20251126_102520_告别“下次一定”:用AI三大武器(Skills、Prompt
在软件开发的世界里,代码安全扫描就像是体检,人人都知道重要,但真正能坚持下来的却寥寥无几。你是否也遇到过这样的场景:
序言:为什么你的代码安全总在“下次一定”?
在软件开发的世界里,代码安全扫描就像是体检,人人都知道重要,但真正能坚持下来的却寥寥无几。你是否也遇到过这样的场景:
上个月我接手一个老项目,提交 PR 前习惯性跑了下安全扫描,结果傻眼了:20+ 个 Critical 漏洞,30+ 个 High 风险。问之前的同事,答曰“知道啊,但是太多了不知道从哪修起,就先放着了”。
这种“安全债”的积累,往往源于流程的繁琐和重复:手动跑工具、分析报告、编写修复方案、起草 PR……每一步都需要耗费大量心力。当工具报告堆满屏幕,开发者很容易产生“算了,下次再说”的心理。
幸运的是,随着大模型(LLM)技术的飞速发展,我们有了更智能、更高效的自动化解决方案。本文将深入对比AI自动化领域的三大主流“武器”:传统 Prompt、Claude Skills 和 模型上下文协议(MCP),并以代码安全自动化为例,展示如何用它们彻底告别“下次一定”。
一、AI自动化三大武器:Skills vs. Prompt vs. MCP
在代码安全自动化场景中,我们期望AI能像一个经验丰富的安全工程师一样,接收指令、调用工具、分析结果并给出行动建议。实现这一目标,有三种主要的AI交互模式。
1. 传统 Prompt:一次性的“口头指令”
传统 Prompt 是最基础的交互方式。你将所有指令、背景信息、期望的输出格式,甚至工具的使用方法,一次性全部输入给大模型。
- 优点: 简单直接,无需任何配置,适用于一次性或临时的任务。
- 缺点:重复性高,每次执行相同任务都需要重新输入或复制粘贴长篇指令;上下文冗余,指令本身会占用大量的上下文窗口(Token),增加了成本和延迟;缺乏结构化,指令和逻辑混杂在一起,难以维护和迭代。
2. Claude Skills:固化的“作业指导书”
Claude Skills 是 Anthropic 推出的一种将复杂工作流固化、模块化的机制。你可以将一套完整的指令、工具调用脚本、输出格式等封装在一个 SKILL.md 文件中,并给它一个简洁的名称和描述。
Claude 在会话开始时只会读取 Skills 的名称和描述(几十个 Token),当用户的请求匹配到某个 Skill 时,才会加载完整的指令内容。
- 核心优势:持久化和复用。指令只需编写一次,就可以在 Claude.ai、Claude Code、API 等所有支持 Skills 的环境中使用。它通过延迟加载**机制,有效节省了上下文 Token,提高了效率。
- 在安全自动化中的体现: 将“检测项目类型 -> 运行 Bandit/Semgrep -> 解析 JSON 报告 -> 生成 Markdown 报告”这一复杂流程,固化为一个可随时调用的
security-scan技能。
3. MCP(Model Context Protocol):标准化的“外部协作”
MCP(Model Context Protocol,模型上下文协议)则代表了更宏大的愿景。它是一种标准化协议,旨在为大模型(LLM)与各种外部系统和工具之间建立双向、结构化的连接[1]。
MCP 的目标是让 LLM 能够像操作系统一样,通过统一的接口与 IDE、Git 仓库、数据库、外部 API 等进行高效、安全的交互。
- 核心优势:外部集成和标准化。它不局限于模型内部的指令,而是将模型的“手”伸向了外部世界,实现了真正的Agent-to-Tool和Agent-to-Agent协作。
- 与 Skills 的区别: Skills 是本地化、模型内的指令和脚本执行(在安全沙箱中),而 MCP 是外部化、跨系统的通信协议。在代码安全场景中,MCP 可以让 LLM 直接与公司的内部漏洞管理系统、代码仓库的 API 进行交互,而不仅仅是运行本地扫描脚本。
三者对比一览表
| 特性 | 传统 Prompt | Claude Skills | MCP (模型上下文协议) |
|---|---|---|---|
| 本质 | 一次性指令 | 固化、模块化的工作流 | 标准化的外部通信协议 |
| 复用性 | 极低(每次需复制粘贴) | 极高(一次编写,多处调用) | 极高(通过协议连接外部系统) |
| 上下文消耗 | 高(指令占用大量 Token) | 低(通过描述触发,延迟加载) | 低(通过结构化数据传输) |
| 执行环境 | 模型内部推理 | 模型内部的安全沙箱(可执行代码) | 外部系统和工具 |
| 适用场景 | 临时查询、简单任务 | 复杂、重复、需要本地工具的任务(如代码扫描) | 跨系统协作、大规模集成、数据交互 |
| 安全风险 | 低(仅文本) | 中(沙箱内执行代码,需注意权限) | 中高(涉及外部系统访问和数据传输) |
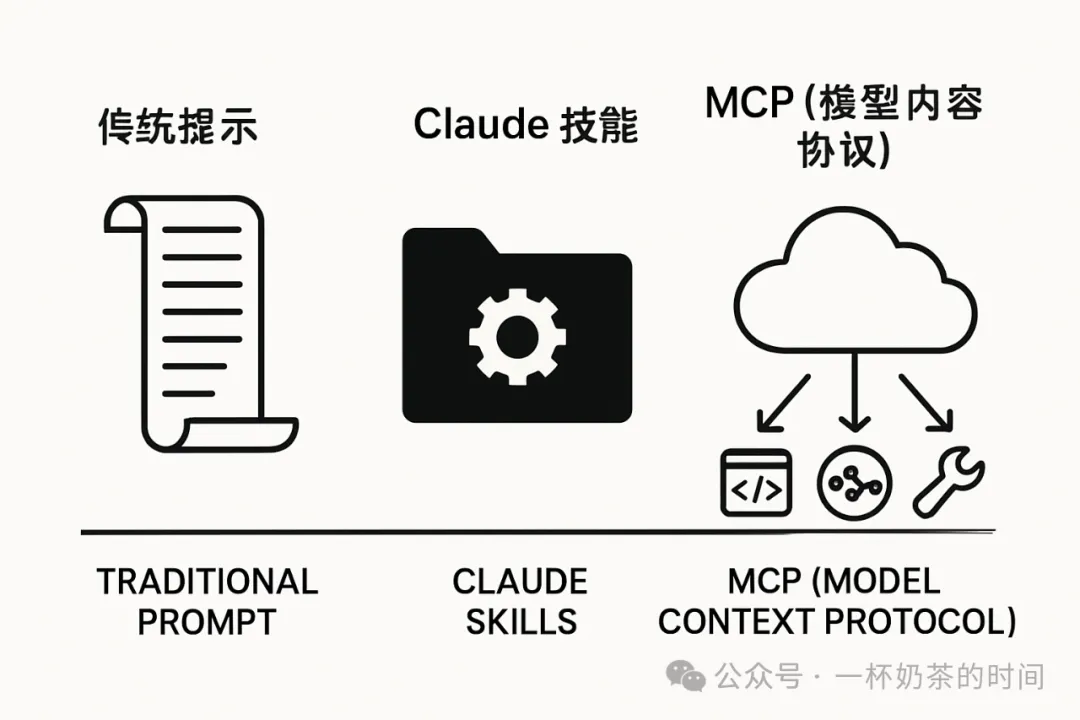
AI自动化三大武器概念对比
二、实战:用 Claude Skills 搭建代码安全自动化流水线
Skills 的出现,让代码安全自动化变得触手可及。它将繁琐的“跑工具、看报告”过程,简化为一句简单的“帮我检查代码安全”。
1. Skills 的工作原理
一个 Skills 的工作流是高度结构化的,确保了每次执行的稳定性和一致性。
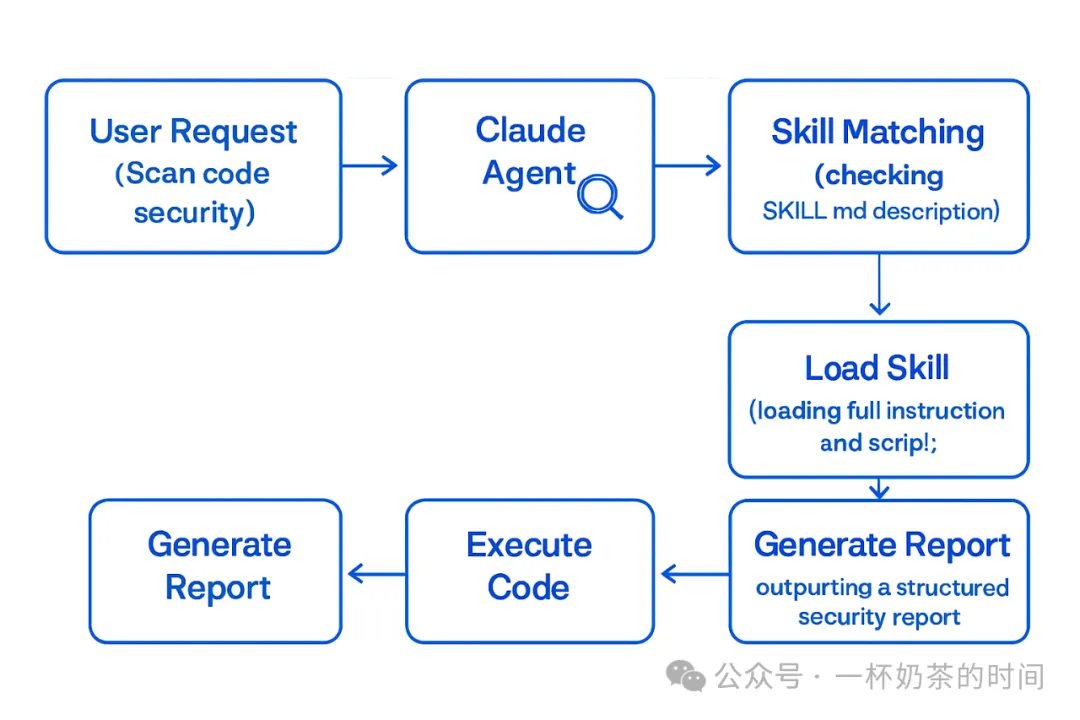
2. 创建 Security Scan Skill
我们将“代码安全扫描、报告生成、PR 描述起草”这三个步骤固化为一个 security-scan Skill。
第一步:定义 Skill 结构
Skill 本质上是一个文件夹,包含一个核心文件 SKILL.md 和可选的辅助脚本。
~/.claude/skills/security-scan/├── SKILL.md # 核心指令和逻辑└── scripts/ └── scan.sh # 实际执行扫描的脚本
第二步:编写 SKILL.md (核心指令)
SKILL.md 的 YAML 头定义了 Skill 的触发条件,正文则详细指导 Claude 的行为。
---name: security-scandescription: Run security scans on code repositories and generate vulnerability reports. Use when user asks to check security, scan for vulnerabilities, or needs a security audit.---# Security Scan Skill## 你的职责帮用户执行代码安全扫描,整理漏洞报告,给出修复建议。## 工作流程1. **检测项目类型**:检查是否有 requirements.txt、go.mod 等文件。2. **运行扫描脚本**:执行 `scripts/scan.sh`,它会根据项目类型运行 Bandit、Semgrep、Trivy 等工具。3. **解析结果**:读取生成的 JSON 报告,按严重程度分类。4. **生成报告**:用 Markdown 格式整理结果,包括问题描述、风险和修复建议。## 报告格式示例 (节选)```markdown# 安全扫描报告## 🔴 Critical Issues### [Bandit] auth.py:45**问题**:使用了硬编码密码**风险**:密码可能被攻击者轻易获取**修复建议**:使用环境变量或密钥管理服务存储密码...
PR 描述模板
当用户需要创建 PR 时,使用以下模板:
## 🔒 Security Fix...### 修复内容- 移除了硬编码的敏感信息- 修复了 SQL 注入漏洞...
``````plaintext
**第三步:编写 `scripts/scan.sh` (工具调用)**这个脚本是 Skills 强大能力的核心,它在 Claude 的安全沙箱中执行,负责调用外部工具。```bash#!/bin/bash# ... (此处省略详细脚本内容,详见原始文档)# 脚本功能:检测 Python/Go 项目,调用 Bandit/pip-audit/gosec/Semgrep/Trivy 等工具,并将结果输出为 JSON 报告。# ...
3. 自动化实战:从“一键扫描”到“智能修复”
通过 Skills,整个流程被极大地简化,但同时保留了人机协作的灵活性,以应对真实世界中的复杂情况。
- 触发增量扫描: 开发者在本地修改了
user_api.py和db_utils.py两个文件,准备提交 PR。他不需要全量扫描,只需在 Claude Code 中输入:“针对我本次修改的文件,跑一下安全扫描”。
- Skills 内部逻辑:
scan.sh脚本通过git diff识别出变更文件,并只对这些文件执行 Semgrep 和 Bandit 的增量扫描。
- AI 智能分析与误报处理: Claude 自动匹配
security-scanSkill,执行扫描并解析报告。
- 扫描结果: 发现
user_api.py中存在一个 High 风险的 SQL 注入(Semgrep 报告),以及tests/test_auth.py中存在一个 Low 风险的硬编码密码(Bandit 报告)。 - Claude 的输出: Claude 根据 Skill 中预设的“已知误报列表”规则(例如,忽略测试文件中的硬编码密码),自动过滤了 Low 风险的误报,只聚焦于真正的 High 风险问题。
- 报告摘要: Claude 输出结构化的报告摘要,重点突出 SQL 注入问题,并给出详细的修复建议(如使用 ORM 或参数化查询)。
- 人机协作修复: 开发者根据 Claude 的建议,在
user_api.py中将字符串拼接改为参数化查询。 - 二次验证与 PR 起草: 修复完成后,开发者输入:“我已修复,请帮我验证并生成 PR 描述”。
- 二次验证: Claude 再次对
user_api.py执行增量扫描,确认 SQL 注入问题已消失。 - 生成 PR: Claude 自动套用 Skill 中预设的 PR 模板,生成专业的提交信息,内容包括:修复了 High 风险的 SQL 注入问题、影响文件、验证方式(二次扫描通过)等,可以直接用于 Git 提交。
实战总结: 这种流程不再是简单的“工具调用”,而是AI驱动的智能工作流。Skills 负责固化流程、处理工具细节和过滤噪音,开发者只需专注于高价值的修复工作,极大地提高了安全修复的效率和准确性。
三、进阶思考:Skills 与 MCP 的未来融合
虽然 Skills 和 MCP 在设计理念上有所不同,但它们并非互斥,而是代表了 AI 自动化能力的两个维度:
- Skills: 专注于本地化、模型内的复杂任务编排和工具调用。它解决了“如何高效、重复地执行一套固定流程”的问题。
- MCP: 专注于外部化、跨系统的标准化数据和上下文传输。它解决了“如何让大模型安全、高效地与企业级系统集成”的问题。
在未来的代码安全自动化中,我们可以预见两者将深度融合:
- Skills 作为执行单元: 一个高级的 Skill 可以被设计为“执行一次全栈安全审计”。
- MCP 作为连接桥梁: 这个 Skill 不仅在本地沙箱中运行 Semgrep,还会通过 MCP 协议,将扫描结果实时同步到 Jira 缺陷管理系统、企业内部的知识库,甚至触发另一个 Agent(通过 A2A 协议)去通知安全团队。
总结
从传统 Prompt 的低效重复,到 Claude Skills 的模块化复用,再到 MCP 的标准化跨系统集成,AI 在代码安全自动化领域的进化速度令人惊叹。
对于开发者而言,Skills 提供了一个即插即用的自动化方案,能将安全扫描从“不得不做”的负担,转变为“一句话搞定”的效率工具。通过固化工作流,我们不仅能提高效率,还能确保每次安全检查的一致性和专业性,真正将代码安全融入日常开发流程,彻底告别“下次一定”的窘境。
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
- 系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
- 高效有序的学习路径:避免无效学习,节省时间,提升效率。
- 完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
- 持续学习能力:Al技术日新月异,保持学习是关键。
- 跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
- 解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献224条内容
已为社区贡献224条内容

所有评论(0)