CDH6.3.2集群Hive2Paimon的表迁移
- 1. 定义 Source Catalog (读取 Hive)'hive-conf-dir' = '/etc/hive/conf.cloudera.hive', -- CDH 标准配置路径'hadoop-conf-dir' = '/etc/hadoop/conf.cloudera.hdfs' -- CDH 标准配置路径-- 2. 定义 Target Catalog (写入 Paimon)
目录
5.方案二:基于 Migrate 的零拷贝迁移(推荐超大表,paimon-flink-1.19-0.9.0.jar)
6.方案三:基于 Migrate 的零拷贝迁移(推荐超大表,paimon-flink-1.19-1.1.1.jar)
6.1 步骤1:解决 HDFS 权限问题 (Sticky Bit)
6.4 步骤 4:执行迁移命令 (Paimon 1.1.1 语法)
7.1 签名不匹配 (Signature mismatch)
7.2 权限拒绝 (Permission denied by sticky bit)
7.3 未知分区格式 (Unknown partition format / PaimonSerDe)
7.4 路径跨库错误 (Path ... is different from where it should be)
7.5 目标库无表 (Success but table missing)
7.6 文件系统存在 Schema (Schema in filesystem exists)
1.环境与背景
现目前是调研批流一体数仓架构,整体的流程图如下:
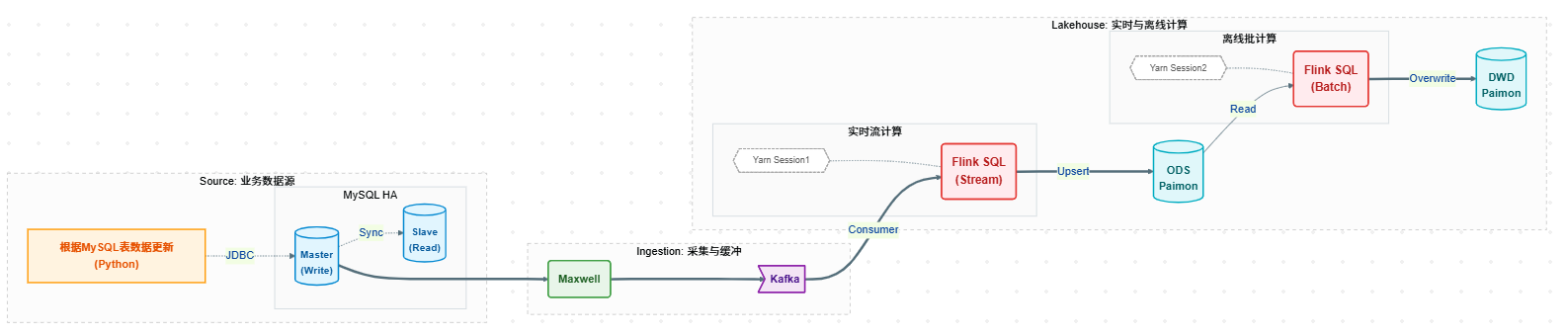
之前使用的离线数仓架构,需要对架构进行调整,因此原有的Hive表需要迁移到新架构下的Paimon表中。本文档是基于调研的架构进行测试的,特别是解决Jar包版本冲突、HDFS权限限制以及元数据污染这三大核心障碍后的最终总结。调研在 CDH 6.3.2 环境下,使用 Flink 1.19 和 Paimon 1.1.1 实现 Hive 到 Paimon 零拷贝(Zero-Copy)秒级迁移 的完整最佳实践。
-
Hadoop 平台:CDH 6.3.2 (Hadoop 3.0.0, Hive 2.1.1)
-
计算引擎:Flink 1.19.3 (Session Cluster)
-
数据湖组件:Apache Paimon 1.1.1
-
迁移目标:
-
源表:Hive
test.test_table(ORC 格式) -
目标表:Paimon
test_db.test_table_* -
要求:保留历史数据,无需重写文件(零拷贝),支持重命名。
-
2. 核心依赖检查 (至关重要)
在开始任何操作前,必须检查 Flink 的 lib 目录,防止“Jar包地狱”导致的功能缺失。
1. 检查 Jar 包冲突 进入 Flink 安装目录的 lib 文件夹,执行:
ls -l $FLINK_HOME/lib/paimon*.jar
# 若查找不到,则需要搭建Flink的实际安装路径
ls -l /home/bigdata/download/flink-1.19.3/lib/paimon*.jar2. 正确的依赖状态
-
❌ 必须删除:
paimon-flink-1.19-0.9.0.jar(或任何低于 1.1.1 的版本,会导致无法使用target_table参数)。 -
✅ 必须保留:
paimon-flink-1.19-1.1.1.jar(核心包)。 -
✅ 必须保留:
paimon-hive-connector-2.1-cdh-6.3-1.1.1.jar(CDH 适配包)。
3. 重启集群 如果有 Jar 包变更,必须重启 Flink 集群(Standalone 或 YARN Session)以及 SQL Client,否则内存中的旧代码不会更新。
3.数据准备
为了模拟真实的迁移场景,我们在 Hive 中创建标准的 ORC 表。
Hive SQL (在 Beeline 或 Hue 中执行):
在CDH 6.3.2集群中创建Hive的数据库、表以及插入测试数据,相应的SQL语句如下:
CREATE DATABASE IF NOT EXISTS test;
USE test;
DROP TABLE IF EXISTS test_table;
-- 创建源表 (必须是 Hive 支持的格式,如 ORC, Parquet, Avro)
CREATE TABLE test.test_table (
id INT,
name STRING,
age INT,
city STRING,
salary DECIMAL(10,2),
create_time TIMESTAMP
)
STORED AS ORC;
INSERT INTO test.test_table VALUES
( 1,'Alice',23,'Beijing',18000.00,'2024-11-20 08:00:00'),
( 2,'Bob',30,'Shanghai',22000.50,'2024-11-20 08:01:00'),
( 3,'Carol',25,'Guangzhou',19500.00,'2024-11-20 08:02:00'),
( 4,'David',28,'Shenzhen',21000.00,'2024-11-20 08:03:00'),
( 5,'Eva',22,'Chengdu',17000.00,'2024-11-20 08:04:00'),
( 6,'Frank',35,'Hangzhou',25000.00,'2024-11-20 08:05:00'),
( 7,'Grace',27,'Wuhan',20000.00,'2024-11-20 08:06:00'),
( 8,'Henry',29,'Nanjing',20500.00,'2024-11-20 08:07:00'),
( 9,'Iris',24,'Xi''an',18500.00,'2024-11-20 08:08:00'),
(10,'Jack',31,'Chongqing',23000.00,'2024-11-20 08:09:00'),
(11,'Kate',26,'Tianjin',19800.00,'2024-11-20 08:10:00'),
(12,'Leo',33,'Suzhou',24000.00,'2024-11-20 08:11:00'),
(13,'Mona',21,'Qingdao',17500.00,'2024-11-20 08:12:00'),
(14,'Nick',34,'Dalian',24500.00,'2024-11-20 08:13:00'),
(15,'Olivia',28,'Xiamen',21500.00,'2024-11-20 08:14:00'),
(16,'Paul',36,'Ningbo',25500.00,'2024-11-20 08:15:00'),
(17,'Quinn',23,'Foshan',18200.00,'2024-11-20 08:16:00'),
(18,'Rose',30,'Wuxi',22500.00,'2024-11-20 08:17:00'),
(19,'Sam',27,'Changsha',20200.00,'2024-11-20 08:18:00'),
(20,'Tina',32,'Zhengzhou',23500.00,'2024-11-20 08:19:00'),
(21,'Uma',25,'Dongguan',19000.00,'2024-11-20 08:20:00'),
(22,'Victor',29,'Jinan',20800.00,'2024-11-20 08:21:00'),
(23,'Wendy',24,'Harbin',18700.00,'2024-11-20 08:22:00'),
(24,'Xander',37,'Kunming',26000.00,'2024-11-20 08:23:00'),
(25,'Yara',26,'Nanchang',19300.00,'2024-11-20 08:24:00'),
(26,'Zane',31,'Guiyang',22800.00,'2024-11-20 08:25:00'),
(27,'Abby',22,'Haikou',17800.00,'2024-11-20 08:26:00'),
(28,'Bryan',35,'Lanzhou',25200.00,'2024-11-20 08:27:00'),
(29,'Cora',28,'Taiyuan',21200.00,'2024-11-20 08:28:00'),
(30,'Derek',33,'Hefei',24200.00,'2024-11-20 08:29:00');
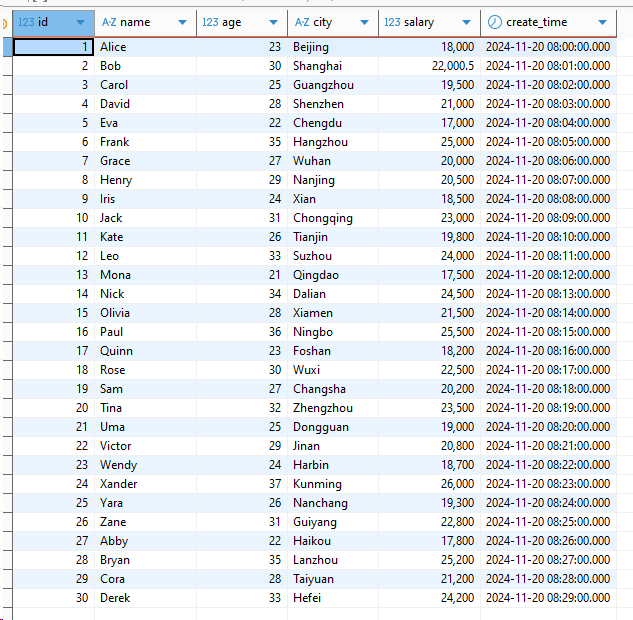
SELECT COUNT(*) AS cnt FROM test_db.test_table;
SELECT * FROM test_db.test_table LIMIT 10;
# copy表方案一:存储格式orc
CREATE TABLE test.test_table_copy
LIKE test.test_table;
INSERT INTO test.test_table_copy
SELECT * FROM test.test_table;
# copy表方案二:存储格式TEXTFILE
# 这里我使用的这种方式进行copy表
CREATE TABLE test.test_table_copy
AS
SELECT * FROM test.test_table;4. 方案一:基于 CTAS 的全量复制(推荐中小表)
适用场景:数据量在可接受范围内(如 <几百GB),追求稳定,无需修改 HDFS 底层权限。 原理:通过 Flink 读取 Hive 源表数据,写入新的 Paimon 表。
4.1 启动Flink 会话
在Flink的bin目录下执行下述语句,进入Flink SQL会话
./sql-client.sh4.2 定义 Catalog
在 Flink SQL Client 中执行:
-- 1. 定义 Source Catalog (读取 Hive)
CREATE CATALOG source_hive WITH (
'type' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive', -- CDH 标准配置路径
'hadoop-conf-dir' = '/etc/hadoop/conf.cloudera.hdfs' -- CDH 标准配置路径
);
-- 2. 定义 Target Catalog (写入 Paimon)
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///user/hive/warehouse',
'metastore' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);4.3 执行迁移
-- 确保当前使用的是 Paimon Catalog
USE CATALOG paimon_catalog;
USE test_db;
-- 创建并写入数据
-- 这会启动一个 Flink Job,读取 Hive 数据并以 ORC 格式写入 Paimon
CREATE TABLE test_table2
WITH (
'file.format' = 'orc',
'bucket' = '-1' -- 如果是 Paimon 0.6+ 建议加上这个,表示不分桶的追加表,写入更快
)
AS SELECT * FROM source_hive.test.test_table;结果验证: 执行完成后,Paimon 会自动在 test_db 下创建 test_table2 并完成数据加载。该操作本质是 MapReduce/Spark/Flink 任务的数据重写。对应结果如下:
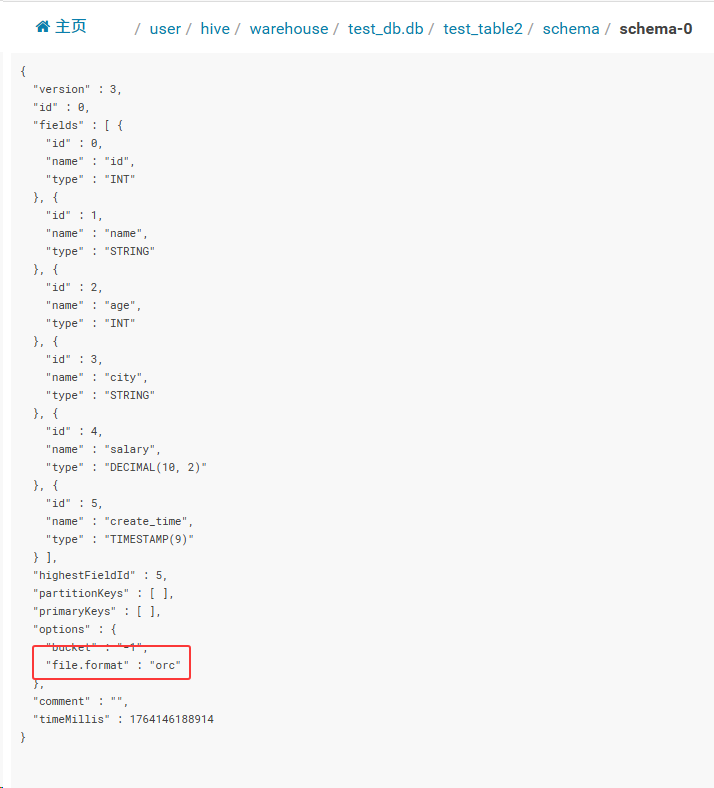
集群上查看表结构,存储格式也是为ORC:
5.方案二:基于 Migrate 的零拷贝迁移(推荐超大表,paimon-flink-1.19-0.9.0.jar)
适用场景:TB/PB 级数据,无法承受重写数据的时间成本,必须“原地转换”。 原理:利用 sys.migrate_table 修改元数据,并配合 HDFS 操作完成库的变更。
jar包下载网址:Central Repository: org/apache/paimon/paimon-flink-1.19/0.9.0
5.1 解决 HDFS 权限问题(关键步骤)
由于 Paimon 需要移动文件,而 CDH 默认开启 Sticky Bit,普通用户无法移动 root 创建的 Hive 文件。 在 Linux 终端执行(需 sudo 或 hdfs 用户):
# 修改源表文件的所有者为运行 Flink 的用户 (例如 bigdata)
sudo -u hdfs hdfs dfs -chown -R bigdata:hive /user/hive/warehouse/test.db/test_table![]()
# 验证属主是否正确
hdfs dfs -ls -R /user/hive/warehouse/test.db/test_table
5.2 执行原地转换
在 Flink SQL Client 中执行:
-- 定义 Target Catalog (写入 Paimon)
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///user/hive/warehouse',
'metastore' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
USE CATALOG paimon_catalog;
USE test_db;
-- 调用迁移过程 (注:因版本限制,无法指定 target_table,默认原地转换)
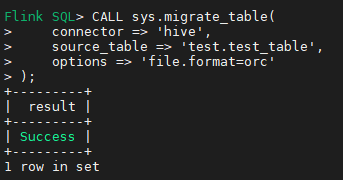
CALL sys.migrate_table(
connector => 'hive',
source_table => 'test.test_table',
options => 'file.format=orc'
);
5.3 物理搬家与注册(解决跨库重命名难题)
由于 migrate_table 默认保留在源库 (test),且 Hive Catalog 对路径有严格校验,我们需要手动将数据移动到 test_db 的标准路径下并重新挂载。
步骤 1:HDFS 文件移动(Linux Shell)
# 1. 创建目标库目录
hdfs dfs -mkdir -p /user/hive/warehouse/test_db.db
# 2. 将数据从 test库 移动到 test_db库,并重命名
hdfs dfs -mv /user/hive/warehouse/test.db/test_table /user/hive/warehouse/test_db.db/test_table4
# 3. (Hack操作) 暂时将数据重命名,骗过 Create Table 检测
hdfs dfs -mv /user/hive/warehouse/test_db.db/test_table4 /user/hive/warehouse/test_db.db/test_table4_bak
步骤 2:创建表结构(Flink SQL)
USE test_db;
-- 创建表元数据(此时路径为空,创建成功)
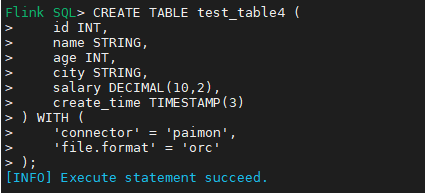
CREATE TABLE test_table4 (
id INT,
name STRING,
age INT,
city STRING,
salary DECIMAL(10,2),
create_time TIMESTAMP(3)
) WITH (
'connector' = 'paimon',
'file.format' = 'orc'
);
步骤 3:恢复数据(Linux Shell)
# 删除 Flink 刚创建的空目录
hdfs dfs -rm -r /user/hive/warehouse/test_db.db/test_table4
# 将真实数据移回原位
hdfs dfs -mv /user/hive/warehouse/test_db.db/test_table4_bak /user/hive/warehouse/test_db.db/test_table4
步骤 4:验证
SELECT * FROM test_table4 LIMIT 5;使用dbeaver查看数据结果如下:
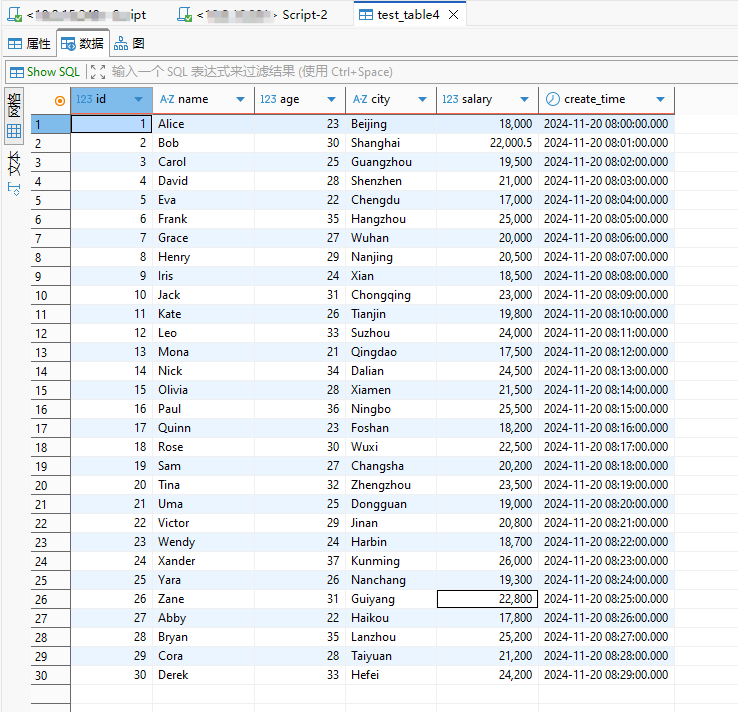
6.方案三:基于 Migrate 的零拷贝迁移(推荐超大表,paimon-flink-1.19-1.1.1.jar)
这是最高效的方案,利用 Paimon 1.1.1 的 migrate_table 过程,仅修改元数据,不移动也不重写 HDFS 上的物理数据文件。但是使用这种方式进行迁移,会将Hive源表给删除,因此在执行的之前需要将表进行备份。
jar包下载网址:Central Repository: org/apache/paimon/paimon-flink-1.19/1.1.1
6.1 步骤1:解决 HDFS 权限问题 (Sticky Bit)
Hive 表的数据通常由 root 或 hive 用户创建,且 CDH 默认开启粘滞位(Sticky Bit)。Flink 运行用户(如 bigdata)默认无权操作这些文件。
在 Linux 终端执行(需 root 或 sudo 权限):
# 将源表 HDFS 文件的所有者修改为 Flink 运行用户 (例如 bigdata)
# 注意:替换路径为实际 Hive 表路径
sudo -u hdfs hdfs dfs -chown -R bigdata:hive /user/hive/warehouse/test.db/test_table# 验证属主是否正确
hdfs dfs -ls -R /user/hive/warehouse/test.db/test_table
6.2 步骤2:启动 Flink SQL Client
export HADOOP_CLASSPATH=`hadoop classpath`
./bin/sql-client.sh6.3 步骤 3:注册 Catalog
-- 定义 Target Catalog (写入 Paimon)
CREATE CATALOG paimon_catalog WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///user/hive/warehouse',
'metastore' = 'hive',
'hive-conf-dir' = '/etc/hive/conf.cloudera.hive'
);
USE CATALOG paimon_catalog;6.4 步骤 4:执行迁移命令 (Paimon 1.1.1 语法)
使用 target_table 参数实现跨库重命名迁移。
CALL sys.migrate_table(
connector => 'hive',
source_table => 'test.test_table', -- 源表
target_table => 'test_db.test_table_3', -- 目标表 (1.1.1 新特性)
delete_origin => false, -- 保留源表的元数据(可选)
options => 'file.format=orc, bucket=-1' -- bucket=-1 表示追加表,性能最好
);执行结果: 应当返回 Success。
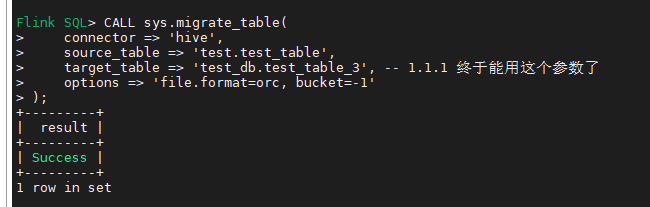
6.5 步骤 5:验证数据
SELECT * FROM test_db.test_table_3;对应结果如下:
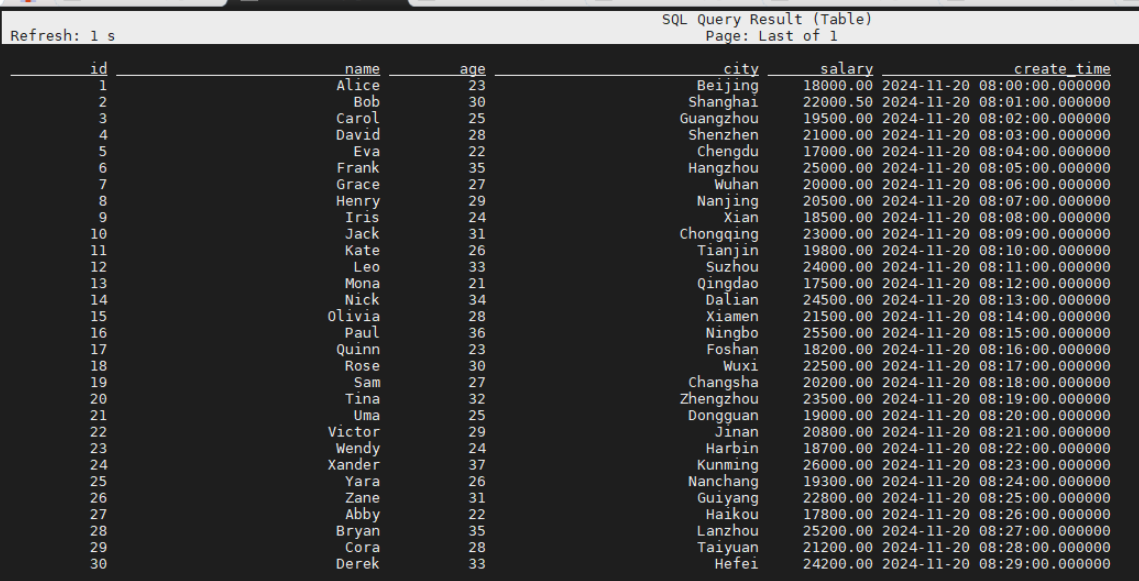
使用dbeaver查看数据结果如下:
7.常见报错与排查手册 (Troubleshooting)
在本次 CDH 6.3.2 + Flink 1.19 + Paimon 1.1.1 的迁移实战中,踩过了以下典型坑点。遇到报错时,可按此清单逐一排查。
7.1 签名不匹配 (Signature mismatch)
-
报错信息:
[ERROR] Could not execute SQL statement. Reason: org.apache.calcite.sql.validate.SqlValidatorException: No match found for function signature migrate_table(connector => <CHARACTER>, source_table => <CHARACTER>, target_table CTER>, delete_origin => <BOOLEAN>, options => <CHARACTER>). Supported signatures are: migrate_table(connector => STRING, source_table => STRING, options => STRING)
-
根本原因:Jar 包版本冲突(Jar Hell)。 Flink 的
lib目录下同时存在旧版本(如 0.9.0)和新版本(1.1.1)的 Paimon Jar 包。Flink 类加载器优先加载了旧版 Jar,而旧版migrate_table不支持target_table参数。 -
解决方案:
-
检查 Flink 库目录:
ls -l $FLINK_HOME/lib/paimon*.jar。 -
删除所有旧版本(如
paimon-flink-1.19-0.9.0.jar)。 -
仅保留
paimon-flink-1.19-1.1.1.jar和对应的 Hive Connector。 -
重启集群(必须重启才能生效)。
-
使用方案二可以解决
-
7.2 权限拒绝 (Permission denied by sticky bit)
-
报错信息:
[ERROR] Could not execute SQL statement. Reason: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied by sticky bit: user=bigdata, path="/user/hive/warehouse/test.db/test_table/000000_0":root:hive:-rwxrwxrwt, parent="/user/hive/warehouse/test.db/test_table":root:hive:drwxrwxrwt
-
根本原因:HDFS 粘滞位限制。 Hive 表数据通常由
root或hive用户创建。CDH 默认开启 Sticky Bit,导致 Flink 运行用户(如bigdata)无权移动或重命名属于root的文件,即使bigdata有写权限。 -
解决方案: 在执行迁移前,必须使用超级用户修改源表文件的所有者。
# 将源表 HDFS 文件的所有者修改为 Flink 运行用户 sudo -u hdfs hdfs dfs -chown -R bigdata:hive /user/hive/warehouse/test.db/test_table注意:每次重建 Hive 源表后,文件归属会变回 root,需要重新执行此命令。
7.3 未知分区格式 (Unknown partition format / PaimonSerDe)
-
报错信息:
java.lang.UnsupportedOperationException: Unknown partition format: SerDeInfo(name:null, serializationLib:org.apache.paimon.hive.PaimonSerDe, parameters:{})
-
根本原因:源表元数据被污染。 通常是因为之前的
migrate_table命令执行了一半(例如:因不支持target_table导致默认在原地修改了元数据,将 Hive 表属性改成了 Paimon 属性,但未改名)。当你再次尝试将这个“已经是 Paimon 格式”的表当作“Hive 源表”进行迁移时,程序会报错。 -
解决方案:
-
重置源表:在 Hive/Spark 中
DROP TABLE test.test_table。 -
重建源表:重新执行
CREATE TABLE ... STORED AS ORC并导入数据。 -
重新赋权:执行 6.1 中的
chown操作。 -
再次迁移:执行
CALL sys.migrate_table(...)。
-
7.4 路径跨库错误 (Path ... is different from where it should be)
-
报错信息:
CatalogException: Path '.../test.db/test_table' is different from where it should be '.../test_db.db/test_table' -
根本原因:Hive Catalog 路径规范限制。 Paimon 的 Hive Catalog 严格遵循 Hive 目录规范。如果你尝试手动
CREATE TABLE或使用migrate_table但未正确重命名路径,导致表名所在的库(test_db)与底层 HDFS 路径(test.db)不匹配,会被拒绝。 -
解决方案:
-
首选:使用 Paimon 1.1.1 的
target_table参数,让程序自动处理跨库移动。 -
备选:手动使用
hdfs dfs -mv将数据移动到规范路径后,再使用register_table。
-
7.5 目标库无表 (Success but table missing)
-
现象:
migrate_table显示成功,但在目标库test_db中找不到表,表还在源库test中。 -
根本原因:原地转换。 这是使用了不支持
target_table的旧版 Jar 包,或未指定该参数时的默认行为。Paimon 仅修改了源表的元数据,未执行移动操作。 -
解决方案:
-
参考 6.1 升级 Jar 包并指定
target_table。 -
或者使用
ALTER TABLE test.test_table RENAME TO test_db.test_table_2手动完成最后一步。
-
7.6 文件系统存在 Schema (Schema in filesystem exists)
-
现象:使用
CREATE TABLE挂载已有数据时报错。 -
根本原因:Paimon 保护机制。目标目录下已存在 Paimon 格式的数据(manifest/schema文件),禁止通过
CREATE覆盖。 -
解决方案:使用
CALL sys.register_table(...)替代CREATE TABLE。
8.总结与最佳实践
在 CDH 6.3.2 这种较老的 Hadoop 环境中使用新版 Paimon (1.1.1) 进行 Hive 迁移,成功的关键在于环境纯净度与权限控制。
8.1 迁移策略选择
-
策略 A:零拷贝秒级迁移 (
sys.migrate_table) ——【推荐】-
适用场景:海量数据(TB/PB级),无法承受数据重写的时间和存储成本。
-
优势:速度极快,不占用额外存储,保留历史文件。
-
要求:必须解决 HDFS 权限问题,必须使用正确的 Paimon 版本以支持跨库重命名。
-
-
策略 B:CTAS 数据复制 (
CREATE TABLE AS SELECT)-
适用场景:中小规模数据,源表格式不兼容(如 TextFile),或需要清洗数据。
-
优势:操作简单,规避了底层权限和元数据污染问题,是最稳妥的兜底方案。
-
劣势:速度慢,消耗计算资源和双倍存储。
-
8.2 成功的三个关键支柱
-
纯净的依赖环境 (Dependency)
-
坚决杜绝
lib目录下多版本 Jar 包共存。这是导致“签名不匹配”等玄学问题的根源。务必删除旧包,保留新包,并重启集群。
-
-
正确的权限管理 (Permission)
-
HDFS 的 Sticky Bit 是迁移操作的最大拦路虎。Flink 任务用户(
bigdata)默认无权操作 Hive 原生数据。必须使用sudo -u hdfs手动介入修改文件所有者。
-
-
正确的版本特性使用 (Features)
-
充分利用 Paimon 1.1.1 的新特性(如
target_table)。它能自动处理跨库、重命名和路径移动,避免了手动 HDFS 操作带来的风险和繁琐。
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 23
23 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)