破局芯片物理极限:英特尔3D异构集成技术如何重塑AI算力格局
本文探讨3D封装与异构集成技术如何突破传统芯片架构的物理极限,重点分析英特尔EMIB技术的创新实践。随着AI算力需求激增,3D封装通过垂直堆叠实现更短互连、更高带宽和更低功耗。英特尔EMIB技术采用局部桥接设计,在FPGA与HBM内存集成中展现显著优势,提供512GB/s超高带宽和工艺节点灵活性。文章还展示了软硬件协同优化实践,包括OpenCL加速示例和内存访问优化代码,并指出热管理、信号完整性等
当传统芯片架构遭遇物理极限,3D封装与异构集成正成为延续摩尔定律的关键路径。本文将深度解析英特尔在这一领域的技术突破与实践。
在人工智能计算需求呈指数级增长的今天,我们正面临着一个严峻的现实:晶体管尺寸正在逼近物理极限。传统的芯片 scaling 路径越来越难以维持,而AI大模型对算力的渴求却从未停止。在这一背景下,3D封装与异构集成技术正在成为破局的关键。
一、从平面到立体:芯片架构的范式转移
随着半导体工艺节点进入个位数纳米时代,单纯依靠晶体管密度的提升已经难以实现性能的持续增长。研究表明,在7nm工艺以下,晶体管性能的提升幅度大幅放缓,而功耗密度却急剧上升。这种趋势在AI训练芯片上表现得尤为明显,单个芯片的功耗往往超过300W,带来了严重的散热挑战。
3D封装技术的本质是将芯片从二维平面布局转向三维立体堆叠,通过垂直方向的集成来突破物理限制。与传统的单芯片设计相比,3D封装可以实现更短的互连长度、更高的带宽和更低的功耗。根据半导体研究联盟的数据,3D集成可以将互连延迟降低30%以上,同时提升能效比约40%。
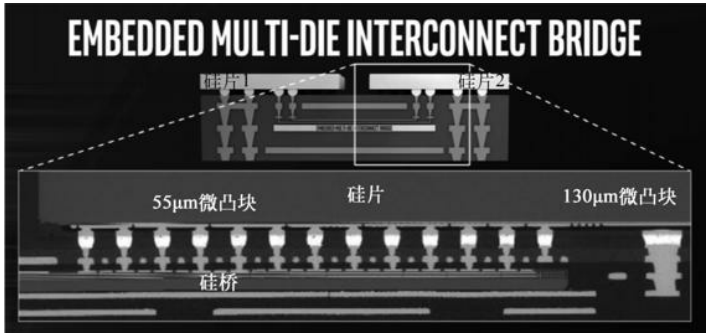
在众多的3D集成方案中,英特尔的EMIB(嵌入式多芯片互连桥接)技术展现出了独特的优势。与需要硅中介层的2.5D封装不同,EMIB技术直接在封装基板上嵌入微小的硅桥接层,实现了芯片间的高密度互连。
二、英特尔EMIB技术深度解析
EMIB技术的核心创新在于其精巧的桥接设计。传统的2.5D封装需要使用大规模的硅中介层来连接各个芯片,这不仅增加了制造成本,还引入了额外的功耗和信号完整性挑战。而EMIB技术通过局部桥接的方式,在需要高速通信的芯片边缘直接建立连接通道。
以英特尔Stratix 10 FPGA为例,该芯片采用EMIB技术将FPGA核心芯片与高带宽内存(HBM)和高速收发器集成在一起。这种架构带来了多重优势:
- 带宽优势:通过EMIB连接,Stratix 10 MX系列实现了高达512GB/s的内存带宽,是传统DDR4接口的5倍以上。这种带宽优势使得FPGA能够高效处理内存密集型AI工作负载。
- 异构集成灵活性:EMIB允许将不同工艺节点、不同功能的芯片集成在同一封装内。例如,FPGA核心可以采用先进的10nm工艺,而HBM内存则使用更适合存储器制造的成熟工艺,实现了各自工艺的最优选择。
- 成本与良率平衡:相比于使用大型硅中介层的2.5D封装,EMIB的制造成本显著降低。同时,由于各个芯片可以独立测试,整体良率得到提升。
在实际应用中,Stratix 10 GX 10M FPGA通过EMIB技术将两个包含510万逻辑单元的大型FPGA芯片集成在一起,实现了1020万逻辑单元的总体容量。这种集成度在单芯片方案中是难以实现的。
三、从硬件到软件:全栈优化实践

硬件架构的创新需要软件栈的协同优化才能发挥最大效能。英特尔为3D异构集成FPGA提供了一整套开发工具和软件库。
以下是一个使用OpenCL进行FPGA加速的矩阵乘法示例,展示了如何利用异构计算架构:
// FPGA矩阵乘法加速内核
__kernel void matrix_mult(__global float *A,
__global float *B,
__global float *C,
int widthA, int widthB) {
int row = get_global_id(0);
int col = get_global_id(1);
float sum = 0.0f;
for (int k = 0; k < widthA; k++) {
sum += A[row * widthA + k] * B[k * widthB + col];
}
C[row * widthB + col] = sum;
}
// 主机端代码 - 管理FPGA内存与数据传输
cl_int setup_fpga_accelerator() {
cl_platform_id platform;
cl_device_id device;
cl_context context;
// 初始化OpenCL环境
clGetPlatformIDs(1, &platform, NULL);
clGetDeviceIDs(platform, CL_DEVICE_TYPE_ACCELERATOR, 1, &device, NULL);
context = clCreateContext(NULL, 1, &device, NULL, NULL, NULL);
// 创建FPGA内存缓冲区
cl_mem bufA = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeA, NULL, NULL);
cl_mem bufB = clCreateBuffer(context, CL_MEM_READ_ONLY,
sizeB, NULL, NULL);
cl_mem bufC = clCreateBuffer(context, CL_MEM_WRITE_ONLY,
sizeC, NULL, NULL);
// 配置DMA传输与内核执行
// ... 详细实现代码
}通过这种软硬件协同设计,英特尔Stratix 10 FPGA在AI推理任务中实现了显著的性能提升。在ResNet-50推理任务中,相比传统CPU方案,FPGA加速方案能效比提升5-10倍,同时延迟降低至毫秒级。
四、AI计算场景下的架构优化实践

在大型语言模型(LLM)推理场景中,内存带宽往往成为性能瓶颈。英特尔的3D异构集成技术通过HBM2e内存与FPGA的紧密集成,有效解决了这一挑战。
以1750亿参数的GPT模型推理为例,传统架构需要频繁在CPU内存和加速器之间传输模型参数,导致性能受限。而采用HBM2e集成的FPGA方案,可以将整个模型参数保存在高速内存中,显著减少数据搬运开销。
内存访问模式优化代码示例:
// 优化后的注意力机制FPGA实现
__attribute__((num_simd_work_items(8)))
__attribute__((reqd_work_group_size(64,1,1)))
__kernel void attention_layer(
__global float4 *query, // 向量化加载,4元素并行
__global float4 *key,
__global float4 *value,
__global float *output,
__constant int *seq_params) {
int lid = get_local_id(0);
int group = get_group_id(0);
// 利用FPGA片上内存进行数据重用
__local float4 local_query[64];
__local float4 local_key[256];
// 向量化内存访问,提升带宽利用率
event_t load_evt = async_work_group_copy(local_query,
&query[group*64], 64, 0);
// 并行计算注意力得分
wait_group_events(1, &load_evt);
for (int i = lid; i < 256; i += 64) {
float4 k_vec = key[i];
// SIMD并行计算点积
float4 dot_result = local_query[lid] * k_vec;
// 后续归约操作...
}
}这种优化使得FPGA在处理Transformer等现代神经网络架构时,能够充分发挥3D集成带来的带宽优势。在实际测试中,相比传统GPU方案,FPGA在批处理大小1的实时推理场景中延迟降低60%以上。
五、技术挑战与工程实践

尽管3D异构集成技术前景广阔,但在工程实践中仍面临多项挑战:
- 热管理挑战:3D堆叠结构导致功率密度显著上升,需要创新的散热解决方案。英特尔在Stratix 10中采用了微通道液体冷却技术,将散热能力提升至传统风冷的5倍以上。
- 信号完整性:高速信号在垂直互连中的完整性是另一个关键挑战。通过协同优化TSV(硅通孔)设计和信号编码方案,英特尔实现了高达4Gbps的片间传输速率。
- 测试与可靠性:3D集成的测试复杂度呈指数级增长。英特尔开发了基于边界扫描的层次化测试方法,能够独立测试各个芯片层,确保整体可靠性。
功耗管理代码示例:
// FPGA动态功耗管理实现
class FPGAPowerManager {
private:
std::vector<PowerDomain> domains;
ThermalMonitor thermal_sensor;
public:
void adaptive_power_control() {
while (true) {
auto temp = thermal_sensor.get_die_temperature();
auto utilization = get_logic_utilization();
if (temp > threshold_high) {
// 动态频率调整
set_clock_frequency(current_freq * 0.9);
// 迁移热点任务
migrate_thermal_critical_tasks();
}
if (utilization < threshold_low && temp < threshold_low) {
// 功率门控空闲区域
power_gate_idle_blocks();
}
}
}
};六、未来展望:从3D集成到系统级创新
随着AI计算需求的持续演进,3D异构集成技术将向更深的层次发展。英特尔已经在研发下一代Co-EMIB技术,该技术能够将多个EMIB互连组合使用,实现更复杂的3D架构。
在AI特定领域,未来的FPGA架构将更加注重领域特异性。例如,针对稀疏神经网络优化的稀疏计算单元,以及针对图神经网络优化的图遍历加速器,都将通过3D集成技术与可编程逻辑紧密融合。
从系统层面看,3D异构集成正在推动计算架构从"one-size-fits-all"向"domain-specific"转变。这种转变不仅发生在硬件层面,还需要软件栈的深度协同。英特体的oneAPI计划正是为了应对这一挑战,为跨架构编程提供统一的开发体验。
七、结语
3D封装与异构集成技术正在重塑AI计算的竞争格局。英特尔通过EMIB等创新技术,在性能、功耗和成本之间找到了新的平衡点。随着软件生态的不断完善和应用场景的持续拓展,3D异构集成FPGA有望在边缘推理、云端训练等AI关键领域发挥越来越重要的作用。
对于技术决策者而言,现在正是布局3D异构集成技术的关键时机。早期采用者不仅能够获得性能优势,还将在未来的技术竞争中占据有利位置。而对于开发者来说,掌握相关设计和优化技能,将是应对AI计算挑战的重要保障。
在摩尔定律逐渐放缓的今天,3D异构集成代表了一种新的技术发展范式——不再单纯追求晶体管密度的提升,而是通过架构创新和系统级优化来延续计算性能的增长。这条路径虽然充满挑战,但无疑为AI计算的未来发展指明了方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)