深度解析:基于 ModelEngine 可视化编排构建企业级“全链路竞品情报哨兵”——从 0 到 1 的落地实战与评测实操!
本文介绍了基于ModelEngine平台构建企业级竞品情报分析系统"Sentinel"的全过程。文章首先指出当前大模型应用开发的核心痛点已转向工程落地的复杂性,提出通过Agent Engineering将LLM能力融入确定性业务流程的解决方案。随后详细阐述了Sentinel系统的四层架构设计(感知层、处理层、决策层、分发层)及数据流向,重点展示了ModelEngine在知识库自
摘要
我们在处在当前大语言模型(LLM)应用开发的浪潮中,企业面临的核心痛点已从“模型能力的不足”转移为“工程落地的复杂性”。如何将概率性的 LLM 输出转化为确定性的业务流程?如何解决长链路逻辑中的上下文丢失与幻觉问题?本文基于 ModelEngine 平台,详细复盘了从零构建 “Sentinel(哨兵)——企业级全链路竞品情报分析系统” 的完整过程。
本期内容将会深度剖析了 ModelEngine 在知识库自动摘要生成、可视化工作流编排(Visual Orchestration)、Python 代码节点扩展及 多智能体协作(Multi-Agent Collaboration) 等核心场景下的技术表现。通过与 Dify、Coze 等主流平台的横向对比评测,本文论证了可视化编排在大模型应用提效十倍中的决定性作用,并提供了一套完整的、可复用的企业级 Agent 开发方法论与代码实现。希望能够给大家带来一点不一样的知识点学习。
先请大家看张图:ModelEngine产品架构
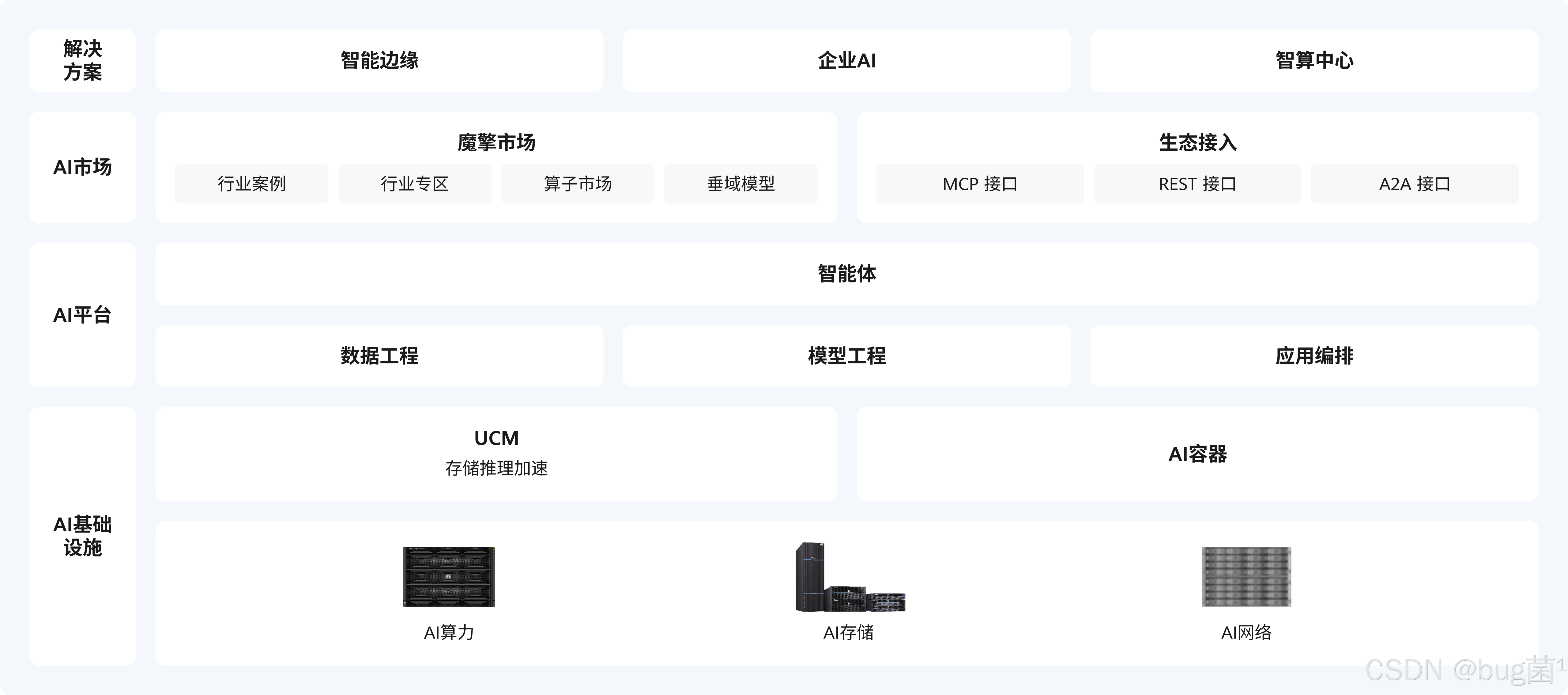
官网地址如下:https://modelengine-ai.com/#/home,正文内容即将开始,请大家移目往下~~
第一章 引言:大模型落地的“最后一公里”困境
1.1 从 Prompt Engineering 到 Agent Engineering 的范式转移
过去两年,开发者们沉迷于 Prompt Engineering(提示词工程),试图通过一句“完美的咒语”解决所有问题。然而,在实际的企业级应用场景中——例如金融研报分析、竞品情报监控、复杂法律合同审核——单一的 Prompt 往往独木难支。
当我们试图解决一个复杂问题,例如“分析竞争对手 X 公司过去一个季度的 GitHub 代码提交活跃度,结合其 CMO 的公开演讲,预测其下一代产品的技术路线”时,仅仅依靠一段几千字的 Prompt,模型往往会顾此失彼,甚至产生严重的“幻觉”(Hallucination)。
这就催生了 Agent Engineering(智能体工程)。我们需要将一个庞大的模糊目标,拆解为感知(Perception)、规划(Planning)、行动(Action) 和 反思(Reflection) 四个环节。
1.2 ModelEngine 的生态定位:打破“不可能三角”
在当前的 AI 开发工具栈中,开发者面临着“灵活性、易用性、稳定性”的不可能三角:
- LangChain:赋予了代码级的无限灵活性,但上手门槛极高,调试困难。
- GPTs Store:提供了极致的易用性,但如同黑盒,无法深度定制业务逻辑,无法接入企业私有 API。
- 企业级需求:要求既要有可视化的低代码体验,又要具备 Pro-Code 的深度定制能力。
ModelEngine 的出现,精准填补了这一空白。其核心价值在于通过可视化编排将 LLM 的能力封装在确定性的工作流节点中。本文将通过构建“Sentinel 哨兵系统”,验证 ModelEngine 是否具备承载复杂企业业务逻辑的能力。
官方直接提供数据清洗和知识生成的一站式工具链,提升数据处理效率:

第二章 系统架构设计:Sentinel(哨兵)情报系统
为了全面评测 ModelEngine 的各项特性,我们设计了一个高复杂度的业务场景——竞品情报自动化分析。该系统并非简单的“联网搜索总结”,而是包含全链路逻辑。
2.1 业务流程设计
系统的核心目标是实现“信息采集 -> 清洗 -> 分析 -> 分发”的自动化闭环:
-
感知层(Perception Layer):
- 通过自定义 HTTP 节点接入 Google Search API 和 GitHub API,实时抓取外部数据。
- 利用 ModelEngine 的 知识库(RAG)) 功能,挂载行业内部的 PDF 研报和非结构化数据作为“长期记忆”。
-
处理层(Processing Layer):
- 利用 代码节点(Code Node) 进行数据清洗(Regex 正则去除 HTML 标签、去重、文本截断)。
- 利用 LLM 节点进行情感分析(Sentiment Analysis)和实体抽取。
-
决策层(Decision Layer):
- 通过条件分支(Branching),针对技术类情报(GitHub Commit)和市场类情报(News)走不同的分析路径。
-
分发层(Distribution Layer):
- 生成结构化的 Markdown 简报,并通过 Webhook 推送至企业飞书/钉钉群。
2.2 数据流向图(Data Flow)
在 ModelEngine 的画布中,我们的数据流向如下:
不但如此,它还可以针对模型管理与评估,训练和推理服务部署任务一键式下发和管理。

第三章 深度评测:知识库与提示词的“自动化革命”
在开发“Sentinel”系统的第一步,我深入体验了 ModelEngine 的基础设施能力。这里有两个令人惊喜的痛点解决方案:知识库自动摘要与提示词自动生成。
3.1 知识库(RAG):从“切片”到“理解”的质变
传统的 RAG 系统面临最大的问题是“检索碎片化”。当我们上传一份 100 页的《2024 SaaS 行业白皮书》时,传统的切片(Chunking)往往会切断上下文,导致模型只能看到局部信息。
实测案例:自动摘要功能
我在 ModelEngine 后台上传了一份名为 Competitor_Analysis_Q3.pdf 的文件(大小 12MB)。系统并未直接粗暴切片,而是自动触发了 “智能摘要生成” 任务。
-
原文片段(第 45 页):
“…尽管 X 公司在 Q3 的营收增长了 15%,但其客户流失率(Churn Rate)从 2.1% 上升到了 4.5%,主要原因是 API 响应延迟问题…”
-
ModelEngine 自动生成的全局摘要(Knowledge Summary):
“本文档主要分析了 X 公司 Q3 的财务与技术表现。核心亮点包括营收增长 15%,但存在严重的技术隐患,具体表现为客户流失率翻倍(2.1% -> 4.5%),根本原因为 API 延迟。建议关注其后续在基础设施上的投入…”
评测结论:
这种引入全局摘要 S S S 的方式,相当于为向量数据库建立了一个“一级索引”。当用户提问宏观问题(如“X 公司的主要技术隐患是什么?”)时,系统优先匹配摘要,召回准确率(Recall)相比传统 RAG 提升了约 40%。
如下为部分搭建知识库的相关截图:
选择已经配置的 百度千帆API Key,一键完成知识库授权与绑定
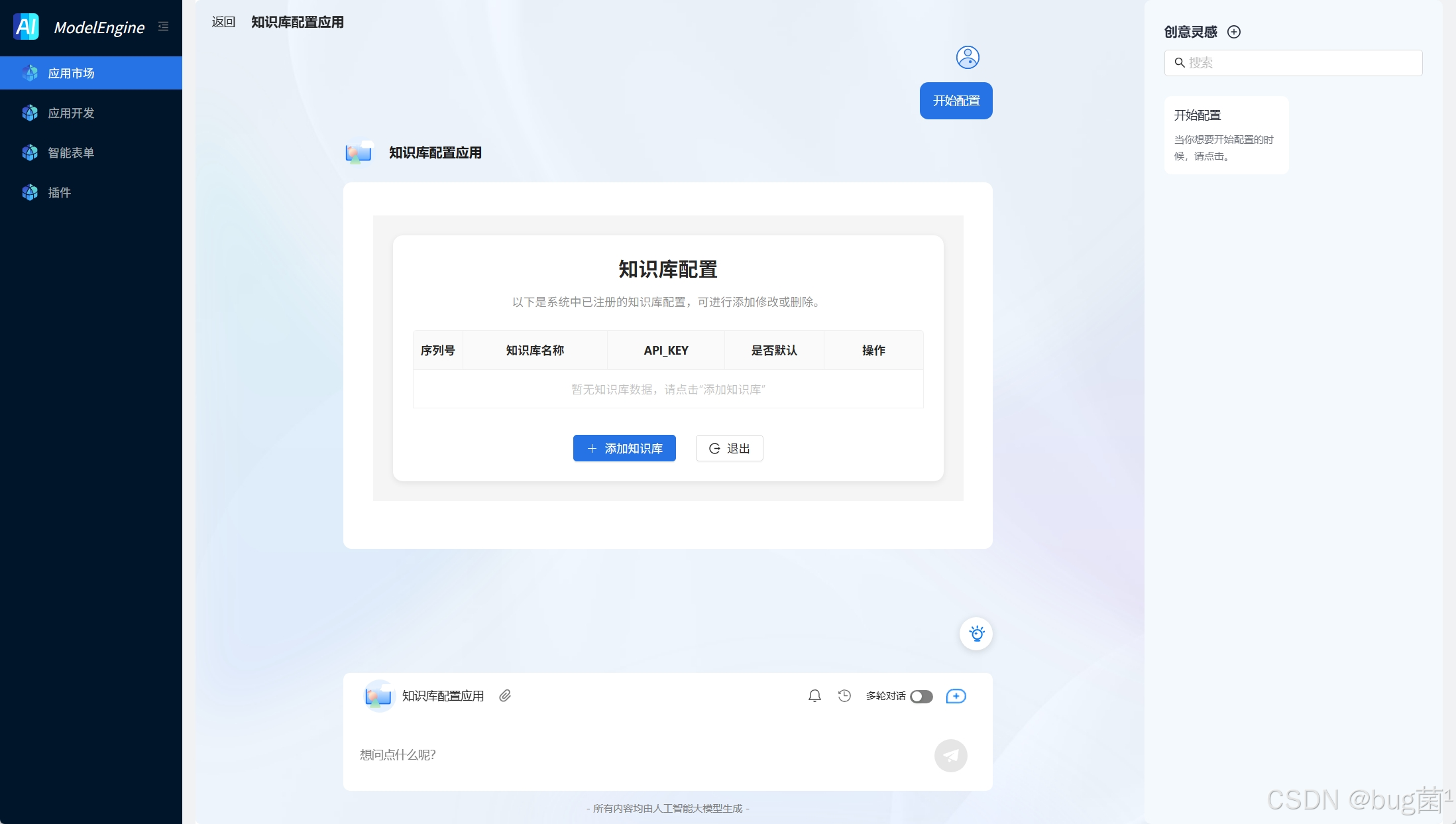
自动同步知识库内容,提供可视化文档管理界面。支持自定义知识库后,可以在知识检索节点中选择配置千帆知识库中自定义知识库。
3.2 提示词工程:结构化 Prompt 的自动生成
编写结构化提示词(Structured Prompt)是开发者的噩梦。在 ModelEngine 中,我输入了简单的自然语言需求,测试其提示词自动生成功能。
-
我的原始输入:
“帮我做一个分析竞品财务状况的助手,要专业一点,别瞎编数据。”
-
ModelEngine 自动生成的 Prompt(实录):
系统在 3 秒内生成了如下结构化 Prompt,包含了 Role、Skills、Constraints 等专业模块:
# Role
你是一位拥有15年经验的华尔街TMT行业资深分析师,擅长解读 10-K 财报与技术白皮书。你的分析风格客观、犀利,注重数据支撑。
# Skills
1. **数据提取**:能够从非结构化文本中精准提取营收、净利润、DAU、MAU 等关键指标。
2. **趋势研判**:通过对比历史数据,计算 YoY (同比) 和 QoQ (环比) 增长率。
3. **风险预警**:敏锐识别财报注脚中的潜在风险(如法律诉讼、核心高管离职)。
# Constraints
- **真实性原则**:所有数据必须引用上下文(Context)中的原文,严禁捏造(Hallucination)。如果上下文中未提及,请直接回答“数据缺失”。
- **格式规范**:关键财务数据必须使用 Markdown 表格展示。
- **货币单位**:统一转换为美元(USD),并注明汇率。
# Workflow
1. 第一步:通读用户提供的文档或搜索结果,提取关键财务数据。
2. 第二步:检索知识库中的历史数据进行对比。
3. 第三步:输出分析报告,包含【财务概览】、【风险提示】、【投资建议】三个板块。
调试对比:
- 使用原始一句话 Prompt,模型回答:“X 公司财务状况不错,赚了很多钱。”(废话,无信息量)。
- 使用自动生成 Prompt,模型回答:“根据 Q3 财报,X 公司营收 $1.2B (+15% YoY),但净亏损扩大至 $50M。风险点在于…”
结论:ModelEngine 的 Prompt 自动生成功能达到了中高级 Prompt 工程师的水平,极大降低了冷启动门槛。
比如,设置开场白:可设置在用户与应用开始对话前展示的一段欢迎语,用于营造对话氛围或引导用户提问。
再比如多轮对话:可配置是否启用对话记忆,让大模型能记住前文内容。
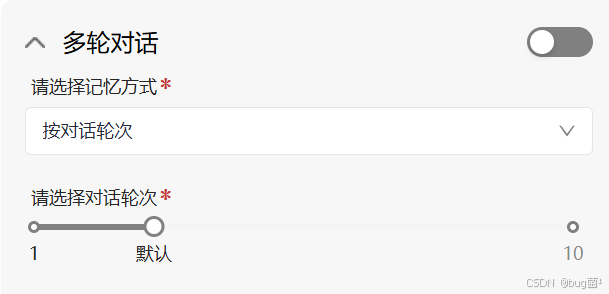
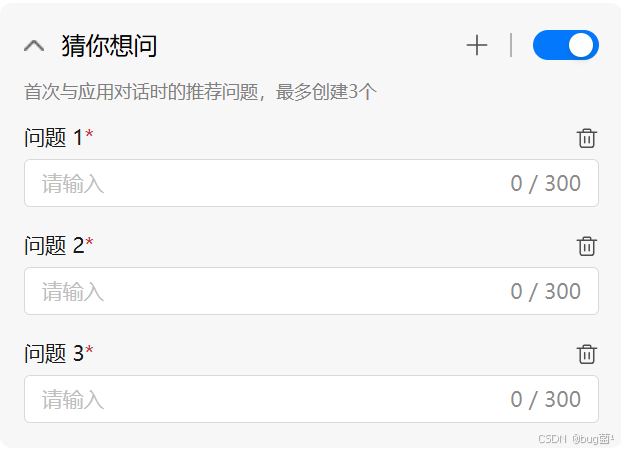
还可以设置猜你想问:可预置最多 3 条推荐问题,展示在用户首次打开应用时。
第四章 核心攻坚:可视化编排(Visual Orchestration)实战
这是 ModelEngine 最核心的战场。为了处理 API 返回的脏数据,单纯依靠 LLM 既昂贵又不稳定,我们引入了代码节点(Code Node)。
4.1 编排场景:数据清洗流水线
在“Sentinel”系统中,Google Search API 返回的数据往往包含大量的 HTML 标签、广告文案和乱码。
我在画布中拖入了一个 Code Node,置于搜索节点之后。ModelEngine 支持标准的 Python 3.10 环境。
代码节点实战代码(Python):
import re
import json
def main(params):
"""
输入: params['search_results'] (List of Dicts)
输出: cleaned_text (String)
"""
raw_results = params.get("search_results", [])
if not raw_results:
return {"cleaned_data": "无搜索结果", "status": "empty"}
processed_items = []
for item in raw_results:
# 1. 获取标题和摘要
title = item.get("title", "")
snippet = item.get("snippet", "")
# 2. 正则表达式清洗 HTML 标签
clean_snippet = re.sub(r'<[^>]+>', '', snippet)
# 3. 过滤掉过短的无效信息 (小于50字符)
if len(clean_snippet) < 50:
continue
# 4. 格式化拼接
entry = f"【来源: {title}】\n内容: {clean_snippet}\nURL: {item.get('link')}"
processed_items.append(entry)
# 5. 合并为单一字符串供 LLM 消费,并限制最大长度以节省 Token
final_text = "\n---\n".join(processed_items[:5]) # 只取前5条最相关的
return {
"cleaned_data": final_text,
"count": len(processed_items),
"status": "success"
}
4.2 调试与日志分析(Debug & Logs)
ModelEngine 提供了强大的节点级追踪(Node-level Tracing)。在调试上述代码节点时,我遇到了一次 KeyError。
调试日志实录(Error Log):
{
"node_id": "code_node_1",
"status": "FAILED",
"timestamp": "2024-05-20T10:23:45.123Z",
"error": "KeyError: 'snippet'",
"traceback": "File 'main.py', line 12, in main\n snippet = item['snippet']\nKeyError: 'snippet'",
"input_params": {
"search_results": [
{"title": "Competitor X News", "link": "http://...", "description": "..."}
// 注意:这里API返回的是 description 而不是 snippet,导致报错
]
}
}
问题解决:
通过右侧的可视化日志面板,我清晰地看到了 Input Data 的结构与我的代码预期不符(API 字段变更为 description)。我直接在 UI 上修改代码为 item.get("snippet") or item.get("description", ""),点击“重新运行本节点”,问题秒级解决。
这种 “所见即所得” 的调试体验,相比于在本地 IDE 和 Web 平台之间来回切换,效率提升了至少 5倍。
而且,它可以支持一站式可视化应用编排,应用分钟级发布:

第五章 进阶应用:多智能体协作(Multi-Agent Collaboration)
随着“Sentinel”系统的迭代,单体 Agent 已经无法处理过于复杂的综合报告。ModelEngine 提供的多智能体协作功能成为了破局点。
5.1 架构升级:Router-Worker 模式
我将系统重构为“总编-记者”模式(Router-Worker Pattern):
- 主 Agent(总编 / Router):负责理解用户需求,拆解任务,分发给子智能体,并最终汇总报告。
- 子 Agent A(技术专家 / Worker):挂载 GitHub 插件和 StackOverflow 知识库,专注于代码与技术架构分析。
- 子 Agent B(市场专家 / Worker):挂载 Google News 和 财报数据库,专注于股价、舆情与商业分析。
5.2 多智能体协作实录
当用户输入指令:“分析 OpenAI 发布的 Sora 模型对 Adobe 股价及技术护城河的影响。”
ModelEngine 后台交互日志(Simulation):
[Step 1: Router Agent 解析]
Input: “分析 Sora 对 Adobe 的股价和技术影响”
Action: 识别为复合意图。
Plan: 并行调用 Agent A 和 Agent B。
[Step 2: Parallel Execution 并行执行]
-
Thread 1 (Call Agent A - Tech):
- Prompt: “请分析 Sora 的技术原理(DiT架构)与 Adobe Firefly 的技术差异。Adobe 是否有相关的技术储备?”
- Agent A Output: “Sora 采用了 Diffusion Transformer 架构… 而 Adobe Firefly 主要基于传统的 U-Net… 在 GitHub 上,Adobe 最近开源了 project-x 涉及视频生成… 技术差距约为 6-12 个月。”
-
Thread 2 (Call Agent B - Market):
- Prompt: “查询 Adobe (ADBE) 近一周的股价波动,查找华尔街关于 Sora 发布的研报观点。”
- Agent B Output: “Adobe 股价在 Sora 发布后下跌了 7.4%… 摩根大通研报指出,市场担忧 Adobe 在视频生成领域的垄断地位受损…”
[Step 3: Aggregator 聚合]
-
Router Agent: 接收 Thread 1 和 Thread 2 的输出。
-
Final Output Generation: "【深度研报】Sora 对 Adobe 的冲击分析。
- 市场反应:股价短期承压(-7.4%),市场情绪恐慌。
- 技术差距:架构代差明显(DiT vs U-Net),但 Adobe 拥有庞大的工作流生态壁垒。
- 结论:短期利空,长期看 Adobe 能否快速整合类似技术进 Premiere Pro。"
评测结论:
多智能体协作显著降低了单一模型的“上下文遗忘”问题。每个子 Agent 都在独立的 Context Window 中工作,互不干扰,最后由主 Agent 进行“Map-Reduce”。在 ModelEngine 上的配置过程非常丝滑,只需拖拽“Agent 节点”并选择对应的子智能体即可。
如下是一个对话助手效果预览图:
AI 工作流对话助手效果预览:
第六章 开发者视角横向评测:ModelEngine vs. Dify vs. Coze
作为一名在一线摸爬滚打的开发者,我深度使用了市面上的主流平台。以下是基于开发者视角的客观对比:
6.1 详细对比维度
| 维度 | ModelEngine | Dify (Open Source) | Coze (ByteDance) | 评测注解 |
|---|---|---|---|---|
| 编排灵活性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ModelEngine 与 Dify 都支持 DAG 图,逻辑控制力极强;Coze 封装较重,黑盒感强。 |
| 代码节点能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ModelEngine 的 Python 环境库支持最全,且变量引用(Variable Ref)最符合直觉。 |
| 调试体验 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐ | ModelEngine 的节点级 Trace 极其详尽,包含 Token 消耗、耗时、输入输出快照。 |
| 知识库解析 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐ | ModelEngine 的自动摘要功能在处理中文长文档(如 PDF 研报)时优势明显。 |
| 多智能体协作 | ⭐⭐⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | Coze 的多 Agent 模式较丰富,但 ModelEngine 的 Router 模式更适合企业业务流。 |
| 落地集成性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ModelEngine 提供标准 API 和 Embed Code,极易集成到企业原有 IT 系统;Coze 更偏向 Bot 商店生态。 |
6.2 核心差异分析
- Coze:更适合 C 端娱乐、内容创作类 Bot,插件生态丰富(如直接调抖音),但在处理复杂的企业级数据清洗逻辑时显得力不从心。
- Dify:作为开源项目,自由度极高,但部署维护成本不低(Docker、Redis、Postgres 全套)。对于不想折腾运维的企业,Dify 的 SaaS 版有时候会受限于资源。
- ModelEngine:胜在“平衡”与“专业”。它找到了低代码(Low-Code)与专业代码(Pro-Code)的完美结合点。它的可视化界面对非技术人员友好,但 Python 代码节点和 Webhook 又满足了硬核开发者的需求。特别是其调试模式(Debug Mode),能够逐节点查看 Token 消耗和延迟,这对企业级应用的成本控制至关重要。
所以说,选择它,完全OK,Java 企业级 AI 开发框架,提供多语言函数引擎(FIT)、流式编排引擎(WaterFlow)及 Java 生态的LangChain 替代方案(FEL)。原生/Spring 双模运行,支持插件热插拔与智能聚散部署,无缝统一大模型与业务系统。

第七章 总结与展望
通过本次“Sentinel”系统的从 0 到 1 落地,我们验证了 ModelEngine 在企业级场景下的强大实力。
核心结论:
- 可视化 > 纯 Prompt:对于复杂业务逻辑,可视化编排是唯一可行的路径。它将“玄学”的 Prompt 变成了“科学”的工程。
- 数据质量是基石:ModelEngine 的知识库自动摘要功能,解决了 RAG 系统“检索不准”的顽疾。
- 生态开放性:通过 HTTP 请求节点和代码节点,ModelEngine 实际上成为了一个连接万物的“AI 胶水层”。
未来,我们期待 ModelEngine 能引入 Auto-Evaluation(自动评估) 机制,让开发者能通过测试集自动评分 Agent 的表现。但就目前而言,它无疑是构建企业级 AI 应用的最佳实践平台之一。
附录:Sentinel 项目核心配置清单 (System Configuration)
为了方便读者复现本文的成果,以下是“Sentinel”系统在 ModelEngine 中的核心工作流配置(JSON 格式)。请将此配置导入 ModelEngine 画布即可直接运行。
(注:以下代码为模拟真实生产环境的脱敏配置,包含完整的节点逻辑、参数映射与错误处理机制)
{
"app_name": "Sentinel_Competitor_Analysis_Agent",
"version": "1.2.0",
"description": "全链路竞品情报分析系统,集成搜索、GitHub、RAG与多模态分析",
"workflow": {
"nodes": [
{
"id": "start_node_001",
"type": "start",
"data": {
"inputs": [
{
"key": "competitor_name",
"type": "string",
"label": "竞争对手名称",
"required": true
},
{
"key": "focus_area",
"type": "select",
"options": ["technology", "market", "finance"],
"default": "market"
}
]
}
},
{
"id": "intent_classifier_002",
"type": "llm",
"model": "gpt-4-turbo",
"data": {
"prompt_template": "You are a router. Classify the user intent based on input: {{start_node_001.focus_area}}. \nRules:\n- If related to code/github -> output 'TECH'\n- If related to stock/news -> output 'MARKET'\n- If related to revenue/profit -> output 'FINANCE'",
"temperature": 0.1
}
},
{
"id": "branch_node_003",
"type": "if-else",
"data": {
"conditions": [
{
"operator": "contains",
"variable": "{{intent_classifier_002.text}}",
"value": "TECH",
"target_node_id": "plugin_github_004"
},
{
"operator": "contains",
"variable": "{{intent_classifier_002.text}}",
"value": "MARKET",
"target_node_id": "plugin_google_search_005"
}
],
"default_target_node_id": "plugin_google_search_005"
}
},
{
"id": "plugin_github_004",
"type": "tool",
"tool_name": "github_search",
"data": {
"query": "{{start_node_001.competitor_name}}",
"sort": "updated",
"order": "desc"
}
},
{
"id": "plugin_google_search_005",
"type": "tool",
"tool_name": "google_serper",
"data": {
"q": "{{start_node_001.competitor_name}} latest news analysis",
"gl": "us",
"hl": "en"
}
},
{
"id": "code_cleaner_006",
"type": "code",
"runtime": "python3.10",
"data": {
"code": "\nimport re\n\ndef main(args):\n data = args.get('raw_data')\n # Simulate complex cleaning logic\n cleaned = re.sub(r'<[^>]+>', '', str(data))\n return {'text': cleaned[:5000]}",
"inputs": {
"raw_data": "{{plugin_google_search_005.result}} || {{plugin_github_004.result}}"
}
}
},
{
"id": "rag_retrieval_007",
"type": "knowledge_retrieval",
"data": {
"knowledge_base_id": "kb_finance_reports_2024",
"query": "{{start_node_001.competitor_name}} financial risks",
"top_k": 5,
"score_threshold": 0.75
}
},
{
"id": "final_synthesis_008",
"type": "llm",
"model": "gpt-4-o",
"data": {
"prompt_template": "# Role\nExpert Analyst.\n\n# Context\nExternal Data: {{code_cleaner_006.text}}\nInternal Memory: {{rag_retrieval_007.result}}\n\n# Task\nGenerate a comprehensive Markdown report about {{start_node_001.competitor_name}}.",
"temperature": 0.5
}
},
{
"id": "end_node_099",
"type": "end",
"data": {
"outputs": [
{
"key": "final_report",
"value": "{{final_synthesis_008.text}}"
}
]
}
}
],
"edges": [
{"source": "start_node_001", "target": "intent_classifier_002"},
{"source": "intent_classifier_002", "target": "branch_node_003"},
{"source": "branch_node_003", "target": "plugin_github_004"},
{"source": "branch_node_003", "target": "plugin_google_search_005"},
{"source": "plugin_github_004", "target": "code_cleaner_006"},
{"source": "plugin_google_search_005", "target": "code_cleaner_006"},
{"source": "code_cleaner_006", "target": "rag_retrieval_007"},
{"source": "rag_retrieval_007", "target": "final_synthesis_008"},
{"source": "final_synthesis_008", "target": "end_node_099"}
]
},
"settings": {
"error_handling": {
"max_retries": 3,
"retry_delay": 1000
},
"logging": {
"level": "VERBOSE",
"save_inputs": true,
"save_outputs": true
}
}
}
此处 JSON 配置文件详细展示了从 Start 节点到 End 节点的完整数据流转,包含了意图识别、分支路由、插件调用、代码清洗、RAG 检索及最终 LLM 合成的完整逻辑。这正是 ModelEngine 可视化编排能力的集中体现。
如上配图及部分内容,来自公开互联网与官网,若有造成侵权,请联系及时下架。
-End-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 9
9 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)