Langchain-Chatchat[二、多功能对话流程代码解析]
本文解析了Langchain-Chatchat的多功能对话流程,重点介绍了基于FastAPI实现的OpenAI统一接口处理流程。通过chat_completions接口接收用户请求后,系统会初始化异步OpenAI客户端,处理SSE格式的流式响应。核心流程包括:1) 获取异步Client实例;2) 初始化AsyncClient和AsyncStream组件;3) 使用SSEDecoder解码流数据。文
前言
Langchain-Chatchat多功能对话流程代码解析。
对话如图: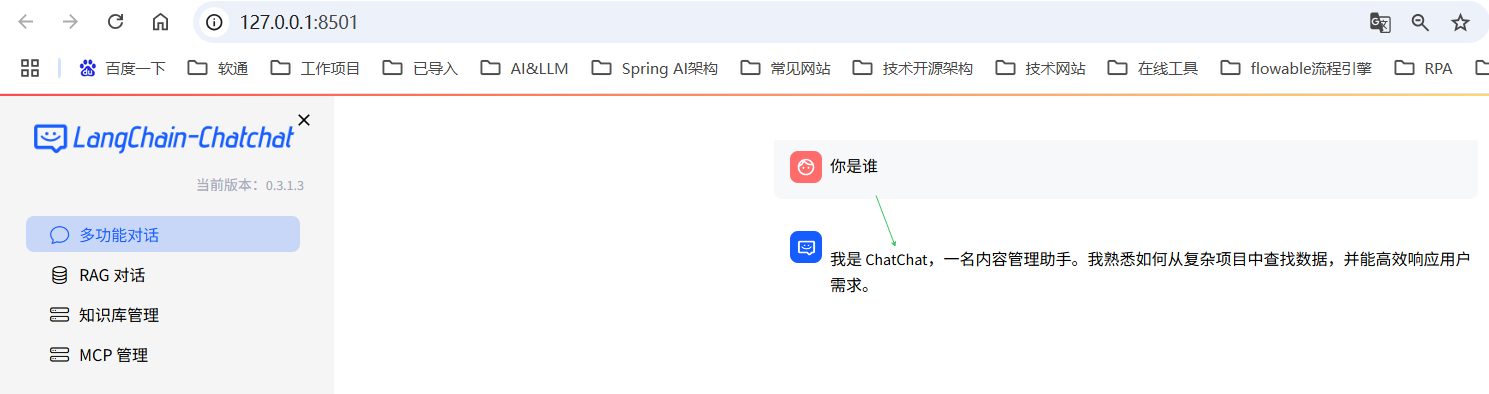
前提
Langchain-Chatchat[一、本地开发环境部署]
PyCharm 配置debug调试参数:start -a
一、AI多功能对话流程图
流程1:统一chat接口流程和设置client子流程
流程2:异步调用chat子流程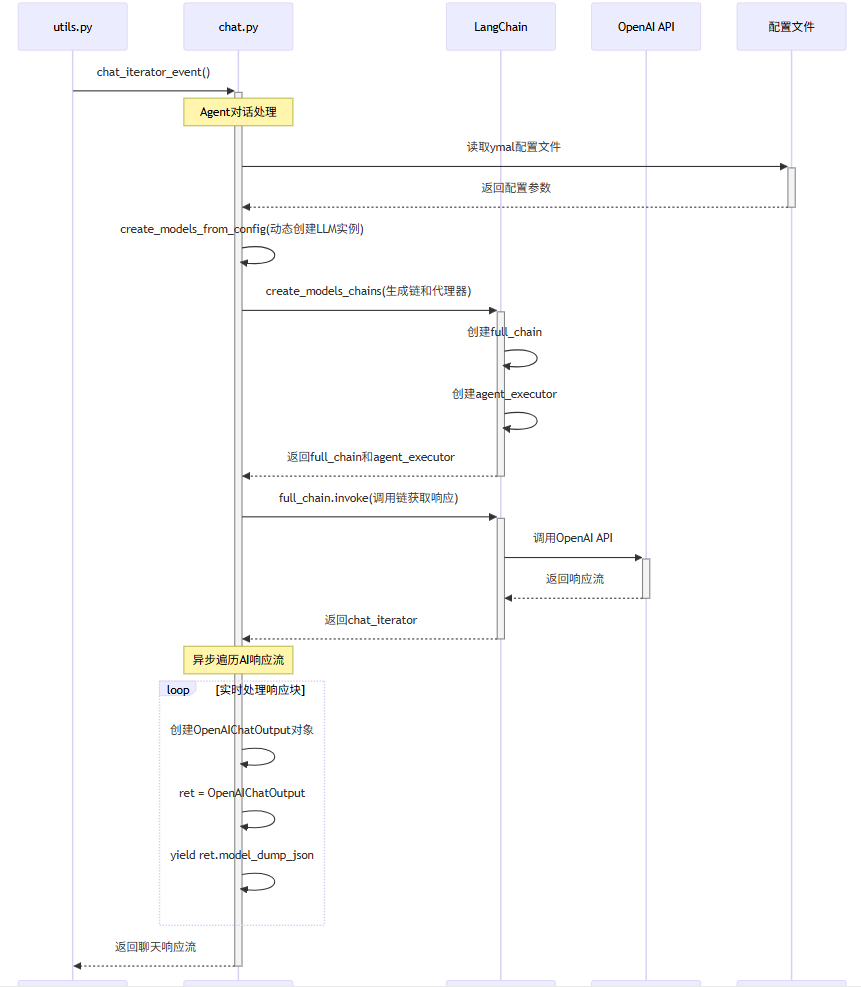
流程3:SSE Stream流数据推送
二、流程说明
1.接收用户AI对话请求,调用OpenAi、生成Stream流数据
chatchat.server.api_server.chat_routes.py
代码如下(片断):
1.基于fastapi组件,实现openai的统一chat接口,接收前台Chat 用户请求
@chat_router.post("/chat/completions", summary="兼容 openai 的统一 chat 接口")
async def chat_completions(
request: Request,
body: OpenAIChatInput,
) -> Dict:
...
"""
设置client,见 1.1 获取AI Client-get_OpenAIClient
"""
client = get_OpenAIClient(model_name=body.model, is_async=True)
...
"""
新增聊天记录到session
"""
try:
message_id = (
add_message_to_db(
chat_type="agent_chat",
query=body.messages[-1]["content"],
conversation_id=conversation_id,
)
if conversation_id
else None
)
...
"""
异步调用chat,见 1.2 初始化openai组件异步Client[AsyncClient]、AsyncAPIClient和异步流AsyncStream
"""
result = await chat(
query=body.messages[-1]["content"],
metadata=extra.get("metadata", {}),
conversation_id=extra.get("conversation_id", ""),
message_id=message_id,
history_len=-1,
stream=body.stream,
chat_model_config=extra.get("chat_model_config", chat_model_config),
tool_config=tool_config,
use_mcp=extra.get("use_mcp", False),
max_tokens=body.max_tokens,
)
return result
1.1 获取AI Client-get_OpenAIClient
def get_OpenAIClient(
platform_name: str = None,
model_name: str = None,
is_async: bool = True,
) -> Union[openai.Client, openai.AsyncClient]:
...
if is_async:
if httpx_params:
params["http_client"] = httpx.AsyncClient(**httpx_params)
return openai.AsyncClient(**params)
1.2 初始化openai组件异步Client[AsyncClient]、AsyncAPIClient和异步流AsyncStream
openai.AsyncClient 调用:
class AsyncOpenAI(AsyncAPIClient):
def __init__(
self,
*,
api_key: str | Callable[[], Awaitable[str]] | None = None,
organization: str | None = None,
project: str | None = None,
webhook_secret: str | None = None,
base_url: str | httpx.URL | None = None,
websocket_base_url: str | httpx.URL | None = None,
timeout: float | Timeout | None | NotGiven = not_given,
max_retries: int = DEFAULT_MAX_RETRIES,
default_headers: Mapping[str, str] | None = None,
default_query: Mapping[str, object] | None = None,
http_client: httpx.AsyncClient | None = None,
_strict_response_validation: bool = False,
) -> None:
...
"""1.初始化api_key、base_url"""
...
"""2.调用父类 class AsyncAPIClient(BaseClient[httpx.AsyncClient, AsyncStream[Any]]) __init__"""
super().__init__(
version=__version__,
base_url=base_url,
max_retries=max_retries,
timeout=timeout,
http_client=http_client,
custom_headers=default_headers,
custom_query=default_query,
_strict_response_validation=_strict_response_validation,
)
"""3.设置异步流AsyncStream"""
self._default_stream_cls = AsyncStream
异步流处理类AsyncStream,用于处理Server-Sent Events (SSE)格式的流式响应
class AsyncStream(Generic[_T]):
""" 提供遍历异步流响应的核心接口 """
response: httpx.Response
_decoder: SSEDecoder | SSEBytesDecoder
"""1.初始化response、client、_decoder( 流式解码器SSEDecoder) 和流式_iterator """
def __init__(
self,
*,
cast_to: type[_T],
response: httpx.Response,
client: AsyncOpenAI,
) -> None:
self.response = response
self._cast_to = cast_to
self._client = client
self._decoder = client._make_sse_decoder() """ 生成SSEDecoder() """
self._iterator = self.__stream__() """ 设置_iterator """
....
"""2.核心流处理逻辑
解析SSE事件并转换为指定类型
"""
async def __stream__(self) -> AsyncIterator[_T]:
cast_to = cast(Any, self._cast_to)
response = self.response
process_data = self._client._process_response_data
""" 设置迭代器iterator,见 _iter_events(self) """
iterator = self._iter_events()
async for sse in iterator:
if sse.data.startswith("[DONE]"): # 检查结束标记
break
...
# 特殊处理Assistants的thread.事件
if sse.event and sse.event.startswith("thread."):
# 处理数据并生成结果
yield process_data(data={"data": data, "event": sse.event},
cast_to=cast_to,
response=response)
...
else:
# 普通事件处理
data = sse.json()
...
# 处理正常数据并生成结果
yield process_data(data=data, cast_to=cast_to, response=response)
...
"""
解码并迭代SSE事件
从HTTP响应中解析Server-Sent Events
"""
async def _iter_events(self) -> AsyncIterator[ServerSentEvent]:
async for sse in self._decoder.aiter_bytes(self.response.aiter_bytes()):
yield sse
1.3 异步调用chat:处理聊天AI的响应流
async def chat(
query: str = Body(..., description="用户输入", examples=["恼羞成怒"]),
metadata: dict = Body({}, description="附件,可能是图像或者其他功能", examples=[]),
conversation_id: str = Body("", description="对话框ID"),
message_id: str = Body(None, description="数据库消息ID"),
history_len: int = Body(-1, description="从数据库中取历史消息的数量"),
stream: bool = Body(True, description="流式输出"),
chat_model_config: dict = Body({}, description="LLM 模型配置", examples=[]),
tool_config: dict = Body({}, description="工具配置", examples=[]),
use_mcp: bool = Body(False, description="使用MCP"),
max_tokens: int = Body(None, description="LLM最大token数配置", example=4096),
):
if stream:
return EventSourceResponse(chat_iterator_event())
.....
"""Agent对话聊天AI的响应,设置注解数据给SSE协议,客户端实时接收AI生成的响应内容"""
async def chat_iterator_event() -> AsyncIterable[OpenAIChatOutput]:
try:
callbacks = []
""" 根据ymal文件配置参数 动态创建LLM实例(如 OpenAI)和提示模板 """
models, prompts = create_models_from_config(
callbacks=callbacks, configs=chat_model_config, stream=stream, max_tokens=max_tokens
)
all_tools = get_tool().values()
tools = [tool for tool in all_tools if tool.name in tool_config]
tools = [t.copy(update={"callbacks": callbacks}) for t in tools]
""" 生成LangChain链full_chain, 代理器agent_executor :
见 1.3.1 生成LangChain链full_chain, 代理器agent_executor
"""
full_chain, agent_executor = create_models_chains(
prompts=prompts,
models=models,
conversation_id=conversation_id,
tools=tools,
callbacks=callbacks,
history_len=history_len,
metadata=metadata,
use_mcp = use_mcp
)
.....
""" invoke 调用链,获取响应文本 chat_iterator """
chat_iterator = full_chain.invoke({
"input": query
})
.....
""" 异步遍历AI响应流,实时处理AI生成的响应块 """
async for item in chat_iterator:
data = {}
.....
elif isinstance(item, PlatformToolsLLMStatus):
data["text"] = item.text
"""
创建OpenAI格式输出:
创建OpenAI API格式的响应对象OpenAIChatOutput;
包含ID、内容、角色、工具调用等标准字段
"""
ret = OpenAIChatOutput(
id=f"chat{uuid.uuid4()}",
object="chat.completion.chunk",
content=data.get("text", ""), """ 将AI生成的响应块data["text"] -> content """
role="assistant",
tool_calls=data["tool_calls"],
model=models["llm_model"].model_name,
status=data["status"],
message_type=data["message_type"],
message_id=message_id,
class_name=item.class_name()
)
""" AI响应数据,见 1.3.2 创建OpenAI格式输出 """
yield ret.model_dump_json()
1.3.1 生成LangChain链full_chain, 代理器agent_executor : 调用 create_models_chains
def create_models_chains(
history_len, prompts, models, tools, callbacks, conversation_id, metadata, use_mcp: bool = False
):
......
""" 设置代理器agent_executor """
agent_executor = PlatformToolsRunnable.create_agent_executor(
agent_type="platform-knowledge-mode", # 代理类型(如知识检索模式)
agents_registry=agents_registry, # 代理注册表(管理可用代理)
llm=llm, # 大语言模型实例(如GPT-4)
tools=tools, # 工具集(如搜索、计算器)
history=history, # 对话历史(支持多轮对话)
intermediate_steps=intermediate_steps, # 中间步骤记录(调试用)
mcp_connections=mcp_connections if use_mcp else {} # 多模态连接(如图像分析)
)
"""
设置链Chain
输入适配器:{"chat_input": lambda x: x["input"]} 将用户输入(如 {"input": "问题"})转换代理可识别的格式
链式组合:通过 | 操作符(LangChain的管道符)将输入适配器与代理执行器串联,形成完整处理链"
""
full_chain = {"chat_input": lambda x: x["input"]} | agent_executor
return full_chain, agent_executor
1.3.2 创建OpenAI格式输出
"""
OpenAI API输出的基础模型类
"""
class OpenAIBaseOutput(BaseModel):
""" 遵循OpenAI API标准格式 """
id: Optional[str] = None
content: Optional[str] = None
model: Optional[str] = None
object: Literal[
"chat.completion", "chat.completion.chunk"
] = "chat.completion.chunk"
role: Literal["assistant"] = "assistant"
finish_reason: Optional[str] = None
created: int = Field(default_factory=lambda: int(time.time()))
tool_calls: List[Dict] = []
status: Optional[int] = None # AgentStatus
message_type: int = MsgType.TEXT
message_id: Optional[str] = None # id in database table
is_ref: bool = False # wheather show in seperated expander
class Config:
extra = "allow"
""" 将模型转换为JSON字符串result ,result封装见 self.model_dump() """
def model_dump_json(self):
return json.dumps(self.model_dump(), ensure_ascii=False)
""" 将模型转换为字典result {},根据对象-self.object的类型封装不同结果 """
def model_dump(self) -> dict:
result = {
"id": self.id,
"object": self.object,
"model": self.model,
"created": self.created,
"status": self.status,
"message_type": self.message_type,
"message_id": self.message_id,
"is_ref": self.is_ref,
**(self.model_extra or {}),
}
if self.object == "chat.completion.chunk":
result["choices"] = [
{
"delta": {
"content": self.content,
"tool_calls": self.tool_calls,
},
"role": self.role,
}
]
elif self.object == "chat.completion":
result["choices"] = [
{
"message": {
"role": self.role,
"content": self.content,
"finish_reason": self.finish_reason,
"tool_calls": self.tool_calls,
}
}
]
return result
2.服务器向客户端推送实时数据(SSE Stream流数据)
基于 【1.接收用户AI对话请求,调用OpenAi、生成Stream流数据】 章节 最终 生成AI响应数据ret.model_dump_json()
async def chat(
query: str = Body(..., description="用户输入", examples=["恼羞成怒"]),
metadata: dict = Body({}, description="附件,可能是图像或者其他功能", examples=[]),
conversation_id: str = Body("", description="对话框ID"),
message_id: str = Body(None, description="数据库消息ID"),
history_len: int = Body(-1, description="从数据库中取历史消息的数量"),
stream: bool = Body(True, description="流式输出"),
chat_model_config: dict = Body({}, description="LLM 模型配置", examples=[]),
tool_config: dict = Body({}, description="工具配置", examples=[]),
use_mcp: bool = Body(False, description="使用MCP"),
max_tokens: int = Body(None, description="LLM最大token数配置", example=4096),
):
async def chat_iterator_event() -> AsyncIterable[OpenAIChatOutput]:
...
""" 异步遍历AI响应流,实时处理AI生成的响应块 """
async for item in chat_iterator:
...
""" AI响应数据 """
yield ret.model_dump_json()
if stream:
""" 基于ServerSentEvent Protocol:Server-Sent Events推送 生成AI响应数据
见 2.1 Server-Sent Events响应-EventSourceResponse
"""
return EventSourceResponse(chat_iterator_event())
2.1 Server-Sent Events响应-EventSourceResponse
文件see.py
"""
定义异步内容流 AsyncContentStream:
内容来源于: yield ret.model_dump_json() -> AsyncIterable[OpenAIChatOutput]
"""
AsyncContentStream = AsyncIterable[Content]
...
""" Server-Sent Events响应类:用于实现服务器向客户端推送实时数据的SSE协议 """
class EventSourceResponse(Response):
# 定义内容迭代器body_iterator
body_iterator: AsyncContentStream
...
def __init__(
self,
content: ContentStream,
status_code: int = 200,
headers: Optional[Mapping[str, str]] = None,
media_type: str = "text/event-stream",
background: Optional[BackgroundTask] = None,
ping: Optional[int] = None,
sep: Optional[str] = None,
ping_message_factory: Optional[Callable[[], ServerSentEvent]] = None,
data_sender_callable: Optional[
Callable[[], Coroutine[None, None, None]]
] = None,
) -> None:
...
# 设置内容迭代器body_iterator
if isinstance(content, AsyncIterable):
self.body_iterator = content
...
""" Server-Sent Events触发时,调用__call__ -> 设置 self.stream_response """
async def __call__(self, scope: Scope, receive: Receive, send: Send) -> None:
""" anyio.create_task_group() 管理多个并发任务 """
async with anyio.create_task_group() as task_group:
...
""" 流式发送响应数据 """
task_group.start_soon(wrap, partial(self.stream_response, send))
""" 定期发送ping消息保持连接 """
task_group.start_soon(wrap, partial(self._ping, send))
task_group.start_soon(wrap, self.listen_for_exit_signal)
if self.data_sender_callable:
task_group.start_soon(self.data_sender_callable)
""" 监听客户端断开连接 """
await wrap(partial(self.listen_for_disconnect, receive))
if self.background is not None:
await self.background()
...
""" 流式发送响应数据 """
async def stream_response(self, send: Send) -> None:
# 基于SSE第1次发送send响应请求头headers
await send(
{
"type": "http.response.start",
"status": self.status_code,
"headers": self.raw_headers,
}
)
async for data in self.body_iterator:
# 遍历响应数据data并进行序列化+分块
chunk = ensure_bytes(data, self.sep)
# 响应数据data解码,输出log
_log.debug(f"chunk: {chunk.decode()}")
# 基于SSE第2次发送send响应body体数据data
await send({"type": "http.response.body", "body": chunk, "more_body": True})
async with self._send_lock:
self.active = False
await send({"type": "http.response.body", "body": b"", "more_body": False})

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)