SpringBoot集成Langchain4j-向量库环境构建(Rag前奏)
上一篇SpringBoot集成Langchain4j的大模型本地应用已有几个月了,现在手上活儿不多,打算继续攻坚,上次已经实现了基础的聊天对话和@Tool注解提示回答,现在打算加入Rag解决问答模型的幻觉问题,即跟公司业务强相关的知识,大模型在回答时,不再一本正经的胡说八道,而是结合Rag知识库有的放矢。
上一篇SpringBoot集成Langchain4j的大模型本地应用已有几个月了,现在手上活儿不多,打算继续攻坚,上次已经实现了基础的聊天对话和@Tool注解提示回答,现在打算加入Rag解决问答模型的幻觉问题,即跟公司业务强相关的知识,大模型在回答时,不再一本正经的胡说八道,而是结合Rag知识库有的放矢
# RAG (Retrieval-Augmented Generation)
基本概念
RAG (Retrieval-Augmented Generation) 是一种结合检索与生成的混合AI模型架构,通过从外部知识库检索相关信息来增强生成模型的输出质量。这种技术解决了传统大语言模型(LLM)在知识更新和事实准确性方面的局限性。
工作原理
-
检索阶段:
- 将用户查询转换为向量表示
- 在向量数据库中搜索最相关的文档片段
- 使用相似度算法(如余弦相似度)匹配最相关内容
-
生成阶段:
- 将检索到的相关内容与原始查询结合
- 语言模型基于增强的上下文生成回答
- 可加入引用标注以提高可信度
核心组件
- 检索器:通常使用稠密检索模型如DPR(Dense Passage Retrieval)
- 向量数据库:如FAISS、Milvus、Pinecone等专用向量存储系统
- 生成模型:如GPT-3、LLaMA等大型语言模型
- 知识库:结构化或非结构化的外部数据源
优势特点
- 动态知识更新:无需重新训练模型即可更新知识
- 降低幻觉风险:基于检索到的真实信息生成内容
- 可解释性强:可追踪信息来源
- 领域适应快:通过切换知识库快速适应新领域
发展趋势
当前RAG技术正向多模态检索、主动检索、端到端训练等方向发展,并与提示工程、模型微调等技术结合形成更强大的解决方案。RAG
RAG环境构建
- Milvus向量数据库:本地的搭建的是Milvus-lite【
docker pull milvusdb/milvus:v2.5.14】 - Attu(Milvus客户端):Milvus可视化界面 【
docker run -d -p 8000:3000 -e MILVUS_URL=127.0.0.1:19530 zilliz/attu:v2.5.10】
使用docker下载下面的镜像
a518@liJei ~ % docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
milvusdb/milvus v2.5.14 35b13b51df3f 4 months ago 1.85GB
zilliz/attu v2.5.10 14cd4448834d 5 months ago 423MB
可以使用docker desktop,可视化界面管理镜像确实很方便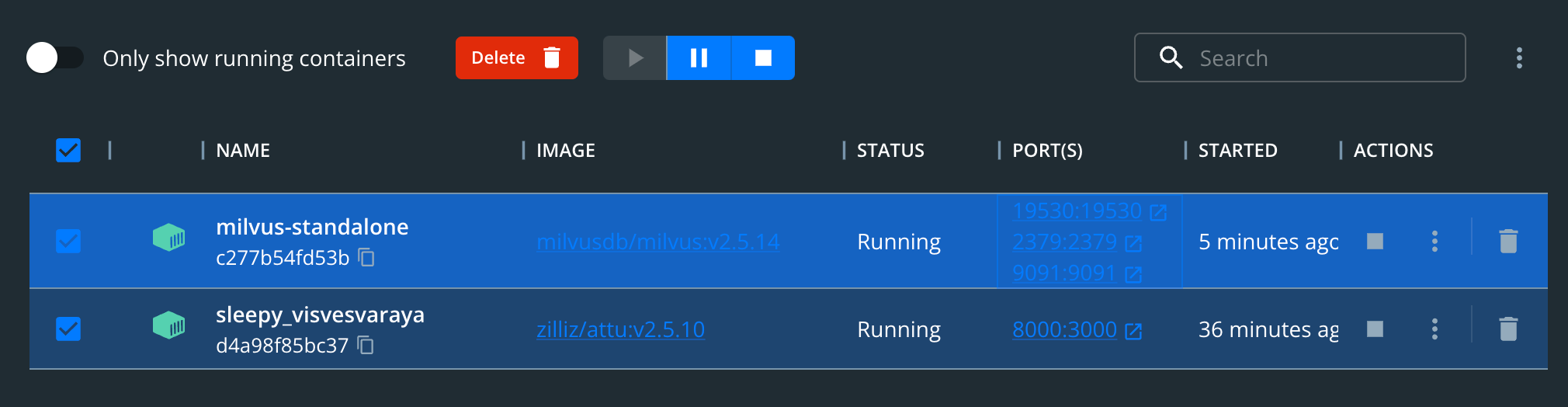
启动后浏览器输入:http://127.0.0.1:8000/#/connect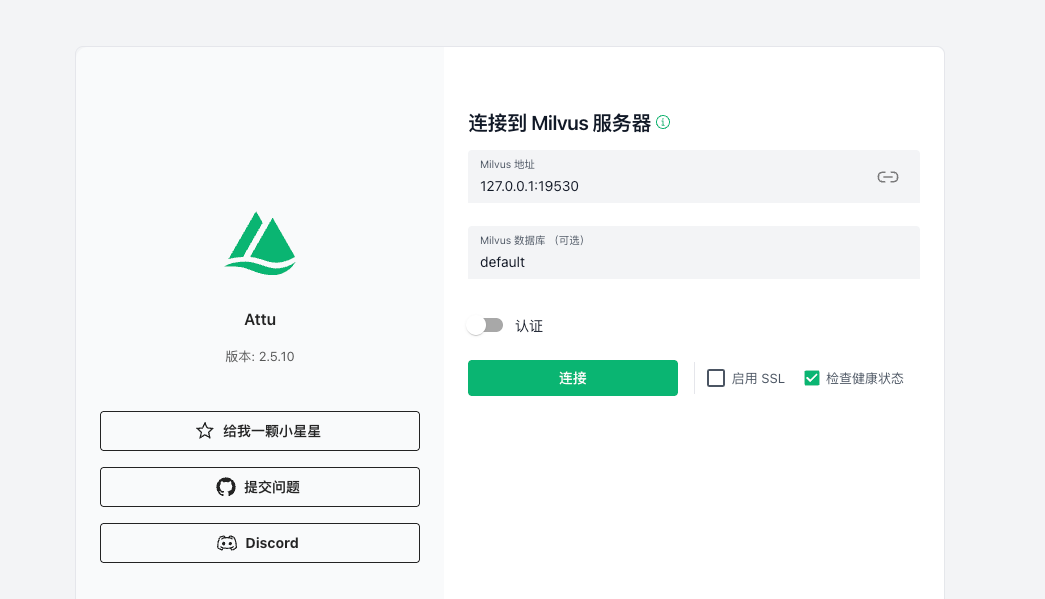
因为都是基于docker访问的,所以直接输入127.0.0.1链接milvus会链接不上:如果是 macOS/Windows → 直接在 Attu 填 【host.docker.internal:19530】,可以连接成功;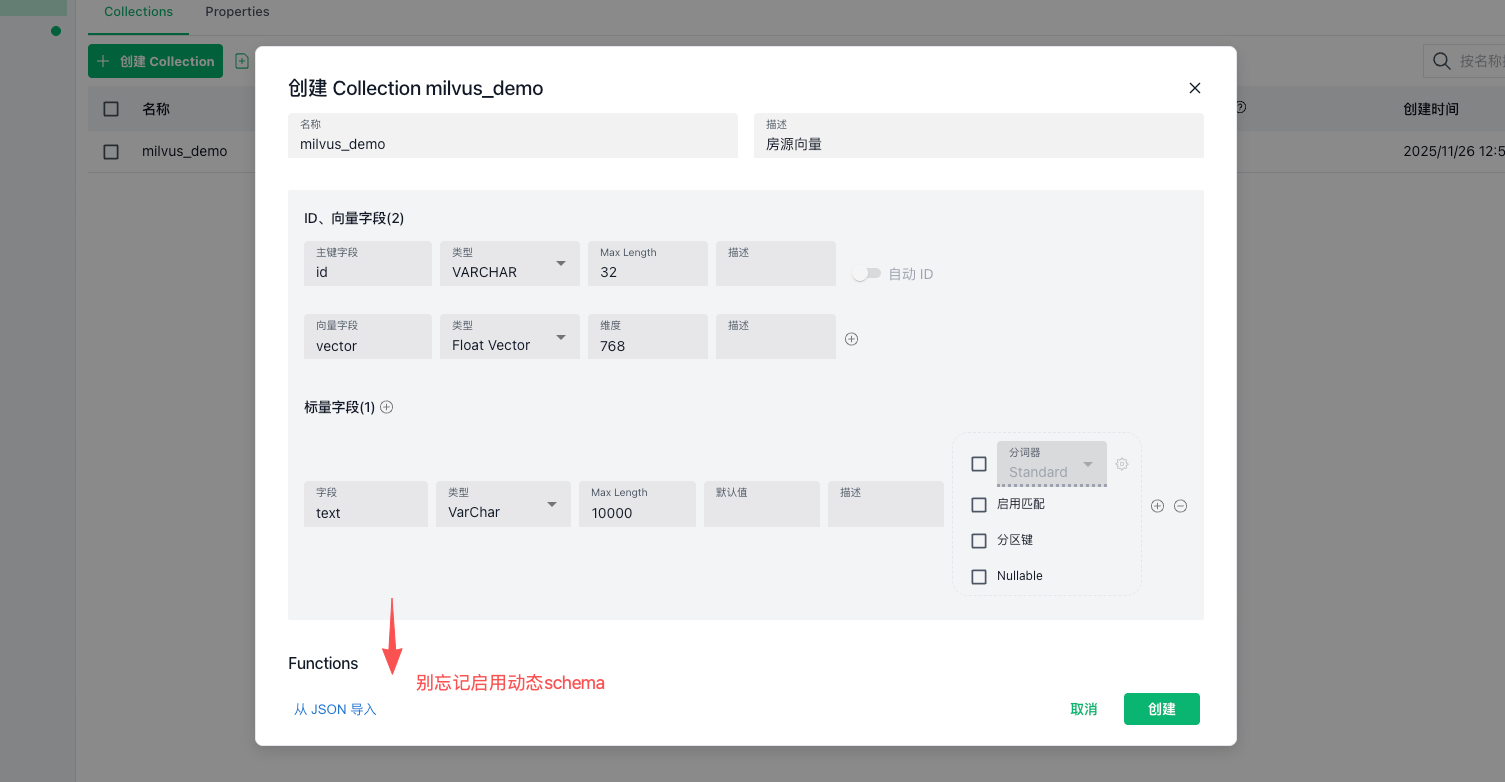
向量的字段
vector、text 和 metadata 在 Milvus 向量数据库中是三个不同的数据结构,作用和存储方式不相同:
- vector 字段
类型:FLOAT_VECTOR
用途:存储向量化后的数值数组
特点:用于相似度计算和语义检索 - text 字段
类型:STRING
用途:存储原始文本内容
特点:可用于文本搜索和展示 - metadata 字段
类型:JSON(动态字段)
用途:存储结构化元数据
特点:支持过滤查询和条件筛选 - 关系说明
vector 是 text 的数学表示,两者对应同一份数据的不同形式
在Milvus中,分为两种字段类型:id和向量、标量字段,text则属于标量字段,再多的字段其实没意义
其中Metadata(元数据)在向量数据库(如 Milvus)和 RAG(Retrieval-Augmented Generation)系统中扮演着 “结构化上下文” 的关键角色。
它的核心作用是:在向量相似度检索的基础上,支持按业务属性进行过滤、排序和结果增强。
比如下面这种数据:
{
"text": "海淀四环内!板楼3居室,中高楼层...",
"vector": [0.12, -0.45, ..., 0.67],
"metadata": {
"id": 403543471323146,
"price": 14600000,
"area": 147.88,
"district": "四季青",
"bedrooms": 3,
"isFullFive": false,
"publishTime": "2025-11-10"
}
}
text + vector → 用于 语义相似度计算
metadata → 用于 业务规则过滤与结果解释,在向量召回 Top-K 结果后,进一步按业务条件筛选
向量化数据存储到milvus
如果大家本地向量化库没有数据,我写了一段初始化的脚本来往本地的milvus插入一组数据,其中milvus的数据集为:milvus_demo,可以在attu上新建或者@Bean调用api新建也可以;
下面是插入数据的Bean:
package com.blue.basic.ai.embed;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import dev.langchain4j.data.document.Metadata;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.ollama.OllamaEmbeddingModel;
import dev.langchain4j.store.embedding.milvus.MilvusEmbeddingStore;
import io.milvus.common.clientenum.ConsistencyLevelEnum;
import jakarta.annotation.PostConstruct;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import io.milvus.param.IndexType;
import io.milvus.param.MetricType;
import java.util.ArrayList;
import java.util.List;
/**
* 向量化存储配置【向量模型、向量数据库】
*/
@Slf4j
@Configuration
public class EmbeddingConfig {
@Value("${milvus.data-status}")
private Boolean dataStatus;// 自定义一个向量库milvus的数据初始化状态
@PostConstruct
public void init() {
System.out.println(dataStatus);
if (!dataStatus) {
// 初始化milvus数据,前提是需要在milvus中建好向量化集合
List<JSONObject> prepareData = JSON.parseArray("[ {\n" +
" \"houseId\" : 100,\n" +
" \"prompt\" : \"二手房帖子,请生成用于向量,突出关键特征:\",\n" +
" \"content\" : \"{\\\"地域ID\\\":\\\"6727\\\",\\\"商圈\\\":\\\"四季青\\\",\\\"小区\\\":\\\"流清园\\\",\\\"总价\\\":\\\"143万\\\",\\\"户型\\\":\\\"3室2厅2卫\\\",\\\"房源特色\\\":\\\"\\\",\\\"房源介绍\\\":\\\"海淀四环内!板楼3居室,中高楼层,中心位置,紧邻双地铁\\\",\\\"建筑面积\\\":\\\"147.88平米\\\",\\\"装修情况\\\":\\\"精装修\\\",\\\"楼层\\\":\\\"7\\\",\\\"房屋朝向\\\":\\\"南北\\\",\\\"详细地址\\\":\\\"云会寺路\\\"}\"\n" +
"}, {\n" +
" \"houseId\" : 200,\n" +
" \"prompt\" : \"二手房帖子,请生成用于向量,突出关键特征:\",\n" +
" \"content\" : \"{\\\"地域ID\\\":\\\"5197\\\",\\\"商圈\\\":\\\"十里堡\\\",\\\"小区\\\":\\\"八里庄东里\\\",\\\"总价\\\":\\\"249万\\\",\\\"户型\\\":\\\"3室1厅1卫\\\",\\\"房源特色\\\":\\\"满五唯一\\\",\\\"房源介绍\\\":\\\"东四环 十里堡 南北两居 明厅 中间层 满五一套 看房方便\\\",\\\"建筑面积\\\":\\\"60.44平米\\\",\\\"装修情况\\\":\\\"简单装修\\\",\\\"楼层\\\":\\\"3\\\",\\\"房屋朝向\\\":\\\"南北\\\",\\\"详细地址\\\":\\\"朝阳路\\\"}\"\n" +
"}, {\n" +
" \"houseId\" : 300,\n" +
" \"prompt\" : \"二手房帖子,请生成用于向量,突出关键特征:\",\n" +
" \"content\" : \"{\\\"地域ID\\\":\\\"3970\\\",\\\"商圈\\\":\\\"西红门\\\",\\\"小区\\\":\\\"橡树湾\\\",\\\"总价\\\":\\\"500万\\\",\\\"户型\\\":\\\"4室2厅2卫\\\",\\\"房源特色\\\":\\\"\\\",\\\"房源介绍\\\":\\\"内部领导急出 无遮挡 可看实体房 西城教育\\\",\\\"建筑面积\\\":\\\"122平米\\\",\\\"装修情况\\\":\\\"精装修\\\",\\\"楼层\\\":\\\"8\\\",\\\"房屋朝向\\\":\\\"南北\\\",\\\"详细地址\\\":\\\"欣顺街39号\\\"}\"\n" +
"}, {\n" +
" \"houseId\" : 400,\n" +
" \"prompt\" : \"二手房帖子,请生成用于向量,突出关键特征:\",\n" +
" \"content\" : \"{\\\"地域ID\\\":\\\"5670\\\",\\\"商圈\\\":\\\"西红门\\\",\\\"小区\\\":\\\"京玺\\\",\\\"总价\\\":\\\"410万\\\",\\\"户型\\\":\\\"5室2厅1卫\\\",\\\"房源特色\\\":\\\"\\\",\\\"房源介绍\\\":\\\"四号线 79平 双阳台 三居 300萬\\\",\\\"建筑面积\\\":\\\"79.0平米\\\",\\\"装修情况\\\":\\\"精装修\\\",\\\"楼层\\\":\\\"\\\",\\\"房屋朝向\\\":\\\"南北\\\",\\\"详细地址\\\":\\\"大兴福海东路福苑小区东南侧约130米\\\"}\"\n" +
"}, {\n" +
" \"houseId\" : 500,\n" +
" \"prompt\" : \"二手房帖子,请生成用于向量,突出关键特征:\",\n" +
" \"content\" : \"{\\\"地域ID\\\":\\\"4506\\\",\\\"商圈\\\":\\\"长阳\\\",\\\"小区\\\":\\\"中海寰宇视界\\\",\\\"总价\\\":\\\"100万\\\",\\\"户型\\\":\\\"4室2厅3卫\\\",\\\"房源特色\\\":\\\"\\\",\\\"房源介绍\\\":\\\"五环 现房 近地铁 60平一居 170萬\\\",\\\"建筑面积\\\":\\\"280.0平米\\\",\\\"装修情况\\\":\\\"精装修\\\",\\\"楼层\\\":\\\"\\\",\\\"房屋朝向\\\":\\\"南北\\\",\\\"详细地址\\\":\\\"西五环稻田站南200米\\\"}\"\n" +
"}, {\n" +
" \"houseId\" : 600,\n" +
" \"prompt\" : \"二手房帖子,请生成用于向量,突出关键特征:\",\n" +
" \"content\" : \"{\\\"地域ID\\\":\\\"3374\\\",\\\"商圈\\\":\\\"潞苑\\\",\\\"小区\\\":\\\"珠江丽景家园\\\",\\\"总价\\\":\\\"240万\\\",\\\"户型\\\":\\\"4室1厅1卫\\\",\\\"房源特色\\\":\\\"满五唯一\\\",\\\"房源介绍\\\":\\\"通州友谊医院旁 南北通透两居室 业主急售 看房有钥匙\\\",\\\"建筑面积\\\":\\\"77.90平米\\\",\\\"装修情况\\\":\\\"精装修\\\",\\\"楼层\\\":\\\"6\\\",\\\"房屋朝向\\\":\\\"南北\\\",\\\"详细地址\\\":\\\"潞苑南大街\\\"}\"\n" +
"} ]", JSONObject.class);
// 获取 embedding 模型和存储实例
OllamaEmbeddingModel embeddingModel = genEmbeddingModel();
MilvusEmbeddingStore milvusEmbeddingStore = genEmbeddingStore();
List<String> ids = new ArrayList<>();
List<Embedding> embeddings = new ArrayList<>();
List<TextSegment> textSegments = new ArrayList<>();
try {
for (JSONObject item : prepareData) {
Long id = item.getLong("houseId");
JSONObject contentObj = JSON.parseObject(item.getString("content"));
Embedding embedding = embeddingModel.embed(contentObj.toJSONString()).content();
Metadata metadata = Metadata
.from("price", contentObj.getString("总价"))
.put("price", contentObj.getString("总价"))
.put("district", contentObj.getString("小区"))
.put("describe", contentObj.getString("房源介绍"));
TextSegment segment = TextSegment.from(contentObj.toJSONString(), metadata);
ids.add(id.toString());
embeddings.add(embedding);
textSegments.add(segment);
}
milvusEmbeddingStore.addAll(ids, embeddings, textSegments);
log.info("向量化数据初始化成功");
} catch (Exception e) {
log.error("向量化数据初始化失败", e);
e.printStackTrace();
}
}
}
@Bean
public MilvusEmbeddingStore embeddingStore() {
return genEmbeddingStore();
}
/**
* 向量化模型-nomic[768维] ollama不提供设置向量维度的方法,维度完全由向量化模型决定
*/
@Bean
public OllamaEmbeddingModel ollamaEmbeddingModel() {
return genEmbeddingModel();
}
public static OllamaEmbeddingModel genEmbeddingModel() {
return OllamaEmbeddingModel.builder()
.baseUrl("http://127.0.0.1:11434")
.modelName("nomic-embed-text:v1.5")
.build();
}
/**
* 向量化存储-milvus
*/
public static MilvusEmbeddingStore genEmbeddingStore() {
return MilvusEmbeddingStore.builder()
.host("127.0.0.1")// attu输入:host.docker.internal:19530来进行连接
.port(19530)
.collectionName("milvus_demo")
.dimension(768) // 此处务必与向量化模型提供的维度一致
.indexType(IndexType.IVF_FLAT)// 索引类型:选择中等规模的数据集
.metricType(MetricType.COSINE)
.consistencyLevel(ConsistencyLevelEnum.STRONG)
.autoFlushOnInsert(true) // 确保实时写入
.metadataFieldName("$meta")// 元数据字段名称,对应动态的schema的key【非常关键】
.idFieldName("id")
.textFieldName("text")
.vectorFieldName("vector")
.build();
}
}
在Attu上新建Collection的时候,要勾选【启用动态Schema】否则代码中的meata插入不进去;
原因:源代码的metadata字段的key默认是:metadata,而attu上新建的默认是$meta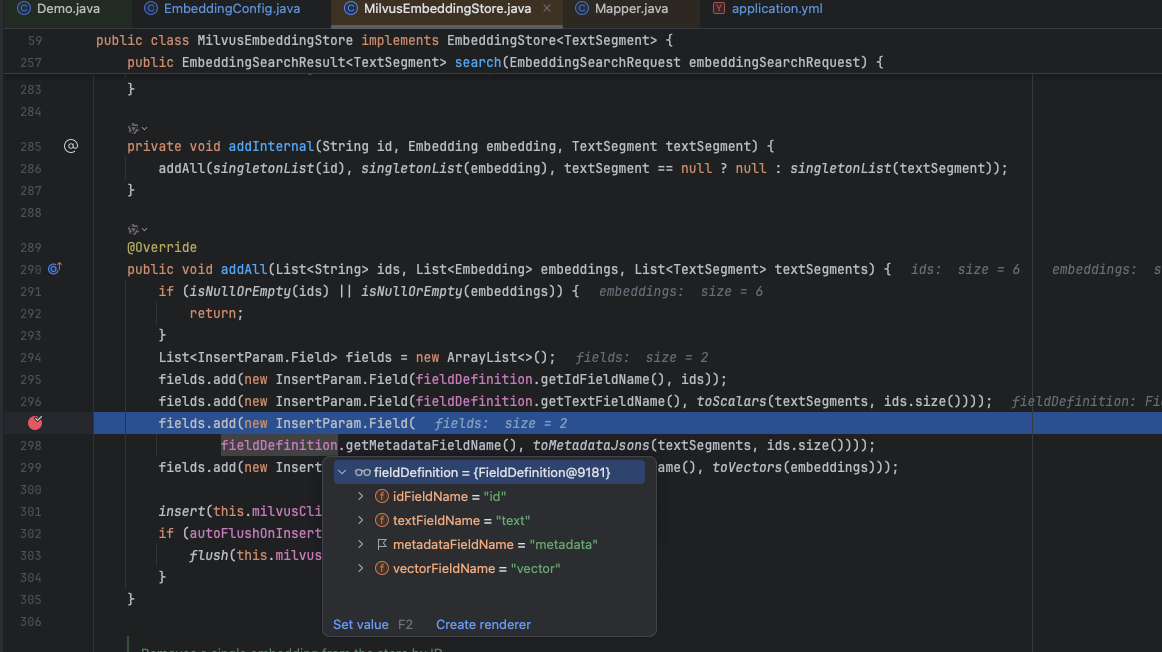
要么创建集合的时候调整动态schema字段的名称,要么咱们代码指定一下,溯源一下addAll()源码就知道在哪儿修改了,蛮有意思;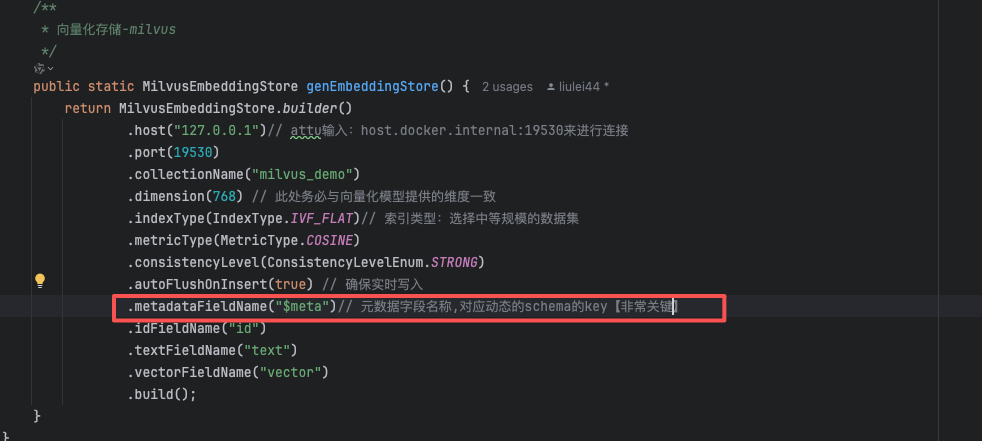
小试牛刀检索一下
小结
Milvus确实很强,如果搭配ES使用的话,可以补全ES在AI语意识别检索上的缺陷,ES8虽然提供了基于KNN的HNSW的向量检索,但是相对于Milvus的全面性支持,粒度差的不是一点半点,从后续的扩展性探索看,Milvus才是最终的选择;
对于RAG库检索的向量库,除了我代码中手动插入的Prompt集合,也可以读取企业知识库,结合DocumentsSpiliter对文档进行切割做向量化,存入向量库后再做增强;

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)