【RAG全栈】Task04:检索优化
{'author': '二次元的Datawhale', 'source': 'BV1ug4y157xA', 'view_count': 19602, 'title': '《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则', 'length': 1063}描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。
1.混合检索
多向量混合搜索集成了不同的搜索方法或跨越了各种模态的 Embeddings:
- 稀疏-密集向量搜索:密集向量是捕捉语义关系的绝佳方法,而稀疏向量则是精确匹配关键词的高效方法。混合搜索结合了这些方法,既能提供广泛的概念理解,又能提供精确的术语相关性,从而改善搜索结果。通过利用每种方法的优势,混合搜索克服了单独方法的局限性,为复杂查询提供了更好的性能。以下是结合语义搜索和全文搜索的混合检索的详细指南。
- 多模态向量搜索:多模态向量搜索是一种功能强大的技术,可以跨文本、图像、音频等各种数据类型进行搜索。这种方法的主要优势在于它能将不同的模式统一为一种无缝、连贯的搜索体验。例如,在产品搜索中,用户可能会输入一个文本查询来查找用文本和图像描述的产品。通过混合搜索方法将这些模式结合起来,可以提高搜索准确性或丰富搜索结果。
使用Milvus 实现混合检索
docker启动Milvus、attu服务

import json
import os
import numpy as np
from pymilvus import connections, MilvusClient, FieldSchema, CollectionSchema, DataType, Collection, AnnSearchRequest, RRFRanker
from pymilvus.model.hybrid import BGEM3EmbeddingFunction
# 1. 初始化设置
COLLECTION_NAME = "dragon_hybrid_demo"
MILVUS_URI = "http://localhost:19530" # 服务器模式
DATA_PATH = "../../data/C4/metadata/dragon.json" # 相对路径
BATCH_SIZE = 50
# 2. 连接 Milvus 并初始化嵌入模型
print(f"--> 正在连接到 Milvus: {MILVUS_URI}")
connections.connect(uri=MILVUS_URI)
print("--> 正在初始化 BGE-M3 嵌入模型...")
ef = BGEM3EmbeddingFunction(use_fp16=False, device="cpu")
print(f"--> 嵌入模型初始化完成。密集向量维度: {ef.dim['dense']}")
# 3. 创建 Collection
milvus_client = MilvusClient(uri=MILVUS_URI)
if milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在删除已存在的 Collection '{COLLECTION_NAME}'...")
milvus_client.drop_collection(COLLECTION_NAME)
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="img_id", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="path", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="title", dtype=DataType.VARCHAR, max_length=256),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=4096),
FieldSchema(name="category", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=128),
FieldSchema(name="environment", dtype=DataType.VARCHAR, max_length=64),
FieldSchema(name="sparse_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
FieldSchema(name="dense_vector", dtype=DataType.FLOAT_VECTOR, dim=ef.dim["dense"])
]
# 如果集合不存在,则创建它及索引
if not milvus_client.has_collection(COLLECTION_NAME):
print(f"--> 正在创建 Collection '{COLLECTION_NAME}'...")
schema = CollectionSchema(fields, description="关于龙的混合检索示例")
# 创建集合
collection = Collection(name=COLLECTION_NAME, schema=schema, consistency_level="Strong")
print("--> Collection 创建成功。")
# 4. 创建索引
print("--> 正在为新集合创建索引...")
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
collection.create_index("sparse_vector", sparse_index)
print("稀疏向量索引创建成功。")
dense_index = {"index_type": "AUTOINDEX", "metric_type": "IP"}
collection.create_index("dense_vector", dense_index)
print("密集向量索引创建成功。")
collection = Collection(COLLECTION_NAME)
# 5. 加载数据并插入
collection.load()
print(f"--> Collection '{COLLECTION_NAME}' 已加载到内存。")
if collection.is_empty:
print(f"--> Collection 为空,开始插入数据...")
if not os.path.exists(DATA_PATH):
raise FileNotFoundError(f"数据文件未找到: {DATA_PATH}")
with open(DATA_PATH, 'r', encoding='utf-8') as f:
dataset = json.load(f)
docs, metadata = [], []
for item in dataset:
parts = [
item.get('title', ''),
item.get('description', ''),
item.get('location', ''),
item.get('environment', ''),
# *item.get('combat_details', {}).get('combat_style', []),
# *item.get('combat_details', {}).get('abilities_used', []),
# item.get('scene_info', {}).get('time_of_day', '')
]
docs.append(' '.join(filter(None, parts)))
metadata.append(item)
print(f"--> 数据加载完成,共 {len(docs)} 条。")
print("--> 正在生成向量嵌入...")
embeddings = ef(docs)
print("--> 向量生成完成。")
print("--> 正在分批插入数据...")
# 为每个字段准备批量数据
img_ids = [doc["img_id"] for doc in metadata]
paths = [doc["path"] for doc in metadata]
titles = [doc["title"] for doc in metadata]
descriptions = [doc["description"] for doc in metadata]
categories = [doc["category"] for doc in metadata]
locations = [doc["location"] for doc in metadata]
environments = [doc["environment"] for doc in metadata]
# 获取向量
sparse_vectors = embeddings["sparse"]
dense_vectors = embeddings["dense"]
# 插入数据
collection.insert([
img_ids,
paths,
titles,
descriptions,
categories,
locations,
environments,
sparse_vectors,
dense_vectors
])
collection.flush()
print(f"--> 数据插入完成,总数: {collection.num_entities}")
else:
print(f"--> Collection 中已有 {collection.num_entities} 条数据,跳过插入。")
# 6. 执行搜索
search_query = "悬崖上的巨龙"
search_filter = 'category in ["western_dragon", "chinese_dragon", "movie_character"]'
top_k = 5
print(f"\n{'='*20} 开始混合搜索 {'='*20}")
print(f"查询: '{search_query}'")
print(f"过滤器: '{search_filter}'")
query_embeddings = ef([search_query])
dense_vec = query_embeddings["dense"][0]
sparse_vec = query_embeddings["sparse"]._getrow(0)
# 打印向量信息
print("\n=== 向量信息 ===")
print(f"密集向量维度: {len(dense_vec)}")
print(f"密集向量前5个元素: {dense_vec[:5]}")
print(f"密集向量范数: {np.linalg.norm(dense_vec):.4f}")
print(f"\n稀疏向量维度: {sparse_vec.shape[1]}")
print(f"稀疏向量非零元素数量: {sparse_vec.nnz}")
print("稀疏向量前5个非零元素:")
for i in range(min(5, sparse_vec.nnz)):
print(f" - 索引: {sparse_vec.indices[i]}, 值: {sparse_vec.data[i]:.4f}")
density = (sparse_vec.nnz / sparse_vec.shape[1] * 100)
print(f"\n稀疏向量密度: {density:.8f}%")
# 定义搜索参数
search_params = {"metric_type": "IP", "params": {}}
# 先执行单独的搜索
print("\n--- [单独] 密集向量搜索结果 ---")
dense_results = collection.search(
[dense_vec],
anns_field="dense_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
for i, hit in enumerate(dense_results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('path')}")
print(f" 描述: {hit.entity.get('description')[:100]}...")
print("\n--- [单独] 稀疏向量搜索结果 ---")
sparse_results = collection.search(
[sparse_vec],
anns_field="sparse_vector",
param=search_params,
limit=top_k,
expr=search_filter,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
for i, hit in enumerate(sparse_results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('path')}")
print(f" 描述: {hit.entity.get('description')[:100]}...")
print("\n--- [混合] 稀疏+密集向量搜索结果 ---")
# 创建 RRF 融合器
rerank = RRFRanker(k=60)
# 创建搜索请求
dense_req = AnnSearchRequest([dense_vec], "dense_vector", search_params, limit=top_k)
sparse_req = AnnSearchRequest([sparse_vec], "sparse_vector", search_params, limit=top_k)
# 执行混合搜索
results = collection.hybrid_search(
[sparse_req, dense_req],
rerank=rerank,
limit=top_k,
output_fields=["title", "path", "description", "category", "location", "environment"]
)[0]
# 打印最终结果
for i, hit in enumerate(results):
print(f"{i+1}. {hit.entity.get('title')} (Score: {hit.distance:.4f})")
print(f" 路径: {hit.entity.get('path')}")
print(f" 描述: {hit.entity.get('description')[:100]}...")
# 7. 清理资源
milvus_client.release_collection(collection_name=COLLECTION_NAME)
print(f"已从内存中释放 Collection: '{COLLECTION_NAME}'")
milvus_client.drop_collection(COLLECTION_NAME)
print(f"已删除 Collection: '{COLLECTION_NAME}'")
运行结果:
--> 嵌入模型初始化完成。密集向量维度: 1024
--> 正在创建 Collection 'dragon_hybrid_demo'...
--> Collection 创建成功。
--> 正在为新集合创建索引...
稀疏向量索引创建成功。
密集向量索引创建成功。
--> Collection 'dragon_hybrid_demo' 已加载到内存。
--> Collection 为空,开始插入数据...
--> 数据加载完成,共 6 条。
--> 正在生成向量嵌入...
You're using a XLMRobertaTokenizerFast tokenizer. Please note that with a fast tokenizer, using the `__call__` method is faster than using a method to encode the text followed by a call to the `pad` method to get a padded encoding.
--> 向量生成完成。
--> 正在分批插入数据...
--> 数据插入完成,总数: 6==================== 开始混合搜索 ====================
查询: '悬崖上的巨龙'
过滤器: 'category in ["western_dragon", "chinese_dragon", "movie_character"]'=== 向量信息 ===
密集向量维度: 1024
密集向量前5个元素: [-0.0035305 0.02043397 -0.04192593 -0.03036701 -0.02098157]
密集向量范数: 1.0000稀疏向量维度: 250002
稀疏向量非零元素数量: 6
稀疏向量前5个非零元素:
- 索引: 6, 值: 0.0659
- 索引: 7977, 值: 0.1459
- 索引: 14732, 值: 0.2959
- 索引: 31433, 值: 0.1463
- 索引: 141121, 值: 0.1587稀疏向量密度: 0.00239998%
--- [单独] 密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.7214)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.5353)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.5231)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...--- [单独] 稀疏向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.2254)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0857)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 驯龙高手:无牙仔 (Score: 0.0639)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...--- [混合] 稀疏+密集向量搜索结果 ---
1. 悬崖上的白龙 (Score: 0.0328)
路径: ../../data/C3/dragon/dragon02.png
描述: 一头雄伟的白色巨龙栖息在悬崖边缘,背景是金色的云霞和远方的海岸。它拥有巨大的翅膀和优雅的身姿,是典型的西方奇幻生物。...
2. 中华金龙 (Score: 0.0320)
路径: ../../data/C3/dragon/dragon06.png
描述: 一条金色的中华龙在祥云间盘旋,它身形矫健,龙须飘逸,展现了东方神话中龙的威严与神圣。...
3. 奔跑的奶龙 (Score: 0.0315)
路径: ../../data/C3/dragon/dragon04.png
描述: 一只Q版的黄色小恐龙,有着大大的绿色眼睛和友善的微笑。是一部动画中的角色,非常可爱。...
4. 驯龙高手:无牙仔 (Score: 0.0313)
路径: ../../data/C3/dragon/dragon05.png
描述: 在电影《驯龙高手》中,主角小嗝嗝骑着他的龙伙伴无牙仔在高空飞翔。他们飞向灿烂的太阳,下方是岛屿和海洋,画面充满了冒险与友谊。...
5. 霸王龙的怒吼 (Score: 0.0312)
路径: ../../data/C3/dragon/dragon03.png
描述: 史前时代的霸王龙张开血盆大口,发出震天的怒吼。在它身后,几只翼龙在阴沉的天空中盘旋,展现了白垩纪的原始力量。...
已从内存中释放 Collection: 'dragon_hybrid_demo'
已删除 Collection: 'dragon_hybrid_demo'
2.智能查询理解与构建
处理复杂和多样化的数据,包括结构化数据(如SQL数据库)、半结构化数据(如带有元数据的文档)以及图数据。用户的查询也可能不仅仅是简单的语义匹配,而是包含复杂的过滤条件、聚合操作或关系查询。
查询构建(Query Construction)利用大语言模型(LLM)的强大理解能力,将用户的自然语言“翻译”成针对特定数据源的结构化查询语言或带有过滤条件的请求。这使得RAG系统能够无缝地连接和利用各种类型的数据,从而极大地扩展了其应用场景和能力。
代码示例
以B站视频为例来看看如何使用SelfQueryRetriever。
步骤如下:
提取元数据、存入向量数据库
创建查询工具
创建智能体自动匹配查询条件
以下是langchain V1.0版本代码
import os
from langchain_openai import ChatOpenAI
from langchain_community.document_loaders import BiliBiliLoader
from langchain.agents import create_agent
from langchain.tools import tool
from langchain_community.vectorstores import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
import logging
logging.basicConfig(level=logging.INFO)
# 1. 初始化视频数据
video_urls=[
"https://www.bilibili.com/video/BV1Bo4y1A7FU",
"https://www.bilibili.com/video/BV1ug4y157xA",
"https://www.bilibili.com/video/BV1yh411V7ge",
]
bili=[]
try:
loader=BiliBiliLoader(video_urls=video_urls)
docs=loader.load()
for doc in docs:
original = doc.metadata
# 提取基本元数据字段
metadata = {
'title': original.get('title', '未知标题'),
'author': original.get('owner', {}).get('name', '未知作者'),
'source': original.get('bvid', '未知ID'),
'view_count': original.get('stat', {}).get('view', 0),
'length': original.get('duration', 0),
}
doc.metadata = metadata
bili.append(doc)
except Exception as e:
print(f"加载BiliBili视频失败: {str(e)}")
if not bili:
print("没有成功加载任何视频,程序退出")
exit()
# 2. 创建向量存储
embed_model=HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vectorstore=Chroma.from_documents(bili,embed_model)
# 3. 初始化查询过滤工具
@tool
def search_videos(query: str,min_length: int = None,max_length: int = None,min_views: int = None) -> str:
"""Search videos by query and optional metadata filters.
Args:
query: Search query text
min_length: Minimum video length in seconds (optional)
max_length: Maximum video length in seconds (optional)
min_views: Minimum number of views (optional)
Returns:
Formatted search results
"""
try:
# Build filter dict - Chroma supports basic filtering
filter_dict={}
if min_length is not None:
filter_dict['length']={'$gte':min_length}
if max_length is not None:
if 'length' in filter_dict:
filter_dict['length']['$lte']=max_length
else:
filter_dict['length']={'$lte':max_length}
if min_views is not None:
filter_dict['view_count']={'$gte':min_views}
# Perform similarity search with filters
results=vectorstore.similarity_search(
query,
k=5,
filter=filter_dict if filter_dict else None
)
if not results:
return "No matching videos found."
output=["Found Videos:\n" + "=" * 50]
for doc in results:
meta=doc.metadata
print(meta)
output.append(
f"Title: {meta.get('title','Unknown')}\n"
f"Author: {meta.get('author','Unknown')}\n"
f"Views: {meta.get('view_count','Unknown')}\n"
f"Duration: {meta.get('length','Unknown')}s\n"
+ "=" * 50
)
return "\n".join(output)
except Exception as e:
return f"Search error: {str(e)}"
# 4. 推荐使用魔搭社区模型,种类齐全,每天2000次免费调用
llm=ChatOpenAI(
model='deepseek-ai/DeepSeek-V3.1',
api_key=os.getenv("MODELSCOPE_API_KEY"),
max_tokens=500,
base_url="https://api-inference.modelscope.cn/v1"
)
agent=create_agent(
model=llm,
tools=[search_videos],
system_prompt="""You are a video search assistant. When users ask about videos:
1. "shortest videos" → search with max_length=300
2. "videos over 600 seconds" → search with min_length=600
3. "most viewed" → search with min_views=10000
4. "short and popular" → combine filters
Always call search_videos with appropriate parameters based on user intent."""
)
# 5. 执行查询示例
queries = [
"Find the shortest videos",
"Show me videos longer than 600 seconds"
]
for query in queries:
print(f"\n--- Query: '{query}' ---")
try:
result=agent.invoke({
"messages":[{"role":"user","content":query}]
})
print(result)
# Extract final message from agent response
if "messages" in result:
final_msg=result["messages"][-1]
print(final_msg.content)
else:
print(result)
except Exception as e:
print(f"未找到匹配的视频: {str(e)}")运行效果:
--- Query: 'Find the shortest videos' ---
INFO:httpx:HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 200 OK"
I'll search for the shortest videos available. Based on your request, I'll look for videos with a maximum length of 300 seconds (5 minutes) or less--- Query: 'Show me videos longer than 600 seconds' ---
INFO:httpx:HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 200 OK"
{'author': '二次元的Datawhale', 'source': 'BV1ug4y157xA', 'view_count': 19602, 'title': '《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则', 'length': 1063}
{'view_count': 7416, 'author': '二次元的Datawhale', 'length': 806, 'source': 'BV1yh411V7ge', 'title': '《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】03.Prompt如何迭代优化'}
INFO:httpx:HTTP Request: POST https://api-inference.modelscope.cn/v1/chat/completions "HTTP/1.1 429 Too Many Requests"
INFO:openai._base_client:Retrying request to /chat/completions in 0.410714 seconds
I found videos that are longer than 600 seconds. Here are the results:**Videos Longer Than 600 Seconds:**
1. **Title:** 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】02.Prompt 的构建原则
- **Author:** 二次元的Datawhale
- **Views:** 19,602
- **Duration:** 1063 seconds (about 17 minutes 43 seconds)2. **Title:** 《吴恩达 x OpenAI Prompt课程》【专业翻译,配套代码笔记】03.Prompt如何迭代优化
- **Author:** 二次元的Datawhale
- **Views:** 7,416
- **Duration:** 806 seconds (about 13 minutes 26 seconds)Both videos are from a series on OpenAI Prompt courses by Andrew Ng, translated with code notes. They exceed your 600-second requirement. Is there a specific topic or type of video you're looking for within this length range?
通过结果可以看到,问到最小视频时,查找600秒以下的短视频,没有找到,在元数据中三个视频都超过300秒
3.自然语言转SQL查询
SQL(Text-to-SQL)利用大语言模型(LLM)将用户的自然语言问题,直接翻译成可以在数据库上执行的SQL查询语句。
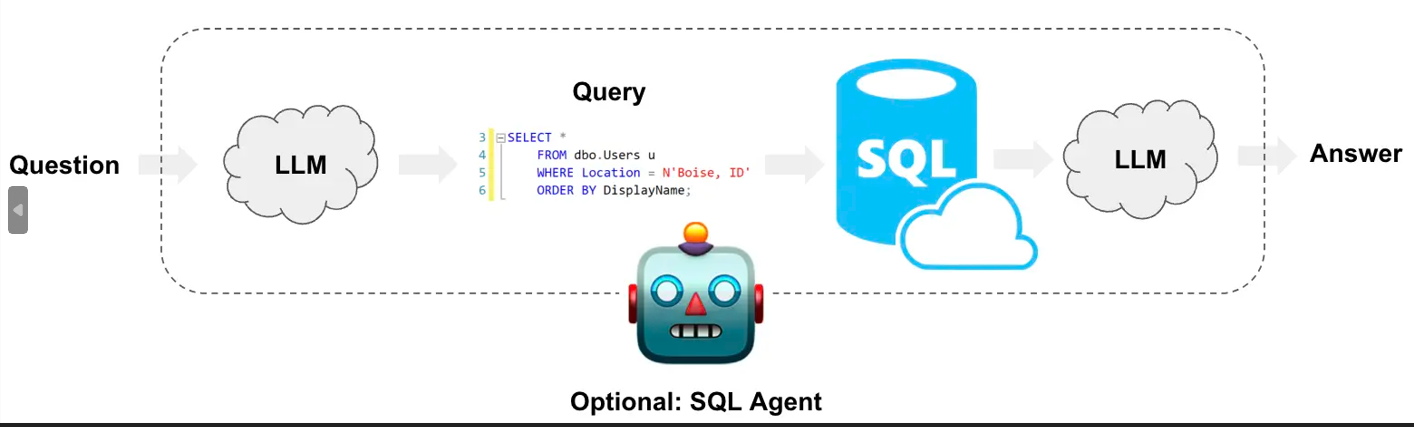
示例代码:
向量数据库text2sql
import os
import json
import sqlite3
from typing import List, Dict, Any
from sentence_transformers import SentenceTransformer
from pymilvus import connections, MilvusClient, FieldSchema, CollectionSchema, DataType, Collection
class BGESmallEmbeddingFunction:
"""BGE-Small中文嵌入函数,用于Text2SQL知识库向量化"""
def __init__(self, model_name="BAAI/bge-small-zh-v1.5", device="cpu"):
self.model_name = model_name
self.device = device
self.model = SentenceTransformer(model_name, device=device)
self.dense_dim = self.model.get_sentence_embedding_dimension()
def encode_text(self, texts):
"""编码文本为密集向量"""
if isinstance(texts, str):
texts = [texts]
embeddings = self.model.encode(
texts,
normalize_embeddings=True,
batch_size=16,
convert_to_numpy=True
)
return embeddings
@property
def dim(self):
"""返回向量维度"""
return self.dense_dim
class SimpleKnowledgeBase:
"""简化的知识库,使用BGE-Small进行向量检索"""
def __init__(self, milvus_uri: str = "http://localhost:19530"):
self.milvus_uri = milvus_uri
self.collection_name = "text2sql_knowledge_base"
self.milvus_client = None
self.collection = None
self.embedding_function = BGESmallEmbeddingFunction(
model_name="BAAI/bge-small-zh-v1.5",
device="cpu"
)
self.sql_examples = []
self.table_schemas = []
self.data_loaded = False
def connect_milvus(self):
"""连接Milvus数据库"""
connections.connect(uri=self.milvus_uri)
self.milvus_client = MilvusClient(uri=self.milvus_uri)
return True
def create_collection(self):
"""创建Milvus集合"""
if not self.milvus_client:
self.connect_milvus()
if self.milvus_client.has_collection(self.collection_name):
self.milvus_client.drop_collection(self.collection_name)
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="content_type", dtype=DataType.VARCHAR, max_length=50),
FieldSchema(name="question", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="sql", dtype=DataType.VARCHAR, max_length=2000),
FieldSchema(name="description", dtype=DataType.VARCHAR, max_length=1000),
FieldSchema(name="table_name", dtype=DataType.VARCHAR, max_length=100),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=self.embedding_function.dim)
]
schema = CollectionSchema(fields, description="Text2SQL知识库")
self.collection = Collection(name=self.collection_name, schema=schema, consistency_level="Strong")
index_params = {"index_type": "AUTOINDEX", "metric_type": "IP", "params": {}}
self.collection.create_index("embedding", index_params)
return True
def load_data(self):
"""加载知识库数据"""
data_dir = os.path.join(os.path.dirname(__file__), "data")
self.load_sql_examples(data_dir)
self.load_table_schemas(data_dir)
self.vectorize_and_store()
self.data_loaded = True
def load_sql_examples(self, data_dir: str):
"""加载SQL示例"""
sql_examples_path = os.path.join(data_dir, "qsql_examples.json")
default_examples = [
{"question": "查询所有用户信息", "sql": "SELECT * FROM users", "description": "获取用户记录", "database": "sqlite"},
{"question": "年龄大于30的用户", "sql": "SELECT * FROM users WHERE age > 30", "description": "年龄筛选", "database": "sqlite"},
{"question": "统计用户总数", "sql": "SELECT COUNT(*) as user_count FROM users", "description": "用户计数", "database": "sqlite"},
{"question": "查询库存不足的产品", "sql": "SELECT * FROM products WHERE stock < 50", "description": "库存筛选", "database": "sqlite"},
{"question": "查询用户订单信息", "sql": "SELECT u.name, p.name, o.quantity FROM orders o JOIN users u ON o.user_id = u.id JOIN products p ON o.product_id = p.id", "description": "订单详情", "database": "sqlite"},
{"question": "按城市统计用户", "sql": "SELECT city, COUNT(*) as count FROM users GROUP BY city", "description": "城市分组", "database": "sqlite"}
]
if os.path.exists(sql_examples_path):
with open(sql_examples_path, 'r', encoding='utf-8') as f:
self.sql_examples = json.load(f)
else:
self.sql_examples = default_examples
os.makedirs(data_dir, exist_ok=True)
with open(sql_examples_path, 'w', encoding='utf-8') as f:
json.dump(self.sql_examples, f, ensure_ascii=False, indent=2)
def load_table_schemas(self, data_dir: str):
"""加载表结构信息"""
schema_path = os.path.join(data_dir, "table_schemas.json")
default_schemas = [
{
"table_name": "users",
"description": "用户信息表",
"columns": [
{"name": "id", "type": "INTEGER", "description": "用户ID"},
{"name": "name", "type": "VARCHAR", "description": "用户姓名"},
{"name": "age", "type": "INTEGER", "description": "用户年龄"},
{"name": "email", "type": "VARCHAR", "description": "邮箱地址"},
{"name": "city", "type": "VARCHAR", "description": "所在城市"},
{"name": "created_at", "type": "DATETIME", "description": "创建时间"}
]
},
{
"table_name": "products",
"description": "产品信息表",
"columns": [
{"name": "id", "type": "INTEGER", "description": "产品ID"},
{"name": "product_name", "type": "VARCHAR", "description": "产品名称"},
{"name": "category", "type": "VARCHAR", "description": "产品类别"},
{"name": "price", "type": "DECIMAL", "description": "产品价格"},
{"name": "stock", "type": "INTEGER", "description": "库存数量"},
{"name": "description", "type": "TEXT", "description": "产品描述"}
]
},
{
"table_name": "orders",
"description": "订单信息表",
"columns": [
{"name": "id", "type": "INTEGER", "description": "订单ID"},
{"name": "user_id", "type": "INTEGER", "description": "用户ID"},
{"name": "product_id", "type": "INTEGER", "description": "产品ID"},
{"name": "quantity", "type": "INTEGER", "description": "购买数量"},
{"name": "total_price", "type": "DECIMAL", "description": "总价格"},
{"name": "order_date", "type": "DATETIME", "description": "订单日期"}
]
}
]
if os.path.exists(schema_path):
with open(schema_path, 'r', encoding='utf-8') as f:
self.table_schemas = json.load(f)
else:
self.table_schemas = default_schemas
os.makedirs(data_dir, exist_ok=True)
with open(schema_path, 'w', encoding='utf-8') as f:
json.dump(self.table_schemas, f, ensure_ascii=False, indent=2)
def vectorize_and_store(self):
"""向量化数据并存储到Milvus"""
self.create_collection()
all_texts = []
all_metadata = []
for example in self.sql_examples:
text = f"问题: {example['question']} SQL: {example['sql']} 描述: {example.get('description', '')}"
all_texts.append(text)
all_metadata.append({
"content_type": "sql_example",
"question": example['question'],
"sql": example['sql'],
"description": example.get('description', ''),
"table_name": ""
})
for schema in self.table_schemas:
columns_desc = ", ".join([f"{col['name']} ({col['type']}): {col.get('description', '')}"
for col in schema['columns']])
text = f"表 {schema['table_name']}: {schema['description']} 字段: {columns_desc}"
all_texts.append(text)
all_metadata.append({
"content_type": "table_schema",
"question": "",
"sql": "",
"description": schema['description'],
"table_name": schema['table_name']
})
embeddings = self.embedding_function.encode_text(all_texts)
insert_data = []
for i, (embedding, metadata) in enumerate(zip(embeddings, all_metadata)):
insert_data.append([
metadata["content_type"],
metadata["question"],
metadata["sql"],
metadata["description"],
metadata["table_name"],
embedding.tolist()
])
self.collection.insert(insert_data)
self.collection.flush()
self.collection.load()
def search(self, query: str, top_k: int = 5) -> List[Dict[str, Any]]:
"""搜索相关的知识库信息"""
if not self.data_loaded:
self.load_data()
query_embedding = self.embedding_function.encode_text([query])[0]
search_params = {"metric_type": "IP", "params": {}}
results = self.collection.search(
[query_embedding.tolist()],
anns_field="embedding",
param=search_params,
limit=top_k,
output_fields=["content_type", "question", "sql", "description", "table_name"]
)[0]
formatted_results = []
for hit in results:
result = {
"score": float(hit.distance),
"content_type": hit.entity.get("content_type"),
"question": hit.entity.get("question"),
"sql": hit.entity.get("sql"),
"description": hit.entity.get("description"),
"table_name": hit.entity.get("table_name")
}
formatted_results.append(result)
return formatted_results
def _fallback_search(self, query: str, top_k: int) -> List[Dict[str, Any]]:
"""降级搜索方法(简单文本匹配)"""
results = []
query_lower = query.lower()
for example in self.sql_examples:
question_lower = example['question'].lower()
sql_lower = example['sql'].lower()
score = 0
for word in query_lower.split():
if word in question_lower:
score += 2
if word in sql_lower:
score += 1
if score > 0:
results.append({
"score": score,
"content_type": "sql_example",
"question": example['question'],
"sql": example['sql'],
"description": example.get('description', ''),
"table_name": ""
})
results.sort(key=lambda x: x['score'], reverse=True)
return results[:top_k]
def add_sql_example(self, question: str, sql: str, description: str = ""):
"""添加新的SQL示例"""
new_example = {
"question": question,
"sql": sql,
"description": description,
"database": "sqlite"
}
self.sql_examples.append(new_example)
data_dir = os.path.join(os.path.dirname(__file__), "data")
sql_examples_path = os.path.join(data_dir, "qsql_examples.json")
with open(sql_examples_path, 'w', encoding='utf-8') as f:
json.dump(self.sql_examples, f, ensure_ascii=False, indent=2)
if self.collection and self.data_loaded:
text = f"问题: {question} SQL: {sql} 描述: {description}"
embedding = self.embedding_function.encode_text([text])[0]
insert_data = [[
"sql_example",
question,
sql,
description,
"",
embedding.tolist()
]]
self.collection.insert(insert_data)
self.collection.flush()
def cleanup(self):
"""清理资源"""
if self.collection:
self.collection.release()
if self.milvus_client and self.milvus_client.has_collection(self.collection_name):
self.milvus_client.drop_collection(self.collection_name)
def demo():
"""简单演示"""
# 模型测试
embedding_function = BGESmallEmbeddingFunction()
test_texts = ["查询用户", "统计数据"]
embeddings = embedding_function.encode_text(test_texts)
print(f"向量维度: {embeddings.shape}")
# 数据库查询演示
db_path = "demo.db"
if os.path.exists(db_path):
os.remove(db_path)
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
cursor.execute("CREATE TABLE users (id INTEGER PRIMARY KEY, name TEXT, age INTEGER, city TEXT)")
users_data = [(1, '张三', 25, '北京'), (2, '李四', 32, '上海'), (3, '王五', 35, '深圳')]
cursor.executemany("INSERT INTO users VALUES (?, ?, ?, ?)", users_data)
conn.commit()
# 执行查询
test_sqls = [
("查询所有用户", "SELECT * FROM users"),
("年龄大于30的用户", "SELECT * FROM users WHERE age > 30"),
("统计用户总数", "SELECT COUNT(*) FROM users")
]
for i, (question, sql) in enumerate(test_sqls, 1):
print(f"\n问题 {i}: {question}")
print("-" * 40)
print(f"SQL: {sql}")
cursor.execute(sql)
rows = cursor.fetchall()
if rows:
print(f"返回 {len(rows)} 行数据")
for j, row in enumerate(rows[:2], 1):
print(f" {j}. {row}")
if len(rows) > 2:
print(f" ... 还有 {len(rows) - 2} 行")
else:
print("无数据返回")
conn.close()
os.remove(db_path)
if __name__ == "__main__":
demo()运行效果:


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)