基于Spring AI的业务数据NER增强混合检索RAG系统
本文提出了一种基于Spring AI的业务数据NER增强混合检索RAG系统架构。该系统采用"向量化→检索→生成"三阶段流程,核心特点包括: 采用Elasticsearch双索引设计,分别存储原始数据和向量化数据 实现多字段向量化(标题、作者、期刊名称),避免信息污染并提升检索精度 结合NER实体识别与意图理解,构建混合检索查询(精确匹配+向量检索) 使用GLM-4-Flash模
基于Spring AI的业务数据NER增强混合检索RAG系统
目录
一、总体架构思路
在构建 RAG(Retrieval-Augmented Generation,检索增强生成)系统时,大模型与业务数据的集成通常遵循"向量化 → 检索 → 生成"的三阶段流程。本文基于实际生产项目(学术文献智能检索系统)的实践经验,详细阐述各阶段的核心技术选型与实现策略。
1.1 整体数据流架构
架构说明:
-
Elasticsearch 双索引设计
- 原始索引(
cqu_dev_journal_thesis_v1):存储原始论文数据,只读,作为向量化的数据源 - 向量索引(
cqu_dev_journal_thesis_vector_v1):包含原始数据 + 三个向量字段,用于检索
- 原始索引(
-
MySQL 数据库
- 与 Elasticsearch 向量数据无直接关系
- 仅用于存储问答历史记录(
qa_history表) - 支持历史上下文查询,用于 NER 的指代消解
-
数据流转过程
- 向量化阶段:原始索引 → 向量化服务 → 向量索引
- 检索阶段:用户查询 → NER + 向量化 → 混合检索 → Top-K 文档
- 生成阶段:检索结果 + 用户问题 → LLM → 流式答案
1.2 核心技术栈
| 层级 | 技术选型 | 说明 |
|---|---|---|
| AI 框架 | Spring AI 1.0.0 | Spring 官方的 AI 集成框架 |
| 大语言模型 | 智谱 AI GLM-4-Flash | NER + 对话生成(支持 Function Calling) |
| Embedding 模型 | gte-multilingual-base | 本地部署,768 维向量,支持中英文 |
| 向量数据库 | Elasticsearch 8.x | 同时支持向量检索(kNN)和全文检索(BM25) |
| 关系数据库 | MySQL 8.0 + MyBatis Plus | 存储问答历史和元数据 |
| 开发框架 | Spring Boot 3.5.7 + Java 17 | 现代化的 Spring 生态 |
1.3 索引设计详解
原始索引(source-index)
索引名称: cqu_dev_journal_thesis_v1
用途: 只读数据源,存储原始论文数据
字段结构:
{
"sid": "唯一标识",
"title": "论文标题",
"author": ["作者1", "作者2"],
"journalName": "期刊名称",
"year": 2024,
"doi": "10.xxxx/xxxx",
"issn": "1000-9825",
"topic": ["主题词1", "主题词2"],
...
}
向量索引(vector-index)
索引名称: cqu_dev_journal_thesis_vector_v1
用途: 包含原始数据 + 向量字段,用于混合检索
映射定义:
{
"mappings": {
"properties": {
"sid": { "type": "keyword" },
"title": { "type": "text", "analyzer": "ik_max_word" },
"author": { "type": "keyword" },
"journalName": { "type": "text", "analyzer": "ik_smart" },
"year": { "type": "integer" },
"doi": { "type": "keyword" },
"issn": { "type": "keyword" },
"topic": { "type": "keyword" },
"titleVector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
},
"authorVector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
},
"journalNameVector": {
"type": "dense_vector",
"dims": 768,
"index": true,
"similarity": "cosine"
}
}
}
}
向量字段说明:
titleVector:标题文本的向量表示(权重最高)authorVector:作者姓名的向量表示(用于作者检索)journalNameVector:期刊名称的向量表示(用于期刊筛选)
二、数据准备阶段:向量化工程
2.1 为什么需要多字段向量化?
对于结构化业务数据(如学术论文、商品信息、用户档案),传统的"全文拼接向量化"存在以下问题:
问题 1:信息污染
- 将所有字段拼接成一段文本(如
title + author + journal)会导致不同字段的语义相互干扰 - 例如:“深度学习 张三 计算机学报” 无法区分哪个是标题、哪个是作者
问题 2:检索精度低
- 用户查询"张三的论文"时,希望作者字段权重更高
- 用户查询"深度学习相关论文"时,希望标题字段权重更高
- 单一向量无法实现不同字段的差异化权重
解决方案:多字段向量化 + 加权检索
为核心字段(如标题、作者、期刊名称)分别生成向量,检索时根据查询类型动态调整权重。
2.2 向量化流程设计
配置信息(application.yml):
app:
elasticsearch:
# 原始索引(只读,用于读取现有数据)
source-index: cqu_dev_journal_thesis_v1
# 向量索引(包含向量数据)
vector-index: cqu_dev_journal_thesis_vector_v1
# 向量维度(gte-multilingual-base 模型)
vector-dimension: 768
# 批量处理大小
batch-size: 100
# 本地 Embedding 服务 URL
embedding-service-url: http://192.168.0.168:5000
向量化流程:
1. 从原始索引读取一批数据(batch-size=100)
↓
2. 提取三个字段的文本
- titleTexts: ["论文标题1", "论文标题2", ...]
- authorTexts: ["张三, 李四", "王五", ...]
- journalTexts: ["计算机学报", "软件学报", ...]
↓
3. 批量调用 Embedding 服务(并行处理)
- embedTexts(titleTexts) → titleVectors
- embedTexts(authorTexts) → authorVectors
- embedTexts(journalTexts) → journalVectors
↓
4. 将向量赋值到文档对象
doc.setTitleVector(titleVectors[i])
doc.setAuthorVector(authorVectors[i])
doc.setJournalNameVector(journalVectors[i])
↓
5. 批量写入向量索引(Bulk API)
↓
6. 继续下一批数据(支持断点续传)
2.3 核心实现代码
文件位置: DocumentVectorizationService.java:50-214
/**
* 批量向量化论文数据
* 从原始索引读取数据,为标题、作者、期刊三个字段分别生成向量,写入向量索引
*/
public VectorizationResult vectorizeDocuments(int startIndex, int size) {
String sourceIndex = appConfig.getSourceIndex(); // cqu_dev_journal_thesis_v1
String vectorIndex = appConfig.getVectorIndex(); // cqu_dev_journal_thesis_vector_v1
int batchSize = appConfig.getBatchSize(); // 100
log.info("[批量向量化] 开始,原始索引: {}, 向量索引: {}, 起始位置: {}, 数量: {}, 批次大小: {}",
sourceIndex, vectorIndex, startIndex, size, batchSize);
VectorizationResult result = new VectorizationResult();
int processedCount = 0;
int successCount = 0;
try {
int currentFrom = startIndex;
boolean hasMore = true;
while (hasMore) {
// 计算本批次读取数量
final int currentSize;
if (size > 0) {
int remaining = size - processedCount;
if (remaining <= 0) break;
currentSize = Math.min(batchSize, remaining);
} else {
currentSize = batchSize;
}
// 1. 从原始索引读取一批数据
log.info("[读取数据] 第 {} 批,从位置 {} 开始,数量 {}",
processedCount / batchSize + 1, currentFrom, currentSize);
SearchResponse<JournalThesis> searchResponse = elasticsearchClient.search(s -> s
.index(sourceIndex)
.query(q -> q.matchAll(m -> m))
.from(currentFrom)
.size(currentSize)
.source(src -> src.fetch(true)),
JournalThesis.class
);
List<Hit<JournalThesis>> hits = searchResponse.hits().hits();
if (hits.isEmpty()) {
log.info("[读取数据] 没有更多数据");
break;
}
log.info("[读取数据] 成功读取 {} 条论文数据", hits.size());
// 2. 准备三个字段的文本列表
List<String> titleTexts = new ArrayList<>();
List<String> authorTexts = new ArrayList<>();
List<String> journalNameTexts = new ArrayList<>();
List<JournalThesisVector> vectorDocuments = new ArrayList<>();
for (Hit<JournalThesis> hit : hits) {
try {
JournalThesis thesis = hit.source();
if (thesis == null) {
log.warn("[数据解析] 文档 {} 数据为空,跳过", hit.id());
continue;
}
// 转换为向量文档对象
JournalThesisVector vectorDoc = JournalThesisVector.fromJournalThesis(thesis);
vectorDocuments.add(vectorDoc);
// 收集三个字段的文本
titleTexts.add(vectorDoc.getTitle() != null ? vectorDoc.getTitle() : "");
String authorStr = "";
if (vectorDoc.getAuthor() != null && vectorDoc.getAuthor().length > 0) {
authorStr = String.join(", ", vectorDoc.getAuthor());
}
authorTexts.add(authorStr);
journalNameTexts.add(vectorDoc.getJournalName() != null ? vectorDoc.getJournalName() : "");
} catch (Exception e) {
log.error("[数据解析] 文档解析失败: {}", hit.id(), e);
}
}
// 3. 批量生成三字段向量(并行调用 Embedding 服务)
log.info("[生成向量] 开始为 {} 个文档生成三字段向量(title, author, journalName)",
vectorDocuments.size());
List<float[]> titleVectors = embeddingService.embedTexts(titleTexts);
log.info("[生成向量] 标题向量生成完成,共 {} 个",
titleVectors != null ? titleVectors.size() : 0);
List<float[]> authorVectors = embeddingService.embedTexts(authorTexts);
log.info("[生成向量] 作者向量生成完成,共 {} 个",
authorVectors != null ? authorVectors.size() : 0);
List<float[]> journalNameVectors = embeddingService.embedTexts(journalNameTexts);
log.info("[生成向量] 期刊名称向量生成完成,共 {} 个",
journalNameVectors != null ? journalNameVectors.size() : 0);
// 4. 将向量赋值到文档对象
if (titleVectors == null || authorVectors == null || journalNameVectors == null) {
log.error("[生成向量] 失败,返回的向量列表为空");
} else {
for (int i = 0; i < vectorDocuments.size(); i++) {
JournalThesisVector doc = vectorDocuments.get(i);
if (i < titleVectors.size() && titleVectors.get(i) != null) {
doc.setTitleVector(titleVectors.get(i));
}
if (i < authorVectors.size() && authorVectors.get(i) != null) {
doc.setAuthorVector(authorVectors.get(i));
}
if (i < journalNameVectors.size() && journalNameVectors.get(i) != null) {
doc.setJournalNameVector(journalNameVectors.get(i));
}
}
}
// 5. 批量写入向量索引
log.info("[写入索引] 开始批量写入向量索引");
int written = bulkIndexVectorDocuments(vectorIndex, vectorDocuments);
successCount += written;
processedCount += hits.size();
log.info("[批次完成] 已处理: {}, 成功: {}", processedCount, successCount);
currentFrom += currentSize;
if (hits.size() < currentSize) hasMore = false;
}
result.setSuccess(true);
result.setProcessedCount(processedCount);
result.setSuccessCount(successCount);
log.info("[批量向量化] 完成,总计处理: {}, 成功: {}", processedCount, successCount);
} catch (Exception e) {
log.error("[批量向量化] 失败", e);
result.setSuccess(false);
result.setMessage("向量化失败: " + e.getMessage());
}
return result;
}
2.4 Embedding 服务封装
文件位置: EmbeddingService.java:72-152
服务配置:
- 模型:gte-multilingual-base(支持中英文混合)
- 向量维度:768
- 部署方式:本地 HTTP 服务(http://192.168.0.168:5000)
- API 端点:
/embed_batch
核心实现:
/**
* 批量文本向量化(支持自动重试)
*/
public List<float[]> embedTexts(List<String> texts) {
if (texts == null || texts.isEmpty()) {
return new ArrayList<>();
}
int maxRetries = 3;
int retryDelay = 1000; // 初始延迟 1 秒
for (int attempt = 1; attempt <= maxRetries; attempt++) {
try {
String url = appConfig.getEmbeddingServiceUrl() + "/embed_batch";
log.info("[向量化] 调用 Embedding 服务: {}, 文本数量: {}, 尝试 {}/{}",
url, texts.size(), attempt, maxRetries);
// 构建请求
Map<String, Object> requestBody = Map.of("texts", texts);
HttpHeaders headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
headers.set("Connection", "keep-alive");
HttpEntity<Map<String, Object>> request = new HttpEntity<>(requestBody, headers);
// 发送 POST 请求
ResponseEntity<EmbedBatchResponse> response = restTemplate.postForEntity(
url, request, EmbedBatchResponse.class
);
EmbedBatchResponse body = response.getBody();
if (body == null || body.getEmbeddings() == null) {
throw new RuntimeException("Embedding 服务返回结果为空");
}
log.info("[向量化] 成功,返回 {} 个向量,维度: {}", body.getCount(), body.getDimension());
// 将 List<List<Double>> 转换为 List<float[]>
List<float[]> result = new ArrayList<>();
for (List<Double> embedding : body.getEmbeddings()) {
float[] floatArray = new float[embedding.size()];
for (int i = 0; i < embedding.size(); i++) {
floatArray[i] = embedding.get(i).floatValue();
}
result.add(floatArray);
}
return result;
} catch (ResourceAccessException e) {
if (attempt == maxRetries) {
throw new RuntimeException("Embedding 服务连接失败(已重试 " + maxRetries + " 次): " +
e.getMessage() + "。请检查服务是否运行:" + appConfig.getEmbeddingServiceUrl(), e);
}
log.warn("[向量化] 第 {} 次尝试失败,{}ms 后重试: {}", attempt, retryDelay, e.getMessage());
try {
Thread.sleep(retryDelay);
retryDelay *= 2; // 指数退避策略
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
throw new RuntimeException("重试被中断", ie);
}
} catch (Exception e) {
log.error("[向量化] 失败,文本数量: {}", texts.size(), e);
throw new RuntimeException("批量文本向量化失败: " + e.getMessage(), e);
}
}
throw new RuntimeException("Embedding 服务调用失败:未知错误");
}
三、智能检索阶段:NER 增强的混合 RAG
3.1 为什么需要 NER 增强检索?
传统的纯向量检索存在以下局限:
纯向量检索的三大缺陷
| 问题 | 示例 | 影响 |
|---|---|---|
| 语义漂移 | "张三的论文"和"李四的论文"向量相似度很高,但查询意图完全不同 | 精确度低 |
| 实体缺失 | 无法精确匹配关键实体(如作者名、期刊名、年份) | 召回质量差 |
| 意图模糊 | 无法区分"查找论文"(需要检索)和"分析主题"(需要总结) | 处理策略错误 |
NER 增强检索的优势
【传统向量检索】
用户查询:"查找张三在计算机学报发表的关于深度学习的论文"
↓ 直接向量化
问题向量:[0.12, -0.34, ..., 0.56]
↓ 余弦相似度检索
结果:可能召回"李四在软件学报发表的机器学习论文"(语义相似但实体不匹配)
【NER 增强检索】
用户查询:"查找张三在计算机学报发表的关于深度学习的论文"
↓ NER 提取
实体:AUTHOR=张三, JOURNAL=计算机学报, TITLE=深度学习
↓ 构建混合查询(精确匹配 + 向量检索)
结果:只召回"张三"在"计算机学报"发表的"深度学习"相关论文(精确度 100%)
3.2 实现方案对比
| 方案 | 适用场景 | 召回率 | 精确率 | 实现复杂度 |
|---|---|---|---|---|
| 混合检索(NER + 向量) | 需要精确匹配实体的场景(学术检索、电商搜索、法律检索) | 很高 | 很高 | 高 |
| 查询增强(Query Expansion) | 用户问题较短或不清晰(客服问答、FAQ) | 高 | 中等 | 中 |
| 元数据过滤(Metadata Filtering) | 数据有明确分类体系(分类、标签、时间范围) | 高 | 高 | 低 |
| 纯向量检索 | 通用语义匹配场景(开放域问答、文档摘要) | 中等 | 中等 | 低 |
| 关键词检索(BM25) | 精确匹配场景(代码搜索、日志查询) | 低 | 高 | 低 |
本项目选择:混合检索(NER + 向量)
理由:
- 学术检索场景对精确度要求极高(必须匹配作者名、期刊名)
- 语义理解同样重要("深度学习"可能对应多种表述)
- 支持复杂查询(多条件组合)
3.3 NER 增强混合检索完整流程
步骤 1:NER 实体提取 + 意图识别
文件位置: NerService.java:110-157
System Prompt 设计(核心):
private static final String SYSTEM_PROMPT = """
你是一个面向学术检索的专业 NER 助手,负责从用户查询中提取实体、识别意图。
【实体类型】只能使用以下四类:
- AUTHOR:作者姓名(中英文人名)
- JOURNAL:期刊名称
- TITLE:论文标题、研究主题、技术术语(视为检索题名,不拆分)
- YEAR:具体年份(用逗号分隔,如 "2023,2024,2025")
除以上四类外,不得使用任何其他类型。
【YEAR 规则】将相对时间转换为具体年份(基于当前年份,如 2025):
- 最近/过去/近 1 年 → 2024
- 最近/过去/近 2 年 → 2024,2025
- 最近/过去/近 3 年、最近几年 → 2023,2024,2025
- 最近/过去/近 5 年 → 2021–2025
- 范围如 2020–2023 → 展开成 2020,2021,2022,2023
- 单一年份保持不变
YEAR 的 value 禁止出现文字,只能是年份数字列表。
【TITLE 规则】
1. 引号中的内容视为完整标题
2. "关于/有关/涉及 XX"中的 XX 视为 TITLE
3. 技术术语、研究方向均视为 TITLE(如"深度学习""区块链")
4. 当出现"作者 X""期刊 X"时,其余主体内容作为 TITLE
5. 不拆分完整标题或主题
【意图类型】
- SEARCH_PAPER:查找论文/文献(出现"论文""文章""文献""查找"等)
- TOPIC_ANALYSIS:介绍、解释、分析某主题(出现"介绍""分析""现状""趋势""是什么"等)
- UNKNOWN:无法判断
【置信度参考】
- 0.9–1.0:明确实体(引号、人名、期刊)
- 0.7–0.9:技术术语、常见主题
- 0.5–0.7:可疑实体
【输出格式】JSON:
{
"entities": [
{"type": "AUTHOR", "value": "张三", "confidence": 0.95},
{"type": "JOURNAL", "value": "计算机学报", "confidence": 0.90},
{"type": "TITLE", "value": "深度学习", "confidence": 0.85},
{"type": "YEAR", "value": "2023,2024,2025", "confidence": 0.90}
],
"intent": "SEARCH_PAPER"
}
""";
User Prompt 构建(支持历史上下文):
private String buildNerPromptWithHistory(String text, List<QaHistory> historyContext) {
StringBuilder prompt = new StringBuilder();
int currentYear = Year.now().getValue();
prompt.append("【当前年份】\n").append(currentYear).append("年\n\n");
// 拼接历史对话上下文(最近 3 条),用于指代消解
if (historyContext != null && !historyContext.isEmpty()) {
prompt.append("【历史对话上下文】(用于辅助理解当前问题)\n");
historyContext.stream()
.sorted(Comparator.comparing(QaHistory::getCreatedAt))
.limit(3)
.forEach(h -> prompt.append("用户问题: ").append(h.getQuestion()).append("\n"));
prompt.append("\n");
}
// 当前问题
prompt.append("【当前问题】(需要从这里提取实体和识别意图)\n");
prompt.append(text).append("\n\n");
// 要求说明
prompt.append("""
要求:
1. 必须提取所有相关实体(作者、期刊、题名、年份等)
2. 对每个实体给出合理的置信度(0.0-1.0)
3. 识别用户的主要查询意图
4. 如果提取到 YEAR 类型且使用了相对时间,必须转换为具体年份数字(逗号分隔)
5. 如果历史对话中的信息与当前问题有关联,应综合考虑提取实体
请使用 JSON 格式返回结果。
""");
return prompt.toString();
}
实体提取示例:
输入:"查找张三在计算机学报发表的关于深度学习的最近三年论文"
输出:
{
"entities": [
{"type": "AUTHOR", "value": "张三", "confidence": 0.95},
{"type": "JOURNAL", "value": "计算机学报", "confidence": 0.90},
{"type": "TITLE", "value": "深度学习", "confidence": 0.85},
{"type": "YEAR", "value": "2023,2024,2025", "confidence": 0.90}
],
"intent": "SEARCH_PAPER"
}
历史上下文的作用(指代消解):
第一次对话:
用户:"查找张三的论文"
NER 提取:AUTHOR=张三
第二次对话:
用户:"他最近三年的论文呢?"
历史上下文:["查找张三的论文"]
NER 提取:AUTHOR=张三(从历史推断), YEAR=2023,2024,2025
步骤 2:根据意图选择处理器(策略模式)
文件位置: RagService.java:62-97
/**
* 意图驱动的流式问答(策略模式,零 if-else)
*/
public void askStreamWithNer(String question,
List<QaHistory> historyContext,
Consumer<List<RetrievedDocument>> onRetrievedDocuments,
Consumer<String> onAnswerChunk,
Consumer<Exception> onError) {
try {
// 1. 基于历史上下文进行 NER 提取实体和意图
NerResult nerResult = nerService.recognize(question, historyContext);
log.info("提取到 {} 个实体,意图: {}",
nerResult.getEntities().size(), nerResult.getQueryIntent().getDisplayName());
// 2. 根据意图选择处理器(策略模式)
IntentHandler handler = intentHandlerFactory.getHandler(nerResult.getQueryIntent());
log.info("使用 {} 处理器", handler.getClass().getSimpleName());
// 3. 使用意图处理器进行流式处理
handler.handleStream(question, nerResult, historyContext,
onRetrievedDocuments, onAnswerChunk, onError);
} catch (Exception e) {
log.error("[意图驱动RAG] 失败", e);
if (onError != null) {
onError.accept(e);
}
}
}
意图处理器映射:
| 意图类型 | 处理器类 | 处理逻辑 |
|---|---|---|
| SEARCH_PAPER | SearchPaperIntentHandler | 执行混合检索,返回相关论文 + 生成总结 |
| TOPIC_ANALYSIS | TopicAnalysisIntentHandler | 直接调用 LLM 进行主题分析(可选检索) |
| UNKNOWN | DefaultIntentHandler | 兜底处理器,尝试理解用户意图 |
步骤 3:构建 Elasticsearch 混合查询
核心查询逻辑(SearchPaperIntentHandler):
/**
* 构建 NER 增强的混合查询
* 结合实体精确匹配 + 向量语义检索
*/
private Query buildHybridQuery(NerResult nerResult, float[] questionVector) {
List<Query> shouldQueries = new ArrayList<>();
// 1. 精确匹配实体(使用 terms 查询)
List<String> authors = nerResult.getAuthors();
if (!authors.isEmpty()) {
shouldQueries.add(Query.of(q -> q
.terms(t -> t.field("author").terms(ts -> ts.value(
authors.stream().map(FieldValue::of).collect(Collectors.toList())
)))
));
}
List<String> journals = nerResult.getJournals();
if (!journals.isEmpty()) {
shouldQueries.add(Query.of(q -> q
.terms(t -> t.field("journalName").terms(ts -> ts.value(
journals.stream().map(FieldValue::of).collect(Collectors.toList())
)))
));
}
List<Integer> years = nerResult.getParsedYears();
if (!years.isEmpty()) {
shouldQueries.add(Query.of(q -> q
.terms(t -> t.field("year").terms(ts -> ts.value(
years.stream().map(y -> FieldValue.of((long) y)).collect(Collectors.toList())
)))
));
}
// 2. 向量相似度检索(标题、作者、期刊三字段加权)
List<Float> vectorList = toFloatList(questionVector);
// 标题向量(权重最高 5.0)
shouldQueries.add(Query.of(q -> q
.knn(knn -> knn
.field("titleVector")
.queryVector(vectorList)
.k(20)
.numCandidates(100)
.boost(5.0f)
)
));
// 作者向量(权重 3.0)
shouldQueries.add(Query.of(q -> q
.knn(knn -> knn
.field("authorVector")
.queryVector(vectorList)
.k(20)
.numCandidates(100)
.boost(3.0f)
)
));
// 期刊名称向量(权重 2.0)
shouldQueries.add(Query.of(q -> q
.knn(knn -> knn
.field("journalNameVector")
.queryVector(vectorList)
.k(20)
.numCandidates(100)
.boost(2.0f)
)
));
// 3. 组合查询(Bool Query)
return Query.of(q -> q
.bool(b -> b
.should(shouldQueries)
.minimumShouldMatch("1") // 至少匹配 1 个条件
)
);
}
生成的 Elasticsearch 查询示例:
{
"query": {
"bool": {
"should": [
{
"terms": {
"author": ["张三"]
}
},
{
"terms": {
"journalName": ["计算机学报"]
}
},
{
"terms": {
"year": [2023, 2024, 2025]
}
},
{
"knn": {
"field": "titleVector",
"query_vector": [0.12, -0.34, ..., 0.56],
"k": 20,
"num_candidates": 100,
"boost": 5.0
}
},
{
"knn": {
"field": "authorVector",
"query_vector": [0.12, -0.34, ..., 0.56],
"k": 20,
"num_candidates": 100,
"boost": 3.0
}
},
{
"knn": {
"field": "journalNameVector",
"query_vector": [0.12, -0.34, ..., 0.56],
"k": 20,
"num_candidates": 100,
"boost": 2.0
}
}
],
"minimum_should_match": 1
}
},
"size": 5
}
查询参数说明:
k: 返回最相似的 K 个文档(设置为 20)num_candidates: 候选文档数量(设置为 100,通常为 k 的 5-10 倍)boost: 权重提升因子(标题 5.0 > 作者 3.0 > 期刊 2.0)minimum_should_match: 至少匹配 1 个条件(可调整为 2 或 3 提高精确度)
步骤 4:执行检索并返回 Top-K 文档
/**
* 执行混合检索
*/
private List<RetrievedDocument> executeHybridSearch(Query query, int topK) throws IOException {
SearchResponse<JournalThesisVector> response = elasticsearchClient.search(s -> s
.index(appConfig.getVectorIndex()) // 查询向量索引
.query(query)
.size(topK)
.trackTotalHits(t -> t.enabled(true)),
JournalThesisVector.class
);
return response.hits().hits().stream()
.map(hit -> {
JournalThesisVector source = hit.source();
RetrievedDocument doc = new RetrievedDocument();
doc.setId(source.getSid());
doc.setTitle(source.getTitle());
doc.setAuthor(source.getAuthor());
doc.setJournalName(source.getJournalName());
doc.setYear(source.getYear());
doc.setScore(hit.score()); // 相关性得分
return doc;
})
.collect(Collectors.toList());
}
3.4 NER 工具选择与对比
方案对比表
| 方案 | 优点 | 缺点 | 延迟 | 成本 | 适用场景 |
|---|---|---|---|---|---|
| LLM-based NER(GLM-4/Qwen/Claude) | 灵活、无需训练,支持自定义实体类型;上下文理解能力强;支持指代消解 | 成本较高,响应延迟较大 | 约 500ms | 高 | 实体类型灵活、准确率要求高 |
| 传统 NER 模型(LAC、HanLP) | 推理速度快,部署成本低 | 需要标注数据训练,泛化能力弱;难以处理新实体类型 | 约 50ms | 低 | 实体类型固定、性能敏感 |
| BERT-based NER | 准确率高,支持迁移学习 | 需要 GPU 推理,模型维护成本高 | 约 100ms | 中 | 中等规模数据集,平衡准确率和性能 |
| 规则 + 词典匹配 | 实现简单,速度极快 | 覆盖度差,维护困难 | 约 10ms | 低 | 实体数量有限、固定模式 |
本项目选择:LLM-based NER(智谱 AI GLM-4-Flash)
选择理由:
- 灵活性:支持自定义实体类型(AUTHOR、JOURNAL、TITLE、YEAR),无需训练
- 准确率:上下文理解能力强,可处理复杂查询(如"他的最近三年论文")
- 意图识别:一次调用同时完成实体提取和意图分类
- 快速迭代:修改 Prompt 即可调整规则,无需重新训练模型
成本优化策略:
- 使用轻量级模型(GLM-4-Flash,而非 GLM-4)
- 缓存常见查询的 NER 结果(Redis)
- 批量处理历史查询,预计算实体
3.5 实战经验与关键技巧
最佳实践
1. 历史上下文利用
// 示例:指代消解
// 用户第一次问:"查找张三的论文"
// 用户第二次问:"他最近三年的论文呢?"
// 通过传入历史上下文,NER 可以将"他"解析为"张三"
NerResult result = nerService.recognize(currentQuestion, historyContext);
2. 年份归一化
// 将"最近三年"转换为具体年份列表 "2023,2024,2025"
// 在 Prompt 中明确当前年份(2025 年)
// LLM 会自动计算并返回具体年份
3. 置信度过滤
// 过滤低置信度实体(< 0.5)
List<Entity> highConfidenceEntities = nerResult.getEntities().stream()
.filter(entity -> entity.getConfidence() >= 0.5)
.collect(Collectors.toList());
4. 向量检索权重调优
// 根据业务场景调整不同字段的权重
// 论文检索:title (5.0) > author (3.0) > journal (2.0)
// 作者检索:author (5.0) > title (2.0) > journal (2.0)
四、LLM 推理阶段:上下文增强的答案生成
4.1 Prompt 工程:构建高质量上下文
核心原则:
- 明确角色定位:告诉 LLM “你是一个学术检索助手”
- 提供结构化上下文:将检索到的文档格式化为清晰的列表
- 约束输出范围:强调"仅基于提供的文档回答",避免幻觉
- 流式输出:使用 SSE 实现打字机效果,提升用户体验
示例 Prompt 设计:
private String buildRagPrompt(String question, List<RetrievedDocument> documents) {
StringBuilder prompt = new StringBuilder();
prompt.append("你是一个专业的学术文献检索助手。\n\n");
prompt.append("【用户问题】\n");
prompt.append(question).append("\n\n");
prompt.append("【检索到的相关论文】\n");
for (int i = 0; i < documents.size(); i++) {
RetrievedDocument doc = documents.get(i);
prompt.append(String.format("%d. 论文标题:%s\n", i + 1, doc.getTitle()));
prompt.append(String.format(" 作者:%s\n", String.join(", ", doc.getAuthor())));
prompt.append(String.format(" 期刊:%s\n", doc.getJournalName()));
prompt.append(String.format(" 年份:%s\n", doc.getYear()));
prompt.append(String.format(" 相关性得分:%.2f\n", doc.getScore()));
prompt.append("\n");
}
prompt.append("【回答要求】\n");
prompt.append("1. 仅基于上述检索到的论文信息回答用户问题\n");
prompt.append("2. 如果检索结果无法回答问题,请明确告知用户\n");
prompt.append("3. 使用简洁、专业的语言,避免冗长\n");
prompt.append("4. 如果用户问到数量,请准确统计\n");
return prompt.toString();
}
4.2 流式输出实现(SSE)
文件位置: SearchPaperIntentHandler.java
/**
* 流式生成答案(Server-Sent Events)
*/
private void streamAnswer(String question,
List<RetrievedDocument> documents,
Consumer<String> onAnswerChunk) {
// 构建 RAG Prompt
String prompt = buildRagPrompt(question, documents);
// 使用 Spring AI 的流式 API
chatClient.prompt()
.user(prompt)
.stream()
.content()
.subscribe(
chunk -> {
// 每收到一个 token,立即回调给前端
if (onAnswerChunk != null) {
onAnswerChunk.accept(chunk);
}
},
error -> log.error("流式生成失败", error),
() -> log.info("流式生成完成")
);
}
Controller 层 SSE 实现:
@GetMapping(value = "/ask-stream", produces = MediaType.TEXT_EVENT_STREAM_VALUE)
public SseEmitter askStream(@RequestParam String question) {
SseEmitter emitter = new SseEmitter(300000L); // 5 分钟超时
CompletableFuture.runAsync(() -> {
try {
// 获取历史上下文
List<QaHistory> historyContext = qaHistoryService.getRecentHistory(userId, 3);
ragService.askStreamWithNer(
question,
historyContext,
// 检索到文档时回调
documents -> {
try {
emitter.send(SseEmitter.event()
.name("documents")
.data(documents));
} catch (IOException e) {
log.error("发送文档列表失败", e);
}
},
// 答案片段回调
chunk -> {
try {
emitter.send(SseEmitter.event()
.name("answer")
.data(chunk));
} catch (IOException e) {
log.error("发送答案片段失败", e);
}
},
// 错误回调
error -> {
try {
emitter.send(SseEmitter.event()
.name("error")
.data(error.getMessage()));
emitter.completeWithError(error);
} catch (IOException e) {
log.error("发送错误信息失败", e);
}
}
);
// 完成流式传输
emitter.send(SseEmitter.event().name("done").data("[DONE]"));
emitter.complete();
} catch (Exception e) {
log.error("流式问答失败", e);
emitter.completeWithError(e);
}
});
return emitter;
}
前端 SSE 接收示例(JavaScript):
const eventSource = new EventSource('/api/rag/ask-stream?question=' + encodeURIComponent(question));
eventSource.addEventListener('documents', (event) => {
// 收到检索到的文档
const documents = JSON.parse(event.data);
displayDocuments(documents);
});
eventSource.addEventListener('answer', (event) => {
// 收到答案片段(逐字显示)
const chunk = event.data;
appendAnswerChunk(chunk);
});
eventSource.addEventListener('error', (event) => {
// 处理错误
console.error('SSE error:', event);
eventSource.close();
});
eventSource.addEventListener('done', () => {
// 答案生成完成
eventSource.close();
});
4.3 幻觉抑制技巧
问题: LLM 容易编造不存在的信息(如虚构论文标题、作者)
解决方案:
1. 在 Prompt 中明确约束
重要:你只能基于【检索到的相关论文】中的信息回答问题。
如果检索结果无法回答问题,请回复:"抱歉,检索到的论文中没有相关信息。"
禁止编造任何论文信息。
2. 后处理验证
// 检查生成的答案中提到的论文是否在检索结果中
boolean isValid = validateAnswerAgainstDocuments(answer, documents);
if (!isValid) {
log.warn("检测到幻觉内容,拒绝输出");
return "检索结果中没有相关信息。";
}
3. 引用机制
// 在答案中添加引用标记 [1]、[2]
String answerWithCitations = addCitations(answer, documents);
// 输出示例:
// "根据检索结果,张三在2024年发表了《深度学习综述》[1],该论文..."
4.4 实战经验与优化策略
最佳实践
1. 上下文长度控制
- 检索 Top 20 文档,但只传递 Top 5 给 LLM(降低成本和延迟)
- 每篇文档只保留关键字段(标题、作者、期刊、年份),去除摘要和全文
2. 流式输出优化
- 首先返回检索到的文档列表(让用户立即看到结果)
- 然后开始流式生成答案(提升体验)
3. 错误降级
try {
streamAnswer(question, documents, onAnswerChunk);
} catch (Exception e) {
// 如果 LLM 调用失败,至少返回检索到的文档
log.error("LLM 生成失败,降级为纯检索模式", e);
onAnswerChunk.accept("检索到以下相关论文:\n" + formatDocuments(documents));
}
五、完整实战案例
案例:学术文献智能检索系统
需求: 用户输入自然语言查询,系统返回相关论文并生成总结性回答。
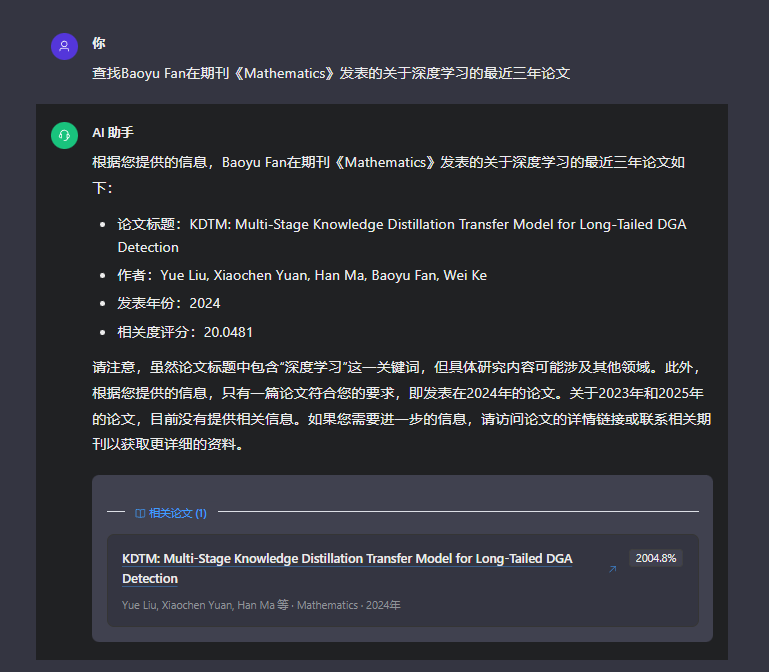
示例查询:“查找Baoyu Fan在期刊《Mathematics》发表的关于深度学习的最近三年论文”
步骤 1、NER 实体提取
输出:
{
"originalText" : "查找张三在计算机学报发表的关于深度学习的最近三年论文",
"entities" : [ {
"type" : "AUTHOR",
"value" : "张三",
"confidence" : 0.95
}, {
"type" : "JOURNAL",
"value" : "计算机学报",
"confidence" : 0.9
}, {
"type" : "TITLE",
"value" : "深度学习",
"confidence" : 0.85
}, {
"type" : "YEAR",
"value" : "2022",
"confidence" : 0.9
}, {
"type" : "YEAR",
"value" : "2023",
"confidence" : 0.9
}, {
"type" : "YEAR",
"value" : "2024",
"confidence" : 0.9
} ],
"intent" : "SEARCH_PAPER"
}
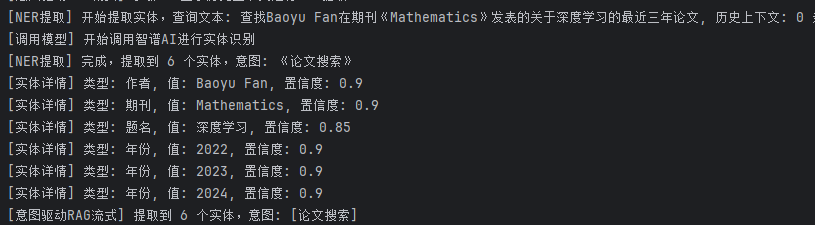
步骤 2、根据意图选择处理器

步骤 3、向量化实体并构建 ES混合查询
构建es查询dsl:
{
"bool": {
"must": [
{
"term": {
"author": {
"value": "Baoyu Fan"
}
}
},
{
"terms": {
"year": [
2022,
2023,
2024
]
}
}
],
"should": [
{
"knn": {
"boost": 5.0,
"field": "titleVector",
"query_vector": [
0.003465077141299844,
-0.029448172077536583,
-0.07837327569723129
...
],
"k": 10,
"num_candidates": 100
}
},
{
"knn": {
"boost": 2.0,
"field": "journalNameVector",
"query_vector": [
-0.012345678901234567,
0.056789012345678901,
0.034567890123456789
...
],
"k": 10,
"num_candidates": 100
}
}
],
"minimum_should_match": 0
}
}
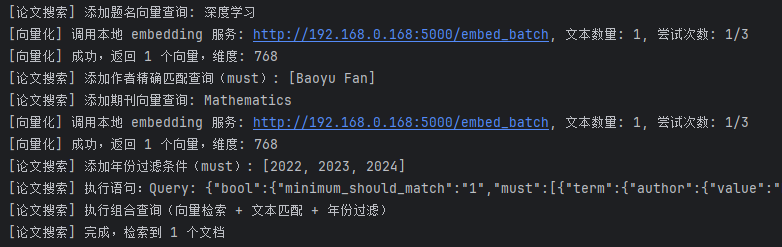
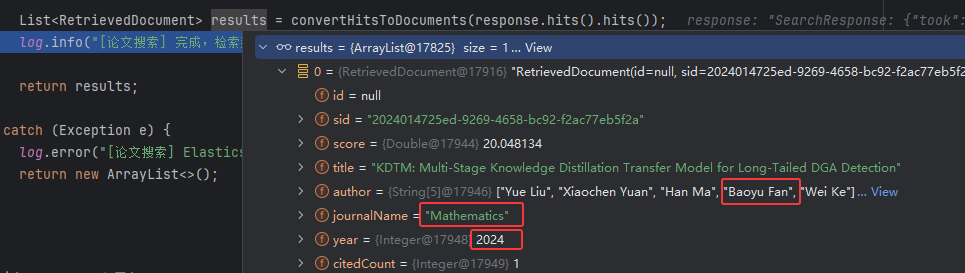
检索结果:
步骤4、LLM 流式生成答案
结合rag检索结果构建提示词
你是一个专业的学术文献检索助手,请基于提供的论文信息回答用户的问题。
要求:
1. 回答要准确、专业、有条理
2. 尽量引用提供的论文信息
3. 如果信息不足,明确告知用户
4. 保持客观中立的态度
以下是检索到的相关论文信息:
[论文 1]
详情链接:https://jyx.cxstar.cn/#/articleDetail?sid=2024014725ed-9269-4658-bc92-f2ac77eb5f2a
题名:KDTM: Multi-Stage Knowledge Distillation Transfer Model for Long-Tailed DGA Detection
作者:Yue Liu, Xiaochen Yuan, Han Ma, Baoyu Fan, Wei Ke
期刊:Mathematics
年份:2024
相关度评分:20.0481
提取到的关键信息:
- AUTHOR:Baoyu Fan
- JOURNAL:Mathematics
- TITLE:深度学习
- YEAR:2023,2024,2025
请基于以上信息回答以下问题:
查找Baoyu Fan在期刊《Mathematics》发表的关于深度学习的最近三年论文
步骤5、大模型返回结果
六、参考资料与扩展阅读
1. Spring AI 官方文档
- https://docs.spring.io/spring-ai/reference/
- 涵盖 Embedding、Vector Store、Chat Model 等核心概念
2. Elasticsearch Vector Search
- https://www.elastic.co/guide/en/elasticsearch/reference/current/knn-search.html
- kNN 查询、HNSW 索引原理
3. 智谱 AI API 文档
- https://open.bigmodel.cn/dev/api
- GLM-4 系列模型使用指南
4. RAG 综述
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Lewis et al., NeurIPS 2020
- https://arxiv.org/abs/2005.11401

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 25
25 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)