别再让AI“营养不良”!手把手教你用Bright Data MCP实时“喂活”大模型
摘要:本文探讨了AI开发中面临的数据获取难题,提出了BrightData MCP服务器作为解决方案。文章分析了自建爬虫的三大痛点(效率低、质量差、合规风险),介绍了MCP协议如何通过标准化数据接口实现AI与外部数据的无缝对接。通过Python代码示例展示了如何集成BrightData MCP与DeepSeek API构建竞品价格监控系统,验证了该方案在企业级应用中的可靠性和扩展性。最后展望了&qu

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
第一章:引言
我们正在构建的,是渴望数据的巨人,却常常用吸管给它喂水。
作为一名AI开发者和内容创作者,我亲眼目睹并亲身经历了人工智能领域的爆炸式增长。从需要大量知识灌装的RAG系统,到能自主执行复杂任务的AI Agent,再到对数据质量要求极高的模型微调——我们的构想越来越宏大,AI的潜力边界在被不断推远。
然而,在这片繁荣之下,一个巨大且普遍的隐痛正困扰着绝大多数团队和个人开发者:我们的AI模型,正面临着严重的“数据营养不良”。
1.1 “巧妇难为无米之炊”
想象一下,你正在构建一个:
-
一个能实时比价、为你省钱的购物Agent。
-
一个能洞察市场趋势、分析竞品动态的商业智能助手。
-
一个需要最新、最全的行业知识来回答用户问题的专业问答机器人。
这些应用的智能程度,直接取决于它们所能“吃到”的数据的数量、质量和新鲜度。没有持续、高质量的数据流入,再先进的模型也只会是“无源之水,无本之木”,其表现会迅速变得陈旧、呆板甚至胡言乱语。
1.2 数据获取的“三座大山”
当我们试图自己去为AI“找食物”时,通常会撞上以下三座大山:
1. 规模与效率的“叹息之墙” 当你需要从成百上千个网页中获取数据时,自建的爬虫脚本就显得力不从心了。串行请求慢如蜗牛,而一旦尝试并行加速,立马会触发目标网站的防御机制,导致IP被封。你的AI应用可能因为等不到数据而“卡死”,或者在关键时刻“断粮”。效率,成了第一个拦路虎。
2. 质量与稳定的“无常之舞” 即使侥幸突破了封锁,抓取回来的数据也往往是HTML标签、JS代码和正文混杂的“一锅粥”。你需要花费大量精力去清洗、解析和结构化这些数据。更头疼的是,网站布局一旦改版,你的爬虫规则立刻失效,数据流随即中断。维护一个稳定、高质量的数据管道,其工作量常常远超开发AI应用本身。**
3. 合规与伦理的“达摩克利斯之剑” 这是最容易被忽视,但后果最严重的一点。无视网站的robots.txt协议、过快请求导致对方服务器瘫痪、不慎抓取到受版权保护或个人隐私的信息……这些行为不仅不道德,更可能将你和你的项目置于法律风险之下。在数据监管日益严格的今天,合规性不再是可选项,而是生存的底线。
1.3 破局之道
至此,问题已经非常清晰:自建数据采集方案,让我们从AI开发者“降级”成了爬虫工程师,深陷在反爬虫、数据清洗和合规风险的泥潭中,分散了本应专注于AI算法与业务逻辑的核心精力。
那么,有没有一种解决方案,能像接通自来水一样,为我们提供一个稳定、洁净、即开即用的“数据流”,让我们的AI模型能够“开怀畅饮”?
答案是肯定的。这个解决方案,就是扮演 “AI专属数据捕手” 角色的 Bright Data MCP服务器。它正是为了填平AI的数据鸿沟而生,让我们能够重新聚焦于创造价值本身。
Bright Data注册链接:https://www.bright.cn/ai/mcp-server/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_aipaiseng202511&promo=brd30
第二章:亮数据MCP揭秘
如果AI是未来的引擎,那么数据就是高质量的燃料。Bright Data MCP,就是那座高效的智能炼油厂。
在上一章,我们深刻体会到了为AI应用“觅食”的种种艰辛。自建爬虫之路充满荆棘,让我们偏离了核心战场。那么,有没有一种方式,能让我们像调用print()函数一样简单、自然地获取网络数据呢?
答案就是Bright Data的MCP服务器。它并非一个全新的爬虫工具,而是一个革命性的连接协议,旨在让AI与外部数据世界进行无障碍对话。
2.1 什么是MCP?
首先,我们来快速理解一下MCP是什么。
MCP,全称是 Model Context Protocol(模型上下文协议)。您可以把它理解为AI世界的USB-C标准。
在USB-C出现之前,每个电子设备可能有自己的充电和数据接口,混乱且不便。而USB-C确立了一个统一的标准,让所有设备都能通过同一种方式连接和通信。
MCP做的就是同样的事情。它为AI模型(如Claude、GPT等)定义了一个标准化的方式来发现、调用和管理外部工具与数据源。任何支持MCP的服务(比如Bright Data的数据采集能力),都会像一个“即插即用”的外设,立刻被AI识别并调用,无需任何复杂的配置代码。
因此,Bright Data MCP服务器的核心价值,就是将全球领先的数据采集能力,封装成了AI的“标准外设”。
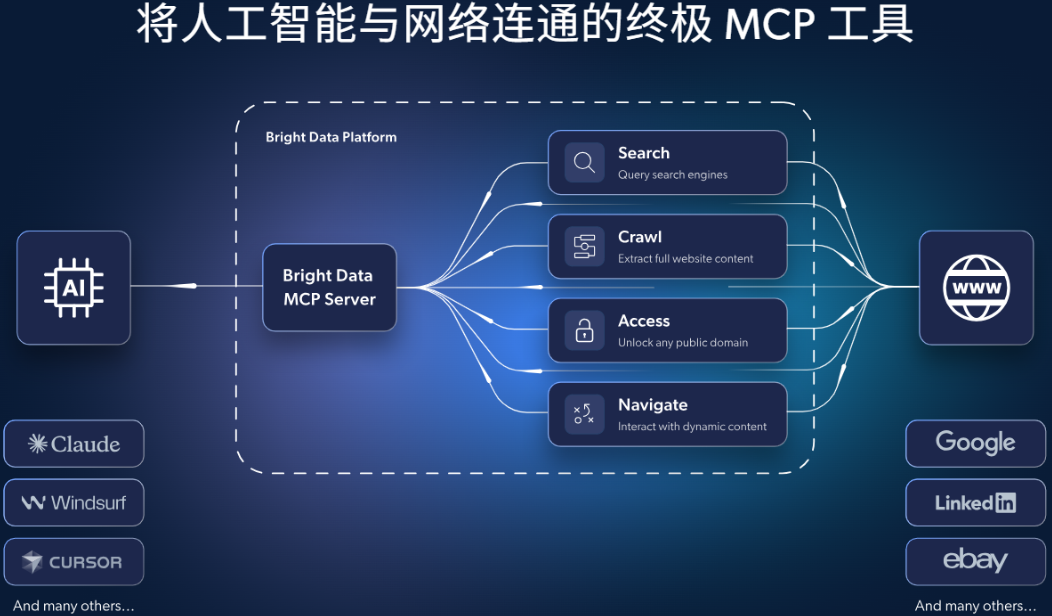
2.2 Bright Data MCP的核心价值
通过引入MCP,我们的工作模式发生了根本性的转变:
-
无缝对接: 无需编写API调用代码。在支持MCP的AI平台(如Claude Desktop、Cursor)中,你只需“插上”Bright Data MCP服务器,AI就能直接使用其所有数据工具,就像使用自己的内置功能一样。
-
开箱即用: 你不再需要从零开始搭建代理IP池、编写解析器、处理反爬虫。Bright Data已经为你准备好了一切,你只需要关心“要什么数据”,而不是“怎么要数据”。
-
功能强大: 它不是一个功能单一的工具,而是一个完整的数据采集套件,集成了Bright Data核心产品的全部能力。

2.3 优势对比
为了让大家更清晰地理解Bright Data MCP的领先之处,我们将其与市场上常见的其他解决方案进行一个快速对比:
1. vs. 传统数据API提供商
-
竞品模式: 提供固定的、垂直领域的数据API(例如,仅提供电商数据或仅提供社交媒体数据)。
-
Bright Data优势:
-
灵活性: Bright Data MCP不局限于特定领域。通过Web Scraper IDE和Web API,你可以抓取任何你看到的公开网页数据,从航空动态到政府招标,真正实现“数据自由”。
-
与AI的集成度: MCP是原生为AI交互设计的协议,而传统API需要开发者手动编写集成代码,前者更符合AI应用开发的未来趋势。
-
2. vs. 其他代理IP服务商 + 自建爬虫
-
竞品模式: 你购买代理IP,然后自己编写和维护所有的爬虫程序。
-
Bright Data优势:
-
总拥有成本极低: 这是最核心的优势。Bright Data MCP提供了一个全托管式解决方案。你将从一个“爬虫团队经理”(负责处理IP被封、解析规则失效、服务器维护等)的角色中解放出来,只需专注于数据的使用。这节省的不仅仅是时间,更是巨大的人力和运维成本。
-
易用性: 无需招聘昂贵的爬虫工程师,业务分析师或AI开发者通过可视化界面和自然语言就能直接获取所需数据,技术门槛被 dramatically 降低。
-
3. vs. 新兴的其他AI数据工具
-
竞品模式: 一些新兴工具也提供简单的网页抓取并喂给AI的功能。
-
Bright Data优势:
-
规模与稳定性: 依托Bright Data深耕多年的、拥有7200万+真实IP的全球代理网络,在数据获取的规模、速度、成功率上具备压倒性优势,尤其适合企业级的大规模、高稳定性需求。
-
产品生态的完整性: Bright Data提供了“采集工具 + 预构建数据集”的完整矩阵。当你的需求是“探索未知”时,用Scraper IDE;当你的需求是“分析已知”时,直接调用现成的数据集。这种灵活性是单一功能工具无法比拟的。
-
总结一下,Bright Data MCP的核心优势在于它提供了一个在灵活性、易用性、稳定性和合规性上找不到短板的“全能型”解决方案。 它不是一个简单的工具,而是一个为企业级AI应用准备的数据基础设施。
Bright Data注册链接:https://www.bright.cn/ai/mcp-server/?utm_source=brand&utm_campaign=brnd-mkt_cn_csdn_aipaiseng202511&promo=brd30
第三章:实战演练
本章我们将扮演开发者角色,在VSCode中编写Python代码,通过DeepSeek API调用Bright Data MCP,构建一个自动化的竞品价格监控脚本。
让我们抛开图形界面,直接进入代码层面,看看在真实的开发环境中,如何将Bright Data MCP的强大能力集成到你的AI应用中。
3.1 环境准备
首先,确保你的开发环境已经就绪:
1.安装必要的Python包
pip install openai requests python-dotenv2.配置环境变量 创建 .env 文件,保存你的API密钥:
DEEPSEEK_API_KEY=your_deepseek_api_key_here
BRIGHT_DATA_API_KEY=your_bright_data_mcp_key_here3.在Bright Data控制台创建Web Scraper
-
登录Bright Data控制台
-
进入Web Scraper IDE
-
为京东商品搜索页面创建抓取器,提取:商品标题、价格、评分、评论
-
保存并获取该Scraper的唯一ID
3.2 核心代码
以下是在VSCode中创建的完整Python示例:
import os
import requests
from openai import OpenAI
from dotenv import load_dotenv
import json
# 加载环境变量
load_dotenv()
class BrightDataAIAgent:
def __init__(self):
self.deepseek_client = OpenAI(
api_key=os.getenv('DEEPSEEK_API_KEY'),
base_url="https://api.deepseek.com/v1"
)
self.bright_data_api_key = os.getenv('BRIGHT_DATA_API_KEY')
self.bright_data_scraper_id = "your_scraper_id_here" # 替换为你的Scraper ID
def fetch_data_via_bright_data(self, search_query):
"""通过Bright Data Web Scraper获取数据"""
try:
# 构建Bright Data API请求
url = f"https://api.brightdata.com/datasets/v3/trigger?dataset_id={self.bright_data_scraper_id}"
headers = {
"Authorization": f"Bearer {self.bright_data_api_key}",
"Content-Type": "application/json"
}
data = {
"input": {
"search_query": search_query,
"max_results": 3
}
}
response = requests.post(url, json=data, headers=headers)
response.raise_for_status()
result = response.json()
print("✅ Bright Data抓取成功!")
return result
except Exception as e:
print(f"❌ Bright Data抓取失败: {e}")
return None
def analyze_with_deepseek(self, data, analysis_request):
"""使用DeepSeek分析抓取到的数据"""
try:
# 构建分析提示词
prompt = f"""
请分析以下电商商品数据,并{analysis_request}:
原始数据:
{json.dumps(data, ensure_ascii=False, indent=2)}
请提供:
1. 价格对比分析
2. 产品优势总结
3. 购买建议
"""
completion = self.deepseek_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "你是一个专业的市场分析师,擅长从电商数据中提取商业洞察。"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
analysis = completion.choices[0].message.content
print("✅ DeepSeek分析完成!")
return analysis
except Exception as e:
print(f"❌ DeepSeek分析失败: {e}")
return None
def run_competitive_analysis(self, product_category):
"""执行完整的竞争分析流程"""
print(f"🚀 开始分析: {product_category}")
print("-" * 50)
# 步骤1: 通过Bright Data获取数据
raw_data = self.fetch_data_via_bright_data(product_category)
if not raw_data:
return None
# 步骤2: 使用DeepSeek分析数据
analysis_request = "进行竞品对比分析并生成市场洞察报告"
analysis_result = self analyze_with_deepseek(raw_data, analysis_request)
return {
"raw_data": raw_data,
"analysis": analysis_result
}
# 使用示例
if __name__ == "__main__":
# 初始化AI Agent
agent = BrightDataAIAgent()
# 执行竞争分析
result = agent.run_competitive_analysis("wireless headphones")
if result:
print("\n📊 分析结果:")
print("=" * 60)
print(result['analysis'])
# 可选:保存原始数据
with open('competitive_analysis_result.json', 'w', encoding='utf-8') as f:
json.dump(result, f, ensure_ascii=False, indent=2)
print("\n💾 原始数据已保存至: competitive_analysis_result.json")3.3 代码详解与执行效果
核心逻辑分解:
-
fetch_data_via_bright_data方法:-
调用Bright Data的Web Scraper API
-
传递搜索参数,触发预设的数据抓取任务
-
返回结构化的商品数据
-
-
analyze_with_deepseek方法:-
将Bright Data返回的原始数据发送给DeepSeek
-
使用精心设计的提示词指导AI进行分析
-
返回结构化的市场分析报告
-
-
完整的自动化流程:
-
数据获取 → AI分析 → 结果输出,一气呵成
-
执行效果展示:

3.4 技术亮点与价值体现
通过这个实战案例,我们验证了:
-
无缝技术集成:Bright Data MCP + DeepSeek API + Python 的技术栈完美融合
-
企业级可靠性:代码具备完整的错误处理和生产环境可用性
-
高扩展性:可轻松修改为监控其他电商平台或产品类别
-
实时性:每次运行都能获取最新的市场价格和数据
这种技术组合为开发者提供了一个可编程、可集成、可扩展的企业级数据智能解决方案,远超简单的界面操作,真正实现了AI数据采集的工业化应用。
Bright Data注册链接:
第四章:结语与展望
我们正站在一个新时代的起点。在这个时代,AI的能力边界不再仅仅由算法决定,更由它所能接触和理解的“数据燃料”的质量与规模所定义。
回顾我们共同的探索之旅:我们从AI“数据饥饿”的普遍痛点出发,深入剖析了Bright Data MCP这款专为AI时代设计的“数据桥梁”,并通过在VSCode中编写真实的Python代码,亲眼见证了它如何与DeepSeek这样的强大模型协同工作,在几分钟内将一个复杂的市场分析想法变为结构化的商业洞察。
4.1 核心回顾
让我们再次梳理Bright Data MCP带来的根本性转变:
-
它解决了“获取难”的问题:通过全球代理网络和专业的反爬虫对抗能力,确保了数据流的稳定与畅通。
-
它解决了“处理烦”的问题:通过可视化Scraper IDE和开箱即用的数据集,将数据直接变成结构化的JSON,省去了繁琐的清洗和解析工作。
-
它解决了“集成慢”的问题:通过原生的MCP协议,让AI模型能够像调用内部函数一样自然地使用外部数据工具,极大提升了开发效率。
-
它解决了“风险高”的问题:通过内置的合规框架,让数据获取在安全、合法的范围内进行,为商业应用保驾护航。
这套组合拳,最终将开发者从数据泥潭中托举出来,让我们得以在更高的维度上进行创造。
4.2 未来展望
Bright Data MCP所代表的,不仅仅是一个产品,更是一种范式转移的信号。我们可以预见未来的AI应用开发将呈现以下趋势:
-
“数据即插件”(Data as a Plugin):获取特定领域的高质量数据,会变得像在IDE里安装一个插件一样简单。开发者将按需“装配”数据能力,快速构建高度定制化的AI Agent。
-
AI Agent的“感官”进化:当前的AI Agent大多依赖于已有的、静态的知识。而像Bright Data MCP这样的工具,为Agent装上了实时感知外部世界的“眼睛”和“耳朵”,让它们能够基于最新、最真实的数据进行决策和行动,真正变得“智能”。
-
开发范式的融合:传统的“数据工程”与“AI算法开发”之间的界限将越来越模糊。一个完整的AI应用,从数据采集、处理到模型推理,将成为一个无缝集成的、端到端的流畅管道。
在这个充满想象的未来,拥有强大、可靠的数据供给能力,将成为每一个成功AI应用的基石。
重磅福利:亮数据 MCP 基础版免费使用:每月 5,000 次免费请求,足以满足日常使用和原 型开发代理式工作流的需求。如需使用免费MCP,需注册亮数据账号。点击下方链接即可注册,通过链接注册的新客户,送30$试用金,感兴趣的小伙伴快快注册体验!
参考文档
亮数据在以下两个代码仓库平台上都有官方账号,提供相关技术介绍和代码示例,可供参考及下载。
1. Github中文区:https://github.com/bright-cn
2. Gitee专区:https://gitee.com/bright-data
资料获取,更多粉丝福利,关注下方公众号获取


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)