ollama下载、安装与简单使用(windows10虚拟机)
Ollama下载、安装与简单使用(windows10虚拟机)围绕Ollama这一“大模型部署推理”利器,简单介绍了Ollama生态,然后说明了Ollama下载与安装,以及模型的安装方式(直接安装、GGUF导入、其他)与命令行简单使用,最后说明了Ollama的API简单使用、常用命令与应用集成问题。
目录
0 前言
windows10虚拟机部署ollma,并且为了便于向内网迁移
创作时间:2025年2月
1 Ollama生态介绍
(这部分偏向于生态介绍、概念理解与介绍,有基础的可以跳过)
用于本地运行LLM模型,是一个简明易用的本地大模型运行框架。
- 简化部署、提高推理效率
- 有模型仓库,一行命令拉取模型运行
- CPU推理,支持显卡加速
- 提供API接口,作为大模型服务器使用,便于开发(开发者角度)
- 广泛被作为本地大模型服务器使用,是使用其他大模型应用的前置(使用者角度)
Ollama官方网站:https://ollama.com/
中文文档(强烈推荐):Ollama 中文文档
1.1 层次定位
属于“大模型部署和推理工具”,负责大模型的部署、推理和优化,与SGLang、VLLM和LLaMA.cpp等属于同一层次。
下面是来自“智谱清言”的总结(个人觉着不错,顺便凝练了一下):
从大模型的整个角度来看,可以分为
- 基础设施层:(包括硬件和基础软件平台,如GPU、TPU、CPU等硬件,以及操作系统和基本的计算框架(如TensorFlow、PyTorch等))
- 模型层:(各种大语言模型本身,如GPT、LLaMA、DeepSeek等。这些模型是核心的智能引擎,负责生成文本、理解语言等)
- 工具和框架层:包括SGLang、Ollama、VLLM和LLaMA.cpp等工具,它们负责大模型的部署、推理和优化
- 应用层:包括各种具体的应用,如智能客服、内容创作、辅助科研、代码生成等。这些应用利用底层的大模型和工具来实现具体的业务功能
1.2 模型的“存在”
既然“工具和框架层”建立在“模型层”之上,就需要对模型的“存在”有一定了解。
模型本体就是权重、结构、优化器、训练配置等等,笔者在使用Keras2时便用model.save()和load_model()来保存模型用于复现与微调(用了自定义的损失函数还需要在load_model()时补充上...【1】)
而大语言模型(Large Language Model,LLM)主流采用PyTorch,主要保存方法torch.save()默认会将对象保存为PyTorch特定的格式(即.pth或.pt后缀)【2】,还有二进制的.bin文件【3】。在此基础上,HuggingFace设计了一种新格式.safetensors ,更安全高效并与HuggingFace生态下的 transformers 库集成【4】【5】。这些主要是为了模型的保存、再训练与推理。
llama.cpp是一个开源项目,专门为在本地CPU上部署量化模型而设计,为了更好的推理,llama.cpp 定义了一种高效存储和交换大模型预训练结果的二进制格式GGUF (GPT-Generated Unified Format)。而Ollama底层使用了llama.cpp,需要适配GGUF格式的模型文件(这也是为什么2025年2月在魔搭的免费CPU资源上使用大模型API选Ollama+GGUF)。当然,目前来看Ollama本身已经支持了从 PyTorch 或 Safetensors 导入模型。
省流:大模型本体可简单视为Safetensors 、GGUF格式的文件。
1.3 本质认识
1、命令行工具,LLM服务器
本身没有可视化图形界面,自带命令行工具,所以说相当于“服务器/后台”,Ollama 默认绑定 127.0.0.1 端口 11434(http://localhost:11434),可以通过设置环境变量的方式更改。其配套的可视化前端Web项目叫做“Open WebUI”,当然还有其他的一些,可以参考官方文档-社区集成
Open WebUI 是一个可扩展的自托管 WebUI,前身就是 Ollama WebUI,为 Ollama 提供一个可视化界面,可以完全离线运行,支持 Ollama 和兼容 OpenAI 的 API。
https://github.com/open-webui/open-webui
2、模型构建
- 直接从Ollama官方模型库拉取
- 下载GGUF、 Safetensors 格式模型(Huggingface或ModelScope)后,使用名为Modelfile 的文件导入
- 将PyTorch or Safetensors 类型模型,通过
llama.cpp进行转换、量化处理成 GGUF,使用名为 Modelfile的文件导入
2 虚拟机与Win10安装
参考其他博客,例如:
VMware Workstation 17 pro安装_vmware workstation17pro百度云-CSDN博客
记着在“虚拟机”菜单中“安装VMware Tools”,这样就可以自动缩放屏幕、共享粘贴板、设置共享文件夹等了~~~
Win10下载iso后,在VMware中选择后一步一步安装即可,也不用激活秘钥
3 Ollama下载、安装、简单使用
3.1 Ollama下载与安装
下载并安装Ollama
官网本身提供了下载链接, 官方网站windows版本下载:Download Ollama on Windows
值得注意的是,GitHub网站上也提供下载链接,(右下角的Releases)如下图
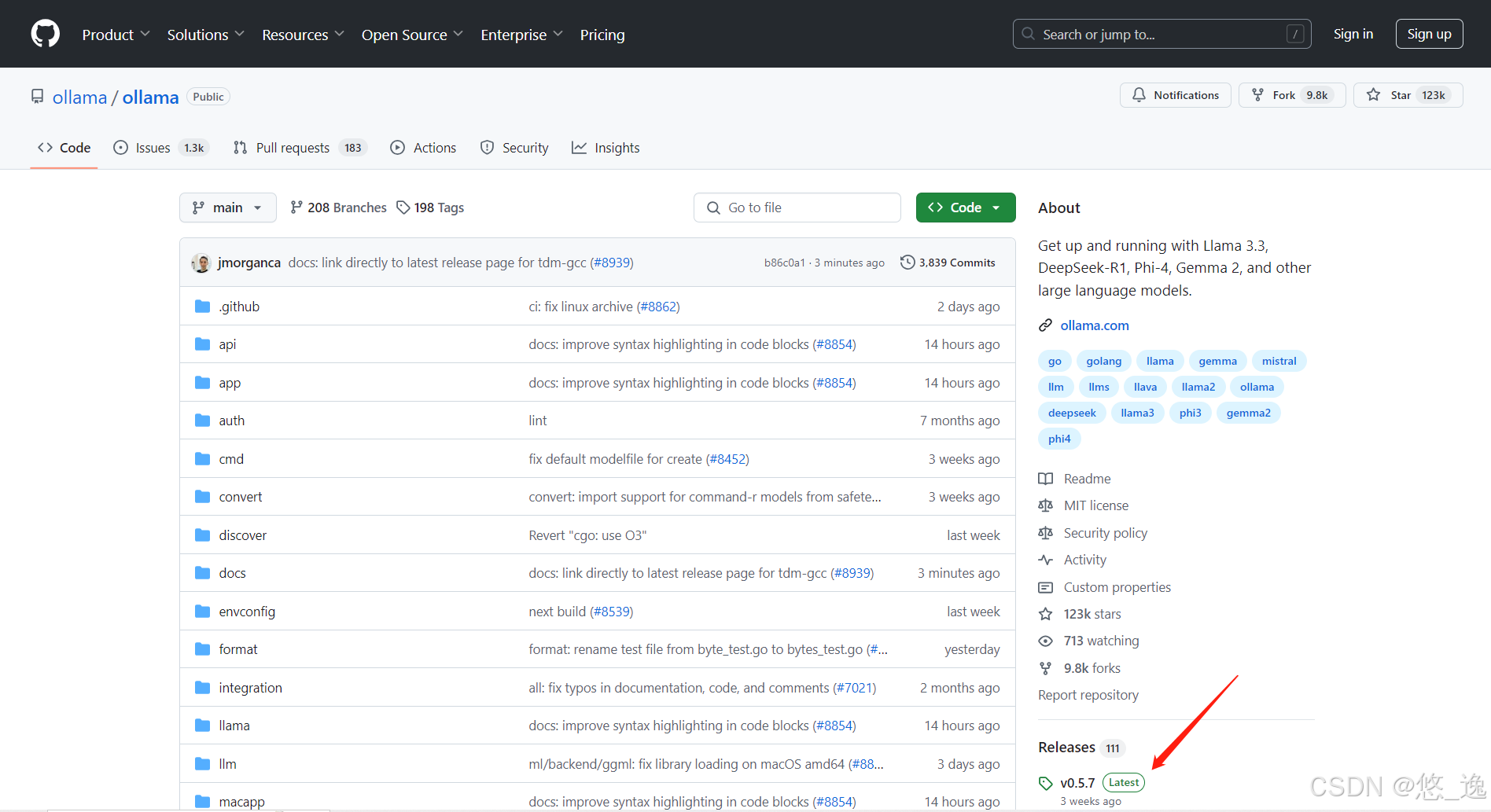
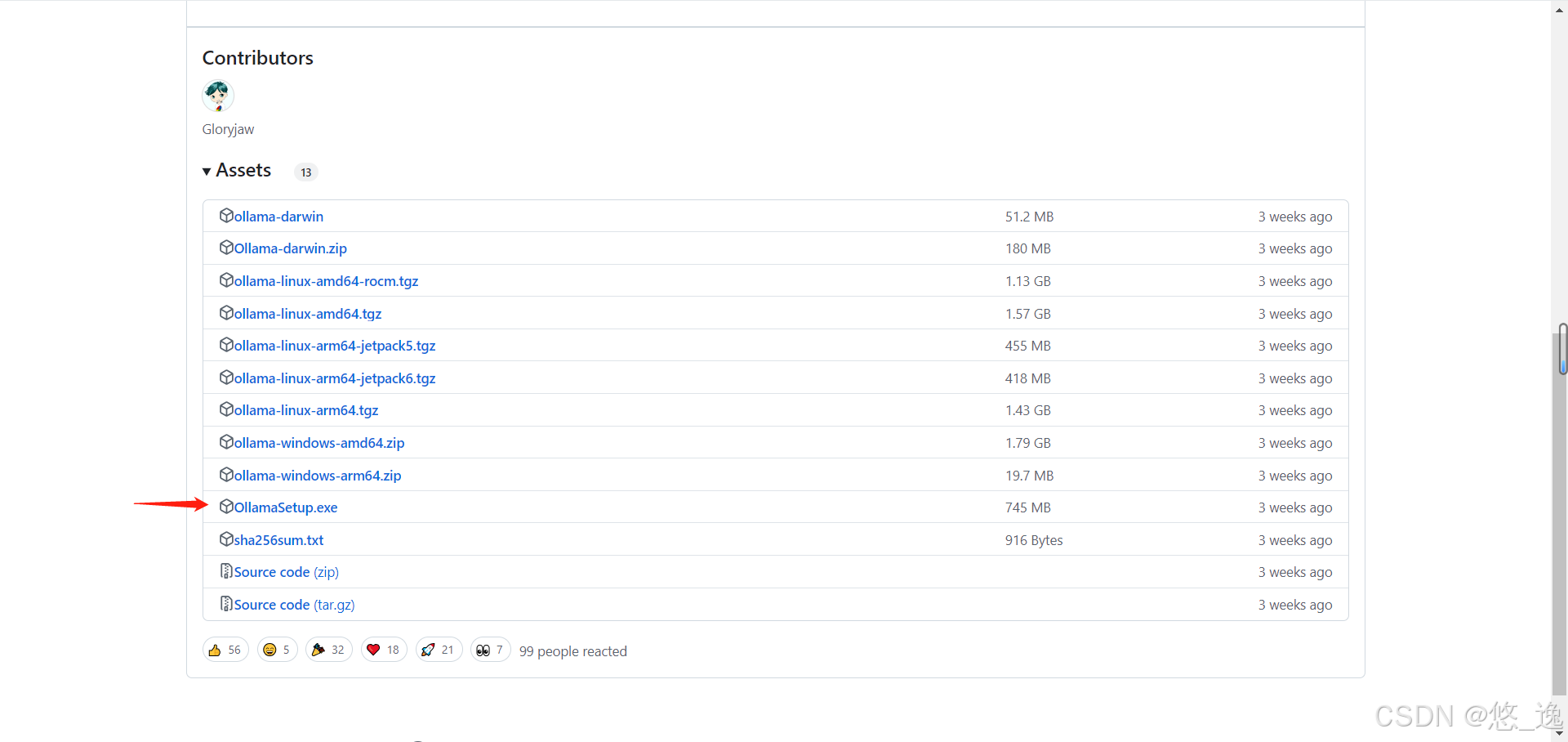
这里就不得不吐槽,,因为国内下载非常慢,,而Gitee的镜像加速上找不到Releases部分,尝试从CSDN上找百度网盘结果下载完报毒,,,最后从国内GitHub镜像站点下载下来的
另外,后来发现还有人“复制链接从某讯下载”【6】(这位确实很具有实践参考价值)
就是下面这个可爱的安装包,,直接安装即可,默认C盘似乎无法更改
后来发现,,官方文档上提供了,而且很详细,具体见文档(可惜我已经安装好了...)
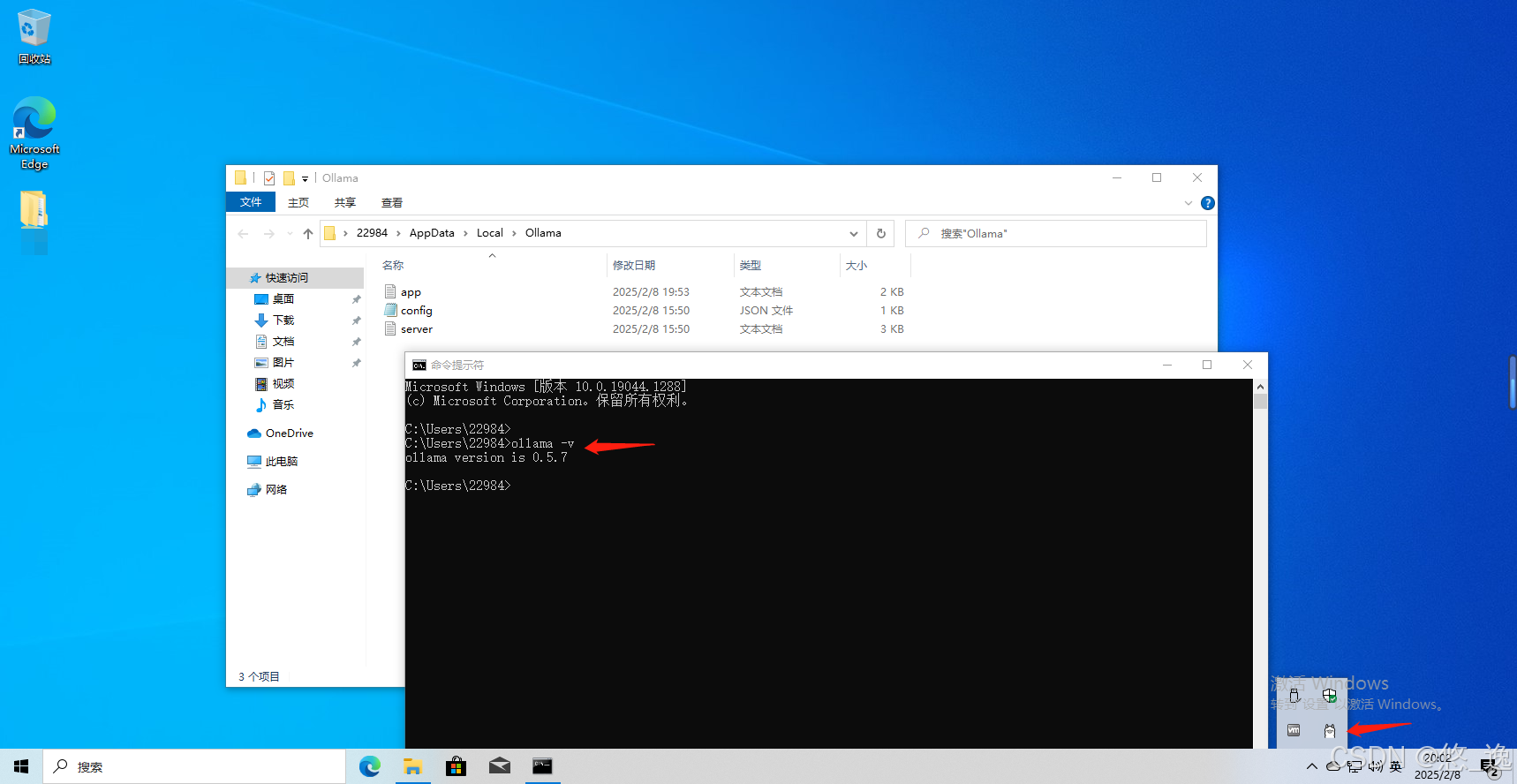
安装成功后,在右下角托盘区就会有Ollama的图标了,同时通过cmd的命令提示符工具测试命令:
ollama -v显示ollama版本信息,安装成功
3.2 模型安装与简单使用
3.2.1 更改模型路径
为了方便后续内网迁移,我们修改模型存储位置,便于找到,实际使用中也是为了合理规划磁盘空间。
编辑环境变量(可以直接通过“搜索栏”搜索“环境变量”),下面为官方文档描述,很清晰了,,
启动设置(Windows 11)或控制面板(Windows 10)应用程序,并搜索 环境变量。
点击 编辑账户环境变量。
编辑或创建一个新的用户账户变量
OLLAMA_MODELS,设置为你希望存储模型的路径。点击确定/应用以保存。
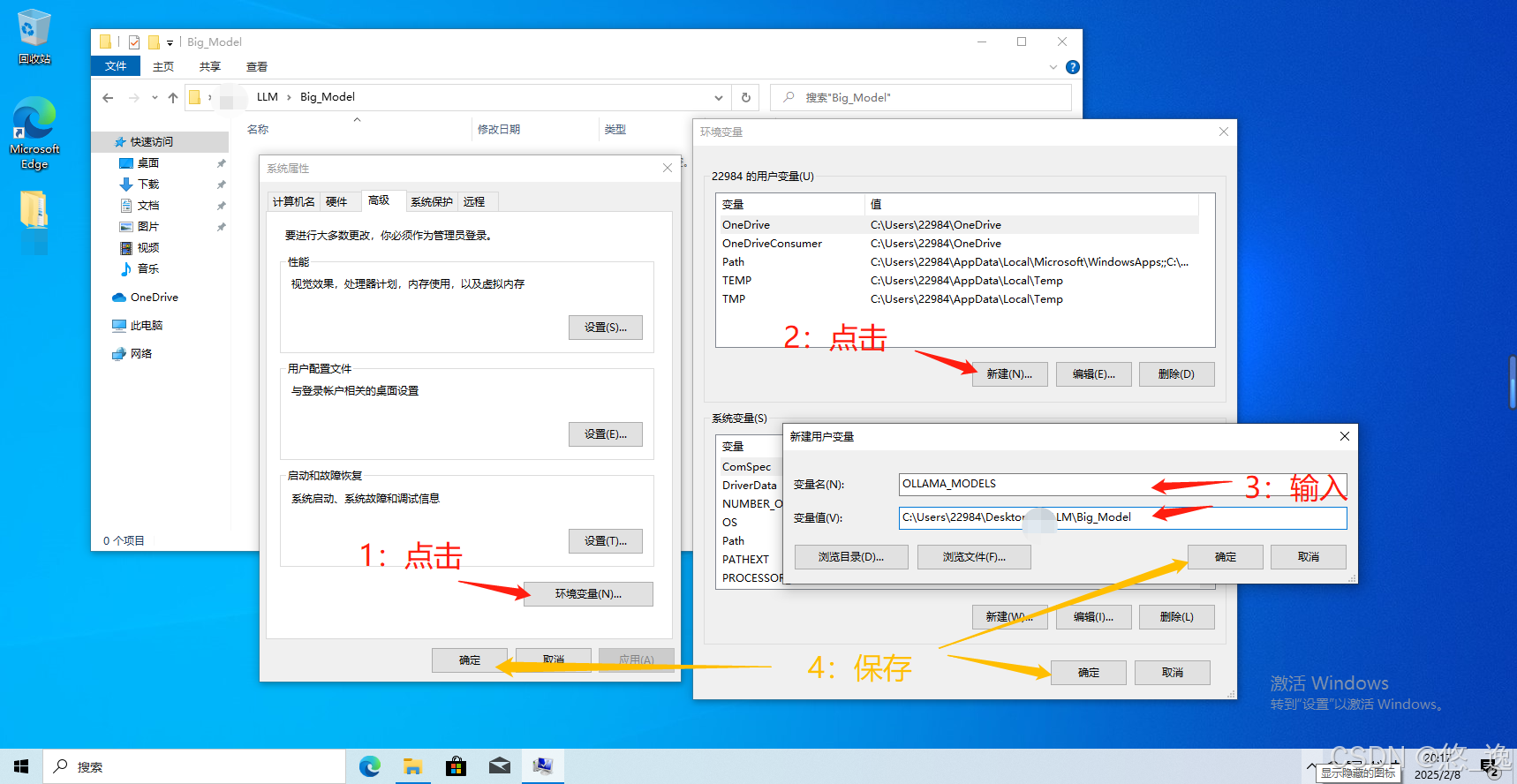
设置完环境变量后,请退出正在运行的Ollama(系统托盘中的应用程序),然后从开始菜单或在保存环境变量后启动的新终端中重新启动它。(改编自官方文档,非常严谨...)
3.2.2 安装:直接从Ollama官方模型库拉取
直接通过 Ollama 远程仓库下载,这是最直接的方式,也是最推荐、最常用的方式
Ollama官方模型库如下:library
就选择最近最火的deepseek-r1试一试吧,选一个最小的试验一下...
理论上,直接在命令行运行“run”即可,正如官网上所给的
ollama run deepseek-r1:1.5b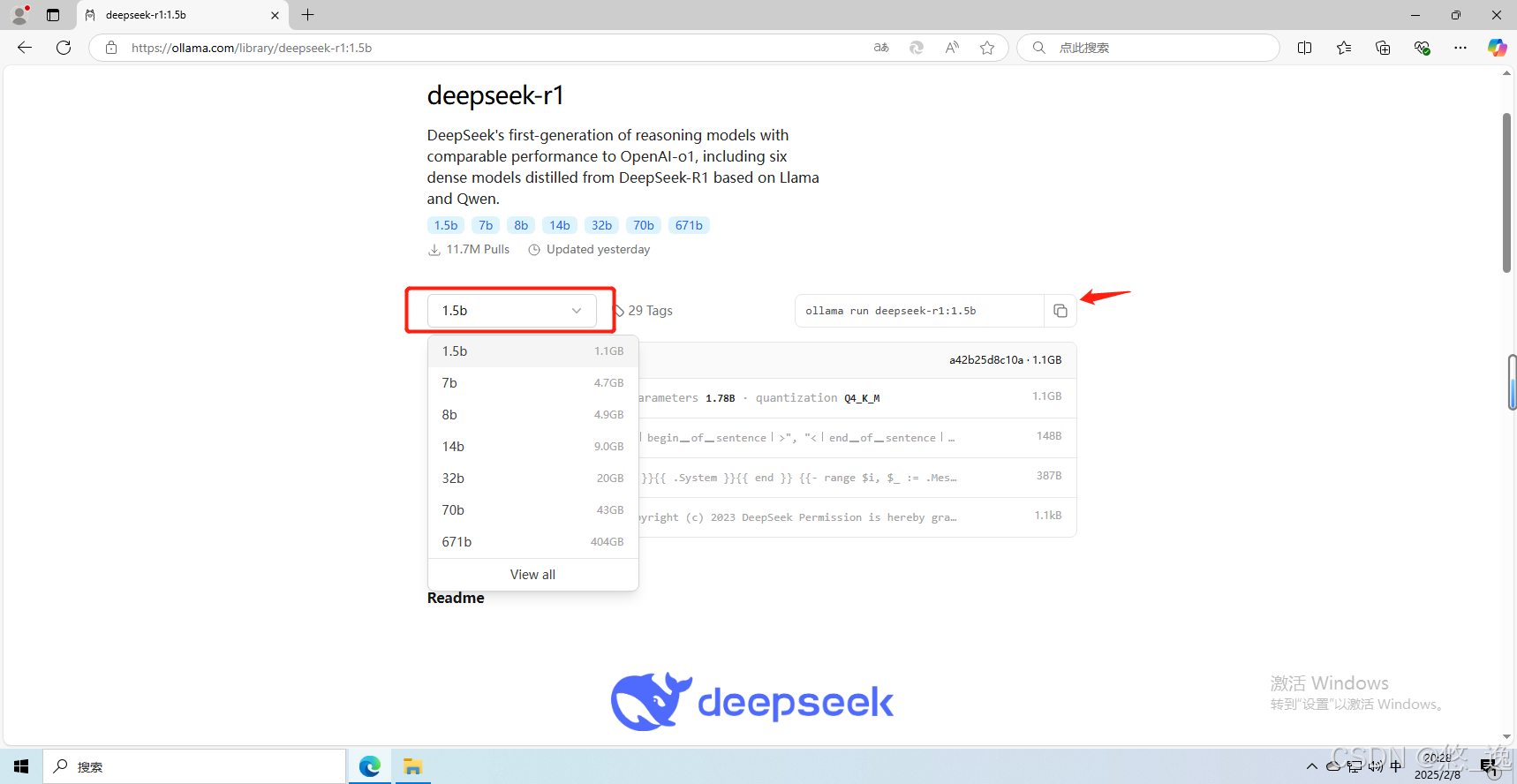
但经查还有“pull”命令,是正经的“下载模型”,即:若本地不存在大模型,则下载完整模型文件到本地磁盘;若本地磁盘存在该大模型,则增量下载大模型更新文件到本地磁盘。
而“run”命令是:若本地不存在大模型,则下载完整模型文件到本地磁盘(类似于pull命令),然后启动大模型;若本地存在大模型,则直接启动(不进行更新)【7】
所以采用先“pull”后“run”
(1)“pull”下载模型
可以看见已经在下载了(一开始下载速度还行后来就龟速了,而且越到后面越慢...)
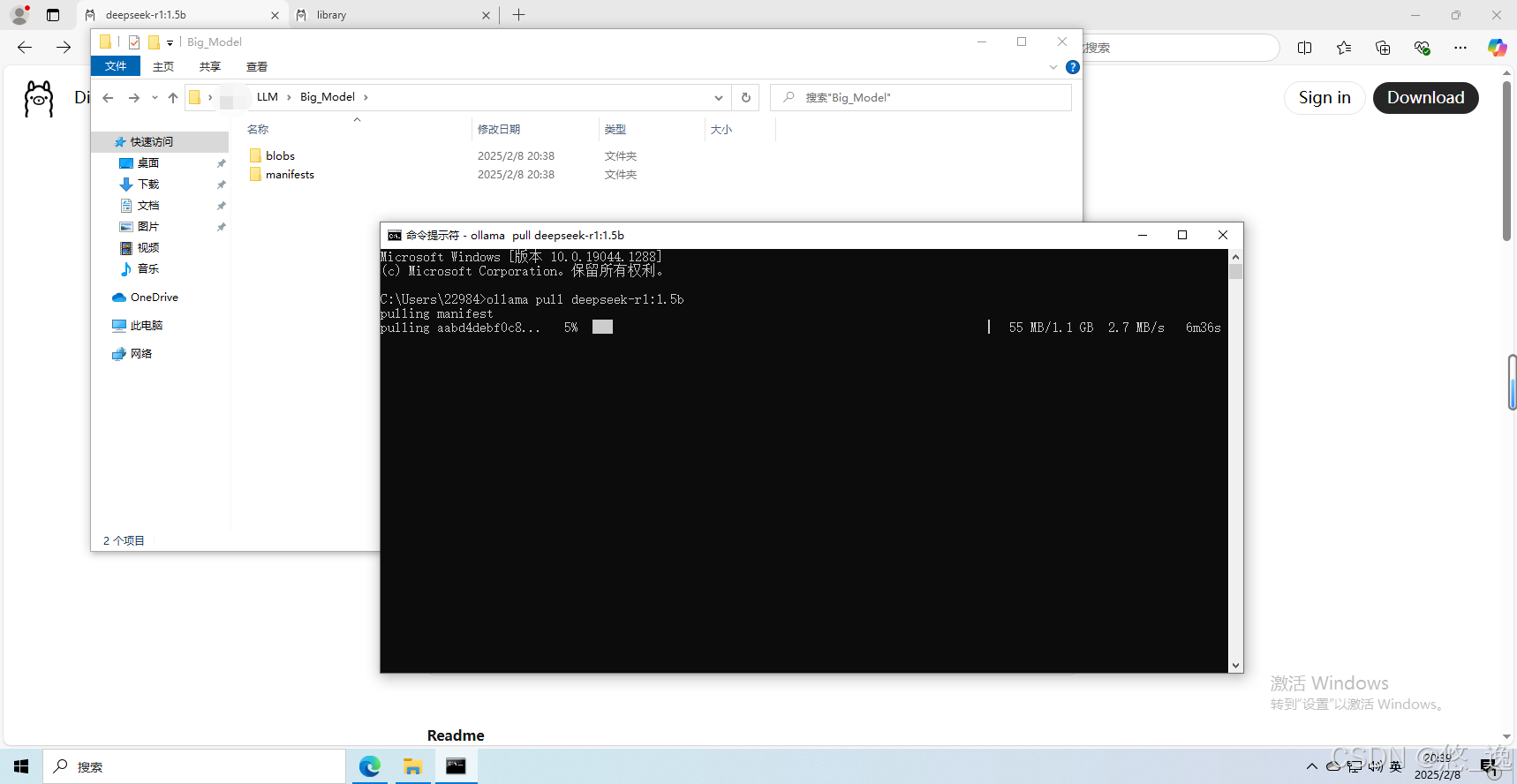
漫长的时间过去后(GGUF格式导入的部分都写完了...),,,重要下载完成,显示“success”后,能够通过“list”查询并“show”详细信息,同时在刚才指定的Ollama模型路径下可以找到对应文件。
(其实个人感觉,就是把GGUF文件、Modelfile文件和其他内容分别下载安装了...官方的Modelfile文件就是不一样)
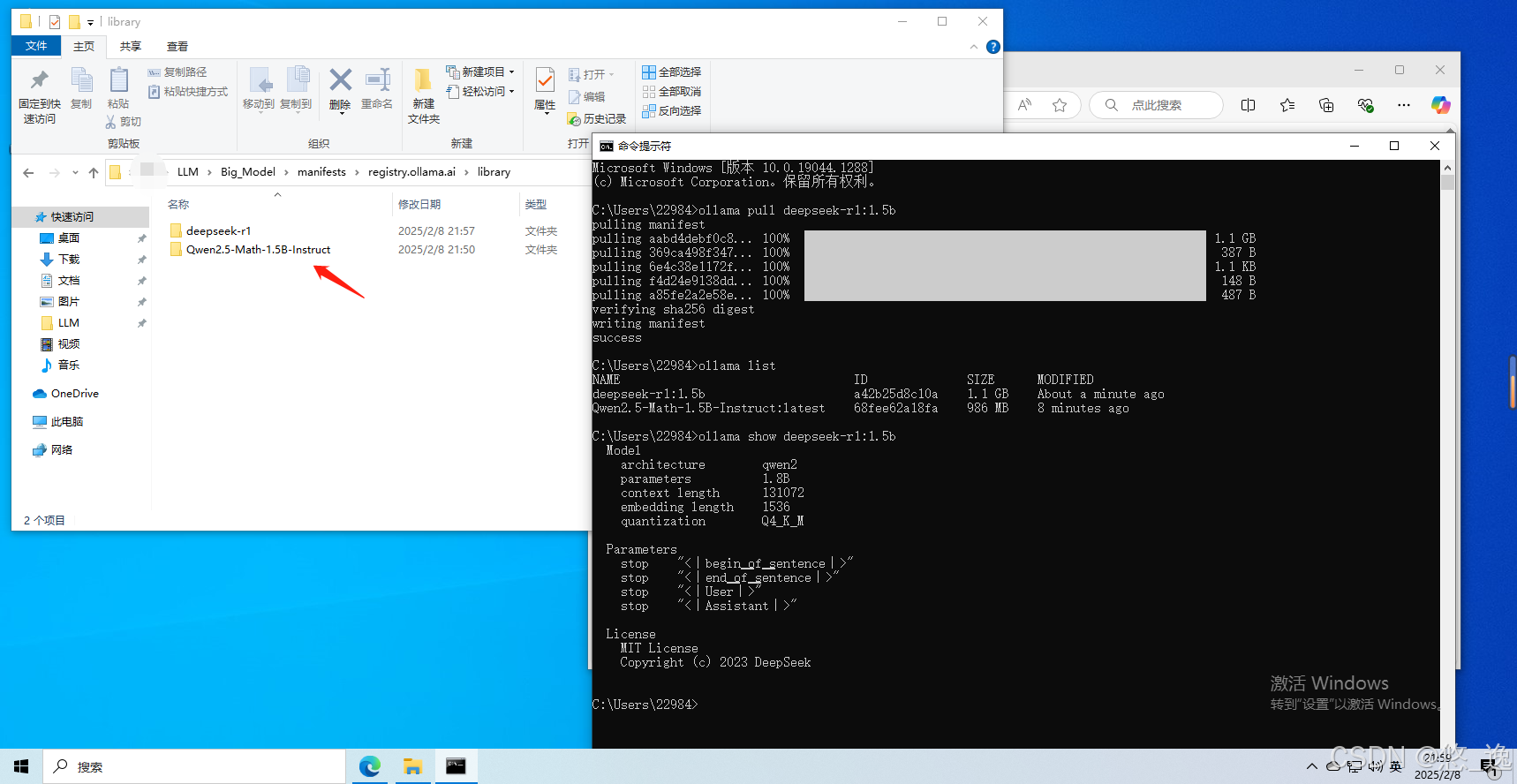
(2)“run”运行模型
直接运行模型,问了个简单的问题,虚拟机没通GPU,正常内存3G,运行模型后内存占了4.3G,CPU干满...(效果MAX)
ollama run deepseek-r1:1.5b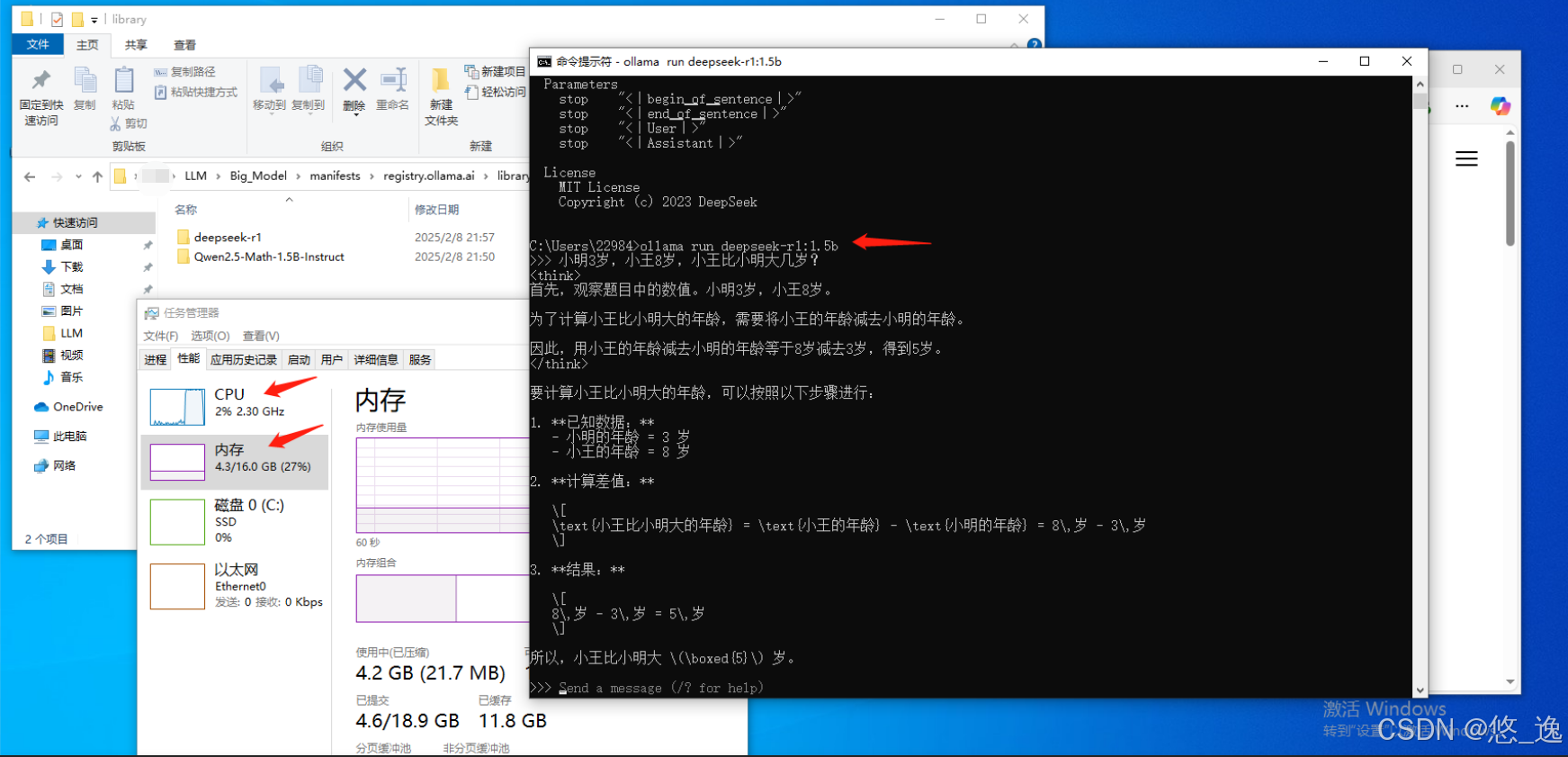
(3)模型的停止
模型一段时间后好像会自动停止,也可以手动停止,见本文 3.3常用命令部分。
3.2.3 安装:GGUF格式导入
(1)下载GGUF与编写Modelfile
据说DeepSeek-R1-Distill-Qwen 1.5是Qwen2.5-Math-1.5B的蒸馏版,专注于数学和逻辑推理。那就从魔搭下载Qwen2.5-Math-1.5B-Instruct.Q4_K_M.gguf,用来测试导入吧。
这里需要使用Modelfile文件,其语法较复杂且还在完善,主要包括:模型位置、运行参数、提示词模版、LoRA适配器、许可证等,不展开了,可以参考下列博客的相关内容:
Ollama内网离线部署大模型_ollama离线部署模型-CSDN博客
https://zhuanlan.zhihu.com/p/711930447
在这里就从简处理好了,只单纯导入模型即可,创建Modelfile文件,使用FROM指令引入模型路径,格式为:
FROM ./ollama-model.ggufGGUF 文件的位置应指定为绝对路径或相对于 Modelfile 的位置。Modelfile文件与GGUF在同一文件夹下,即:
FROM ./Qwen2.5-Math-1.5B-Instruct.Q4_K_M.gguf(2)创建模型
然后在命令行中,cd到该文件夹下,按照如下格式在Ollama中创建模型:
ollama create <your-model-name> -f <./Modelfile>
<your-model-name>即为模型的名字,<./Modelfile>为Modelfile文件相对位置,即
ollama create Qwen2.5-Math-1.5B-Instruct -f ./Modelfile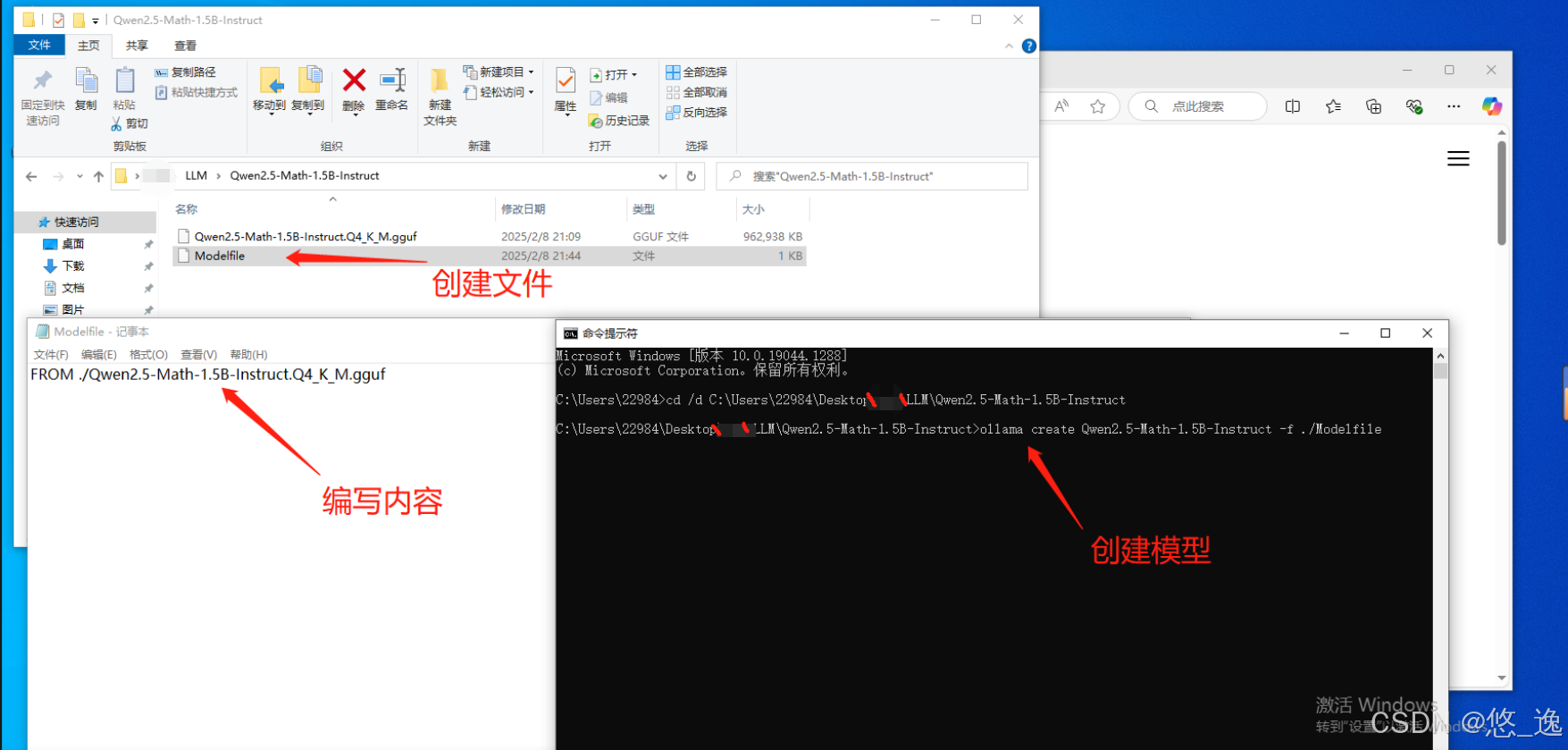
回车,便开始创建模型(或者说注册...),显示“success”后,能够通过“list”查询并“show”详细信息,同时在刚才指定的Ollama模型路径下可以找到对应文件。
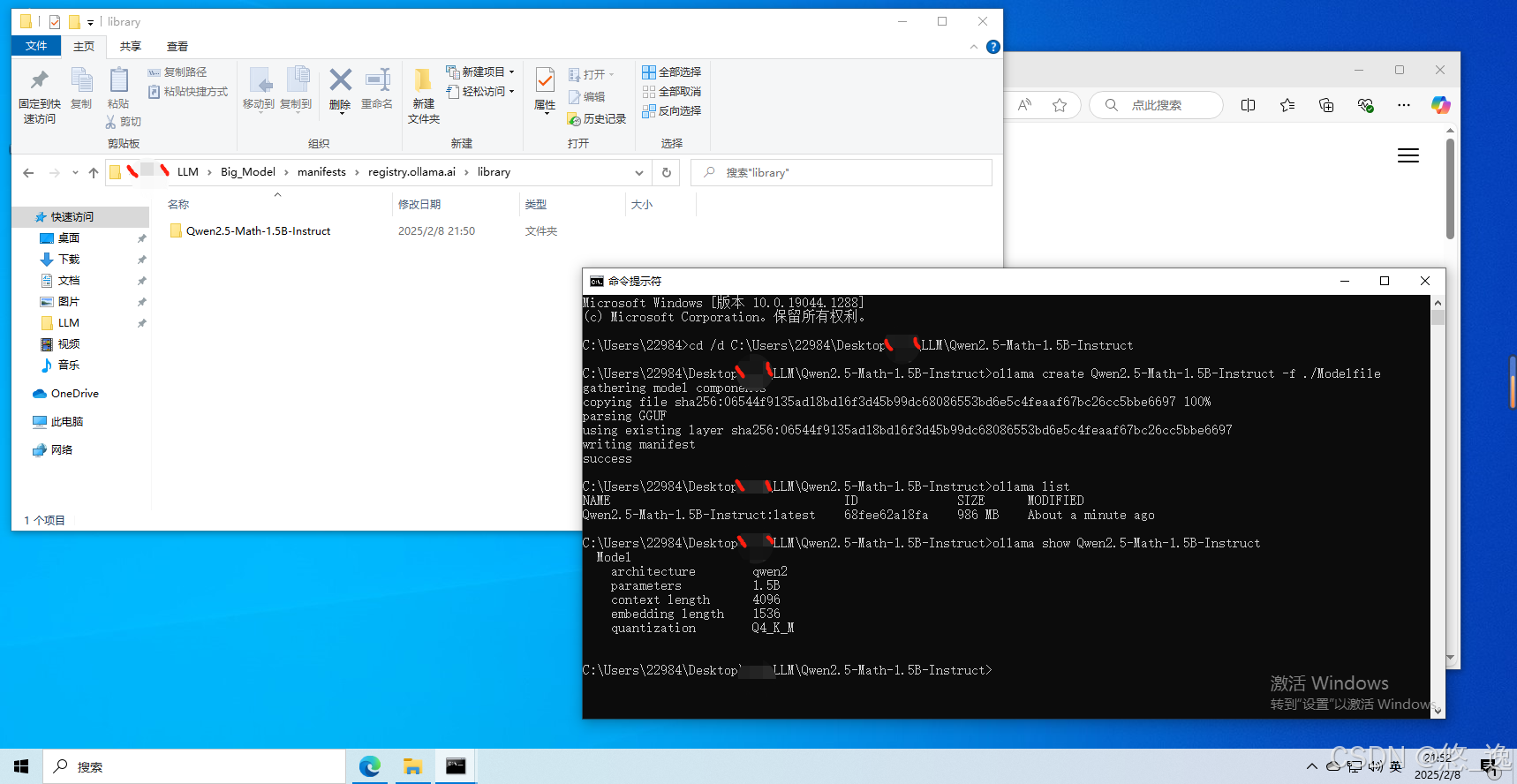
(3)运行模型
直接运行模型,问个问题测试一下,OK

题外话:原本内存占用4.3G,加了一个然后升到5.5G,虽然推理CPU就100%,,,但,简直了,我主机直接自建环境,运行Qwen2.5 0.5B模型独立GPU还占用2G呢...............
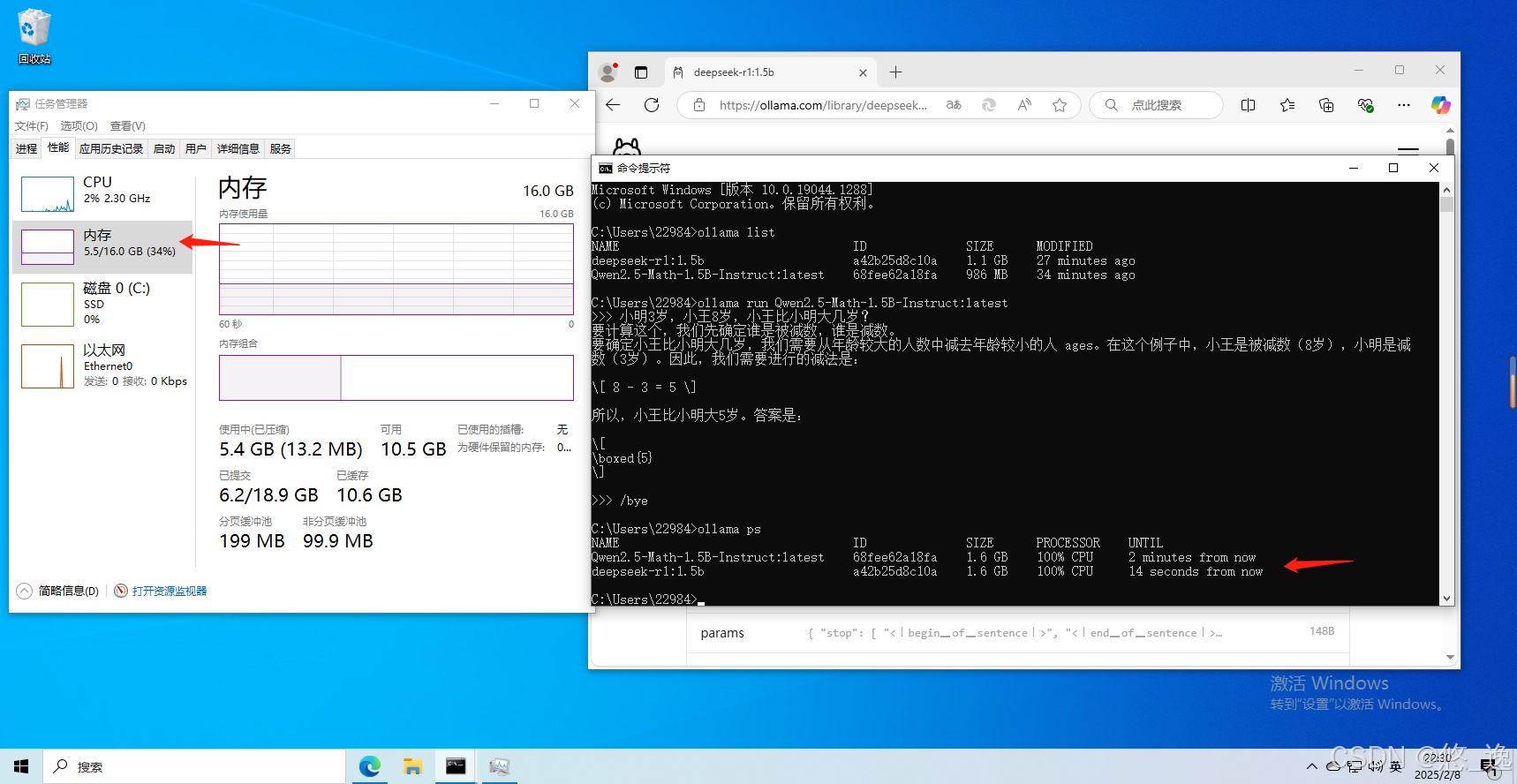
3.2.4 安装:从 Safetensors 权重导入模型
尚未实践(该部分理论上与3.2.2 GGUF一致....先挖坑有空再填)
官网指导:导入模型 - Ollama 中文文档
3.2.5 使用 Llama.cpp 转化为GGUF
没试过,,,可以单列一篇了,可以参考下面这个:(它说Ollama不直接支持Safetensors ,但官方文档上说可以,,不知道是不是更新过)本地部署大模型?Ollama 部署和实战,看这篇就够了!_ollama配置-CSDN博客
3.2.6 其他
(还有量化、适配器(感觉是使用微调 LoRA的配套)等等,尚未实践)
3.3 API简单使用
只有命令行可不够,需要通过API接口向其他应用提供大模型推理服务。该部分也比较复杂,这里制作简单演示,毕竟是“简单使用”嘛~
Ollama 默认绑定 127.0.0.1 端口 11434(http://localhost:11434),可以通过设置环境变量的方式更改。参考官方文档,并用“智谱清言”优化一个命令行命令:
curl -X POST http://localhost:11434/api/generate -H "Content-Type: application/json" -d "{\"model\": \"Qwen2.5-Math-1.5B-Instruct:latest\", \"prompt\": \"小王3岁,小李2岁,小王小李大几岁?\", \"stream\": false}"
即使用curl工具,向http://localhost:11434/api/generate,发送了json如下:
{
"model": "Qwen2.5-Math-1.5B-Instruct:latest",
"prompt": "小王3岁,小李2岁,小王小李大几岁?",
"stream": false
}向模型提问问题,不使用流式响应,(注意,该模型适用于数学问题,问常识问题会发疯...)
(有结果是有结果,,但我完全不知道它在说什么...但命令行问就正常,,应该是API调用有问题,不过演示是够了。。。)
具体可以参考API 参考 - Ollama 中文文档,并且可以与OpenAI兼容,OpenAI 兼容性 - Ollama 中文文档,这块是对于LLM应用开发者所需要的。
3.4 Ollama常用命令
(1)展示本地大模型列表
ollama list(2)运行某个大模型
ollama run 大模型名称(3)退出命令行对话
# 退出命令
/bye(4)查看本地运行中模型列表
ollama ps(5)停止当前正在运行的模型
ollama stop 正运行的大模型名称(6)复制本地大模型
ollama cp 本地存在的模型名 新复制模型名(7)删除单个本地大模型
ollama rm 本地模型名称(8)不运行桌面应用程序的情况下启动 Ollama
ollama serve4 应用集成
这个就比较多了(以聊天和本地知识库为主...),比如:
- OneAPI :方便管理和分发 API 密钥的工具,它支持多个常用的 LLMs 服务,用户可以轻松管理多个LLMs服务的密钥,并进行二次分发管理。“阀门”
- Open WebUI:可视化界面,聊天
- AnythingLLM:本地知识库,支持多种 LLM、嵌入模型和向量数据库
- ......
注:默认情况下,模型在生成响应后会在内存中保留 5 分钟。要预加载模型并使其保留在内存中,请使用【9】:
curl http://localhost:11434/api/generate -d '{"model": "llama3", "keep_alive": -1}'
参考
感谢各位大佬!
【1】Keras如何保存、加载Keras模型_keras保存模型-CSDN博客
【2】PyTorch 模型保存与加载的三种常用方式_pytorch保存和加载模型-CSDN博客
【3】模型相关.pt和.bin文件在PyTorch中的用途以及存储和加载方式_torch.load可以加载bin文件吗-CSDN博客
【4】Safetensors,高效安全易用的深度学习新工具-CSDN博客
【5】深入了解 大模型参数文件存储格式-Safetensors_.safetensors-CSDN博客
【6】ollama本地部署一些问题和收集gpu占用率为0解决方案_ollama gpu利用率很低-CSDN博客
【7】Ollama完整教程:本地LLM管理、WebUI对话、Python/Java客户端API应用_name id size modified-CSDN博客
【8】GPU使用问题:ollama本地部署一些问题和收集gpu占用率为0解决方案_ollama gpu利用率很低-CSDN博客
【9】模型保持问题:ollama如何保持模型加载在内存(显存)中或立即卸载_ollama卸载模型-CSDN博客
【10】Ollama 中文文档

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)