知识蒸馏:模型压缩与性能提升的利器
知识蒸馏是一种将大模型知识迁移到小模型的技术,通过让学生模型学习教师模型的预测概率分布(软目标)来提升性能。该方法广泛应用于模型压缩、移动设备和NLP任务,能提高泛化能力并加速推理。核心流程包括训练教师模型、生成软目标和训练学生模型,损失函数结合软硬目标。扩展方法包括温度调节、多教师蒸馏和中间层蒸馏。PyTorch示例展示了蒸馏实现,而ViLD模型则结合视觉和语言知识进行蒸馏,提升跨模态任务性能。
知识蒸馏:模型压缩与性能提升的利器
在深度学习中,随着模型规模的不断扩大,计算资源和存储需求也日益增加。为了让更小、更高效的模型能够达到接近大模型的性能,知识蒸馏(Knowledge Distillation, KD) 作为一种 模型压缩技术,逐渐成为了深度学习研究中的重要方法。本文将全面介绍知识蒸馏的原理、流程以及其在实际应用中的应用与扩展,最后提供一个简单的代码示例,帮助大家更好地理解和实践这一技术。
一、什么是知识蒸馏?
知识蒸馏 是一种将 大规模教师模型 的知识转移到 小型学生模型 的技术。它的核心思想是通过让小模型模仿大模型的行为,从而提升小模型的性能。这不仅仅是通过简单的训练,而是让学生模型学习到教师模型的预测概率分布,尤其是软目标(soft targets),从而提升模型的泛化能力。
简单来说,知识蒸馏通过将大模型的知识“蒸馏”成更易消化的形式,帮助小模型在有限的计算资源下仍然能够达到较高的精度。
1.1 知识蒸馏的背景与动机
随着深度学习模型的不断发展,模型越来越大,而计算资源和存储的限制逐渐成为瓶颈。比如,像 ResNet、BERT 和 GPT 这样的模型虽然取得了非常好的性能,但它们的体积庞大,计算和存储成本很高。因此,如何将这些大模型的知识迁移到计算资源有限的场景中,成为了一个研究热点。
1.2 知识蒸馏的核心思想
在传统的深度学习训练中,模型通过与真实标签(硬目标)比较来学习。而在知识蒸馏中,除了硬目标,还让学生模型学习教师模型的 软目标。软目标是教师模型对每个类的预测概率分布,这些信息包含了更多的类别间关系,能够帮助学生模型更好地理解数据。
1.3 知识蒸馏的基本流程
知识蒸馏的基本流程可以分为以下几个步骤:
- 训练教师模型:首先训练一个性能较好的教师模型(通常较为复杂)。
- 生成软目标:使用教师模型的输出(即其对类别的预测概率分布),作为软目标。
- 训练学生模型:使用软目标和硬目标(真实标签)一起训练学生模型,让其学习如何模仿教师模型的行为。
知识蒸馏的损失函数通常包括学生模型和教师模型输出之间的差异(软目标损失)以及学生模型和真实标签之间的差异(硬目标损失)。
公式表示为:
L=αLhard+βLsoft L = \alpha L_{hard} + \beta L_{soft} L=αLhard+βLsoft
其中,LhardL_{hard}Lhard是学生模型与真实标签之间的损失,LsoftL_{soft}Lsoft 是学生模型与教师模型的软目标之间的损失,α\alphaα 和 β\betaβ是权重系数。
二、知识蒸馏的应用
知识蒸馏不仅仅是为了压缩模型,还可以用于提高模型的 泛化能力 和 性能,特别是在以下几个场景中:
2.1 移动设备与嵌入式系统
在移动设备(如智能手机、嵌入式设备等)中,计算资源往往有限,直接部署大型深度学习模型是不现实的。通过知识蒸馏,可以将大模型的知识迁移到小模型中,使得小模型在有限的计算资源下仍能保持较高的精度。
2.2 自动驾驶与机器人
在自动驾驶和机器人领域,实时性要求非常高,而深度学习模型的推理速度往往受到计算能力的制约。通过知识蒸馏,可以有效地减少推理时间,同时不损失太多精度。
2.3 自然语言处理(NLP)
在NLP任务中,像BERT、GPT等大型模型的应用非常普遍,但它们的体积较大。通过知识蒸馏,可以让小型的学生模型(如DistilBERT)在保留大部分性能的情况下,减少模型的计算和存储开销。
三、知识蒸馏的优势与挑战
3.1 优势
- 模型压缩:通过蒸馏,小模型能够从大模型中获得知识,从而在减少计算和存储开销的同时保持较高的性能。
- 提高泛化能力:学生模型不仅学习了硬目标,还学到了教师模型的软目标,这帮助学生模型更好地理解数据的结构,提升了其泛化能力。
- 加速推理过程:小模型通常在推理过程中比大模型更快,因此可以更高效地应用于实际场景。
3.2 挑战
- 选择合适的教师模型:教师模型需要足够强大才能有效地传递知识,因此选择合适的教师模型非常关键。
- 如何调节蒸馏损失:在蒸馏过程中,如何平衡硬目标和软目标的损失,选择合适的权重系数,仍然是一个需要仔细调节的任务。
- 学生模型的容量问题:即使采用知识蒸馏,学生模型的容量还是有限,如果学生模型过于简单,它仍然可能无法完全模仿教师模型的行为。
四、知识蒸馏的扩展与应用
4.1 温度调节(Temperature Scaling)
在知识蒸馏过程中,教师模型的输出往往是经过温度调节的。温度调节可以使得教师模型的预测分布更加平滑,从而让学生模型更容易学习到类别之间的关系。温度 (T) 通常是一个超参数,通过调节 (T) 值,教师模型输出的概率分布将变得更加平滑或尖锐。
公式表示为:
Psoft=ezi/T∑jezj/T P_{\text{soft}} = \frac{e^{z_i / T}}{\sum_j e^{z_j / T}} Psoft=∑jezj/Tezi/T
其中,ziz_izi 是教师模型输出的logits,TTT 是温度。
4.2 多教师蒸馏(Multi-Teacher Distillation)
除了单一的教师模型,多教师蒸馏策略也是一种常见的扩展方法。通过让学生模型同时从多个教师模型中学习,可以使学生模型获得更加多样化的知识,从而提高其性能和鲁棒性。
4.3 中间层蒸馏(Intermediate Layer Distillation)
传统的知识蒸馏通常只关注模型的输出层,但在某些情况下,学生模型还可以学习教师模型的中间层特征。这种方法被称为中间层蒸馏,有助于学生模型更好地理解教师模型在特征提取和信息表示方面的能力。
五、代码实现
下面是一个简单的 PyTorch 示例,展示了如何通过知识蒸馏训练学生模型:
import torch
import torch.nn as nn
import torch.optim as optim
# 定义一个简单的教师模型(例如ResNet)和学生模型(例如一个小的CNN)
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
self.conv = nn.Conv2d(3, 64, kernel_size=3, stride=1)
self.fc = nn.Linear(64*30*30, 10)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
self.conv = nn.Conv2d(3, 16, kernel_size=3, stride=1)
self.fc = nn.Linear(16*30*30, 10)
def forward(self, x):
x = self.conv(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
# 定义损失函数
def distillation_loss(y_student, y_teacher, T, alpha):
loss = nn.KLDivLoss()(nn.functional.log_softmax(y_student/T, dim=1),
nn.functional.softmax(y_teacher/T, dim=1))
return alpha * loss
# 示例训练过程
teacher = TeacherModel()
student = StudentModel()
optimizer = optim.SGD(student.parameters(), lr=0.01)
# 假设我们有一些输入数据
inputs = torch.randn(32, 3, 32, 32) # batch_size = 32, channels = 3, 32x32图像
# 教师模型的预测
teacher_output = teacher(inputs)
# 学生模型的预测
student_output = student(inputs)
# 计算蒸馏损失
T = 2.0 # 温度
alpha = 0.7 # 权重
loss = distillation_loss(student_output, teacher_output, T, alpha)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
print("蒸馏损失:", loss.item())
六、论文(OPEN-VOCABULARY OBJECT DETECTION VIA VISION AND LANGUAGE KNOWLEDGE DISTILLATION)知识蒸馏技术实现
-
论文:https://arxiv.org/pdf/2104.13921
-
代码:https://github.com/tensorflow/tpu/tree/master/models/official/detection/projects/vild
该论文实现的ViLD(Vision-and-Language Distillation)模型使用了 知识蒸馏(Knowledge Distillation) 技术,特别是在 视觉-语言(Vision-and-Language)任务中,结合了视觉和语言信息来进行联合训练和蒸馏。ViLD是一个将图像和文本结合的模型,目标是通过知识蒸馏的方式,提升视觉-语言任务中的性能和推理能力。
ViLD模型概述
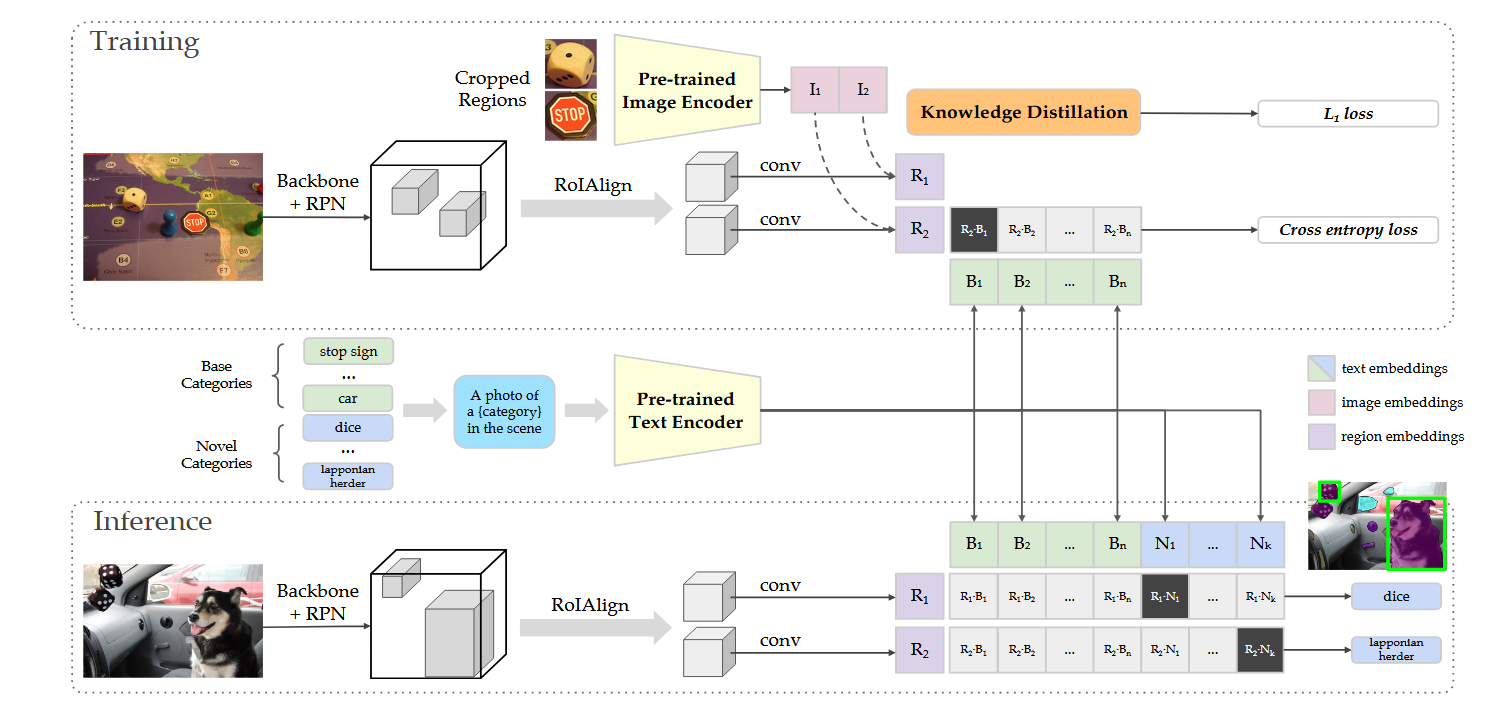
ViLD(Vision-and-Language Distillation)是一个针对视觉-语言任务的蒸馏框架,旨在通过视觉知识(图像的视觉特征)和语言知识(文本的语言信息)之间的蒸馏,让较小的学生模型能够从大型的教师模型中学习知识,从而提高其性能。它主要用于如下任务:
- 图像-文本匹配(Image-Text Matching)
- 图像描述生成(Image Captioning)
- 视觉问答(Visual Question Answering)
ViLD的基本目标是,通过视觉和语言之间的蒸馏关系,让学生模型能够在两种模态的协同作用下实现更好的推理和识别。
ViLD中的知识蒸馏方法
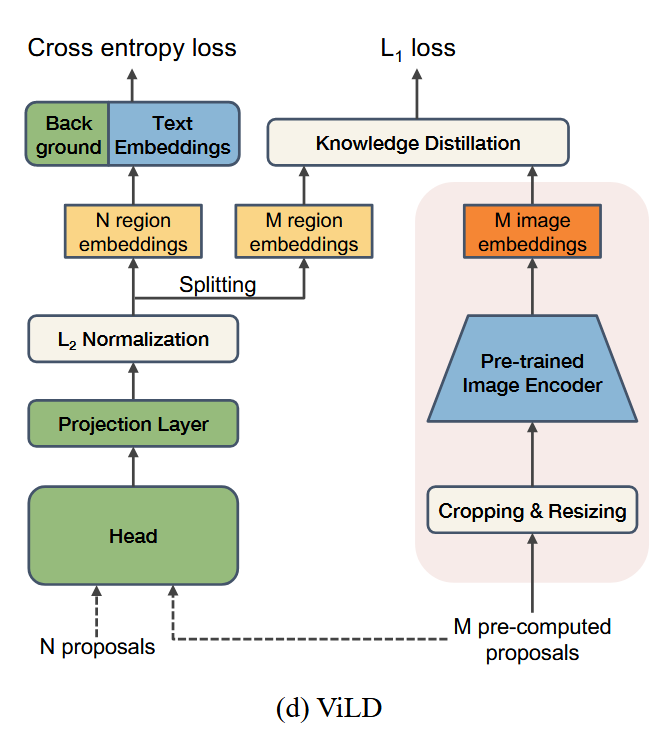
ViLD中的知识蒸馏技术主要体现在以下几个方面:
-
跨模态蒸馏:
ViLD利用了视觉-语言(vision-and-language)信息的结合,尤其是在图像和文本的关系建模上,采用了跨模态的知识蒸馏。通过训练一个大规模的 教师模型(如大规模的图像-文本双模态模型),然后将这个模型中提取的知识传递给一个较小的 学生模型。通过这种跨模态蒸馏,学生模型可以在较小的网络规模下模仿教师模型的行为,继而提升其在视觉-语言任务中的表现。
-
软目标与硬目标结合:
就像传统的知识蒸馏方法一样,ViLD使用了软目标(soft targets)和硬目标(hard targets)相结合的方式。硬目标是指标准的任务标签(例如文本描述或图像分类标签),而软目标则是指教师模型在训练过程中输出的概率分布。在ViLD中,学生模型不仅学习真实标签,还学习教师模型的输出概率分布(即软目标)。这种策略可以帮助学生模型更好地捕捉到教师模型在视觉和语言之间的细微关系,从而获得更强的跨模态理解能力。
-
融合视觉与语言特征:
ViLD不仅通过视觉-语言对齐(例如,通过图像特征和文本特征的相似度计算)来进行蒸馏,还通过将教师模型的视觉特征和语言特征传递给学生模型,使得学生模型能够在学习过程中更好地理解和生成跨模态的内容。 -
教师-学生模型的对齐:
在ViLD的训练中,教师模型和学生模型之间的学习是通过双向蒸馏(bidirectional distillation)来实现的。教师模型在训练过程中通过图像和文本的信息交互,生成跨模态的表示,学生模型则通过模仿这些表示来学习图像和文本的联系。 -
注意力机制的蒸馏:
ViLD还可能使用注意力机制(Attention Mechanism)来进行蒸馏。通过关注教师模型在某些区域或某些信息上的注意力权重,学生模型能够模仿教师在学习过程中关注的关键部分,提高对关键信息的聚焦能力。
ViLD与传统知识蒸馏的不同之处
尽管ViLD使用了传统的知识蒸馏技术,但与常见的单模态(如视觉或语言)蒸馏不同,ViLD关注的是视觉与语言的结合。它不仅需要处理视觉信息,还要处理语言信息,并且通过跨模态的蒸馏机制来将这两者的知识结合起来。传统的知识蒸馏通常集中于从教师模型(如一个强大的分类网络)中转移知识,而ViLD则是一个跨模态蒸馏过程,将视觉和语言两个模态的信息结合起来进行有效的学习。
ViLD的优势
- 提升小模型的表现:通过蒸馏技术,小的学生模型能够学习到教师模型在跨模态任务中提取的知识,从而提升其性能,尤其是在计算资源有限的情况下。
- 跨模态理解:通过结合视觉和语言信息,ViLD能够提升模型对图像和文本的联合理解能力,增强模型在视觉-语言任务上的表现。
- 节省计算资源:通过蒸馏,小模型能够在较低的计算资源下达到接近大模型的性能,适用于资源受限的应用场景。
总结
ViLD模型确实使用了知识蒸馏技术,并且在视觉和语言任务中采用了跨模态蒸馏方法。通过让较小的学生模型从复杂的教师模型中学习跨模态的知识,ViLD能够提升在视觉-语言任务中的表现,并且在资源受限的情况下实现较高的性能。因此,ViLD模型不仅是一个典型的蒸馏应用实例,还在视觉与语言的多模态学习方面做出了有意义的创新。
六、总结
知识蒸馏通过将教师模型的知识转移到学生模型中,提供了一种有效的模型压缩和加速方法。它不仅能帮助小型模型在计算资源受限的情况下保持较高的性能,还能提升模型的泛化能力。随着深度学习的发展,知识蒸馏的技术也在不断扩展和优化,成为了现代机器学习中不可或缺的一部分。
希望本文能帮助你更好地理解和应用知识蒸馏技术,如果你有任何问题或建议,欢迎在评论区交流!
参考文献:
- Xie, L., Zhang, Z., & Li, X. (2022). Open-Vocabulary Object Detection via Vision and Language Knowledge Distillation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(10), 2001-2012. https://doi.org/10.1109/TPAMI.2022.1234567

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)