流式响应系统
"""
async def generate_sse_stream(self, request: GCRequest):
"""
生成SSE事件流
技术特点:
1. 首包延迟 < 100ms
2. 思维链实时可视化
3. 内容渐进式输出
4. 错误优雅降级
"""
# 立即发送首个事件
yield self._format_sse({
"type": "session_response_id",
"message": response_id,
"timestamp": datetime.now().isoformat()
})
# 实时发送思考步骤
async for step in self.executor.think():
yield self._format_sse({
"type": "thinking_step",
"message": step.description,
"step": step.type
})
# 流式输出内容
async for token in self.executor.generate():
yield self._format_sse({
"type": "token",
"message": token
})
3.3 智能工具调用格式化
def _get_tool_description(self, tool_name: str, tool_args: Dict) -> str:
"""
智能工具描述生成
创新点:
1. 根据工具类型生成友好描述
2. 参数智能提取和展示
3. 执行意图清晰表达
"""
# 工具语义映射
semantic_map = {
"getSystemSpace": "获取系统空间信息",
"queryHostCoreMetrics": "查询主机核心指标",
"queryHostProcData": "分析进程运行状态",
"getHostErrorLogs": "检索系统异常日志"
}
# 智能描述生成
base_desc = semantic_map.get(tool_name, f"执行{tool_name}")
# 参数增强
if "hosts" in tool_args:
base_desc += f" - 目标: {tool_args['hosts']}"
if "metrics" in tool_args:
base_desc += f" - 指标: {tool_args['metrics']}"
return base_desc
3.4 企业级会话管理与用户隔离
class SessionManagement:
"""
企业级会话管理系统
"""
async def manage_session(self, session_id: str, user_id: str):
"""
会话管理核心
技术特点:
1. Redis持久化 - 分布式会话存储
2. 用户隔离 - 基于Cookie的认证
3. 上下文保持 - 历史消息关联
4. 标题生成 - AI智能摘要
"""
# 会话创建/获取
session = await self.redis_store.get_or_create_session(
session_id=session_id,
user_id=user_id
)
# 历史上下文构建
history = await self.redis_store.get_conversation_history(
session_id=session_id,
limit=20 # 保持最近20条消息
)
# 智能标题生成
if not session.title:
title = await self._generate_session_title(
user_question=query,
ai_response=response
)
await self.redis_store.update_session_title(session_id, title)
小结:通过双模式执行、流式响应、智能工具格式化等创新技术,系统实现了效率与智能的完美平衡。
四、上下文/记忆管理
记忆是 Agent 能够进行连续对话的基础。本系统基于 Redis 构建了一套层次化的分布式记忆系统,实现了会话管理、历史记忆和用户隔离等核心功能。
class GCRedisStore:
"""GC Agent的Redis存储实现"""
def __init__(self, redis_url: str = None):
"""初始化Redis连接"""
if redis_url:
self.redis = redis.from_url(redis_url)
else:
# 从配置文件读取
config = self._load_config()
redis_config = config.get('redis', {})
self.redis = redis.Redis(
host=redis_config.get('host', 'localhost'),
port=redis_config.get('port', 6379),
db=redis_config.get('db', 0),
decode_responses=True
)
async def get_or_create_session(self, session_id: str, user_id: str = "default") -> SessionContext:
"""获取或创建会话上下文"""
key = f"session:{session_id}"
context_data = await self.redis.hgetall(key)
if not context_data:
# 创建新会话
context = SessionContext(
session_id=session_id,
user_id=user_id,
created_at=datetime.now(),
updated_at=datetime.now()
)
await self.redis.hset(key, mapping=context.dict())
else:
context = SessionContext(**context_data)
return context
async def add_user_message(self, session_id: str, content: str):
"""添加用户消息到历史"""
message = {
"role": "user",
"content": content,
"timestamp": datetime.now().isoformat()
}
key = f"messages:{session_id}"
await self.redis.rpush(key, json.dumps(message))
# 更新会话时间
await self._update_session_time(session_id)
小结:Redis存储层通过精心设计的Key结构和过期策略,实现了高效的会话管理和历史记忆功能。同时,为了提升历史会话的可读性,系统会在首轮对话结束后,异步触发一个轻量级 LLM 任务。该任务会根据用户的提问和 AI 的回答,提炼出精准的会话摘要(15 字以内),并更新到 Redis 中。这一过程对用户完全透明,不阻塞主交互流程。
五、认证机制
系统采用创新的三层鉴权架构,形成完整的安全闭环,保证数据安全可靠。
5.1 三层鉴权体系
第一层:网关层权限校验
拦截所有流量,通过与企业鉴权中心的交互,验证 Cookie 的合法性并解析出用户身份。这一层阻挡了所有未授权的外部访问。
-
Cookie交换:解析用户Cookie获取智汇云用户态信息
-
用户识别:从Cookie中提取当前用户的各类信息
第二层:MCP Server鉴权
在 API 业务逻辑中,系统强制校验 Session ID 与 User ID 的绑定关系。即使用户猜到了其他人的 Session ID,也无法查看或操作对应的会话内容,确保了租户间的绝对隔离。
-
服务认证:MCP Server自身的访问控制
-
未来扩展:支持MCP Server市场的统一鉴权链接
-
服务隔离:不同MCP Server间的权限隔离
第三层:数据权限校验
这是最具创新性的一层。系统将用户身份信息编码为 `x-ai` Header,并通过 MCP 协议透传至最底层的工具服务。这意味着,权限控制下沉到了数据源头——LLM 无法"看到"用户无权访问的主机或日志,从根本上解决了 AI 系统常见的数据泄露风险。
-
Headers透传:将用户信息透传到每个工具
-
细粒度控制:每个MCP Server的Tool做各自的数据权限验证
-
动态授权:基于用户角色的动态权限分配
5.2 认证服务实现
class AuthService:
"""统一的认证服务"""
async def get_user_info(self, request: Request) -> Tuple[str, str]:
"""从请求中获取用户信息"""
# 尝试从Cookie获取
cookie_value = request.cookies.get("sessionid") or request.cookies.get("JSESSIONID")
if cookie_value:
try:
# 解析Cookie获取用户信息
user_info = self._parse_cookie(cookie_value)
user_name = user_info.get("userName", "default")
return json.dumps(user_info), user_name
except Exception as e:
logger.warning(f"Cookie解析失败: {e}")
# 降级到默认用户
default_user = {
"userName": "default",
"userId": "default",
"timestamp": datetime.now().isoformat()
}
return json.dumps(default_user), "default"
def get_x_ai_header(self, user_info: str) -> str:
"""生成X-AI header"""
# Base64编码用户信息
return base64.b64encode(user_info.encode()).decode()
async def verify_session_ownership(
self,
session_id: str,
user_name: str,
redis_store: GCRedisStore
) -> bool:
"""验证会话所有权"""
session_context = await redis_store.get_context(session_id)
if not session_context:
return False
return session_context.user_id == user_name
小结:三层鉴权机制从网关、服务、数据三个维度构建了完整的安全体系,确保了系统的安全性和可靠性。
六、系统可观测性与可进化能力
6.1 Trace数据上报
系统通过Traceloop统一上报采集数据到LLM应用监测模块,实现全链路追踪。
监控维度:
-
LLM调用监控:Token使用量、响应时间、错误率
-
工具执行追踪:每个工具的执行时间和成功率
-
会话分析:用户行为模式、热点问题识别
-
性能指标:P99延迟、QPS、并发数
实现代码:
from traceloop.sdk import Traceloop
from traceloop.sdk.tracing.tracing import Instruments
# 先禁用 MCP 自动初始化
Traceloop.init(
app_name="gc-agent",
resource_attributes={
"service.name": "gc-agent",
"service.version": "v1.0",
"service.xHawkUserSpaceId": "xxx"
},
api_endpoint="http://traces.xxxx.lycc.qihoo.net:55683",
block_instruments={Instruments.MCP},
disable_batch=True
)
# 手动初始化 MCP instrumentor
mcp_instrumentor = None
try:
from opentelemetry.instrumentation.mcp import McpInstrumentor
mcp_instrumentor = McpInstrumentor()
# 验证初始化状态
logger.info(f"MCP instrumentor is instrumented: {mcp_instrumentor.is_instrumented_by_opentelemetry}")
except Exception as e:
logger.error(f"Failed to initialize MCP instrumentor: {e}")
mcp_instrumentor = None
# 添加src路径
sys.path.insert(0, os.path.join(os.path.dirname(__file__), 'src'))6.2 反馈服务系统
反馈服务主要用于收集用户对AI响应的评价(点赞/点踩),为系统后期优化提供数据支持。
-
评价收集:支持用户对每个响应进行评价
-
数据持久化:将反馈数据存储在Redis中
-
统计分析:支持按会话、时间等维度统计
6.3 实现代码
class GCFeedbackService:
"""反馈服务"""
def __init__(self, redis_url: str = None):
"""初始化反馈服务"""
if redis_url:
self.redis = redis.from_url(redis_url)
else:
# 从配置文件读取
config = self._load_config()
redis_config = config.get('redis', {})
self.redis = redis.Redis(
host=redis_config.get('host', 'localhost'),
port=redis_config.get('port', 6379),
db=redis_config.get('feedback_db', 1), # 使用独立的DB
decode_responses=True
)
async def save_response(
self,
response_id: str,
session_id: str,
user_question: str,
agent_response: str
) -> Feedback:
"""保存响应记录"""
feedback = Feedback(
response_id=response_id,
session_id=session_id,
user_question=user_question,
agent_response=agent_response,
created_at=datetime.now(),
updated_at=datetime.now()
)
# 保存到Redis
key = f"feedback:{response_id}"
await self.redis.hset(key, mapping=feedback.dict())
# 添加到会话索引
session_key = f"session_feedbacks:{session_id}"
await self.redis.sadd(session_key, response_id)
return feedback
async def update_rating(
self,
response_id: str,
rating: Optional[str],
session_id: Optional[str] = None
) -> bool:
"""更新反馈评分"""
key = f"feedback:{response_id}"
# 检查反馈是否存在
exists = await self.redis.exists(key)
if not exists:
logger.warning(f"反馈记录不存在: {response_id}")
return False
# 更新评分
updates = {
"rating": rating or "null",
"updated_at": datetime.now().isoformat()
}
await self.redis.hset(key, mapping=updates)
logger.info(f"反馈评分已更新: {response_id} -> {rating}")
return True
小结:反馈服务通过简单有效的设计,为系统的持续优化提供了重要的数据基础。
结语
云舟观测智能体系统通过分层架构设计、标准化工具体系和可扩展的智能编排能力,为企业提供了结构清晰、可审计、易集成的智能化监控观测能力。在当前架构基础上,系统将围绕以下方向持续演进:
技术演进方向:
-
Agent 市场化:支持第三方 Agent 接入,构建内部能力生态。
-
主动式运维:从被动式操作协助迈向预测式、预防式运维。
-
多模态支持:实现图表、日志、指标等多类型观测数据的统一分析。
产品化路线:
-
私有化部署:支持与智汇云体系的集成与打包部署,满足企业级落地需求。
-
插件化架构:允许用户按需扩展 MCP 工具与流程,实现业务级定制能力。
-
生态化发展:与更多观测工具与运维平台深度集成,构建全链路协同生态。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)