(论文速读)使用文本到图像生成器的介入数据增强
探讨了利用文本到图像(T2I)生成器进行介入性数据增强的方法,以提高图像分类器在环境变化下的鲁棒性。针对单域泛化(SDG)和减少虚假特征依赖(RRSF)任务,研究系统评估了提示策略、条件机制和后处理过滤三个维度的影响。实验结果表明,现代T2I生成器(如Stable Diffusion)作为数据增强机制显著优于传统方法,其中纯文本生成方式表现最佳,且简单提示往往足够有效。该研究为数据增强提供了新范式
论文题目:Not Just Pretty Pictures: Toward Interventional Data Augmentation Using Text-to-Image Generators(不只是漂亮的图片:使用文本到图像生成器的介入数据增强)
会议:ICML2024
摘要:已知神经图像分类器在暴露于不同于其训练数据的环境条件中采样的输入时,会经历严重的性能下降。鉴于文本到图像(T2I)生成的最新进展,一个自然的问题是如何使用现代T2I生成器来模拟对此类环境因素的任意干预,以增加训练数据并提高下游分类器的鲁棒性。我们在单域泛化(SDG)和减少对虚假特征(RRSF)的依赖的各种基准上进行了实验,并在T2I生成的关键维度上进行了细化,包括介入提示策略、调节机制和事后过滤。我们广泛的实证研究结果表明,像稳定扩散这样的现代T2I发生器确实可以用作强大的介入数据增强机制,无论每个维度如何配置,它都优于以前最先进的数据增强技术。
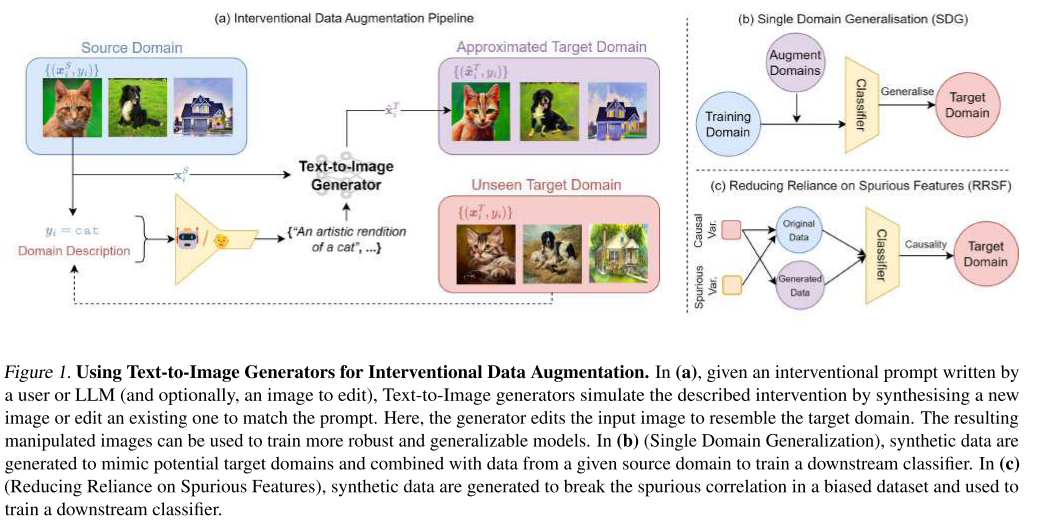
用文本生成图像做数据增强,不只是生成漂亮图片
一、研究背景与动机
核心问题
深度学习图像分类器存在一个致命弱点:当测试环境与训练环境不同时,性能会急剧下降。这种现象被称为协变量偏移(covariate shift)或域偏移(domain shift)。
举个例子:
- 训练数据:白天拍摄的照片
- 测试数据:夜晚拍摄的照片
- 结果:模型性能大幅下降
传统方法的局限
现有的数据增强方法主要依赖预定义的图像变换(如旋转、裁剪、颜色抖动等),存在以下问题:
- 表达能力有限:无法模拟复杂的环境变化(如"将卡通图转为真实照片")
- 需要专业知识:针对不同任务需要手工设计增强策略
- 缺乏灵活性:难以用自然语言描述想要的变换
研究机遇
近年来,文本到图像(Text-to-Image, T2I)生成模型(如Stable Diffusion)取得了惊人进展,能够:
- 根据文本描述生成或编辑图像
- 理解复杂的语义概念
- 模拟多样的视觉风格
关键问题:这些强大的生成模型能否用于数据增强,以提高分类器的鲁棒性?
二、论文的核心创新
1. 将T2I模型用作通用干预性数据增强机制
论文提出了一个新视角:将数据增强理解为对环境变量的"干预"
传统增强方法可以看作是对环境条件(如光照、天气)的近似干预,而T2I模型能够通过自然语言提示模拟任意干预。
工作流程:
原始图像 → T2I模型 + 干预提示 → 增强图像
例如:"一只猫的照片" + "转为素描风格" → "一只猫的素描"
2. 系统性研究框架
论文在两个关键任务上进行了全面实验:
任务1:单域泛化(Single Domain Generalization, SDG)
- 目标:从单一训练域泛化到多个未见测试域
- 数据集:PACS, OfficeHome, NICO++, DomainNet
- 示例:用艺术画训练,在照片、卡通、素描上测试
任务2:减少对伪相关特征的依赖(RRSF)
- 目标:打破训练数据中的伪相关性
- 数据集:
- ImageNet-9(背景偏差)
- CCS(纹理偏差)
- CelebA(人口统计学偏差)
3. 多维度对比研究
论文系统研究了三个关键维度:
维度1:提示策略(Prompting Strategies)
实验了四种提示策略:最小化提示(M)、领域专家手工制作(H)、以及两种语言增强策略(LEC和LEM)
示例:
- Minimal (M): "a sketch of an elephant"
- Hand-crafted (H): "an ink pen sketch of an elephant", "a charcoal sketch of an elephant"
- Language Enhancement: 使用T5模型生成多样化提示
维度2:条件机制(Conditioning Mechanisms)
对比了四种生成/编辑方法:
- SDEdit: 从原图像嵌入开始扩散
- Text2Image: 纯文本生成(不依赖原图)
- ControlNet: 使用边缘检测保持空间结构
- InstructPix2Pix: 基于编辑指令微调
还对比了检索(Retrieval):直接从训练数据中检索相关图像
维度3:后处理过滤
使用CLIP相似度过滤低质量生成图像
三、主要实验结果
1. SDG任务:大幅超越现有方法
在ResNet-50上,使用最小提示的SDEdit在PACS数据集上达到76.43%平均准确率,相比最强基线PixMix的67.12%提升了约9个百分点
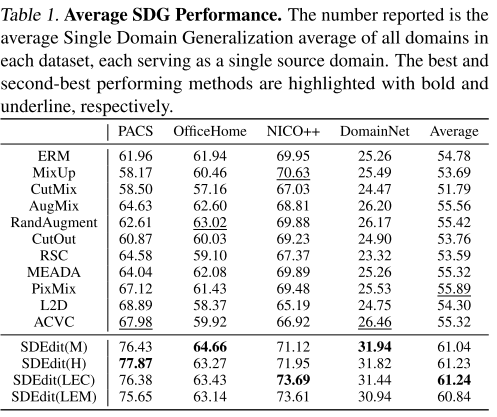
各数据集表现:
| 数据集 | ERM | PixMix | SDEdit(M) | 提升 |
|---|---|---|---|---|
| PACS | 61.96% | 67.12% | 76.43% | +9.31% |
| OfficeHome | 61.94% | 61.43% | 64.66% | +3.23% |
| NICO++ | 69.95% | 69.48% | 71.12% | +1.64% |
| DomainNet | 25.26% | 25.53% | 31.94% | +6.41% |
关键发现1:简单的Minimal提示策略往往与复杂的手工制作或LLM生成的提示性能相当,在某些数据集上甚至更好
2. 条件机制的重要性
Text2Image(纯文本生成)在多数情况下表现最好,表明条件在原图像上有时反而是一种限制
PACS数据集对比(ResNet-50):
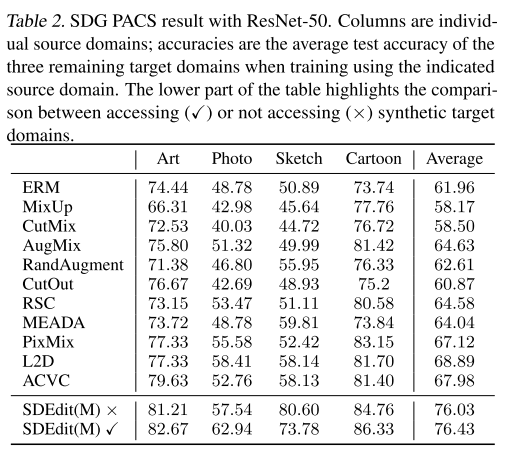
| 方法 | 平均准确率 |
|---|---|
| SDEdit(M) | 76.43% |
| Text2Image(M) | 83.72% |
| ControlNet(M) | 74.49% |
| InstructPix2Pix | 66.82% |
| Retrieval | 82.90% |
意外发现:检索方法表现出色,在某些数据集上甚至超过生成方法,这表明Stable Diffusion的训练数据已包含许多相关样本
3. 无需精确描述目标域
论文做了一个有趣的实验:在不生成目标测试域数据的情况下(SDEdit(M)×),仍然显著超过基线方法,仅比使用目标域的版本略差
这说明:T2I模型模拟的干预本身就是有用的,即使不精确匹配测试分布
4. RRSF任务:有效打破伪相关
在所有RRSF基准上,SDEdit都实现了显著改进,而且可以灵活地针对不同类型的偏差调整提示
ImageNet-9(背景偏差):
- ERM: Gap = 12.48%
- SDEdit: Gap = 9.63%
- Text2Image: Gap = 6.17%
CCS(纹理偏差):
- ERM: Texture Bias = 72.45%
- Text2Image: Texture Bias = 51.21%
CelebA(性别-发色伪相关):
- ERM: FlipGap = 22.28%
- Text2Image: FlipGap = 8.8%
5. CLIP过滤的作用有限
与之前的工作不同,论文发现CLIP过滤并未一致性地带来性能提升,这可能是因为较新的生成模型质量已经足够高
四、深入分析与洞见
1. 生成 vs 检索
论文对比了生成和检索两种方法的优缺点:
检索的优势:
- 图像真实,无生成伪影
- 一旦部署,速度快
- 在某些任务上性能优秀
检索的劣势:
- 需要巨大存储空间(>200TB)
- 需要复杂的索引基础设施
- 难以组合新概念
生成的优势:
- 模型紧凑(Stable Diffusion约8GB),现代生成器能有效地以新方式组合训练数据中的概念
- 更灵活,可控性强
2. 为什么简单提示有效?
论文发现Minimal提示(如"a sketch of a cat")往往与复杂提示性能相当。可能原因:
- T2I模型的鲁棒性:Stable Diffusion训练时就接触了各种表述方式
- 过度具体化的风险:太详细的描述可能引入不必要的噪声
- 域标签的充分性:对于定义明确的域(如"sketch"),简单描述已经足够
3. 失败案例分析
论文诚实地讨论了局限性,特别是对于远离训练分布的数据:
- 医学图像(组织病理学切片)
- 显微镜图像(细胞图像)
- 特殊视角的农业图像(小麦检测)
在这些情况下,生成质量下降,需要进一步研究。
五、方法论亮点
1. 实验设计的全面性
- 4个SDG数据集 × 6个域 = 24种训练-测试组合
- 3个RRSF数据集涵盖不同类型的偏差
- 11种基线方法,包括传统增强和最新的域泛化方法
- 多种架构:ResNet-18, ResNet-50, ConvNeXt-L
2. 消融研究的深度
- 系统地研究了提示、条件、过滤三个维度
- 对比了生成和检索
- 分析了生成样本数量的影响
- 研究了不使用目标域信息的情况
3. 定性和定量分析结合
- 丰富的可视化示例
- FID分数分析域偏移
- CLIP相似度分析
- 人工检查重复性
关键要点总结
-
核心贡献:T2I生成模型可以作为强大的通用干预性数据增强机制,在SDG和RRSF任务上大幅超越现有方法
-
最重要的发现:
- 条件机制的选择影响最大
- 简单提示往往足够有效
- Text2Image(纯文本生成)在多数情况下最优
- 检索也是一个有竞争力的选择
-
实践建议:
- 从简单的Minimal提示开始
- 根据任务选择合适的条件机制
- 考虑生成和检索的混合使用
- 利用人机协作迭代改进
-
研究意义:
- 为数据增强提供了新范式
- 将自然语言与计算机视觉深度融合
- 为人机协作的机器学习开辟新途径
结语
这篇论文展示了生成模型在数据增强中的巨大潜力,不仅在性能上取得了显著提升,更重要的是提供了一种更灵活、更直观、更强大的增强范式。
随着T2I模型的持续进步,我们可以期待:
- 更快的生成速度
- 更好的编辑质量
- 更精确的控制能力
- 更广泛的应用场景
"Not Just Pretty Pictures" —— 这个标题恰如其分地概括了论文的主旨:生成模型不仅能创造美丽的图像,更能成为提升AI系统鲁棒性和泛化能力的强大工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 39
39 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)