AI 数据分析如何保障准确性?构建可信数据基础成为关键
真正实现“自助式、敏捷化、可解释”的 AI 数据分析决策
前言:
在数字化转型浪潮中,企业数据分析决策的时效性与准确性已成为竞争胜负的关键。随着“Data + AI”融合加深,ChatBI 产品爆发式增长。但在当前市场中,大多数 ChatBI 产品依赖大模型直接生成 SQL 的技术路径(NL2SQL),普遍面临“大模型幻觉”导致的数据不可信问题——模型可能生成与事实不符、计算逻辑矛盾、口径不一致甚至完全虚构的数据结果,直接影响分析决策质量。
痛点直击:“大模型幻觉”导致数据不可信
众所周知,“大模型幻觉”是生成式 AI 的固有缺陷,在企业数据分析决策场景中如果缺乏可信的数据基础,则会引发数据准确性不可靠、决策方向误导、协作效率下降等问题。
比如,当用户查询“近七天的订单数”时,大模型生成的 SQL 可能直接对订单金额进行聚合计算,看似正确,但可能不符合企业对订单数的标准定义(如剔除刷单或测试订单)。再比如,某生产制造企业依赖 AI 生成的财报分析,因模型虚构收入指标,导致其错误扩大生产规模,最终形成库存积压,或者某对冲基金因 AI 算法错误判断市场趋势,造成单日超千万的损失等。
究其根本,在于 NL2SQL 方案的局限性。目前市面上主流的 NL2SQL 方案是直接将自然语言映射为 SQL,依赖表结构与字段名的精确匹配。当表结构变更或业务语义复杂时(如“OEE 指标需跨多表计算”),模型极易生成错误 SQL,且难以追溯问题根源。
技术路径对比:NL2SQL vs NL2MQL2SQL 的本质差异
1、NL2SQL:基于物理表的“概率生成”
大模型直接解析用户问题,尝试从物理表结构中生成 SQL。但物理表本身不具备业务语义,导致很多信息是无法让大模型很好地理解的。例如,用户通过 ChatBI 提问“帮我分析华北区销售额”,模型需要先识别表名 sales_region、字段名 region 和 amount,并拼接为 SELECT amount FROM sales_region WHERE region='华北'。这一过程中,大模型能否精准锁定正确的物理表,并给出准确的数据就成了一个“概率性事件”。
与此同时,物理表结构一旦变更,便会导致 SQL 失效,需要重新训练模型。同一指标在不同场景下,也可能存在着不同的计算逻辑(如“销售额”是否含税),NL2SQL 技术路径则难以统一管理,无法保障数据和业务语义对齐。此外,业务规则变化时,用户还需要手动调整所有相关 SQL 语句,直接带来更高的维护成本。
2、NL2MQL2SQL:基于指标语义层的“确定性构建”
这一技术路径则为 Aloudata Agent 分析决策智能体独创且跑通。首先,大模型精准解析用户意图,识别原子化数据要素,如指标、维度、筛选条件、时间范围;随后,再通过 NoETL 指标语义层将要素拼接为 MQL(Metrics Query Language),明确指标计算逻辑与业务口径;最后,通过语义引擎将 MQL 转化为 100% 准确的 SQL,并支持跨表动态查询。
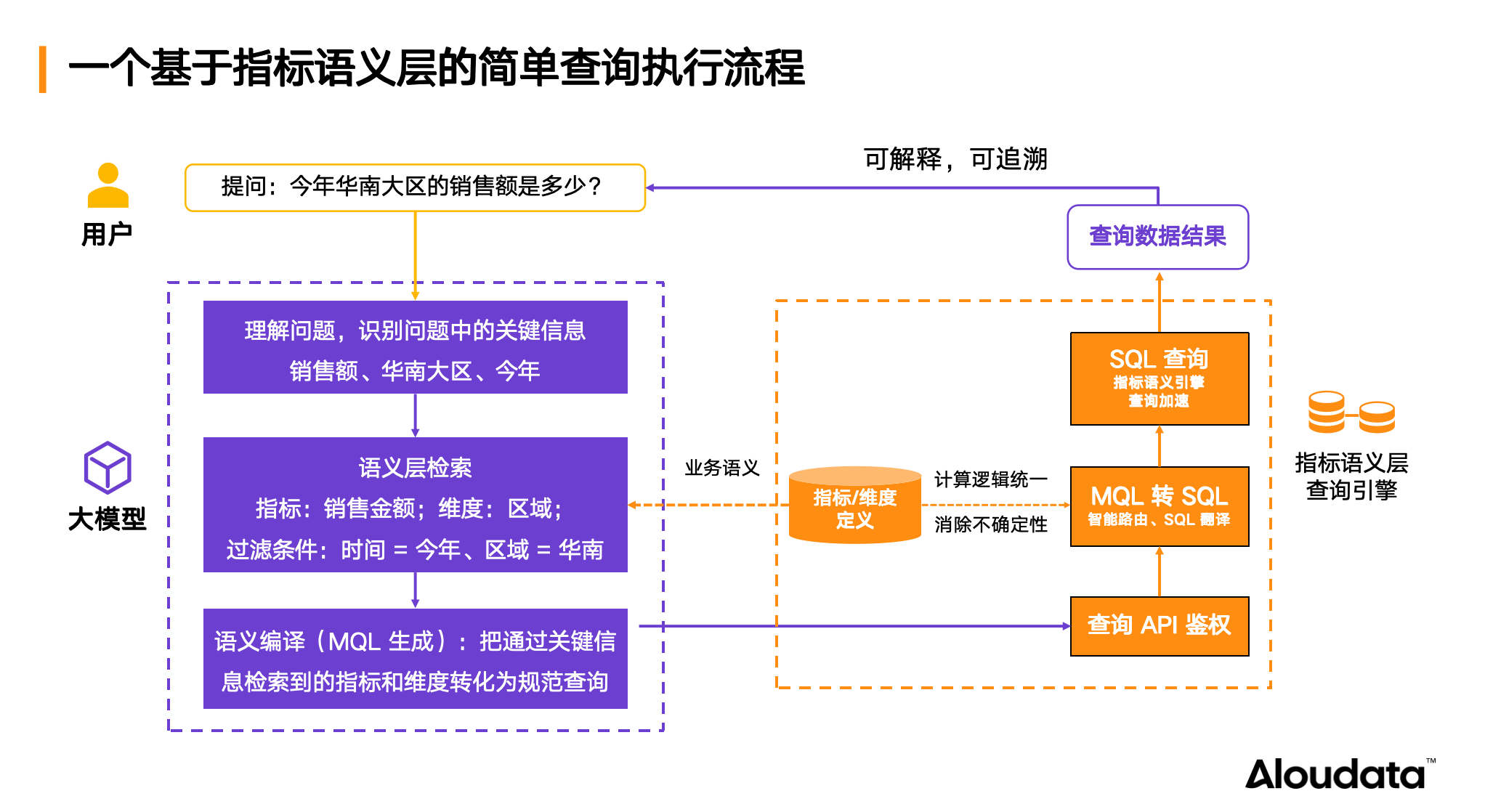
相较于 NL2SQL 技术路径,NL2MQL2SQL 则实现了业务语义与物理表结构分离,表结构变更不影响查询逻辑;同时指标计算逻辑在 NoETL 指标语义层明确定义,实现口径的一致性,避免了“同名不同义”“同义不同名”的问题。此外,该路径还支持多维度、多层次归因分析,让用户无需预定义复杂报表。
核心突破:NoETL 指标语义层如何确保 SQL 生成 100% 准确?
Aloudata Agent 分析决策智能体所依赖的 NoETL 指标语义层是保障 SQL 生成 100% 准确性的“数据引擎”,其设计包含三大核心机制:
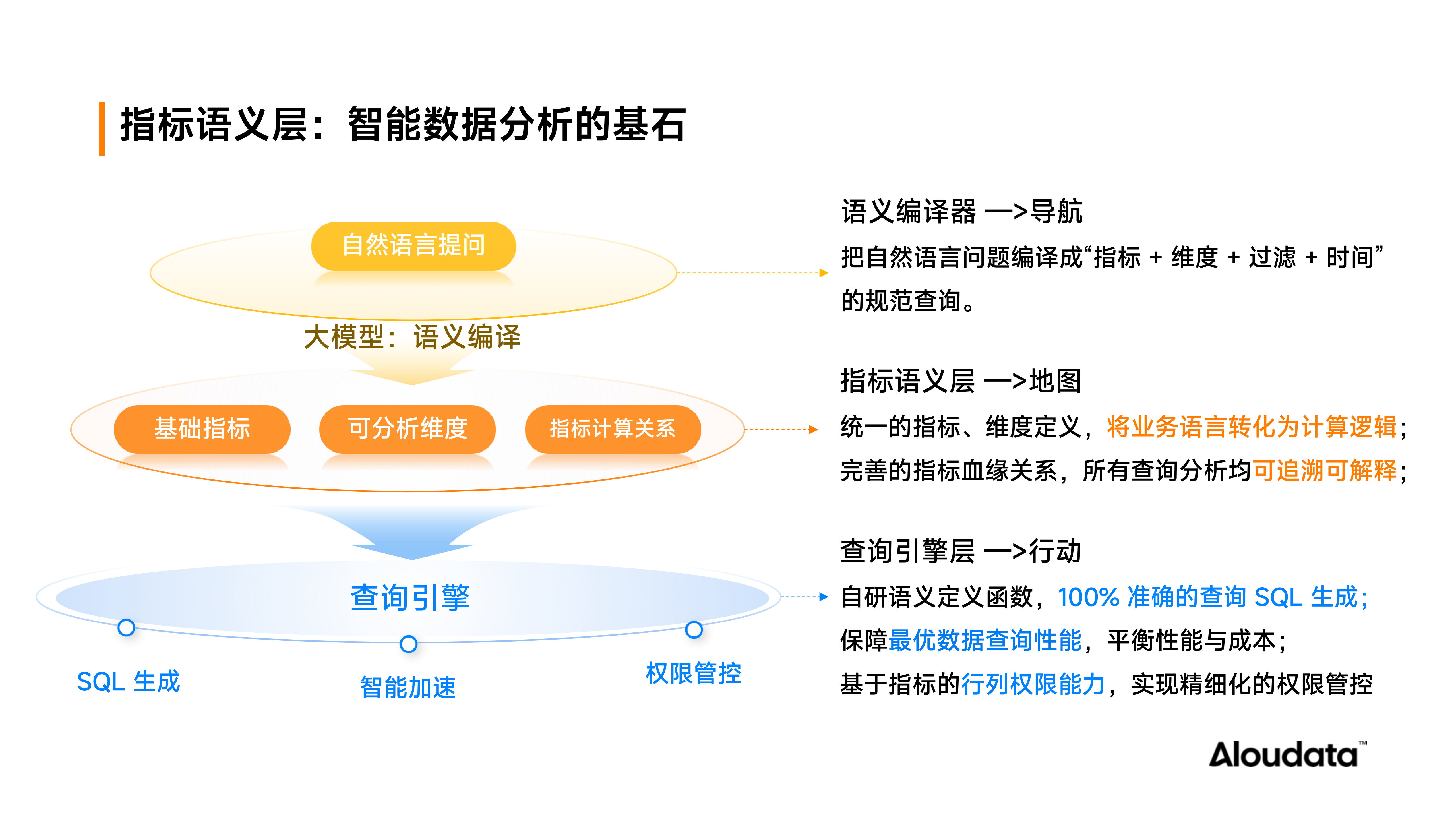
1、统一的指标语义定义:将混乱的数据转化成唯一标准的指标
基于强大的逻辑模型和语义函数,将混乱的数据转化成标准的指标定义,实现业务语言与 SQL 的映射。
强大的语义数据模型:NoETL 指标语义层支持一对一、一对多以及复杂的多角色关联场景。例如,在电商场景中,一个用户可以同时是买家和卖家两种身份,意味着订单事实表中的买家 ID 和卖家 ID 要同时和客户维表中的用户 ID 进行关联。
丰富的指标语义函数:NoETL 指标语义层提供 100+ 指标语义函数(日期类、文本类、聚合函数、窗口函数、逻辑函数、运算符、分析函数等),并封装成配置化模板,任意指标皆可零代码方式实现逻辑化定义和标准化管理。
2、动态 SQL 组装:基于指标要素动态组装出正确的 SQL
用户提问时,问题会映射到 NoETL 指标语义层中最原子化的要素,即询问的指标和维度。随后,NoETL 指标语义层将这些原子化要素 100% 准确的翻译成 SQL,这涉及 NoETL 指标语义层中查询元素的结构与 SQL Query 结构对齐。例如,SQL 中的 WHERE 对应指标元数据的业务限定,GROUP BY 对应分析维度等。
3、结果的可解释性:一键查看结果背后的业务含义与计算逻辑
对于查询结果,确保业务人员可以判断与验证数据准确性至关重要,即结果的可解释性。传统 NL2SQL 模式下,业务人员看不懂 SQL,无法判断结果是否可信。NL2MQL2SQL 模式下采取两个措施:一是透明化查询过程,向用户展示大模型的思考过程和计算方式,且以业务人员能理解的查询指标和维度呈现;二是展示指标的详细业务口径、计算逻辑和血缘,使用户能以业务语言判断数据准确性,确保每次查询结果可解释、可验证。若数据与设想不符,用户还可进行干预和调整。
综上,Aloudata Agent 之所以能够确保数据分析决策场景 SQL 生成 100% 准确,关键在于 NoETL 指标语义层的引入,将智能问数从“概率游戏”拉回到“工程科学”。它不否定大模型的价值,而是为其划定边界——让大模型做它最擅长的事(理解语言、归纳总结),而将准确性、一致性、安全性交给确定性的软件工程体系,让业务人员真正实现“自助式、敏捷化、可解释”的数据分析决策。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 6
6 0
0- 0



 已为社区贡献30条内容
已为社区贡献30条内容

所有评论(0)