LangGraph构建大模型应用的认知架构:从LLM调用到智能路由决策!
本文介绍了构建大语言模型应用的四种认知架构:代码架构、LLM调用、链式和路由架构。这些架构在自主性与监管间取得平衡,从简单LLM调用到让LLM决定下一步操作。文章详细解释了每种架构特点和实现方法,并通过LangGraph代码示例展示如何构建这些架构,帮助开发者根据应用需求选择合适的架构设计。
- [✓] Chapter 5. Cognitive Architectures with LangGraph
如何将LLM提示技巧、RAG、记忆整合成一个连贯的应用,实现我们设定的目标?用砖瓦世界做类比,游泳池和一层房屋用的是相同材料建造,但显然用途截然不同。使它们独特适合不同用途的是材料组合的规划——也就是它们的建筑结构。构建LLM应用时也是如此,你必须做出的最重要的决定是如何将你手头的各种组成部分(比如RAG、提示技巧、记忆)组合成实现你目的的东西。
在我们具体了解具体架构之前,先来举个例子。你可能开发的任何大型语言模型应用,都会从一个目的出发:应用设计的目的。假设你想开发一个电子邮件助手——一个能先阅读你的邮件并减少你需要查看的邮件数量的大型语言模型应用。应用可能会通过存档一些无聊的邮件,直接回复一些,并标记其他值得你关注的邮件来实现这一点。
你可能还希望应用在操作上受到一些约束。列出这些限制条件极大帮助,因为它们有助于寻找合适的架构。对于这个假设的电子邮件助手,假设我们希望它能做到以下内容:
- 尽量减少它打扰你的次数(毕竟,关键就是节省时间)。
- 避免你的邮件对手收到你自己绝不会收到的回复。
这暗示了构建大型语言模型应用时常面临的关键权衡:能动性(或自主行动能力)与可靠性(即你对其输出的信任程度)之间的权衡。直观上,邮件助手如果能在你不参与的情况下处理更多操作,它会更有用,但如果你用得太过头,它最终会发送你希望它没发的邮件。
描述LLM应用自主性程度的一种方法是评估应用行为中有多少是由LLM决定的(而非代码):
- 让大型语言模型决定步骤的输出(例如,写邮件的草稿回复)。
- 让大型语言模型决定下一步该采取什么(例如,对于新邮件,可以在邮件中采取的三种作中选择:归档、回复或标记审查)。
- 让LLM决定可以采取哪些步骤(比如让LLM写代码执行你没有预先编程到应用中的动态作)。
我们可以根据LLM应用在自主性范围中的位置,对构建LLM应用的多种常见方法进行分类,也就是说,上述三项任务中哪些由LLM处理,哪些仍由开发者或用户掌握。这些配方可以称为认知架构。在人工智能领域,“认知架构”一词长期以来一直用来指代人类推理的模型(及其在计算机中的实现)。LLM认知架构(据我们所知,该术语最早用于LLM的一篇论文①)可以定义为LLM应用应采取步骤的配方(见图1)。例如,步骤是检索相关文档(RAG),或通过思维链提示调用大型语言模型。
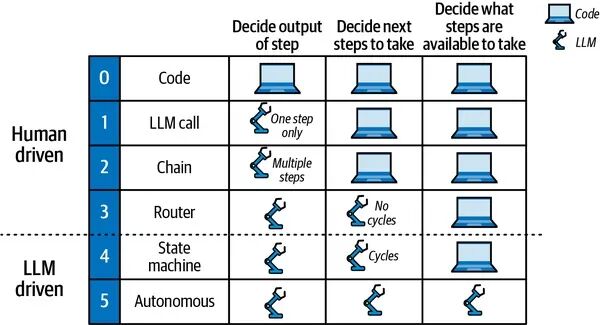
图1 LLM应用的认知架构
现在让我们来看一下在构建应用时可以使用的每种主要架构或配方(如图1所示):
0:代码这不是大型语言模型的认知架构(因此我们编号为0),因为它根本不使用大型语言模型。你可以把它看作是你习惯编写的普通软件。
1:LLM调用这是我们看到的大多数例子,只有一个LLM调用。这主要适用于大型语言模型(LLM)用于完成特定任务的大型应用,比如翻译或总结一段文本。
**2:链(Chain)**可以说,更进一步的层次是按照预设顺序使用多个LLM调用。例如,文本转SQL应用程序(从用户那里接收到用于数据库的自然语言计算描述)可以连续使用两个LLM调用:
一个LLM调用,生成SQL查询,基于用户提供的自然语言查询,以及开发者提供的数据库内容描述。
还有另一个LLM调用,针对非技术用户,根据上一次调用生成的查询,写出适合非技术用户的查询说明。该查询可用于用户检查生成的查询是否符合他的请求。
**3:路由(Router)**下一步是利用LLM定义步骤顺序。也就是说,链式架构总是执行由开发者确定的静态步骤序列,而路由架构则通过使用大型语言模型(LLM)在某些预定义步骤中进行选择。一个例子是RAG应用,具有多个不同领域文档索引,步骤如下:
- 通过调用LLM来选择使用哪些可用索引,基于用户提供的查询和开发者提供的索引描述。
- 检索步骤查询所选索引中最相关文档。
- 另一个LLM调用,根据用户提供的查询和从索引中获取的相关文档列表生成答案。
下面我们将依次讨论每一种架构,这些架构对LLM的使用更加频繁。但首先,让我们谈谈一些更好的工具,帮助我们顺利完成这项任务。
架构 #1:LLM 调用
作为大型语言模型调用架构以创建的聊天机器人的例子,该聊天机器人将直接回复用户消息。
首先创建一个,我们将添加一个节点来表示LLM调用:
python
”
from typing import Annotated, TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messagesfrom langchain_openai import ChatOpenAImodel = ChatOpenAI()class State(TypedDict): # Messages have the type "list". The `add_messages` # function in the annotation defines how this state should # be updated (in this case, it appends new messages to the # list, rather than replacing the previous messages) messages: Annotated[list, add_messages]def chatbot(state: State): answer = model.invoke(state["messages"]) return {"messages": [answer]}builder = StateGraph(State)builder.add_node("chatbot", chatbot)builder.add_edge(START, 'chatbot')builder.add_edge('chatbot', END)graph = builder.compile()
JavaScript
”
import { StateGraph, Annotation, messagesStateReducer, START, END} from'@langchain/langgraph'import {ChatOpenAI} from'@langchain/openai'const model = new ChatOpenAI()const State = {/** * The State defines three things: * 1. The structure of the graph's state (which "channels" are available to * read/write) * 2. The default values for the state's channels * 3. The reducers for the state's channels. Reducers are functions that * determine how to apply updates to the state. Below, new messages are * appended to the messages array. */messages: Annotation({ reducer: messagesStateReducer, default: () => [] }),}asyncfunction chatbot(state) {const answer = await model.invoke(state.messages)return {"messages": answer}}const builder = new StateGraph(State) .addNode('chatbot', chatbot) .addEdge(START, 'chatbot') .addEdge('chatbot', END)const graph = builder.compile()
我们也可以绘制图的可视化表示:
Pythongraph.get_graph().draw_mermaid_png()
JavaScriptawait graph.getGraph().drawMermaidPng()
我们刚才画的图看起来像图2。
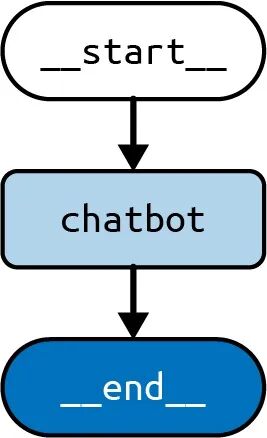
图2 LLM调用架构
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

你可以使用熟悉的 stream() 方法来运行它:
python
”
input = {"messages": [HumanMessage('hi!)]}for chunk in graph.stream(input): print(chunk)
JavaScript
”
const input = {messages: [new HumanMessage('hi!)]}for await (const chunk of await graph.stream(input)) { console.log(chunk)}
然后输出:
{ "chatbot": { "messages": [AIMessage("How can I help you?")] } }
注意图的输入形状与我们之前定义的Statemessages对象相同;也就是说,我们发送了一份按字典键的消息列表。
这是使用LLM最简单的架构,但这并不意味着它不应该被使用。以下是一些你可能在流行产品中看到的示例,以及许多其他产品:
- AI驱动的功能如摘要和翻译(如Notion这一流行的写作软件)可以通过单一LLM调用驱动。
- 根据开发者心中的用户体验和目标用户,简单的SQL查询生成可以通过单次LLM调用实现。
架构 #2:链
这种架构在所有这些基础上进行了扩展,通过使用多个LLM调用,按预定义的顺序进行(即应用程序的不同调用执行相同的LLM调用序列,尽管输入和结果不同)。
以文本转SQL应用为例,它从用户那里接收到一个自然语言描述,描述需要在数据库上进行的某种计算。我们之前提到,只需一个LLM调用即可生成SQL查询,但我们可以通过连续使用多个LLM调用来创建更复杂的应用。有些作者称这种架构为流程工程。②
首先,让我们用语言描述这种流程:
- 一个LLM调用,从用户提供的自然语言查询和开发者提供的数据库内容描述中生成SQL查询。
- 另一个LLM调用,针对非技术用户编写适合查询的解释,前提是之前调用中生成的查询。该查询可用于用户检查生成的查询是否符合他的请求。
你也可以进一步扩展(但这里不做),在前两步之后还要采取额外步骤:
- 对数据库执行查询,数据库返回一个二维表。
- 使用第三个LLM调用将查询结果总结为对原始用户问题的文本回答。
现在让我们用LangGraph实现这个:
python
”
from typing import Annotated, TypedDictfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_openai import ChatOpenAIfrom langgraph.graph import END, START, StateGraphfrom langgraph.graph.message import add_messages# useful to generate SQL querymodel_low_temp = ChatOpenAI(temperature=0.1)# useful to generate natural language outputsmodel_high_temp = ChatOpenAI(temperature=0.7)class State(TypedDict): # to track conversation history messages: Annotated[list, add_messages] # input user_query: str # output sql_query: str sql_explanation: strclass Input(TypedDict): user_query: strclass Output(TypedDict): sql_query: str sql_explanation: strgenerate_prompt = SystemMessage( """You are a helpful data analyst who generates SQL queries for users based on their questions.""")def generate_sql(state: State) -> State: user_message = HumanMessage(state["user_query"]) messages = [generate_prompt, *state["messages"], user_message] res = model_low_temp.invoke(messages) return { "sql_query": res.content, # update conversation history "messages": [user_message, res], }explain_prompt = SystemMessage( "You are a helpful data analyst who explains SQL queries to users.")def explain_sql(state: State) -> State: messages = [ explain_prompt, # contains user's query and SQL query from prev step *state["messages"], ] res = model_high_temp.invoke(messages) return { "sql_explanation": res.content, # update conversation history "messages": res, }builder = StateGraph(State, input=Input, output=Output)builder.add_node("generate_sql", generate_sql)builder.add_node("explain_sql", explain_sql)builder.add_edge(START, "generate_sql")builder.add_edge("generate_sql", "explain_sql")builder.add_edge("explain_sql", END)graph = builder.compile()
JavaScript
”
import { HumanMessage, SystemMessage} from"@langchain/core/messages";import { ChatOpenAI } from"@langchain/openai";import { StateGraph, Annotation, messagesStateReducer, START, END,} from"@langchain/langgraph";// useful to generate SQL queryconst modelLowTemp = new ChatOpenAI({ temperature: 0.1 });// useful to generate natural language outputsconst modelHighTemp = new ChatOpenAI({ temperature: 0.7 });const annotation = Annotation.Root({messages: Annotation({ reducer: messagesStateReducer, default: () => [] }),user_query: Annotation(),sql_query: Annotation(),sql_explanation: Annotation(),});const generatePrompt = new SystemMessage(`You are a helpful data analyst who generates SQL queries for users based on their questions.`);asyncfunction generateSql(state) {const userMessage = new HumanMessage(state.user_query);const messages = [generatePrompt, ...state.messages, userMessage];const res = await modelLowTemp.invoke(messages);return { sql_query: res.content as string, // update conversation history messages: [userMessage, res], };}const explainPrompt = new SystemMessage("You are a helpful data analyst who explains SQL queries to users.");asyncfunction explainSql(state) {const messages = [explainPrompt, ...state.messages];const res = await modelHighTemp.invoke(messages);return { sql_explanation: res.content as string, // update conversation history messages: res, };}const builder = new StateGraph(annotation) .addNode("generate_sql", generateSql) .addNode("explain_sql", explainSql) .addEdge(START, "generate_sql") .addEdge("generate_sql", "explain_sql") .addEdge("explain_sql", END);const graph = builder.compile();
图3 显示了该图表的可视化表示。
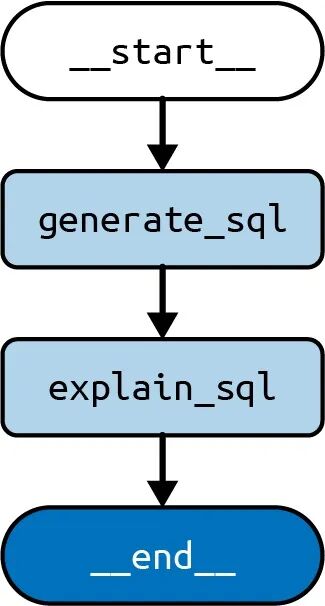
图3 链式架构
这里是一个输入和输出的示例:
python
”
graph.invoke({ "user_query": "What is the total sales for each product?"})
JavaScript
”
await graph.invoke({ user_query: "What is the total sales for each product?"})
然后输出:
{ "sql_query": "SELECT product_name, SUM(sales_amount) AS total_sales\nFROM sales\nGROUP BY product_name;", "sql_explanation": "This query will retrieve the total sales for each product by summing up the sales_amount column for each product and grouping the results by product_name.",}
首先,执行该节点,将密钥填充到状态中(该状态将成为最终输出的一部分),并用新消息更新密钥。然后节点运行,将前一步生成的SQL查询输入状态。此时,图运行结束,输出返回给调用者。generate_sqlsql_querymessagesexplain_sqlsql_explanation
还要注意,在创建 .这让你可以自定义哪些状态部分被接受为用户输入,哪些部分作为最终输出返回。其余状态键由图节点内部用于保持中间状态,并作为由 产生的流输出的一部分向用户开放。StateGraphstream()
架构 #3:路由
下一个架构通过赋予LLM我们之前描述的下一步职责——决定下一步该采取什么——来提升自主性阶梯。也就是说,链式架构总是执行静态的步骤序列(无论数量多少),而路由器架构的特点是使用LLM在某些预定义步骤中进行选择。
我们以一个RAG应用程序为例,该应用能够访问来自不同领域的多个文档索引。通常,通过避免提示中包含的无关信息,可以从LLM中提取更好的性能。因此,在构建这个应用时,我们应该尝试为每个查询选择合适的索引,只使用那一个。该架构的关键发展是使用LLM来做出决策,实际上利用LLM评估每个输入查询,并决定该查询应使用哪个索引。
| 注意 |
|---|
| 在大型语言模型出现之前,解决这个问题的常见方法是利用机器学习技术构建分类器模型,并将示例用户查询映射到正确的索引。这可能相当具有挑战性,因为需要以下条件: |
| - 手工组装数据集 |
| - 从每个用户查询生成足够的特征(定量属性),以便训练该任务的分类器 |
| 由于LLM编码人类语言,可以有效地作为这种分类器,只需零或极少的例子或额外训练。 |
首先,让我们用语言描述这种流程:
- 通过调用LLM来选择使用哪些可用索引,基于用户提供的查询和开发者提供的索引描述
- 检索步骤查询所选索引中最相关的文档
- 另一个LLM调用以生成答案,基于用户提供的查询和从索引中获取的相关文档列表
现在让我们用LangGraph实现它:
python
”
from typing import Annotated, Literal, TypedDictfrom langchain_core.documents import Documentfrom langchain_core.messages import HumanMessage, SystemMessagefrom langchain_core.vectorstores.in_memory import InMemoryVectorStorefrom langchain_openai import ChatOpenAI, OpenAIEmbeddingsfrom langgraph.graph import END, START, StateGraphfrom langgraph.graph.message import add_messagesembeddings = OpenAIEmbeddings()# useful to generate SQL querymodel_low_temp = ChatOpenAI(temperature=0.1)# useful to generate natural language outputsmodel_high_temp = ChatOpenAI(temperature=0.7)class State(TypedDict): # to track conversation history messages: Annotated[list, add_messages] # input user_query: str # output domain: Literal["records", "insurance"] documents: list[Document] answer: strclass Input(TypedDict): user_query: strclass Output(TypedDict): documents: list[Document] answer: str# refer to Chapter 2 on how to fill a vector store with documentsmedical_records_store = InMemoryVectorStore.from_documents([], embeddings)medical_records_retriever = medical_records_store.as_retriever()insurance_faqs_store = InMemoryVectorStore.from_documents([], embeddings)insurance_faqs_retriever = insurance_faqs_store.as_retriever()router_prompt = SystemMessage( """You need to decide which domain to route the user query to. You have two domains to choose from: - records: contains medical records of the patient, such as diagnosis, treatment, and prescriptions. - insurance: contains frequently asked questions about insurance policies, claims, and coverage.Output only the domain name.""")def router_node(state: State) -> State: user_message = HumanMessage(state["user_query"]) messages = [router_prompt, *state["messages"], user_message] res = model_low_temp.invoke(messages) return { "domain": res.content, # update conversation history "messages": [user_message, res], }def pick_retriever( state: State,) -> Literal["retrieve_medical_records", "retrieve_insurance_faqs"]: if state["domain"] == "records": return"retrieve_medical_records" else: return"retrieve_insurance_faqs"def retrieve_medical_records(state: State) -> State: documents = medical_records_retriever.invoke(state["user_query"]) return { "documents": documents, }def retrieve_insurance_faqs(state: State) -> State: documents = insurance_faqs_retriever.invoke(state["user_query"]) return { "documents": documents, }medical_records_prompt = SystemMessage( """You are a helpful medical chatbot who answers questions based on the patient's medical records, such as diagnosis, treatment, and prescriptions.""")insurance_faqs_prompt = SystemMessage( """You are a helpful medical insurance chatbot who answers frequently asked questions about insurance policies, claims, and coverage.""")def generate_answer(state: State) -> State: if state["domain"] == "records": prompt = medical_records_prompt else: prompt = insurance_faqs_prompt messages = [ prompt, *state["messages"], HumanMessage(f"Documents: {state["documents"]}"), ] res = model_high_temp.invoke(messages) return { "answer": res.content, # update conversation history "messages": res, }builder = StateGraph(State, input=Input, output=Output)builder.add_node("router", router_node)builder.add_node("retrieve_medical_records", retrieve_medical_records)builder.add_node("retrieve_insurance_faqs", retrieve_insurance_faqs)builder.add_node("generate_answer", generate_answer)builder.add_edge(START, "router")builder.add_conditional_edges("router", pick_retriever)builder.add_edge("retrieve_medical_records", "generate_answer")builder.add_edge("retrieve_insurance_faqs", "generate_answer")builder.add_edge("generate_answer", END)graph = builder.compile()
JavaScript
”
import { HumanMessage, SystemMessage} from"@langchain/core/messages";import { ChatOpenAI, OpenAIEmbeddings} from"@langchain/openai";import { MemoryVectorStore} from"langchain/vectorstores/memory";import { DocumentInterface} from"@langchain/core/documents";import { StateGraph, Annotation, messagesStateReducer, START, END,} from"@langchain/langgraph";const embeddings = new OpenAIEmbeddings();// useful to generate SQL queryconst modelLowTemp = new ChatOpenAI({ temperature: 0.1 });// useful to generate natural language outputsconst modelHighTemp = new ChatOpenAI({ temperature: 0.7 });const annotation = Annotation.Root({messages: Annotation({ reducer: messagesStateReducer, default: () => [] }),user_query: Annotation(),domain: Annotation(),documents: Annotation(),answer: Annotation(),});// refer to Chapter 2 on how to fill a vector store with documentsconst medicalRecordsStore = await MemoryVectorStore.fromDocuments( [], embeddings);const medicalRecordsRetriever = medicalRecordsStore.asRetriever();const insuranceFaqsStore = await MemoryVectorStore.fromDocuments( [], embeddings);const insuranceFaqsRetriever = insuranceFaqsStore.asRetriever();const routerPrompt = new SystemMessage(`You need to decide which domain to route the user query to. You have two domains to choose from: - records: contains medical records of the patient, such as diagnosis, treatment, and prescriptions. - insurance: contains frequently asked questions about insurance policies, claims, and coverage.Output only the domain name.`);asyncfunction routerNode(state) {const userMessage = new HumanMessage(state.user_query);const messages = [routerPrompt, ...state.messages, userMessage];const res = await modelLowTemp.invoke(messages);return { domain: res.content as"records" | "insurance", // update conversation history messages: [userMessage, res], };}function pickRetriever(state) {if (state.domain === "records") { return"retrieve_medical_records"; } else { return"retrieve_insurance_faqs"; }}asyncfunction retrieveMedicalRecords(state) {const documents = await medicalRecordsRetriever.invoke(state.user_query);return { documents, };}asyncfunction retrieveInsuranceFaqs(state) {const documents = await insuranceFaqsRetriever.invoke(state.user_query);return { documents, };}const medicalRecordsPrompt = new SystemMessage(`You are a helpful medical chatbot who answers questions based on the patient's medical records, such as diagnosis, treatment, and prescriptions.`);const insuranceFaqsPrompt = new SystemMessage(`You are a helpful medical insurance chatbot who answers frequently asked questions about insurance policies, claims, and coverage.`);asyncfunction generateAnswer(state) {const prompt = state.domain === "records" ? medicalRecordsPrompt : insuranceFaqsPrompt;const messages = [ prompt, ...state.messages, new HumanMessage(`Documents: ${state.documents}`), ];const res = await modelHighTemp.invoke(messages);return { answer: res.content as string, // update conversation history messages: res, };}const builder = new StateGraph(annotation) .addNode("router", routerNode) .addNode("retrieve_medical_records", retrieveMedicalRecords) .addNode("retrieve_insurance_faqs", retrieveInsuranceFaqs) .addNode("generate_answer", generateAnswer) .addEdge(START, "router") .addConditionalEdges("router", pickRetriever) .addEdge("retrieve_medical_records", "generate_answer") .addEdge("retrieve_insurance_faqs", "generate_answer") .addEdge("generate_answer", END);const graph = builder.compile();
图4展示了可视化表现。
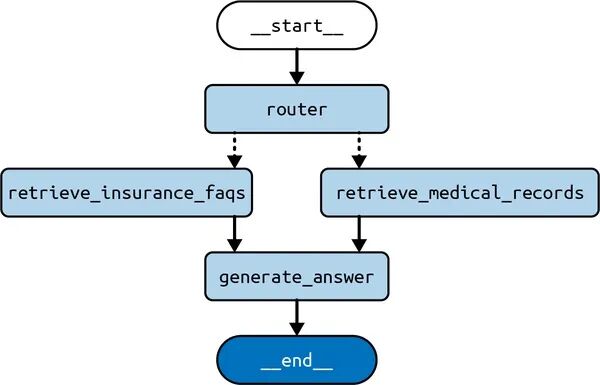
图4 路由架构
注意这现在开始变得更有用了,因为它展示了图中可能的两条路径,分别是通过或通过,并且对于这两条路径,我们先访问节点,最后访问节点。这两种可能路径通过条件边实现,条件边通过函数实现,该函数将LLM所选的节点映射到前面提到的两个节点之一。条件边如图4所示,为从源节点到目标节点的虚线。retrieve_medical_recordsretrieve_insurance_faqsroutergenerate_answerpick_retrieverdomain
现在举例来说,输入和输出,这次是流式输出:
python
”
input = { "user_query": "Am I covered for COVID-19 treatment?"}for c in graph.stream(input): print(c)
JavaScript
”
const input = { user_query: "Am I covered for COVID-19 treatment?"}for await (const chunk of await graph.stream(input)) {console.log(chunk)}
输出(实际答案不显示,因为这取决于你的文档):
{ "router": { "messages": [ HumanMessage(content="Am I covered for COVID-19 treatment?"), AIMessage(content="insurance"), ], "domain": "insurance", }}{ "retrieve_insurance_faqs": { "documents": [...] }}{ "generate_answer": { "messages": AIMessage( content="...", ), "answer": "...", }}
该输出流包含在图执行过程中每个节点返回的值。我们一个一个来。每个词典中的顶层键是节点的名称,而该键的值则是该节点返回的:
- 路由节点返回了消息更新(这将使我们能够轻松地使用之前描述的记忆技巧继续对话),以及LLM为该用户查询选择的领域,在本例中是
insurance。 - 然后
pick_retriever函数运行并返回下一个要运行的节点名称,该名称基于上一步 LLM 调用识别的领域。 - 然后
retrieve_insurance_faqs节点运行,返回了该索引中一组相关文档。这意味着,在前面看到的图中,我们选择了左侧路径,这是由 LLM 决定的。 - 最后,
generate_answer节点运行,它使用这些文档和原始用户查询生成了问题的答案,并将答案写入状态(同时对 messages 键进行了最终更新)。
本文讨论了构建LLM应用时的关键权衡:自主性与监管。一个LLM应用越自主,它能够完成的任务就越多——但这也增加了对其行为进行更多控制机制的需求。随后我们讨论了不同的认知架构,这些架构在自主性与监管之间取得了不同的平衡。
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!
01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献420条内容
已为社区贡献420条内容

所有评论(0)