【AI大模型前沿】Ming-UniAudio:蚂蚁集团开源的多功能统一语音大模型
Ming-UniAudio 是蚂蚁集团开源的一个创新语音处理项目,旨在通过统一的连续语音分词器 MingTok-Audio 和端到端的语音语言模型,实现语音理解、生成和编辑任务的高效融合。MingTok-Audio 基于 VAE 框架和因果 Transformer 架构,能够有效整合语义和声学特征,为语音理解和生成任务提供统一的表示。在此基础上,Ming-UniAudio 开发了一个端到端的语音语
系列篇章💥
前言
在人工智能领域,语音处理技术一直是研究的热点之一。随着大语言模型(LLM)的快速发展,语音语言模型在语音理解、生成和编辑等方面取得了显著进展。然而,现有的大多数语音模型要么将理解与生成任务的表示分离,要么采用离散化表示,导致语音细节损失。为了解决这些问题,蚂蚁集团推出了Ming-UniAudio,这是一个基于统一连续分词器的语音大模型,能够同时处理语音理解、生成和编辑任务。
一、项目概述
Ming-UniAudio 是蚂蚁集团开源的一个创新语音处理项目,旨在通过统一的连续语音分词器 MingTok-Audio 和端到端的语音语言模型,实现语音理解、生成和编辑任务的高效融合。MingTok-Audio 基于 VAE 框架和因果 Transformer 架构,能够有效整合语义和声学特征,为语音理解和生成任务提供统一的表示。在此基础上,Ming-UniAudio 开发了一个端到端的语音语言模型,支持语音理解和生成任务,并通过扩散头技术确保高质量的语音合成。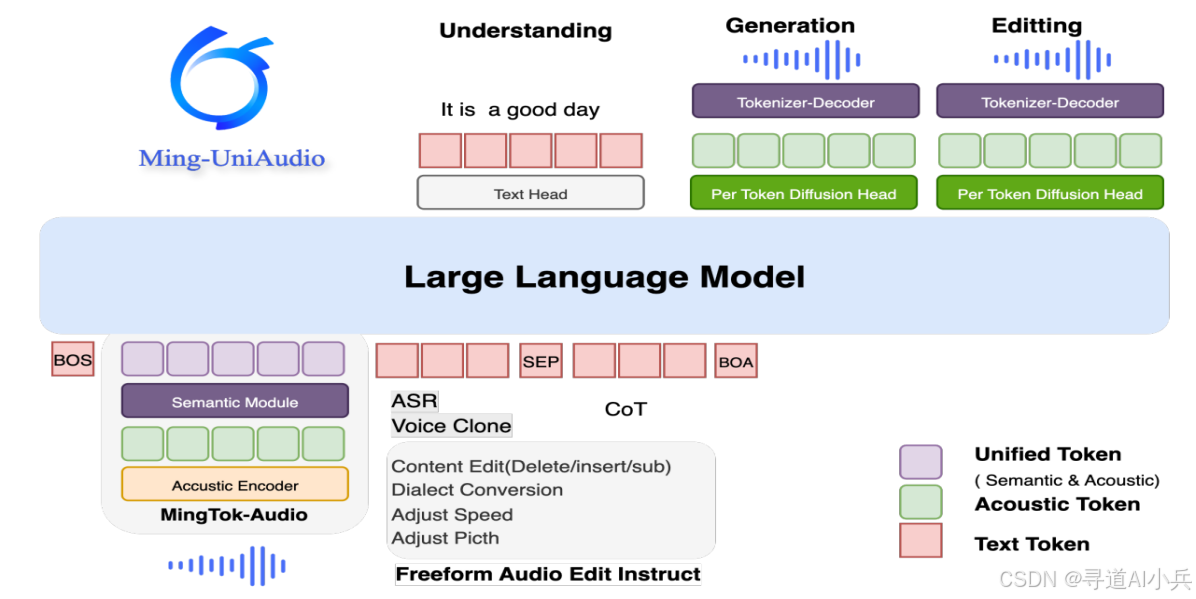
二、核心功能
(一)语音理解
能够准确识别多种语言和方言的语音内容,并将其转录为文本。这使得它在语音助手、会议记录等场景中表现出色,能够实时提供准确的语音识别结果。同时支持多种语言和方言,包括但不限于普通话、英语、湖南话、闽南话等,极大地扩展了其应用场景。
(二)语音生成
根据文本生成自然流畅的语音,适用于有声读物、语音播报等应用。生成的语音不仅自然,而且具有高相似度,接近真人发音。通过扩散头技术,确保生成语音的高质量和自然度,提供优质的听觉体验。
(三)语音编辑
支持自由形式的语音编辑,如插入、删除、替换等操作,无需手动指定编辑区域。这使得音频后期制作和语音内容创作更加高效。通过自然语言指令引导的语音编辑,简化了编辑流程,提高了用户体验。例如,用户可以通过简单的指令完成复杂的语音编辑任务。
(四)多模态融合
支持文本和音频等多种模态输入,能够实现复杂的多模态交互任务。这使得模型在处理复杂的交互场景时更加灵活和强大。支持多种模态的输入和输出,提升了模型的通用性和适应性,适用于多种应用场景。
(五)高效分词
采用统一的连续语音分词器 MingTok-Audio,有效整合语义和声学特征,提升模型性能。这使得模型在处理语音任务时更加高效和准确。通过层次化的特征表示,MingTok-Audio 能够更好地捕捉语音的细节和语义信息。
(六)高质量合成
通过扩散头技术,确保生成语音的高质量和自然度。这使得生成的语音不仅自然,而且具有高相似度,接近真人发音。另外通过多任务学习,平衡了语音生成和理解的能力,提升了在不同任务上的性能表现。
(七)开源易用
提供开源代码和预训练模型,方便开发者快速部署和二次开发。这使得开发者可以轻松地在现有模型基础上进行定制和扩展。并提供详细的使用指南和示例,帮助开发者快速上手和应用。
三、技术揭秘
(一)统一连续语音分词器
Ming-UniAudio 的核心是 MingTok-Audio,一个基于 VAE(变分自编码器)框架和因果 Transformer 架构的连续语音分词器。它能够有效整合语义和声学特征,为语音理解和生成任务提供统一的表示。这种分词器不仅支持层次化的特征表示,还能通过连续的特征空间捕捉语音的细节和语义信息,从而实现高质量的语音处理。
(二)端到端语音语言模型
Ming-UniAudio 预训练了一个端到端的语音语言模型,支持语音理解和生成任务。该模型通过单个语言模型(LLM)主干网络进行预训练,结合扩散头技术确保高质量的语音合成。这种设计不仅提高了模型在语音任务上的性能,还通过多任务学习平衡了生成和理解的能力,使其在多种任务中表现出色。
(三)指令引导的自由形式语音编辑
Ming-UniAudio 引入了首个指令引导的自由形式语音编辑框架,支持复杂的语义和声学修改。用户可以通过自然语言指令完成插入、删除、替换等编辑操作,无需手动指定编辑区域。这种设计极大地简化了语音编辑流程,提高了用户体验,适用于音频后期制作和语音内容创作。
(四)多模态融合
Ming-UniAudio 支持文本和音频等多种模态输入,能够实现复杂的多模态交互任务。这种多模态融合不仅提升了模型的通用性和灵活性,还使其在处理复杂的交互场景时更加高效。例如,在语音助手和智能对话系统中,模型可以同时处理语音和文本输入,提供更加自然和流畅的交互体验。
(五)高质量语音合成
Ming-UniAudio 通过扩散模型技术生成高质量、自然流畅的语音。这种技术确保了生成语音的高质量和自然度,使其接近真人发音。无论是在有声读物、语音播报还是其他语音生成场景中,Ming-UniAudio 都能提供优质的听觉体验,满足用户对语音质量的高要求。
(六)多任务学习
Ming-UniAudio 通过多任务学习平衡了语音生成和理解的能力。这种学习方式不仅提高了模型在不同任务上的性能,还增强了其在复杂场景中的适应性。通过大规模音频和文本数据的预训练,Ming-UniAudio 能够更好地理解和生成语音内容,从而在多种语音处理任务中表现出色。
(七)大规模预训练
Ming-UniAudio 基于大规模音频和文本数据进行预训练,极大地增强了模型的语言理解和生成能力。这种大规模预训练不仅提高了模型的性能,还使其能够处理复杂的语音任务。通过丰富的数据和先进的训练方法,Ming-UniAudio 在语音理解、生成和编辑任务中都取得了显著的成果,为语音处理领域的发展提供了新的思路和方法。
四、基准评测
(一)语音分词
在 Seed-zh 和 Seed-en 数据集上,MingTok-Audio 的 PESQ、SIM 和 STOI 指标均优于其他模型。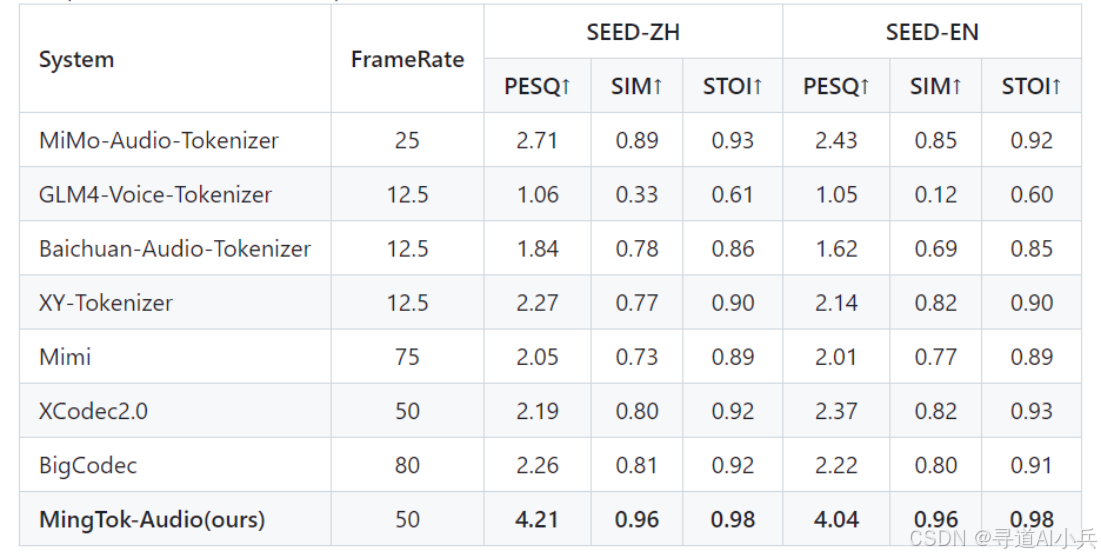
(二)语音理解
在多种方言的语音识别任务中,Ming-UniAudio 的错误率(WER)显著低于其他模型,例如湖南方言的 WER 仅为 9.80%,闽南语的 WER 为 16.50%。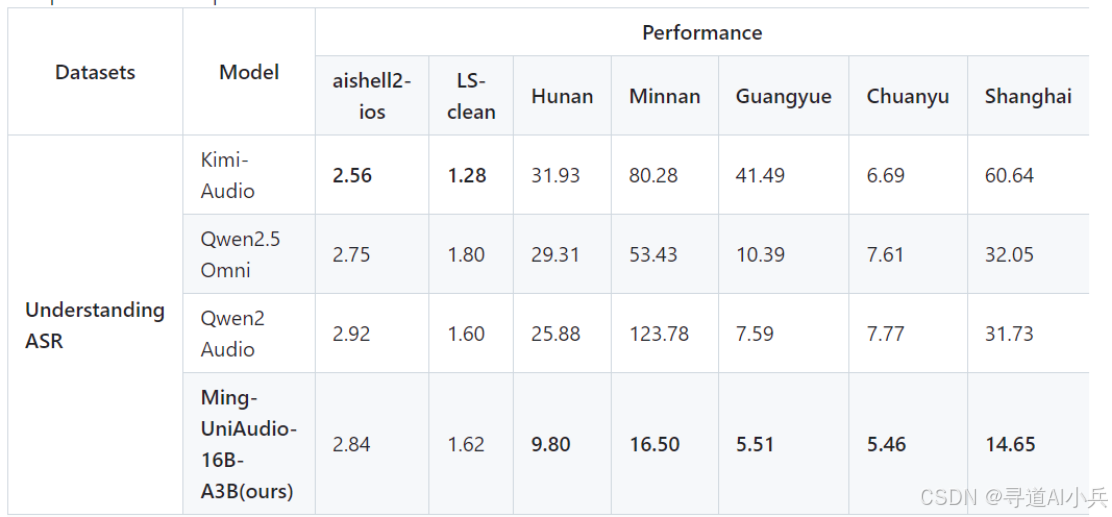
(三)语音生成
在 Seed-zh 中文数据集上,Ming-UniAudio 的 WER 仅为 0.95%,合成语音的相似度(SIM)达到 0.70,接近真人发音。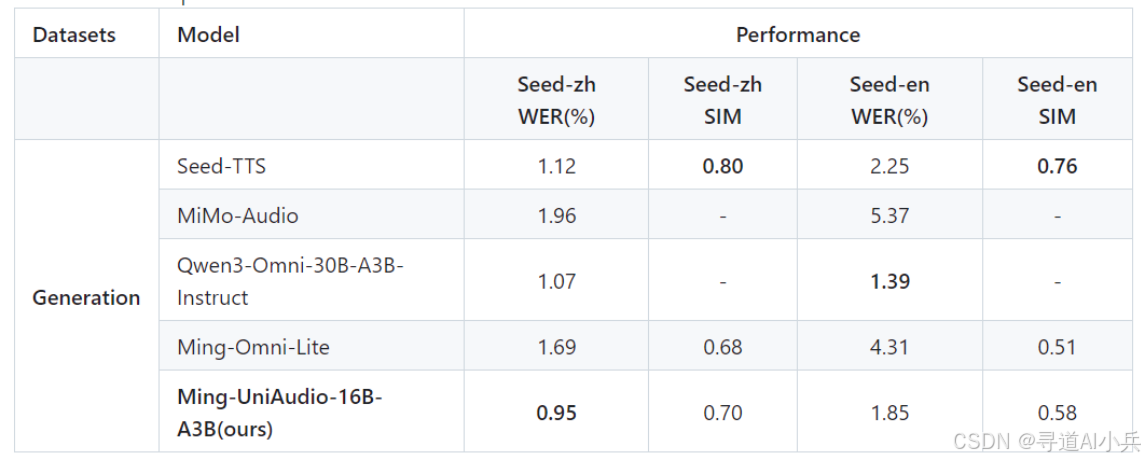
五、应用场景
(一)语音助手
Ming-UniAudio 的语音理解和生成能力使其成为语音助手的理想选择。它能够准确识别用户的语音指令并生成自然流畅的语音回应,支持多种语言和方言,极大地提升了用户体验。无论是智能家居设备、智能手机还是车载系统,Ming-UniAudio 都能提供高效、准确的语音交互功能。
(二)有声读物
Ming-UniAudio 的语音生成功能可以将文本内容转换为自然流畅的语音,适用于有声读物的制作。它支持多种语言和方言,生成的语音质量高,接近真人发音,能够为用户提供优质的听觉体验。这不仅提高了有声读物的制作效率,还降低了成本。
(三)音频后期制作
Ming-UniAudio 的自由形式语音编辑功能为音频后期制作提供了强大的工具。用户可以通过自然语言指令完成复杂的语音编辑任务,如插入、删除、替换等操作,无需手动指定编辑区域。这不仅简化了编辑流程,还提高了制作效率,适用于电影、广告、播客等多种音频内容的后期制作。
(四)多模态交互
Ming-UniAudio 支持文本和音频等多种模态输入,能够实现复杂的多模态交互任务。在智能对话系统和虚拟助手等应用中,模型可以同时处理语音和文本输入,提供更加自然和流畅的交互体验。这种多模态融合能力使其在多种复杂交互场景中表现出色。
(五)语音内容创作
Ming-UniAudio 的指令引导的语音编辑功能为语音内容创作提供了极大的便利。创作者可以通过简单的自然语言指令完成复杂的语音编辑任务,无需专业的音频编辑技能。这不仅提高了创作效率,还激发了更多创意,适用于播客、有声故事、语音广告等多种语音内容的创作。
六、快速使用
(一)环境准备
- 使用 pip 安装依赖:
https://github.com/inclusionAI/Ming-UniAudio.git
cd Ming-UniAudio
pip install -r requirements.txt
- 使用 Docker 构建环境:
git clone --depth 1 https://github.com/inclusionAI/Ming-UniAudio
cd Ming-UniAudio
docker build -t ming:py310-cu121 docker/docker-py310-cu121
docker run -it --gpus all -v "$(pwd)":/workspace/Ming-UniAudio ming:py310-cu121 ming:py310-cu121 /bin/bash
(二)下载源代码
git clone https://github.com/inclusionAI/Ming-UniAudio
cd Ming-UniAudio
(三)下载模型
下载 Ming-UniAudio 模型权重并在源代码目录中创建软链接
pip install modelscope
modelscope download --model inclusionAI/Ming-UniAudio-16B-A3B --local_dir inclusionAI/Ming-UniAudio-16B-A3B --revision master
mkdir inclusionAI ln -s /path/to/inclusionAI/Ming-UniAudio-16B-A3B inclusionAI/Ming-UniAudio-16B-A3B
(四)使用示例
官方提供了一个关于此仓库使用的简单示例,有关详细用法,可参阅 demobook.ipynb。
import warnings
import torch
from modelscope import AutoProcessor
from modeling_bailingmm import BailingMMNativeForConditionalGeneration
import random
import numpy as np
from loguru import logger
def seed_everything(seed=1895):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
seed_everything()
warnings.filterwarnings("ignore")
class MingAudio:
def __init__(self, model_path, device="cuda:0"):
self.device = device
self.model = BailingMMNativeForConditionalGeneration.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
).eval().to(torch.bfloat16).to(self.device)
self.processor = AutoProcessorinclusionAI/Ming-UniAudio-16B-A3Bfrom_pretrained(".", trust_remote_code=True)
self.tokenizer = self.processor.tokenizer
self.sample_rate = self.processor.audio_processor.sample_rate
self.patch_size = self.processor.audio_processor.patch_size
def speech_understanding(self, messages):
text = self.processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
).to(self.device)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
logger.info(f"input: {self.tokenizer.decode(inputs['input_ids'].cpu().numpy().tolist()[0])}")
generated_ids = self.model.generate(
**inputs,
max_new_tokens=512,
eos_token_id=self.processor.gen_terminator,
)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = self.processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)[0]
return output_text
def speech_generation(
self,
text,
prompt_wav_path,
prompt_text,
lang='zh',
output_wav_path='out.wav'
):
waveform = self.model.generate_tts(
text=text,
prompt_wav_path=prompt_wav_path,
prompt_text=prompt_text,
patch_size=self.patch_size,
tokenizer=self.tokenizer,
lang=lang,
output_wav_path=output_wav_path,
sample_rate=self.sample_rate,
device=self.device
)
return waveform
def speech_edit(
self,
messages,
output_wav_path='out.wav'
):
text = self.processor.apply_chat_template(messages, add_generation_prompt=True)
image_inputs, video_inputs, audio_inputs = self.processor.process_vision_info(messages)
inputs = self.processor(
text=[text],
images=image_inputs,
videos=video_inputs,
audios=audio_inputs,
return_tensors="pt",
).to(self.device)
ans = torch.tensor([self.tokenizer.encode('<answer>')]).to(inputs['input_ids'].device)
inputs['input_ids'] = torch.cat([inputs['input_ids'], ans], dim=1)
attention_mask = inputs['attention_mask']
inputs['attention_mask'] = torch.cat((attention_mask, attention_mask[:, :1]), dim=-1)
for k in inputs.keys():
if k == "pixel_values" or k == "pixel_values_videos" or k == "audio_feats":
inputs[k] = inputs[k].to(dtype=torch.bfloat16)
logger.info(f"input: {self.tokenizer.decode(inputs['input_ids'].cpu().numpy().tolist()[0])}")
edited_speech, edited_text = self.model.generate_edit(
**inputs,
tokenizer=self.tokenizer,
output_wav_path=output_wav_path
)
return edited_speech, edited_text
if __name__ == "__main__":
model = MingAudio("inclusionAI/Ming-UniAudio-16B-A3B")
# ASR
messages = [
{
"role": "HUMAN",
"content": [
{
"type": "text",
"text": "Please recognize the language of this speech and transcribe it. Format: oral.",
},
{"type": "audio", "audio": "data/wavs/BAC009S0915W0292.wav"},
],
},
]
response = model.speech_understanding(messages=messages)
logger.info(f"Generated Response: {response}")
# TTS
model.speech_generation(
text='我们的愿景是构建未来服务业的数字化基础设施,为世界带来更多微小而美好的改变。',
prompt_wav_path='data/wavs/10002287-00000094.wav',
prompt_text='在此奉劝大家别乱打美白针。',
)
结语
Ming-UniAudio 作为蚂蚁集团开源的多功能统一语音大模型,通过创新的连续语音分词器 MingTok-Audio 和端到端的语音语言模型,实现了语音理解、生成和编辑任务的统一表示。其强大的性能和多功能性使其在多种应用场景中具有广泛的应用前景。开发者可以通过开源代码和预训练模型快速部署和二次开发,推动语音处理技术的发展。
项目地址
- 项目官网:https://xqacmer.github.io/Ming-Unitok-Audio.github.io/
- Github仓库:https://github.com/inclusionAI/Ming-UniAudio
- Hugging Face 模型库:https://huggingface.co/inclusionAI/Ming-UniAudio-16B-A3B

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 22
22 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)