即插即用!AAAI 2025 DDI模块发布,双MLP实现跨尺度信息融合
时间序列预测(Time Series Forecasting, TSF)领域的主流方法,如基于Transformer和MLP的模型,在处理现实世界中复杂的时间序列数据时面临各自的挑战。真实世界的时间序列通常在不同尺度上展现出多样的模式,而未来的变化正是由这些重叠尺度的相互作用共同决定的。Transformer模型虽擅长捕捉长程依赖,但计算复杂度高且易过拟合;MLP模型虽计算高效,却难以有效捕获复杂
时间序列预测(Time Series Forecasting, TSF)领域的主流方法,如基于Transformer和MLP的模型,在处理现实世界中复杂的时间序列数据时面临各自的挑战。
真实世界的时间序列通常在不同尺度上展现出多样的模式,而未来的变化正是由这些重叠尺度的相互作用共同决定的。Transformer模型虽擅长捕捉长程依赖,但计算复杂度高且易过拟合;MLP模型虽计算高效,却难以有效捕获复杂尺度下的时间模式。
针对这一“多尺度纠缠效应”,本文提出了一种新颖的、基于MLP的自适应多尺度分解(Adaptive Multi-Scale Decomposition, AMD)框架。该框架首先将时间序列分解为多个尺度的不同时间模式,然后对这些模式中的时间和通道依赖性进行建模,最后利用自相关性来自适应地聚合多尺度预测结果。此方法旨在克服现有方法的局限性,通过精确识别和利用主导时间模式,在提升预测精度的同时保持计算效率。
01 论文基本信息

- 标题: Adaptive Multi-Scale Decomposition Framework for Time Series Forecasting(用于时间序列预测的自适应多尺度分解框架)
- 核心模块: 多尺度可分解混合(Multi-Scale Decomposable Mixing, MDM)、双重依赖交互(Dual Dependency Interaction,
DDI)、自适应多预测器合成(Adaptive Multi-predictor Synthesis, AMS)
02 算法框架与核心模块
2.1 算法框架
本文提出的AMD框架整体架构所示。首先,输入的时间序列X经过MDM模块进行多尺度分解与信息混合,生成富含多尺度信息的张量U。接着,DDI模块对U进行处理,同时建模其时间和通道维度的依赖关系。最后,AMS模块为每个通道生成独立的预测器权重S,并对DDI的输出进行加权求和,得到最终的预测结果Y。整个框架通过端到端的方式进行训练。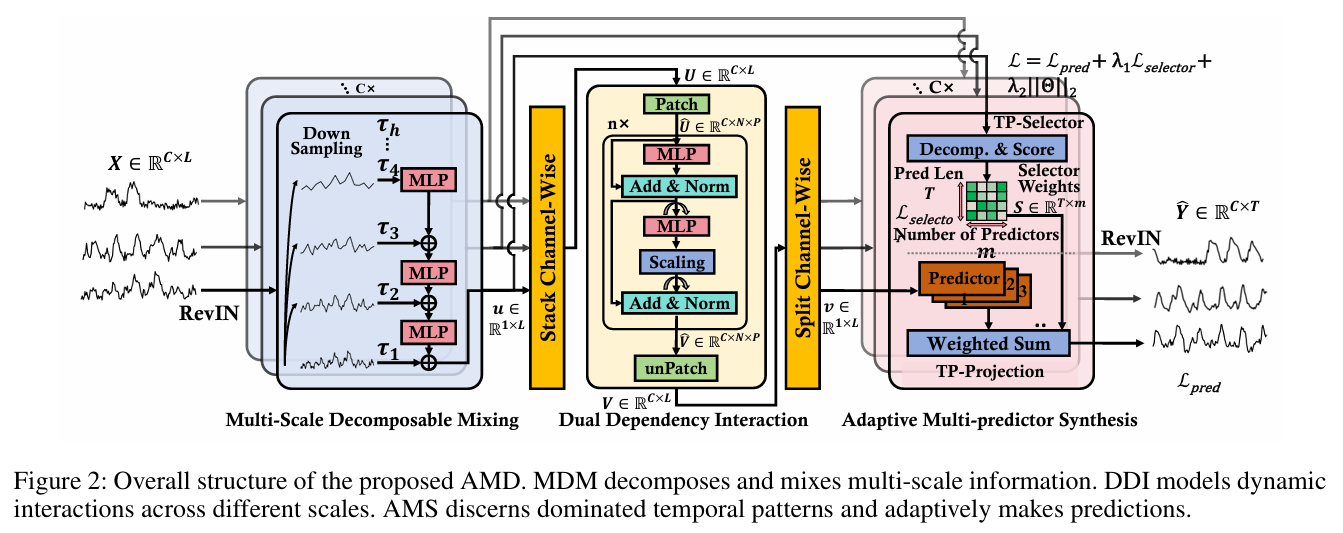
2.2 核心模块
模块一:多尺度可分解混合 (Multi-Scale Decomposable Mixing, MDM)
- 核心功能: 将原始时间序列分解为多个不同粒度(从细到粗)的时间模式,然后将这些模式的信息逐级混合,为后续模块提供一个包含多尺度信息的增强表示。
- 实现逻辑: 分解过程通过对输入序列进行多次**平均池化(Average Pooling)**实现,逐层提取更粗粒度的时间模式
τ。混合过程则采用一个自顶向下(从粗到细)的前馈残差网络,将粗粒度的信息ξ逐层融入细粒度模式中。- 分解逻辑:
τi=AvgPooling(τi−1) \tau_i = \text{AvgPooling}(\tau_{i-1}) τi=AvgPooling(τi−1) - 混合逻辑:
ξi=τi+MLP(ξi+1) \xi_i = \tau_i + \text{MLP}(\xi_{i+1}) ξi=τi+MLP(ξi+1)
- 分解逻辑:
- 优势: 相比传统的季节-趋势分解,MDM能够更灵活地将序列分解为多个互补的尺度信息,提供了一个更全面、更细致的序列视图,从而增强了模型对复杂时间动态的表达能力。
模块二:双重依赖交互 (Dual Dependency Interaction, DDI)
- 核心功能: 旨在对MDM模块输出的多尺度混合信息同时建模时间依赖(temporal dependencies)和通道依赖(channel dependencies)。
- 实现逻辑: 该模块接收混合后的多尺度信息
U,并对其进行分块(Patching)处理。它交替使用两个MLP:一个在时间维度上共享,用于混合时间信息;另一个在通道维度上共享(通过矩阵转置实现),用于混合通道信息。通过残差连接保留原始信息。引入一个缩放因子β来平衡两种依赖的重要性。- 时间混合:
Zt+Pt=U^t+Pt+MLP(V^tt−P) Z_{t+P_t} = \hat{U}_{t+P_t} + \text{MLP}(\hat{V}_{t_{t-P}}) Zt+Pt=U^t+Pt+MLP(V^tt−P) - 通道混合:
V^t+Pt=Zt+Pt+β⋅MLP((Zt+Pt)T)T \hat{V}_{t+P_t} = Z_{t+P_t} + \beta \cdot \text{MLP}((Z_{t+P_t})^T)^T V^t+Pt=Zt+Pt+β⋅MLP((Zt+Pt)T)T
- 时间混合:
- 优势: DDI能够显式地捕捉不同时间步和不同变量之间的动态交互。引入的缩放因子
β允许模型自适应地调整对通道间依赖的关注程度,从而在增强信息交互的同时抑制不相关变量带来的噪声,提升了模型的鲁棒性。
模块三:自适应多预测器合成 (AMS)
- 核心功能: 采用**专家混合(Mixture of Experts, MoE)**思想,为不同的时间模式训练专门的预测器,并根据输入动态地为这些预测器分配权重,最后加权合成最终的预测结果。
- 实现逻辑: 该模块由两部分组成:1) 时间模式选择器 (TP-Selector) 和 2) 时间模式投影 (TP-Projection)。TP-Selector通过一个带噪声的门控网络,为多个预测器生成权重
S。TP-Projection则包含多个并行的预测器(均为MLP),它们的输出与TP-Selector生成的权重S相乘后求和,得到最终预测值。- 选择器权重生成(部分):
S=Softmax(TopK(Softmax(Q(u)),k)) S = \text{Softmax}(\text{TopK}(\text{Softmax}(Q(u)), k)) S=Softmax(TopK(Softmax(Q(u)),k)) - 预测值合成:
y^=∑j=0mSj⋅Predictorj(v) \hat{y} = \sum_{j=0}^{m} S_j \cdot \text{Predictor}_j(v) y^=j=0∑mSj⋅Predictorj(v)
- 选择器权重生成(部分):
- 优势: 相比于对所有尺度信息进行简单平均,AMS能够识别并聚焦于在不同时间段内对未来起主导作用的时间模式,实现了预测策略的动态调整。这种自适应加权机制不仅提升了预测的准确性,也增强了模型的可解释性。
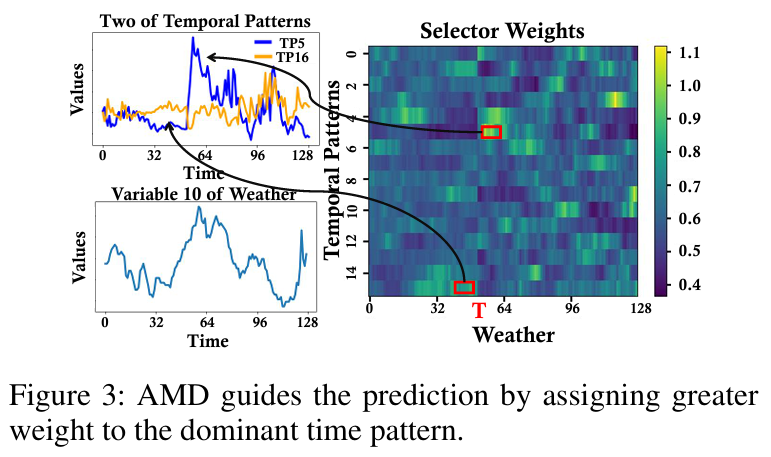
03 模块适用任务
- 核心应用场景: 长时间序列预测与短时间序列预测。特别适用于那些呈现出多重周期性、趋势性且动态变化的真实世界时间序列数据,例如气象、电力、交通流量和金融等领域。
- 方法论核心: 本质思想是“分解-建模-自适应综合”。它将一个复杂的预测问题,通过在不同时间尺度上进行分解,转化为一组更简单的子问题进行建模,最后通过一个智能的、数据驱动的专家混合机制将子问题的解进行动态组合,得到最终的全局最优解。
- 启发性拓展:
- 频域自适应分解: 结合论文中提到的FITS等工作,未来可以探索在频域中进行自适应的模式分解与挖掘,以替代当前基于平均池化的时域分解,可能更高效地捕捉周期性特征。
- 深度网络分布偏移问题的改进: 论文中使用了RevIN来处理输入层的分布偏移,但指出深层网络中的分布变化仍是挑战。未来可以研究更先进的归一化技术,以解决AMD框架在更深层次结构中的稳定性问题。
04 实验结果与可视化分析
核心实验与结论
本文最能体现其贡献的核心实验是模型组件的消融研究(Ablation Study),尤其是对AMS模块的分析。
- 实验目的: 该实验旨在验证AMD框架中每个核心模块(MDM, DDI, AMS)的必要性和有效性。特别是验证AMS模块的自适应加权策略是否优于其他聚合方法(如随机排序、平均加权或单一预测器),并证明性能提升并非仅仅源于模型参数量的增加。
- 关键结果:
- w/o AMS: 移除AMS模块并替换为单个线性预测器后,模型性能显著下降,证明了多预测器架构的优势。
- AverageWeight: 将AMS的自适应权重替换为简单的平均加权后,性能同样下降。这表明,对不同时间模式赋予同等重要性不如AMS的动态加权策略有效。
- w/o MDM: 移除MDM模块,仅使用单一尺度进行预测,误差同样增加,说明了多尺度分解的必要性。
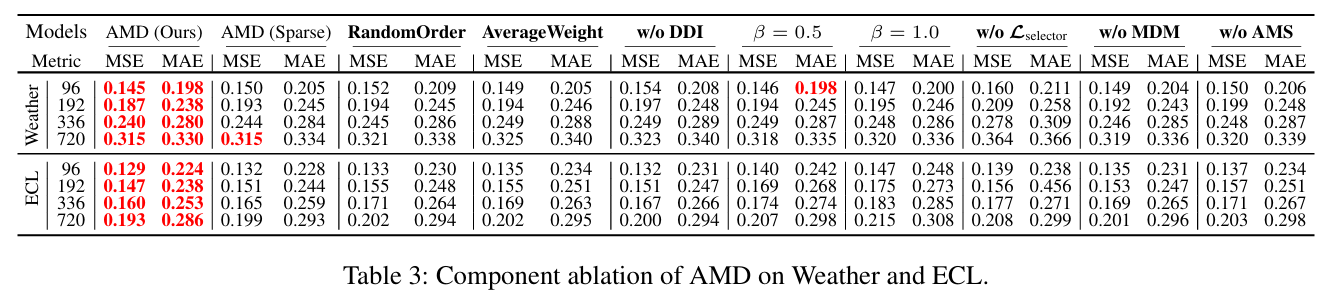
- 作者结论: 作者基于此实验得出结论:AMD框架的优越性能确实来源于其独特的多尺度分解和自适应合成机制。与依赖排列不变性的自注意力机制不同,AMS能够保留序列的时序信息,并有效利用随时间变化的主导模式。与简单的平均聚合相比,AMS通过自适应地为不同时间模式分配权重,实现了更精准的预测。这证明了AMD框架设计的合理性与高效性。
05 即插即用模块代码
多尺度可分解混合(MDM)
-
核心功能:将序列按多种尺度进行平均池化分解,并用逐级前馈残差混合回细粒度表示
-
核心优势:以轻量方式获取互补的多尺度信息,提升复杂时序的表达能力
-
核心代码(片段):
models/common.py:58与models/common.py:79
class MDM(nn.Module):
def __init__(self, input_shape, k=3, c=2, layernorm=True):
super(MDM, self).__init__()
self.seq_len = input_shape[0]
self.k = k
if self.k > 0:
self.k_list = [c ** i for i in range(k, 0, -1)]
self.avg_pools = nn.ModuleList([nn.AvgPool1d(kernel_size=k, stride=k) for k in self.k_list])
self.linears = nn.ModuleList(
[
nn.Sequential(nn.Linear(self.seq_len // k, self.seq_len // k),
nn.GELU(),
nn.Linear(self.seq_len // k, self.seq_len * c // k),
)
for k in self.k_list
]
)
self.layernorm = layernorm
if self.layernorm:
self.norm = nn.BatchNorm1d(input_shape[0] * input_shape[-1])
def forward(self, x):
if self.layernorm:
x = self.norm(torch.flatten(x, 1, -1)).reshape(x.shape)
if self.k == 0:
return x
# x [batch_size, feature_num, seq_len]
sample_x = []
for i, k in enumerate(self.k_list):
sample_x.append(self.avg_pools[i](x))
sample_x.append(x)
n = len(sample_x)
for i in range(n - 1):
tmp = self.linears[i](sample_x[i])
sample_x[i + 1] = torch.add(sample_x[i + 1], tmp, alpha=1.0)
# [batch_size, feature_num, seq_len]
return sample_x[n - 1]
双重依赖交互(DDI)
-
核心功能:在时间维与通道维上交替混合与残差叠加,分块建模双重依赖
-
核心优势:显式捕捉时间步与变量间的动态交互,并以可调强度抑制无关噪声
-
核心代码(片段):
models/common.py:97与models/common.py:127
class DDI(nn.Module):
def __init__(self, input_shape, dropout=0.2, patch=12, alpha=0.0, layernorm=True):
super(DDI, self).__init__()
# input_shape[0] = seq_len input_shape[1] = feature_num
self.input_shape = input_shape
if alpha > 0.0:
self.ff_dim = 2 ** math.ceil(math.log2(self.input_shape[-1]))
self.fc_block = nn.Sequential(
nn.Linear(self.input_shape[-1], self.ff_dim),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(self.ff_dim, self.input_shape[-1]),
nn.GELU(),
nn.Dropout(dropout),
)
self.n_history = 1
self.alpha = alpha
self.patch = patch
self.layernorm = layernorm
if self.layernorm:
self.norm = nn.BatchNorm1d(self.input_shape[0] * self.input_shape[-1])
self.norm1 = nn.BatchNorm1d(self.n_history * patch * self.input_shape[-1])
if self.alpha > 0.0:
self.norm2 = nn.BatchNorm1d(self.patch * self.input_shape[-1])
self.agg = nn.Linear(self.n_history * self.patch, self.patch)
self.dropout_t = nn.Dropout(dropout)
def forward(self, x):
# [batch_size, feature_num, seq_len]
if self.layernorm:
x = self.norm(torch.flatten(x, 1, -1)).reshape(x.shape)
output = torch.zeros_like(x)
output[:, :, :self.n_history * self.patch] = x[:, :, :self.n_history * self.patch].clone()
for i in range(self.n_history * self.patch, self.input_shape[0], self.patch):
# input [batch_size, feature_num, self.n_history * patch]
input = output[:, :, i - self.n_history * self.patch: i]
# input [batch_size, feature_num, self.n_history * patch]
input = self.norm1(torch.flatten(input, 1, -1)).reshape(input.shape)
# aggregation
# [batch_size, feature_num, patch]
input = F.gelu(self.agg(input)) # self.n_history * patch -> patch
input = self.dropout_t(input)
# input [batch_size, feature_num, patch]
# input = torch.squeeze(input, dim=-1)
tmp = input + x[:, :, i: i + self.patch]
res = tmp
# [batch_size, feature_num, patch]
if self.alpha > 0.0:
tmp = self.norm2(torch.flatten(tmp, 1, -1)).reshape(tmp.shape)
tmp = torch.transpose(tmp, 1, 2)
# [batch_size, patch, feature_num]
tmp = self.fc_block(tmp)
tmp = torch.transpose(tmp, 1, 2)
output[:, :, i: i + self.patch] = res + self.alpha * tmp
# [batch_size, feature_num, seq_len]
return output
自适应多预测器合成(AMS)
-
核心功能:用门控选择器为并行预测器动态分配权重,并加权合成预测
-
核心优势:自适应聚焦主导时间模式,显著优于平均或单一预测器
-
核心代码(片段):
models/tsmoe.py:5、models/tsmoe.py:75与models/tsmoe.py:97
class TopKGating(nn.Module):
def __init__(self, input_dim, num_experts, top_k=2, noise_epsilon=1e-5):
super(TopKGating, self).__init__()
self.gate = nn.Linear(input_dim, num_experts)
self.top_k = top_k
self.noise_epsilon = noise_epsilon
self.num_experts = num_experts
self.w_noise = nn.Parameter(torch.zeros(num_experts, num_experts), requires_grad=True)
self.softplus = nn.Softplus()
self.softmax = nn.Softmax(1)
def decompostion_tp(self, x, alpha=10):
# x [batch_size, seq_len]
output = torch.zeros_like(x)
# [batch_size]
kth_largest_val, _ = torch.kthvalue(x, self.num_experts - self.top_k + 1)
# [batch_size, num_expert]
kth_largest_mat = kth_largest_val.unsqueeze(1).expand(-1, self.num_experts)
mask = x < kth_largest_mat
x = self.softmax(x)
output[mask] = alpha * torch.log(x[mask] + 1)
output[~mask] = alpha * (torch.exp(x[~mask]) - 1)
# Ablation Spare MoE
# output[mask] = 0
# [batch_size, seq_len]
return output
def forward(self, x):
# [batch_size, seq_len]
x = self.gate(x)
clean_logits = x
# [batch_size, num_experts]
if self.training:
raw_noise_stddev = x @ self.w_noise
noise_stddev = ((self.softplus(raw_noise_stddev) + self.noise_epsilon))
noisy_logits = clean_logits + (torch.randn_like(clean_logits) * noise_stddev)
logits = noisy_logits
else:
logits = clean_logits
logits = self.decompostion_tp(logits)
gates = self.softmax(logits)
return gates
class AMS(nn.Module):
def __init__(self, input_shape, pred_len, ff_dim=2048, dropout=0.2, loss_coef=1.0, num_experts=4, top_k=2):
super(AMS, self).__init__()
# input_shape[0] = seq_len input_shape[1] = feature_num
self.num_experts = num_experts
self.top_k = top_k
self.pred_len = pred_len
self.gating = TopKGating(input_shape[0], num_experts, top_k)
self.experts = nn.ModuleList(
[Expert(input_shape[0], pred_len, hidden_dim=ff_dim, dropout=dropout) for _ in range(num_experts)])
self.loss_coef = loss_coef
assert (self.top_k <= self.num_experts)
def cv_squared(self, x):
eps = 1e-10
# if only num_experts = 1
if x.shape[0] == 1:
return torch.tensor([0], device=x.device, dtype=x.dtype)
return x.float().var() / (x.float().mean() ** 2 + eps)
def forward(self, x, time_embedding):
# [batch_size, feature_num, seq_len]
batch_size = x.shape[0]
feature_num = x.shape[1]
# [feature_num, batch_size, seq_len]
x = torch.transpose(x, 0, 1)
time_embedding = torch.transpose(time_embedding, 0, 1)
output = torch.zeros(feature_num, batch_size, self.pred_len).to(x.device)
loss = 0
for i in range(feature_num):
input = x[i]
time_info = time_embedding[i]
# x[i] [batch_size, seq_len]
gates = self.gating(time_info)
# expert_outputs [batch_size, num_experts, pred_len]
expert_outputs = torch.zeros(self.num_experts, batch_size, self.pred_len).to(x.device)
for j in range(self.num_experts):
expert_outputs[j, :, :] = self.experts[j](input)
expert_outputs = torch.transpose(expert_outputs, 0, 1)
# gates [batch_size, num_experts, pred_len]
gates = gates.unsqueeze(-1).expand(-1, -1, self.pred_len)
# batch_output [batch_size, pred_len]
batch_output = (gates * expert_outputs).sum(1)
output[i, :, :] = batch_output
importance = gates.sum(0)
loss += self.loss_coef * self.cv_squared(importance)
# [feature_num, batch_size, seq_len]
output = torch.transpose(output, 0, 1)
# [batch_size, feature_num, seq_len]
return output, loss

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 28
28 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)