自动驾驶生成式革命!AAAI2026 Oral 顶会成果:新国立 & 自动化所 LiDARCrafter,文本秒变 4D LiDAR 序列,高危场景生成让仿真更真实!
本文提出LiDARCrafter这一统一框架,专为可控4D LiDAR序列生成与编辑设计。其通过场景图解析文本指令,结合多分支扩散模型生成目标布局、静态帧,并以自回归策略保证序列时间连贯性,同时构建覆盖场景-目标-序列级的评估基准。在nuScenes数据集上的实验表明,该框架在保真度、连贯性与可控性上全面超越现有方法,不仅能生成高质量LiDAR数据,还可合成安全关键场景,为自动驾驶下游系统评估提供
大家好,今天给大家讲讲 AAAI2026 Oral中,新加坡国立大学、中科院等团队联合提出的LiDARCrafter,首创“文本→布局→场景→序列”三阶段框架:用LLM解析文本生成场景图,三分支扩散网络生成精准布局,自回归模块保障时序连贯,还构建了首个覆盖场景-目标-序列级的评估基准。
在nuScenes数据集上,其保真度、可控性与时间一致性全面领先,还能合成车辆切入、盲区行人等高危场景。
1. 【导读】

论文标题:LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences
作者:Ao Liang, Youquan Liu, Yu Yang, Dongyue Lu, Linfeng Li, Lingdong Kong, Huaici Zhao, Wei Tsang Ooi
作者机构:1. National University of Singapore;2. University of Chinese Academy of Sciences;3. Shenyang Institute of Automation, Chinese
Academy of Sciences;4. Fudan University;5. Zhejiang University
论文来源:AAAI2026 Oral
论文链接:https://arxiv.org/abs/2508.03692
项目链接:Project Page - https://lidarcrafter.github.io;GitHub - https://github.com/worldbench/lidarcrafter
2. 【论文速读】
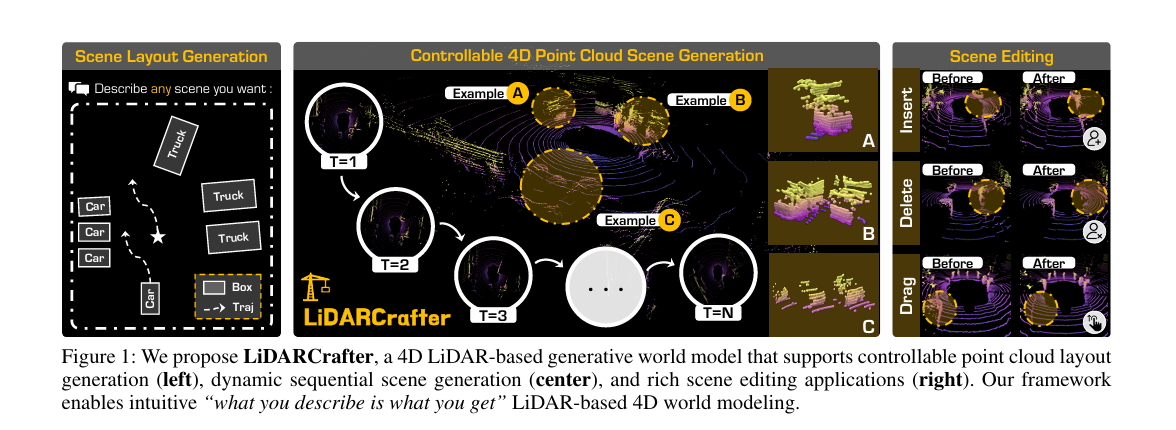
生成式世界模型已成为自动驾驶领域关键的数据引擎,但现有研究多聚焦于视频或占据栅格,却忽视了激光雷达(LiDAR)的独特属性。将LiDAR生成拓展至动态4D世界建模,需应对可控性、时间连贯性与评估标准化三大挑战。为此,研究提出统一框架LiDARCrafter,可实现4D LiDAR生成与编辑:其先将自然语言指令解析为以自车为中心的场景图,再通过三分支扩散网络生成目标结构、运动轨迹与几何形状,支持多样化细粒度场景编辑;同时,自回归模块能生成时间连贯的4D LiDAR序列,确保过渡平滑。此外,研究构建了涵盖场景级、目标级与序列级的综合基准以实现标准化评估。在nuScenes数据集上的实验表明,LiDARCrafter在各层级的保真度、可控性与时间一致性上均达到当前最优水平,为数据增强与仿真奠定基础,并已向社区开放代码与基准。
3. 自动驾驶生成式建模的“LiDAR困境”与研究脉络
3.1 领域趋势:生成式世界模型成自动驾驶关键,但LiDAR技术被“冷落”
生成式世界模型正快速推动自动驾驶大规模传感器数据的合成与解读,现有研究多聚焦于视频、占据栅格等结构化模态(如GAIA-1、OccWorld等),这类模态的密集规则结构适配图像与体素处理流程。然而,对自动驾驶中 metric 3D几何感知与全天候感知至关重要的LiDAR,却因点云稀疏、无序、不规则的特性被研究忽视,适用于图像或栅格的技术无法直接迁移,且缺乏专用的4D LiDAR世界模型。
3.2 现有局限:三大核心挑战阻碍LiDAR 4D建模发展
- 用户可控性不足:文本指令虽易获取,但缺乏LiDAR场景所需的空间细节;而3D框、高精地图等精准输入需高昂标注成本,难以平衡易用性与精准度。
- 时间一致性缺失:现有方法多提升单帧LiDAR生成保真度(如LiDARGen、R2DM),却无法生成动态序列,无法满足下游对遮挡模式、目标运动学的需求,且传统跨帧注意力策略忽视点云几何连续性。
- 评估标准空白:视频生成模型已有成熟基准(如VBench),可评估视觉质量、感知精度等,但LiDAR领域仍缺乏评估多视角保真度与一致性的标准协议。
3.3 相关研究短板:LiDAR生成与可控性技术存在明显缺口
- LiDAR点云生成局限:早期方法(如LiDARGen)将LiDAR投影为距离图像借用像素方法,后续方法(如RangeLDM、R2DM)虽提升单帧精度,但未解决动态序列生成与细粒度可控性问题;多模态模型(如UniScene、GENESIS)依赖占据栅格或视频作为中介,限制LiDAR独立性且增加计算量。
- 场景合成可控性不足:现有可控方法依赖BEV语义图、高精地图等 labor-intensive 输入,文本驱动方法(如Text2LiDAR)虽简便却缺乏空间精度,且成熟的动态4D LiDAR场景可控生成与编辑技术尚未建立。
4. LiDARCrafter:三步打造“可控+连贯”的4D LiDAR世界
4.1 核心框架:三阶段流程实现从文本到4D序列的转化
LiDARCrafter是首个将自由文本指令转化为具有目标级控制的时间连贯4D点云序列的LiDAR世界模型,核心是通过“显式4D前景布局”连接语言描述与LiDAR几何严谨性,整体采用三阶段流程:
- Text2Layout阶段:利用大语言模型(LLM)将文本指令解析为以自车为中心的场景图,再通过三分支扩散采样器生成目标框、轨迹与形状先验,形成条件布局信号;
- Layout2Scene阶段:基于距离图像扩散模型,将布局转化为高保真静态LiDAR扫描帧;
- Scene2Seq阶段:通过自回归模块对静态点云进行变换与补绘,生成无漂移的后续帧,同时结合EvalSuite评估目标语义、布局合理性与运动保真度,形成4D LiDAR生成的完整基准。
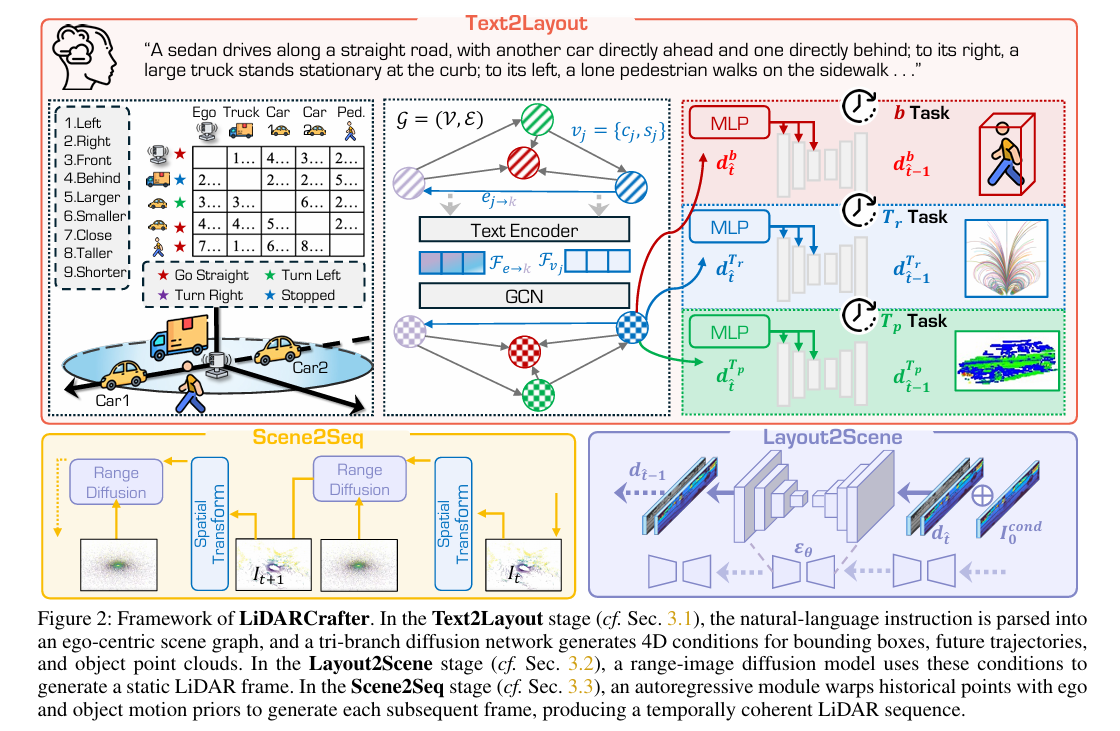
4.2 Text2Layout:从语言到4D布局的精准“翻译”
该阶段解决自然语言缺乏空间精度的问题,通过场景图作为中间载体,将文本转化为指导LiDAR生成的详细4D布局,分为三步:
4.2.1 语言驱动的场景图构建
输入文本指令后,通过LLM构建以自车为中心的场景图G=(V,E)G=(V, E)G=(V,E):
- 节点集VVV:包含自车节点v0v_0v0与MMM个动态目标节点,每个节点viv_ivi标注语义类别cic_ici(如“轿车”)与运动状态sis_isi(如“直线行驶”);
- 边集EEE:对任意有序节点对(i,j)(i,j)(i,j)(i≠ji≠ji=j),有向边ei→je_{i→j}ei→j编码空间关系(如“前方”“大于”),纳入自车节点确保场景图结构完整,为下游布局生成提供充分条件。
4.2.2 场景图升维:生成4D布局元组
针对每个节点viv_ivi,推断4D布局元组Oi=(bi,δi,pi)O_i=(b_i, \delta_i, p_i)Oi=(bi,δi,pi),捕捉目标的“位置-运动-形状”信息:
- bi=(xi,yi,zi,wi,li,hi,ψi)b_i=(x_i, y_i, z_i, w_i, l_i, h_i, \psi_i)bi=(xi,yi,zi,wi,li,hi,ψi):3D边界框,包含中心坐标、尺寸与偏航角;
- δi={(Δxit,Δyit)}t=1T\delta_i=\{(\Delta x_i^t, \Delta y_i^t)\}_{t=1}^Tδi={(Δxit,Δyit)}t=1T:未来TTT帧的平面位移序列;
- pi∈RN×3p_i \in \mathbb{R}^{N×3}pi∈RN×3:NNN个规范前景点,勾勒目标形状。
4.2.3 图融合编码器与布局扩散解码器
- 图融合编码器:采用LLL层TripletGCN处理场景图GGG,先通过冻结的CLIP文本编码器嵌入节点与边特征:
- 节点初始特征:hvi(0)=concat(CLIP(ci),CLIP(si),ωi)h_{v_i}^{(0)}=concat(CLIP(c_i), CLIP(s_i), \omega_i)hvi(0)=concat(CLIP(ci),CLIP(si),ωi)(ωi\omega_iωi为可学习位置编码);
- 边初始特征:hei→j(0)=CLIP(ei→j)h_{e_{i→j}}^{(0)}=CLIP(e_{i→j})hei→j(0)=CLIP(ei→j);
- 每层通过两个轻量级MLP更新:Φedge\Phi_{edge}Φedge用于边推理,Φagg\Phi_{agg}Φagg用于邻域聚合,最终节点特征hvi(L)h_{v_i}^{(L)}hvi(L)融合全局语义与局部几何,为布局生成提供先验。
- 布局扩散解码器:基于三分支扩散解码器(共享噪声调度),对OiO_iOi的三个元素分别优化,每个分支最小化损失:
Lo=Eτ,do,ε∥ε−εθo(dτo,τ,co)∥22{\mathcal{L}}^o=\mathbb{E}_{\tau, d^o, \varepsilon}\left\| \varepsilon-\varepsilon_{\theta}^o\left(d_{\tau}^o, \tau, c^o\right)\right\| _{2}^{2}Lo=Eτ,do,ε∥ε−εθo(dτo,τ,co)∥22
其中,边界框与轨迹通过1D U-Net去噪,目标形状通过基于点的U-Net合成,仅匹配LiDAR采样分布以降低计算成本。
4.3 Layout2Scene:基于布局的可控LiDAR生成
以场景图GGG与解码布局OiO_iOi为条件,通过统一的距离图像扩散骨干网络,端到端生成LiDAR点云,核心包含两大设计:
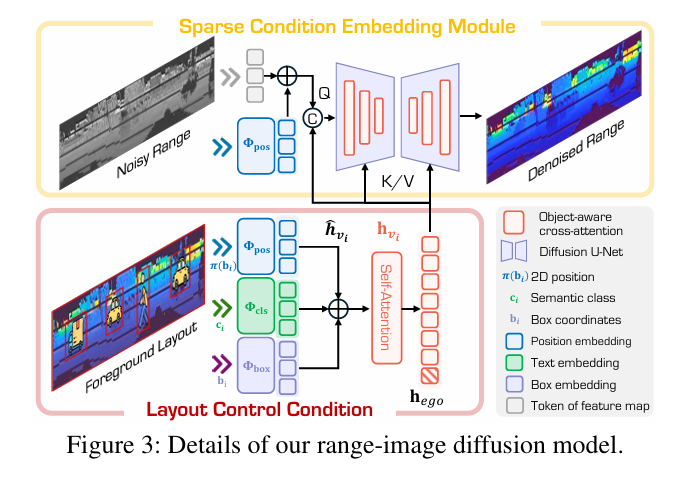
4.3.1 稀疏目标条件机制
针对小/远距离目标在距离图像中像素占比低的问题,通过稀疏目标表示编码语义、姿态与粗粒度形状,辅助模型生成细结构:
- 对每个节点,聚合特征生成条件向量:
h^vi=Φpos(π(bi))+Φcls(ci)+Φbox(bi)\hat{h}_{v_i}=\Phi_{pos}(\pi(b_i))+\Phi_{cls}(c_i)+\Phi_{box}(b_i)h^vi=Φpos(π(bi))+Φcls(ci)+Φbox(bi)
其中π(bi)\pi(b_i)π(bi)为3D框投影到图像坐标,Φpos\Phi_{pos}Φpos为位置嵌入器,Φcls\Phi_{cls}Φcls、Φbox\Phi_{box}Φbox为学习型MLP; - 经轻量级自注意力层优化特征,自车节点特征进一步压缩为场景级向量hegoh_{ego}hego;
- 扩散过程中,将噪声距离图dτd_{\tau}dτ与稀疏条件图IcondI_{cond}Icond(布局点pip_ipi投影到图像平面)拼接输入,全局条件由场景级向量、时间嵌入与自车状态CLIP嵌入构成:
hcond=hego+Φtime(τ)+CLIP(s0)h_{cond}=h_{ego}+\Phi_{time}(\tau)+CLIP(s_0)hcond=hego+Φtime(τ)+CLIP(s0)
最终通过Transformer-based U-Net预测清晰的距离图像I0I^0I0,启动LiDAR序列P={Pt}t=0TP=\{P^t\}_{t=0}^TP={Pt}t=0T。
4.3.2 布局驱动的场景编辑
基于显式布局实现目标编辑(插入/删除/拖动)且不干扰静态背景,流程为:
- 生成原始场景d0origd_0^{orig}d0orig后,用户修改布局元组;
- 重运行反向扩散,通过二进制掩码mmm标记受编辑影响的像素,按公式融合原始场景与新去噪样本:
dτ−1=(1−m)⊙d~τ−1+m⊙d^τ−1d_{\tau-1}=(1-m) \odot \tilde{d}_{\tau-1}+m \odot \hat{d}_{\tau-1}dτ−1=(1−m)⊙d~τ−1+m⊙d^τ−1
其中d^τ−1\hat{d}_{\tau-1}d^τ−1为新去噪样本,d~τ−1∼N(αˉd0orig,(1−αˉ)I)\tilde{d}_{\tau-1} \sim N(\sqrt{\bar{\alpha}} d_0^{orig}, (1-\bar{\alpha})\mathbb{I})d~τ−1∼N(αˉd0orig,(1−αˉ)I)为原始场景的高斯扰动副本,确保编辑区域无伪影。
4.4 Scene2Seq:自回归生成时间连贯的4D序列
利用LiDAR场景“静态环境为主、仅自车与目标运动”的特性,通过变换历史点云提供强先验,实现时间连贯的序列生成:
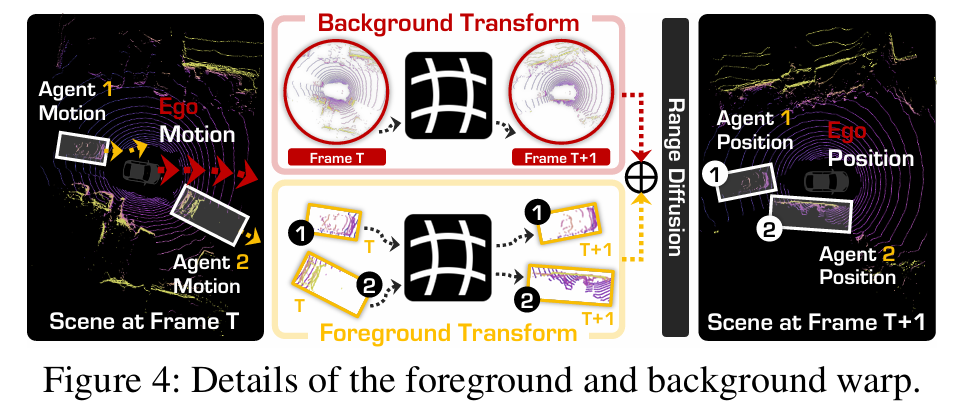
4.4.1 静态场景与动态目标的变换策略
- 静态场景变换:以第0帧为世界原点,自车在ttt帧的平移u0t=[Δx0t,Δy0t,z0]⊤u_0^t=[\Delta x_0^t, \Delta y_0^t, z_0]^⊤u0t=[Δx0t,Δy0t,z0]⊤(z0z_0z0为传感器固定高度),增量偏航角:
ψ0t=atan2(Δy0t−Δy0t−1,Δx0t−Δx0t−1)\psi_0^t=atan2\left(\Delta y_0^t-\Delta y_0^{t-1}, \Delta x_0^t-\Delta x_0^{t-1}\right)ψ0t=atan2(Δy0t−Δy0t−1,Δx0t−Δx0t−1)
构建齐次自车姿态矩阵G0t∈SE(3)G_0^t \in SE(3)G0t∈SE(3),计算相对运动ΔG0t=G0t(G0t−1)−1\Delta G_0^t=G_0^t (G_0^{t-1})^{-1}ΔG0t=G0t(G0t−1)−1,通过B~t=ΔG0tBt−1\tilde{B}^t=\Delta G_0^t B^{t-1}B~t=ΔG0tBt−1更新背景点BBB。 - 动态目标变换:目标iii的框中心按累积位移(Δxit,Δyit)(\Delta x_i^t, \Delta y_i^t)(Δxit,Δyit)更新为世界坐标uit=[xi+Δxit,yi+Δyit,zi]⊤u_i^t=[x_i+\Delta x_i^t, y_i+\Delta y_i^t, z_i]^⊤uit=[xi+Δxit,yi+Δyit,zi]⊤,偏航角计算同自车;通过逆自车变换(平移−u0t-u_0^t−u0t+旋转−ψ0t-\psi_0^t−ψ0t)将目标前景点Fi0F_i^0Fi0映射为FitF_i^tFit,提供几何先验。
4.4.2 自回归生成流程
对t>0t>0t>0的每帧,构建条件距离图:
Icondt=Π(B0→t∪Bt−1→t∪{Fit−1→t}i=1M)I_{cond}^t=\Pi\left(B^{0→t} \cup B^{t-1→t} \cup \{F_i^{t-1→t}\}_{i=1}^M\right)Icondt=Π(B0→t∪Bt−1→t∪{Fit−1→t}i=1M)
其中Π(⋅)\Pi(\cdot)Π(⋅)为球面投影,纳入第0帧背景变换B0→tB^{0→t}B0→t以消除累积漂移;将IcondtI_{cond}^tIcondt与噪声样本拼接输入扩散骨干网络,迭代生成完整序列。
4.5 EvalSuite:4D LiDAR生成的“全面体检”基准
针对现有LiDAR生成指标(如FRD)仅评估静态真实性的缺陷,构建涵盖三大维度的评估套件:
- 目标级指标:FDC(前景检测置信度)、CDA(条件检测精度)、CFCA(条件前景分类精度)、CFSC(条件前景空间一致性),验证目标标签、框几何与检测器置信度;
- 布局级指标:SCR(空间一致性率)、MSCR(运动状态一致性率)、BCR(框碰撞率)、TCR(轨迹碰撞率),衡量空间/轨迹一致性并惩罚碰撞;
- 序列级指标:TTCE(时间变换一致性误差)、CTC( Chamfer时间一致性),跟踪帧间变换精度与序列平滑度,实现4D感知的完整评估。
5. 实测见真章:LiDARCrafter在nuScenes上的“全维领先”
5.1 实验基础:数据集与设置
- 数据集:采用nuScenes数据集(32线LiDAR扫描、3D框、实例ID、高精地图),提供丰富条件信息;
- 评估指标:结合经典静态指标(FRD、FPD、JSD、MMD)与自研的目标级、布局级、运动级指标;
- 训练配置:6台NVIDIA A40 GPU,三分支布局扩散器训练100万步(批大小64),距离图像模型(32×1024)训练50万步(批大小32),所有扩散器训练用1024去噪步、采样用256去噪步。
5.2 场景级生成:整体保真度“一骑绝尘”
聚焦全场景生成质量与前景目标精度,结果如下:
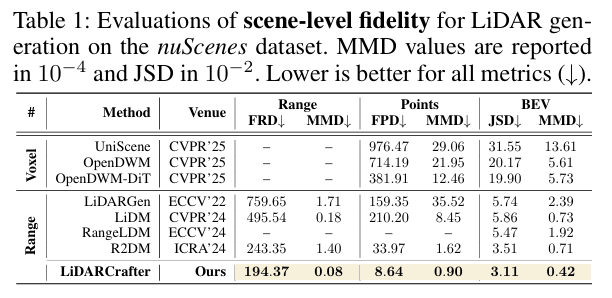
5.2.1 全场景保真度:刷新最优水平
对比主流LiDAR生成基线,LiDARCrafter在关键指标上显著领先:
- 最低FRD(194.37):较R2DM提升20%,意味着2D距离结构重建更准;
- 最低FPD(8.64):3D点分布更贴近真实;
- 可视化显示:生成扫描帧与真值高度相似,前景结构完整,而其他方法(如LiDARGen、UniScene)存在背景噪声或模糊问题。
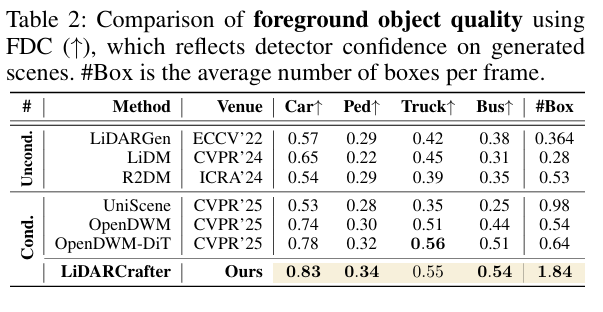
5.2.2 前景目标精度:检测器“更认账”
用预训练VoxelRCNN检测器评估:
- FDC(前景检测置信度):在轿车(0.83)、行人(0.34)、卡车(0.55)等类别上均获最高分,目标真实性更强;
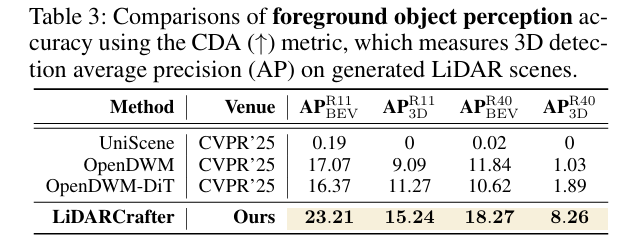
- CDA(条件检测精度):AP R11 BEV达23.21、AP R11 3D达15.24,远超OpenDWM(分别为17.07、9.09),生成结构与条件对齐度更高。
5.3 目标级生成:单目标几何与语义“双精准”
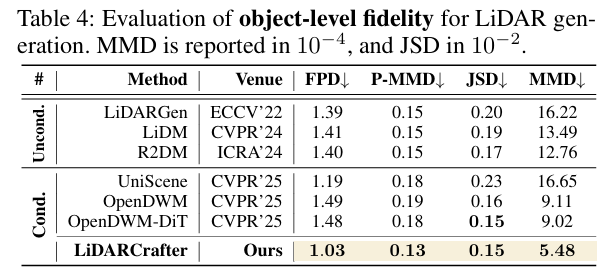
针对单个目标生成质量,从保真度与一致性两方面验证:
5.3.1 目标保真度:细粒度几何更优
提取2000个“轿车”目标评估,LiDARCrafter:
- 最低FPD(1.03)、最低MMD(5.48×10⁻⁴),显著优于OpenDWM(FPD 1.49、MMD 9.11×10⁻⁴),细粒度几何重建更精准。
5.3.2 语义与几何一致性:贴合真实类别与约束
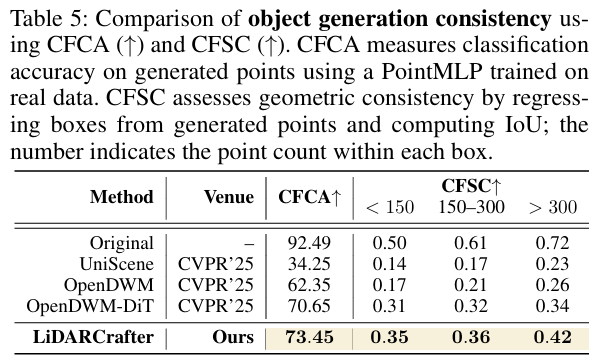
- 语义一致性(CFCA):用预训练PointMLP分类生成实例,得分73.45%,与真实类别对齐度高;
- 几何一致性(CFSC):用条件变分自编码器从生成点云回归3D框,在不同点数量(<150、150-300、>300)下均获最高IoU(0.35、0.36、0.42),严格遵循几何约束。
5.4 4D序列生成:时间连贯性“稳如泰山”
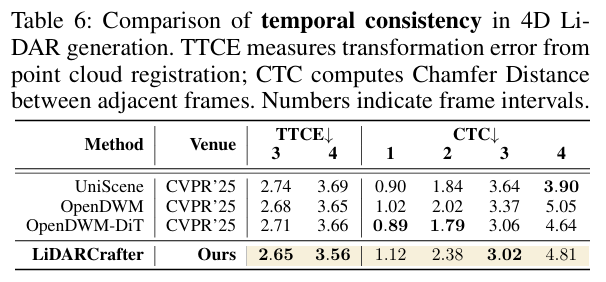
通过TTCE(帧间变换误差)与CTC(帧间Chamfer距离)评估序列时间一致性:
- TTCE:在3帧、4帧间隔下均获最低值(2.65、3.56),帧间变换与真值偏差更小;
- CTC:各帧间隔(1-4)性能竞争力强,序列过渡平滑;
- 可视化验证:生成序列全程保持结构一致与几何细节,而UniScene、OpenDWM等方法随时间推移保真度下降。
5.5 消融实验:关键设计“缺一不可”
验证核心模块有效性,关键结论如下:
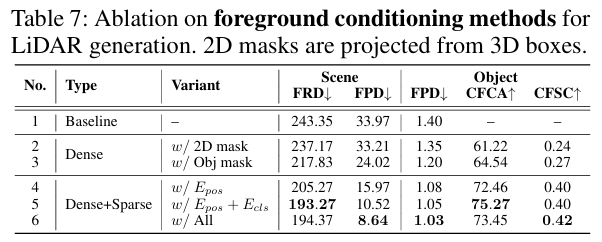
5.5.1 前景生成与条件:细节决定质量
- 加入3D框投影的2D前景掩码,场景生成质量提升;
- 进一步加入前景生成分支(细粒度目标掩码),FPD降低;
- 稀疏条件(嵌入位置+语义+几何属性)最优,FRD降至194.37、FPD降至8.64,证明目标中心条件的必要性。
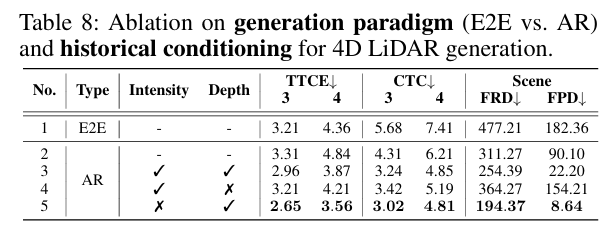
5.5.2 4D生成范式:自回归更适配LiDAR
- 自回归(AR)范式优于端到端(E2E):AR在TTCE、CTC等时间指标上更优,契合LiDAR“静态环境为主”的特性;
- 深度先验是关键:仅用深度先验(不含强度特征)时,FRD(194.37)、TTCE(2.65/3.56)最优,而排除深度先验会导致误差累积(FRD增加109.88)。
5.6 应用价值:能生成“危险场景”的“数据引擎”
依托目标级可控性,LiDARCrafter可合成罕见、高风险的自动驾驶边角场景,如:
- 车辆切入车道、公交车盲区出现行人、两车相邻碰撞等;
- 生成序列不仅符合用户指定场景,且全程保持时间连贯性,可用于数据增强与下游算法鲁棒性测试。
6. 收尾与远眺:LiDAR 4D建模的“现在与未来”
6.1 总结
本文提出LiDARCrafter这一统一框架,专为可控4D LiDAR序列生成与编辑设计。其通过场景图解析文本指令,结合多分支扩散模型生成目标布局、静态帧,并以自回归策略保证序列时间连贯性,同时构建覆盖场景-目标-序列级的评估基准。在nuScenes数据集上的实验表明,该框架在保真度、连贯性与可控性上全面超越现有方法,不仅能生成高质量LiDAR数据,还可合成安全关键场景,为自动驾驶下游系统评估提供支撑。
6.2 展望
未来将围绕两方向深化:一是探索多模态拓展,融合更多传感器数据(如摄像头、雷达)提升场景建模丰富度;二是优化模型效率,进一步降低计算成本、减少长序列生成中的误差累积,推动LiDAR 4D世界模型在更复杂真实场景中的落地应用。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)