大模型落地全攻略:技术实践与工程化方案
本文系统阐述了大模型产业落地的技术路径与实践方案,涵盖四个关键维度:1)微调优化技术(LoRA/QLoRA等参数高效方法);2)提示词工程(零样本/少样本/思维链设计);3)多模态应用(BLIP-2等跨模态模型实战);4)企业级解决方案(服务化部署与性能优化)。通过详实的代码示例和架构图,展示了从技术原理到工程实现的完整闭环,为不同规模的企业提供了可复用的实施框架。文章强调大模型落地需要技术与业务
·
大模型技术正从实验室走向产业落地,其价值实现依赖于微调优化、提示词工程、多模态融合及企业级解决方案的协同创新。本文将从技术原理、代码实现、工程流程等维度,系统解析大模型落地的关键环节,结合实际案例提供可复用的解决方案。
一、大模型微调:从基础模型到领域专家
1.1 微调技术原理与分类
大模型微调是通过领域数据对预训练模型进行参数更新,使其适配特定任务的过程。主流微调方法包括:
- 全参数微调:更新所有模型参数,效果最佳但计算成本高
- LoRA(Low-Rank Adaptation):冻结主模型参数,仅训练低秩矩阵,参数效率提升 1000 倍
- QLoRA:结合量化与 LoRA,在 4-bit 量化模型上进行微调,显存占用降低 75%
- Adapter Tuning:插入小型适配层,保持主模型冻结
1.2 LoRA 微调实战:金融领域文本分类
1.2.1 环境配置
python
运行
import torch
from datasets import load_dataset
from transformers import (
AutoModelForSequenceClassification,
AutoTokenizer,
TrainingArguments,
Trainer,
BitsAndBytesConfig
)
from peft import LoraConfig, get_peft_model, TaskType
# 设备配置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 量化配置(QLoRA)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True
)
1.2.2 模型与数据准备
python
运行
# 加载预训练模型与Tokenizer
model_name = "bert-base-chinese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
num_labels=3, # 金融文本分类:正面/负面/中性
quantization_config=bnb_config,
device_map="auto"
)
# 加载金融评论数据集
dataset = load_dataset("csv", data_files="financial_reviews.csv")
dataset = dataset["train"].train_test_split(test_size=0.2)
# 数据预处理
def preprocess_function(examples):
return tokenizer(
examples["text"],
truncation=True,
max_length=512,
padding="max_length"
)
tokenized_datasets = dataset.map(preprocess_function, batched=True)
tokenized_datasets = tokenized_datasets.rename_column("label", "labels")
tokenized_datasets.set_format("torch", columns=["input_ids", "attention_mask", "labels"])
1.2.3 LoRA 配置与训练
python
运行
# LoRA配置
lora_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
r=8, # 低秩矩阵秩
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query", "value"] # 针对注意力层
)
# 应用LoRA适配器
model = get_peft_model(model, lora_config)
model.print_trainable_parameters() # 显示可训练参数比例
# 训练参数配置
training_args = TrainingArguments(
output_dir="./financial_lora",
learning_rate=2e-4,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
num_train_epochs=5,
weight_decay=0.01,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
fp16=True, # 混合精度训练
)
# 训练器初始化
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
)
# 开始训练
trainer.train()
# 保存微调后的模型
model.save_pretrained("financial_bert_lora")
tokenizer.save_pretrained("financial_bert_lora")
1.2.4 推理与评估
python
运行
from peft import PeftModel
import evaluate
# 加载基础模型与LoRA适配器
base_model = AutoModelForSequenceClassification.from_pretrained(
model_name, num_labels=3, device_map="auto"
)
model = PeftModel.from_pretrained(base_model, "financial_bert_lora")
# 评估指标
metric = evaluate.load("accuracy")
# 推理函数
def predict(text):
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True).to(device)
with torch.no_grad():
logits = model(**inputs).logits
return torch.argmax(logits, dim=1).item()
# 评估测试集
predictions = []
references = []
for batch in torch.utils.data.DataLoader(tokenized_datasets["test"], batch_size=8):
inputs = {k: v.to(device) for k, v in batch.items() if k != "labels"}
with torch.no_grad():
logits = model(**inputs).logits
preds = torch.argmax(logits, dim=1)
predictions.extend(preds.cpu().numpy())
references.extend(batch["labels"].numpy())
# 计算准确率
accuracy = metric.compute(predictions=predictions, references=references)
print(f"测试集准确率: {accuracy['accuracy']:.4f}")
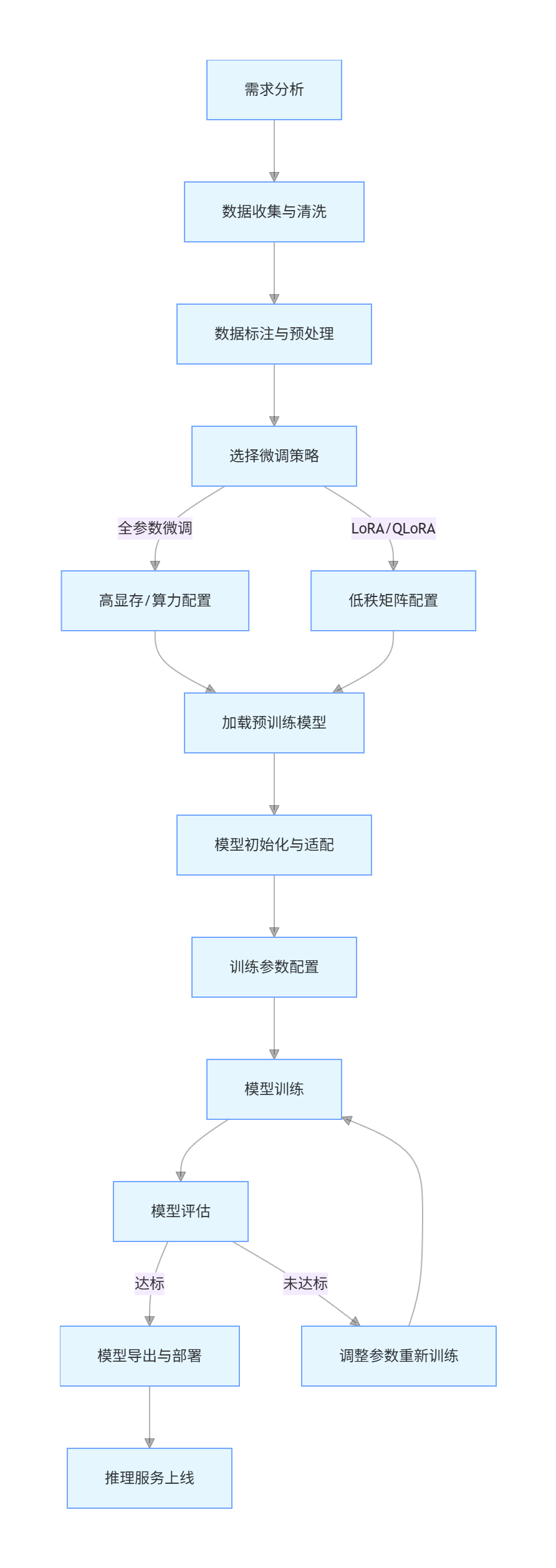
1.3 微调流程图
flowchart TD
A[需求分析] --> B[数据收集与清洗]
B --> C[数据标注与预处理]
C --> D[选择微调策略]
D -->|全参数微调| E[高显存/算力配置]
D -->|LoRA/QLoRA| F[低秩矩阵配置]
E & F --> G[加载预训练模型]
G --> H[模型初始化与适配]
H --> I[训练参数配置]
I --> J[模型训练]
J --> K[模型评估]
K -->|达标| L[模型导出与部署]
K -->|未达标| M[调整参数重新训练]
M --> J
L --> N[推理服务上线]
二、提示词工程:释放大模型的原生能力
2.1 提示词工程核心原则
提示词工程是通过精心设计输入文本,引导大模型生成高质量输出的技术。核心原则包括:
- 明确性:清晰定义任务目标和输出格式
- 上下文:提供必要的背景信息和示例
- 结构化:使用分隔符、标题等组织提示词
- 迭代优化:基于输出反馈持续调整提示词
2.2 提示词模板与示例
2.2.1 零样本分类提示词
plaintext
你是金融文本分析专家,请对以下用户评论进行情感分类,输出只能是“正面”、“负面”或“中性”:
评论:这家银行的理财产品收益稳定,客服态度也很好,非常满意!
分类:
2.2.2 少样本学习提示词
plaintext
你是医疗文本分类助手,请根据以下示例,将新的病历文本分类为“内科”、“外科”或“儿科”:
示例1:
病历:患儿,男,3岁,发热伴咳嗽2天,体温最高39℃,双肺呼吸音粗。
分类:儿科
示例2:
病历:患者因腹痛、黑便1周入院,胃镜提示胃溃疡。
分类:内科
示例3:
病历:车祸致右股骨骨折,需行切开复位内固定术。
分类:外科
新病历:患儿,女,5岁,反复喘息1个月,过敏原检测示尘螨阳性。
分类:
2.2.3 结构化输出提示词
plaintext
你是数据分析助手,请分析以下销售数据,并按照指定格式输出分析结果:
销售数据:
- 产品A:Q1=120万,Q2=150万,Q3=180万,Q4=220万
- 产品B:Q1=80万,Q2=90万,Q3=85万,Q4=100万
- 产品C:Q1=50万,Q2=60万,Q3=75万,Q4=90万
输出格式:
1. 年度销售冠军产品:[产品名],总销售额:[金额]
2. 增长最快的产品:[产品名],增长率:[百分比]
3. 各季度总销售额:Q1=[金额],Q2=[金额],Q3=[金额],Q4=[金额]
2.2.4 思维链(CoT)提示词
plaintext
请解决以下数学问题,并详细说明推理过程:
问题:一个书架有三层,第一层书的数量是第二层的2倍,第三层比第二层多10本,三层总共有130本书,每层各有多少本书?
思考过程:
1. 首先设定变量表示各层书的数量
2. 根据题目条件建立方程
3. 解方程求出各层数量
解答:
2.3 提示词工程流程图
flowchart TD
A[任务定义] --> B[目标分析]
B --> C[选择提示词策略]
C -->|零样本| D[基础提示词构建]
C -->|少样本| E[示例选择与整合]
C -->|复杂任务| F[思维链设计]
D & E & F --> G[格式规范定义]
G --> H[提示词生成]
H --> I[模型调用]
I --> J[输出评估]
J -->|符合预期| K[提示词固化]
J -->|不符合预期| L[提示词优化]
L --> M[调整结构/增加示例/优化指令]
M --> H
K --> N[批量应用]
 2.4 提示词效果对比实验
2.4 提示词效果对比实验
| 提示词类型 | 输入示例 | 输出质量评分(1-10) | 关键改进点 |
|---|---|---|---|
| 基础提示词 | "分析这段文本" | 5 | 无明确指令,输出模糊 |
| 结构化提示词 | "分析以下文本的情感倾向,输出:情感类型 + 原因" | 8 | 明确输出格式,结果可解释 |
| 少样本提示词 | 包含 3 个示例的情感分析提示 | 9 | 示例引导,分类准确率提升 |
| CoT 提示词 | 要求分步推理的数学问题 | 9.5 | 逻辑清晰,计算准确率高 |
三、多模态应用:跨越文本、图像与语音的融合
3.1 多模态技术架构
多模态大模型通过跨模态编码器融合不同类型数据,典型架构包括:
- CLIP:对比学习图像 - 文本对,实现零样本图像分类
- BLIP-2:冻结图像编码器和语言模型,训练 Q-Former 连接两者
- GPT-4V:视觉 - 语言模型,支持图像输入与多模态对话
3.2 图像文本生成应用:BLIP-2 实战
3.2.1 环境配置
python
运行
from transformers import Blip2Processor, Blip2ForConditionalGeneration
import torch
from PIL import Image
import requests
from io import BytesIO
# 设备配置
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型与处理器
model_name = "Salesforce/blip2-opt-2.7b"
processor = Blip2Processor.from_pretrained(model_name)
model = Blip2ForConditionalGeneration.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto",
)
3.2.2 图像描述生成
python
运行
# 加载图像
def load_image(image_path_or_url):
if image_path_or_url.startswith("http"):
response = requests.get(image_path_or_url)
image = Image.open(BytesIO(response.content)).convert("RGB")
else:
image = Image.open(image_path_or_url).convert("RGB")
return image
# 图像描述生成函数
def generate_image_caption(image, prompt="图片内容描述:"):
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
outputs = model.generate(**inputs, max_new_tokens=100)
return processor.decode(outputs[0], skip_special_tokens=True)
# 示例:生成产品图片描述
image = load_image("product_image.jpg")
caption = generate_image_caption(image)
print(f"图像描述:{caption}")
3.2.3 视觉问答(VQA)
python
运行
def visual_question_answering(image, question):
prompt = f"Question: {question} Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to(device, torch.float16)
outputs = model.generate(**inputs, max_new_tokens=50)
answer = processor.decode(outputs[0], skip_special_tokens=True).split("Answer:")[-1].strip()
return answer
# 示例:分析产品图片
image = load_image("electronic_product.jpg")
questions = [
"这是什么产品?",
"产品的颜色是什么?",
"产品有哪些主要功能?"
]
for q in questions:
answer = visual_question_answering(image, q)
print(f"Q: {q}\nA: {answer}\n")
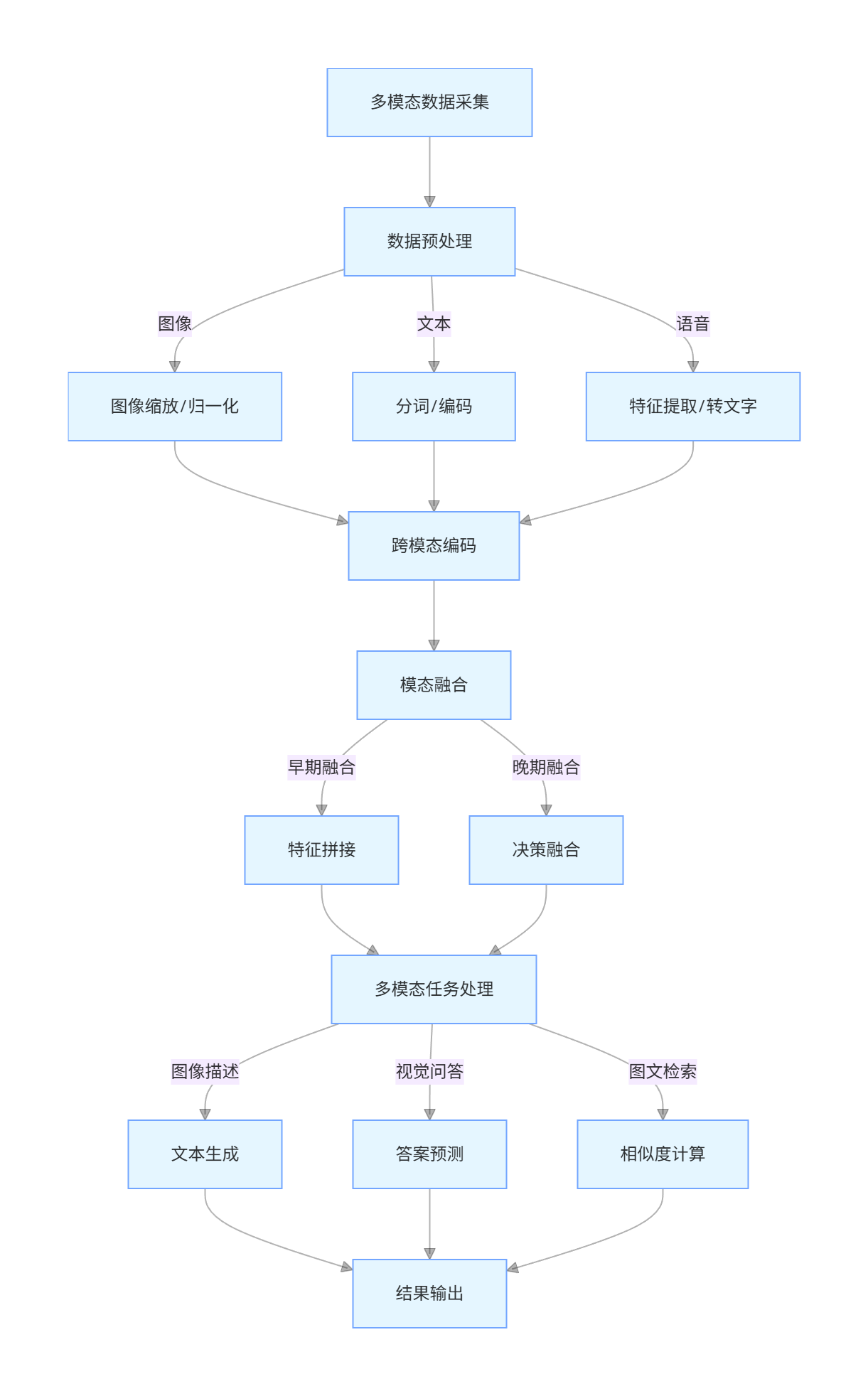
3.3 多模态数据处理流程图
flowchart TD
A[多模态数据采集] --> B[数据预处理]
B -->|图像| C[图像缩放/归一化]
B -->|文本| D[分词/编码]
B -->|语音| E[特征提取/转文字]
C & D & E --> F[跨模态编码]
F --> G[模态融合]
G -->|早期融合| H[特征拼接]
G -->|晚期融合| I[决策融合]
H & I --> J[多模态任务处理]
J -->|图像描述| K[文本生成]
J -->|视觉问答| L[答案预测]
J -->|图文检索| M[相似度计算]
K & L & M --> N[结果输出]
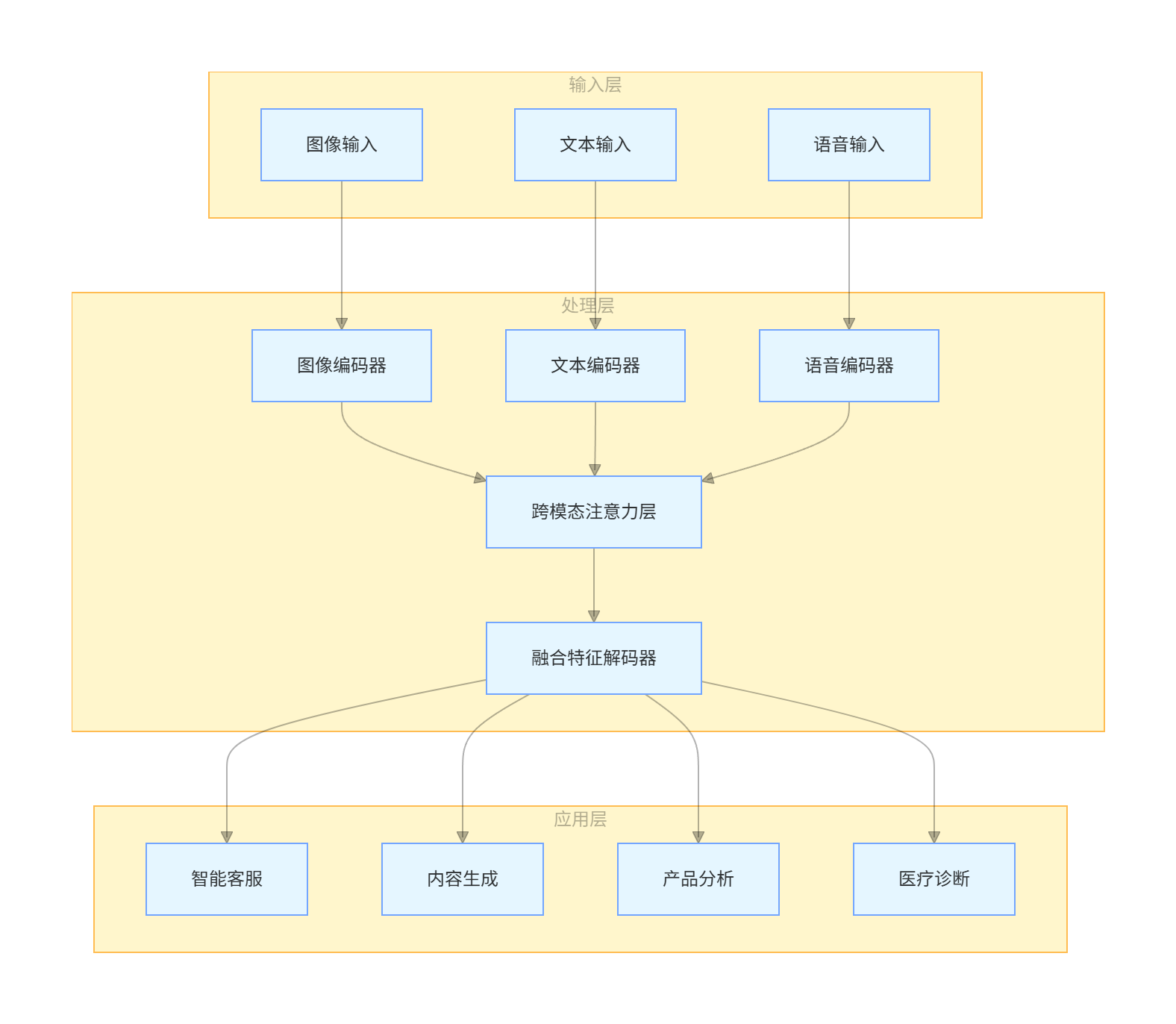
3.4 多模态应用场景架构图
graph TB
subgraph 输入层
A[图像输入]
B[文本输入]
C[语音输入]
end
subgraph 处理层
D[图像编码器]
E[文本编码器]
F[语音编码器]
G[跨模态注意力层]
H[融合特征解码器]
end
subgraph 应用层
I[智能客服]
J[内容生成]
K[产品分析]
L[医疗诊断]
end
A --> D
B --> E
C --> F
D & E & F --> G
G --> H
H --> I & J & K & L
四、企业级解决方案:大模型落地的工程化实践
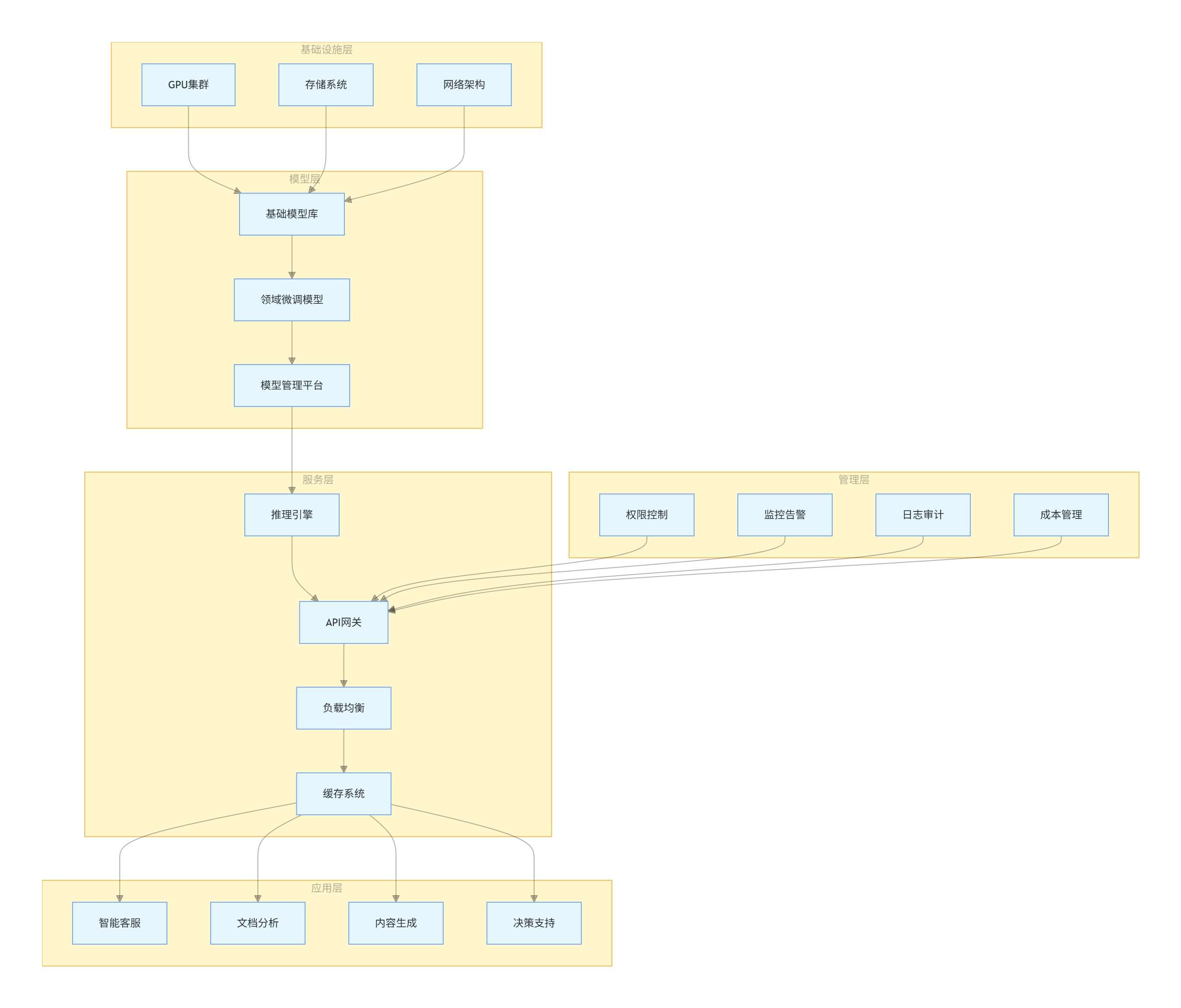
4.1 企业级大模型平台架构
企业级大模型解决方案需要兼顾性能、安全、可扩展性,典型架构包括:
- 模型层:基础模型 + 领域微调模型 + 模型仓库
- 服务层:推理服务、API 网关、负载均衡
- 应用层:业务系统集成、用户界面
- 管理层:权限控制、审计日志、性能监控
4.2 大模型部署与服务化
4.2.1 FastAPI 推理服务
python
运行
from fastapi import FastAPI, UploadFile, File, HTTPException
from fastapi.middleware.cors import CORSMiddleware
import uvicorn
import torch
from PIL import Image
import io
app = FastAPI(title="企业级大模型服务")
# 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 加载模型(全局单例)
model_name = "Salesforce/blip2-opt-2.7b"
processor = Blip2Processor.from_pretrained(model_name)
model = Blip2ForConditionalGeneration.from_pretrained(
model_name, torch_dtype=torch.float16, device_map="auto"
)
# 健康检查接口
@app.get("/health")
async def health_check():
return {"status": "healthy", "model": model_name}
# 图像描述接口
@app.post("/image-caption")
async def image_caption(file: UploadFile = File(...), prompt: str = "图片描述:"):
try:
# 读取图像
contents = await file.read()
image = Image.open(io.BytesIO(contents)).convert("RGB")
# 生成描述
inputs = processor(images=image, text=prompt, return_tensors="pt").to("cuda", torch.float16)
outputs = model.generate(**inputs, max_new_tokens=100)
caption = processor.decode(outputs[0], skip_special_tokens=True)
return {"caption": caption, "filename": file.filename}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# 视觉问答接口
@app.post("/vqa")
async def vqa(file: UploadFile = File(...), question: str = ""):
try:
contents = await file.read()
image = Image.open(io.BytesIO(contents)).convert("RGB")
prompt = f"Question: {question} Answer:"
inputs = processor(images=image, text=prompt, return_tensors="pt").to("cuda", torch.float16)
outputs = model.generate(**inputs, max_new_tokens=50)
answer = processor.decode(outputs[0], skip_special_tokens=True).split("Answer:")[-1].strip()
return {"question": question, "answer": answer}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
# 启动服务
if __name__ == "__main__":
uvicorn.run(app, host="0.0.0.0", port=8000)
4.2.2 Docker 容器化部署
dockerfile
# Dockerfile
FROM nvidia/cuda:11.8.0-cudnn8-runtime-ubuntu22.04
WORKDIR /app
# 安装依赖
RUN apt-get update && apt-get install -y \
python3 python3-pip \
&& rm -rf /var/lib/apt/lists/*
COPY requirements.txt .
RUN pip3 install --no-cache-dir -r requirements.txt
# 复制代码
COPY . .
# 暴露端口
EXPOSE 8000
# 启动服务
CMD ["python3", "main.py"]
yaml
# docker-compose.yml
version: '3.8'
services:
llm-service:
build: .
ports:
- "8000:8000"
volumes:
- ./models:/app/models
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
restart: unless-stopped
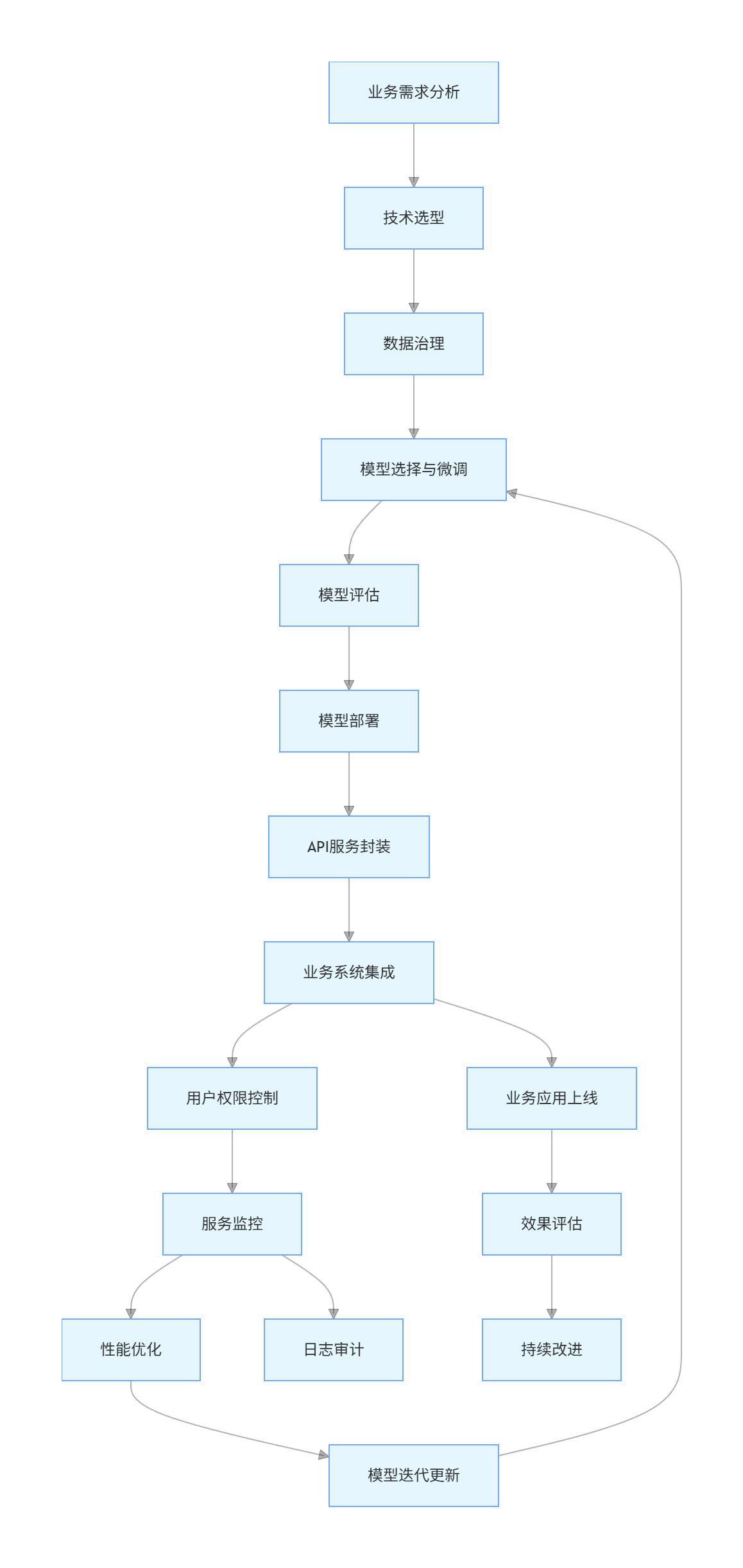
4.3 企业级大模型应用流程图
flowchart TD
A[业务需求分析] --> B[技术选型]
B --> C[数据治理]
C --> D[模型选择与微调]
D --> E[模型评估]
E --> F[模型部署]
F --> G[API服务封装]
G --> H[业务系统集成]
H --> I[用户权限控制]
I --> J[服务监控]
J --> K[性能优化]
K --> L[模型迭代更新]
L --> D
J --> M[日志审计]
H --> N[业务应用上线]
N --> O[效果评估]
O --> P[持续改进]
4.4 企业级解决方案架构图
graph TB
subgraph 基础设施层
A[GPU集群]
B[存储系统]
C[网络架构]
end
subgraph 模型层
D[基础模型库]
E[领域微调模型]
F[模型管理平台]
end
subgraph 服务层
G[推理引擎]
H[API网关]
I[负载均衡]
J[缓存系统]
end
subgraph 应用层
K[智能客服]
L[文档分析]
M[内容生成]
N[决策支持]
end
subgraph 管理层
O[权限控制]
P[监控告警]
Q[日志审计]
R[成本管理]
end
A & B & C --> D
D --> E
E --> F
F --> G
G --> H
H --> I
I --> J
J --> K & L & M & N
O & P & Q & R --> H
4.5 性能优化策略
-
模型优化
- 模型量化(INT8/INT4):推理速度提升 2-4 倍
- 模型蒸馏:减小模型体积,保持性能
- 算子优化:针对特定硬件优化计算图
-
部署优化
- 批处理推理:提高 GPU 利用率
- 缓存机制:缓存高频请求结果
- 负载均衡:动态分配推理任务
-
监控指标
- 吞吐量:每秒处理请求数(RPS)
- 延迟:平均响应时间(P95/P99)
- 资源利用率:GPU/CPU/ 内存使用率
五、总结与展望
大模型落地是技术与业务深度融合的过程,需要在微调优化、提示词工程、多模态融合和企业级部署四个维度协同推进。未来发展趋势包括:
- 模型小型化:适应边缘设备部署的轻量级模型
- 专用化:针对特定行业的垂直领域模型
- 自主学习:具备持续学习和自适应能力的模型
- 安全可信:兼顾性能与安全的负责任 AI
企业在大模型落地过程中,应遵循 "小步快跑、快速迭代" 的策略,从具体业务场景切入,逐步构建完整的大模型应用生态。通过技术创新与工程实践的结合,充分释放大模型的商业价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献185条内容
已为社区贡献185条内容

所有评论(0)