基于 CANN Kernel 直调工程的 Ascend C 算子开发实战:从 Add 到多核流水的深度实践(训练营深度实践篇)
在昇腾生态中,CANN 提供了一整套从算子开发到部署的高效工具链,而 Ascend C 则是其中面向 AI Core 进行 Kernel 编程的核心能力。对于很多初次接触 CANN 的开发者而言,“算子如何真正落到 AI Core 上运行?”、“如何实现多核并行与流水化效率最大化?”往往是最关键,也最容易迷失的问题。
基于 CANN Kernel 直调工程的 Ascend C 算子开发实战:从 Add 到多核流水的深度实践(训练营深度实践篇)
在昇腾生态中,CANN 提供了一整套从算子开发到部署的高效工具链,而 Ascend C 则是其中面向 AI Core 进行 Kernel 编程的核心能力。对于很多初次接触 CANN 的开发者而言,“算子如何真正落到 AI Core 上运行?”、“如何实现多核并行与流水化效率最大化?”往往是最关键,也最容易迷失的问题。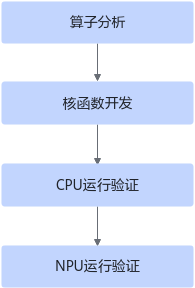
本文将通过一个从零开始的 Add 算子开发示例,完整走通 Kernel 直调工程(Kernel Direct Call) 的算子开发路径。无论你是已经熟悉 CANN、还是首次接触 Ascend C,都能通过本文系统理解算子开发背后的思路与真实工程模式。
训练营简介
2025年昇腾CANN训练营第二季,基于CANN开源开放全场景,推出0基础入门系列、码力全开特辑、开发者案例等专题课程,助力不同阶段开发者快速提升算子开发技能。获得Ascend C算子中级认证,即可领取精美证书,完成社区任务更有机会赢取华为手机,平板、开发板等大奖。
报名链接:https://www.hiascend.com/developer/activities/cann20252#cann-camp-2502-intro
一、算子开发的本质:从数学表达式到 AI Core 执行路径
算子开发的起点永远是“算子的数学定义”。以最小的示例 Add 为例,它的数学表达式并不复杂:
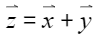
而真正的挑战在于:如何把这个看似简单的表达,在 AI Core 的执行模型下实现最高效的调度?
在 Ascend C 的编程体系中,一个算子的执行路径大致包含三部分:
- 数据搬运(Global Memory ↔ Local Memory):所有矢量计算都发生在 AI Core 的 Local Memory,因此必须先搬数据。
- 矢量计算 Add、Mul、Div 等:由 AI Core 内置的矢量指令(VEC 系列)完成。
- 并行与流水化治理(Pipe + Queue):通过异步队列与双缓冲提升吞吐。
Add 算子虽然简单,但掩盖着 Ascend C 深层次的执行哲学:每一个算子都必须打通“多核 + 流水 + tiling + 矢量计算 + 内存治理”的体系才能发挥真正性能。
二、环境与工程准备:算子开发的最小可运行形态
正式编码之前需要做好 CANN 环境准备,包括:
-
安装 Ascend-CANN Toolkit
-
配置运行环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
只要环境准备正确,你就具备了编译 kernel、在 CPU/NPU 上执行的全部基础能力。
为了让开发者快速进入实战,CANN 直接提供 Kernel 直调工程样例,包含:
- Kernel 源码
- Host 调试程序
- CPU 模拟执行(ICPU_RUN_KF)
- NPU 真机调用
- 数据构造/验证脚本
真正做到 “拿来就能跑,跑完能理解,理解后能开发”。
三、算子设计分析:从 Global Tensor 到 Local Tensor 的数据路径规划
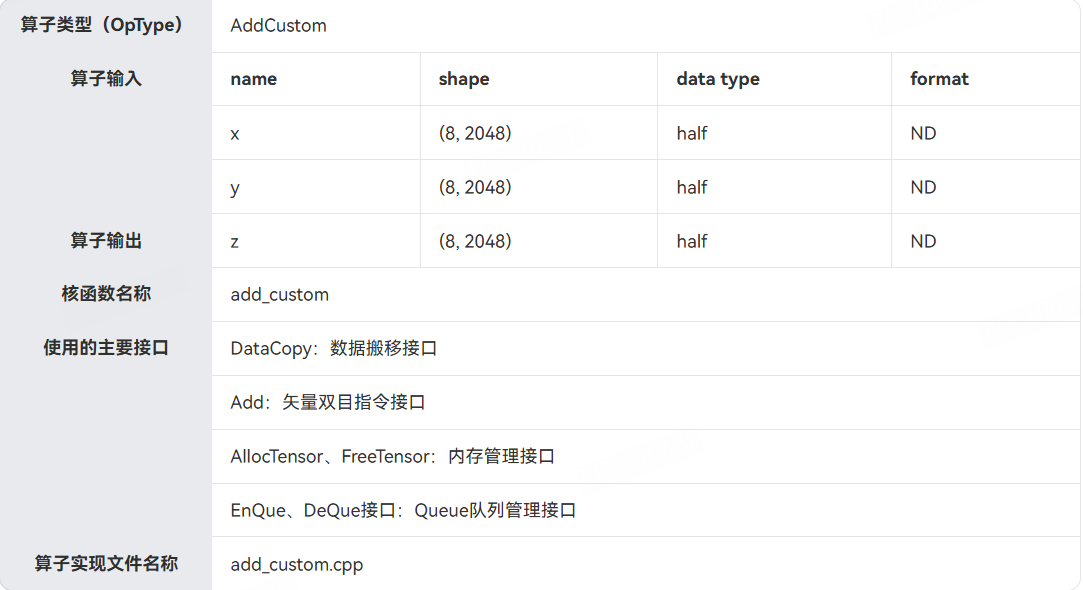
Add 算子输入/输出的规格如下:
| 输入 | 形状 | 类型 | Format |
|---|---|---|---|
| x | (8, 2048) | half | ND |
| y | (8, 2048) | half | ND |
| 输出 z | (8, 2048) | half | ND |
整个数据总量为:
[
8 \times 2048 = 16384 \text{ elements}
]
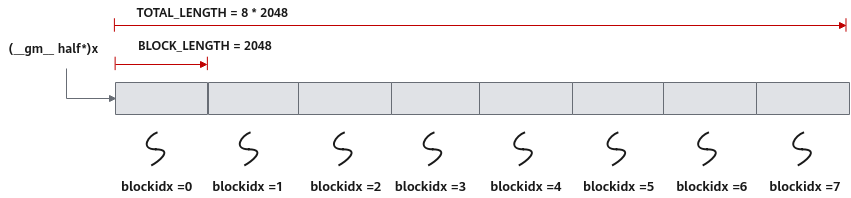
为了充分利用 8 个 AI Core,本例选择 按行切分,每个 Core 处理一个 block:
TOTAL_LENGTH = 16384
BLOCK_LENGTH = 2048
USE_CORE = 8
分配方式为:
Core0 → x[0:2048]
Core1 → x[2048:4096]
...
Core7 → x[14336:16384]
每个 Core 内部又做一次细分(Tiling):
- 每个 block 再切成 8 份 tile
- 每个 tile 再细分为 2 份(双缓冲 double buffer)
- 最终每个 Core 的 2048 数据被切成 16 份,每份 128 个元素
这个分块策略贯彻了 Ascend C 的核心理念:
多核并行解决整体规模,单核流水化解决局部吞吐。
四、Ascend C 核函数开发:实现 AI Core 上真正运行的算子
核函数的外壳非常简洁:
extern "C" __global__ __aicore__
void add_custom(GM_ADDR x, GM_ADDR y, GM_ADDR z)
{
KernelAdd op;
op.Init(x, y, z);
op.Process();
}
两个关键修饰符:
__global__:表示可被 <<<>>> 调用的 kernel__aicore__:表示运行在 AI Core 上
GM_ADDR 是 Global Memory 地址类型。
五、KernelAdd 类:算子的核心执行模型

1. 成员结构:完整覆盖 pipeline
AscendC::TPipe pipe;
TQue<VECIN> inQueueX, inQueueY;
TQue<VECOUT> outQueueZ;
GlobalTensor xGm, yGm, zGm;
- TPipe:为 Queue 分配 Local Memory
- TQue:流水各阶段的任务队列
- GlobalTensor:封装 GM 内存
2. Init:数据切分 + 内存准备
- 多核切分(GetBlockIdx)
- Tile 切分
- Double buffer 内存申请
这一步奠定了算子运行性能的“地基”。
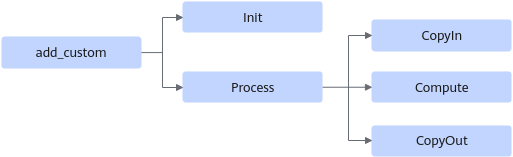
六、三段式 Pipeline:CopyIn / Compute / CopyOut
整个算子执行顺序如下:
for each i in loopCount:
CopyIn(i)
Compute(i)
CopyOut(i)
1. CopyIn:将 Global Memory 搬到 Local Memory
LocalTensor xLocal = inQueueX.AllocTensor<half>();
DataCopy(xLocal, xGm[offset], TILE_LENGTH);
inQueueX.EnQue(xLocal);
2. Compute:调用 Add 矢量指令
LocalTensor zLocal = outQueueZ.AllocTensor<half>();
Add(zLocal, xLocal, yLocal, TILE_LENGTH);
outQueueZ.EnQue(zLocal);
该 step 是算子逻辑的唯一核心:
[
z[i] = x[i] + y[i]
]
3. CopyOut:将结果写回 Global Memory
LocalTensor zLocal = outQueueZ.DeQue<half>();
DataCopy(zGm[offset], zLocal, TILE_LENGTH);
Pipeline + double buffer 的方式确保:
- CopyIn、Compute、CopyOut 可并行重叠
- AI Core 保持高利用率
七、Host 侧调试:一次工程完整的闭环
为了让 kernel 能运行,我们需要 host 程序作为入口。
CANN 提供两种模式:
1. CPU 调试模式(无设备也能执行)
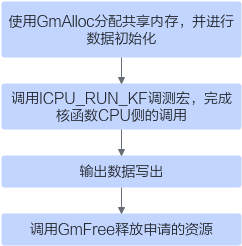
核心是:
ICPU_RUN_KF(add_custom, blockDim, x, y, z);
CPU 会模拟 AI Core 行为,极大提升开发效率。
2. NPU 真机模式
Host 程序步骤包括:
- aclInit 初始化
- Host/Device 内存申请
- H2D 拷贝
- 调用 kernel(<<<>>> 封装在 add_custom_do 中)
- D2H 拷贝
- 验证结果
- 释放资源
整个流程完全符合 AI 计算链路的真实运作方式。

八、从示例走向通用:算子开发的“哲学”与工程方法论
Add 看似简单,但它体现了通用算子开发的关键思想:
1. 算子性能的根是“数据分块 + 流水化”
- Core 级别:block 分片决定多核吞吐
- Core 内部:tile + double buffer 决定流水并行度
2. Ascend C 并不是简单的 C 语言,而是一套贴近硬件的矢量编程范式
所有计算必须围绕:
- Local Memory
- Vector 指令
- DataCopy
- Pipeline 阶段
这是一套高度工程化的编程框架。
3. CPU/NPU 双轨验证机制保证算子开发链路完整可控
- CPU 调试快速验证逻辑 correctness
- NPU 启动验证性能与真实行为
九、总结:从 Add 开始,真正理解 Ascend C 的执行模型
通过这个 Add 示例,我们不仅“开发了一个算子”,更理解了 Ascend C 中最关键的思想:
- 如何构建 AI Core 友好的数据布局
- 如何使用 Queue/Double Buffer 构建流水线
- 如何做到多核并行
- 如何在 Host 侧完整执行一个算子
- 如何从 C++ 层调度与验证 Kernel
换句话说,你真正掌握了 CANN 算子开发的核心方法论。
Add 只是一个开始。
真正的价值,是你学会了如何开发未来更复杂的:
- 激活函数算子
- 聚合类算子
- 卷积/归一化算子
- 张量变换算子
而 Ascend C + CANN 也正是为此而设计的。


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)