【youcans论文精读】回归基础:让去噪生成模型来去噪
Kaiming He 发布论文【回归基础:让去噪生成模型来去噪】。本文提出,预测干净数据与预测含噪量存在本质区别。倡导直接预测干净数据的模型设计:这类模型能让看似容量不足的神经网络在极高维空间中高效工作。提出极简自包含模型 “JiT”,简化扩散模型的设计范式:完全基于标准视觉 Transformer(ViT),无分词器、无预训练、无额外损失。
欢迎关注『youcans论文精读』系列
【youcans论文精读】回归基础:让去噪生成模型来去噪
0. 论文简介
0.1 基本信息
2025年 11月,Kaiming He(何恺明) 等 在 arXiv 发布论文 【回归基础:让去噪生成模型来去噪】(Back to Basics: Let Denoising Generative Models Denoise)。
本文指出提出直接预测干净数据(x-prediction)的思路,设计极简模型 “Just image Transformers(JiT)”。无需分词器、预训练和额外损失,仅用大 patch(16/32)的视觉 Transformer 处理像素为高维自然数据的 “扩散 + Transformer” 范式提供自包含方案。
论文标题: Back to Basics: Let Denoising Generative Models Denoise
作者: Tianhong Li(黎天鸿), Kaiming He(何恺明)
论文地址: https://arxiv.org/abs/2511.13720
代码仓库: https://github.com/LTH14/JiT
引用格式: Li T H, He K M. Back to Basics: Let Denoising Generative Models Denoise (EB/OL). (2025-11-17) [2025-XX-XX]. https://arxiv.org/pdf/2511.13720.
0.2 论文速览
研究背景
- 当前扩散模型的偏离:早期扩散模型核心是 “去噪”(从含噪图像预测干净图像),但后续发展转向预测噪声或含噪量,未遵循经典去噪逻辑。
- 流形假设的关键作用:机器学习中经典假设 ——自然数据(如图像)位于低维流形,而噪声、流速度等含噪量分布于全高维空间。这导致 “预测干净数据(x-prediction)” 与 “预测含噪量” 本质不同:
- 预测含噪量:需网络保留高维噪声全部信息,对模型容量要求极高;
- 预测干净数据:仅需保留低维流形信息,低容量网络也可在高维空间有效工作。
- 现有方法的局限:潜在扩散模型(如 LDM)依赖预训练 latent 空间,非自包含;像素扩散模型(如 SiD2)需密集卷积、小 patch 等复杂设计,源于需预测高维含噪量。
模型设计:JiT(Just image Transformers)
- 极简设计原则:无分词器、无预训练、无额外损失(无对抗损失、感知损失、表示对齐等),仅基于视觉 Transformer(ViT)处理原始像素。
- 网络流程:patch→线性嵌入→位置嵌入→Transformer 块堆叠→线性预测(还原为 p×p×3 patch),采用 adaLN-Zero 进行时间 t 和类别条件控制。
关键改进:
- 瓶颈嵌入:将线性 patch 嵌入替换为 “降维→升维” 两层线性结构,中间瓶颈维度 d’ 可低至 16-d,仍能提升性能;
- 通用 Transformer 增强:整合 SwiGLU、RMSNorm、RoPE、qk-norm 等语言模型组件,加入 32 个上下文类别 token,进一步降低 FID。
主要贡献
- 理论层面:重新确立 “x-prediction” 的核心价值,验证流形假设的实践意义。
- 方法层面:提出极简自包含模型 “JiT”,简化扩散模型的设计范式。
- 实验层面:突破高分辨率像素扩散的 “维度灾难”,验证方法的有效性与扩展性。
- 应用层面:拓展 “扩散 + Transformer” 范式的通用性,赋能跨领域高维数据生成。

0.3 摘要
如今的去噪扩散模型并未遵循 “经典意义上的去噪”—— 即它们不会直接预测干净图像,而是由神经网络预测噪声或含噪量。
本文提出,预测干净数据与预测含噪量存在本质区别。基于流形假设,自然数据应位于低维流形上,而含噪量则不遵循这一分布特性。依托该假设,我们倡导直接预测干净数据的模型设计:这类模型能让看似容量不足的神经网络在极高维空间中高效工作。
研究表明,基于像素的简单大 patch Transformer 可成为性能强劲的生成模型 —— 无需分词器、无需预训练、也无需额外损失函数。我们将这种方法命名为 “Just image Transformers(JiT,即‘仅图像 Transformer’)”。
实验显示,在 ImageNet 数据集的 256×256 和 512×512 分辨率下,采用 16×16 和 32×32 大 patch 的 JiT 模型取得了具竞争力的结果;而在这些场景中,预测高维含噪量的传统方法会发生灾难性失效。通过让网络回归流形假设的核心本质,本研究回归基础,为基于 Transformer 的原始自然数据扩散模型提供了一套自包含的范式。
代码已发布于 https://github.com/LTH14/JiT。
1. 引言
扩散生成模型最初被提出时 [57, 59, 23],其核心思想本应是 “去噪”—— 即从被污染的版本中预测干净图像。然而,扩散模型发展过程中的两个重要里程碑,却偏离了直接预测干净图像的目标。首先,预测噪声本身(即 “ε 预测”[23])对生成质量产生了关键性影响,并在很大程度上推动了这类模型的普及。随后,通过预测流速度(“v 预测”[52],一种融合干净数据与噪声的变量),扩散模型与基于流的方法 [37, 38, 1] 建立了关联。如今,实际应用中的扩散模型通常会预测噪声或含噪量(例如流速度)。
大量研究 [52, 29, 25, 15] 表明,只要对预测损失的权重进行相应重构(详见第 3 节),预测干净图像(即 “x 预测”[52])与 ε 预测、v 预测密切相关。正因这种关联性,人们较少关注网络应直接预测何种变量,而是默认网络有能力完成分配的任务。
但干净图像与含噪量(包括噪声本身)的作用并非对等。在机器学习领域,长期以来存在一种假设 [4, 3]:“(高维)数据大致位于低维流形上”([4, 第 6 页])。基于这一流形假设,干净数据可被建模为位于低维流形上,而含噪量本质上分布于整个高维空间 [69](见图 1)。因此,预测干净数据与预测噪声或含噪量存在本质区别。
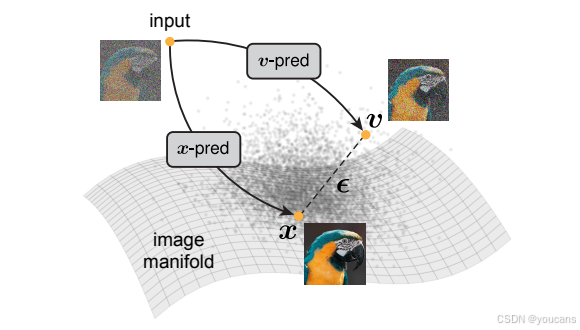
图 1:流形假设[4]认为自然图像位于高维像素空间中的低维流形上。虽然干净的图像x可以视为流形内的,噪声ϵ或流动速度v(例如,v = x−ϵ)本质上是流形外的。训练神经网络预测干净图像(即x预测)与训练其预测噪声或受噪声影响的量(即ϵ/v预测)在本质上是不同的。
试想这样一种场景:低维流形嵌入在高维观测空间中。在该高维空间中预测噪声需要极高的模型容量 —— 网络需保留与噪声相关的所有信息。相比之下,容量有限的网络仍能预测干净数据,因为它只需保留低维信息并过滤掉噪声即可。
当使用低维空间(例如图像潜变量 [49])时,预测噪声的难度会有所缓解,但这一问题只是被隐藏而非真正解决。一旦涉及像素或其他高维空间,现有扩散模型仍难以应对维度灾难 [4]。而对预训练潜空间的严重依赖,也使得扩散模型无法实现 “自包含”(即不依赖外部组件)。
为追求自包含的设计原则,研究者们一直致力于推进像素空间中的扩散建模 [7, 25, 26, 6, 70]。这类方法通常会通过显性或隐性方式规避网络中的信息瓶颈,例如使用密集卷积或更小的图像块、增加通道数、添加长跳跃连接等。我们认为,这些设计之所以必要,源于其需要预测高维含噪量的核心需求。
在本文中,我们回归基本原则,让神经网络直接预测干净图像。实验表明,一个简单的视觉 Transformer(ViT)[13],仅需对原始像素构成的大图像块进行处理,就能有效完成扩散建模任务。我们的方法具有自包含性,不依赖任何预训练或辅助损失 —— 无需潜变量分词器 [49]、无需对抗损失 [16, 49]、无需感知损失 [77, 49](因此无需预训练分类器 [56]),也无需表示对齐 [74](因此无需自监督预训练 [45])。从概念上讲,我们的模型就是将 “仅图像 Transformer”(Just image Transformers,简称 JiT)应用于扩散任务。
我们在 ImageNet 数据集 [11] 的 256×256 和 512×512 分辨率下进行了实验,分别采用图像块尺寸为 16 和 32 的 JiT 模型。尽管这些图像块具有极高的维度(数百甚至数千维),但基于 x 预测的我们的模型仍能轻松取得优异结果,而 ε 预测和 v 预测在相同场景下会发生灾难性失效。进一步分析表明,网络宽度无需与图像块维度匹配或超过后者;事实上,令人意外的是,瓶颈设计(即网络中间层维度低于输入维度)甚至可能带来性能提升,这与经典流形学习中的观测结果相呼应。
本研究为原生数据上 “扩散 + Transformer” 的自包含理念 [46] 迈出了重要一步。除计算机视觉领域外,这一理念在其他涉及自然数据的领域(例如蛋白质、分子或气象数据)也具有极高的应用价值 —— 这些领域中,分词器的设计往往十分困难。通过最大限度减少领域特异性设计,我们希望源自计算机视觉的通用 “扩散 + Transformer” 范式能够获得更广泛的应用。
2. 相关工作
扩散模型及其预测目标
扩散模型的开创性研究 [57] 提出学习一个反向随机过程,网络在该过程中预测正态分布的参数(例如均值和标准差)。该方法提出五年后,去噪扩散概率模型(DDPM)[23] 对其进行了革新与普及:一项关键发现是将噪声作为预测目标(即 ε 预测)。
随后,有研究 [52](最初基于模型蒸馏场景)探究了不同预测目标之间的关联,并提出了 v 预测的概念。该研究重点关注了参数重构带来的权重影响。
与此同时,EDM [29] 围绕去噪器函数重新构建了扩散问题,成为扩散模型发展历程中的重要里程碑。然而,EDM 采用了一种条件设定,网络的直接输出并非去噪后的图像。这种设定在低维场景中更为适用,但本质上仍要求网络输出融合数据与噪声的变量(附录中有更多对比)。
流匹配模型 [37, 38, 1] 可被解读为扩散建模框架下 v 预测的一种形式 [52]。与纯噪声不同,v 是数据与噪声的结合体。已有研究建立了基于流的模型与早期扩散模型之间的关联 [15]。如今,扩散模型及其基于流的同类模型通常在统一框架下被研究。
去噪模型
过去几十年中,去噪的概念一直与表示学习密切相关。以 BM3D [9] 及其他方法 [47, 14, 79] 为代表的经典方法,利用稀疏性和低维性假设实现图像去噪。
去噪自编码器(DAE)[68, 69] 作为一种无监督表示学习方法被提出,将去噪作为训练目标。它们借助流形假设 [4](图 1)学习能够逼近低维数据流形的有意义表示。去噪自编码器可被视为去噪分数匹配 [67] 的一种形式,而后者又与现代基于分数的扩散模型 [59, 60] 密切相关。尽管去噪自编码器为实现流形学习而自然地选择预测干净数据,但在分数匹配中,有效预测分数函数本质上等同于预测噪声(相差一个缩放因子),即 ε 预测。
流形学习
流形学习是一个经典研究领域 [51, 63],专注于从观测数据中学习低维、非线性表示。通常,流形学习方法会利用瓶颈结构 [64, 48, 41, 2],仅允许有用信息通过。已有多项研究探索了流形学习与生成模型之间的关联 [39, 27, 8]。潜扩散模型(LDM)[49] 可被视为第一阶段通过自编码器进行流形学习,第二阶段进行扩散建模的方法。
像素空间扩散
尽管潜扩散 [49] 已成为当前领域的默认选择,但扩散模型的发展最初始于像素空间设定 [59, 23, 44, 12]。早期的像素空间扩散模型通常基于密集卷积网络,最常见的是 U-Net [50]。这些模型往往采用过完备的通道表示(例如在第一层将 H×W×3 转换为 H×W×128),并辅以长程跳跃连接。这类模型在 ε 预测和 v 预测中表现良好,但它们的密集卷积结构计算成本通常较高。将这些卷积模型应用于高分辨率图像不会导致灾难性退化,因此该方向的研究通常聚焦于噪声调度和 / 或权重方案 [7, 25, 26, 30],以进一步提升生成质量。
相比之下,将视觉 Transformer(ViT)[13] 直接应用于像素则面临更大挑战。标准 ViT 架构采用较大的图像块尺寸(例如 16×16 像素),导致生成的令牌空间维度较高,可能与 Transformer 的隐藏层维度相当甚至更高。SiD2 [26] 和 PixelFlow [6] 采用了从较小图像块开始的分层设计;然而,这些模型 “计算量巨大”[26],且丧失了标准 Transformer 固有的通用性和简洁性。PixNerd [70] 采用了 NeRF 头 [43],整合了 Transformer 输出、含噪输入和空间坐标的信息,训练过程还借助了表示对齐 [74] 的辅助。
即便采用了这些专用设计,相关研究中的架构通常也从 “L”(大型)或 “XL”(超大型)尺寸起步。事实上,最新研究 [73] 表明,对于高维数据,较大的隐藏层尺寸似乎是必要的。
高维扩散
当使用 ViT 风格的架构时,现代扩散模型在高维输入空间(无论是像素还是潜变量)中仍面临挑战。文献 [8, 73, 55] 中多次报道,无论使用像素还是潜变量,当每个令牌的维度增加时,ViT 风格的扩散模型会迅速且灾难性地退化。
与本研究同时进行的一系列研究 [78, 34, 55] 借助自监督预训练来解决高维扩散问题。与之不同,我们的研究表明,无需任何预训练,仅使用 Transformer 即可实现高维扩散。
x 预测
x 预测的设定既自然又并非全新概念;其最早可追溯至原始的 DDPM [23](参见其代码 [24])。然而,DDPM 观测到 ε 预测的性能显著更优,这一方法随后成为主流解决方案。在后续研究中(例如 [26]),尽管分析有时更倾向于在 x 空间中进行,但实际预测往往在其他空间中完成,这可能是出于历史原因。
在扩散模型所处理的图像恢复任务中 [10, 72, 42],网络自然会预测干净数据,因为这是图像恢复的最终目标。与本研究同时进行的一项工作 [18] 也倡导使用 x 预测,用于基于先前帧的生成式世界模型。
本研究并非旨在重新发明这一基础概念;相反,我们希望引起人们对高维数据(具有潜在低维流形)场景中一个被严重忽视但至关重要的问题的关注。
3. 扩散模型的预测输出
扩散模型可在 x、ε 或 v 所在的空间中构建。空间的选择不仅决定了损失函数的定义范围,还决定了网络的预测目标。重要的是,损失空间与网络输出空间未必一致,这一选择可能会产生关键性影响。
3.1 背景:扩散与流
扩散模型可从常微分方程(ODE)的角度进行构建 [5, 60, 37, 58]。我们首先从基于流的范式 [37, 38, 1] 入手(即 v 空间),将其作为更简洁的起点,随后再讨论其他空间。
考虑数据分布 x 服从 p₍data₎(x),噪声分布 ε 服从 p₍noise₎(ε)(例如 ε 服从标准正态分布 N (0, I))。训练过程中,含噪样本 zₜ是一种插值结果,其生成方式由预定义的噪声调度 aₜ和 bₜ决定(t 的取值范围为 [0, 1])。本文采用线性调度,此时 zₜ的生成遵循特定插值规则,当 t=1 时,zₜ服从数据分布 p₍data₎。我们对 t 采用 logit 正态分布进行采样。
流速度 v 定义为 z 关于时间的导数。根据 zₜ的插值规则,可推导出 v 的具体表达式。

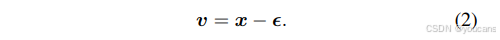

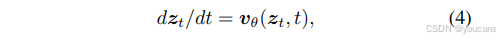
基于流的方法 [37, 38, 1] 通过最小化特定损失函数进行训练,该损失函数衡量模型预测的流速度 v_θ 与真实流速度 v 的差异,其中 v_θ 由参数 θ 控制。v_θ 通常是网络的直接输出,也可通过对网络输出进行转换得到,后续将详细阐述。
给定函数 v_θ 后,采样过程通过求解关于 z 的常微分方程实现,从服从噪声分布的 z₀开始,直至 t=1 结束。实际应用中,该常微分方程可通过数值求解器进行近似求解,本文默认使用 50 步 Heun 方法。
3.2 预测空间与损失空间
- 预测空间。
网络的直接输出可以定义在任何空间中:v、x 或 ϵ。接下来,我们讨论由此产生的转换。请注意,在本文的上下文中,我们仅当网络 netθ 的直接输出严格为 x、ϵ、v 时,才将其称为 “x、ϵ、v 预测”。
x、ε、v 三个变量中,若已知其中一个由网络预测得出,可通过两条约束关系推导出另外两个变量。例如,当网络直接输出为 x 时,可通过约束关系求解得到 ε 和 v 的表达式,同理可推导网络输出为 ε 或 v 时的情况。这表明,只要预测出 x、ε、v 中的任意一个,其余两个均可通过推导获得。
例如,当我们将网络的直接输出 netθ 定义为 x 时,我们求解以下方程组:在这里,符号 xθ、ϵθ 和 vθ 表示它们都是依赖于 θ 的预测值。求解这个方程组得到:ϵθ = (zt−txθ)/(1−t) 和 vθ = (xθ−zt)/(1−t),也就是说,ϵθ 和 vθ 都可以从 zt 和网络的 xθ 计算得出。这些内容总结在表 1 的列(a)中。
同样,当我们将网络的直接输出 netθ 定义为 ϵ 或 v 时,我们得到其他方程组(通过替换公式(5)中的第一个)。转换总结在表 1 的列(b)、(c)中,分别对应 ϵ-、v 预测。
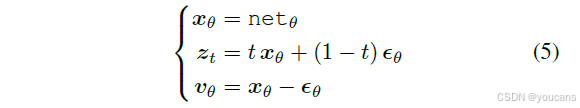
- 损失空间:损失函数通常定义在某一参考空间(例如式(3)中的 v 损失),但理论上可定义在任意空间。研究表明 [52, 15],当预测空间与损失空间不同时,通过参数重构可实现损失的重新加权。
所有预测空间与损失空间的组合均构成有效的模型构建方式,且这九种组合在数学上并不等价。
- 生成空间:无论采用哪种组合,推理阶段进行生成时,均可将网络输出转换至 v 空间,并通过求解对应的常微分方程完成采样。因此,这九种组合均为合法的生成方式。
表 1:在x、v或ϵ空间中定义损失和网络预测的所有可能组合。直接网络输出用颜色高亮显示。对于任何网络输出空间与损失空间不同的非对角线条目,对网络输出进行转换。
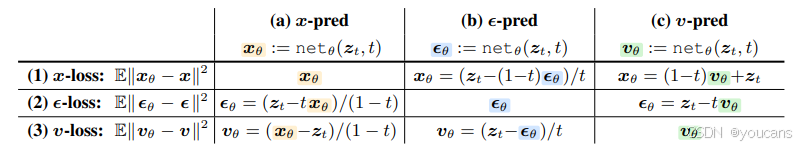
3.3 小样本实验
根据流形假设 [4],数据 x 倾向于位于低维流形上,而噪声 ε 和速度 v 则处于流形之外。让网络直接预测干净数据 x 理应更易于实现,本节通过玩具实验验证这一假设。
我们构建了一个小样本场景:将 d 维的底层数据 “嵌入” 到 D 维的观测空间中(d<D)。具体通过一个列正交的投影矩阵 P 实现,观测数据 x 由底层数据经过该矩阵投影得到。投影矩阵 P 对模型而言是未知的,因此对模型来说这是一个 D 维的生成问题。
我们训练了一个 5 层 ReLU 多层感知机(MLP)作为生成器,并通过投影矩阵 P 将生成的 D 维样本映射回 d 维以进行可视化。实验中固定 d=2,探究 D 取不同值时的情况,同时分别采用 x、ε 或 v 预测方式,且均使用 v 损失进行训练。
实验结果表明,随着观测维度 D 的增加,仅有 x 预测能够产生合理结果。对于 ε 预测和 v 预测,模型在 D=16 时便难以应对,当 D=512(此时 256 维的 MLP 属于欠完备模型)时会发生灾难性失效。
值得注意的是,即使模型为欠完备,x 预测仍能表现良好。在 D=512 的场景中,256 维的 MLP 必然会丢弃部分信息,但由于真实数据本质上位于低维的 d 维空间,x 预测仍能有效工作 —— 其理想输出隐含着低维特性。后续将展示,在 ImageNet 的真实数据场景中,我们也观察到了类似现象。

图 2:小样本实验:d维(d = 2)的基本数据通过一个固定、随机的列正交投影矩阵“埋藏”在D维空间中。在D维空间中,我们训练一个简单的生成模型(5层ReLU MLP,隐藏单元为256维)。投影矩阵对模型未知,我们仅用于可视化输出。在这个小样本实验中,随着观测维度D的增加,只有x预测能产生合理的结果。
4. 用于扩散模型的 “仅图像 Transformer”(Just Image Transformers)
基于上述分析,我们将证明,仅通过 x 预测,直接作用于像素的简单视觉 Transformer(ViT)[13] 就能取得出人意料的良好效果。
4.1 仅图像 Transformer(Just Image Transformers)
ViT [13] 的核心思想是 “基于图像块的 Transformer(Transformer on Patches, ToP)”。我们的架构设计遵循这一理念。
形式上,考虑 H×W×C 维的图像数据(C=3)。所有 x,ϵ,v 和 zt 都共享这一相同的维度。给定一张图像,我们将它划分为尺寸为 p×p 的不重叠小块,得到一个长度为 H/p×W/p 的序列。每个小块是一个 p×p×3 维的向量。这个序列经过线性嵌入投影,加上位置嵌入 [66],并由 Transformer 块 [66] 的堆叠进行映射。输出层是一个线性预测器,将每个标记重新映射回一个 p×p×3 维的小块。见图 3。
按照标准做法,架构以时间 t 和给定的类别标签为条件。我们采用 adaLN-Zero [46] 实现条件控制,并将在后面讨论其他选项。从概念上讲,这种架构相当于将扩散 Transformer(DiT)[46] 直接应用于像素图像块。
整个架构不过就是 “Just image Transformers”,我们将其称为 JiT。例如,我们在 256×256 的图像上研究 JiT/16(即小块尺寸 p=16,[13]),在 512×512 的图像上研究 JiT/32(p=32)。这些设置分别导致每个小块的维度为 768(16×16×3)和 3072(32×32×3)。如此高维的小块可以通过 x 预测来处理。
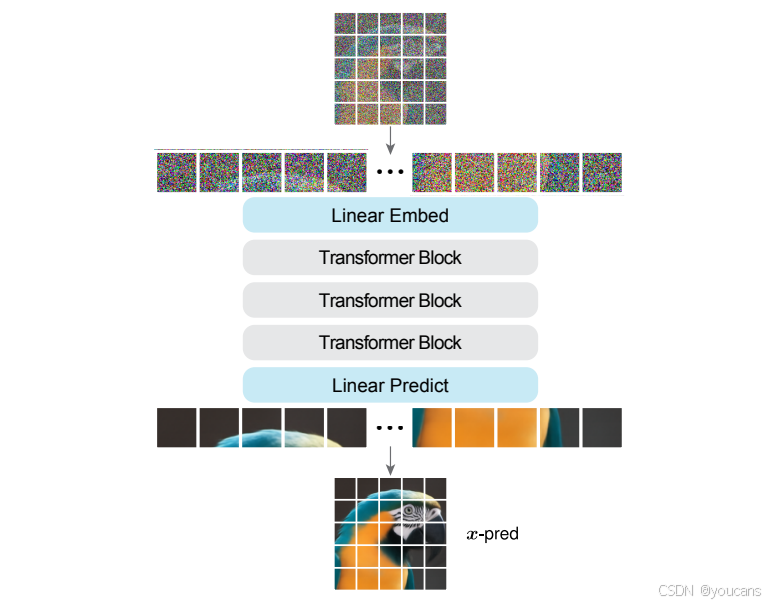
图 3 : “仅图像变换器”(JiT)架构:仅对像素块进行简单的ViT [13],用于x预测。
4.2 网络应该预测什么?
我们在表格 1 中总结了损失空间与预测空间的所有九种组合。针对每种组合,我们训练了一个 “基础版(Base)” 模型(JiT-B),其每个令牌的隐藏层维度为 768 维。在表格 2(a)中,我们研究了 256×256 分辨率下的 JiT-B/16 模型;作为参考,在表格 2(b)中研究了 64×64 分辨率下的 JiT-B/4 模型(即 p=4)。这两种设置下的序列长度相同(均为 16×16)。

我们得出以下观察结果:
-
x 预测至关重要。
在表格 2(a)的 JiT-B/16 模型实验中,仅有 x 预测表现良好,且在三种损失函数下均能有效工作。此处每个图像块维度为 768 维(16×16×3),与 JiT-B 的隐藏层维度一致。尽管这看似 “刚好满足需求”,但实际应用中模型可能需要额外容量(例如处理位置嵌入)。对于 ε 预测和 v 预测,模型缺乏足够容量来分离和保留含噪量,这与玩具实验(图 2)中的观察结果一致。
作为对比,表格 2(b)展示了 64×64 分辨率下的 JiT-B/4 模型实验结果。此处所有组合的表现均较为合理,九种组合之间的精度差距微小,并非决定性因素。每个图像块的维度为 48 维(4×4×3),远低于 JiT-B 的 768 维隐藏层维度,这也解释了为何所有组合均能正常工作。我们注意到,许多先前的潜扩散模型输入维度与此类似,因此未遇到本文所讨论的问题。 -
损失加权并非万能。
本研究并非首次枚举相关因素的组合。已有研究 [52] 探索了损失加权与网络预测的组合关系,其实验在低维的 CIFAR-10 数据集上进行,采用 U-Net 架构,观察结果与我们在 ImageNet 64×64 分辨率下的实验更为接近。然而,表格 2(a)中 ImageNet 256×256 分辨率的实验结果表明,损失加权并非解决问题的全部。一方面,无论采用何种损失空间(对应不同的有效加权方式),ε 预测和 v 预测均会发生灾难性失效;另一方面,x 预测在所有三种损失空间下均能有效工作,v 损失带来的加权效果虽更优,但并非关键因素。 -
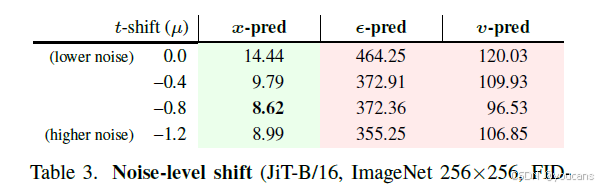
噪声水平调整并非万能。
已有研究 [7, 25, 26] 提出,提高噪声水平对基于像素的高分辨率扩散模型有益。我们在表格 3 中通过 JiT-B/16 模型验证了这一点。由于我们采用 logit 正态分布 [15] 对 t 进行采样,可通过调整该分布的参数 μ 来改变噪声水平:直观而言,将 μ 向负值方向调整会减小 t,从而提高噪声水平。表格 3 显示,当模型本身表现良好时(此处为 x 预测),适当提高噪声水平确实有益,这与先前的观察结果 [7, 25, 26] 一致。然而,仅通过调整噪声水平无法弥补 ε 预测或 v 预测的缺陷 —— 它们的失效本质上源于无法传递高维信息。
作为补充说明,根据表格 3 的结果,我们在 ImageNet 256×256 的其他实验中设置 μ=-0.8。
-
增加隐藏层单元并非必要。
由于模型容量可能受网络宽度(即隐藏层单元数量)限制,一个自然的想法是增加隐藏层单元数量。但在观测维度极高的情况下,这种解决方案既缺乏理论依据,也不具备可行性。我们的实验表明,对于 x 预测而言,增加隐藏层单元并非必要。
在下一节的表格 5 和表格 6 中,我们将展示 JiT/32 模型在 512 分辨率、JiT/64 模型在 1024 分辨率下的实验结果,这两种模型分别采用比例放大的 32×32 或 64×64 图像块。对应的每个图像块维度高达 3072 维(32×32×3)或 12288 维(64×64×3),远高于 B、L、H 型模型的隐藏层维度(定义见 [13])。尽管如此,x 预测仍能有效工作;事实上,除了按比例调整噪声强度外(例如在 512 和 1024 分辨率下分别将噪声强度扩大 2 倍和 4 倍),无需进行其他修改。
这一证据表明,网络设计在很大程度上可与观测维度解耦,这与许多其他神经网络应用场景一致。增加隐藏层单元数量可能有益(深度学习中已被广泛观察到),但并非决定性因素。 -
瓶颈设计可能有益。
更令人意外的是,我们发现,反过来在网络中引入降低维度的瓶颈结构可能会带来性能提升。
具体而言,我们将线性图像块嵌入层替换为一对瓶颈(但仍为线性)层,将其转换为低秩线性层。第一层将维度降至 d’,第二层再将其扩展至 Transformer 的隐藏层维度。这两层均为线性层,起到低秩参数重构的作用。
图 4 展示了 FID 值与瓶颈维度 d’ 的关系,实验采用 JiT-B/16 模型(原始图像块维度为 768 维)。降低瓶颈维度(即使降至 16 维)并不会导致灾难性失效。事实上,当瓶颈维度在较宽范围(32 至 512)内时,模型质量可得到显著提升,FID 值最高可降低约 1.3。
从表示学习的更广泛视角来看,这一观察结果并非完全出乎意料。瓶颈设计常被用于促使模型学习本质上低维的表示 [64, 48, 41, 2]。
4.3 我们的算法
我们最终的算法采用 x 预测和 v 损失,对应于表 1(3)(a)。:。具体而言,我们优化的目标函数如下,其中 v_θ(zₜ, t) 由网络输出与含噪样本 zₜ推导得出。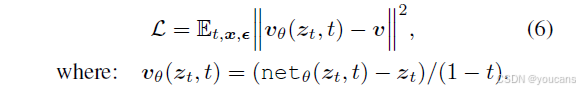
算法 1 展示了训练步骤的伪代码,算法 2 展示了采样步骤的伪代码(采用欧拉求解器,可扩展至龙格-库塔或其他求解器)。为简洁起见,省略了类别条件控制和 CFG [22] 相关内容,这两部分均遵循标准做法。为避免 1/(1−t) 中出现除零错误,在计算该除法时,我们默认将分母截断至 0.05。


4.4 “仅进阶版” Transformer(Just Advanced Transformers)
通用 Transformer [66] 的优势之一在于,当其设计与特定任务解耦时,它可以受益于在其他应用中开发的架构改进。这种特性支撑了使用任务无关的 Transformer 来构建扩散模型的优势。
按照 [73] 的方法,我们引入了流行的通用改进:SwiGLU [54]、RMSNorm [75]、RoPE [62] 和 qk-norm [19],这些改进最初都是为语言模型开发的。我们还探索了上下文中的类别条件化:与原始 ViT [13] 在序列末尾附加一个类别标记不同,我们附加多个这样的标记(默认为 32 个;见附录),遵循 [35]。表 4 报告了这些组件的效果。
5. 对比实验
-
高分辨率像素生成。
在表 5 中,我们进一步报告了我们的基础尺寸模型(JiT-B)在 ImageNet 上于 512 和甚至 1024 分辨率下的表现。我们使用与图像尺寸成比例的小块尺寸,因此在不同分辨率下序列长度保持不变。每个小块的维度可以高达 3072 或 12288,而常见的模型都没有足够的隐藏单元。表 5 显示我们的模型在不同分辨率下表现良好。所有模型的参数数量和计算成本相似,仅在输入/输出小块嵌入方面有所不同。我们的方法不会受到观测维度的诅咒。 -
可扩展性。
将 Transformer 设计与任务解耦的核心目标之一是利用其可扩展性潜力。表 6 提供了在 ImageNet 256 和 512 分辨率下四种模型尺寸的结果(请注意,在 512 分辨率下,这些模型的隐藏单元数量都不超过小块维度)。模型尺寸和浮点运算次数(flops)在表 7 和表 8 中显示:我们的 256 分辨率模型与 512 分辨率模型的计算成本相似。我们的方法受益于规模扩展。
有趣的是,随着模型尺寸增大,256 分辨率和 512 分辨率之间的 FID 差距变小。对于 JiT-G,512 分辨率下的 FID 甚至更低。对于 ImageNet 上的非常大的模型,FID 性能主要取决于过拟合程度,而 512 分辨率下的去噪任务更具挑战性,使其更不容易过拟合。参考先前工作的结果。 -
与现有研究结果的对比
作为参考,我们在表格 7 和表格 8 中与现有研究结果进行了对比,并标注了每种方法涉及的预训练组件。与其他基于像素的方法相比,我们的方法完全基于简单的通用 Transformer 驱动,具有计算高效的特点,且避免了分辨率翻倍时计算成本呈二次方增长的问题(详见表格 8 中的浮点运算量数据)。
我们的方法未使用额外损失函数或预训练过程,而这些因素有望带来进一步的性能提升(附录中提供了相关示例),相关方向将留待未来研究。
6. 讨论与结论
-
噪声与自然数据存在本质区别。
多年来,扩散模型的发展主要聚焦于概率建模形式,而对所使用神经网络的能力(及局限性)关注较少。然而,神经网络的能力并非无限 —— 它们能更高效地利用自身容量对数据进行建模,而非对噪声建模。从这些角度来看,我们关于 x 预测的研究发现,事后回顾其实是顺理成章的结果。 -
本研究采用极简且自包含的设计理念。
通过减少领域特异性归纳偏置,我们希望该方法能够泛化至其他难以设计分词器的领域。这一特性对于涉及原始、高维自然数据的科学应用而言尤为重要。我们预计,通用的 “扩散 + Transformer” 范式有望成为其他领域的潜在基础框架。

图 5:定性结果。使用JiT-H/32在512×512 ImageNet上的选定示例。更多未编辑的结果见附录。
A. 实现细节
我们的实现紧密遵循 DiT [46] 和 SiT [40] 的公开代码库。我们的配置总结在表 9 中。

以下是详细描述。
-
时间分布。
按照 [15] 的方法,在训练过程中,我们对 t 采用 logit 正态分布: l o g i t ( t ) ∼ N ( μ , σ 2 ) logit(t)∼N(μ,σ^2) logit(t)∼N(μ,σ2) 。具体来说,我们从 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2) 中采样 s ,然后计算 t=sigmoid(s) 。超参数 μ 决定了噪声水平(见表 3),默认情况下,我们在 ImageNet 256 分辨率(或 512、1024 分辨率)上设置 μ=−0.8 ,并将 σ 固定为 0.8。 -
ImageNet 512×512 和 1024×1024。
我们在 ImageNet 512×512 上采用 JiT/32(即小块尺寸为 32)。该模型生成了 256 = 16×16 个小块序列,与 ImageNet 256×256 上的 JiT/16 相同。因此,JiT/32 仅在输入/输出小块维度上与 JiT/16 不同,每个小块的维度从 768 维增加到 3072 维;所有其他计算和成本完全相同。
为了复用 ImageNet 256×256 的确切配置,对于 512×512 的图像,我们将噪声 ϵ 的幅度放大 2 倍,即 ϵ ∼ N ( 0 , 2 2 I ) ϵ∼N(0,2^2 I) ϵ∼N(0,22I) 。这一简单修改大致保持了 256×256 和 512×512 分辨率之间的信噪比(SNR)[25, 7, 26]。
无需对 ImageNet 256×256 的配置进行其他更改或应用。
对于 ImageNet 1024×1024,我们使用 JiT/64 模型,并将噪声 ϵ 放大 4 倍。无需进行其他更改。 -
上下文中的类别条件。
标准的 DiT [46] 通过 adaLN-Zero 进行类别条件化。在表 4 中,我们进一步探索了上下文中的类别条件化。
具体来说,按照 ViT [13] 的方法,可以在小块序列的开头附加一个类别标记。这在 DiT [46] 中被称为 “上下文条件化”。请注意,我们同时使用上下文条件化和默认的 adaLN-Zero 条件化,与 DiT 不同。此外,按照 MAR [35] 的方法,我们进一步在序列开头附加多个这样的标记。这些标记是同一个类别标记的重复实例,添加了不同的位置嵌入。我们附加了 32 个这样的标记。此外,我们发现将这些标记附加到 Transformer 的较后块中可能会更有益(见表 9 中的 “上下文起始块”)。表 4 显示,我们的上下文条件化实现将 FID 提高了约 1.2。 -
Dropout 和提前停止。
我们在 JiT-H 和 G 中应用 Dropout [61],以降低过拟合的风险。具体来说,我们将 Dropout 应用于 Transformer 块的中间一半。对于应用了 Dropout 的 Transformer 块,我们同时将其应用于注意力块和 MLP 块。
由于 G 尺寸的模型在我们当前的 Dropout 设置下仍倾向于过拟合,因此当监控的 FID 开始下降时,我们采用提前停止。这发生在 JiT-G/16 和 JiT-G/32 的大约 320 个训练周期时。 -
EMA 和 CFG。
我们的研究涵盖了广泛的配置,包括在损失空间和预测空间的变化、模型尺寸和架构组件方面的变化。CFG 缩放比例 [22] 和 EMA(指数移动平均)衰减的最佳值因情况而异,固定它们可能会导致不完整或误导性的观察结果。由于维护这些超参数配置的代价相对较小,我们努力采用最佳值。
具体来说,对于 CFG 缩放比例 ω [22],我们在推理时通过搜索一系列候选缩放比例来确定最佳值,这是现有工作中的常见做法。对于 EMA 衰减,我们在训练过程中维护多份移动平均参数,这引入了可以忽略不计的计算开销。为了避免内存开销,不同的 EMA 副本可以存储在不同的设备上(例如 GPU)。因此,CFG 缩放比例和 EMA 衰减本质上是推理时的决策。
我们的 CFG 缩放比例候选值范围从 1.0 到 4.0,步长为 0.1。CFG 的影响在图 6 中为 JiT-L/16 模型进行了展示。我们的 EMA 衰减候选值为 0.9996、0.9998 和 0.9999,使用 1024 的批量大小进行评估。对于每个模型(包括任何消融实验中的模型),我们使用 8K 样本搜索最佳设置,然后将其应用于评估 50K 样本。 -
评估。
按照常见做法,我们使用 ImageNet 训练集评估 FID [21]。我们在 50K 生成图像上评估 FID,每个 1000 个 ImageNet 类别各取 50 个样本。我们还在相同的 50K 图像上评估 Inception Score(IS)[53]。
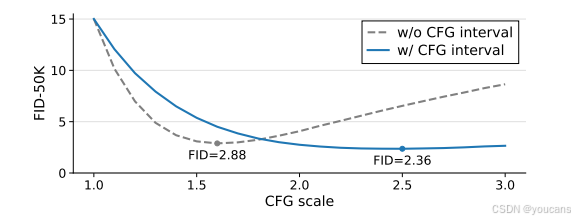
图 6:CFG的影响,包括CFG区间(对于ImageNet 256×256的JiT-L/16,在600个周期中的影响)。
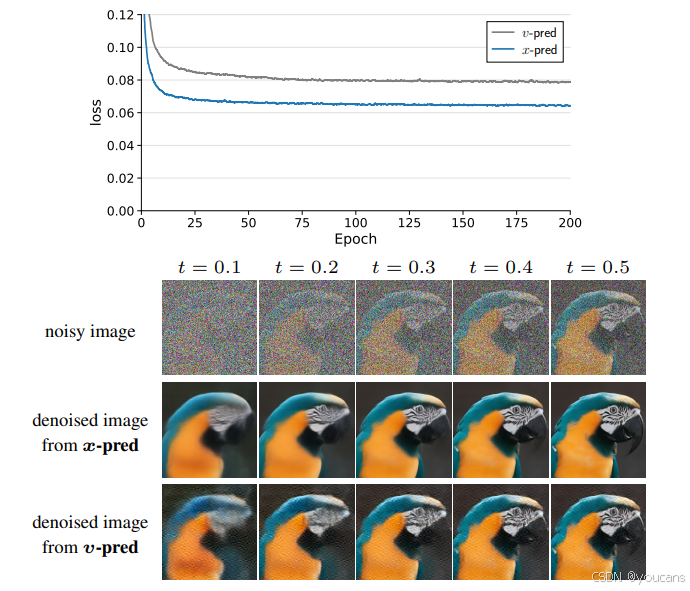
图7. (顶部):使用v损失相同损失空间的x-和v预测的训练损失(表2(a)第三行)。我们绘制每个像素每个通道的损失平均值。(底部):从x-和v预测得到的去噪图像,其中v预测的去噪输出根据表1©(1)进行可视化。v预测的去噪图像有明显的伪影,这反映在较高的损失上。
7. 代码运行
代码仓库: https://github.com/LTH14/JiT
JiT 为像素级高分辨率图像扩散任务采用极简且自包含的设计。原始实现基于 JAX+TPU 框架,本复现版本基于 PyTorch+GPU 开发。
7.1 数据集
下载 ImageNet 数据集,并将其放置在你的 IMAGENET_PATH 路径下。
7.2 安装步骤
- 下载代码:
git clone https://github.com/LTH14/JiT.git
cd JiT
- 创建并激活名为 jit 的适配 conda 环境:
conda env create -f environment.yaml
conda activate jit
- 若导入 PyTorch 时出现 undefined symbol: iJIT_NotifyEvent 错误,直接执行以下命令修复:
pip uninstall torch
pip install torch==2.5.1 --index-url https://download.pytorch.org/whl/cu124
更多细节可参考相关 Issue(注:原文未提供具体 Issue 链接,保留原文表述逻辑)。
7.3 训练
以下训练脚本已在 8 张 H200 GPU 上完成测试。
在 ImageNet 256×256 分辨率下训练 JiT-B/16 模型,共 600 轮的示例脚本:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_jit.py \
--model JiT-B/16 \
--proj_dropout 0.0 \
--P_mean -0.8 --P_std 0.8 \
--img_size 256 --noise_scale 1.0 \
--batch_size 128 --blr 5e-5 \
--epochs 600 --warmup_epochs 5 \
--gen_bsz 128 --num_images 50000 --cfg 2.9 --interval_min 0.1 --interval_max 1.0 \
--output_dir ${OUTPUT_DIR} --resume ${OUTPUT_DIR} \
--data_path ${IMAGENET_PATH} --online_eval
训练ImageNet 512x512的JiT-B/32模型600个周期的示例脚本:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_jit.py \
--model JiT-B/32 \
--proj_dropout 0.0 \
--P_mean -0.8 --P_std 0.8 \
--img_size 512 --noise_scale 2.0 \
--batch_size 128 --blr 5e-5 \
--epochs 600 --warmup_epochs 5 \
--gen_bsz 128 --num_images 50000 --cfg 2.9 --interval_min 0.1 --interval_max 1.0 \
--output_dir ${OUTPUT_DIR} --resume ${OUTPUT_DIR} \
--data_path ${IMAGENET_PATH} --online_eval
训练ImageNet 256x256的JiT-H/16模型600个周期的示例脚本:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_jit.py \
--model JiT-H/16 \
--proj_dropout 0.2 \
--P_mean -0.8 --P_std 0.8 \
--img_size 256 --noise_scale 1.0 \
--batch_size 128 --blr 5e-5 \
--epochs 600 --warmup_epochs 5 \
--gen_bsz 128 --num_images 50000 --cfg 2.2 --interval_min 0.1 --interval_max 1.0 \
--output_dir ${OUTPUT_DIR} --resume ${OUTPUT_DIR} \
--data_path ${IMAGENET_PATH} --online_eval
7.4 评估
评估一个已训练的 JiT:
torchrun --nproc_per_node=8 --nnodes=1 --node_rank=0 \
main_jit.py \
--model JiT-B/16 \
--img_size 256 --noise_scale 1.0 \
--gen_bsz 128 --num_images 50000 --cfg 2.9 --interval_min 0.1 --interval_max 1.0 \
--output_dir ${CKPT_DIR} --resume ${CKPT_DIR} \
--data_path ${IMAGENET_PATH} --evaluate_gen
我们使用定制的torch-fidelity来评估与参考图像文件夹或统计数据的FID和IS。您可以使用prepare_ref.py来准备参考图像文件夹,或者直接使用我们预先计算的参考统计数据,这些数据位于fid_stats目录下。
import argparse
import datetime
import numpy as np
import os
import time
from pathlib import Path
import torch
import torch.backends.cudnn as cudnn
from torch.utils.tensorboard import SummaryWriter
import torchvision.transforms as transforms
import torchvision.datasets as datasets
from util.crop import center_crop_arr
import util.misc as misc
import copy
from engine_jit import train_one_epoch, evaluate
from denoiser import Denoiser
def get_args_parser():
parser = argparse.ArgumentParser('JiT', add_help=False)
# architecture
parser.add_argument('--model', default='JiT-B/16', type=str, metavar='MODEL',
help='Name of the model to train')
parser.add_argument('--img_size', default=256, type=int, help='Image size')
parser.add_argument('--attn_dropout', type=float, default=0.0, help='Attention dropout rate')
parser.add_argument('--proj_dropout', type=float, default=0.0, help='Projection dropout rate')
# training
parser.add_argument('--epochs', default=200, type=int)
parser.add_argument('--warmup_epochs', type=int, default=5, metavar='N',
help='Epochs to warm up LR')
parser.add_argument('--batch_size', default=128, type=int,
help='Batch size per GPU (effective batch size = batch_size * # GPUs)')
parser.add_argument('--lr', type=float, default=None, metavar='LR',
help='Learning rate (absolute)')
parser.add_argument('--blr', type=float, default=5e-5, metavar='LR',
help='Base learning rate: absolute_lr = base_lr * total_batch_size / 256')
parser.add_argument('--min_lr', type=float, default=0., metavar='LR',
help='Minimum LR for cyclic schedulers that hit 0')
parser.add_argument('--lr_schedule', type=str, default='constant',
help='Learning rate schedule')
parser.add_argument('--weight_decay', type=float, default=0.0,
help='Weight decay (default: 0.0)')
parser.add_argument('--ema_decay1', type=float, default=0.9999,
help='The first ema to track. Use the first ema for sampling by default.')
parser.add_argument('--ema_decay2', type=float, default=0.9996,
help='The second ema to track')
parser.add_argument('--P_mean', default=-0.8, type=float)
parser.add_argument('--P_std', default=0.8, type=float)
parser.add_argument('--noise_scale', default=1.0, type=float)
parser.add_argument('--t_eps', default=5e-2, type=float)
parser.add_argument('--label_drop_prob', default=0.1, type=float)
parser.add_argument('--seed', default=0, type=int)
parser.add_argument('--start_epoch', default=0, type=int, metavar='N',
help='Starting epoch')
parser.add_argument('--num_workers', default=12, type=int)
parser.add_argument('--pin_mem', action='store_true',
help='Pin CPU memory in DataLoader for faster GPU transfers')
parser.add_argument('--no_pin_mem', action='store_false', dest='pin_mem')
parser.set_defaults(pin_mem=True)
# sampling
parser.add_argument('--sampling_method', default='heun', type=str,
help='ODE samping method')
parser.add_argument('--num_sampling_steps', default=50, type=int,
help='Sampling steps')
parser.add_argument('--cfg', default=1.0, type=float,
help='Classifier-free guidance factor')
parser.add_argument('--interval_min', default=0.0, type=float,
help='CFG interval min')
parser.add_argument('--interval_max', default=1.0, type=float,
help='CFG interval max')
parser.add_argument('--num_images', default=50000, type=int,
help='Number of images to generate')
parser.add_argument('--eval_freq', type=int, default=40,
help='Frequency (in epochs) for evaluation')
parser.add_argument('--online_eval', action='store_true')
parser.add_argument('--evaluate_gen', action='store_true')
parser.add_argument('--gen_bsz', type=int, default=256,
help='Generation batch size')
# dataset
parser.add_argument('--data_path', default='./data/imagenet', type=str,
help='Path to the dataset')
parser.add_argument('--class_num', default=1000, type=int)
# checkpointing
parser.add_argument('--output_dir', default='./output_dir',
help='Directory to save outputs (empty for no saving)')
parser.add_argument('--resume', default='',
help='Folder that contains checkpoint to resume from')
parser.add_argument('--save_last_freq', type=int, default=5,
help='Frequency (in epochs) to save checkpoints')
parser.add_argument('--log_freq', default=100, type=int)
parser.add_argument('--device', default='cuda',
help='Device to use for training/testing')
# distributed training
parser.add_argument('--world_size', default=1, type=int,
help='Number of distributed processes')
parser.add_argument('--local_rank', default=-1, type=int)
parser.add_argument('--dist_on_itp', action='store_true')
parser.add_argument('--dist_url', default='env://',
help='URL used to set up distributed training')
return parser
def main(args):
misc.init_distributed_mode(args)
print('Job directory:', os.path.dirname(os.path.realpath(__file__)))
print("Arguments:\n{}".format(args).replace(', ', ',\n'))
device = torch.device(args.device)
# Set seeds for reproducibility
seed = args.seed + misc.get_rank()
torch.manual_seed(seed)
np.random.seed(seed)
cudnn.benchmark = True
num_tasks = misc.get_world_size()
global_rank = misc.get_rank()
# Set up TensorBoard logging (only on main process)
if global_rank == 0 and args.output_dir is not None:
os.makedirs(args.output_dir, exist_ok=True)
log_writer = SummaryWriter(log_dir=args.output_dir)
else:
log_writer = None
# Data augmentation transforms
transform_train = transforms.Compose([
transforms.Lambda(lambda img: center_crop_arr(img, args.img_size)),
transforms.RandomHorizontalFlip(),
transforms.PILToTensor()
])
dataset_train = datasets.ImageFolder(os.path.join(args.data_path, 'train'), transform=transform_train)
print(dataset_train)
sampler_train = torch.utils.data.DistributedSampler(
dataset_train, num_replicas=num_tasks, rank=global_rank, shuffle=True
)
print("Sampler_train =", sampler_train)
data_loader_train = torch.utils.data.DataLoader(
dataset_train, sampler=sampler_train,
batch_size=args.batch_size,
num_workers=args.num_workers,
pin_memory=args.pin_mem,
drop_last=True
)
torch._dynamo.config.cache_size_limit = 128
torch._dynamo.config.optimize_ddp = False
# Create denoiser
model = Denoiser(args)
print("Model =", model)
n_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print("Number of trainable parameters: {:.6f}M".format(n_params / 1e6))
model.to(device)
eff_batch_size = args.batch_size * misc.get_world_size()
if args.lr is None: # only base_lr (blr) is specified
args.lr = args.blr * eff_batch_size / 256
print("Base lr: {:.2e}".format(args.lr * 256 / eff_batch_size))
print("Actual lr: {:.2e}".format(args.lr))
print("Effective batch size: %d" % eff_batch_size)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.gpu])
model_without_ddp = model.module
# Set up optimizer with weight decay adjustment for bias and norm layers
param_groups = misc.add_weight_decay(model_without_ddp, args.weight_decay)
optimizer = torch.optim.AdamW(param_groups, lr=args.lr, betas=(0.9, 0.95))
print(optimizer)
# Resume from checkpoint if provided
checkpoint_path = os.path.join(args.resume, "checkpoint-last.pth") if args.resume else None
if checkpoint_path and os.path.exists(checkpoint_path):
checkpoint = torch.load(checkpoint_path, map_location='cpu')
model_without_ddp.load_state_dict(checkpoint['model'])
ema_state_dict1 = checkpoint['model_ema1']
ema_state_dict2 = checkpoint['model_ema2']
model_without_ddp.ema_params1 = [ema_state_dict1[name].cuda() for name, _ in model_without_ddp.named_parameters()]
model_without_ddp.ema_params2 = [ema_state_dict2[name].cuda() for name, _ in model_without_ddp.named_parameters()]
print("Resumed checkpoint from", args.resume)
if 'optimizer' in checkpoint and 'epoch' in checkpoint:
optimizer.load_state_dict(checkpoint['optimizer'])
args.start_epoch = checkpoint['epoch'] + 1
print("Loaded optimizer & scaler state!")
del checkpoint
else:
model_without_ddp.ema_params1 = copy.deepcopy(list(model_without_ddp.parameters()))
model_without_ddp.ema_params2 = copy.deepcopy(list(model_without_ddp.parameters()))
print("Training from scratch")
# Evaluate generation
if args.evaluate_gen:
print("Evaluating checkpoint at {} epoch".format(args.start_epoch))
with torch.random.fork_rng():
torch.manual_seed(seed)
with torch.no_grad():
evaluate(model_without_ddp, args, 0, batch_size=args.gen_bsz, log_writer=log_writer)
return
# Training loop
print(f"Start training for {args.epochs} epochs")
start_time = time.time()
for epoch in range(args.start_epoch, args.epochs):
if args.distributed:
data_loader_train.sampler.set_epoch(epoch)
train_one_epoch(model, model_without_ddp, data_loader_train, optimizer, device, epoch, log_writer=log_writer, args=args)
# Save checkpoint periodically
if epoch % args.save_last_freq == 0 or epoch + 1 == args.epochs:
misc.save_model(
args=args,
model_without_ddp=model_without_ddp,
optimizer=optimizer,
epoch=epoch,
epoch_name="last"
)
if epoch % 100 == 0 and epoch > 0:
misc.save_model(
args=args,
model_without_ddp=model_without_ddp,
optimizer=optimizer,
epoch=epoch
)
# Perform online evaluation at specified intervals
if args.online_eval and (epoch % args.eval_freq == 0 or epoch + 1 == args.epochs):
torch.cuda.empty_cache()
with torch.no_grad():
evaluate(model_without_ddp, args, epoch, batch_size=args.gen_bsz, log_writer=log_writer)
torch.cuda.empty_cache()
if misc.is_main_process() and log_writer is not None:
log_writer.flush()
total_time = time.time() - start_time
total_time_str = str(datetime.timedelta(seconds=int(total_time)))
print('Training time:', total_time_str)
if __name__ == '__main__':
args = get_args_parser().parse_args()
Path(args.output_dir).mkdir(parents=True, exist_ok=True)
main(args)
8. 参考文献
[1] Michael Samuel Albergo and Eric Vanden-Eijnden. Buildingnormalizing flows with stochastic interpolants. In ICLR,2023.
[2] Alexander A Alemi, Ian Fischer, Joshua V Dillon, and KevinMurphy. Deep variational information bottleneck. In ICLR,2017.
[3] Gunnar Carlsson. Topology and data. Bulletin of the AmericanMathematical Society, 46(2):255–308, 2009.
[4] Olivier Chapelle, Bernhard Sch¨olkopf, and Alexander Zien,editors. Semi-Supervised Learning. MIT Press, Cambridge,MA, USA, 2006.
[5] Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, andDavid K Duvenaud. Neural ordinary differential equations.In NeurIPS, 2018.
[6] Shoufa Chen, Chongjian Ge, Shilong Zhang, Peize Sun, andPing Luo. PixelFlow: Pixel-space generative models withflow. arXiv:2504.07963, 2025.
[7] Ting Chen. On the importance of noise scheduling for diffusionmodels. arXiv:2301.10972, 2023.
[8] Xinlei Chen, Zhuang Liu, Saining Xie, and Kaiming He. Deconstructingdenoising diffusion models for self-supervisedlearning. In ICLR, 2025.
[9] Kostadin Dabov, Alessandro Foi, Vladimir Katkovnik, andKaren Egiazarian. Image denoising by sparse 3-D transformdomaincollaborative filtering. IEEE Transactions on imageprocessing, 16(8):2080–2095, 2007.
[10] Mauricio Delbracio and Peyman Milanfar. Inversion by directiteration: An alternative to denoising diffusion for imagerestoration. Transactions on Machine Learning Research,2023.
[11] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,and Li Fei-Fei. ImageNet: A large-scale hierarchical imagedatabase. In CVPR, 2009.
[12] Prafulla Dhariwal and Alexander Nichol. Diffusion modelsbeat GANs on image synthesis. In NeurIPS, 2021.
[13] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov,Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner,Mostafa Dehghani, Matthias Minderer, Georg Heigold, SylvainGelly, Jakob Uszkoreit, and Neil Houlsby. An image isworth 16x16 words: Transformers for image recognition atscale. In ICLR, 2021.
[14] Michael Elad and Michal Aharon. Image denoising viasparse and redundant representations over learned dictionaries.IEEE Transactions on Image processing, 15(12):3736–3745, 2006.
[15] Patrick Esser, Sumith Kulal, Andreas Blattmann, RahimEntezari, Jonas M¨uller, Harry Saini, Yam Levi, DominikLorenz, Axel Sauer, Frederic Boesel, Dustin Podell, TimDockhorn, Zion English, and Robin Rombach. Scaling rectifiedflow Transformers for high-resolution image synthesis.In ICML, 2024.
[16] Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, BingXu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, andYoshua Bengio. Generative adversarial nets. In NeurIPS,2014.
[17] Priya Goyal, Piotr Doll´ar, Ross Girshick, Pieter Noordhuis,Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch,Yangqing Jia, and Kaiming He. Accurate, large minibatchSGD: Training ImageNet in 1 hour. arXiv:1706.02677, 2017.
[18] Danijar Hafner,Wilson Yan, and Timothy Lillicrap. Trainingagents inside of scalable world models. arXiv:2509.24527,2025.
[19] Alex Henry, Prudhvi Raj Dachapally, Shubham ShantaramPawar, and Yuxuan Chen. Query-key normalization forTransformers. In Findings of EMNLP, 2020.
[20] Karl Heun. Neue methoden zur approximativen integrationder differentialgleichungen einer unabh¨angigen ver¨anderlichen.Z. Math. Phys, 45:23–38, 1900.
[21] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,Bernhard Nessler, and Sepp Hochreiter. GANs trained bya two time-scale update rule converge to a local Nash equilibrium.NeurIPS, 2017.
[22] Jonathan Ho and Tim Salimans. Classifier-free diffusionguidance. In NeurIPS Workshops, 2021.
[23] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusionprobabilistic models. In NeurIPS, 2020.
[24] Jonathan Ho, Ajay Jain, and Pieter Abbeel. DDPM githubrepo. L155, diffusion utils 2.py, 2020.
[25] Emiel Hoogeboom, Jonathan Heek, and Tim Salimans. simplediffusion: End-to-end diffusion for high resolution images.ICML, 2023.
[26] Emiel Hoogeboom, Thomas Mensink, Jonathan Heek, KayLamerigts, Ruiqi Gao, and Tim Salimans. Simpler Diffusion(SiD2): 1.5 FID on ImageNet512 with pixel-space diffusion.In CVPR, 2025.
[27] Ahmed Imtiaz Humayun, Ibtihel Amara, Cristina Vasconcelos,Deepak Ramachandran, Candice Schumann, JunfengHe, Katherine Heller, Golnoosh Farnadi, Negar Rostamzadeh,and Mohammad Havaei. What secrets do yourmanifolds hold? understanding the local geometry of generativemodels. In ICLR, 2025.
[28] Allan Jabri, David Fleet, and Ting Chen. Scalable adaptivecomputation for iterative generation. In ICML, 2023.
[29] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine.Elucidating the design space of diffusion-based generativemodels. In NeurIPS, 2022.
[30] Diederik Kingma and Ruiqi Gao. Understanding diffusionobjectives as the ELBO with simple data augmentation. InNeurIPS, 2023.
[31] Diederik P Kingma and Jimmy Ba. Adam: A method forstochastic optimization. In ICLR, 2015.
[32] Tuomas Kynk¨a¨anniemi, Tero Karras, Samuli Laine, JaakkoLehtinen, and Timo Aila. Improved precision and recall metricfor assessing generative models. NeurIPS, 2019.
[33] Tuomas Kynk¨a¨anniemi, Miika Aittala, Tero Karras, SamuliLaine, Timo Aila, and Jaakko Lehtinen. Applying guidancein a limited interval improves sample and distribution qualityin diffusion models. In NeurIPS, 2024.
[34] Jiachen Lei, Keli Liu, Julius Berner, Haiming Yu, HongkaiZheng, Jiahong Wu, and Xiangxiang Chu. Advancing endto-end pixel space generative modeling via self-supervisedpre-training. arXiv:2510.12586, 2025.
[35] Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, andKaiming He. Autoregressive image generation without vectorquantization. In NeurIPS, 2024.
[36] Tianhong Li, Qinyi Sun, Lijie Fan, and Kaiming He. Fractalgenerative models. arXiv:2502.17437, 2025.
[37] Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, MaximilianNickel, and Matt Le. Flow matching for generative modeling.In ICLR, 2023.
[38] Xingchao Liu, Chengyue Gong, and Qiang Liu. Flowstraight and fast: Learning to generate and transfer data withrectified flow. In ICLR, 2023.
[39] Gabriel Loaiza-Ganem, Brendan Leigh Ross, Rasa Hosseinzadeh,Anthony L Caterini, and Jesse C Cresswell. Deepgenerative models through the lens of the manifold hypothesis:A survey and new connections. Transactions on MachineLearning Research, 2024.
[40] Nanye Ma, Mark Goldstein, Michael S Albergo, Nicholas MBoffi, Eric Vanden-Eijnden, and Saining Xie. SiT: Exploringflow and diffusion-based generative models with scalableinterpolant Transformers. In ECCV, 2024.
[41] Alireza Makhzani and Brendan Frey. K-sparse autoencoders.arXiv:1312.5663, 2013.
[42] Peyman Milanfar and Mauricio Delbracio. Denoising: apowerful building block for imaging, inverse problems andmachine learning. Philosophical Transactions A, 383(2299):20240326, 2025.
[43] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik,Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. NeRF:Representing scenes as neural radiance fields for view synthesis.Communications of the ACM, 65(1):99–106, 2021.
[44] Alexander Quinn Nichol and Prafulla Dhariwal. Improveddenoising diffusion probabilistic models. In ICML, 2021.
[45] Maxime Oquab et al. DINOv2: Learning robust visual featureswithout supervision. Transactions on Machine LearningResearch, 2023.
[46] William Peebles and Saining Xie. Scalable diffusion modelswith Transformers. In ICCV, 2023.
[47] Javier Portilla, Vasily Strela, Martin J Wainwright, andEero P Simoncelli. Image denoising using scale mixturesof Gaussians in the wavelet domain. IEEE Transactions onImage processing, 12(11):1338–1351, 2003.
[48] Salah Rifai, Pascal Vincent, Xavier Muller, Xavier Glorot,and Yoshua Bengio. Contractive auto-encoders: Explicit invarianceduring feature extraction. In ICML, 2011.
[49] Robin Rombach, Andreas Blattmann, Dominik Lorenz,Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesiswith latent diffusion models. In CVPR, 2022.
[50] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. UNet:Convolutional networks for biomedical image segmentation.In MICCAI, 2015.
[51] Sam T Roweis and Lawrence K Saul. Nonlinear dimensionalityreduction by locally linear embedding. Science, 290(5500):2323–2326, 2000.
[52] Tim Salimans and Jonathan Ho. Progressive distillation forfast sampling of diffusion models. In ICLR, 2022.
[53] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, VickiCheung, Alec Radford, and Xi Chen. Improved techniquesfor training GANs. NeurIPS, 29, 2016.
[54] Noam Shazeer. GLU variants improve Transformer.arXiv:2002.05202, 2020.
[55] Minglei Shi, Haolin Wang, Wenzhao Zheng, Ziyang Yuan,Xiaoshi Wu, Xintao Wang, Pengfei Wan, Jie Zhou, and JiwenLu. Latent diffusion model without variational autoencoder.arXiv:2510.15301, 2025.
[56] Karen Simonyan and Andrew Zisserman. Very deepconvolutional networks for large-scale image recognition.arXiv:1409.1556, 2014.
[57] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan,and Surya Ganguli. Deep unsupervised learning usingnonequilibrium thermodynamics. In ICML, 2015.
[58] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoisingdiffusion implicit models. In ICLR, 2021.
[59] Yang Song and Stefano Ermon. Generative modeling by estimatinggradients of the data distribution. In NeurIPS, 2019.
[60] Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, AbhishekKumar, Stefano Ermon, and Ben Poole. Score-basedgenerative modeling through stochastic differential equations.In ICLR, 2021.
[61] Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, IlyaSutskever, and Ruslan Salakhutdinov. Dropout: a simple wayto prevent neural networks from overfitting. The journal ofmachine learning research, 15(1):1929–1958, 2014.
[62] Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, WenBo, and Yunfeng Liu. RoFormer: Enhanced Transformerwith rotary position embedding. Neurocomputing, 568:127063, 2024.
[63] Joshua B Tenenbaum, Vin de Silva, and John C Langford.A global geometric framework for nonlinear dimensionalityreduction. Science, 290(5500):2319–2323, 2000.
[64] Naftali Tishby, Fernando C Pereira, and William Bialek.The information bottleneck method. arXiv preprintphysics/0004057, 2000.
[65] Michael Tschannen, Andr´e Susano Pinto, and AlexanderKolesnikov. JetFormer: an autoregressive generative modelof raw images and text. In ICLR, 2025.
[66] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,Llion Jones, Aidan N Gomez, Łukasz Kaiser, and IlliaPolosukhin. Attention is all you need. NeurIPS, 2017.
[67] Pascal Vincent. A connection between score matching anddenoising autoencoders. Neural computation, 23(7):1661–1674, 2011.
[68] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, andPierre-Antoine Manzagol. Extracting and composing robustfeatures with denoising autoencoders. In ICML, 2008.
[69] Pascal Vincent, Hugo Larochelle, Isabelle Lajoie, YoshuaBengio, Pierre-Antoine Manzagol, and L´eon Bottou.Stacked denoising autoencoders: Learning useful representationsin a deep network with a local denoising criterion.Journal of Machine Learning Research, 11(12), 2010.
[70] Shuai Wang, Ziteng Gao, Chenhui Zhu, Weilin Huang,and Limin Wang. PixNerd: Pixel neural field diffusion.arXiv:2507.23268, 2025.
[71] Shuai Wang, Zhi Tian, Weilin Huang, and Limin Wang.DDT: Decoupled diffusion Transformer. arXiv:2504.05741,2025.
[72] Yutong Xie, Minne Yuan, Bin Dong, and Quanzheng Li. Diffusionmodel for generative image denoising. In ICCV, 2023.
[73] Jingfeng Yao, Bin Yang, and Xinggang Wang. Reconstructionvs. generation: Taming optimization dilemma in latentdiffusion models. In CVPR, 2025.
[74] Sihyun Yu, Sangkyung Kwak, Huiwon Jang, JongheonJeong, Jonathan Huang, Jinwoo Shin, and Saining Xie.Representation alignment for generation: Training diffusionTransformers is easier than you think. In ICLR, 2025.
[75] Biao Zhang and Rico Sennrich. Root mean square layer normalization.In NeurIPS, 2019.
[76] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman,and Oliver Wang. The unreasonable effectiveness of deepfeatures as a perceptual metric. In CVPR, 2018.
[77] Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman,and Oliver Wang. The unreasonable effectiveness of deepfeatures as a perceptual metric. In CVPR, 2018.
[78] Boyang Zheng, Nanye Ma, Shengbang Tong, and SainingXie. Diffusion Transformers with representation autoencoders.arXiv:2510.11690, 2025.
[79] Daniel Zoran and Yair Weiss. From learning models of naturalimage patches to whole image restoration. In ICCV,2011.
引用格式: Li T H, He K M. Back to Basics: Let Denoising Generative Models Denoise (EB/OL). (2025-11-17) [2025-XX-XX]. https://arxiv.org/pdf/2511.13720.
版权说明:
youcans@xidian 作品,转载必须标注原文链接:
【youcans论文精读】回归基础:让去噪生成模型来去噪(https://youcans.blog.csdn.net/article/details/153210209)
Crated:2025-11

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献234条内容
已为社区贡献234条内容

所有评论(0)