LangChain 核心组件
消息、提示词模板、少样本提示、输出解析器、文档加载器
一.消息
消息是聊天模型中的通信单位,用于表示聊天模型的输入和输出 ,以及可能与对话关联的任何其他上下文或元数据 。
1.LLM消息结构
每条消息都有一个角色和内容,以及因 LLM 的不同而不同的附加元数据。
消息角色(Role):用来区分对话中不同类型的消息,并帮助聊天模型了解如何响应给定的消息序列。
消息内容 (Content):表示多模态数据 (例如,图像、音频、视频)的消息文本或字典列表的内容。内容的具体格式可能因底层不同的 LLM 而异。目前,大多数模型都支持文本作为主要内容类型,对多模态数据的支持仍然有限。
消息其他元数据(Additional metadata):
| 元数据 | 描述 |
| ID | 消息标识符 |
| Name | 名称允许区分具有相同角色的不同实体。并非所有型号都支持此功能 |
| Metadata | 有关消息的其他信息,例如时间戳、令牌使用情况等 |
| Tool Calls | 模型发出的一个或多个工具的调用请求 |
举例OpenAI的格式消息列表:
[
{
"role": "user",
"content": "Hello, how are you?",
},
{
"role": "assistant",
"content": "I'm doing well, thank you for asking.",
},
{
"role": "user",
"content": "Can you tell me a joke?",
}
]2.LangChain消息
LangChain 提供了一种统一的消息格式,可以跨聊天模型使用,允许用户使用不同的聊天模型,而无需担心每个模型提供商使用的消息格式的具体细节。
虽然模型提供商不同,但对于其输入和输出,统一使用 LangChain 的消息格式。LangChain 消息格式主要分为五种,分别是:
| 消息类型 | 对应角色 | 描述 |
| SystemMessage | system 系统角色 | 用于启动 AI 模型的行为并提供额外的上下文,例如指示模型采用特定角色或设定对话的基调 |
| HumanMessage | user 用户角色 | 人类消息表示用户与模型交互的输入。大多数聊天模型都希望用户输入采用文本形式 |
| AIMessage | assistant 助理角色 | 这是来自模型的响应,其中可以包括文本或调用工具的请求。它还可能包括其他媒体类型,如图像、音频或视频⸺尽管这目前仍然不常见 |
| AIMessageChunk | assistant 助理角色 | 用于流式响应通常在生成聊天模型时流式传输响应,因此用户可以实时看到响应,而不是等待生成整个响应后再显示 |
| ToolMessage | tool 工具角色 | 对应这表示一条角色为“tool”的消息,其中包含调用工具的结果 |
3.缓存历史消息
多轮对话
在与大型语言模型交互的过程中,我们常常体验到与智能助手进行连贯多轮对话的便利性。但目前我们的系统还不支持此功能。
我们可以通过上下文来保存信息:
# 配置 DeepSeek 模型
model = ChatOpenAI(
model="deepseek-chat",
base_url="https://api.deepseek.com/v1"
)
# 记录消息
messages = [
HumanMessage(content="Hi! I'm Bob"),
AIMessage(content="Hello Bob! How can I assist you today?"),
HumanMessage(content="What's my name?"),
]内存缓存
在 LangChain 老版本中,可以使用RunnableWithMessageHistory 消息历史类来包装另一个 Runnable 并为其管理聊天消息历史记录。它将跟踪模型的输入和输出,并将其存储在某个数据存储中。未来的交互将加载这些消息,并将其作为输入的一部分传递给链。
model = ChatOpenAI(model="gpt-4o-mini")
store = {}
# 根据会话 id 查询会话里的消息列表
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
# InMemoryChatMessageHistory() 帮助我们将AIMessage、HumanMessage等消息自动添加进来
store[session_id] = InMemoryChatMessageHistory()
return store[session_id]
# 包装了 model, 让model具备存储历史消息的能力
with_history_message_model = RunnableWithMessageHistory(model, get_session_history)
# model: Runnable 实例
# invoke: config: 配置 Runnable 实例
config={"configurable": {"session_id" : "1"}}
with_history_message_model.invoke(
[HumanMessage(content="我是小明,你好!")],
config = config,
).pretty_print()
with_history_message_model.invoke(
[HumanMessage(content="你知道我是谁吗?")],
config = config,
).pretty_print()class langchain_core.runnables.history.RunnableWithMessageHistory 类初始化参数说明:
| runnable | 被包装 Runnable 实例,这里就是我们定义的聊天模型 |
| get_session_history | 返回类型为 BaseChatMessageHistory 的函数,传入后作为回调函数。此函数接受一个 session_id 字符串类型,并返回相应的聊天消息历史记录实例 |
class langchain_core.runnables.history.RunnableWithMessageHistory 类方法说明:
| invoke() | 此方法与其他 Runnable 实例的 .invoke() 方法相同。只不过注意其config配置,需要配置成 config={"configurable": {"session_id": ""}} ,让RunnableWithMessageHistory 可以读取到会话id |
4.管理历史消息
消息裁剪
细看前面多轮对话的代码,发现其并不是真正的实现了缓存,而是把前面的对话和新的对话一起发过去了。由于所有模型的上下文窗口大小都是有限的,这意味着作为输入的 Token 也是有限的。如果有累积了很长的消息历史记录,则需要管理传递给模型的消息的长度。
trim_messages 可用于将聊天历史记录的大小裁剪为指定的令牌计数或指定的消息计数。
1)基于输入 Token 数的裁剪
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage(content="you're a good assistant"),
HumanMessage(content="hi! I'm bob"),
AIMessage(content="hi!"),
HumanMessage(content="I like vanilla ice cream"),
AIMessage(content="nice"),
HumanMessage(content="whats 2 + 2"),
AIMessage(content="4"),
HumanMessage(content="thanks"),
AIMessage(content="no problem!"),
HumanMessage(content="having fun?"),
AIMessage(content="yes!"),
HumanMessage(content="What's my name?"),
]
# 使用 trim_messages 减少发送给模型的消息数量
trimmer = trim_messages(
max_tokens=65, # 修剪消息的最大令牌数,根据你想要的谈话长度来调整
strategy="last", # 修剪策略:
# “last”(默认):保留最后的消息。
# “first”:保留最早的消息。
token_counter=model, # 传入一个函数或一个语言模型(因为语言模型有消息令牌计数方法)
include_system=True, # 如果想始终保留初始系统消息,可以指定 include_system=True
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第一条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)
chain = trimmer | model
print(chain.invoke(messages))2)基于消息数的裁剪
除了基于 token 的裁剪,还可以通过设置 token_counter=len 根据消息数修剪聊天记录。在这种情况下, max_tokens 将控制最大消息数。
trimmer = trim_messages(
max_tokens=11, # 修剪消息的最大令牌数,根据你想要的谈话长度来调整
strategy="last", # 修剪策略:
# “last”(默认):保留最后的消息。
# “first”:保留最早的消息。
token_counter=len, # 传入一个函数或一个语言模型(因为语言模型有消息令牌计数方法)
include_system=True, # 如果想始终保留初始系统消息,可以指定 include_system=True
allow_partial=False, # 是否允许拆分消息的内容
start_on="human", # 如果需要确保我们的第一条消息(不包括系统消息)始终是特定类型,可以指定 start_on
)消息过滤
在更复杂的场景下,我们可能会使用消息列表来跟踪状态,例如我们可能只想将这个完整消息列表的子集传递模型调用,而不是所有的历史记录。
filter_messages 方法则可以轻松地按类型、ID 或名称过滤 message。
# 历史消息记录
messages = [
SystemMessage("你是一个聊天助手", id="1"),
HumanMessage("示例输入", id="2"),
AIMessage("示例输出", id="3"),
HumanMessage("真实输入", id="4"),
AIMessage("真实输出", id="5"),
]
# 按照类型筛选
print(filter_messages(messages, include_types="human"))
# 按照id筛选
print(filter_messages(messages, exclude_ids=["3"]))
# 按照id+类型筛选
print(filter_messages(messages, exclude_ids=["3"], include_types=[HumanMessage, AIMessage]))消息合并
若我们的消息列表存在连续某种类型相同的消息,但实际上某些模型不支持传递相同类型的连续消息。因此对于这种情况,我们可以使用 merge_message_runs 方法轻松合并相同类型的连续消息。
model = ChatOpenAI(model="gpt-4o-mini")
# 历史消息记录
messages = [
SystemMessage("你是一个聊天助手。"),
SystemMessage("你总是以笑话回应。"),
HumanMessage("为什么要使用 LangChain?"),
HumanMessage("为什么要使用 LangGraph?"),
AIMessage("因为当你试图让你的代码更有条理时,LangGraph 会让你感到“节点”是个好主意!"),
AIMessage("不过别担心,它不会“分散”你的注意力!"),
HumanMessage("选择LangChain还是LangGraph?"),
]
# 方式1
merger_message = merge_message_runs(messages)
model.invoke(merger_message).pretty_print()
# 方式2
merger = merge_message_runs()
chain = merger | model
chain.invoke(messages).pretty_print()二.提示词模板
提示词模板(Prompt Template)是 LangChain 的核心抽象之一,它被广泛应用于构建大语言模型(LLM)应用的各个环节。简单来说,只要是需要动态、批量、或有结构地向大语言模型【发送请求】的地方,几乎都会用到提示词模板。
举个例子,假设我们想根据一个城市名询问 LLM 其历史,按照之前的做法,我们可以定义HumanMessage("请介绍北京的历史") 、 HumanMessage("请介绍上海的历史") 消息等等。可以发现每次询问都会描写重复的消息内容: 请介绍xxx的历史 。
但是现在可以使用提示词模板,定义一个固定文本:请介绍{city}的历史。我们使用的时候只需要输入对应的城市名称就可以了。
1.字符串模板
LangChain 提供了 PromptTemplate 类来轻松实现这一功能。 PromptTemplate 实现了标准的 Runnable 接口。PromptTemplate专用于处理文本类型的模板。
# 方式1:
prompt_template = PromptTemplate(
template="介绍{city}的历史",
input_variables=["city"],
)
print(prompt_template.invoke({"city": "北京"}))
# 方式2
prompt_template = PromptTemplate.from_template("将文本从{language_from}翻译为{language_to}")
# 调用:实例化模板
print(prompt_template.invoke({"language_from": "英文", "language_to": "中文"}))2.聊天消息模板
ChatPromptTemplate 模板:专为 LangChain 聊天模型设计。可以方便地构建包含SystemMessage 、 HumanMessage 、 AIMessage 的消息模板。
# 处理聊天消息的模板
chat_prompt_template = ChatPromptTemplate(
[
("system", "将文本从{language_from}翻译为{language_to}"),
("user", "{text}")
]
)
print(chat_prompt_template.invoke(
{
"language_from": "英文",
"language_to": "中文",
"text": "hi, what is your age?"
}
))3.消息占位符
MessagesPlaceholder 是 LangChain 框架中的一个重要组件,主要用于在对话链中动态地管理和插入历史消息。什么意思呢?使用占位符,我们可以站住这个位置,现在不往里添加信息,可能后面模型产生了某些数据,我们要将这些数据放入。
prompt_template = ChatPromptTemplate([
("system", "你是一个聊天助手"),
MessagesPlaceholder("msgs") # 消息占位符
])
messages_to_pass = [
HumanMessage(content="中国的首都是哪里?"),
AIMessage(content="中国的首都是北京。"),
HumanMessage(content="那韩国呢?")
]
formatted_prompt = prompt_template.invoke({"msgs": messages_to_pass})
print(formatted_prompt)
4.LangChain Hub
LangChain Hub 是一个用于上传、浏览、拉取和管理提示词(prompts)的地方。
官网地址:LangSmith
LangChain Hub类似于GitHub,里面有别人上传的提示词模板。
如果要使用就是下面的代码:

这个 prompt 就是一个组件,要使用直接 chain = prompt | model 即可。
三.少样本提示
少样本提示是一种通过向 LLM 提供少量具体示例或样本,来教会它如何执行某项特定任务的技术。提高模型性能的最有效方法之一是给出一个【模型示例】指导大模型你想做什么、怎么做。
LangChain为我们提供了FewShotChatMessagePromptTemplate 。
FewShotChatMessagePromptTemplate 是一个提示词模板,专门用来将示例集实例化为聊天消息。
类初始化参数说明:
| examples | 样本示例 |
| example_prompt | ChatPromptTemplate,用于格式化单个示例 |
example_prompt = ChatPromptTemplate(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt, # ChatPromptTemplate,⽤于格式化单个⽰例
examples=examples # 样本⽰例
)
print(few_shot_prompt.invoke({}).to_messages())四.输出解析器
负责获取模型的输出,并将输出转换为更结构化的格式。当使用 LLM 生成结构化数据或规范化聊天模型和 LLM 的输出时,这很有用。
大型语言模型(LLM)的输出本质上是非结构化的文本。但在构建应用程序时,我们通常希望得到结构化的、机器可读的数据,这样可以将其转换为更适合下游任务的格式。
输出解析器的作用就是架起这座桥梁:它们将 LLM 的非结构化文本输出转换为结构化格式。这使得与LLM 的交互从“模糊的文本对话”变成了“精确的数据 API 调用”,是构建可靠、高效 LLM 应用不可或缺的组件。
1.解析文本输出
使用 StrOutputParser 输出解析器输出文本:
model = ChatOpenAI(model="gpt-4o-mini")
chain = model | StrOutputParser()
for chunk in chain.stream("写⼀⾸夏天的诗词,50字以内。"):
print(chunk, end="|")
2.解析结构化对象输出
要输出结构化对象,需要用到的输出解析器是 PydanticOutputParser 。
model = ChatOpenAI(model="gpt-4o-mini")
# 定义输出结构:Pydantic 类
class Joke(BaseModel):
"""给用户讲的一个笑话"""
setup: str = Field(description="这个笑话的开头")
punchline: str = Field(description="这个笑话的妙语")
rating: Optional[int] = Field(
default=None, description="从1到10分,给这个笑话评分"
)
# 设置解析器
parser = PydanticOutputParser(pydantic_object=Joke)
# 提⽰词模板
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
# partial_variables:提⽰模板携带的部分变量的字典,⽆需在每次调⽤提⽰时都传⼊它们。
# 类型为 Mapping[str, Any],传⼊template携带的部分变量的字典。
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
for chunk in chain.stream({"query": "给我讲⼀个关于唱歌的笑话"}):
print(chunk, end="|")3.解析JSON输出
要输出 JSON 格式,需要用到的输出解析器是 JsonOutputParser 。
model = ChatOpenAI(model="gpt-4o-mini")
# 设置解析器
parser = JsonOutputParser()
# 提示词模板
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
chain = prompt | model | parser
print(chain.invoke({"query": "给我讲⼀个关于唱歌的笑话"}))五.文档加载器
文档加载器就是将给出的文档转换成 Document 对象。为什么要这么做呢?这都是为了下面的RAG做铺垫。我们要构建自己的向量数据库,首先就要将外部的文件加载进来,因此需要文档加载器。
1.Document 文档类
class langchain_core.documents.base.Document 用于存储一段文本和相关元数据的类,我们可以直接定义LangChain 文档列表。
from langchain_core.documents import Document
documents = [
# 单个Document对象通常表⽰较⼤⽂档的⼀个块
Document(
# 内容字符串
page_content="狗是很好的伴侣,以忠诚和友好⽽闻名。",
# 元数据字典
# 元数据属性可以捕获有关⽂档源、与其他⽂档的关系以及其他信息的信息。
metadata={"source": "mammal-pets-doc"},
),
Document(
page_content="猫是独⽴的宠物,经常享受⾃⼰的空间。",
metadata={"source": "mammal-pets-doc"},
),
]2.加载 PDF 文档
将本地的 PDF 文档加载到 LangChain 中,其实就是将 PDF 文档转换为一个个 Document 对象。这时就需要我们使用 PyPDFLoader 文档加载器完成这一功能。
class langchain_community.document_loaders.pdf.PyPDFLoader 类,有以下关键函数:
| init() | 初始化函数,入参 file_path ,表示要加载的 PDF 文件的路径 |
| load() → list[Document] | 将数据加载到文档对象中。返回文档对象列表 |
from langchain_community.document_loaders import PyPDFLoader
file_path = "./example_data/example.pdf"
loader = PyPDFLoader(file_path)
# 将 PDF ⽂件的每⼀⻚转换为⼀个独⽴的 Document 对象,并存储在列表 docs 中。
docs = loader.load()
print(f"问:PDF ⽂件的总⻚数为:\n{len(docs)}\n")
print(f"问:第⼀⻚⽂本内容的前200个字符是:\n{docs[0].page_content[:200]}\n")
print(f"问:第⼀⻚元数据:\n{docs[0].metadata}")3.加载 Markdown 文件
将本地的 Markdown 文档加载到 LangChain 中,需要我们使用 UnstructuredMarkdownLoader 文档加载器完成这一功能。
classlangchain_community.document_loaders.markdown.UnstructuredMarkdownLoader 类,有以下关键函数:
| init() | 初始化函数 |
| load() → list[Document] | 将数据加载到文档对象中。返回文档对象列表 |
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_core.documents import Document
# 文档加载器(MD)
md_loader = UnstructuredMarkdownLoader(
"./example_data/example.md",
# mode="single", # MD 加载器默认将文档加载为一个
mode="elements", # 拆分成不同类型的子块
)
data = md_loader.load()
print(data[0].page_content[:200])
print(data[0].metadata)六.文本分割器
我们已经知道可以通过文档加载器完成各种数据源的加载,将其转换为文档对象 Document 。那么接下来要做的就是文档拆分。
文档拆分通常是将大文本分解为更小的、易于管理的块。这对于索引数据并将其传递到模型中都很有用。因为大块更难搜索并且不适合模型的有限上下文窗口。拆分可以提高搜索结果的粒度,从而可以更精确地将查询与相关文档部分进行匹配。
LangChain 的文本分割器便能将大型文档分解为更小的块。
1.根据文档长度与文档语义拆分
基于字符长度拆分
根据给定的字符序列进行拆分,拆分的块长度则按字符数来衡量。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
markdown_path = "./example_data/example.md"
# single 模式加载后,默认只有⼀个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# ⽂本分割器
text_splitter = CharacterTextSplitter(
separator="\n\n", # 选择分隔符:它有⼀个默认的分隔符优先级列表,通常是:["\n\n", "\n", " ", ""]。它会按顺序尝试这些分隔符
chunk_size=100, # 设定⽬标:⽬标块⼤⼩
chunk_overlap=20, # 设定⽬标:块之间的重叠⼤⼩
length_function=len, # 使⽤测量⻓度的函数
is_separator_regex=False, # 分隔符是正则表达式吗
)
# 分割⽂档,返回被分割的⽂档列表
texts = text_splitter.split_documents(data)
# 打印前10个被分割出来的⽂档
for document in texts[:10]:
print("*" * 30)
print(f"{document}\n")当我们执行上面的代码的时候,会出现下面的提示:
Created a chunk of size xxx, which is longer than the specified 100
会有这个提示是因为文本分割器根据我们给出的选择分隔符分割出一段文本,但是这个文本块的超过了chunk_size。为了保证语义的完整性, 没有强行根据 chunk_size 来截断文本,而是将文本全部保存,同时输出提示告知我们。
基于 Token 长度拆分
在LangChain中,我们可以使用 CharacterTextSplitter 分割器的 .from_tiktoken_encoder() 方法来定义根据 tiktoken 分词器拆分文本的分割器。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
markdown_path = "./example_data/example.md"
# single 模式加载后,默认只有⼀个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 分割⽂档
texts = text_splitter.split_documents(data)
# 打印前10个被分割出来的⽂档
for document in texts[:10]:
print("*" * 30)
print(f"{document}\n")cl100k_base 是 tiktoken 分词器中的一种编码方式。 gpt-4 、 gpt-3.5-turbo 等都采用这种切分编码方法。下面是代码演示:
import tiktoken
# 定于cl100k_base编码⽅式的分词器
enc = tiktoken.get_encoding("cl100k_base")
# 进⾏切分编码
enc_output = enc.encode("my name is LiHua!")
# 打印结果
print(f"编码后的token:{str(enc_output)}")
for token in enc_output:
print(f"将token: {str(token)} 变成⽂本:{str(enc.decode_single_token_bytes(token))}")硬性约束长度拆分
想要求任何块都不能超过指定大小,可以使用 RecursiveCharacterTextSplitter 类或RecursiveCharacterTextSplitter.from_tiktoken_encoder 方法,它会严格遵守对块大小的硬约束。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
markdown_path = "./example_data/example.md"
# single 模式加载后,默认只有⼀个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# ⽣成分割器
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base",
chunk_size=100,
chunk_overlap=0,
)
# 分割⽂档
texts = text_splitter.split_documents(data)
# 打印前10个被分割出来的⽂档
for document in texts[:10]:
print("*" * 30)
print(f"{document}\n")这里要注意,使用这种方式分割文本硬性约束了文本长度大小,可能会导致语义不一致问题。
2.特殊文档结构拆分
若对于代码等特殊文本,可以尝试使用 Language 提供的不同的分割器(如 PythonCodeTextSplitter 、 HTMLHeaderTextSplitter 等)效果会更好,它会理解代码的语法结构。
from langchain_text_splitters import PythonCodeTextSplitter
# 字符串⽂档
PYTHON_CODE = """
def hello_world():
print("Hello, World!")
def hello_python():
print("Hello, Python!")
"""
python_splitter = PythonCodeTextSplitter(chunk_size=50, chunk_overlap=0)
python_docs = python_splitter.create_documents([PYTHON_CODE])
for document in python_docs[:2]:
print("*" * 30)
print(f"{document}\n")七.文本向量
关于向量的介绍在这篇文章里有:大模型介绍-CSDN博客这里就不介绍了。
1.Embeddings 嵌入模型类
在 LangChain 中,有很多的嵌入模型提供方,使用不同的模型提供方,需要安装为其各自包:Embedding models - Docs by LangChain
像LLM一样,要使用模型,首先要定义模型。这里以OpenAI为例,定义 OpenAI 下的嵌入模型使用:class langchain_openai.embeddings.base.OpenAIEmbeddings
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large",
)OpenAIEmbeddings 继承于 Embeddings 类,Embeddings 类有两个核心方法:
| embed_documents() | 用于处理文档 Documents 。它的输入是多个文本。例如要将一个知识库里的所有段落都转换成向量后存入数据库,就会使用这个方法 |
| embed_query() | 用于处理查询 Query 。它的输入是单个文本(一个字符串,str)。例如,当用户提出一个问题时,需要将这个问题转换成向量,以便在数据库中搜索相似的文档段落,就会使用这个方法 |
简单来说,embed_documents() 就是将文档转化成向量,embed_query() 就是将我们发送的请求转成向量。
下面详细说说。
embed_documents 的语义是 “索引”。它的目的是预处理大量文本,为它们创建向量表示,以便后续被搜索。这一般是一个离线、批量处理的过程。下面用代码演示这个过程:
from langchain_openai import OpenAIEmbeddings
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
markdown_path = ""
# single 模式加载后,默认只有一个 Document 对象
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 分割文档
documents = text_splitter.split_documents(data)
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 嵌入文档列表,生成向量列表
# 注意这⾥需要提取文档内容为字符串列表,才能传递给嵌⼊模型
texts = [doc.page_content for doc in documents]
documents_vector = embeddings.embed_documents(texts)
print(f"⽂档数量为:{len(documents)},⽣成了{len(documents_vector)}个向量的列表")
print(f"第⼀个⽂档向量维度:{len(documents_vector[0])}")
print(f"第⼆个⽂档向量维度:{len(documents_vector[1])}")embed_query 的语义是 “搜索”。它的目的是在用户发起请求时,实时地将一个问题或指令转换为向量,用于在已索引的文档向量中进行检索。这是一个在线、实时、按需处理的过程。下面用代码演示这个过程:
from langchain_openai import OpenAIEmbeddings
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 嵌⼊单个查询
query_vector = embeddings.embed_query("介绍一些文档")
print(f"向量维度:{len(query_vector)}")
print(f"向量前五个数值为:{query_vector[:5]}")2.向量存储(Vector Stores)
前面使用嵌入模型类的方法来生成了向量,生成后要进行存储。
向量存储的核心任务是解决一个传统数据库(如MySQL)不擅长的问题:基于内容的相似性搜索(Similarity Search),而不是基于精确匹配的查询。因此向量要存储在专门的向量存储介质中。
内存存储
使用 LangChain 的 InMemoryVectorStore 来实现向量的内存存储。
1)初始化
LangChain 中的大多数向量在初始化向量存储时接受嵌入模型作为参数。
from langchain_openai import OpenAIEmbeddings
from langchain_core.vectorstores import InMemoryVectorStore
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 内存存储初始化
vector_store = InMemoryVectorStore(embedding=embeddings)2)添加文档
我们可以使用 add_documents 方法,向内存存储中去添加文档。要注意的是,该方法会为添加的文档编排索引,索引列表随着该方法返回。
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_text_splitters import CharacterTextSplitter
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载⽂档
data = UnstructuredMarkdownLoader("").load()
# 分割⽂档
documents = text_splitter.split_documents(data)
# 添加⽂档
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个⽂档索引")
print(f"前3个⽂档的索引是:{ids[:3]}")3)获取文档
使用 get_by_ids 方法,通过索引列表获取对应的文档列表。
doc_3 = vector_store.get_by_ids(ids[:3])
print(f"{[doc.page_content for doc in doc_3]}")4)删除文档
使用 delete 方法,删除传入索引列表对应的文档列表;若不传入索引列表,则认为全量删除。
vector_store.delete(ids=ids[:3])5)相似性搜索
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返回。这可以使用 similarity_search 方法来实现。
search_docs = vector_store.similarity_search(query="数据库表怎么设计的?", k=2)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)Redis 向量存储
1)初始化
LangChain 中使用 RedisVectorStore 初始化 Redis 向量存储。由于 Redis 需要相关配置,如连接 URL 等,因此 LangChain 提供了 RedisConfig 配置类供我们使用。
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客⼾端
redis_url = "redis://127.0.0.1:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)2)添加文档
我们可以使用 add_documents 方法,向向量库中去添加文档。这次我们可以给被分割的文档添加相关的元数据。
# ⽣成分割器
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
encoding_name="cl100k_base", chunk_size=200, chunk_overlap=50
)
# 加载⽂档
data = UnstructuredMarkdownLoader("", category="QA").load()
# 分割⽂档
documents = text_splitter.split_documents(data)
# 为⽂档添加元数据
for i, doc in enumerate(documents, start=1):
doc.metadata["category"] = "QA"
doc.metadata["num"] = i
ids = vector_store.add_documents(documents=documents)
print(f"共编排了{len(ids)}个⽂档索引")
print(f"前3个⽂档的索引是:{ids[:3]}")3)获取文档
使用 get_by_ids 方法,通过索引列表获取对应的文档列表。
ids = [":01K4Q0A3DSQVZBRFKJD5MS25HJ", ":01K4Q0A3DSQVZBRFKJD5MS25HK",":01K4Q0A3DSQVZBRFKJD5MS25HM"]
doc_3 = vector_store.get_by_ids(ids)
print(f"{[doc.page_content for doc in doc_3]}")4)删除文档
使用 delete 方法,删除传入索引列表对应的文档列表。
vector_store.delete([":01K4Q0A3DSQVZBRFKJD5MS25HJ"])5)相似性搜索
想要获取根据相似性搜索的结果,即嵌入单个查询,并查找相似的文档,并将它们作为文档列表返回。这可以使用 similarity_search 方法来实现。
search_docs = vector_store.similarity_search(query="数据库表怎么设计的?", k=2)
for doc in search_docs:
print("*" * 30)
print(doc.page_content)八.检索器(Retrievers)
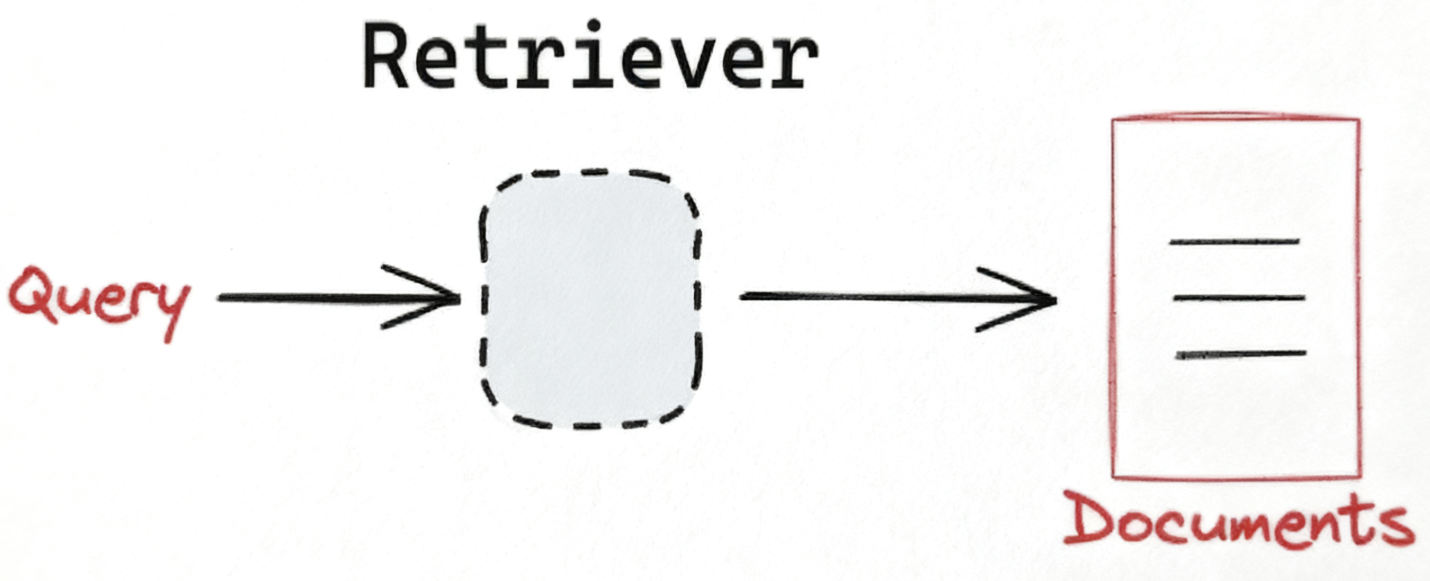
检索系统(Information Retrieval System, IR System)是一个为了满足用户信息需求,从大规模、非结构化的数据集合中,自动、高效地查找、排序并返回相关信息的计算机系统。它的核心任务是:在正确的时间,以正确的方式,将正确的信息传递给正确的人。
检索器是检索系统中的一个核心组件,它接收来自用户接口的查询(Query),检索出包含查询关键词的候选文档集合。
LangChain 提供了一个统一的接口来与不同类型的检索系统进行交互。LangChain的检索器接口非常简单:输入:查询字符串。输出:文档列表(标准化的 LangChain 文档对象 Document)。
1.使用向量数据库作为检索器
向量存储是索引和检索非结构化数据的⼀种强大而有效的方法。可以通过调用向量数据库的 as_retriever 方法,将向量存储用作检索器。在这里我们使用 Redis 向量存储。
from langchain_openai import OpenAIEmbeddings
from langchain_redis import RedisConfig, RedisVectorStore
# 定义嵌⼊模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 配置 Redis 客⼾端
redis_url = "redis://127.0.0.1:6379"
config = RedisConfig(
index_name="qa",
redis_url=redis_url,
metadata_schema=[
{"name": "category", "type": "tag"},
{"name": "num", "type": "numeric"},
],
)
# Redis 存储初始化
vector_store = RedisVectorStore(embeddings, config=config)
retriever = vector_store.as_retriever()
docs = retriever.invoke("数据库表怎么设计的?")
for doc in docs:
print("*" * 30)
print(doc.page_content[:30])2.使用 @chain 创建“检索器”
@chain
def retriever(query: str) -> List[Document]:
return vector_store.similarity_search(query, k=2)
docs = retriever.invoke("数据库表怎么设计的?")
for doc in docs:
print("*" * 30)
print(doc.page_content[:30])上面定义了一个函数,使用 @chain 修饰,该修饰可以使其成为 Runnable 函数,且满足检索器输入输出的要求。在函数中,我们依旧使用向量数据库的相似性搜索方法,这样灵活性也更高,想要进行元数据筛选也更便利。
注意,这并不是真正的检索器,检索器是一个 Runnable 对象,而我们定义的只是一个函数,具备其特点罢了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)