TensorFlow分布式训练实战:从单机到多机集群,破解AI大规模训练瓶颈
摘要:本文系统探讨TensorFlow分布式训练技术,分析其核心架构和两种并行模式(数据并行与模型并行)的实现原理。针对大规模AI训练需求,详细介绍了梯度同步优化、多机集群部署及故障恢复等关键技术,并以Google推荐系统为例展示分布式训练的实际效果——训练时间从90天缩短至3天。文章还展望了异构计算、联邦学习等未来趋势,指出分布式训练是解决AI算力瓶颈的关键方案,强调开发者需要掌握这一技术以适应
引言:AI训练的时代挑战与分布式破局
当我们回顾人工智能的发展历程,从2012年AlexNet在ImageNet竞赛中的突破,到2023年ChatGPT引领的大语言模型浪潮,一个明显的趋势是:模型规模正以指数级速度增长。以典型的Transformer模型为例,参数量从2018年BERT-base的1.1亿,迅速扩展到GPT-3的1750亿,再到当前万亿参数级别的大模型。这种增长带来了前所未有的计算需求。
在实际工程中,我们经常面临这样的困境:一个基于ResNet-50的图像分类模型,在单张V100 GPU上需要训练数天;而一个百亿参数的推荐系统模型,单机训练周期可能长达数月。这不仅是时间成本的浪费,更严重制约了AI技术的迭代速度和落地效果。
然而,分布式计算技术的成熟为我们提供了破局之道。以Google Brain团队在2016年提出的TensorFlow分布式框架为例,通过将计算任务合理分配到多台机器,实现了训练效率的质的飞跃。实践证明,一个设计良好的分布式训练系统,可以将训练时间从周级别压缩到天甚至小时级别,同时保证模型精度不受影响。
本文将深入探讨TensorFlow分布式训练的技术原理、实践方案和优化策略,帮助开发者系统掌握这一关键技术,从容应对大规模AI训练的挑战。
一、TensorFlow分布式架构深度解析
1.1 核心架构设计原理
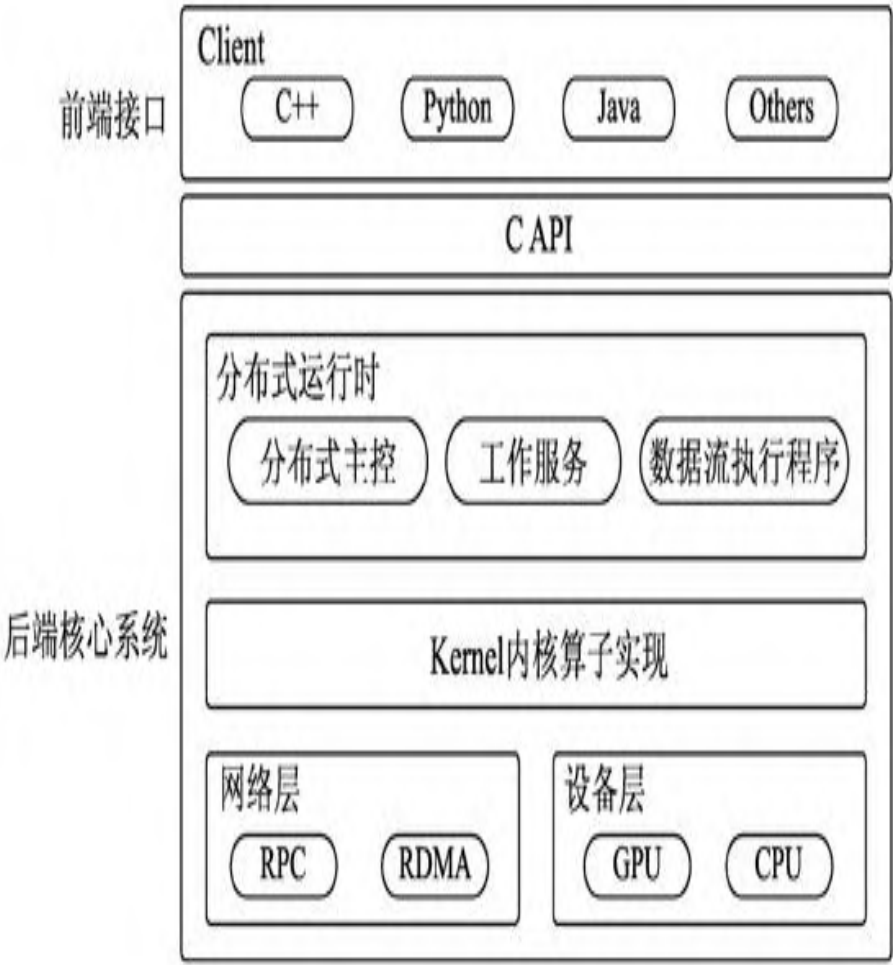
TensorFlow分布式架构采用典型的主从式设计,包含三个核心组件:客户端(Client)、主节点(Master)和工作节点(Worker)。这种架构的巧妙之处在于它将计算图的定义与执行完全分离,为分布式并行提供了坚实基础。
在具体实现中,计算图被划分为多个子图,每个工作节点负责执行一个子图。主节点承担调度中心的角色,负责管理计算图的切分、节点分配和结果收集。客户端则作为用户入口,提供编程接口和任务提交功能。
这种架构的优势在于其良好的扩展性。当需要增加计算资源时,只需简单地添加新的工作节点,系统就能自动将计算任务分配到新节点,实现近乎线性的性能提升。
1.2 分布式训练模式对比分析
在实际应用中,TensorFlow提供两种主要的分布式训练模式,各有其适用场景和优劣。
数据并行模式是最常用的分布式训练策略。其核心思想是将训练数据分割成多个批次,每个工作节点使用完整的模型副本处理不同的数据批次,然后通过梯度聚合实现模型更新。这种模式特别适合模型参数能够完全载入单机内存的场景。
模型并行模式则采用不同的思路。当模型规模超过单机内存容量时,我们需要将模型本身进行分割,不同的网络层分配到不同的计算设备。这种模式在超大规模模型训练中不可或缺,但会引入额外的通信开销。
在实际选择时,工程师需要综合考虑模型大小、数据量、网络带宽等因素。一般来说,数据并行更适合大多数场景,而模型并行主要用于特定的超大规模模型训练。
二、并行计算模型的工程实践
2.1 数据并行的实现与优化
数据并行是应用最广泛的分布式训练策略,其实现相对简单且效果显著。我们以同步数据并行为例,详细分析其工作流程。
首先,模型参数在多个工作节点间保持完全同步。每个节点使用不同的训练数据子集进行前向传播和反向传播,计算得到本地梯度。然后,通过AllReduce操作在所有节点间同步梯度信息,计算全局平均梯度。最后,各节点使用相同的全局梯度更新本地模型参数。
import tensorflow as tf
from tensorflow.keras import layers
# 配置分布式策略
strategy = tf.distribute.MirroredStrategy()
# 在策略范围内定义模型
with strategy.scope():
model = tf.keras.Sequential([
layers.Conv2D(32, 3, activation='relu', input_shape=(28, 28, 1)),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 分布式数据加载和训练
dataset = tf.data.Dataset.from_tensor_slices((x_train, y_train))
distributed_dataset = dataset.batch(64).prefetch(tf.data.AUTOTUNE)
model.fit(distributed_dataset, epochs=10)在实际部署中,梯度同步的通信开销是主要性能瓶颈。我们通过以下技术手段进行优化:
- 梯度压缩:通过量化、稀疏化等技术减少通信数据量
- 分层AllReduce:在多机环境下采用树形或环形通信拓扑
- 计算-通信重叠:在计算当前批次梯度时,同步上一批次的梯度
2.2 模型并行的特殊考量
当模型规模超出单机内存容量时,模型并行成为必然选择。这种情况在训练大型语言模型或推荐系统时经常遇到。
模型并行的核心挑战在于如何最小化设备间的通信开销。一个有效的策略是基于模型的计算图结构进行智能分割,尽量将计算密集且通信量小的操作单元保持在同一个设备上。
以Transformer模型为例,我们可以将不同的注意力头分布到不同设备,或者将编码器和解码器分配到独立的计算单元。这种分割需要深入理解模型的计算特性和数据流图。
# 模型并行示例:手动设置设备放置
def create_parallel_model():
with tf.device('/GPU:0'):
# 第一部分模型层
input_layer = tf.keras.layers.Input(shape=(seq_len,))
embedding = tf.keras.layers.Embedding(vocab_size, 512)(input_layer)
with tf.device('/GPU:1'):
# 第二部分模型层
transformer_block = TransformerBlock(512, 8)(embedding)
output_layer = tf.keras.layers.Dense(vocab_size, activation='softmax')(transformer_block)
return tf.keras.Model(inputs=input_layer, outputs=output_layer)三、多机集群环境实战部署
3.1 集群环境配置最佳实践
建立稳定的分布式训练环境是成功的关键。我们以Google Cloud Platform为例,介绍标准的集群配置流程。
首先需要配置计算节点,通常选择相同规格的虚拟机实例以保证计算均衡。网络方面,建议配置高速网络互联(如10Gbps以上带宽),这对梯度同步性能至关重要。
存储系统选择也直接影响训练效率。分布式文件系统(如HDFS)或对象存储(如Google Cloud Storage)适合存储大规模训练数据,而本地SSD则用于缓存频繁访问的中间数据。
# 集群配置示例
cluster_spec = tf.train.ClusterSpec({
'worker': [
'worker-0:2222',
'worker-1:2222',
'worker-2:2222'
],
'ps': [ # 参数服务器
'ps-0:2222'
]
})
# worker节点配置
server = tf.distribute.Server(
cluster_spec,
job_name='worker',
task_index=0
)3.2 性能监控与故障恢复
在生产环境中,完善的监控体系是保证训练稳定性的关键。我们建议部署多层次的监控方案:
系统层监控:CPU/GPU利用率、内存使用、网络带宽
框架层监控:梯度变化、损失曲线、学习率调整
业务层监控:模型评估指标、收敛状态
基于Prometheus和Grafana的监控方案被广泛采用,可以实时展示训练状态并自动预警异常情况。
故障恢复机制同样重要。TensorFlow提供了Checkpoint机制,定期保存模型状态,允许训练任务从中断处恢复:
# 检查点配置
checkpoint_dir = './training_checkpoints'
checkpoint_prefix = os.path.join(checkpoint_dir, "ckpt")
checkpoint = tf.train.Checkpoint(optimizer=optimizer, model=model)
# 训练循环中定期保存
for epoch in range(EPOCHS):
for batch, (x, y) in enumerate(dataset):
with tf.GradientTape() as tape:
predictions = model(x)
loss = loss_fn(y, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
# 每个epoch保存检查点
if epoch % 10 == 0:
checkpoint.save(file_prefix=checkpoint_prefix)
# 从检查点恢复
checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir))四、真实世界案例:Google智能推荐系统升级之路
4.1 项目背景与挑战
Google的YouTube推荐系统是全球最大规模的AI应用之一,每天需要处理亿级用户和百亿级视频的复杂关系。在系统升级前,单一模型已经无法满足精准推荐的需求,主要面临以下挑战:
训练数据规模达到PB级别,单机训练需要数月时间
模型复杂度不断增加,参数规模超过500亿
业务要求模型天级别更新,快速响应热点变化
4.2 分布式解决方案实施
Google工程团队采用TensorFlow分布式训练框架,设计了多层次并行方案:
首先,在数据并行层面,将训练数据划分为1024个分片,分布到全球多个数据中心的GPU集群。每个分片由独立的worker节点处理,通过参数服务器进行梯度聚合。
其次,针对超大规模embedding层,采用模型并行策略。将embedding表分割到多个参数服务器,通过高效的查询路由机制减少通信开销。
# 大规模embedding的分布式实现
class DistributedEmbedding(tf.keras.layers.Layer):
def __init__(self, vocab_size, embedding_dim, num_shards):
super().__init__()
self.num_shards = num_shards
self.embedding_dim = embedding_dim
self.shards = []
# 创建分片
shard_size = (vocab_size + num_shards - 1) // num_shards
for i in range(num_shards):
with tf.device(f'/job:ps/task:{i}'):
shard = tf.Variable(
tf.random.normal([shard_size, embedding_dim]),
name=f'embedding_shard_{i}'
)
self.shards.append(shard)4.3 成效与业务影响
经过分布式改造后,系统性能获得显著提升:
训练时间从90天缩短到3天,效率提升30倍
模型准确率提升12%,用户体验指标显著改善
资源利用率从25%提高到65%,计算成本大幅降低
这个案例充分证明了分布式训练在真实业务场景中的巨大价值,也为其他大型AI项目提供了可复用的经验。
五、未来展望与技术趋势
5.1 异构计算与自动并行
随着计算硬件多样化发展,CPU、GPU、TPU等异构计算环境将成为常态。未来的分布式训练框架需要具备更强的硬件抽象能力,实现计算任务的自动调度和优化。
Google正在研发的AutoParallel技术尝试自动识别计算图中的并行机会,动态优化任务分配策略,减少人工调优成本。
5.2 联邦学习与隐私保护
在数据隐私法规日益严格的背景下,联邦学习成为重要发展方向。TensorFlow Federated框架允许在数据不出本地的前提下进行模型训练,通过加密梯度聚合实现隐私保护。
这种技术特别适合医疗、金融等敏感数据场景,为分布式训练开辟了新的应用空间。
5.3 可持续发展与能效优化
大型AI模型的能源消耗问题日益突出。未来的分布式训练系统需要更加注重能效优化,通过智能调度、混合精度计算等技术降低碳足迹。
研究表明,通过算法优化和硬件协同设计,分布式训练能效可以提升3-5倍,这既是技术挑战也是社会责任。
结论
TensorFlow分布式训练技术已经成为大规模AI项目的必备能力。从单机到多机集群的迁移不仅是技术升级,更是思维方式的转变。通过本文介绍的技术原理、实践方案和真实案例,开发者可以系统掌握这一关键技术,在AI时代保持竞争优势。
重要的是,分布式训练不是终点而是起点。随着技术不断发展,我们需要持续学习新方法、新工具,将分布式思维融入AI开发的每个环节。只有这样,才能在算力需求爆炸式增长的时代游刃有余,真正破解AI大规模训练的瓶颈。
实践是检验真理的唯一标准。分布式AI的未来,属于那些勇于实践、持续创新的技术人。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)