Elastic Observability:Streams 数据质量与故障存储洞察
Elastic Observability推出Streams数据质量功能,通过AI驱动帮助用户监控和管理数据质量。该功能可识别三类问题文档:Degraded(字段被忽略)、Failed(被拒绝)和综合质量评分,并提供可视化图表跟踪问题趋势。用户可设置警报规则、查看问题字段详情,并利用failurestore存储被拒文档以便修复。技术实现基于ES|QL查询计算文档质量比例,并通过阈值自动评估数据状态
作者:来自 Elastic Elena Stoeva 及 Yngrid Coello

了解 Streams —— Elastic Observability 的一项新的 AI 驱动功能 —— 如何通过故障存储管理数据质量,帮助你监控、排查问题并保留高质量数据。
在处理 observability 和日志数据时,并非所有文档都能以完整状态进入 Elasticsearch。有些可能因 ingest pipeline 的处理失败或映射错误而被丢弃,而另一些可能因字段值与定义的映射不兼容而部分被摄取,某些字段被忽略。这些问题会影响下游分析和仪表板。Streams 数据质量让你比以往更容易监控摄取数据的健康状况、识别潜在问题,并直接在 UI 上采取纠正措施。通过数据质量,你现在可以清楚地看到 Stream 的表现如何,并快速了解你的数据质量是 Good、Degraded 还是 Poor。
数据质量有哪些?
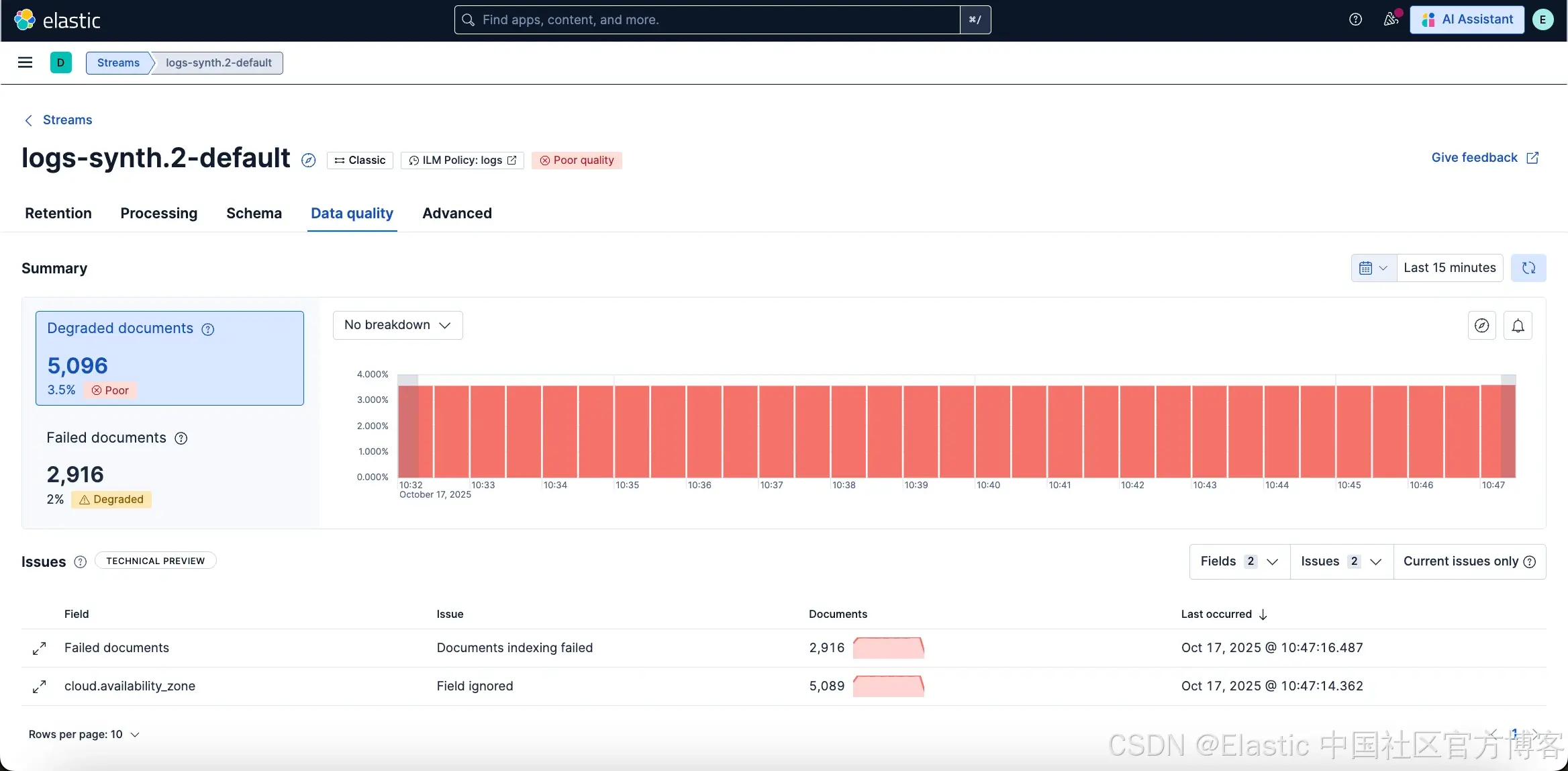
一览摘要
摘要卡显示:
-
Degraded 文档 ——包含 _ignored 字段的文档 —— 更多信息请查看此处。
-
Failed 文档 —— 因映射冲突或 pipeline 失败而在摄取时被拒绝的文档。
综合质量评分(Good、Degraded、Poor)会根据 Degraded 和 Failed 文档的比例自动计算。
随时间变化的趋势
该标签页包含时间序列图表,可跟踪随时间累积的 Degraded 和 Failed 文档。使用日期选择器缩放到特定范围,了解问题高峰期。
质量问题表
详细表格列出影响你的 Stream 的问题类型。对于每个问题,你可以:
-
查看哪些字段导致了问题。
-
查看受影响文档的数量。
-
仅筛选尚未解决的问题(仅当前问题)。
-
打开浮出窗口深入分析问题原因并了解如何修复。
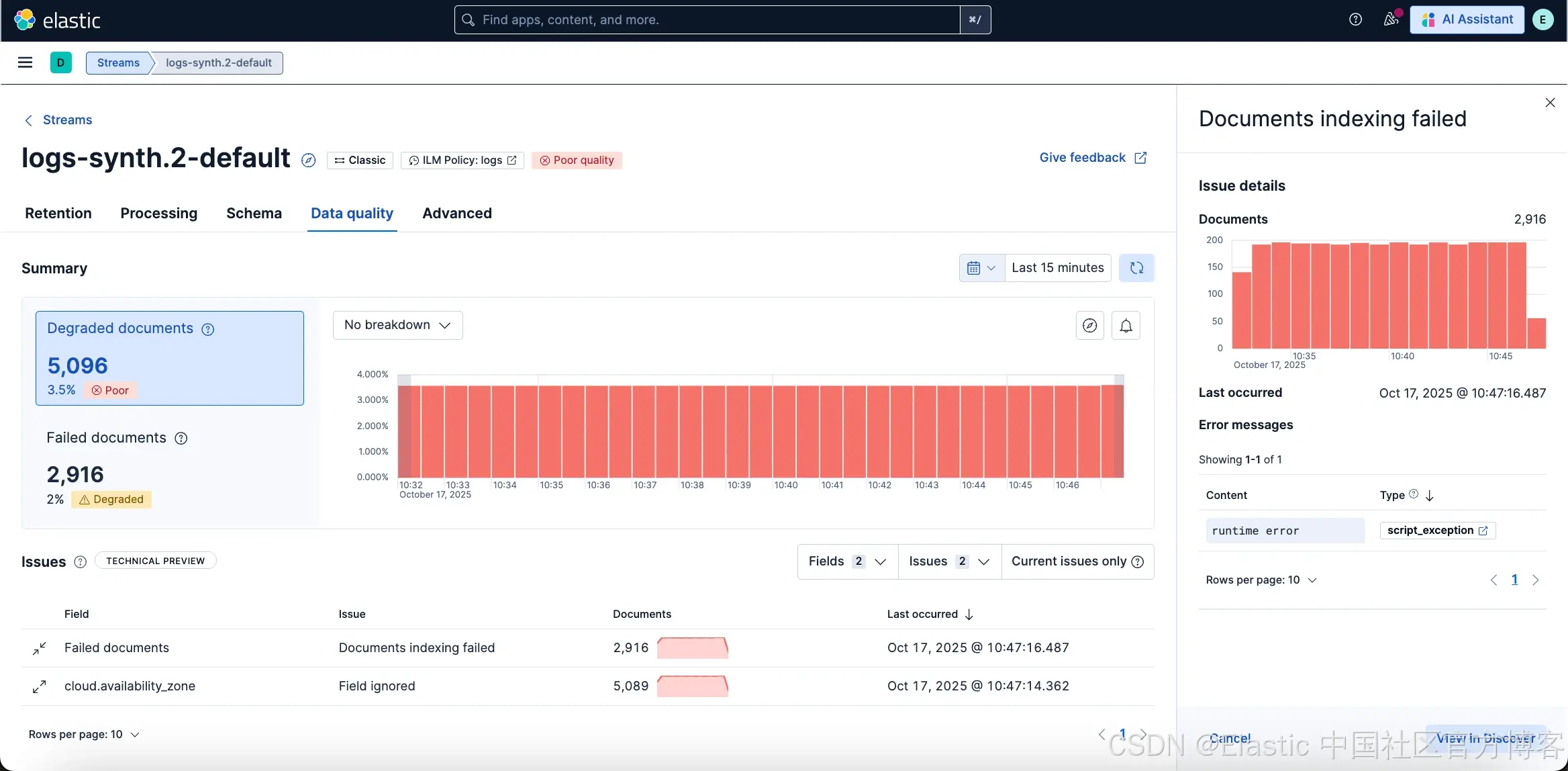
监控 Degraded 文档
Degraded 文档是包含 _ignored 字段的文档,这意味着其一个或多个字段在索引过程中被忽略。原因之一可能是字段值与预期映射不匹配。虽然文档的其余部分仍被索引,但大量 Degraded 文档可能影响查询结果、仪表板和整体 observability 的准确性。
为了帮助控制这些问题,Data quality 标签页提供了 Stream 中 Degraded 文档比例的可视化。
设置规则以提前应对问题
你可以使用 Degraded docs 图表上方的 Create rule 按钮定义警报,当 Degraded 文档比例超过某个阈值时通知你。这使你能够主动监控映射不匹配问题,并确保数据持续符合质量预期。
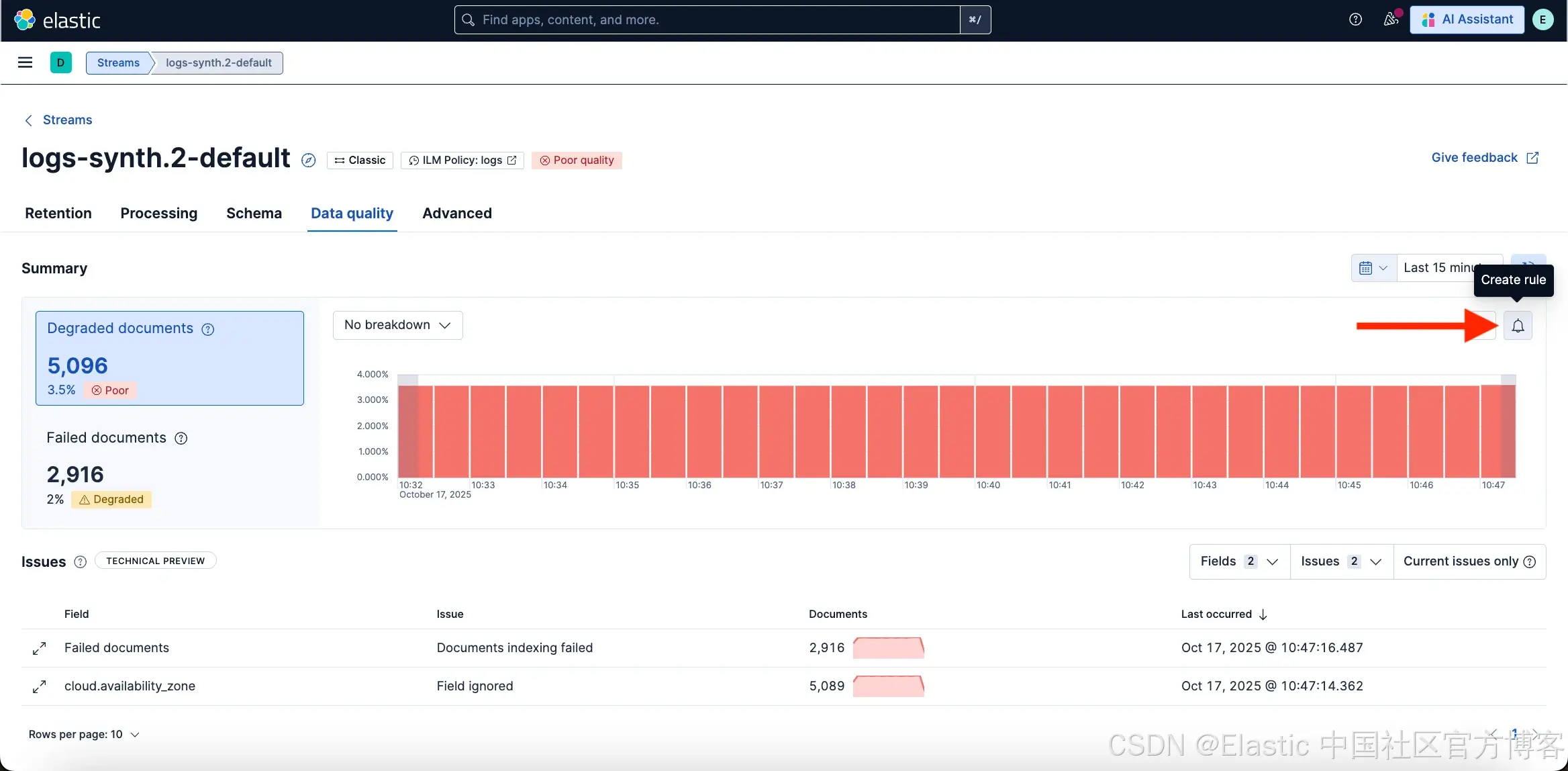
有关如何配置此规则的更多信息,请参见 Degraded docs rule conditions。
使用 failure store 处理 Failed 文档
Failure store 是一个特殊索引,用于捕获在摄取过程中被拒绝的文档。failure store 会将这些数据保存在专用的 ::failures 索引中,而不是丢失它,使你能够检查有问题的文档、了解问题原因并修复潜在问题。
在 Data Quality 标签页中,只有在 Stream 启用了 failure store 时,Failed 文档才可见。要检查 failure store 文档,你需要至少具备 read_failure_store 权限。如果未启用 failure store,你会看到一个 “Enable failure store” 链接,点击会打开配置弹窗并设置保留期限。启用 failure store 需要你对特定数据流具备 manage_failure_store 权限。有关 failure store 安全性的更多信息,请参见 Searching failures。
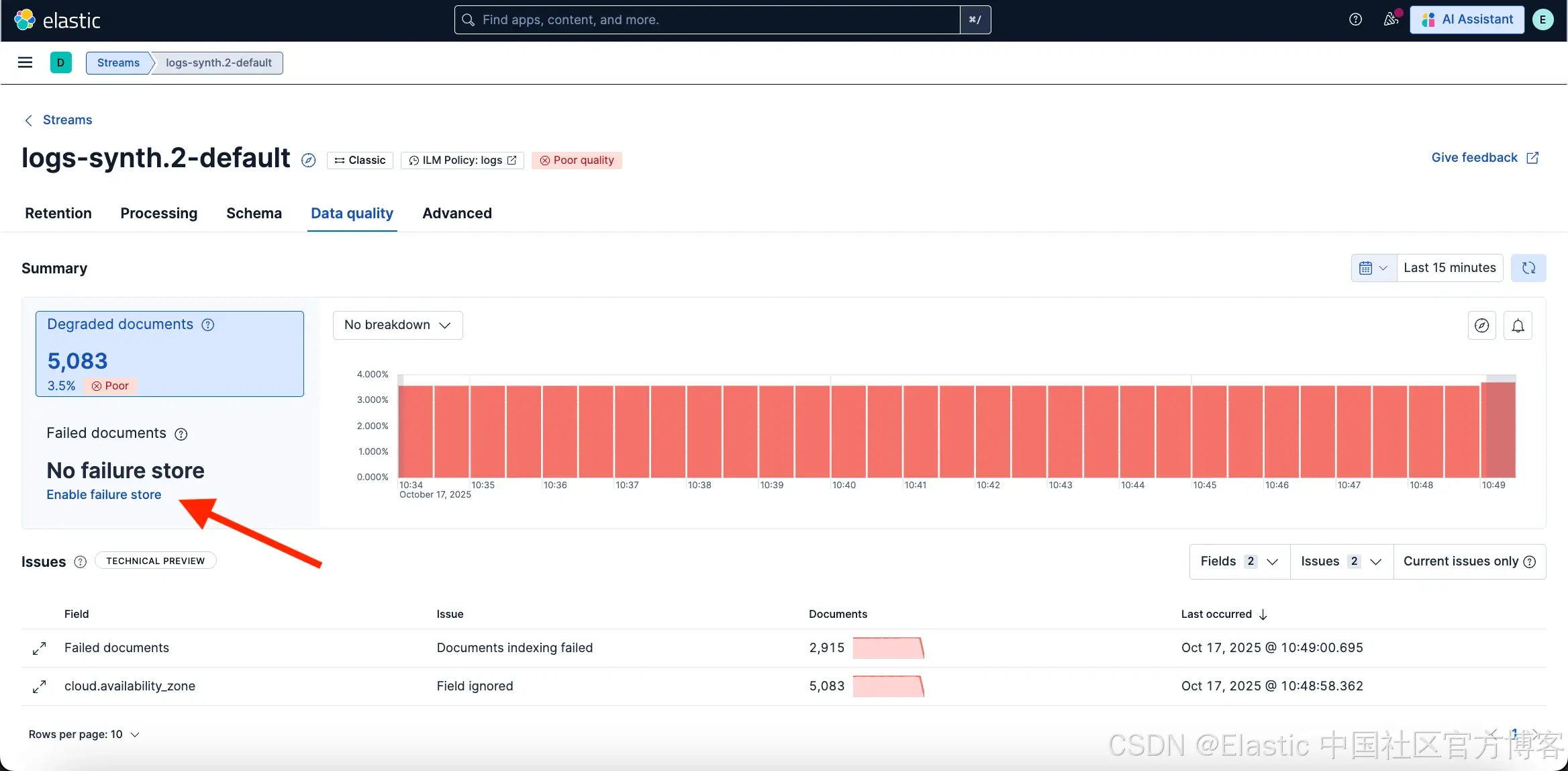
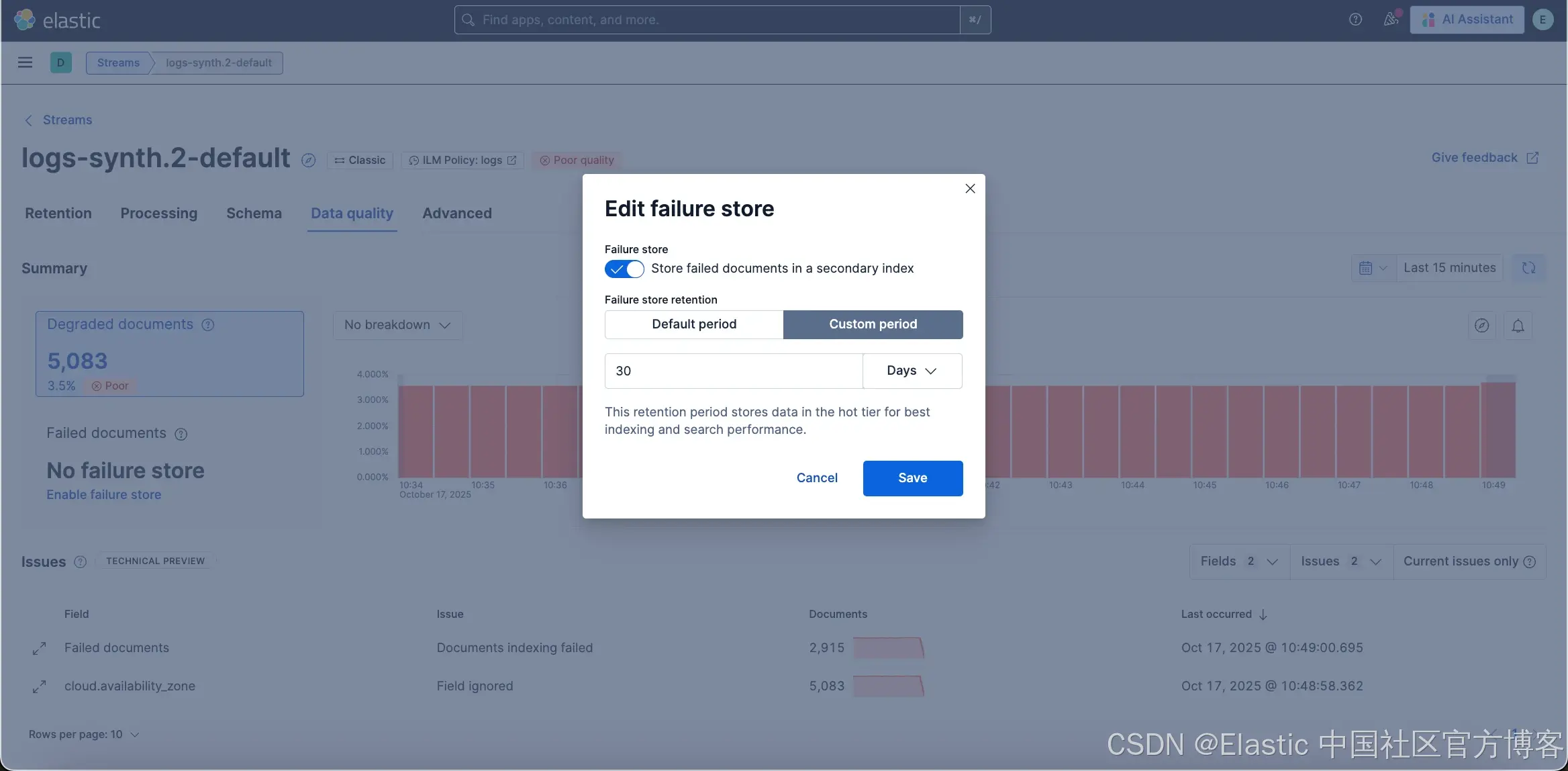
启用后,你可以随时使用 Failed docs 图表上方的 Edit 按钮编辑 failure store 配置或将其禁用。
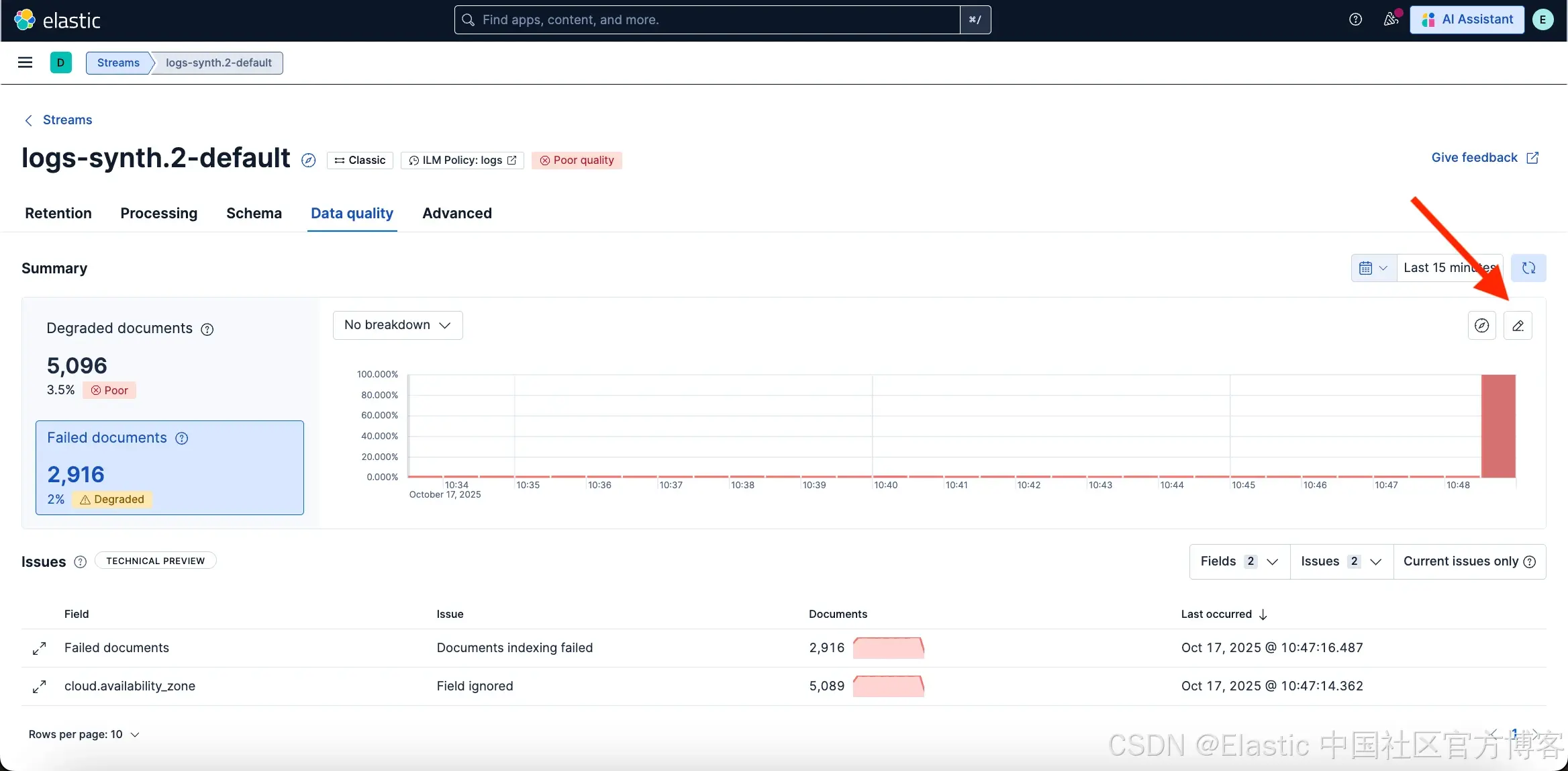
failure store 也可以在 Streams Retention 标签页中配置 —— 更多信息请参见本文。
技术实现
在底层,Data quality 标签页基于现有的 Dataset quality 插件构建 —— 同样是为 Stack Management 中的 Dataset quality 页面提供支持的插件。不过,它现在专为 Streams 定制,而不是按照 Data stream 命名方案处理 datasets。
为了确定一个 Stream 的质量,UI 会发送三个 ES|QL 查询服务器请求:
1)所有文档(包括 Failed 文档):
FROM myStream, myStream::failures | STATS doc_count = COUNT(*)
2)仅 Failed 文档:
FROM myStream::failures | STATS failed_doc_count = COUNT(*)
3)Degraded 文档:
FROM myStream METADATA _ignored | WHERE _ignored IS NOT NULL | STATS degraded_doc_count = COUNT(*)
这些查询的结果随后用于计算 Failed 和 Degraded 文档的比例。整体数据质量通过简单的阈值确定:
-
Good:两个比例均为 0%
-
Degraded:任一比例大于 0% 且小于 3%
-
Poor:任一比例超过 3%
在管理 failure store 时,Streams 使用 Update data stream options API 的 failure_store 参数来配置和更新 failure store 设置,包括启用该存储和设置保留期。
为什么你会喜欢它
新的 Data quality 标签页提供了:
-
无需翻日志即可了解摄取问题
-
清晰区分 Degraded 文档与 Failed 文档
-
洞察哪些字段被忽略以及原因
-
使用 failure store 捕获和排查 Failed 文档的工具
通过在 Streams UI 中直接呈现数据质量问题,我们让保持数据可靠流动更容易,并确保你的分析建立在坚实基础上。
今天就试用
Data quality 功能已在 Elastic Observability 的 Serverless 上提供,并将在不久后为自托管和 Elastic Cloud 用户推出。
在 cloud.elastic.co 注册 Elastic 试用,并体验 Elastic 的 Serverless 服务,享受所有 Streams 功能。
关于 Streams 的更多信息:
-
浏览 Streams 网站
-
阅读 Streams 文档
原文:https://www.elastic.co/observability-labs/blog/data-quality-and-failure-store-in-streams

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)