Agent之Reflexion
本文探讨了LangChain框架中Reflexion模块的实现与论文原版的差异。LangChain版本主要通过Revisor组件实现答案迭代优化,包含生成反思、搜索查询和修订答案的循环过程。而原论文Reflexion架构更强调记忆系统,包含短期记忆(记录历史优化轨迹)和长期记忆(存储优化经验)两个核心模块。实验代码可见于GitHub项目llm-reasoners,展示了基于语言模型的强化学习在智能
文章目录
前言
阅读之前,建议先阅读下上篇:Agent之reflection
论文:Reflexion: Language Agents with Verbal Reinforcement Learning
GIthub: https://github.com/noahshinn/reflexion
本文实验代码:https://github.com/seanzhang-zhichen/llm-reasoners
langchain中的reflexion
我们先从一个简单的例子说起,先来看看langchain的reflexion的实现。
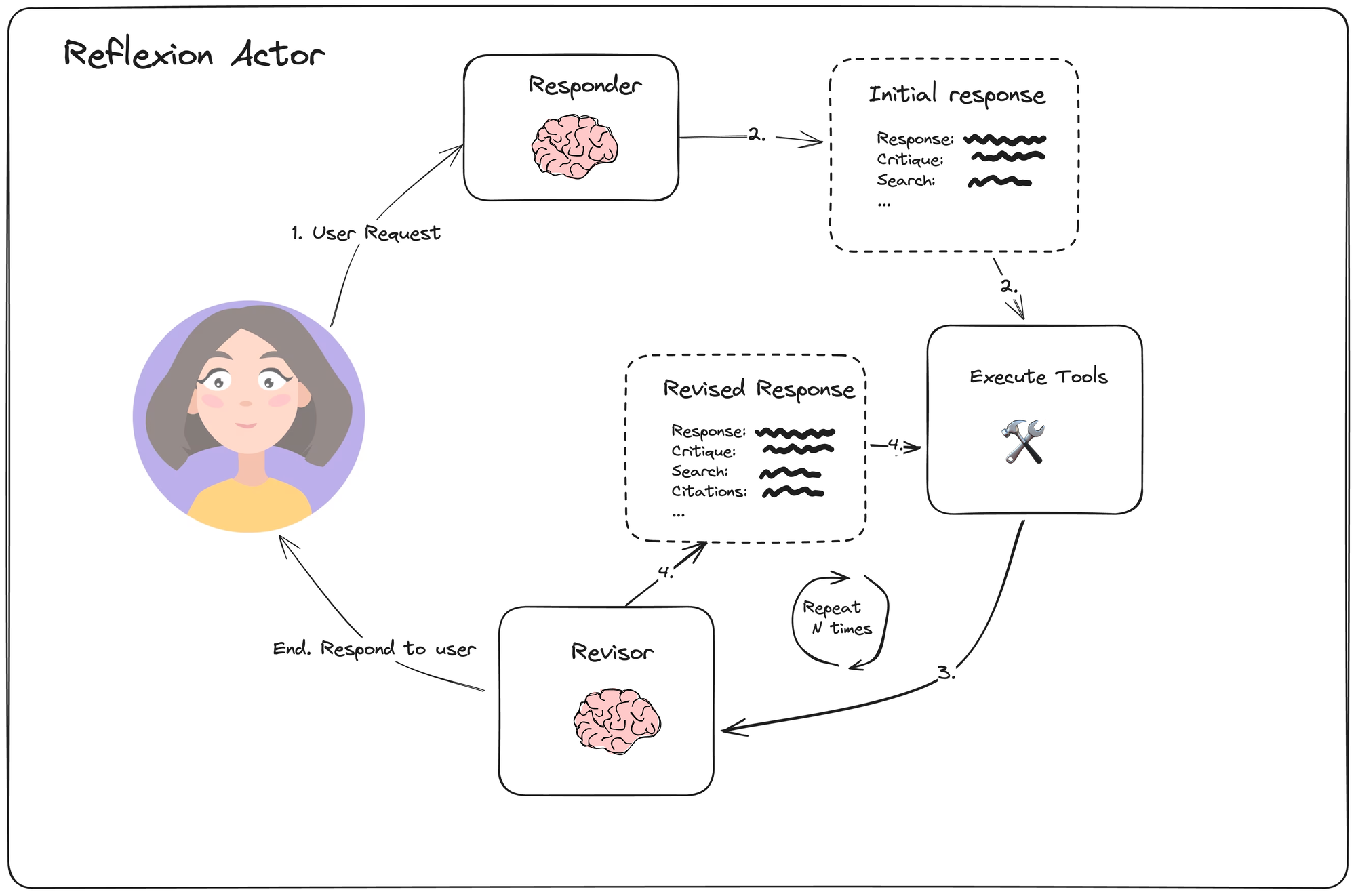
从上图可以看的出来,Reflexion中最重要的部分就是Revisor了
结合代码理解:
class Reflection(BaseModel):
missing: str = Field(description="对答案中“缺失内容”的批评与指出")
superfluous: str = Field(description="对答案中“多余或冗余内容”的批评与指出。")
class AnswerQuestion(BaseModel):
"""回答问题。提供答案、反思,并随后提出搜索查询以改进答案。"""
answer: str = Field(description="约250字的详细答案。")
reflection: Reflection = Field(description="对初始答案的反思。")
search_queries: list[str] = Field(
description="1-3个搜索查询,用于研究如何改进当前答案以回应批评。"
)
class ReviseAnswer(AnswerQuestion):
"""根据新信息修订原始答案,并添加参考资料。"""
references: list[str] = Field(description="支持更新答案的引用。")
def build_actor_prompt() -> ChatPromptTemplate:
return ChatPromptTemplate.from_messages(
[
(
"system",
"""你是一名专业的研究人员。
当前时间:{time}
1. {first_instruction}
2. 反思并批评你的答案。要严格,以最大化改进。
3. 推荐搜索查询以研究信息并改进你的答案。""",
),
MessagesPlaceholder(variable_name="messages"),
(
"user",
"\n\n<system>请反思用户的原始问题和至今已采取的操作。"
" 使用{function_name}函数回复。</reminder>",
),
]
).partial(time=lambda: datetime.datetime.now().isoformat())
class ResponderWithRetries:
"""对 LangChain runnable 进行封装,失败时自动重试。"""
def __init__(self, runnable, validator, max_attempts: int = 3):
self.runnable = runnable
self.validator = validator
self.max_attempts = max_attempts
def respond(self, state: dict):
messages: list[BaseMessage] = state["messages"]
response: AIMessage | None = None
for attempt in range(self.max_attempts):
logger.info("尝试第 %s 次调用 runnable", attempt + 1)
response = self.runnable.invoke(
{"messages": messages},
{"tags": [f"attempt:{attempt}"]},
)
try:
self.validator.invoke(response)
logger.info("验证通过,返回响应")
return {"messages": response}
except ValidationError as err:
logger.warning("验证失败: %s", err)
messages = messages + [
response,
ToolMessage(
content=_format_validation_error(err, self.validator.schema_json()),
tool_call_id=response.tool_calls[0]["id"],
),
]
logger.error("达到最大重试次数,返回最后一次响应")
return {"messages": response}
def build_initial_responder(llm: ChatFireworks, actor_prompt: ChatPromptTemplate) -> ResponderWithRetries:
chain = actor_prompt.partial(
first_instruction="请提供一个约250字的详细答案。",
function_name=AnswerQuestion.__name__,
) | llm.bind_tools(tools=[AnswerQuestion])
validator = PydanticToolsParser(tools=[AnswerQuestion])
return ResponderWithRetries(chain, validator)
REVISION_INSTRUCTIONS = """请使用新信息完善之前的答案。
- 使用之前的反思来添加重要信息到你的答案中。
- 你必须在你的答案中包含数值引用,以确保它可以被验证。
- 在答案底部添加“References”部分(不计入字数),格式:
- [1] https://example.com
- [2] https://example.com
- 使用反思移除多余或冗余的信息,确保答案不超过250字。
"""
def build_revision_responder(llm: ChatFireworks, actor_prompt: ChatPromptTemplate) -> ResponderWithRetries:
chain = actor_prompt.partial(
first_instruction=REVISION_INSTRUCTIONS,
function_name=ReviseAnswer.__name__,
) | llm.bind_tools(tools=[ReviseAnswer])
validator = PydanticToolsParser(tools=[ReviseAnswer])
return ResponderWithRetries(chain, validator)
可以看的出来,Revisor其实就是对初始答案生成 评价/评估/反思,并且生成几个可以改进当前答案的sub query,用sub query去检索数据,然后再基于检索结果重新生成答案,如此往复,直到达到退出条件。
表面上看起来和reflection差不多,唯一区别可能是相比reflection,多了个工具调用的步骤。reflection是利用模型自身知识来优化上一次的响应,而reflexion是利用外部工具(搜索)来优化上一次的响应。
但在Reflexion的论文中,有明确提到,Memory模块是reflexion中的核心组件,这一点在langchain的实现中,并没有被提及。
实际的reflexion
接下来,我们看看实际的reflexion的结构是怎样的,如图:
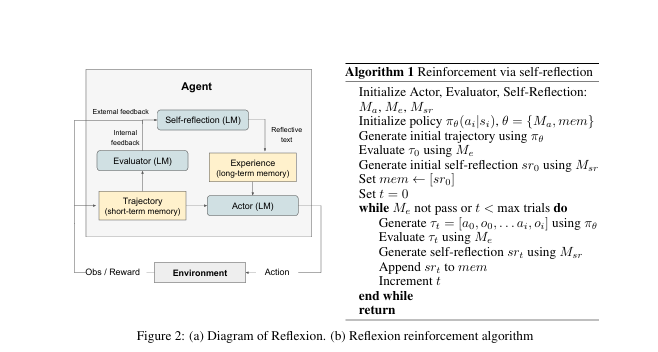
可以看到,原论文中的reflexion确实有两个memory模块:短期记忆和长期记忆模块。
短暂思考下,这两个模块是用来做什么的呢?
答:这两个模块用来记录上一次不足的地方在哪里,下次应该怎么做。举个例子:比如 “刚才写代码没考虑负数情况,测试没通过,下次要加个判断负数的逻辑”。短期记忆(实际上就是历史消息)中存放的是历史优化轨迹,长期记忆存放的是这种情况下次应该怎么做,如:刚才写代码没考虑负数情况,测试没通过,下次要加个判断负数的逻辑,这部分用向量数据库来存会更合适。
实际上,这种用向量库来储存失败经验的或者提示的方法,很有效,去年在处理海量Tool的Agent调用时,用到了类似reflexion的策略。针对处理某个复杂问题,需要连续调用多个Tool的场景时,Agent总是不知道先调用哪个,再调用哪个,后来通过增加一段特定提示,才解决了这种情况。具体做法是,当匹配到当前类型问题时,会从知识库中检索出处理该类型问题的提示出来,加到上下文中。这部分,正好当时也写了篇文章,见:LLM之Agent落地篇
言归正传。
那么,实际的reflexion是如何工作的呢?
以下回答来自豆包:
第一步:AI 先尝试做事(Actor)
比如让 AI 写一段代码、解一个文字游戏任务,AI 会生成一系列 “行动”(比如写代码的步骤、游戏里的操作),形成一条 “尝试轨迹”(比如从开始到失败 / 成功的全过程)。
第二步:判断做得好不好(Evaluator)
有个 “裁判” 角色来评价 AI 的表现:比如写代码就看能不能通过测试、玩游戏就看任务完没完成、回答问题就看答案对不对。评价结果可能是 “过 / 不过”“得分多少”,甚至是具体的错误提示(比如 “这段代码少了个括号”)。
第三步:AI 反思错在哪(Self-Reflection)
最关键的一步:让 AI 把 “裁判的评价” 和 “自己的尝试轨迹” 结合起来,用自然语言总结经验 —— 比如 “刚才写代码没考虑负数情况,测试没通过,下次要加个判断负数的逻辑”“玩游戏时先找了杯子再找台灯,其实应该先找台灯,不然步骤反了”。这些反思会存进 AI 的 “长期记忆” 里。
循环:下次做事用记忆
下次再做类似任务时,AI 会先看之前的 “反思笔记”,避免重复犯错。比如再写同类代码,就会记得加负数判断;再玩同款游戏,就会先找台灯。
不同任务表现
也来自豆包
文字游戏(比如 “AlfWorld”)
任务是让 AI 在文字描述的房间里做事(比如 “找到杯子并用台灯检查它”)。传统 AI 经常犯 “幻觉错误”(比如以为自己拿了杯子,其实没拿),或者步骤混乱;加了 Reflexion 后,12 次尝试内正确率比传统方法高 22%,几乎能完成所有任务。
复杂问答(比如 “HotPotQA”)
任务是让 AI 查资料回答多步骤问题(比如 “《Grown-Ups》里的演员,在《’Allo ’Allo!》里最出名的角色是什么?”)。传统 AI 容易查错资料、漏步骤;Reflexion 让 AI 反思 “上次查错了演员名字,这次要先确认演员列表”,正确率提高了 20%。
写代码(比如 “HumanEval”“LeetCode 难题”)
任务是让 AI 写能运行的代码,甚至处理 19 种编程语言(比如 Python、Rust)。传统 AI 写的代码经常通不过测试,而 Reflexion 会让 AI 自己生成 “测试用例”(比如验证代码是否正确的小脚本),再反思 “测试没通过是因为少了个循环”,最后正确率特别突出。
总结
1、Reflexion 本质是让 AI “学会记教训”—— 不用像以前那样 “练一万次才会”,而是做一次、反思一次、记一次,下次直接避开坑。
2、豆包总结的比我总结的好多了。上面那段也来自豆包

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)