CPU 和 GPU 的指令集:类型、作用及核心差异解析
CPU与GPU指令集设计差异源于其核心定位:CPU指令集(如x86/ARM)侧重通用性,支持复杂逻辑判断、多任务调度和多样化计算,具备丰富指令类型和低延迟特性;GPU指令集(如CUDA/ROCm)专为并行计算优化,采用SIMD模式实现数万核心同步运算,聚焦算术运算和内存访问,吞吐量极高但延迟较高。在科研场景中,CPU负责任务调度与系统控制,GPU处理海量并行计算(如AI训练),二者协同工作。优化指
CPU(通用计算核心)和 GPU(并行计算核心)的指令集设计,完全适配其核心定位 ——CPU 侧重 “复杂逻辑 + 通用任务”,指令集兼顾灵活性与功能性;GPU 侧重 “海量并行 + 重复计算”,指令集主打高效吞吐量与并行适配。
一、核心前提:指令集的本质的是 “硬件能听懂的命令”
指令集是 CPU/GPU 与软件之间的 “沟通语言”—— 软件(如操作系统、AI 框架、游戏)的逻辑,最终会编译成指令集中的一条条 “命令”,硬件执行这些命令完成计算。
- CPU 的指令集:像 “多功能工具箱”,包含各种复杂工具(应对不同场景),支持 “按需调用”;
- GPU 的指令集:像 “流水线专用工具”,只有少数高频工具,但能让数千个工人同时使用。
二、CPU 的指令集:通用、灵活、覆盖全场景
CPU 的指令集(如 x86、ARM)是 “通用指令集(CISC/RISC)”,核心目标是适配复杂逻辑判断、多任务调度、多样化计算需求,指令类型丰富,支持单条指令完成复杂操作。
1. 核心指令类型及作用(结合科研 / 日常场景)
| 指令类别 | 具体作用 | 通俗类比 | 典型场景举例 |
|---|---|---|---|
| 数据传输指令 | 实现 CPU 与内存、寄存器之间的数据读写(如加载数据、存储结果) | “搬运工”:移动数据 | 编程中读取变量、保存计算结果 |
| 算术逻辑指令(ALU) | 基础运算(加减乘除、模运算)+ 逻辑判断(与 / 或 / 非、比较大小) | “计算器”:做基础运算 + 判断 | 科学计算中的公式求解、代码中的 if-else |
| 控制流指令 | 改变程序执行顺序(如跳转、循环、函数调用、中断处理) | “交通指挥员”:规划执行路径 | 循环训练 AI 模型、程序报错时触发中断 |
| 复杂运算指令 | 单条指令完成复杂操作(如浮点运算、矩阵乘法、加密解密) | “高级工匠”:一站式复杂任务 | 高精度科学计算、数据加密传输 |
| 多线程 / 同步指令 | 支持多核心协同(如线程创建、锁机制、缓存同步) | “团队协调员”:让多核心配合 | 多线程编程、分布式任务中的数据同步 |
| 系统特权指令 | 操作硬件资源(如控制 PCIe 通道、管理内存地址、访问 I/O 设备) | “管理员”:操控核心硬件 | 操作系统启动、配置 GPU 与 CPU 的通信 |
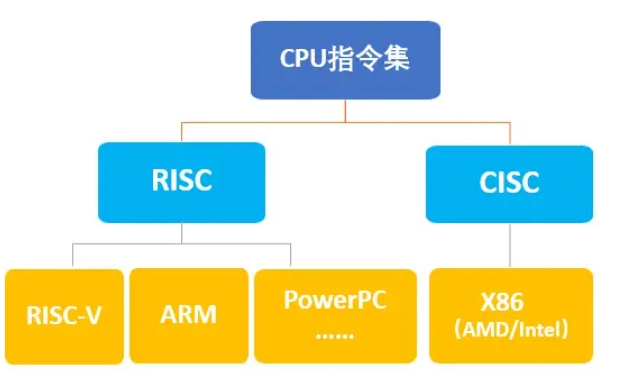
2. 主流 CPU 指令集架构(ISA)
- x86 架构:Intel/AMD 桌面端 / 服务器 CPU(如 i9、Ryzen),指令集丰富(CISC 复杂指令集),兼容所有主流软件,支持复杂逻辑和多任务,科研中服务器常用;
- ARM 架构:华为鲲鹏、苹果 M 系列 CPU,指令集精简(RISC 精简指令集),功耗低、效率高,适合移动设备和低功耗服务器,部分科研集群会采用 ARM 服务器降本。
3. CPU 指令集的核心特点
- 「灵活通用」:单条指令可处理复杂任务(如 x86 的
AVX-512指令支持 512 位宽的向量运算),适配从办公软件到科学计算的所有场景;- 「低延迟优先」:指令执行流程优化(如流水线、乱序执行),减少单条指令的延迟,适合串行复杂逻辑;
- 「功能全面」:包含系统级指令(如中断、特权操作),能直接操控硬件,是整个计算机系统的 “控制核心”。
三、GPU 的指令集:并行、高效、聚焦重复计算
GPU 的指令集(如 CUDA、ROCm、昇腾指令集)是 “并行专用指令集”,核心目标是适配数万流处理器的海量并行计算,指令类型简洁,侧重 “单指令多数据(SIMD)”—— 即一条指令同时控制数千个核心处理不同数据。
1. 核心指令类型及作用(结合科研 / AI 场景)
| 指令类别 | 具体作用 | 通俗类比 | 典型场景举例 |
|---|---|---|---|
| 算术运算指令 | 基础浮点运算(FP8/FP16/FP32/FP64)、整数运算、向量运算(SIMD) | “流水线工人”:重复做简单运算 | AI 模型的矩阵乘法、图形渲染的像素计算 |
| 内存访问指令 | 实现 GPU 与显存、共享内存、寄存器之间的数据读写(高带宽优化) | “高速传送带”:批量运输数据 | 大模型训练时读取参数 / 梯度、存储中间结果 |
| 纹理采样指令 | 图形渲染专用(读取 3D 模型的纹理、光影数据) | “美工”:处理图形细节 | 游戏画面渲染、科研中的 3D 场景仿真 |
| 专用计算指令 | 适配 AI、光追的专用指令(如张量核心指令、光线追踪指令) | “专业工具人”:专攻特定任务 | 深度学习的矩阵乘加(GEMM)、光追的光线相交计算 |
| 并行控制指令 | 控制流处理器集群的并行执行(如线程同步、分支预测) | “流水线调度员”:协调数千工人 | 多卡并行训练时的线程同步、数据分片处理 |
3. GPU 指令集的核心特点
- 「单指令多数据(SIMD)」:一条指令同时控制数千个流处理器(如 NVIDIA SM 的 warp 机制,32 个核心执行同一条指令),大幅提升并行吞吐量;
- 「高带宽优化」:内存访问指令适配 HBM3/GDDR7 的高带宽特性,支持批量数据读写,避免 “计算核心等数据”;
- 「专用指令加速」:针对 AI、光追等场景设计专用指令(如 NVIDIA 的
Tensor Core指令,FP8 算力达 4PFLOPS),远超通用指令的效率;- 「简化控制流」:不支持复杂的系统级指令(如中断、特权操作),控制流指令(如分支)效率低,避免影响并行吞吐量。
四、CPU 与 GPU 指令集的核心差异对比表
| 对比维度 | CPU 指令集 | GPU 指令集 |
|---|---|---|
| 设计目标 | 通用灵活、低延迟、适配复杂逻辑 | 并行高效、高吞吐量、适配重复计算 |
| 指令类型 | 丰富多样(数据传输、逻辑判断、系统控制等) | 简洁专一(算术运算、内存访问、专用计算) |
| 执行模式 | 单指令单数据(SISD)+ 少量向量运算(SIMD) | 单指令多数据(SIMD/SIMT),数万核心并行 |
| 核心优势 | 处理复杂逻辑、多任务调度、系统控制 | 处理海量重复计算(AI、科学计算、图形) |
| 延迟水平 | 低(单指令延迟 1-10ns) | 高(单指令延迟 5-20ns),但吞吐量极高 |
| 软件适配 | 所有通用软件(操作系统、办公、编程工具) | 专用软件(AI 框架、HPC 软件、游戏),需编译适配 |
| 典型指令 | x86 的 AVX-512、ARM 的 NEON | CUDA 的 Tensor Core 指令、昇腾的 GEMM 指令 |
五、结合科研 / 工作场景的关键结论
-
为什么 AI 大模型必须用 GPU 指令集?大模型训练的核心是 “海量矩阵乘法”(重复、独立的计算),GPU 的 SIMD 指令能让数万核心同时执行同一条乘法指令,吞吐量是 CPU 的数百倍 —— 比如用 CPU 的 AVX-512 指令训练 GPT-3 需要几年,而 GPU 的 Tensor Core 指令仅需几周。
-
科研中 CPU 和 GPU 指令集的协同逻辑?
- CPU 指令集:负责任务调度(如启动训练任务、分配数据)、复杂逻辑处理(如数据预处理、参数优化算法)、系统控制(如控制 GPU 与内存的通信);
- GPU 指令集:负责并行计算核心任务(如模型的前向 / 反向传播、梯度计算),接收 CPU 的 “调度指令” 后,批量处理海量数据。
-
GPU 集群的指令集适配建议?
- 若使用 NVIDIA GPU(H100/A100):优先用 CUDA 指令集,搭配 TensorFlow/PyTorch 的 CUDA 版本,启用 Tensor Core 加速 FP8 训练;
- 若使用华为昇腾 GPU:适配昇腾指令集,用 MindSpore 框架或 TensorFlow/Ascend 版,调用
GE(昇腾计算引擎)优化指令执行效率; - 跨平台需求:用 OpenCL 或 OneAPI,兼容不同厂商 GPU,但性能会略低于原生指令集。
-
指令集优化的科研价值?同一 GPU 下,优化指令集执行(如用混合精度指令 FP8 替代 FP32、启用专用指令),可将训练 / 计算效率提升 2-5 倍 —— 比如鹏城云脑 II 的大模型训练,通过优化 CUDA 指令集和 Tensor Core 调度,将千亿参数模型的训练周期从 3 个月压缩至 1 个月。
总结
CPU 和 GPU 的指令集是 “功能互补” 的设计:
- CPU 指令集是 “通用控制语言”,擅长复杂逻辑、多任务和系统管理,是计算机的 “大脑”;
- GPU 指令集是 “并行计算语言”,擅长海量重复计算,是 AI 和科学计算的 “算力引擎”。
在科研中,两者的协同是 “CPU 指令集调度,GPU 指令集计算”—— 理解它们的差异,能帮助你更好地优化代码(如用 CUDA 指令优化 GPU 计算、用 AVX 指令优化 CPU 预处理),充分释放硬件算力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 4
4 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)