【AI大模型前沿】微软UserLM-8b:AI助手的逼真陪练,多轮对话精炼利器
UserLM-8b是由微软推出的一款80亿参数的用户语言模型,旨在模拟真实用户在多轮对话中的行为,以评估和优化AI助手的性能。该模型通过逐步揭示任务意图,生成更接近真实用户行为的对话内容,为AI助手的开发和优化提供了高效的模拟环境。它在大规模真实对话数据集(如WildChat-1M)上进行训练,能够生成第一轮用户话语、后续用户话语,并判断对话何时结束。
系列篇章💥
目录
前言
随着AI技术的飞速发展,AI助手在各个领域得到了广泛应用。然而,如何准确评估和优化AI助手在多轮对话中的表现,一直是研究者和开发者面临的挑战。微软最新发布的UserLM-8b模型,为这一问题提供了新的解决方案。本文将详细介绍UserLM-8b的核心功能、技术原理、应用场景及快速使用方法,帮助读者全面了解这一创新模型。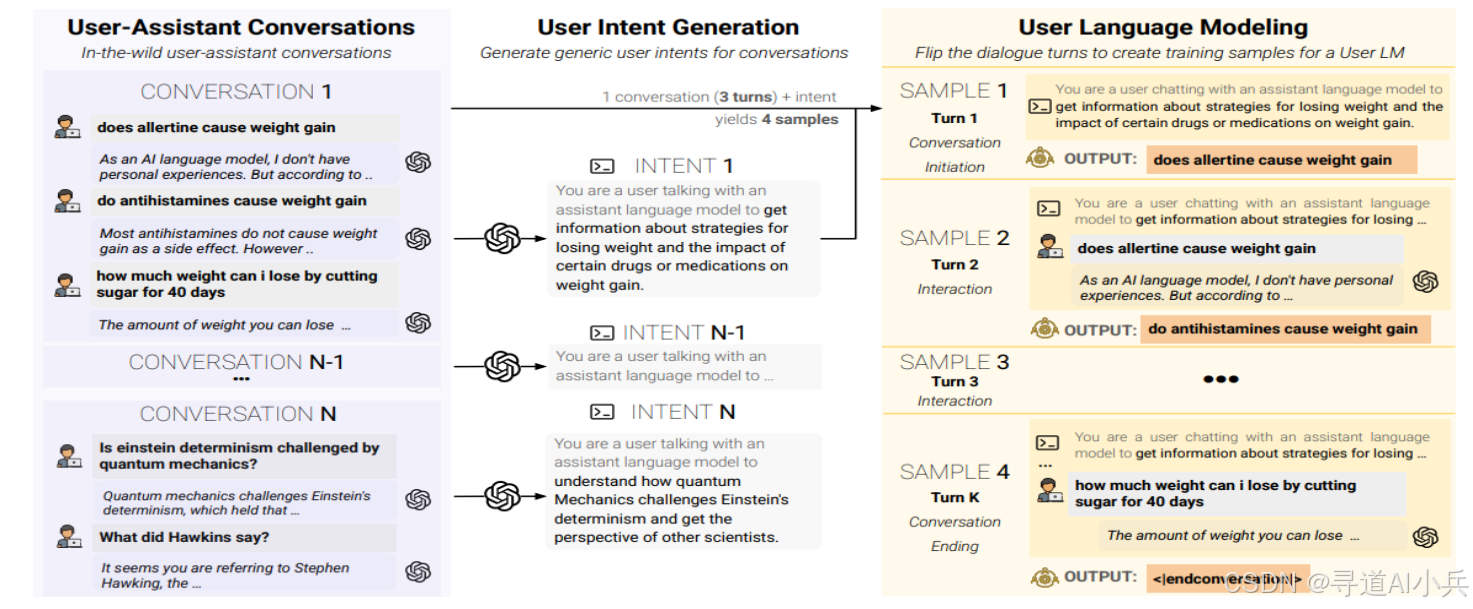
一、项目概述
UserLM-8b是由微软推出的一款80亿参数的用户语言模型,旨在模拟真实用户在多轮对话中的行为,以评估和优化AI助手的性能。该模型通过逐步揭示任务意图,生成更接近真实用户行为的对话内容,为AI助手的开发和优化提供了高效的模拟环境。它在大规模真实对话数据集(如WildChat-1M)上进行训练,能够生成第一轮用户话语、后续用户话语,并判断对话何时结束。
二、核心功能
(一)生成第一轮用户话语
UserLM-8b能够根据给定的任务意图,生成对话的初始用户话语。这使得模型能够在对话开始时就准确地表达用户的需求和目标,为后续的多轮对话奠定基础。例如,如果任务意图是“获取关于Python编程的信息”,模型会生成如“我想了解Python编程的一些基础知识”这样的初始话语,自然地开启对话。
(二)生成后续用户话语
基于对话状态(即之前的用户-助手交互内容),UserLM-8b可以生成后续的用户话语。这使得模型能够在多轮对话中逐步揭示任务意图,模拟真实用户在对话中的行为。例如,在对话中,用户可能会根据助手的回答进一步提问或澄清,模型能够生成如“那Python有哪些应用场景呢?”这样的后续话语,推动对话的深入进行。
(三)判断对话结束
UserLM-8b能够在合适的时机生成结束对话的标记(<|endconversation|>),模拟真实用户结束对话的行为。这使得模型能够更自然地控制对话的节奏和结束时机。例如,当用户的需求得到满足或对话达到自然的终点时,模型会生成结束标记,如“好的,谢谢,我明白了,我们结束这次对话吧”,使对话更加完整和自然。
(四)支持多轮对话
UserLM-8b通过逐步揭示任务意图,支持多轮对话。这使得模型能够模拟真实用户在多轮对话中的行为,使对话更加自然和多样化。例如,在一个关于旅行计划的对话中,用户可能会先询问目的地的信息,然后根据助手的回答进一步询问交通和住宿的建议,最后决定是否结束对话。模型能够根据用户的反馈和需求,灵活地调整对话内容和节奏,提供更加丰富和真实的对话体验。
三、技术揭秘
(一)数据来源
UserLM-8b的训练数据来源于大规模真实用户与助手的对话数据集,如WildChat-1M。该数据集包含丰富的用户行为模式,涵盖了多种主题和场景的对话内容。通过使用这样的真实数据进行训练,模型能够学习到用户在不同情境下的表达方式和对话习惯,从而更好地模拟真实用户的行为。
(二)训练方法
UserLM-8b采用“翻转对话”的训练方法,即将助手的角色转换为用户的角色,训练模型生成用户话语。具体来说,模型通过预测用户在对话中的下一个话语来学习用户的行为模式。这种方法使模型能够专注于用户角色的表达,而不是像传统助手模型那样侧重于提供答案,从而更准确地模拟用户在对话中的行为。
(三)任务意图
UserLM-8b接受一个任务意图作为输入,该意图定义了用户在对话中的目标。任务意图是模型生成用户话语的指导方针,它决定了用户话语的方向和内容。模型根据这个意图逐步揭示任务的具体细节,使对话更加自然和连贯。例如,如果任务意图是“获取旅行建议”,模型会生成与旅行相关的一系列用户话语,逐步探索旅行的目的地、时间、预算等细节。
(四)生成控制
为了提高生成质量,UserLM-8b在生成过程中采用多种控制机制。例如,模型会限制生成的对话长度,避免生成过长或过短的话语;同时,模型还会避免重复生成相同的内容,确保对话的多样性和自然性。此外,模型还会根据对话的上下文和任务意图动态调整生成策略,使生成的话语更加符合用户的意图和对话的逻辑。
(五)评估指标
UserLM-8b的性能通过多种评估指标进行衡量,包括第一轮话语的多样性、意图分解、对话终止能力等。这些指标从不同角度评估模型在模拟用户行为方面的能力。例如,第一轮话语的多样性反映了模型在初始对话时能否生成多种不同的表达方式;意图分解则衡量模型是否能够逐步揭示任务意图,而不是一次性将所有信息都表达出来;对话终止能力则评估模型是否能够在合适的时机结束对话。通过这些综合评估,确保模型能够更好地模拟真实用户的对话行为。
四、应用场景
(一)研究与开发
UserLM-8b在研究与开发领域具有重要应用价值。它能够模拟真实用户的行为,帮助研究人员评估和改进助手语言模型(LLM)在多轮对话中的表现。通过模拟多轮对话,研究人员可以更好地理解助手模型的强项和弱点,从而优化模型的性能,使其在实际应用中表现更加出色。
(二)用户模拟
在用户模拟方面,UserLM-8b能够模拟真实用户的行为,用于测试和优化聊天机器人、虚拟助手等交互式系统。通过模拟用户的不同行为模式,开发者可以发现系统在处理复杂对话时的不足之处,进而改进系统的交互逻辑和用户体验,使其更加符合用户需求。
(三)合成数据生成
UserLM-8b可以与助手模型结合,生成用于训练和测试的合成对话数据。这些合成数据能够丰富训练数据集,提升模型的鲁棒性和泛化能力。通过模拟多样化的对话场景,模型能够在更多样的数据上进行训练,从而更好地应对实际应用中的各种情况。
(四)用户建模
UserLM-8b能够预测用户对特定问题的反应,帮助理解用户需求和行为模式。通过分析用户在不同对话中的行为,开发者可以构建更精准的用户模型,从而为用户提供更加个性化和精准的服务。这对于提升用户满意度和系统性能具有重要意义。
(五)教育与培训
在教育场景中,UserLM-8b可以模拟学生或学习者的提问方式,用于开发智能教育工具。通过模拟学生在学习过程中可能提出的问题,教育工具可以更好地引导学生思考和学习,提供更加有针对性的教学内容,提升教学效果和学习体验。
五、快速使用
以下是使用UserLM-8b的简单示例:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# 加载模型和分词器
model_path = "microsoft/UserLM-8b"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, trust_remote_code=True).to("cuda")
# 创建对话
messages = [{"role": "system", "content": "You are a user who wants to implement a special type of sequence. The sequence sums up the two previous numbers in the sequence and adds 1 to the result. The first two numbers in the sequence are 1 and 1."}]
inputs = tokenizer.apply_chat_template(messages, return_tensors="pt").to("cuda")
end_token = "<|eot_id|>"
end_token_id = tokenizer.encode(end_token, add_special_tokens=False)
end_conv_token = "<|endconversation|>"
end_conv_token_id = tokenizer.encode(end_conv_token, add_special_tokens=False)
# 生成用户话语
outputs = model.generate(
input_ids=inputs,
do_sample=True,
top_p=0.8,
temperature=1,
max_new_tokens=10,
eos_token_id=end_token_id,
pad_token_id=tokenizer.eos_token_id,
bad_words_ids=[[token_id] for token_id in end_conv_token_id]
)
response = tokenizer.decode(outputs[0][inputs.shape[1]:], skip_special_tokens=True)
print(response)
六、结语
UserLM-8b作为微软在AI助手优化领域的创新成果,通过模拟真实用户行为,为AI助手的性能评估和优化提供了高效、低成本的解决方案。其逼真的多轮对话能力和强大的技术架构,使其在多个应用场景中展现出巨大潜力。未来,随着技术的进一步发展,UserLM-8b有望在更多领域得到广泛应用,推动AI助手技术的持续进步。
项目地址
- HuggingFace模型库:https://huggingface.co/microsoft/UserLM-8b
- arXiv技术论文:https://arxiv.org/pdf/2510.06552

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)