AAAI 2026|厦大提出NFA-ViT:现有模型在BR-Gen上集体翻车?它却稳稳领先!
本文直面当前AI生成图像检测领域的一个核心短板——对背景、环境等非物体区域的局部篡改检测能力不足。通过构建一个名为BR-Gen的大规模、高质量数据集,论文成功地量化并暴露了现有方法的局限性。在此基础上,本文提出的NFA-ViT模型,通过一种创新的噪声引导伪造放大机制,能够敏锐地捕捉并放大那些容易被忽略的微弱伪造线索,实现了在检测和定位任务上的双重领先。这项研究不仅为社区提供了一个极具价值的评测基准
随着AI图像编辑工具的普及,在图片中进行局部、细微的篡改变得越来越容易和逼真,这给数字内容的真实性带来了巨大挑战。现有检测伪造图像的研究,大多集中在整张图片被替换或者图片中的某个显著物体被修改的情况,但对于更常见的、更隐蔽的场景元素(如天空、地面、墙壁)的篡改,却常常束手无策。这主要是因为缺乏专门针对这类伪造的训练数据,导致现有模型存在明显的“认知盲区”。
为了解决这一难题,本文提出了一个名为BR-Gen的大规模、高仿真度的局部伪造图像数据集,并提出了一种名为NFA-ViT的新型检测模型。这个新模型通过一种巧妙的伪造信号放大机制,显著提升了对微小、隐蔽伪造区域的识别能力,在实验中取得了目前最优的检测效果。
另外我整理了AAAI 2026 CV相关论文合集(持续更新中),感兴趣的自取哦~
一、论文基本信息

论文标题: Zooming In on Fakes: A Novel Dataset for Localized AI-Generated Image Detection with Forgery Amplification Approach
作者姓名: Lvpan Cai, Haowei Wang, Jiayi Ji, YanShu ZhouMen, Yiwei Ma, Xiaoshuai Sun, Liujuan Cao, Rongrong Ji
作者单位/机构: 厦门大学、腾讯优图实验室、新加坡国立大学
论文链接: https://arxiv.org/abs/2504.11922
项目地址: https://github.com/clpbc/BR-Gen
二、主要贡献与创新
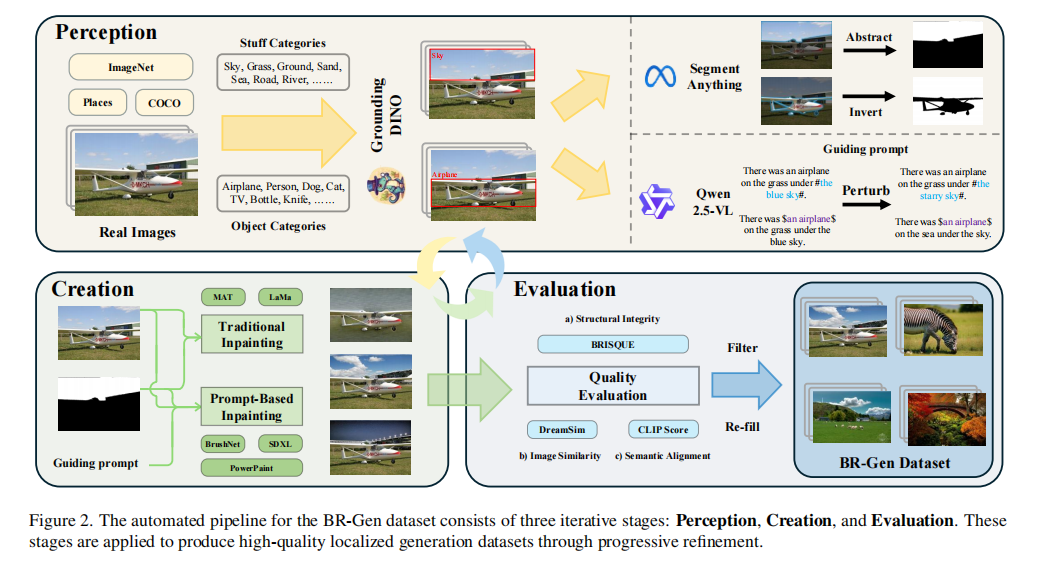
- 指出现有数据集的区域偏见和质量问题,并构建了更全面的BR-Gen数据集。
- 提出NFA-ViT模型,利用噪声引导注意力机制,有效放大了微弱的伪造特征。
- 大量实验证明了BR-Gen数据集的挑战性,以及NFA-ViT模型卓越的检测性能。
三、研究方法与原理
该论文提出的NFA-ViT模型,核心思路是构建一个双分支网络,利用一个分支提取的噪声特征去引导另一个分支的图像特征学习,从而放大并扩散伪造区域的微弱信号。
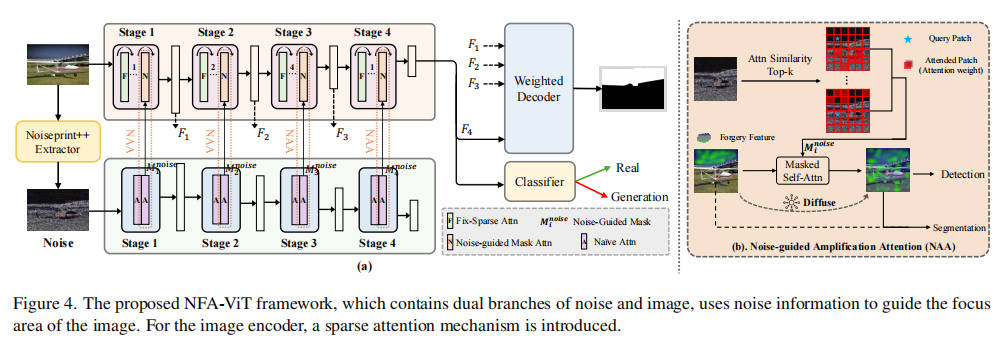
NFA-ViT (Noise-guided Forgery Amplification Vision Transformer) 的整体框架如上图所示,它主要包含图像和噪声两个分支,并通过一种新颖的注意力机制将两者联系起来。
首先,对于一张输入的RGB图像 x x x,模型会先通过一个预训练的噪声提取器Noiseprint++来获得其独特的噪声指纹(noise fingerprints) n n n。这个噪声指纹可以反映出图像中不同区域因生成方式不同而产生的微小差异。随后,图像 x x x 和噪声指-纹 n n n 被分别送入两个并行的编码器分支中。
这两个分支都采用了当下流行的视觉变换器 (Vision Transformer) 结构,但关键的创新在于图像分支中所使用的噪声引导放大注意力 (Noise-guided Amplification Attention, NAA) 机制。在传统的自注意力机制 (self-attention) 中,图像中的每个小块(patch)会平等地与其他所有小块进行信息交互。但在NAA中,这种交互是有选择性的。具体来说,噪声分支的学习结果会生成一个“引导面具” M n o i s e M_{noise} Mnoise,这个面具会告诉图像分支,哪些区域是“可疑的”(即潜在的伪造区域)。
这个过程可以分为几步。在每个阶段的最后一层,噪声分支会计算出一个注意力矩阵 A n o i s e A_{noise} Anoise:
A n o i s e = Softmax ( Q n o i s e K n o i s e T d ) A_{noise} = \text{Softmax}\left(\frac{Q_{noise}K_{noise}^T}{\sqrt{d}}\right) Anoise=Softmax(dQnoiseKnoiseT)
这个矩阵反映了噪声特征中任意两个位置之间的相似度。接着,模型会为每个查询 Q Q Q 找到与之最不相似的 k k k 个键 K K K,并将这些位置标记为1,形成引导面具 M n o i s e M_{noise} Mnoise。这个操作可以用公式表达为:
M n o i s e = 1 [ Top-k ( − A n o i s e ) ] M_{noise} = \mathbf{1}[\text{Top-k}(-A_{noise})] Mnoise=1[Top-k(−Anoise)]
这里的负号很关键,它意味着模型寻找的是相似度最低、差异最大的区域,这些区域很可能就是真实区域与伪造区域的边界或内部。
然后,这个引导面具 M n o i s e M_{noise} Mnoise 会被应用到图像分支的注意力计算中。图像分支只会在 M n o i s e M_{noise} Mnoise 标记为1的位置上计算注意力权重,如公式所示:
F i j = Softmax ( Q i m a g e K i m a g e T d ) i j iff M n o i s e i j = 1 F_{ij} = \text{Softmax}\left(\frac{Q_{image}K_{image}^T}{\sqrt{d}}\right)_{ij} \quad \text{iff} \quad M_{noise_{ij}} = 1 Fij=Softmax(dQimageKimageT)ijiffMnoiseij=1
通过这种方式,真实区域的特征块被迫去“关注”那些被噪声分支识别出的可疑伪造区域,从而学习并吸收伪造痕迹。这个过程就像在一个安静的房间里,通过一个放大器将微弱的杂音放大,让房间里的每个人都能听到。论文中将其描述为一个特征扩散过程:
P l + 1 ( i , j ) = α ⋅ P l ( i , j ) + β ⋅ 1 ∣ N ( i , j ) ∣ ∑ ( k , l ) ∈ N ( i , j ) P l ( k , l ) P^{l+1}(i,j) = \alpha \cdot P^l(i,j) + \beta \cdot \frac{1}{|N(i,j)|} \sum_{(k,l) \in N(i,j)} P^l(k,l) Pl+1(i,j)=α⋅Pl(i,j)+β⋅∣N(i,j)∣1(k,l)∈N(i,j)∑Pl(k,l)
其中, P l ( i , j ) P^l(i,j) Pl(i,j) 代表第 l l l 层位于 ( i , j ) (i,j) (i,j) 的真实特征,而 N ( i , j ) N(i,j) N(i,j) 是其关注的伪造特征集合。通过逐层传播,微弱的局部伪造信号被有效放大并扩散到了整个图像的特征表示中,使得最终的分类器更容易做出判断。
最后,模型还设计了一个加权解码器 (Weighted Decoder)。传统方法通常简单地将不同层级的特征图拼接或相加,而这里则为每个层级的特征图分配了一个可学习的权重参数 γ i \gamma_i γi,使得模型能自适应地融合多尺度信息,进一步提升定位伪造区域的准确性。其融合方式如下:
M ^ = Upscale ( MLP ( ∑ i = 1 4 ( F ^ i × γ i ) ) ) \hat{M} = \text{Upscale}\left(\text{MLP}\left(\sum_{i=1}^{4} (\hat{F}_i \times \gamma_i)\right)\right) M^=Upscale(MLP(i=1∑4(F^i×γi)))
这里 F ^ i \hat{F}_i F^i 是经过处理的第 i i i 层特征图。这种设计使得模型可以更智能地平衡来自不同层级的特征,突出关键信息,抑制无关干扰。
四、实验设计与结果分析
论文的实验部分设计非常全面,旨在验证其提出的数据集BR-Gen的挑战性以及新模型NFA-ViT的有效性。实验使用了ImageNet、COCO、Places等多个大型数据集作为原始真实图像来源,构建了包含15万张局部伪造图像的BR-Gen数据集。评测指标主要包括Recall@50(衡量模型区分真假图像的能力)、F1分数、AUC(评估分类性能的综合指标)以及IoU(衡量伪造区域定位准确性)。
跨域测试(Cross-domain on BR-Gen)
为了证明现有模型在面对新型伪造时的“脆弱性”,作者们直接将在其他数据集上训练好的模型,拿到BR-Gen数据集上进行测试。
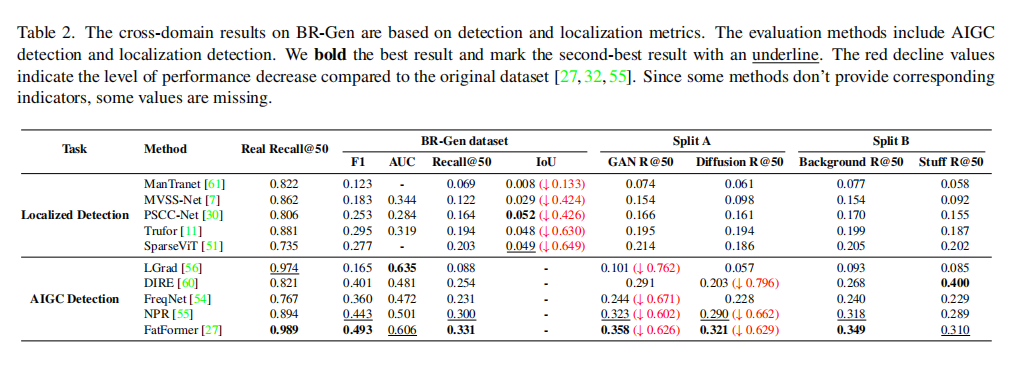
如表2所示,实验结果非常显著。无论是专门用于局部伪造检测的模型(如TruFor、SparseViT),还是通用的AI图像检测模型(如DIRE、FatFormer),其性能都出现了断崖式下跌。例如,目前最先进的模型之一FatFormer,在检测其原始任务中的生成图像时准确率高达99%以上,但在BR-Gen上,对生成图像的召回率(Gen. R@50)骤降至33.1%。在定位任务上,所有模型的IoU值都低得可怜,最高仅为0.052,这说明它们几乎无法准确圈出伪造区域。这些结果有力地证明了现有检测任务中存在严重的数据偏见,同时也反衬出BR-Gen数据集的独特性和挑战性。
域内测试(In-domain on BR-Gen)
接下来,作者将所有对比模型在BR-Gen的训练集上重新训练,并在其测试集上进行评估。
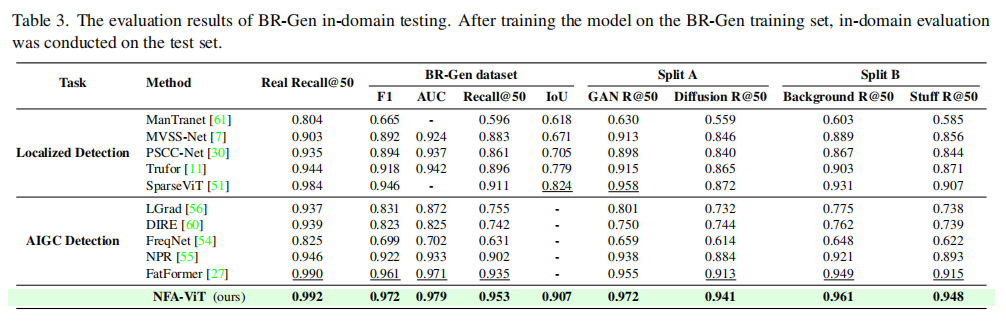
如表3所示,经过重新训练后,所有模型的性能都有了大幅提升,这说明它们具备从BR-Gen数据集中学习新知识的能力。然而,即使是在“开卷考试”的情况下,大多数模型的表现仍不完美。例如,FatFormer的生成图像召回率也只达到了93.5%,而定位性能最好的SparseViT的IoU为82.4%。相比之下,本文提出的NFA-ViT模型在所有关键指标上都取得了最优成绩。其F1分数达到了0.972,IoU更是高达0.907,比次优的SparseViT高出8.3个百分点。这充分说明了NFA-ViT的噪声引导放大机制在处理这类复杂、隐蔽的伪造场景时的巨大优势。
可视化对比
为了更直观地展示模型的定位能力,论文给出了可视化的对比结果。

从图5中可以清晰地看到,面对背景(Background)和环境物(Stuff)这两类伪造区域,传统的局部检测模型如TruFor和SparseViT,其预测的伪造蒙版(mask)要么不完整,要么充满了噪点和错误。而NFA-ViT生成的蒙版则干净利落,与真实的伪造区域高度重合,展现了其卓越的定位精度。
消融实验
为了验证NFA-ViT模型中各个组件的有效性,作者进行了一系列消融实验。其中一个关键实验是关于NAA机制中Top-k参数的选取。
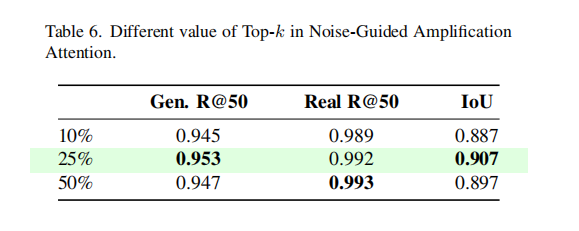
如表6所示,实验对比了不同的k值(即选择最不相似区域的比例)。结果表明,当k=25%时,模型在召回率、F1分数和IoU等各项指标上均达到最佳。这说明选择适量的、差异最显著的区域进行特征放大,是模型取得良好性能的关键。如果k值太小,获取的伪造信息不足;如果k值太大,则可能引入过多无关信息,反而干扰判断。
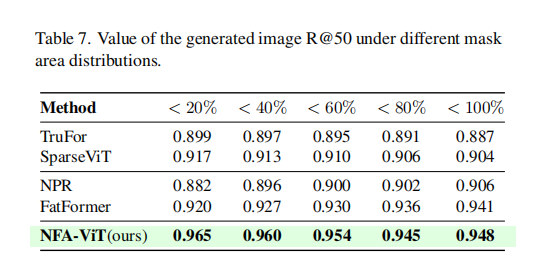
此外,表7对不同伪造面积下的模型性能进行了分析,结果显示,当伪造区域很小(小于20%)时,NFA-ViT的性能优势最为明显,比其他模型高出约4.5%,证明了它对微小伪造的强大检测能力。
五、论文结论与评价
总结
本文直面当前AI生成图像检测领域的一个核心短板——对背景、环境等非物体区域的局部篡改检测能力不足。通过构建一个名为BR-Gen的大规模、高质量数据集,论文成功地量化并暴露了现有方法的局限性。在此基础上,本文提出的NFA-ViT模型,通过一种创新的噪声引导伪造放大机制,能够敏锐地捕捉并放大那些容易被忽略的微弱伪造线索,实现了在检测和定位任务上的双重领先。这项研究不仅为社区提供了一个极具价值的评测基准,也为未来开发更鲁棒、更通用的伪造检测技术指明了新的方向。
优点
- 问题切入点精准:论文敏锐地捕捉到了现有研究在“场景级”伪造检测上的空白,提出的BR-Gen数据集具有很强的现实意义和前瞻性。
- 方法创新且有效:NFA-ViT的噪声引导放大思想非常巧妙。它没有暴力地堆叠网络层数,而是通过一个辅助的噪声分支来智能地引导特征学习,尤其擅长处理“以假乱真”的微小伪造。
- 实验验证充分:论文的实验设计严谨、全面,通过跨域、域内、消融等多种测试,非常有说服力地证明了新数据集的价值和新方法的优越性。
缺点
- 对噪声提取器的依赖:NFA-ViT的性能在一定程度上依赖于Noiseprint++提取噪声指纹的有效性。如果未来出现新的生成模型,其产生的图像在噪声层面与真实图像无法区分,那么NFA-ViT的引导机制可能会失效。
- 超参数的设定:模型中的Top-k是一个固定的超参数,虽然通过实验找到了最优值,但这可能不是在所有情况下都最优的。一个能够根据图像内容自适应调整k值的机制,可能会让模型更具鲁棒性。
- 泛化性的潜在挑战:尽管论文测试了模型在现有数据集上的泛化能力,但BR-Gen本身是由特定的几种生成对抗网络 (Generative Adversarial Networks, GAN) 和扩散模型 (diffusion models) 构建的。面对未来层出不穷的新型生成技术,模型的持续有效性仍需进一步检验。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)