昇腾AI核心基石:深度解析AscendCL架构与核心概念
摘要:本文系统介绍了AscendCL(昇腾计算语言)的架构设计和核心概念。AscendCL采用四层架构设计:应用层、API层、运行时层和驱动层,实现从上层业务到底层硬件的完整支持。重点解析了设备与上下文、流与同步、内存管理、模型与张量等关键概念,并展示了典型的AI推理任务流程。这种分层设计使开发者能专注于业务逻辑,同时充分发挥昇腾AI处理器的计算性能,为后续AscendCL编程实践奠定理论基础。
摘要: 在编写代码之前,理解AscendCL的架构和核心概念至关重要。本文将化身你的“昇腾AI导览图”,深入讲解AscendCL的层次结构、运行流程和关键组件,让你彻底明白一个AI应用是如何在昇腾芯片上跑起来的。
- AscendCL的整体架构
AscendCL(Ascend Computing Language)采用模块化、分层的设计架构,这种设计理念使得上层应用开发更加简洁,同时能够高效管理底层复杂的硬件资源。整个架构从下到上可分为四个核心层次:
1.1 应用层(Application Layer)
应用层是AscendCL(Ascend Computing Language)开发框架的最上层,开发者可以基于该层构建各类AI应用程序。这些应用程序通过调用AscendCL提供的API接口,实现对昇腾AI处理器的计算能力调用。
典型应用场景包括但不限于:
-
计算机视觉:
- 目标检测:如智能安防中的人脸识别、自动驾驶中的障碍物检测
- 图像分类:如医疗影像分析、工业质检中的缺陷识别
- 实例:基于YOLOv3的实时交通监控系统
-
自然语言处理:
- 文本分类:如垃圾邮件过滤、新闻分类
- 机器翻译:如多语言实时翻译系统
- 实例:使用BERT模型的智能客服系统
-
推荐系统:
- 商品推荐:如电商平台的个性化商品推送
- 内容推荐:如新闻资讯App的个性化内容分发
- 实例:基于深度协同过滤的影视推荐系统
具体示例: 一个基于ResNet50的图像分类应用开发流程包括:
- 模型准备:获取或训练ResNet50模型
- 模型转换:使用ATC工具将模型转换为昇腾支持的格式
- 应用开发:调用AscendCL接口实现图像预处理、模型推理、结果后处理
- 部署运行:在Atlas硬件平台上部署执行
该应用可应用于多个领域,如:
- 医疗领域:X光片疾病识别
- 工业领域:产品缺陷检测
- 农业领域:农作物病虫害识别
1.2 AscendCL API层
AscendCL(Ascend Computing Language)API层是华为昇腾AI处理器面向开发者的核心编程接口层,提供了200+个功能丰富的API接口,覆盖了AI应用开发的各个环节。这些API按照功能模块划分如下:
- 模型管理模块
- 提供模型加载/卸载相关API,支持多种模型格式(如.om、.onnx等)
- 示例:支持加载经过ATC工具转换后的离线模型
- 支持多模型并行管理,可同时加载多个模型进行推理
- 张量操作模块
- 提供完整的张量创建/销毁API
- 支持多种数据类型(float16/float32/int8等)的张量操作
- 包含张量形状调整、数据拷贝等实用功能
- 计算图管理模块
- 提供计算图构建和执行API
- 支持动态图/静态图两种模式
- 包含算子融合、图优化等高级功能
- 内存管理模块
- 提供设备内存分配/释放API
- 支持内存池管理,提高内存使用效率
- 包含主机-设备内存拷贝等数据传输功能
编程语言支持:
- 提供C/C++原生接口(头文件:acl/acl.h)
- 提供Python绑定接口(ascendcl包)
- 两种接口功能完全一致,开发者可根据项目需求选择
应用场景:
- 适用于图像分类、目标检测等AI推理任务
- 可用于模型训练加速
- 支持云端和边缘计算场景
1.3 运行时层(Runtime Layer)
运行时层是连接上层编程接口与底层硬件驱动的重要中间层,主要负责资源管理和任务调度。它通过抽象硬件细节,为上层应用提供统一的运行时环境。
核心功能组件:
-
上下文管理(Context Management)
- 负责管理设备上下文环境,包括:
- 设备初始化与状态维护
- 上下文创建、销毁和切换
- 错误处理与恢复机制
- 示例:在GPU计算中,上下文保存了当前设备状态、内存分配等信息
- 负责管理设备上下文环境,包括:
-
流管理(Stream Management)
- 创建和管理计算流(Compute Stream):
- 每个流代表一个独立的任务队列
- 支持流间同步与依赖管理
- 典型应用场景:
- 多流并行:同时执行多个独立计算任务
- 流水线执行:重叠计算与数据传输
- 创建和管理计算流(Compute Stream):
-
内存管理(Memory Management)
- 协调主机(CPU)和设备(如GPU)内存:
- 内存分配与释放
- 主机-设备数据传输
- 统一内存管理(Unified Memory)
- 优化技术:
- 内存池(Memory Pool)减少分配开销
- 异步数据传输隐藏延迟
- 协调主机(CPU)和设备(如GPU)内存:
-
任务调度(Task Scheduling)
- 优化计算任务执行顺序:
- 静态调度:编译时确定执行顺序
- 动态调度:运行时根据资源状况调整
- 提供异步执行机制:
- 非阻塞API调用
- 回调(Callback)机制
- 事件(Event)同步机制
- 优化计算任务执行顺序:
运行时层还提供以下高级特性:
- 多设备管理:协调多个计算设备
- 错误检测与恢复:捕获并处理运行时错误
- 性能分析:提供运行时性能指标
典型工作流程示例:
- 创建上下文和计算流
- 分配设备内存
- 提交异步计算任务
- 通过事件或回调监控任务完成
- 释放资源
1.4 驱动层(Driver Layer)
2. 计算任务调度
3. 异常处理机制
4. 性能优化
5. 多设备管理
应用场景
-
昇腾AI处理器交互功能详解
1. 硬件资源管理
- 资源分配:支持对Ascend 910/310处理器的计算核心、内存等资源进行动态分配,可按任务需求灵活配置
- 资源释放:提供自动/手动释放机制,确保计算资源高效利用
- 示例:在模型推理完成后自动释放占用的HBM内存
- 任务下发:支持多种计算任务提交方式:
- 单次任务提交
- 批量任务队列
- 流式任务处理
- 执行控制:提供任务优先级设置、执行状态查询和中断控制功能
- 错误检测:实时监控硬件状态,检测包括:
- 温度异常
- 内存溢出
- 计算单元故障
- 恢复策略:提供多级处理方案:
- 自动重试
- 任务迁移
- 硬件隔离
- 实时监控:采集关键指标:
- 计算单元利用率
- 内存带宽
- 功耗数据
- 调优建议:基于性能数据提供优化方案:
- 算子融合建议
- 内存访问优化
- 任务并行度调整
- 负载均衡:支持动态调度算法:
- 轮询调度
- 基于负载的智能调度
- 优先级调度
- 拓扑感知:优化设备间通信,支持:
- PCIe/NVLink拓扑识别
- 跨设备通信优化
- 数据局部性保障
- 分布式训练:在多块Ascend 910间自动分配计算任务
- 边缘推理:在Ascend 310集群上实现负载均衡的推理服务
- 异构计算:与CPU/GPU协同工作,统一资源管理
这种分层架构设计使得各层职责明确,上层开发者只需关注业务逻辑实现,无需深入了解底层硬件细节,大大降低了开发难度。同时,通过运行时层的优化调度,能够充分发挥昇腾AI处理器的计算性能。
2. 核心概念详解
AscendCL 核心概念详解
2.1 设备与上下文
Device(设备) 定义:Device指的是物理的昇腾AI处理器硬件单元,主要包括Ascend 910(训练用高性能AI处理器)和Ascend 310(推理用高效能AI处理器)等型号。
特点:
- 物理连接特性
- 一个主机系统(如x86服务器)可以通过PCIe总线连接多个昇腾AI处理器设备
- 典型配置:单台服务器可搭载4-8块Ascend 910加速卡
- 资源独立性
- 每个Device都有独立的计算核心(如Ascend 910内置32个达芬奇AI Core)
- 拥有专用的HBM(高带宽内存),如Ascend 910配备32GB HBM2内存
- 标识方式
- 系统为每个Device分配唯一的Device ID(非负整数)
- 编号规则:从0开始依次递增(0,1,2...)
- 示例:在4卡服务器中,Device ID分别为0,1,2,3
Context(上下文) 定义:Context是AscendCL(昇腾计算语言)中抽象的执行环境容器,为AI计算任务提供运行时的资源管理环境。
功能特性:
- 计算操作管理
- 模型推理任务(如图像分类、目标检测)
- 张量运算(矩阵乘法、卷积等)
- 需要在Context中指定具体的计算流(Stream)
- 资源管理
- 设备内存申请(如通过aclrtMalloc接口)
- 内存释放与回收
- 支持内存池优化机制
- 数据传输
- Host(CPU)与Device(Ascend)间的数据搬运
- 支持同步/异步传输模式
- 典型场景:输入数据从Host内存拷贝到Device内存
重要关系:
- 设备关联性
- 一个Device可创建多个Context(如为不同任务创建独立Context)
- 典型应用:多线程场景下,每个线程使用独立的Context
- 但一个Context严格绑定到单个Device,不可跨设备共享
- 执行流程
- 完整关系链:Device → Context → Stream → 具体算子
- 示例流程:
- 获取Device 0
- 创建Context关联Device 0
- 在Context中创建Stream
- 在指定Stream上执行矩阵乘算子
注意事项:
- 默认Context:系统会自动为每个Device创建默认Context
- 显式管理:推荐显式创建Context以获得更好的资源控制
- 线程安全:不同Context之间操作相互隔离,支持并发执行
2.2 流与同步机制
Stream(流)
本质与架构
流(Stream)本质上是一个任务队列和调度单元,由运行时系统(Runtime)进行管理和调度。每个流维护一个独立的任务队列,系统按照特定策略从这些队列中取出任务分配给计算单元执行。
执行特性详解
-
顺序执行特性:
- 同一Stream中的任务严格遵循先进先出(FIFO)原则执行
- 例如:Stream A中有任务A1、A2、A3,执行顺序必然是A1→A2→A3
-
并行执行能力:
- 可以创建多个Stream实现任务级并行
- 典型配置:主计算流(Stream 0) + 辅助流(Stream 1,2,...)
- 不同Stream间的任务可能并发执行,实际并发度取决于:
- 硬件资源(如GPU的SM数量)
- 任务间的资源竞争情况
-
内存访问特性:
- 同一Stream内任务共享内存上下文
- 不同Stream间内存访问需要显式同步
典型应用场景
-
多模型并行推理:
- 示例:同时运行目标检测模型(Stream 0)和分类模型(Stream 1)
- 通过流并行可提高整体吞吐量
-
计算与数据传输重叠:
- 典型模式:
- Stream 0:执行计算任务
- Stream 1:处理主机到设备的数据传输
- 可实现计算与通信的流水线并行
- 典型模式:
-
多任务流水线:
- 将复杂任务拆分为多个阶段分配到不同流
- 例如:预处理(Stream 0)→推理(Stream 1)→后处理(Stream 2)
同步操作
关键同步函数
aclError aclrtSynchronizeStream(aclrtStream stream);
功能详解
-
阻塞行为:
- 调用线程会被阻塞,直到:
- 指定Stream中所有已提交任务完成执行
- 包括内核计算、内存操作等所有任务类型
- 调用线程会被阻塞,直到:
-
同步必要性:
- 确保结果可用性:在访问计算结果前必须同步
- 避免竞争条件:当多个流访问共享资源时
- 性能测量准确性:正确的时间统计需要同步
-
使用模式示例:
// 提交任务到流 aclrtLaunchKernel(stream, kernel, args...); // 等待任务完成 aclrtSynchronizeStream(stream); // 安全访问结果 aclrtMemcpy(host_ptr, device_ptr, size, ACL_MEMCPY_DEVICE_TO_HOST); -
性能考量:
- 过度同步会降低并行度
- 建议策略:
- 仅在必要时同步
- 使用事件(event)进行精细粒度同步
- 批量操作后统一同步
其他同步机制
-
事件(Event)同步:
- 更细粒度的同步方式
- 可以标记特定任务点而非整个流
-
隐式同步:
- 某些API调用会触发隐式同步
- 例如内存分配、默认流操作等
-
多设备同步:
- 跨设备操作需要额外的同步机制
- 通常通过事件记录和等待实现
- 使用场景示例:
// 提交多个任务到stream aclmdlExecuteAsync(modelDesc, input, output, stream); // 等待任务完成 aclrtSynchronizeStream(stream); // 安全处理结果 processOutput(output);
2.3 内存管理体系
内存类型详解
Host内存(主机内存)
-
物理位置:
- 位于CPU所在的主机服务器的主内存中
- 通过主板总线与CPU直接相连
-
技术特点:
- 通用型内存架构,支持各种数据类型和操作
- 典型访问延迟在100ns级别
- 容量配置灵活(通常为GB到TB级)
- 支持虚拟内存管理和分页机制
-
典型应用场景:
- 数据预处理:如图像解码、格式转换
- 结果后处理:推理结果的解析和格式化
- 控制流处理:程序逻辑控制和调度
- 示例:在图像识别应用中,原始JPEG图像的加载和解码通常在Host内存中完成
-
管理方式:
- 通过标准内存分配接口(如malloc/new)
- 支持自动垃圾回收(某些语言环境)
Device内存(设备内存)
-
物理位置:
- 集成在昇腾AI处理器芯片内部
- 通过高速片上互联网络与计算单元连接
-
技术特点:
- 专为AI计算优化的存储架构
- 访问延迟低至10ns级别
- 高带宽设计(可达TB/s级)
- 支持细粒度数据并行访问
-
典型应用场景:
- 神经网络权重参数的存储
- 计算过程中的中间结果缓存
- 大规模张量数据的快速存取
- 示例:卷积层的特征图在计算时会全程驻留在Device内存
-
管理方式:
- 通过专用API(如AscendCL)进行分配
- 显式内存传输控制(Host-Device间)
- 支持内存复用和共享优化
内存交互机制
-
数据传输通道:
- PCIe总线(标准服务器配置)
- 专用高速互联(某些优化配置)
-
传输优化技术:
- 批量数据传输
- 异步重叠传输
- 零拷贝技术
-
典型工作流:
Host内存预处理 → 传输至Device → Device计算 → 结果传回Host → Host后处理
关键内存操作
-
设备内存管理:
aclrtMalloc(void** devPtr, size_t size):申请Device内存aclrtFree(void* devPtr):释放Device内存- 示例:
float* deviceData; size_t dataSize = 1024 * sizeof(float); aclrtMalloc((void**)&deviceData, dataSize);
-
数据传输:
aclrtMemcpy(void* dst, size_t destMax, const void* src, size_t count, aclrtMemcpyKind kind)- 传输方向枚举:
- ACL_MEMCPY_HOST_TO_DEVICE
- ACL_MEMCPY_DEVICE_TO_HOST
- ACL_MEMCPY_DEVICE_TO_DEVICE
2.4 模型与张量系统
离线模型(.om文件)
- 生成流程:
原始框架模型(Caffe/TensorFlow等) → ATC模型转换工具 → 离线模型(.om) - 特点:
- 包含优化后的计算图
- 固化模型结构和参数
- 专为昇腾硬件优化
张量(Tensor)结构
- 核心属性:
- 数据指针(host或device内存地址)
- 维度信息(如NCHW格式)
- 数据类型(float16/float32/int8等)
- 内存布局描述
- 典型使用流程:
- 创建模型描述对象
- 获取输入/输出张量信息
- 准备对应内存空间
- 执行推理
- 处理输出张量
3. 一个典型的AscendCL应用流程
下图清晰地展示了一个AI推理任务的完整生命周期:
flowchart TD
A[初始化AscendCL] --> B[申请Device内存]
B --> C[数据H->D拷贝]
C --> D[加载模型<br>并创建模型描述]
D --> E[执行模型推理]
E --> F[数据D->H拷贝]
F --> G[释放资源<br>并去初始化]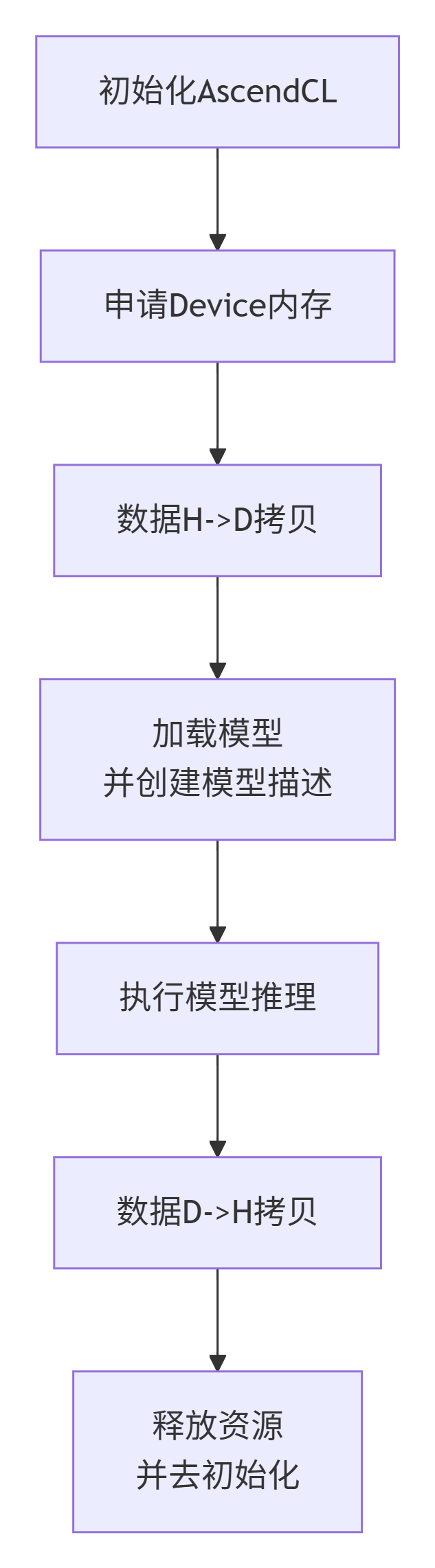
结语:
掌握了AscendCL的核心概念,就像拿到了打开昇腾AI大门的钥匙。下一篇文章,我们将把这些理论付诸实践,从初始化开始,一步步编写出我们的第一个AscendCL程序。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)