最新版LLaMa-Factory多模态微调实践:微调Qwen2-VL构建文旅大模型
本次教程介绍了如何使用 LLaMA Factory 框架,基于全参方法微调 Qwen2-VL-2B-Instruct 模型,使其能够进行文旅领域知识问答,同时通过人工测试验证了微调的效果。你只需要有一台24GB显存的GPU即可操作。
引言
本博客参考 LLaMA Factory多模态微调实践:微调Qwen2-VL构建文旅大模型 官方文档,并添加了一些内容帮你排除一些只看官方文档会出现的bug。
LLaMA Factory 是一款开源低代码大模型微调框架,集成了业界最广泛使用的微调技术,支持通过 Web UI 界面零代码微调大模型,目前已经成为开源社区内最受欢迎的微调框架之一,GitHub 星标超过 6 万。本教程将基于通义千问团队开源的新一代多模态大模型 Qwen2-VL-2B-Instruct,介绍如何使用 PAI 平台及 LLaMA Factory 训练框架完成文旅领域大模型的构建。
注:
运行环境为服务器4090 ---24GB显存
不使用DSW 官方镜像
step1 创建conda环境
安装各种依赖包时,建议去官网看支持的版本号https://github.com/hiyouga/LLaMA-Factory,不然后面很容易版本不兼容。
(base) root@zhao:~# conda create -n myenv python=3.10 -y
(base) root@zhao:~# conda activate myenv 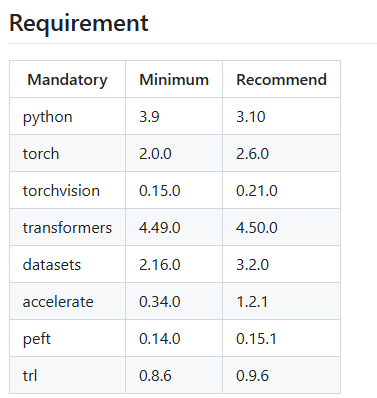
step2 安装 LLaMA Factory
这里我安装的是最新版的LLaMa-Factory,这样可以兼容上面各种依赖包,保证不出错。
一键安装
pip install git+https://github.com/hiyouga/LLaMA-Factory.git也可以选择手动下载。具体如下:
在官网 https://github.com/hiyouga/LLaMA-Factory 手动下载 LLaMA-Factory压缩包,并上传到服务器上,目录为/mnt/zhao/trip-lm。然后解压并进入该目录。
手动下载可以避免很多不必要的麻烦。
(myenv) root@zhao:/mnt/zhao/trip-lm# unzip LLaMA-Factory-main.zip
(myenv) root@zhao:/mnt/zhao/trip-lm# cd LLaMA-Factory
(myenv) root@zhao:/mnt/zhao/trip-lm# pip install -e .step3 下载多轮对话数据集
(myenv) root@zhao:/mnt/zhao/trip-lm/LLaMA-Factory-main# wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/llama_factory/Qwen2-VL-History.zip
(myenv) root@zhao:/mnt/zhao/trip-lm/LLaMA-Factory-main# mv data rawdata && unzip Qwen2-VL-History.zip -d datastep4 模型微调
进入 Web UI界面
直接运行下述命令就可以启动 Web UI 界面,以此零代码微调大模型。
(myenv) root@zhao:/mnt/zhao/trip-lm/LLaMA-Factory-main# USE_MODELSCOPE_HUB=1 llamafactory-cli webui
Running on local URL: http://0.0.0.0:7861如果是本地运行,则点击返回的 URL 地址,进入 Web UI 页面。我用的是服务器,所以需要改成 http://<服务器IP>:7861
浏览器输入上面地址就可以就进来了。
配置参数
按照下面的参数无脑配置即可。
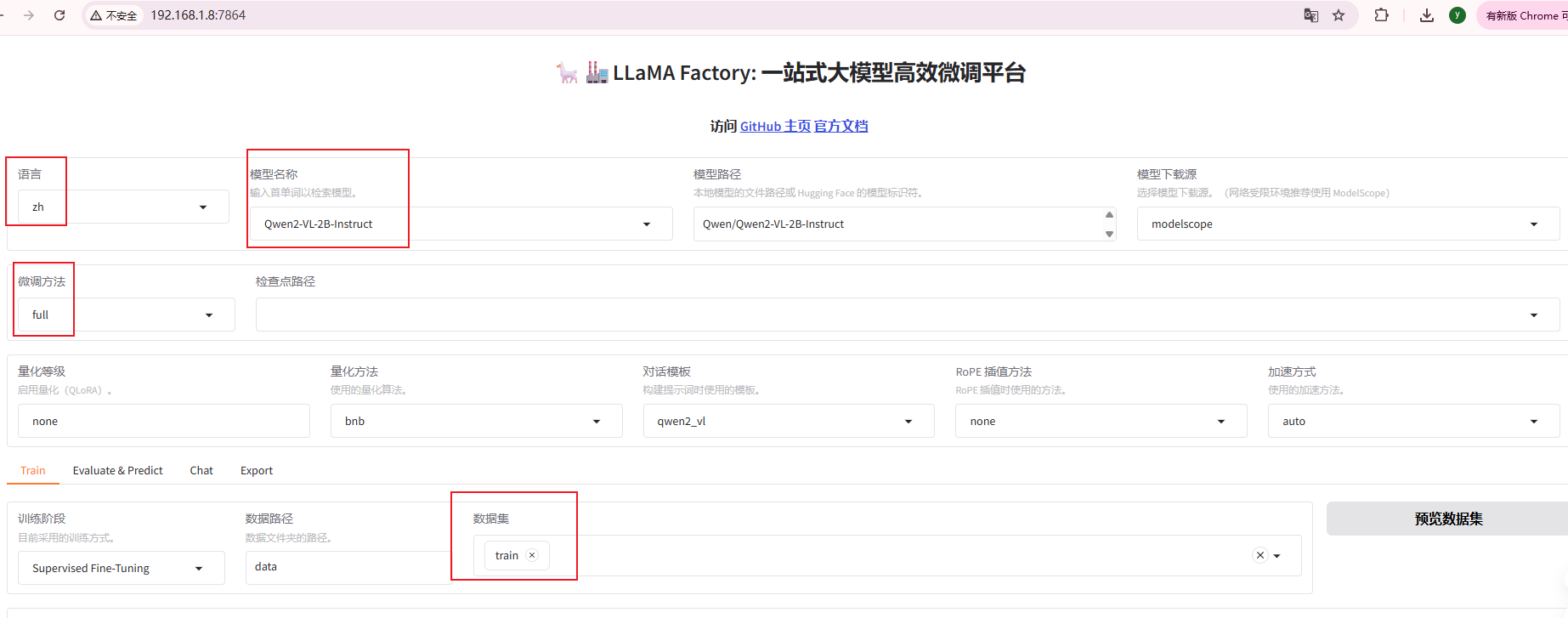
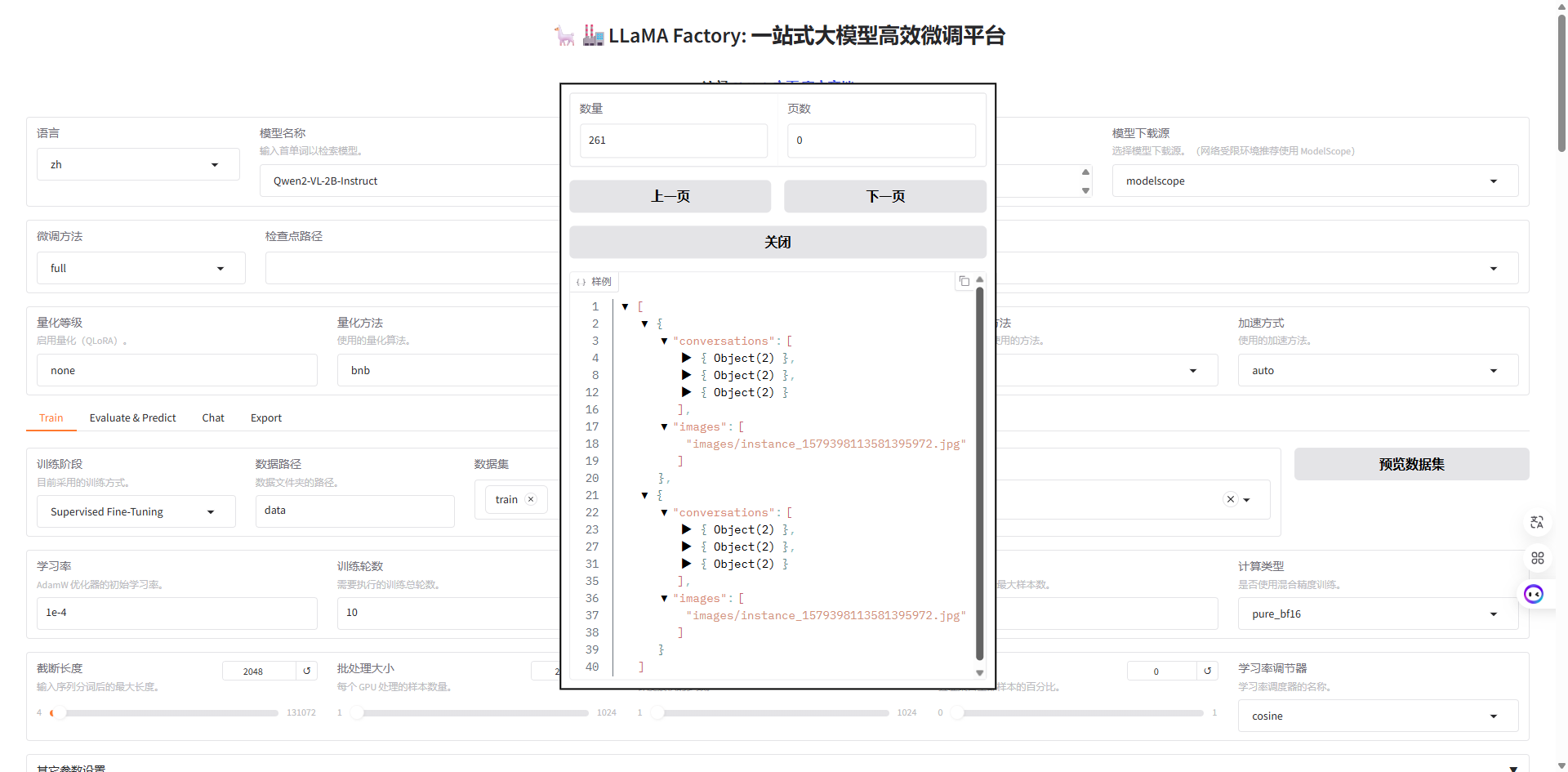
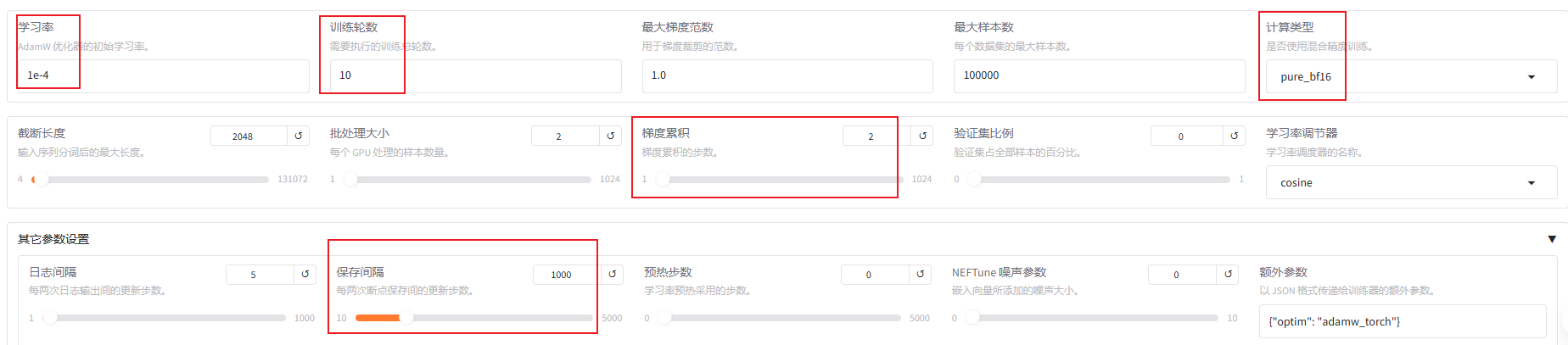
生成微调命令并启动微调
这一步就是使用上一步的配置参数生成最终的微调命令。
首先根据自己的情况修改输出目录和配置路径,也可以不改。
点击预览命令可以看到生成的命令。点击开始就可以启动微调了。这一过程中基本没有写代码。这就是LLaMA Factory大模型微调框架的好处----低代码。
点击启动之后,在服务器端可以看到模型的实时训练情况。
微调成功
第一次微调需要下载模型到服务器上,之后就不用了。
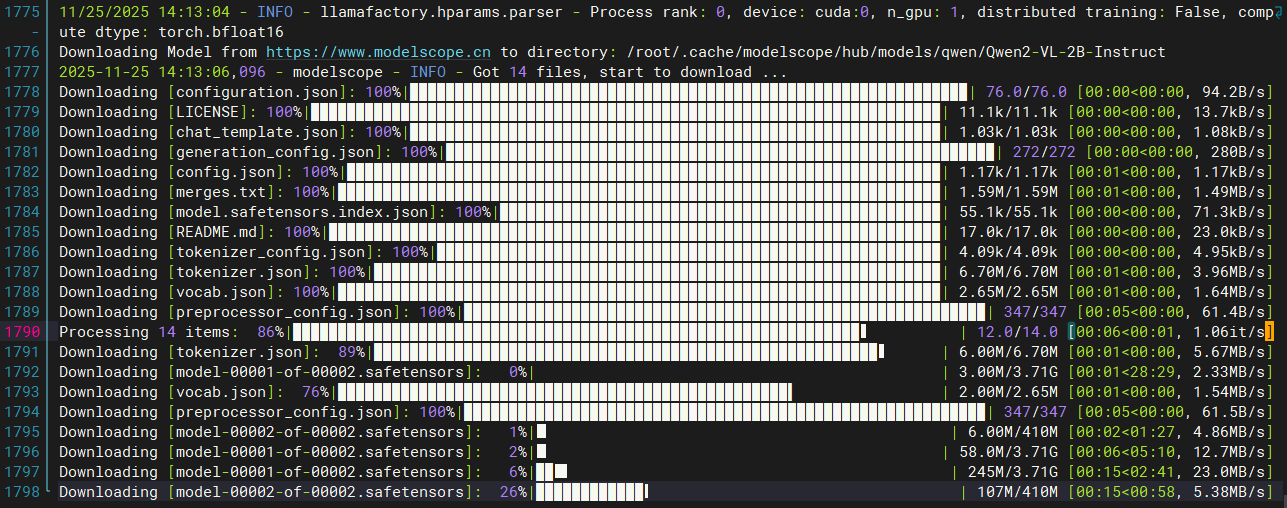
在ui界面中可以看到模型训练时间不到半小时。右边可以看到损失下降曲线。
最下端可以看到GPU现存情况,请一定确保至少24GB显存。

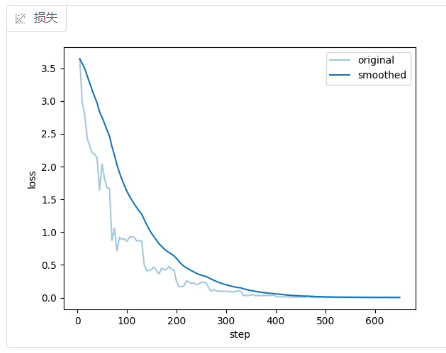
训练完成后损失函数如下
分析
其实第四步和下面代码等效
(base) root@zhao:~# conda activate myenv
(myenv) root@zhao:~# cd /mnt/zhao/trip-lm/LLaMA-Factory-main/
(myenv) root@zhao:/mnt/zhao/trip-lm/LLaMA-Factory-main# llamafactory-cli train \
> --stage sft \
> --do_train True \
> --model_name_or_path Qwen/Qwen2-VL-2B-Instruct \
> --preprocessing_num_workers 16 \
> --finetuning_type full \
> --template qwen2_vl \
> --flash_attn auto \
> --dataset_dir data \
> --dataset train \
> --cutoff_len 2048 \
> --learning_rate 5e-05 \
> --num_train_epochs 3.0 \
> --max_samples 100000 \
> --per_device_train_batch_size 2 \
> --gradient_accumulation_steps 2 \
> --lr_scheduler_type cosine \
> --max_grad_norm 1.0 \
> --logging_steps 5 \
> --save_steps 1000 \
> --warmup_steps 0 \
> --packing False \
> --enable_thinking True \
> --report_to none \
> --output_dir saves/Qwen2-VL-2B-Instruct/full/train_2025-11-25-16-08-12 \
> --bf16 True \
> --plot_loss True \
> --trust_remote_code True \
> --ddp_timeout 180000000 \
> --include_num_input_tokens_seen True \
> --optim adamw_torch \
> --freeze_vision_tower True \
> --freeze_multi_modal_projector True \
> --image_max_pixels 589824 \
> --image_min_pixels 1024 \
> --video_max_pixels 65536 \
> --video_min_pixels 256和模型对话
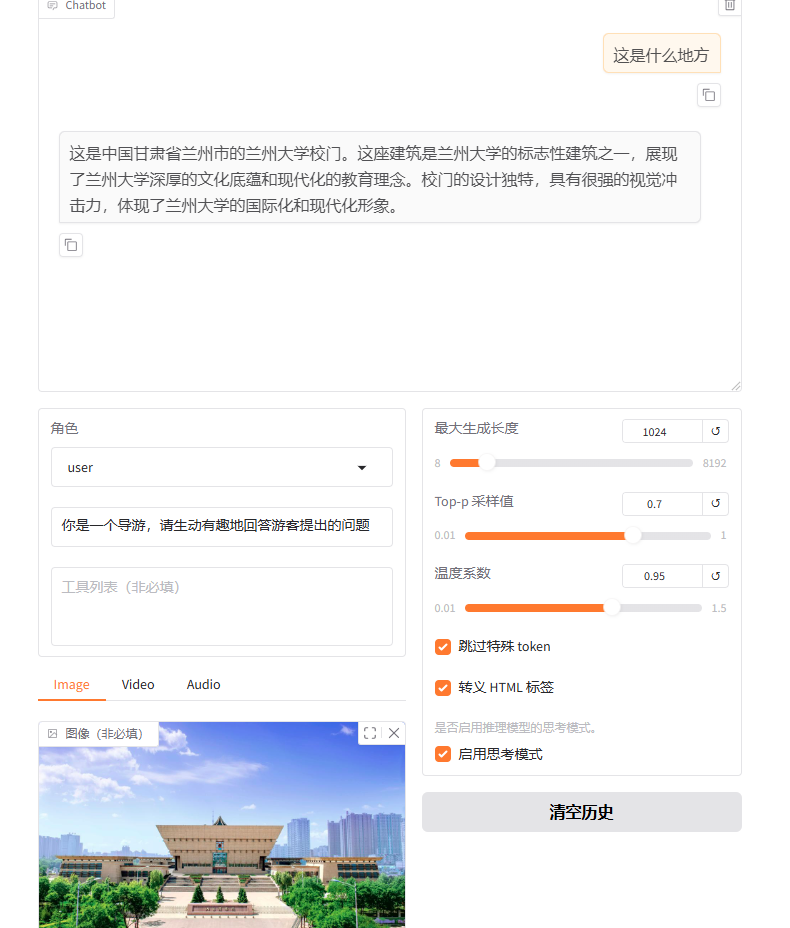
原模型的回答
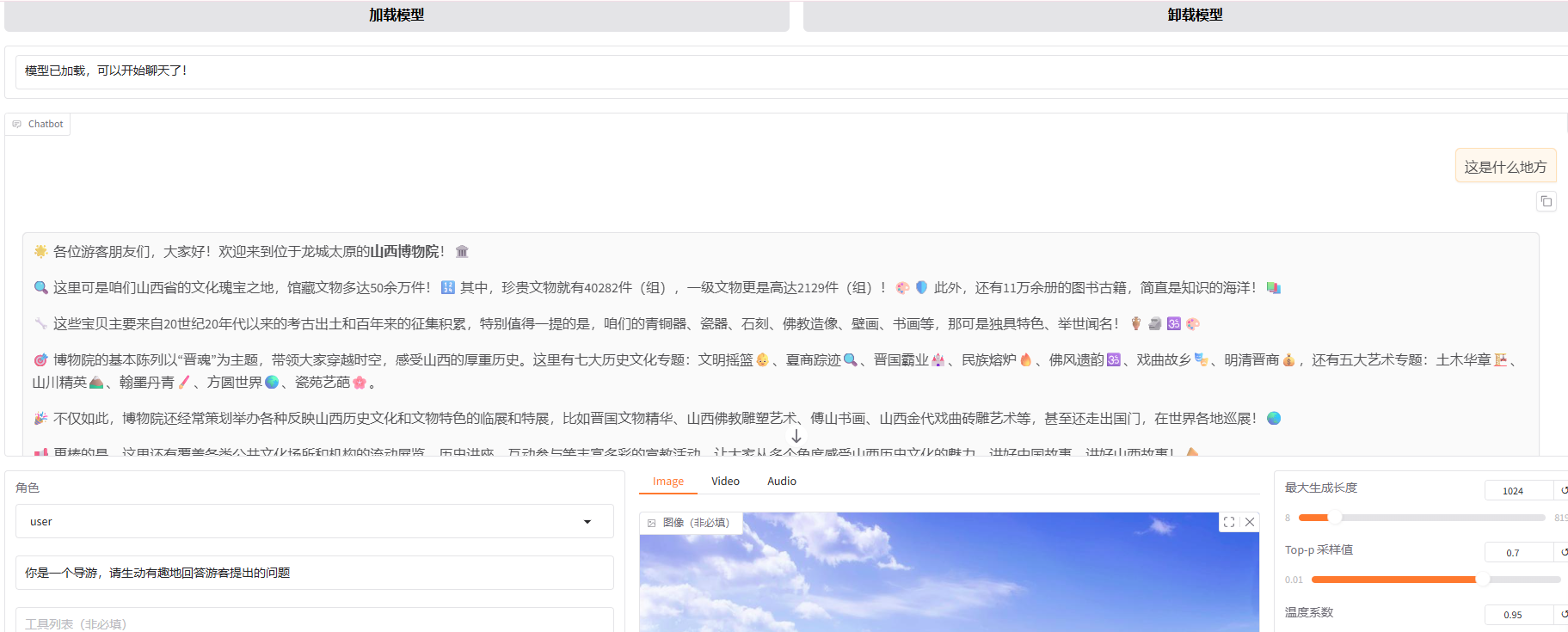
微调后模型的回答

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 3
3 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)