最大开源模型Kimi K2 Thinking:开源AI“思考大师”,重塑智能边界
摘要:月之暗面(MoonshotAI)推出革命性开源模型KimiK2Thinking,具备1万亿参数和256Ktoken上下文窗口,采用MoE架构。这款"思考代理人"能自主完成200-300步复杂任务链,实现推理与工具调用的无缝衔接。在HLE等基准测试中表现优异,以44.9%成绩超越GPT-5,且训练成本仅460万美元。其突出特点包括深度推理、超长记忆、稳定行为和高性价比,标志
想象一下,一个AI不仅能回答你的问题,还能像福尔摩斯一样——边推理、边调查、边调用各种工具,独立完成200-300个步骤的复杂任务链,中间不卡顿、不迷路、不"犯糊涂"。这不再是科幻电影,这就是月之暗面(Moonshot AI)刚刚放出的"重磅炸弹":Kimi K2 Thinking。这个模型一经发布,就在AI界掀起波澜。它不仅仅是工具,更是“思考代理人”,让AI从被动响应转向主动探索。

人工智能的舞台上,Kimi K2 Thinking 就像一台实力炸裂的机甲——不仅能思考,还能自我驱动、自主行动。没错,这是一款真正意义上的Thinking Agent(思考型智能体),它的出现,让开源 AI 进入了一个新的战场。
什么是 Kimi K2 Thinking?
简单来说,Kimi K2 Thinking 是月之暗面(Moonshot AI)推出的旗舰级开源模型。它拥有 1 万亿参数(trillion-parameter),但在实际推理时只激活约 320 亿参数,采用 Mixture-of-Experts(MoE,多专家)架构。它支持 256K token 的上下文窗口,能处理极长文本、代码库或复杂项目。

它训练时就被设计为「边思考边 action」,也就是 end-to-end 训练它在推理过程中可以不断调用工具(如搜索、编程、浏览等),进行数百步连续操作。
它还支持 原生 INT4 量化,在低精度下仍能维持高质量,这意味着推理更省资源、部署更灵活。

起源:从Kimi家族到“思考升级”
Kimi系列AI早已不是新人。早在今年7月,Moonshot就发布了Kimi K2基础版,以其长上下文处理和高效性能闻名。但Kimi K2 Thinking是它的“进化版”,专为推理而生。Moonshot的工程师们像打造一台精密仪器一样,将它构建成一个“思考代理”(Thinking Agent)。不同于传统模型的“一问一答”,Kimi K2 Thinking会像人类大脑一样,逐步拆解问题、动态调用工具(如搜索、计算或外部API),并在过程中保持逻辑的连贯性。
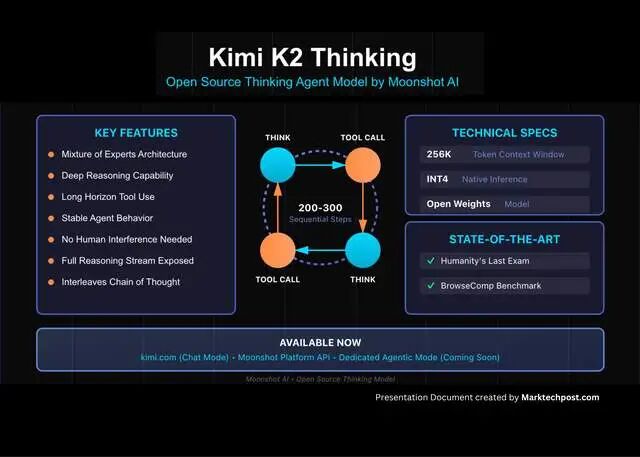
据官方介绍,这个模型能执行高达200-300个连续工具调用,而无需人类干预! 想想看,这相当于让AI独自完成一场马拉松式的脑力挑战,从数学难题到逻辑推理,再到实时数据分析,全程不掉链子。Hugging Face上的模型页面直言:它从Kimi K2起步,但加入了先进的推理机制,让AI真正“会思考”。
开源界的"异类":用460万美元挑战10亿美元俱乐部
11月6日,当Hugging Face联合创始人Thomas Wolf在X上感叹"又一个DeepSeek时刻"时,整个AI圈都在讨论同一个名字——Kimi K2 Thinking。这个仅用460万美元训练成本的模型,正在用实力质疑:顶尖AI真的需要天价投入和闭源垄断吗?
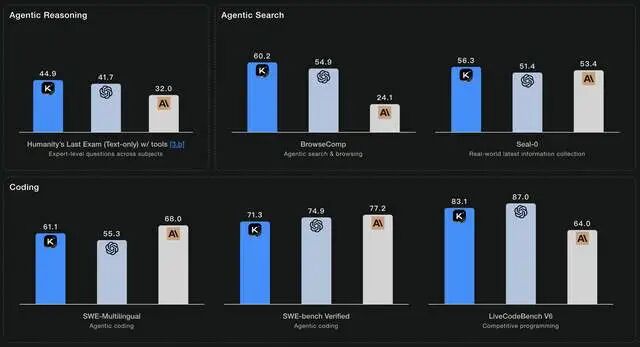
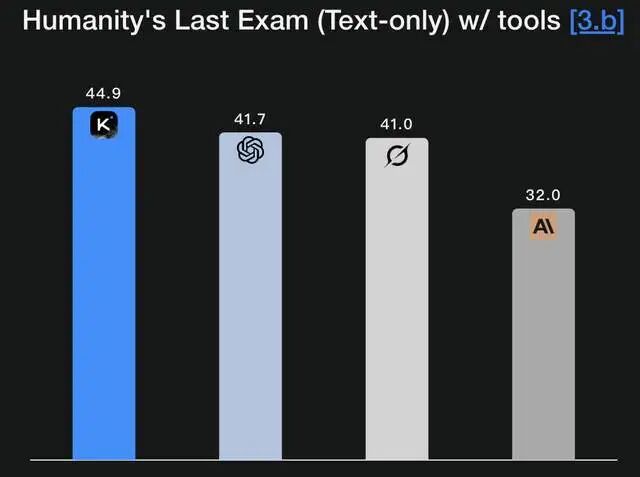
在最具挑战性的人类终极考试(HLE)中,K2 Thinking以44.9%的成绩碾压GPT-5的41.7%。在BrowseComp自主浏览测试中,它达到60.2%的SOTA水平。更惊人的是,在τ²-Bench Telecom代理工具使用基准中,它拿下了93分——这不是单科状元,这是全科制霸。
为什么说它强大?亮点剖析
1. 深度推理能力 + 工具协调
很多模型只能在对话里答问题,但 Kimi K2 Thinking 则像一个真正的研究员:思考 → 调用工具 → 再思考 → 再调用。它在训练中就学会了这种交替进行的方法,让它能处理非常复杂、多轮、多步骤的任务。在多个基准测试中(比如 HLE,人类终极考试;还有 Agentic 搜索、编程任务),它都表现出色。
2. 超长上下文 + 极致记忆
256K token 的上下文窗口意味着它能一次读入非常长的文本、整个代码项目,甚至多个文档,逻辑不会断。对于需要跨文档推理、长期规划的问题,这简直是神器。
3. 高性价比 + 开源精神
它是开源发布的(采用修改后的 MIT 许可证),允许商用。更惊人的是,据媒体报道,其训练成本仅约 460 万美元。对比之下,一些闭源大模型背后是十几亿、几十亿美元的投入——Kimi K2 Thinking 用小预算打出高能表现,这对开源社区和创业公司来说是巨大的利好。
模型权重已在Hugging Face和Together AI上免费下载,你可以本地运行、微调,甚至集成到自己的应用中。这意味着,开发者不再受限于昂贵的API调用,就能拥有顶尖推理能力。
4. 稳定的长期 Agent 行为
它可以维持 200–300 轮工具调用而不走偏,逻辑一致性很强。这意味着它不是那种想两下就迷路的大模型,而是真的能长期思考 + 长期行动。对于需要持续规划和执行的任务(比如研究型机器人、自动化流程)特别有价值。
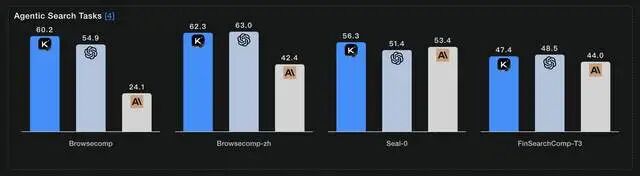
5. 卓越表现的基准成绩
在 HLE(Humanity’s Last Exam)中取得 44.9% 的成绩,这个分数在开源模型里非常亮眼。在 BrowseComp(衡量浏览与推理能力的测试)中,它也创下高分。
编程任务也很擅长,比如在 LiveCodeBench、SWE-bench 上都有不俗表现。
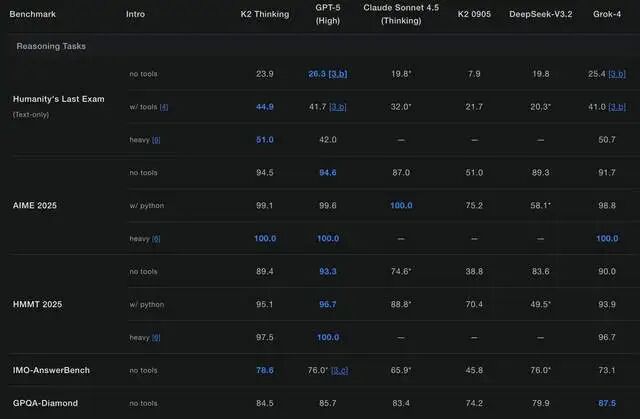
核心亮点:推理能力碾压,基准测试亮眼
Kimi K2 Thinking的最大卖点,就是它的“思考深度”。 具体来说,它在数学和逻辑问题上,能步步推导解决方案;在复杂场景中,如多步规划或工具链使用,它能保持数百步的连贯推理,而不迷失方向。
举个生动例子:假如你问它“如何优化一个投资组合,同时考虑实时市场数据?”传统AI可能给出泛泛建议,但Kimi K2 Thinking会先分析你的风险偏好,然后调用工具获取最新股市数据,逐步计算最佳配比,甚至模拟不同场景的风险评估。
一个时代的隐喻
从DeepSeek到Kimi K2 Thinking,中国AI团队正在证明:创新不一定要靠封闭和天价投入。当K2 Thinking在LMSYS Arena盲测中被评为排名第一的开源模型、总榜第五时,它挑战的不仅是技术天花板,更是整个AI产业的权力结构。
Kimi K2 Thinking的出现,像一颗AI界的“原子弹”,炸开了开源推理模型的新纪元。它不只是强大,更是智慧的化身——步步推理、工具联动、长链连贯,这些核心能力让它脱颖而出。如果你是个AI爱好者、开发者或只是好奇的普通人,不妨去Hugging Face下载试试。未来,AI将不再是“回答机器”,而是你的“思考伙伴”。Moonshot用Kimi K2 Thinking证明:开源,才能真正 democratize AI!快行动起来,拥抱这个智能革命吧!
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)