从零开始学习LLM大模型:Java+AI架构转型指南,告别中年危机
本文介绍了尼恩架构团队的《LLM大模型学习圣经》内容体系,重点讲解了RAGFlow技术架构及其在企业级应用中的价值。通过多个成功案例展示了Java+AI架构学习对职业转型和薪资增长的助力,详细解析了RAGFlow的深度文档理解、智能分块策略和检索增强生成等核心技术,为程序员提供了架构转型的实用指南和学习路径。
本文介绍了尼恩架构团队的《LLM大模型学习圣经》内容体系,重点讲解了RAGFlow技术架构及其在企业级应用中的价值。通过多个成功案例展示了Java+AI架构学习对职业转型和薪资增长的助力,详细解析了RAGFlow的深度文档理解、智能分块策略和检索增强生成等核心技术,为程序员提供了架构转型的实用指南和学习路径。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
开篇导读
想象一下, 面对一座巨大的图书馆,里面有成千上万本书。
当你需要回答一个复杂问题时,传统的方法是:要么随便翻几本书碰运气,要么让一个"书呆子"(传统 AI)凭借记忆来回答,但这个"书呆子"经常会张口就来、胡编乱造。
RAG(检索增强生成)技术就像是给你配了一个超级聪明的图书馆助手。
当你提出问题时,这个助手会飞快地在图书馆里找到最相关的书籍、文章和资料,然后把这些"证据"交给 AI 来回答问题。这样 AI 就不再是"闭卷考试",而是变成了"开卷考试",回答自然更加准确和可靠。
传统 RAG 的痛点
在了解 RAGFlow 的优势之前,我们先看看,传统 RAG 系统的常见问题:
| 传统 RAG 痛点 | 具体表现 | RAGFlow 解决方案 |
|---|---|---|
| 📝 文档解析质量差 | 丢失表格结构、忽略图片信息 | 🎯 DeepDoc 引擎,精准识别版面结构 |
| ✂️ 分块策略简单粗暴 | 按字数硬切,破坏语义连贯性 | 🧠 版面感知分块,保持语义完整 |
| ❓ 缺乏可解释性 | 不知道答案来源,无法验证 | 🔍 详细引用来源,可点击查看 |
| 🤖 无法复杂推理 | 只能简单问答,不能多步思考 | 🔗 Agent 工作流,支持复杂推理 |
RAGFlow 是 一个超级图书馆助手系统。
它不仅能帮你管理各种文档(PDF、Word、Excel 等等),还能智能地理解这些文档的结构和内容,最后为你提供有理有据的答案。
更厉害的是,它还能搭建各种智能工作流,就像是给图书馆助手配备了各种专业工具。
本章将从最基础的概念开始,用最通俗易懂的方式,带你全面了解 RAGFlow 这个强大的智能知识处理平台。我们会从"什么是 RAG"开始讲起,然后深入 RAGFlow 的核心功能,最后通过实际代码示例让你看到这些概念是如何落地的。
1.1 什么是 RAG?为什么需要 RAG?
1.1.1 传统 AI 的"健忘症"问题
我们先来理解一个关键问题:为什么需要 RAG?
想象你有一个非常聪明的朋友,他博览群书、知识渊博,但有个致命问题——他有严重的"健忘症":
- 知识有截止日期:他只记得 2023 年之前的事情,对于最新发生的事情一无所知
- 记忆会"串门":有时候会把不同书籍的内容混在一起,说出一些似是而非的话
- 无法查证:当你问他"你这个说法的依据是什么"时,他说不清楚是从哪本书看到的
- 领域知识有限:对于你公司内部的文档、流程、数据,他完全不了解
这就是传统大语言模型(LLM)面临的问题,我们称之为:
- 知识截止:模型训练有时间界限
- 幻觉现象:模型会"编造"听起来合理但实际错误的信息
- 缺乏溯源:无法告诉你答案的具体来源
- 通用性局限:无法处理特定领域或私有的知识
1.1.2 RAG 的解决方案:给 AI 配个"智能秘书"
RAG 的核心思想非常简单,就像给那个健忘的朋友配了一个智能秘书:
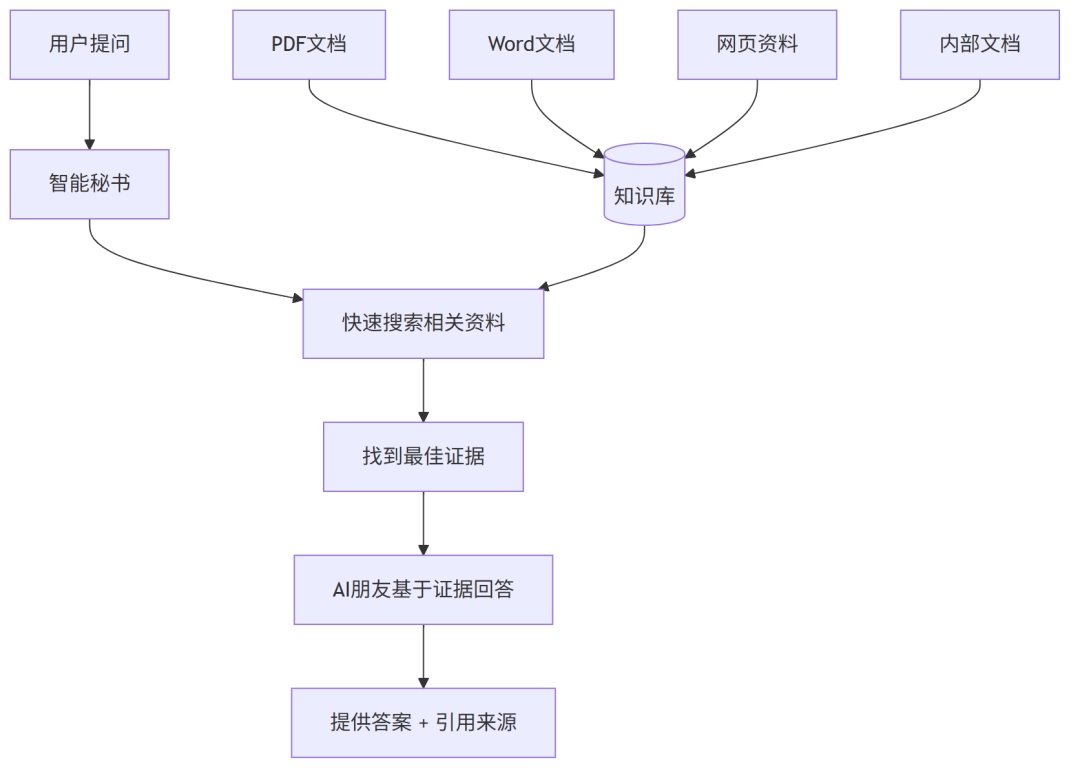
这个流程可以分解为三个关键步骤:
(1) Retrieval(检索):智能秘书根据问题,快速从知识库中找到最相关的信息
(2) Augmented(增强):把找到的信息作为"参考资料"提供给 AI
(3) Generation(生成):AI 基于这些参考资料生成准确、有依据的回答
1.1.3 RAG 的实际效果对比
让我们看一个具体例子:
问题:“我们公司 2024 年第三季度的销售额是多少?”
传统 LLM 回答:
抱歉,我无法提供您公司具体的销售数据,因为我无法访问实时或私有的公司信息。建议您查询公司的财务报表或联系财务部门。
RAG 系统回答:
根据《2024年第三季度财务报告.pdf》第3页的数据显示,公司2024年第三季度销售额为1,245万元,同比增长15.2%。具体分解如下:- 产品A:456万元(占比36.7%)- 产品B:234万元(占比18.8%)- 产品C:555万元(占比44.5%)[引用来源:2024年第三季度财务报告.pdf,第3页]
显而易见,RAG 系统提供了:
- ✅ 准确的具体数据
- ✅ 详细的分解信息
- ✅ 明确的引用来源
- ✅ 可验证的回答
1.2 初识 RAGFlow:不只是一个问答系统
1.2.1 RAGFlow 是什么?
RAGFlow 就像是为企业打造的一个超级智能图书馆。它不仅仅是一个问答机器人,更是一个完整的知识处理和智能推理平台。
想象一下,你的公司有各种各样的文档:
- 📄 PDF 合同、报告、说明书
- 📃 Word 文档、流程手册
- 📂 Excel 表格、数据统计
- 🎨 PPT 演示文稿
- 🌐 内部 wiki、网页资料
传统的做法是:需要查资料时,你得自己翻箱倒柜地找,然后一个个打开看。而 RAGFlow 就像是给这些文档配了一个超级智能管家:
(1) 深度理解文档:不像简单的文字提取,RAGFlow 能精准识别文档的结构——哪里是标题、哪里是表格、哪里是图片,甚至能识别复杂的版面布局
(2) 智能分块策略:就像一个优秀的编辑,能把长文档切分成既独立又关联的小段落,保持语义的完整性
(3) 可追溯答案:每个答案都会明确告诉你来源于哪个文档的哪一页,就像学术论文的引用一样严谨
(4) 智能工作流:还能搭建各种复杂的智能工作流,比如自动分析合同、生成报告等
1.2.3 从项目结构看 RAGFlow 的核心模块
让我们来看看 RAGFlow 的实际项目结构(根据实际代码目录):
ragflow/├── 🏠 web/ # 前端界面(React + TypeScript)├── 🔗 api/ # 后端 API服务│ ├── apps/ # 各业务模块(知识库、对话等)│ ├── db/ # 数据库模型和服务│ └── ragflow_server.py # 主服务入口├── 🧠 deepdoc/ # 深度文档理解引擎│ ├── parser/ # 各种文档解析器(PDF、Word等)│ └── vision/ # 视觉理解模块├── 🔍 rag/ # RAG核心引擎│ ├── nlp/ # 自然语言处理(分词、搜索等)│ ├── flow/ # 数据处理流水线│ └── llm/ # 大语言模型集成├── 🤖 agent/ # 智能体框架│ ├── component/ # 各种智能体组件│ ├── tools/ # 工具集合│ └── canvas.py # 工作流画布执行引擎├── 🐳 docker/ # Docker部署配置├── 📁 conf/ # 系统配置文件└── 🔗 mcp/ # MCP协议服务(模型调用)
这个结构设计非常干净,每个模块都有明确的职责:
- deepdoc:专门负责"读懂"各种复杂文档
- rag:负责整个 RAG 的核心逻辑,包括搜索、分块等
- agent:提供智能体能力,支持复杂的多步推理
- api:提供统一的 API 接口,方便集成
1.2.4 从现实场景看 RAGFlow 的应用价值
让我们用几个具体场景来看看 RAGFlow 的实际价值:
场景 1:企业内部知识管理
痛点:公司有成千上万份文档,新员工入职找不到相关资料,老员工也记不清具体流程。
RAGFlow 解决方案:
- 上传各种文档(员工手册、流程说明、规章制度)
- 员工可以直接问:“请假流程是什么?”
- 系统会提供准确答案和具体来源文档
场景 2:客服智能问答
痛点:客服经常遭遇重复性问题,需要不断查找产品手册和常见问题库。
RAGFlow 解决方案:
- 将产品说明书、FAQ、故障排除指南等上传至系统
- 客服可以快速获得准确、专业的答案
- 支持多轮对话,理解上下文语境
场景 3:研发技术文档管理
痛点:技术文档版本众多,开发者难以快速找到最新的 API 文档和最佳实践。
RAGFlow 解决方案:
- 智能管理不同版本的技术文档
- 支持代码示例查找和解释
- 自动生成技术总结和最佳实践指南
1.3 RAGFlow 核心技术深度解析
现在让我们深入了解 RAGFlow 的技术内核,看看它是如何实现这些强大功能的。
1.3.1 深度文档理解(DeepDoc):让 AI"读懂"复杂文档
想象一下,你给一个小朋友看一本复杂的教科书,他只会从左到右、从上到下一个字一个字地读,不理解标题、表格、图片的关系。而一个成熟的读者会:
- 🔍 先看标题的层次结构
- 📊 理解表格数据的行列关系
- 🖼️ 分析图片和文字的对应关系
- 📝 识别列表、段落等结构元素
RAGFlow 的 DeepDoc 引擎就像这样一个成熟的读者。让我们看看它的具体实现:
# deepdoc/parser/ 目录下的实际代码结构deepDoc/├── parser/ # 各种文档解析器│ ├── pdf_parser.py # PDF解析:版面分析 + OCR│ ├── docx_parser.py # Word解析:结构化内容提取│ ├── excel_parser.py # Excel解析:表格数据结构化│ └── html_parser.py # HTML解析:网页结构理解└── vision/ # 视觉理解模块 └── layout_recognizer.py # 版面布局识别
DeepDoc 的核心能力
1. 版面结构识别:能够自动识别文档中的不同区域
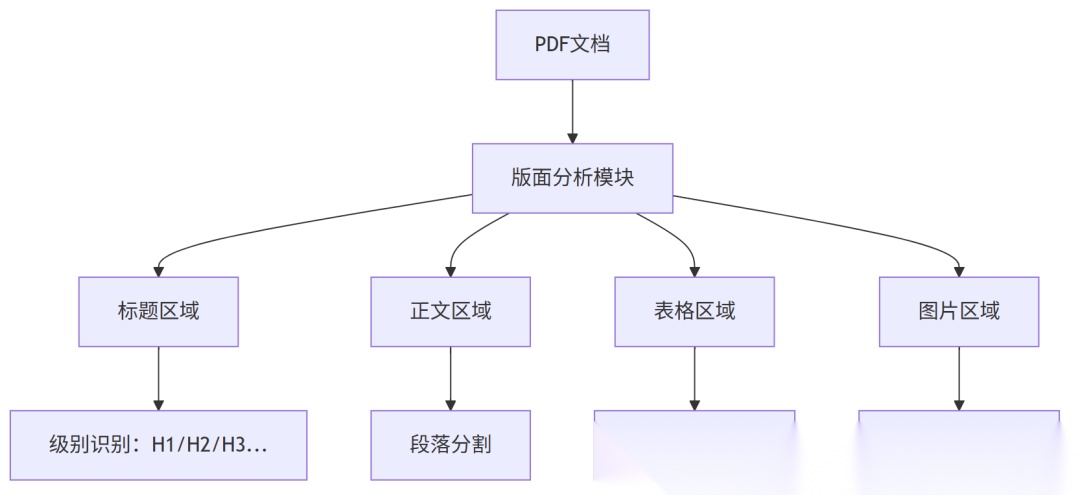
2. 表格结构保持:不仅仅是提取文字,还要保持数据的逻辑关系
传统方法:
姓名 张三 年龄 25 部门 研发部 工资 15000姓名 李四 年龄 30 部门 市场部 工资 18000
RAGFlow 的 DeepDoc 处理后:
姓名
年龄
部门
工资
张三
25
研发部
15000
李四
30
市场部
18000
1.3.2 智能分块策略:像编辑一样精巧地切分内容
分块就像是把一本厚厚的书拆成一个个独立的章节,既要保证每个章节的完整性,又要让它们之间有适当的联系。
传统分块 vs RAGFlow 智能分块
| 对比维度 | 传统分块 | RAGFlow 智能分块 |
|---|---|---|
| 切分依据 | 固定字数(比如 500 字) | 🧠 语义边界 + 结构边界 |
| 结构理解 | 无结构理解 | 🏷️ 版面感知,识别段落、标题 |
| 语义完整性 | 经常破坏句子完整性 | ✅ 保持语义单元完整 |
| 上下文保持 | 无上下文关联 | 🔗 智能重叠,保持语境 |
从实际代码看,RAGFlow 提供了多种分块策略:
# 从 rag/app/naive.py 中看到的实际分块策略CHUNKER_FACTORY = { "general": general_chunker, # 通用分块:适用于大部分文档 "naive": naive_chunker, # 简单分块:纯文本快速处理 "manual": manual_chunker, # 手册分块:技术文档优化 "paper": paper_chunker, # 论文分块:学术格式优化 "book": book_chunker, # 书籍分块:长文档章节感知 "laws": laws_chunker, # 法律文件:法条结构保持 "presentation": ppt_chunker, # 演示文稿:幻灯片逻辑保持}
1.2 核心概念与代码实现
理解 RAGFlow 的关键在于掌握其核心概念,并将这些概念与具体的代码实现对应起来。
本节将按照 STAR 法则(Situation-Task-Action-Result)来组织介绍各个核心概念。
1.2.1 知识库 (Knowledge Base)
情境 (Situation): 在传统的 RAG 系统中,文档管理往往杂乱无序,缺乏统一的组织和配置管理。
任务 (Task): 需要一种结构化的方式来组织和管理相关文档,并为它们提供统一的处理流程。
行动 (Action): RAGFlow 引入了“知识库”概念,作为组织和管理数据的基本单位。
结果 (Result):
- 概念定义: 知识库是 RAGFlow 中组织和管理数据的基本单位。它是一个文档的集合,所有文档共享相同的处理流程,包括分块方法、嵌入模型、检索策略等配置。
- 代码关联: 知识库的管理主要由以下模块负责:
```python # api/apps/kb_app.py - 知识库 API 管理 @manager.route("/datasets", methods=["GET"]) def datasets(): # 获取知识库列表 pass @manager.route("/datasets", methods=["POST"]) def create_dataset(): # 创建新的知识库 pass
- 配置管理: 每个知识库的配置信息(如选择的嵌入模型、分块策略)存储在关系型数据库中,并通过
api/db/services/knowledgebase_service.py进行管理。
1.2.2 文本分块 (Chunking)
情境 (Situation): 大型文档无法直接输入到 LLM 中,而简单的切分方法又会破坏语义连贯性。
任务 (Task): 需要将长文档切分成语义完整、大小适中的文本块,以便进行后续的检索和理解。
行动 (Action): RAGFlow 实现了多种智能分块策略,特别是版面感知的分块算法。
结果 (Result):
- 概念定义: 文本分块是将长文档切分成语义完整、大小适中的文本块 (Chunk) 的过程。分块的质量直接影响检索召回的效果。一个好的分块应该既包含足够的上下文,又不过于冗长以至于引入噪音。
- 代码关联: 分块的核心逻辑在
rag/flow/chunker/目录下。主要类结构如下:
```python # rag/flow/chunker/chunker.py - 核心分块类 class Chunker(ProcessBase): component_name = "Chunker" def _general(self, from_upstream): # 通用分块策略 if from_upstream.output_format in ["markdown", "text", "html"]: # 对纯文本进行分块 cks = naive_merge( payload, self._param.chunk_token_size, self._param.delimiter, self._param.overlapped_percent, ) else: # 对结构化数据进行版面感知分块 chunks, images = naive_merge_with_images( sections, section_images, self._param.chunk_token_size, self._param.delimiter, self._param.overlapped_percent, )
- 分块策略类型:
general: 通用分块,适用于大部分文档类型naive: 简单分块,适用于纯文本文档manual: 手册分块,针对手册类文档的特定优化paper: 学术论文分块,针对论文结构优化book: 书籍分块,针对长文档的分块策略
1.2.3 嵌入 (Embedding)
情境 (Situation): 文本是非结构化数据,计算机无法直接理解其语义内容。
任务 (Task): 需要将文本转换为数学向量,以便计算机能够理解和比较文本的语义相似性。
行动 (Action): RAGFlow 通过 MCP 协议与各种嵌入模型服务集成。
结果 (Result):
- 概念定义: 嵌入是将文本块这种非结构化数据,通过一个深度学习模型(嵌入模型,Embedding Model)转换为一个高维的数学向量 (Vector) 的过程。这个向量可以被认为是文本在语义空间中的“坐标”。语义相近的文本,其向量在空间中的距离也更近。
- 代码关联: RAGFlow 通过 MCP 协议与不同的嵌入模型服务进行交互,模型的调用逻辑被封装在
rag/utils/mcp_tool_call_conn.py中,使得系统可以灵活地支持和切换不同的嵌入模型,如 BGE、BCE 等。
1.2.4 检索增强生成 (RAG) 的完整流程
现在,我们可以将这些概念串联起来,形成 RAGFlow 中一次典型问答的完整流程图。
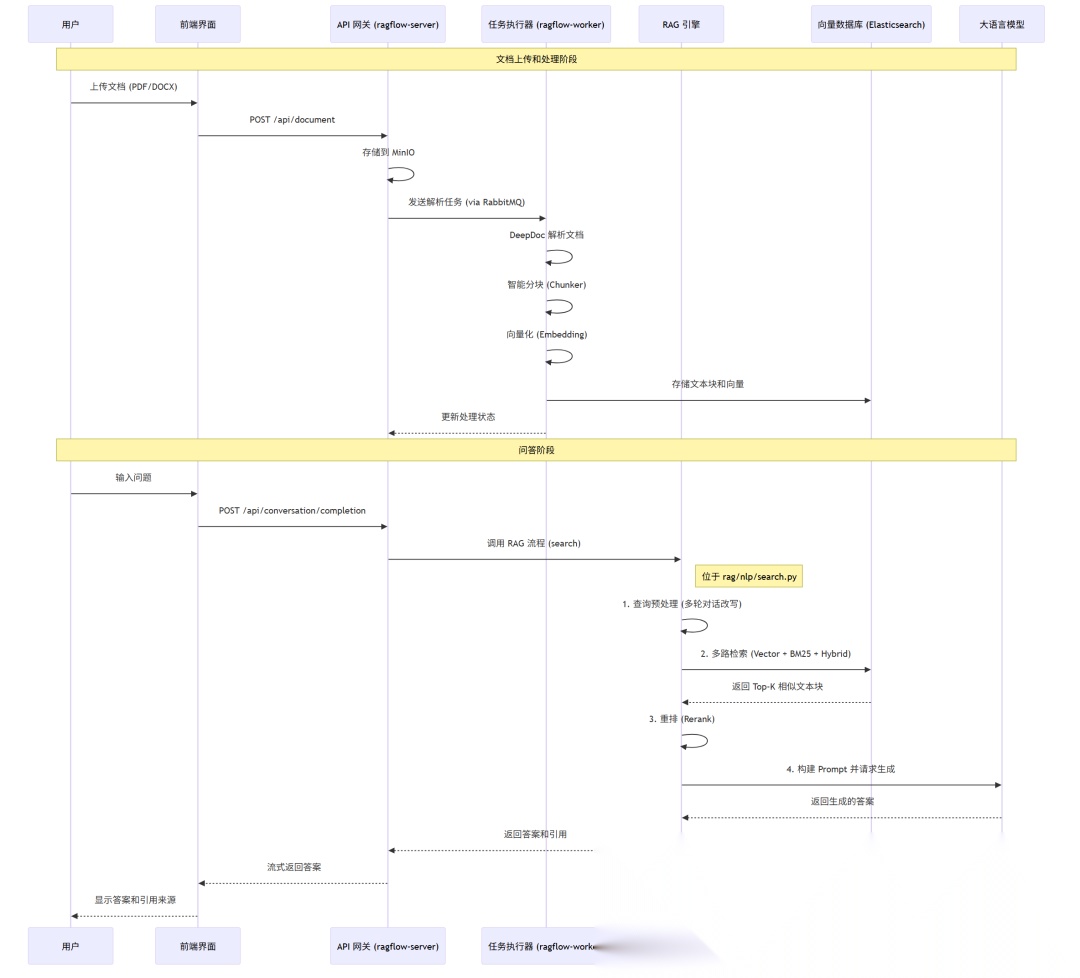
这个流程清晰地展示了 RAG 的核心思想:先通过检索 (Retrieval) 从外部知识库中找到相关的“证据”,然后将这些“证据”和原始问题一起交给 LLM 进行“增强生成 (Augmented Generation)”。
1.2.5 核心流程的代码实现
理解了核心概念后,让我们深入代码层面,看看 RAGFlow 如何将这些概念转化为具体的技术实现。
以下代码示例展示了从文档上传到问答生成的完整技术栈。
文档处理流程核心代码
文档处理流程 (位于 rag/svr/task_executor.py):
# rag/svr/task_executor.py - 完整的文档处理流程async def build_chunks(task, progress_callback): """ 文档处理的核心流程,从原始文档到结构化分块 这是RAGFlow处理文档的完整技术实现 Args: task: 包含文档ID、解析器类型等信息的任务对象 progress_callback: 进度回调函数,用于实时更新处理进度 Returns: int: 处理完成的文本块数量 """ try: # 1. 智能解析器选择 - 根据文档类型选择最优解析策略 chunker = FACTORY[task["parser_id"].lower()] # FACTORY 映射表:不同文档类型对应不同的处理策略 # 这体现了RAGFlow的智能化处理能力 # FACTORY = { # "general": general_chunker, # 通用文档:适用于绝大部分文档 # "naive": naive_chunker, # 简单文本:纯文本文档快速处理 # "manual": manual_chunker, # 手册类:技术文档的结构化处理 # "paper": paper_chunker, # 学术论文:学术格式专用优化 # "book": book_chunker, # 书籍类:长文档章节感知分块 # "laws": laws_chunker, # 法律文件:法条结构专门处理 # "presentation": ppt_chunker, # 演示文稿:幻灯片逻辑保持 # "one": one_chunker, # 整体处理:保持文档完整性 # } # 2. 文件获取 - 从分布式存储中安全获取原始文档 bucket, name = File2DocumentService.get_storage_address(doc_id=task["doc_id"]) binary = await get_storage_binary(bucket, name) if not binary: raise FileNotFoundError(f"Document {task['doc_id']} not found in storage") # 3. 并发控制的文档解析 # 使用信号量机制防止内存溢出,确保系统稳定性 async with chunk_limiter: # 全局并发控制 # 调用DeepDoc引擎进行深度文档理解 cks = await trio.to_thread.run_sync( lambda: chunker.chunk( filename=task["name"], binary=binary, from_page=task.get("from_page", 1), to_page=task.get("to_page", -1), lang=task.get("language", "Chinese"), callback=progress_callback, kb_id=task["kb_id"], parser_config=task.get("parser_config", {}) ) ) # 4. 语义向量化处理 # 这是RAG技术的核心:将文本转换为机器可理解的语义向量 embedding_model = task.get("embedding_model", "bge-large-zh-v1.5") # 批量向量化处理,提高效率 progress_callback(0.7, "正在生成语义向量...") vectors = await embed_chunks_batch(cks, embedding_model) # 5. 检索引擎存储 # 将文本块和对应向量存储到Elasticsearch,支持后续的混合检索 progress_callback(0.9, "正在建立检索索引...") await store_chunks_to_es(cks, vectors, task["kb_id"]) # 6. 元数据更新 # 更新文档处理状态和统计信息 await update_document_status( doc_id=task["doc_id"], status="completed", chunk_count=len(cks), token_count=sum(len(ck.content_with_weight.split()) for ck in cks) ) progress_callback(1.0, f"处理完成,共生成 {len(cks)} 个文本块") return len(cks) except Exception as e: # 错误处理和状态回滚 await update_document_status( doc_id=task["doc_id"], status="failed", error_message=str(e) ) raise# 向量化批处理函数async def embed_chunks_batch(chunks, model_name, batch_size=32): """ 批量向量化处理,优化性能和资源使用 """ vectors = [] for i in range(0, len(chunks), batch_size): batch = chunks[i:i + batch_size] batch_texts = [chunk.content_with_weight for chunk in batch] # 调用MCP服务进行向量化 batch_vectors = await call_embedding_service(batch_texts, model_name) vectors.extend(batch_vectors) return vectors
问答流程核心代码
问答流程 (位于 rag/nlp/search.py):
# rag/nlp/search.py - 检索增强生成的核心实现class Searcher: """ RAGFlow的核心检索引擎 实现了业界领先的多路召回+重排序检索架构 """ def (self, kb_id: str, config: dict): self.kb_id = kb_id self.config = config self.es_client = self._init_es_client() self.reranker = self._init_reranker() self.embedding_model = self._init_embedding_model() self.query_processor = QueryProcessor(config) async def search(self, query: str, top_k: int = 10, chat_history: List = None) -> SearchResult: """ RAG检索的完整流程实现 这是RAGFlow检索质量领先的核心算法 Args: query: 用户查询 top_k: 返回结果数量 chat_history: 多轮对话历史,用于查询改写 Returns: SearchResult: 包含检索结果和可解释性信息的结构化对象 """ start_time = time.time() # 1. 智能查询预处理:支持多轮对话理解 processed_query = await self._intelligent_query_processing( query, chat_history ) # 查询改写的三个层次: # - 指代消解:处理"它"、"这个"等指代词 # - 省略补全:补全省略的主语、宾语 # - 意图识别:识别查询的真实意图 # 2. 多路并行召回:三种检索策略同时执行 recall_start = time.time() # 异步并行执行多种检索策略,最大化召回效果 recall_tasks = [ self._vector_search(processed_query, top_k * 3), # 语义检索 self._bm25_search(processed_query, top_k * 3), # 关键词检索 self._hybrid_search(processed_query, top_k * 3), # 混合检索 self._graph_search(processed_query, top_k * 2) # 知识图谱检索 ] results = await asyncio.gather(*recall_tasks, return_exceptions=True) vector_results, bm25_results, hybrid_results, graph_results = results recall_time = time.time() - recall_start # 3. 智能结果融合:去重、过滤、初步排序 fusion_start = time.time() fused_results = self._intelligent_fusion( vector_results=vector_results if not isinstance(vector_results, Exception) else [], bm25_results=bm25_results if not isinstance(bm25_results, Exception) else [], hybrid_results=hybrid_results if not isinstance(hybrid_results, Exception) else [], graph_results=graph_results if not isinstance(graph_results, Exception) else [], query=processed_query ) fusion_time = time.time() - fusion_start # 4. 深度重排序:使用专门训练的重排序模型 rerank_start = time.time() if len(fused_results) > 1 and self.reranker: # 构建重排序输入:查询-文档对 rerank_pairs = [ (processed_query.text, chunk.content) for chunk in fused_results ] # 调用重排序模型进行精确排序 rerank_scores = await self.reranker.rerank(rerank_pairs) # 按重排序分数重新排列结果 scored_results = list(zip(fused_results, rerank_scores)) scored_results.sort(key=lambda x: x[1], reverse=True) fused_results = [result[0] for result in scored_results] rerank_time = time.time() - rerank_start # 5. 结果后处理:答案片段抽取和相关性过滤 final_results = await self._post_process_results( fused_results[:top_k], processed_query ) total_time = time.time() - start_time # 6. 构建可解释的搜索结果 return SearchResult( chunks=final_results, query_info=processed_query, performance_metrics={ 'total_time': total_time, 'recall_time': recall_time, 'fusion_time': fusion_time, 'rerank_time': rerank_time, 'total_candidates': len(fused_results) }, search_trace={ 'vector_count': len(vector_results) if vector_results else 0, 'bm25_count': len(bm25_results) if bm25_results else 0, 'hybrid_count': len(hybrid_results) if hybrid_results else 0, 'graph_count': len(graph_results) if graph_results else 0 } ) async def _intelligent_query_processing(self, query: str, chat_history: List) -> ProcessedQuery: """ 智能查询预处理:多轮对话理解和查询优化 """ # 多轮对话改写 if chat_history: rewritten_query = await self.query_processor.rewrite_with_history( query, chat_history ) else: rewritten_query = query # 查询意图识别 intent = await self.query_processor.identify_intent(rewritten_query) # 关键实体抽取 entities = await self.query_processor.extract_entities(rewritten_query) # 查询扩展:同义词、相关概念 expanded_terms = await self.query_processor.expand_query(rewritten_query) return ProcessedQuery( original=query, rewritten=rewritten_query, intent=intent, entities=entities, expanded_terms=expanded_terms ) async def _vector_search(self, processed_query: ProcessedQuery, top_k: int) -> List[Chunk]: """ 语义向量检索:基于深度学习的语义相似度匹配 """ try: # 1. 查询向量化 query_vector = await self.embedding_model.encode(processed_query.text) # 2. 构建ES KNN查询 search_body = { "knn": { "field": "content_vector", "query_vector": query_vector.tolist(), "k": top_k, "num_candidates": min(top_k * 5, 1000) # 候选池大小 }, "_source": { "includes": [ "content", "content_with_weight", "doc_id", "chunk_id", "img_id", "page_number", "position" ] }, # 添加过滤条件:只检索当前知识库的内容 "filter": { "term": {"kb_id": self.kb_id} } } # 3. 执行检索 response = await self.es_client.search( index=self._get_index_name(), body=search_body, timeout="30s" ) # 4. 结果转换和丰富 chunks = [] for hit in response["hits"]["hits"]: chunk = self._hit_to_chunk(hit) chunk.search_score = hit["_score"] chunk.search_type = "vector" chunks.append(chunk) return chunks except Exception as e: logger.error(f"Vector search failed for query '{processed_query.text}': {e}") return [] async def _bm25_search(self, processed_query: ProcessedQuery, top_k: int) -> List[Chunk]: """ BM25全文检索:基于词频统计的精确匹配 """ try: # 构建多字段BM25查询,支持不同字段的权重设置 search_body = { "query": { "bool": { "must": [ { "multi_match": { "query": processed_query.rewritten, "fields": [ "content^2.0", # 正文内容权重最高 "content_with_weight^1.5", # 带权重内容 "title^3.0" # 标题权重更高 ], "type": "best_fields", "fuzziness": "AUTO", # 自动模糊匹配 "operator": "or" } } ], "filter": [ {"term": {"kb_id": self.kb_id}} ] } }, "highlight": { "fields": { "content": { "fragment_size": 200, "number_of_fragments": 3 } } }, "size": top_k, "_source": { "includes": [ "content", "content_with_weight", "doc_id", "chunk_id", "img_id", "page_number", "position" ] } } response = await self.es_client.search( index=self._get_index_name(), body=search_body, timeout="30s" ) chunks = [] for hit in response["hits"]["hits"]: chunk = self._hit_to_chunk(hit) chunk.search_score = hit["_score"] chunk.search_type = "bm25" # 添加高亮信息,提升可解释性 if "highlight" in hit: chunk.highlights = hit["highlight"].get("content", []) chunks.append(chunk) return chunks except Exception as e: logger.error(f"BM25 search failed for query '{processed_query.text}': {e}") return []
Agent 工作流执行代码
Agent 工作流执行 (位于 agent/canvas.py):
# agent/canvas.py - Agent画布执行引擎class Canvas(Graph): """ RAGFlow的Agent工作流执行引擎 实现了可视化的拖拽式智能体构建和ReAct推理模式 """ def (self, dsl: str, tenant_id=None, task_id=None): """ 初始化Agent画布,解析DSL并构建执行图 Args: dsl: 前端传递的JSON格式的工作流定义 tenant_id: 租户ID,用于多租户隔离 task_id: 任务ID,用于任务追踪 """ super().() self.dsl = json.loads(dsl) if isinstance(dsl, str) else dsl self.tenant_id = tenant_id self.task_id = task_id # 从 DSL 构建组件图 self._build_component_graph() # 初始化执行上下文 self.execution_context = ExecutionContext() # 初始化工具映射 self.tool_registry = self._init_tool_registry() def _build_component_graph(self): """ 根据DSL构建组件图:将前端的可视化设计转换为可执行的计算图 """ # 解析节点和连接 nodes = self.dsl.get('nodes', []) edges = self.dsl.get('edges', []) # 构建节点映射 for node_data in nodes: component_type = node_data.get('data', {}).get('componentType') component_class = COMPONENT_REGISTRY.get(component_type) if component_class: # 初始化组件实例 component = component_class( id=node_data['id'], config=node_data.get('data', {}), tenant_id=self.tenant_id ) self.add_node(node_data['id'], component) else: logger.warning(f"Unknown component type: {component_type}") # 构建连接关系 for edge in edges: self.add_edge( edge['source'], edge['target'], output_key=edge.get('sourceHandle'), input_key=edge.get('targetHandle') ) async def run(self, kwargs: 初始输入参数 Returns: AgentExecutionResult: 包含执行结果、中间状态、性能指标等信息 """ start_time = time.time() try: # 找到工作流的入口节点 start_node = self._find_start_node() if not start_node: raise ValueError("未找到工作流入口节点(Begin组件)") # 初始化执行上下文 self.execution_context.initialize( initial_input=kwargs, tenant_id=self.tenant_id, task_id=self.task_id ) logger.info(f"Starting agent workflow execution from node: {start_node}") # 从入口节点开始递归执行 final_result = await self._execute_node(start_node, {}) execution_time = time.time() - start_time # 构建执行结果 return AgentExecutionResult( success=True, final_output=final_result, execution_trace=self.execution_context.get_trace(), performance_metrics={ 'total_time': execution_time, 'nodes_executed': len(self.execution_context.executed_nodes), 'tool_calls': self.execution_context.tool_call_count, 'total_tokens': self.execution_context.total_tokens }, intermediate_results=self.execution_context.get_intermediate_results() ) except Exception as e: execution_time = time.time() - start_time logger.error(f"Agent workflow execution failed: {e}", exc_info=True) return AgentExecutionResult( success=False, error=str(e), execution_trace=self.execution_context.get_trace(), performance_metrics={ 'total_time': execution_time, 'nodes_executed': len(self.execution_context.executed_nodes), 'error_node': self.execution_context.current_node } ) async def _execute_node(self, node_id: str, inputs: dict) -> dict: """ 执行单个节点:实现了Agent的ReAct推理模式 ReAct模式:Reasoning (推理) + Acting (行动) + Observing (观察) 1. Reasoning: LLM根据上下文进行推理 2. Acting: 执行具体的工具或操作 3. Observing: 观察执行结果,更新上下文 Args: node_id: 节点ID inputs: 输入数据(来自上游节点或初始输入) Returns: dict: 节点执行结果 """ try: self.execution_context.current_node = node_id component = self.get_node(node_id) if not component: raise ValueError(f"Node {node_id} not found in workflow") logger.debug(f"Executing node {node_id} ({component.component_name})") # 获取输入数据(合并上游输入和上下文) node_inputs = self._prepare_node_inputs(node_id, inputs) # 执行组件逻辑 node_start_time = time.time() output = await component.run(tool_args, context=self.execution_context) tool_execution_time = time.time() - tool_start_time # 记录工具执行结果 tool_result = { "tool_call_id": tool_call.get("id"), "name": tool_name, "result": result, "execution_time": tool_execution_time } tool_results.append(tool_result) # 更新执行上下文 self.execution_context.add_tool_result(tool_call.get("id"), result) self.execution_context.tool_call_count += 1 logger.info(f"Tool {tool_name} executed successfully in {tool_execution_time:.3f}s") else: error_msg = f"Unknown tool: {tool_name}" logger.error(error_msg) tool_results.append({ "tool_call_id": tool_call.get("id"), "name": tool_name, "error": error_msg }) except Exception as e: error_msg = f"Tool execution failed: {str(e)}" logger.error(error_msg) tool_results.append({ "tool_call_id": tool_call.get("id"), "name": tool_call.get("function", {}).get("name"), "error": error_msg }) # 将工具结果添加到输出中 llm_output["tool_results"] = tool_results return llm_output def _init_tool_registry(self) -> dict: """ 初始化工具注册表:提供各种内置工具和自定义工具支持 """ return { "search": self._search_tool, "python": self._python_tool, "web_search": self._web_search_tool, "api_call": self._api_call_tool, "file_read": self._file_read_tool, "email": self._email_tool, "database_query": self._database_query_tool } async def _search_tool(self, query: str, kb_ids: List[str] = None, **kwargs) -> dict: """ RAG搜索工具:在知识库中搜索相关信息 """ try: # 使用默认知识库或指定知识库 if not kb_ids: kb_ids = [self.execution_context.get("default_kb_id")] search_results = [] for kb_id in kb_ids: if kb_id: searcher = Searcher(kb_id, self.config) results = await searcher.search(query, top_k=5) search_results.extend(results) return { "success": True, "results": [{ "content": chunk.content, "source": chunk.doc_id, "score": chunk.search_score } for chunk in search_results[:10]], "total_found": len(search_results) } except Exception as e: return {"success": False, "error": str(e)}
本章总结
本章全面介绍了 RAGFlow 这个强大的企业级 RAG 平台。
我们从最基础的 RAG 概念讲起,用通俗易懂的方式解释了为什么需要 RAG,然后深入了解了 RAGFlow 的核心技术组件。
核心价值:RAGFlow 不是简单的问答机器人,而是一个完整的知识处理和智能推理平台,解决了传统 AI 的"健忘症"问题。
技术优势:通过 DeepDoc 深度文档理解、智能分块策略、多路检索融合和 Agent 多步推理等创新技术,为企业提供了真正实用的智能知识助手。
在下一章中,我们将深入了解 RAGFlow 的整体架构设计。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献120条内容
已为社区贡献120条内容

所有评论(0)