别再混淆了!RAG、LangChain与Agent的真实关系,看这篇就够了
这是个极具代表性的问题——过去十八个月里,无论是刚入行的算法工程师,还是从传统开发转型AI的技术人,几乎都问过我同样的困惑。RAG、LangChain、Agent这三个词总是被捆绑出现,以至于很多人误以为它们是同一维度的技术,甚至必须组合使用才能落地。但事实恰恰相反:一个是业务架构模式,一个是开发工具框架,一个是智能应用形态,三者本质上泾渭分明。
这是个极具代表性的问题——过去十八个月里,无论是刚入行的算法工程师,还是从传统开发转型AI的技术人,几乎都问过我同样的困惑。RAG、LangChain、Agent这三个词总是被捆绑出现,以至于很多人误以为它们是同一维度的技术,甚至必须组合使用才能落地。但事实恰恰相反:一个是业务架构模式,一个是开发工具框架,一个是智能应用形态,三者本质上泾渭分明。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
咱们抛开晦涩的学术定义,也不用绕弯子的比喻,我结合过去多个企业级AI项目的踩坑经历,把这三者的关系彻底讲透。文章会涉及不少技术细节和落地取舍,建议你找个不受干扰的环境慢慢读——这些内容,可能会帮你避开转型路上的不少坑。
最常见的误区就是:“我该用RAG还是LangChain?” 这种问法堪比"我该用红烧还是铁锅做菜"——RAG是红烧这种烹饪方法,LangChain则是铁锅这类工具。你完全可以用不锈钢盆(原生Python代码)做出红烧肉(RAG系统),也能用铁锅(LangChain)烹制清蒸鱼(普通Prompt工程应用)。搞懂这个类比,就解开了第一个心结。
当前AI行业的核心痛点很明确:大模型的能力存在天然边界。为了突破这个边界,RAG这种"外接知识库"的模式应运而生;为了降低开发门槛、提升效率,LangChain这类集成化框架才被推出;而当大模型从"能说会道"进化到"能执行任务",Agent这种智能形态就成了新的方向。咱们逐个拆解,最后再看它们如何协同。
RAG:给大模型装个"可靠的记忆库"
最早我们尝试用微调(Fine-tuning)解决这些问题——把几万条垂直领域数据喂给模型训练。结果可想而知:算力成本高到离谱,效果却极其不稳定。模型倒是学会了行业话术,但具体知识点经常张冠李戴;更麻烦的是,数据一旦更新,总不能天天重启训练吧?这时候,RAG就成了性价比最高的解法。
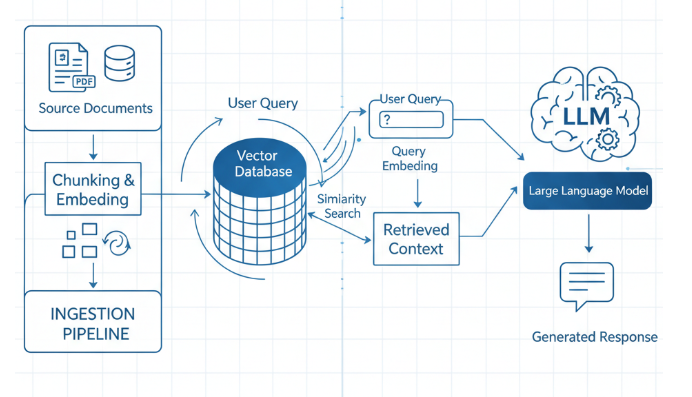
RAG的本质不是让模型死记硬背,而是教会它"翻参考书"。用户提问后,系统不会直接把问题丢给模型,而是先去你的私有数据库里检索相关资料,把最匹配的几段内容提取出来,和问题一起作为提示词传给模型。这时候模型的角色从"百科全书"变成了"专业阅卷人",基于给定的参考资料生成答案,幻觉和知识滞后问题自然就解决了。
落地RAG时,这几个技术点是我们踩坑最多的地方,也是效果的关键:
第一是数据切分。整份文档直接入库肯定不行,大模型的上下文窗口扛不住。但切多大、怎么切是门学问:按字符切容易截断语义,比如把法律条文的"应当"和"承担责任"拆开;按语义切又会增加模型计算开销。我们现在的实战经验是"小切片+多重叠"——单段控制在300-500字,相邻切片保留20%的重叠内容,既能控制成本又能避免语义丢失。
第二是向量化与检索,这是RAG的核心。先把文本转换成向量(Embedding)存入向量数据库,检索时再把用户问题也转成向量,找相似度最高的内容。这里必须提醒:选对中文Embedding模型至关重要,建议去MTEB排行榜上挑,BGE、Jina系列的中文效果都比OpenAI的Embedding好,还更省钱。单纯向量检索也不够,对专有名词不敏感、容易混淆近义反义内容,所以现在主流玩法是"混合检索"——向量检索+BM25关键词检索,最后用Rerank模型重排序,精度能提升40%以上。
想深入学RAG优化,强烈推荐啃LlamaIndex的官方文档。它虽然是个框架,但文档里把"从小到大检索"“滑动窗口匹配”"元数据过滤"这些进阶策略讲得明明白白,比看十篇公众号文章都管用。另外,字节跳动的6万字RAG实践手册也很实用,从数据清洗、知识库构建到性能优化,全是工程落地干货,还能免费获取,对新手特别友好。
我们之前做过法律文书查询系统,一开始简单切块入库,律师用了直接骂娘——法条上下文全乱了。后来发现法律文档层级极强,光切分不够,必须保留"章节-条款-细则"的父子关系。优化后,检索到子切片时会自动带上父级上下文,比如"《民法典》第1052条-婚姻家庭编-夫妻关系",结果准确率直接从58%冲到92%。这才是RAG的精髓:数据治理比选模型更重要。
LangChain:大模型时代的"脚手架",好用但别依赖
LangChain在AI圈的争议很大:支持者觉得它省事儿,反对者嫌它臃肿。其实它的定位很清晰——大模型开发的集成框架,相当于AI时代的Spring Boot。它把大模型调用、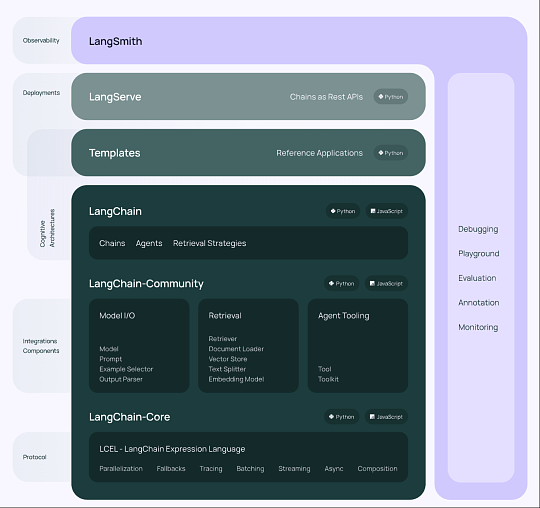 向量数据库连接、Prompt模板管理、输出解析这些零散组件全封装好了,你只要用"链(Chain)"把它们串起来,就能快速搭出应用。
向量数据库连接、Prompt模板管理、输出解析这些零散组件全封装好了,你只要用"链(Chain)"把它们串起来,就能快速搭出应用。
LangChain最大的贡献是建立了行业标准。在它出现前,对接OpenAI是一套代码,对接Claude是另一套,本地部署Llama又得重写适配逻辑。现在有了它,换模型只需要改一行配置,极大降低了开发成本。但作为踩过坑的过来人,我必须泼盆冷水:它的缺点和优点一样突出。
首先是版本迭代太激进,API兼容性极差。我们去年写的RAG代码,今年升级LangChain后直接报错——三个核心函数全改了参数。其次是过度封装,想改个底层参数比登天还难。之前做对话应用时,默认的Memory组件会自动压缩历史对话,但它的总结Prompt是英文的,导致中文对话被译成英文再喂给模型,结果模型直接开始飙英语。为了改这个Prompt,我翻了三层源码才找到隐藏的默认配置。那时候真觉得,还不如自己用Python写个简单的历史记录管理器,两小时就能搞定。
所以LangChain和RAG的关系很明确:LangChain内置了Document Loaders、Text Splitters这些RAG必需的组件,用它搭RAG Demo最快只要半小时。但如果是企业级项目,业务逻辑复杂、对性能要求高,就别全盘依赖它了。现在很多资深团队的做法是:借鉴LangChain的编排思想,用LCEL(LangChain Expression Language)写轻量代码,或者干脆自己封装核心组件——把控制权握在手里才踏实。
学习LangChain的话,Andrew Ng和LangChain创始人合开的短课程一定要看。DeepLearning.AI平台上就能找到,全程不讲虚的,从搭对话机器人到集成工具调用,全是实战案例,是入门的最佳路径。官方文档也要常翻,但别死记API,重点学它的组件设计思路——这才是能长期复用的能力。
Agent:让模型从"会说"到"会做",落地先从"副驾驶"开始
如果说RAG是给模型装了"记忆库",LangChain是架起"神经网络",那Agent就是让模型长出"手脚"。作为最近最火的概念,很多人把它和RAG搞混,其实区别很简单:RAG是静态的"问-查-答",路径固定;Agent是动态的"思考-行动",有自主决策能力。
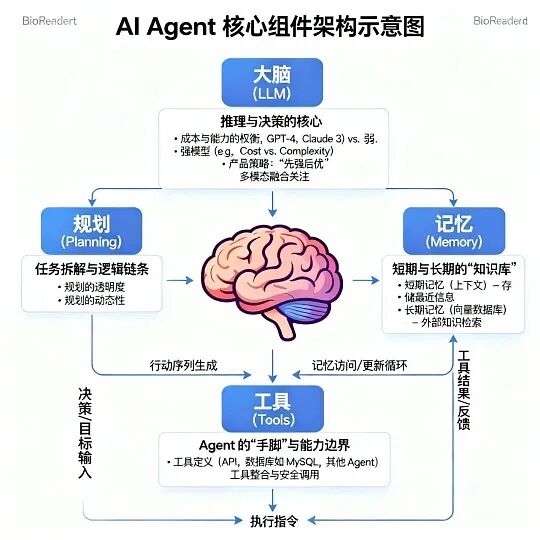
Agent的核心逻辑是闭环:感知问题→规划步骤→执行行动→观察结果→调整规划。举个实际场景你就懂了:“查一下明天北京的天气,如果下雨就给老板发请假邮件,不下雨就订一张去天津的高铁票。” 纯RAG系统根本做不了——它没有调用API的能力,也不会做逻辑分支判断,但这正是Agent的专长。
这个场景里,Agent会这样思考:第一步需要调用天气API获取数据;第二步根据结果判断分支——雨天调用邮件工具,晴天调用订票工具。这里面涉及两个关键能力:规划(Planning)和工具使用(Tool Use),也是Agent落地的核心难点。
技术实现上,LangChain也提供了Agent的构建模块,早期的ReAct(Reason + Act)模式是经典方案——模型输出答案前,会先输出思考过程,比如"我需要先获取天气数据,所以调用XX API",拿到结果后再进行下一步决策。但Agent的落地难度比RAG高一个量级,最大的问题是稳定性。
模型经常会"走神":让它查天气,它可能突然跑去搜北京的旅游攻略;调用订票API时,还会出现参数填错的情况,比如把"天津"写成"天津西",导致程序崩溃。我们做企业级Agent时,80%的精力都花在容错上——比如给工具调用加参数校验,给规划步骤加边界约束,防止模型天马行空。
现在很多热门的Agent框架,比如AutoGPT,演示时看着很酷,真上生产环境全是坑。它可能陷入死循环,反复思考"要不要再查一次天气",把Token耗光了还没执行核心任务。所以目前Agent的落地,基本都是Copilot(副驾驶)模式,而不是Autopilot(全自动)——关键节点必须有人干预确认,比如订票前让用户核对日期和车次,发邮件前确认内容无误。
学习Agent技术,首先要吃透OpenAI的Function Calling文档,这是实现工具调用的底层能力,不管用不用LangChain都得学。其次可以关注Microsoft的AutoGen框架,它支持多个Agent协作对话,比如一个负责查数据,一个负责写报告,虽然还在实验阶段,但代表了多智能体协作的未来方向。
想了解Agent的实际落地案例,字节的内部实践手册值得一看。字节业务版图大,手册里覆盖了从底层技术(大模型优化、API集成、架构设计)到上层场景(飞书智能办公、抖音电商、内容创作)的全链路案例。比如飞书的Agent能自动排会生成纪要,抖音电商的Agent能做库存监控和智能定价,这些真实案例比纯理论有用得多。
三者协同:搭建企业级AI助手的完整逻辑
说了这么多,终于可以把三者串起来了。假设你要做一个企业级AI助手,这三者的角色会非常清晰:
你需要RAG——不然助手根本不懂公司的内部文档、项目资料和客户数据,只能做个通用聊天机器人,没法落地业务。
你需要LangChain(或类似的编排逻辑)——它就像乐高底板,帮你把大模型、向量数据库、RAG流程和各种业务API串起来,还要负责管理对话历史、处理格式转换这些杂活。
你需要Agent——让助手从"问答工具"升级成"办公伙伴",比如根据RAG检索到的项目数据自动生成周报,或者发现客户资料更新后主动发通知给销售。
总结一下关系:LangChain是工具箱,RAG是用工具箱实现的核心功能,Agent是融合了RAG与其他工具的高级形态。在实际架构中,Agent往往会包含RAG——比如Agent在执行"整理竞品分析报告"的任务时,发现自己对某款产品的信息不足,就会自动调用检索工具,而这个工具的底层就是一套RAG系统。
这一年多里,我见过太多盲目跟风的公司:有的企业文档全是扫描件,连OCR识别都没做就上RAG,结果检索出来全是乱码;有的业务逻辑特别固定,比如电商售后话术查询,非要强行上Agent,结果模型偶尔的不可控导致订单出错——其实用关键词匹配+简单RAG就足够了,成本还不到十分之一。
技术永远是服务于业务的,选型前一定要想清楚:你的核心需求是什么?如果是客服机器人、文档查询这类固定场景,RAG足够用;如果是个人助理、办公自动化这类复杂场景,再考虑Agent,但要做好长期调优的准备;至于LangChain,我的建议是"学思想,轻封装"——Demo阶段随便用,生产环境一定要把代码控制权拿回来,核心逻辑自己写,只复用它的基础组件。
AI行业变化太快,今天讲的具体工具可能半年后就会被替代,但核心逻辑不会变:用RAG管理数据,用LangChain这类框架编排流程,用Agent赋予自主能力。把这三者的关系理清楚,无论技术怎么迭代,你都能快速找准方向。
如果这篇内容帮你解开了困惑,建议收藏起来——以后面试聊技术选型,或者项目里遇到决策难题时,翻出来看看,应该能帮你少走不少弯路。
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献206条内容
已为社区贡献206条内容

所有评论(0)