PyTorch 实现单多智能体深度强化学习算法的奇妙之旅
PyTorch 实现针对单智能体和多智能体的多种深度强化学习 (DRL) 算法A2CACKTRDQNDDPGPPO该项目包括针对单智能体和多智能体的各种深度强化学习算法的 PyTorch 实现以模块化的方式编写,允许不同算法之间共享代码gympython 3.6pytorch在深度强化学习(DRL)的世界里,我们常常需要针对单智能体和多智能体场景选择合适的算法来解决各种复杂问题。
PyTorch 实现针对单智能体和多智能体的多种深度强化学习 (DRL) 算法 A2C ACKTR DQN DDPG PPO 该项目包括针对单智能体和多智能体的各种深度强化学习算法的 PyTorch 实现 以模块化的方式编写,允许不同算法之间共享代码 gym python 3.6 pytorch
在深度强化学习(DRL)的世界里,我们常常需要针对单智能体和多智能体场景选择合适的算法来解决各种复杂问题。今天就来聊聊如何使用 PyTorch 实现 A2C、ACKTR、DQN、DDPG、PPO 这些经典的深度强化学习算法。
项目基础框架
这个项目的一大亮点是以模块化方式编写,不同算法间可共享代码,大大提高了代码的复用性和开发效率。整个项目基于 Python 3.6,借助强大的 PyTorch 深度学习库和 gym 这个用于开发和比较强化学习算法的工具包来搭建。
A2C 算法实现
A2C(Asynchronous Advantage Actor - Critic)是一种异步优势演员 - 评论家算法,它在多个线程或进程中并行地运行多个智能体,从而加速学习过程。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
class ActorCritic(nn.Module):
def __init__(self, state_dim, action_dim):
super(ActorCritic, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.actor = nn.Linear(64, action_dim)
self.critic = nn.Linear(64, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
action_probs = Categorical(logits = self.actor(x))
value = self.critic(x)
return action_probs, value
def a2c_train(env, actor_critic, optimizer, num_steps):
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
total_reward = 0
for step in range(num_steps):
action_probs, value = actor_critic(state)
action = action_probs.sample()
next_state, reward, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward]).unsqueeze(0)
mask = torch.FloatTensor([0.0]) if done else torch.FloatTensor([1.0])
next_action_probs, next_value = actor_critic(next_state)
td_target = reward + mask * 0.99 * next_value
advantage = td_target - value
actor_loss = -action_probs.log_prob(action) * advantage.detach()
critic_loss = advantage.pow(2)
loss = actor_loss + 0.5 * critic_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
total_reward += reward.item()
if done:
break
return total_reward在这段代码中,我们首先定义了 ActorCritic 网络,它包含一个用于输出动作概率的 actor 层和一个用于估计状态价值的 critic 层。a2c_train 函数则是训练的核心部分,它通过与环境交互获取奖励和下一状态,计算优势和损失,然后更新网络参数。
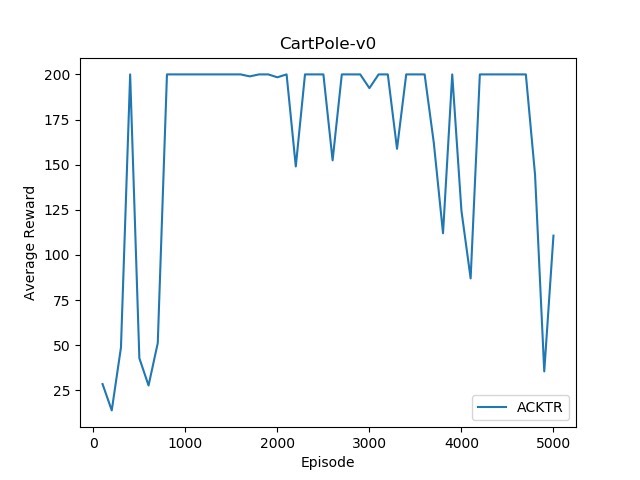
ACKTR 算法
ACKTR(Asynchronous Kronecker - Factored Trust Region)算法是在 A2C 基础上,使用 Kronecker - Factored 近似曲率来进行信任区域更新,以提高算法的稳定性和收敛速度。
# 这里简单示意 ACKTR 与 A2C 的不同部分,完整代码需要更多构建
class ACKTR_ActorCritic(nn.Module):
# 结构与 A2C 类似,但优化部分不同
pass
def acktr_train(env, actor_critic, optimizer, num_steps):
# 训练过程与 A2C 有别,主要在优化步骤
pass虽然代码结构和 A2C 类似,但在优化步骤上有很大差异,它利用了更复杂的矩阵运算来近似计算 Fisher 信息矩阵,以实现更高效的更新。
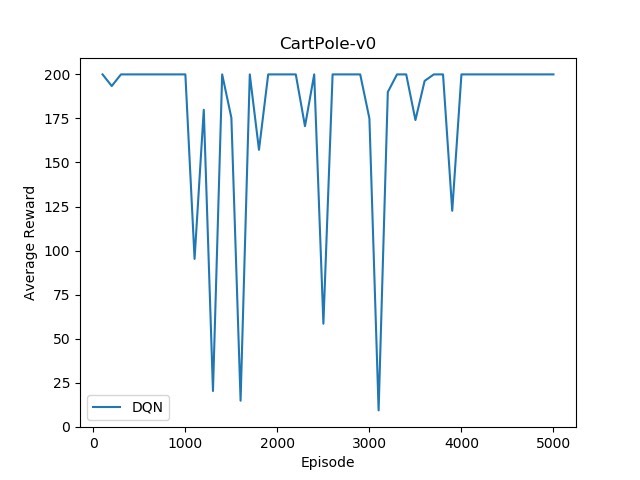
DQN 算法
DQN(Deep Q - Network)是最早成功将深度学习与强化学习相结合的算法之一,它通过神经网络来估计 Q 值。
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
import random
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
return self.fc2(x)
def dqn_train(env, dqn, target_dqn, optimizer, replay_buffer, batch_size, gamma):
if len(replay_buffer) < batch_size:
return 0
state, action, reward, next_state, done = zip(*random.sample(replay_buffer, batch_size))
state = torch.FloatTensor(state)
action = torch.LongTensor(action).unsqueeze(1)
reward = torch.FloatTensor(reward).unsqueeze(1)
next_state = torch.FloatTensor(next_state)
done = torch.FloatTensor(done).unsqueeze(1)
q_values = dqn(state).gather(1, action)
next_q_values = target_dqn(next_state).max(1)[0].detach().unsqueeze(1)
target_q_values = reward + (1 - done) * gamma * next_q_values
loss = nn.MSELoss()(q_values, target_q_values)
optimizer.zero_grad()
loss.backward()
optimizer.step()
return loss.item()这里的 DQN 网络简单地将状态映射到每个动作的 Q 值。dqn_train 函数从经验回放缓冲区中采样数据,计算目标 Q 值和当前 Q 值的损失,从而更新网络。
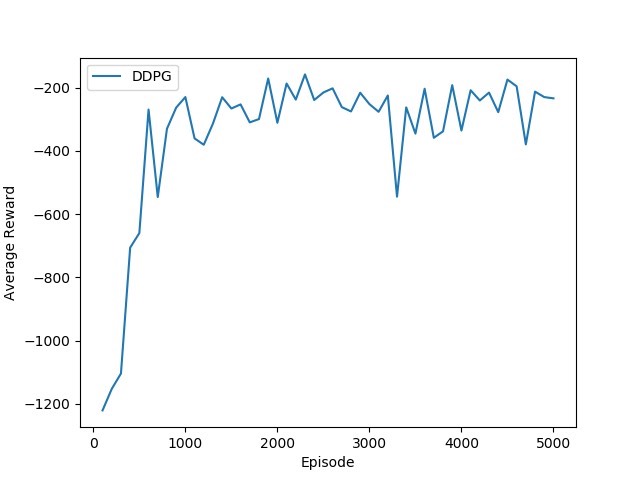
DDPG 算法
DDPG(Deep Deterministic Policy Gradient)用于连续动作空间的强化学习问题,它结合了 DQN 的思想和确定性策略梯度。
import torch
import torch.nn as nn
import torch.optim as optim
class Actor(nn.Module):
def __init__(self, state_dim, action_dim):
super(Actor, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.fc2 = nn.Linear(64, action_dim)
self.fc2.weight.data.uniform_(-3e-3, 3e-3)
def forward(self, x):
x = torch.relu(self.fc1(x))
return torch.tanh(self.fc2(x))
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.fc1 = nn.Linear(state_dim + action_dim, 64)
self.fc2 = nn.Linear(64, 1)
self.fc2.weight.data.uniform_(-3e-3, 3e-3)
def forward(self, state, action):
x = torch.cat([state, action], 1)
x = torch.relu(self.fc1(x))
return self.fc2(x)
def ddpg_train(env, actor, critic, target_actor, target_critic, actor_optimizer, critic_optimizer, noise, state):
action = actor(state) + noise.sample()
next_state, reward, done, _ = env.step(action.detach().numpy())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward]).unsqueeze(0)
done = torch.FloatTensor([done]).unsqueeze(0)
target_action = target_actor(next_state)
target_q = target_critic(next_state, target_action)
q_value = critic(state, action)
target_q = reward + (1 - done) * 0.99 * target_q
critic_loss = nn.MSELoss()(q_value, target_q.detach())
actor_loss = -critic(state, actor(state)).mean()
critic_optimizer.zero_grad()
critic_loss.backward()
critic_optimizer.step()
actor_optimizer.zero_grad()
actor_loss.backward()
actor_optimizer.step()
return reward.item()Actor 网络输出确定性的动作,Critic 网络评估动作 - 状态对的价值。训练过程中,通过最小化评论家的损失和最大化演员的奖励来更新网络。
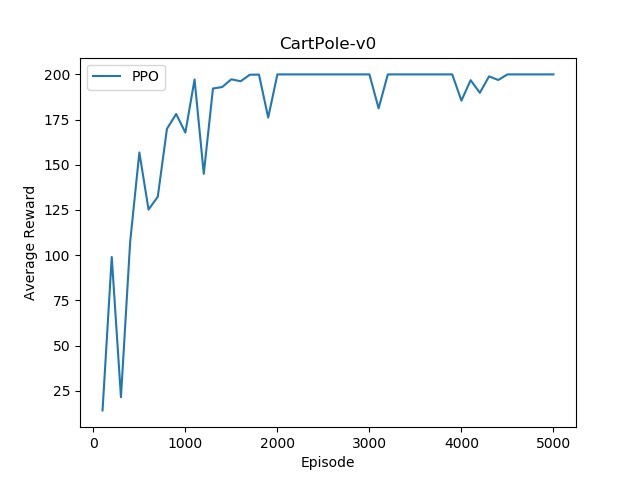
PPO 算法
PPO(Proximal Policy Optimization)是一种基于策略梯度的算法,它通过限制策略更新的步长来提高算法的稳定性。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.distributions import Categorical
class PPOActorCritic(nn.Module):
def __init__(self, state_dim, action_dim):
super(PPOActorCritic, self).__init__()
self.fc1 = nn.Linear(state_dim, 64)
self.actor = nn.Linear(64, action_dim)
self.critic = nn.Linear(64, 1)
def forward(self, x):
x = torch.relu(self.fc1(x))
action_probs = Categorical(logits = self.actor(x))
value = self.critic(x)
return action_probs, value
def ppo_train(env, actor_critic, optimizer, num_steps, clip_param=0.2):
state = env.reset()
state = torch.FloatTensor(state).unsqueeze(0)
log_probs = []
values = []
rewards = []
masks = []
for step in range(num_steps):
action_probs, value = actor_critic(state)
action = action_probs.sample()
log_prob = action_probs.log_prob(action)
next_state, reward, done, _ = env.step(action.item())
next_state = torch.FloatTensor(next_state).unsqueeze(0)
reward = torch.FloatTensor([reward]).unsqueeze(0)
mask = torch.FloatTensor([0.0]) if done else torch.FloatTensor([1.0])
log_probs.append(log_prob)
values.append(value)
rewards.append(reward)
masks.append(mask)
state = next_state
if done:
break
returns = []
advantage = torch.zeros(1, 1)
for i in reversed(range(len(rewards))):
returns.insert(0, rewards[i] + 0.99 * masks[i] * returns[0] if returns else rewards[i])
td_error = rewards[i] + 0.99 * masks[i] * values[i + 1] - values[i] if i < len(rewards) - 1 else rewards[i] - values[i]
advantage = advantage * 0.99 * masks[i] + td_error
returns = torch.cat(returns).detach()
log_probs = torch.cat(log_probs).detach()
values = torch.cat(values)
advantage = (advantage - advantage.mean()) / (advantage.std() + 1e-5)
old_log_probs = log_probs
for _ in range(3):
action_probs, value = actor_critic(state)
action = action_probs.sample()
log_prob = action_probs.log_prob(action)
ratio = torch.exp(log_prob - old_log_probs)
surr1 = ratio * advantage
surr2 = torch.clamp(ratio, 1 - clip_param, 1 + clip_param) * advantage
actor_loss = -torch.min(surr1, surr2).mean()
critic_loss = (returns - value).pow(2).mean()
loss = actor_loss + 0.5 * critic_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
return sum([r.item() for r in rewards])PPO 通过重要性采样来估计策略梯度,并使用裁剪函数来限制策略更新的幅度,从而使学习过程更加稳定。
通过这些基于 PyTorch 的实现,无论是单智能体还是多智能体场景下的深度强化学习问题,我们都能借助这些算法找到有效的解决方案,开启更多有趣的强化学习应用探索。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)