从零到可落地的企业级 RAG:拆解微软 Kernel Memory 的架构心法
微软开源项目KernelMemory解决了RAG系统常见的文档处理难题。针对"直接丢文档给大模型"的痛点,它提供了可扩展的记忆管理系统,通过标准化数据摄取、索引和检索流程,解决了文档处理慢、权限管理混乱、多模态支持不足等问题。项目采用分层架构,支持多种部署方式,核心是通过可编排的流水线将文档转化为可问答的记忆。典型应用场景包括企业知识库、文档分析等,其设计亮点在于将"
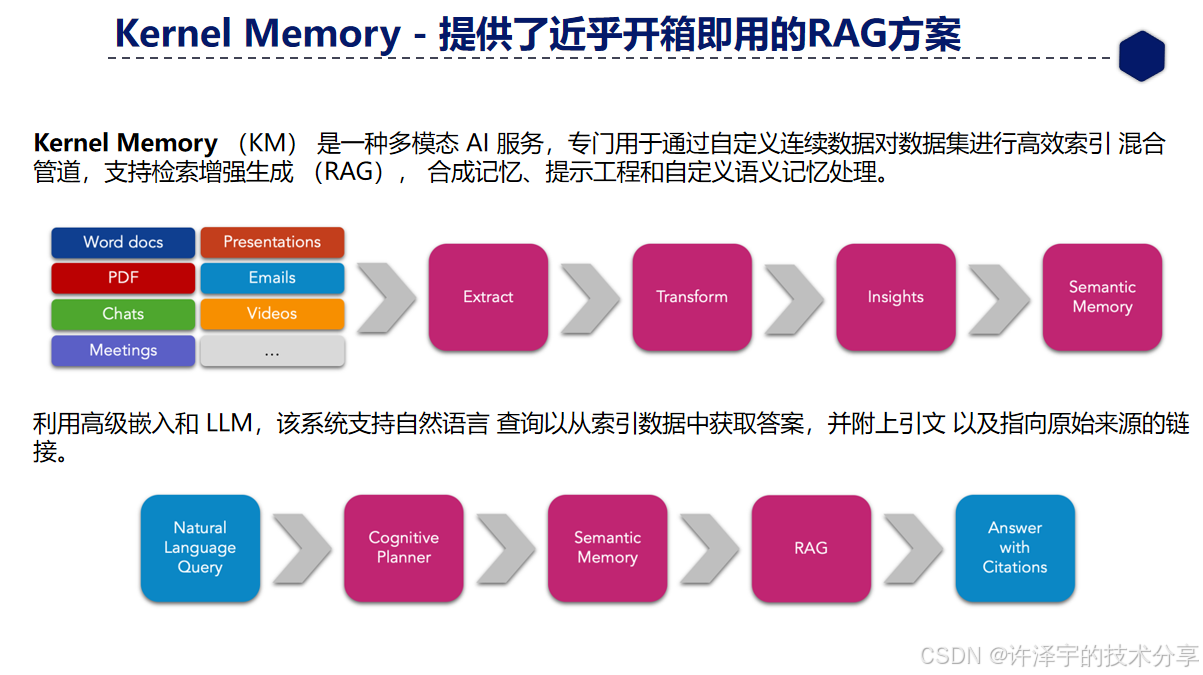
这篇文章试图回答两个问题:
为什么“直接丢文档给大模型”常常翻车?
微软开源项目 Kernel Memory 究竟解决了哪些“记忆与检索”的硬伤?
如果你已经在做 RAG、知识库问答、企业 Copilot 之类的项目,相信你多少有点相同的体验——
-
刚开始时,一腔热血:
“有向量数据库 + Embedding + ChatCompletion,不就完事了?” - 过一段时间:
-
文档一多,索引慢得像蜗牛在搬砖;
-
数据权限一上,安全逻辑到处散落;
-
模型账单一出来,老板看你眼神都变了。
-
于是你开始怀疑人生:是不是人人都在说的“RAG”,其实只是“人人都在自己造一遍轮子”?
这时候,就轮到今天的主角登场了:Kernel Memory(KM)。
Kernel Memory 是微软开源的一套 多模态 AI Memory 服务,专注做一件事:
用一套可扩展、可编排、可插拔的“记忆系统”,帮你的 AI 应用稳稳地管好数据、建好索引、做对检索。
它既不是一个“又一个向量数据库”,也不是一个“一键搞定所有场景”的黑盒,而是介于 SDK 与基础设施 之间的“中间层”:
-
向下封装各种 LLM / Embedding / 向量库 / 文件存储;
-
向上暴露统一的 Web Service API 和
.NET组件; -
围绕“Memory”抽象,搭好了一整套 数据摄取(Ingestion)+ 索引(Indexing)+ 检索(Retrieval)+ RAG 的骨架。
下面我们就从项目背景、整体架构、核心实现思路、典型应用场景和未来趋势几个角度,系统拆解一下这个项目到底值不值得你在下一个 AI 应用里用上它。
一、项目背景:为什么需要一个“Memory”服务?
先抛开 Kernel Memory 本身,回到最朴素的问题:
“我已经有大模型 API 了,为什么还需要一个额外的 Memory 系统?”
直说了,大模型是大脑,不是记忆宫殿。它短期记忆很强(上下文窗口),但长期记忆和数据治理这块,天生是短板:
- 上下文窗口有限:
-
你不可能每次提问都把 10 万行文档全塞进去;
-
塞多了不仅贵,还容易让模型“注意力涣散”,反而答偏。
-
- 数据更新与重索引麻烦:
-
文件改动、版本更新、权限变化,都需要重新处理;
-
如果没有统一的流水线,很快就变成“谁都不敢动”的黑盒。
-
- 安全与权限碎片化:
-
权限往往散落在各个服务里,逻辑重复、难以审计;
-
一不小心就来一波“知识泄露 live demo”。
-
- 多模态、多来源的复杂性:
-
真实项目不会只处理 txt 和 markdown;
-
PDF、Word、PPT、网页、图片、甚至外部 API 返回的数据,都要进来。
-
这些问题本身并不新鲜,只要你自己撸过一个稍微复杂点的 RAG 系统,就会很自然地造出一堆类似的东西:
-
文本提取脚本
-
分块与清洗模块
-
Embedding 计算与入库逻辑
-
查询与重排逻辑
-
权限过滤
-
异步任务队列、重试机制、失败告警
听起来像不像一个完整的 “小型 Memory 领域子系统”?
Kernel Memory 要做的,就是把这套“大家都在暗处重复造的轮子”,
拉到明面上,规范化,组件化,云就绪化。
用一句更工程味的话概括:
KM 是围绕“记忆(Memory)”这一概念,整合数据摄取、索引、向量检索、RAG 模板、安全过滤的 参考实现 + 可运行服务。
它既能以 Web Service 形态对外提供服务,也能作为 .NET 组件“无服务(serverless)嵌入”你的应用内部; 还支持通过插件和扩展点接入不同的向量库、存储、LLM 服务。
下面我们正式开拆它的技术架构。
二、总体技术架构:从“文件”到“可被问答的记忆”
从 README 和项目结构可以看出,Kernel Memory 主要分成几层:
- 调用层(Clients & APIs)
-
.NET WebClient(Microsoft.KernelMemory.WebClient) -
.NETServerless 组件(Microsoft.KernelMemory) -
OpenAPI Web Service(任意语言可用)
-
- 服务层(Service)
-
提供
/upload、/ask等 HTTP 接口 -
内部驱动数据摄取流水线、文件存储、向量索引
-
- 流水线层(Pipelines / Orchestrator)
-
提取(Extract)、分块(Chunk)、向量化(Vectorize)、存储(Store)等步骤
-
支持自定义 Handler 与步骤编排
-
- 扩展层(Extensions)
-
LLM & Embedding:OpenAI、Azure OpenAI、Ollama、本地模型等
-
向量库:Azure AI Search、Qdrant、Postgres、SQL Server、Redis 等
-
文件存储:本地磁盘、Azure Blob、S3、MongoDB Atlas 等
-
队列系统:Azure Queue、RabbitMQ 等
-
官方 README 给了一张非常关键的图:
-
“Kernel Memory Lambda Architecture”
可以理解为一个 RAG 系统的“流水线 + 服务”整体蓝图:
- 批处理/离线路径:
-
文档通过上传 / 定时任务 / 外部系统导入
-
进入 KM 的数据摄取流水线,完成提取、分块、向量化、入库
-
- 在线查询路径:
-
用户通过
/ask或客户端 SDK 提问 -
KM 根据问题在索引中检索相关分块
-
组装上下文 + 提示词(Prompt),调用 LLM 生成答案
-
自动带上引用、数据血缘(lineage)、token 使用报告等信息
-
换句话说,你的应用并不需要知道“文档是如何一步步被拆解、向量化的”,
你只需要相信:只要把文档“喂”给 Kernel Memory,它就会负责记住;而当你问问题时,它会找到合适的记忆给大模型看。
2.1 部署形态:Service / Docker / Azure / Aspire
Kernel Memory 非常强调 部署灵活性:
- 你可以:
-
直接
docker run kernelmemory/service本地起服务; -
部署到 Azure,作为独立的 Memory 后端;
-
在
.NET Aspire应用中一键拉起 KM 容器并做依赖编排; -
甚至把它作为插件挂到 Semantic Kernel、Microsoft Copilot、ChatGPT 里。
-
从架构角度看,KM 把自己定位成:
“一个对外暴露 OpenAPI 的 Memory Backend”。
这意味着:
-
你不一定非得跟着它的示例用
.NET; -
完全可以在 TypeScript、Java、Python 等任意语言里,按普通 Web API 来消费。
这也是它和单纯的 .NET SDK 的最大区别之一:KM 是一个服务,不只是一堆类库。
三、核心实现思路:一条“可编排的记忆流水线”
讲完了整体视角,我们往下多看半层——它到底是如何把一个文档变成“可问答的记忆”的?
Kernel Memory 默认的数据摄取管线,大致可以拆成这样几步:
-
自动识别文件类型并提取文本(Extract)
-
将长文本按策略切成合适的“分块”(Chunk)
-
对每个分块生成向量(Vectorize)
-
将原文与向量写入底层存储 / 向量库(Store)
-
关联上各种 Tag / Metadata(如用户、业务线、年份等)
README 里给了非常直观的 C# 用法:
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY"))
.Build<MemoryServerless>();
// 导入一个文件
await memory.ImportDocumentAsync("meeting-transcript.docx");
// 导入文件并绑定业务标签
await memory.ImportDocumentAsync("business-plan.docx",
new Document("doc01")
.AddTag("collection", "business")
.AddTag("collection", "plans")
.AddTag("fiscalYear", "2025"));
你会发现:
-
调用侧非常“佛系”:只管给文档、给标签;
-
管线细节全部被隐藏在
KernelMemoryBuilder和MemoryServerless之下。
3.1 Orchestrator 与 Handler:把复杂度“锁”在流水线里
真正有意思的是 自定义流水线 这一块。
仓库示例里有自定义 Handler 的写法:
// 关闭默认处理器,只保留我们想要的
var memoryBuilder = new KernelMemoryBuilder()
.WithoutDefaultHandlers()
.WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY"));
var memory = memoryBuilder.Build();
// 注册自定义处理步骤
memory.Orchestrator.AddHandler<MyHandler1>("step1");
memory.Orchestrator.AddHandler<MyHandler2>("step2");
memory.Orchestrator.AddHandler<MyHandler3>("step3");
// 指定自定义步骤执行顺序
await memory.ImportDocumentAsync(
new Document("mytest001")
.AddFile("file1.docx")
.AddFile("file2.pdf"),
steps: new[] { "step1", "step2", "step3" });
这段代码背后藏着 KM 的一条“暗线”设计理念:
所有“脏活累活”尽量塞进流水线 Handler 里,调用层只看到一个干干净净的
ImportDocumentAsync。
这带来几个非常现实的工程收益:
- 逻辑集中:
-
提取、清洗、重排、分块、向量化等,都在统一的 Orchestrator 里编排;
-
出了问题,优先看流水线;
-
想加步骤,只需新增 Handler,而不是改一堆调用端代码。
-
- 可插拔与多语言:
-
Handler 本身可以是 HTTP 调用,也可以是脚本、容器微服务;
-
非 .NET 团队可以用自己熟悉的语言写“某一个步骤”,再接入整个 KM 管线。
-
- 易于演进:
-
你今天只做“提取 + 纯向量检索”;
-
明天想加“标题抽取”、“章节层级识别”、“敏感信息脱敏”,都可以逐步叠加。
-
简单来说:
KM 把“记忆处理”看成一条 有状态的流水线,而不是一坨写死的脚本。
3.2 检索与 RAG:AskAsync 的“冰山下半截”
在查询侧,AskAsync 是最常用的入口:
var answer1 = await memory.AskAsync("How many people attended the meeting?");
var answer2 = await memory.AskAsync(
"what's the project timeline?",
filter: MemoryFilters.ByTag("user", "devis@contoso.com"));
从调用上看很简单:提问 + 可选过滤条件。
但在 KM 内部,大致会经历这样几步:
-
将自然语言问题转成向量(使用同一套 Embedding 模型);
-
在向量库中按相似度检索相关分块;
-
应用 Tag / 用户过滤等安全策略;
- 组装成 Prompt,包括:
-
问题本身
-
若干检索到的分块内容
-
RAG 模板(例如告诉模型必须引用来源、不得瞎编等)
-
-
调用 Text Generation 模型生成答案;
-
生成 引用信息(RelevantSources)、token 使用报告 等元数据。
其中几个特别值得工程师关注的小点:
- 分块上下文扩展:
-
README 里还有“扩展相邻分块”的例子(
examples/207-dotnet-expanding-chunks-on-retrieval), -
说明 KM 支持在检索时把“前后邻居分块”也拉进上下文,
-
避免“只看中间几句,误解整段语义”的情况。
-
- 数据血缘(Data Lineage)与引用:
-
返回结果中包含
RelevantSources,可以追溯到原始文件名、更新时间、分块内容; -
这对企业内审、可信度展示至关重要。
-
- Token 使用统计:
-
内置 token 报表,有助于做成本监控与调优;
-
比你事后通过日志瞎算靠谱多了。
-
换句话说:
AskAsync看着只是“问个问题”,其实在 KM 背后已经帮你跑了一整套 RAG 工作流。
四、使用方式:从“快速试水”到“深度集成”的几条路径
一个好的框架,既要“上手不难”,也要“用深了不憋屈”。
从 Kernel Memory 的示例和文档看,大致有几条典型的落地路径:
4.1 用 Docker 一键起一个本地 Memory 服务
如果你只是想快速体验 RAG + Memory 服务,用 Docker 是最丝滑的方式:
docker run -e OPENAI_API_KEY="..." -it --rm -p 9001:9001 kernelmemory/service
启动完之后,你就拥有了:
-
一个跑在本地
http://127.0.0.1:9001的 Memory 服务; -
带 OpenAPI Swagger 文档;
-
能接收
/upload、/ask等 HTTP 请求。
Python 示例里演示了如何上传文档:
import requests
files = {
"file1": ("business-plan.docx", open("business-plan.docx", "rb")),
}
data = {
"documentId": "doc01",
"tags": [
"user:devis@contoso.com",
"collection:business",
"collection:plans",
"fiscalYear:2025",
],
}
resp = requests.post("http://127.0.0.1:9001/upload", files=files, data=data)
然后再发一个 /ask 请求就能问问题。对大多数“想先玩一玩”的开发者来说,这已经足够搭一个 demo 甚至 PoC。
4.2 在 .NET 项目中以 Serverless 组件嵌入
如果你主要用 .NET,可以直接把 KM 当成一个 本地组件:
var memory = new KernelMemoryBuilder()
.WithOpenAIDefaults(Environment.GetEnvironmentVariable("OPENAI_API_KEY"))
.Build<MemoryServerless>();
await memory.ImportDocumentAsync("meeting-transcript.docx");
var answer = await memory.AskAsync("How many people attended the meeting?");
Console.WriteLine(answer.Result);
这种模式下:
-
你不需要额外跑一个 Web Service;
-
一切运行在你的进程内;
-
适合控制台工具、小型内部服务、桌面应用等。
当然,代价也很明显:
-
文档摄取是同步的,会阻塞当前进程;
-
不适合长耗时、大体量场景;
-
异步与弹性更多要靠你自己在外面搭配任务队列与调度。
4.3 部署到 Azure,做成企业级 Memory 后端
当你需要:
-
多语言客户端;
-
云上高可用与扩展性;
-
与 Azure AI Search / Blob / Cosmos 等服务深度集成;
时,就可以考虑把 KM 部署成一个标准的 后端服务。仓库里提供了:
-
Azure 部署文档(
docs/azure.md与infra/目录); -
一键部署按钮;
-
与 .NET Aspire 的集成示例。
这时,你可以把 KM 当成:
“公司内部所有 AI 应用共同使用的 统一 Memory 层”。
每个业务系统不再各自造轮子,而是:
-
把数据同步到 Kernel Memory;
-
对接统一的
/upload、/ask、/search接口; -
通过 Tag 和索引隔离不同系统的数据域与权限。
4.4 与 Semantic Kernel / Copilot / ChatGPT 等集成
KM 还提供了:
Microsoft.KernelMemory.SemanticKernelPlugin:-
可以直接作为 Semantic Kernel 的 Memory 插件;
-
替换原生的 Semantic Memory 能力;
-
让 SK 调用 KM 完成 RAG 与记忆管理。
-
这就像在你的 Agent / Planner 背后,
悄悄挂上了一个“企业级记忆中枢”。
五、典型应用场景:它最适合解决哪些“痛点项目”?
既然讲的是工程实战,不如直接对号入座,看一看哪些场景特别适合用 Kernel Memory。
5.1 企业知识库问答 / Copilot for X
这是最典型的场景:
-
内部大量 Word/PPT/PDF 文档;
-
希望员工能用自然语言问问题;
-
又要考虑权限、合规、敏感信息脱敏等。
在这种场景下,KM 的优势非常明显:
-
内置多种文档解码器:PDF、Word、PPT、网页等;
-
可伸缩的文档摄取流水线;
-
丰富的扩展点可以挂接内容安全服务(如 Azure AI Content Safety);
-
统一管理索引与 Tag,便于做业务线/部门级隔离。
你可以很自然地把它设计成:
-
一个“知识库后端 + RAG 中枢”,
- 上层再挂一个核心 Copilot 应用:
-
Web Portal
-
Teams Bot
-
Outlook 插件
-
内部工单系统助手等。
-
5.2 文档总结、合规检查、风控审阅
KM 不只支持“问答”,还支持 合成记忆(synthetic memories):
-
你可以让它先对原始文档做一轮 summary / 结构化提取;
-
把结果作为新的“记忆对象”再写回索引;
-
之后再基于这些更结构化的“二级记忆”做推理与检索。
比如:
-
合同条款抽取;
-
投诉邮件分类与风险打分;
-
财报中的关键指标提取。
KM 的流水线模式非常适合在这类场景里:
-
给某一批文档跑 “提取 + 总结 + 打标签 + 风险分级” 多步处理; -, 每一步都可以挂自定义模型或外部服务。
5.3 多源数据融合:从 Discord、Web、API 到统一记忆
从 examples 可以看到:
-
有 Discord 数据抓取 示例;
-
有 自定义 Web Scraper 示例;
-
也有“自定义 Handler As A Service”的案例。
这意味着你可以做这样的事情:
-
写一个 Handler 去抓 GitHub Issues;
-
再写一个 Handler 去抓公司内部 Wiki;
-
再写一个 Handler 去读某个业务系统的 HTTP API;
-
全部输送到同一套 Kernel Memory。
最后,对于上层应用来说,它见到的永远是一个“统一的 Memory 接口”:
问:最近一周用户在社区里对新功能的主要吐槽点是什么?
—> Kernel Memory 背后在 Discord / GitHub / 工单系统等多源数据里做统一检索
你不需要在上层应用手动聚合这些异构数据源,而是把这部分工作下沉给 KM 的流水线和扩展点。
5.4 AI 助手的“长期记忆模块”
很多人做聊天机器人、个人助手的时候,都会碰到一个问题:
“我希望助手记住用户的偏好 / 历史对话,但又不想无限堆上下文。”
KM 本身虽然更偏“文档级记忆”,但完全可以:
-
把对话内容以某种结构写入 Kernel Memory;
-
每次会话开始时,根据用户 ID / 主题检索历史“记忆”;
-
把这些记忆拼进 Prompt;
-
或者生成更加抽象的用户画像与偏好标签,写回 KM。
这样,你的 Agent 不需要自己再造一个“记忆模块”,而是
像调用一个“记忆数据库”一样调用 Kernel Memory。
六、技术亮点与设计哲学:Kernel Memory 值得借鉴的地方
即便你最后没有直接用 KM,这个项目本身的 架构思路 也很值得借鉴。
6.1 把“Memory”当成一等公民
KM 的最大特点之一是:
它不是从“对话”出发,而是从“记忆”出发设计系统。
很多 demo 式的 AI 应用,都是先有一个 Chat 界面,再想:
“要不接个向量库,让它能记点东西?”
而 Kernel Memory 是反过来的:
- 先想清楚:什么是 Memory?
-
它有 Document、Partition、Tag、Source、Lineage 等结构;
-
-
再围绕 Memory 构建摄取、索引、查询 API;
-
对话和 Agent 只是“站在记忆之上”的一层消费者。
这种视角转变,会让你在做架构决策时更关注:
-
数据如何进入系统(Ingestion);
-
如何被组织和治理(Schema & Governance);
-
如何被安全地取出和组合(Retrieval & RAG)。
6.2 把“脏逻辑”放到流水线里,而不是塞进 Controller / Service
KM 用 Orchestrator + Handler 的方式,把复杂度锁定在 流水线层。
对比很多业务项目里的常见写法:
-
一堆 if-else 分布在 Controller / Service / Repository 之间;
-
文档处理逻辑散落在各个微服务里;
-
一旦需求改动,就得大规模修改调用链。
而 KM 把这类逻辑封装成一个个独立 Handler,
-
让 Controller 只做“收参数 + 丢进队列”;
-
让主业务服务只关心“调一次 Import / Ask 就能搞定”。
这种方式,特别适合那种:
-
需要频繁调整、试验不同步骤组合的 AI 流水线;
-
或者需要让不同团队在同一条管线上插入自己逻辑的场景。
6.3 强调“服务化 +多语言友好”
很多 AI 框架天然绑定在某一种语言上(比如某 Python 框架只为 Python 而生)。
而 KM 一上来就选择以:
-
Web Service + OpenAPI 作为核心对外能力;
-
再在
.NET里提供第一方客户端和 Serverless 组件; -
其他语言通过 HTTP 调用毫无障碍地接入。
这种策略有两个直接好处:
-
公司内其他技术栈团队也能无缝用;
-
即便未来你换了主要开发语言,Memory 层也可以保持不动。
6.4 尊重“工程现实”:监控、扩展、可配置
从 README 和 examples 里可以看到,KM 很在意一些“看起来不酷,但很重要”的工程细节:
-
appsettings.json / 环境变量配置;
-
与 Azure、Docker、Aspire 的集成示例;
-
针对不同后端(Qdrant、Elasticsearch、Redis 等)的脚本工具;
-
Token 使用统计、数据血缘等观测能力。
这些东西单拎出来都不算高大上,但组合在一起,就变成了:
“一个你真的可以在项目里用起来,而不是停留在 GitHub Star 上的项目。”
七、未来趋势:Memory 系统会往哪走?
站在 Kernel Memory 的角度往前看,“记忆系统”本身还有很多值得探索的方向:
- 更智能的多级记忆:
- 不只是“文档级记忆”,还包括:
-
用户级记忆(偏好、历史);
-
任务级记忆(某次分析链路的中间结论);
-
组织级记忆(一段时间内的趋势总结)。
-
-
KM 已经提供了一些合成记忆的基础,但未来可以做得更“脑科学”一点。
- 不只是“文档级记忆”,还包括:
- 与 Agent 框架更紧密的协作:
-
今天的 KM 和 Semantic Kernel 是“插件关系”;
-
未来更高级的 Agent 可能需要“主动规划记忆读写”的能力;
-
Memory 不再是“被动被查”,而是参与到“下一步该做什么”的决策中。
-
- 与安全、合规体系的深度绑定:
-
当越来越多企业把敏感数据给 AI 看时;
-
Memory 层会自然成为“审计与访问控制”的关键节点;
-
像内容安全、权限策略、数据脱敏都会沉到 Memory 层。
-
- 更标准化的 Memory 接口:
-
现在不同项目都有自己的一套“向量检索 + RAG”约定;
-
未来不排除会出现更统一的 Memory API 标准;
-
KM 这种服务化项目很可能成为“事实标准”的候选之一。
-
不管怎样,有一点几乎可以确定:
在 AI 应用体系里,“Memory” 这一层会越来越重要,越来越不能被“临时脚本 + 向量库拼凑”替代。
而 Kernel Memory 正是在这个趋势下,一个相对完整、工程化、可运行的实践样本。
八、落地建议:什么时候该用 Kernel Memory?
聊了这么多,最后我们落回到一个最现实的问题:
“我手上这个项目,适不适合上 Kernel Memory?”
可以给你一个非常接地气的判断标准:
8.1 非常适合用 KM 的场景
如果你符合以下任意两条及以上,就可以认真考虑直接用 KM:
-
文档来源复杂:PDF、Office、网页、图片等齐活;
-
有明确的权限隔离需求(部门/用户/项目级);
-
需要支撑多种客户端语言(.NET + Node + Python 等);
-
文档体量较大,摄取与索引是长耗时任务;
-
项目有一定生命周期,不想以后维护一团“手撸 RAG 脚本”。
8.2 可以轻量借鉴思路的场景
如果你的项目:
-
只是一个简单 PoC / 内部 Demo;
-
数据量很小,文件格式也很单一(例如全是 Markdown);
-
没啥复杂权限;
那么你可以:
-
不一定直接引入 KM 全家桶;
- 但可以“抄作业”它的架构思路:
-
把摄取流程拆成 Handler;
-
用 Tag/Metadata 来做数据治理;
-
把 Memory 视作独立的子系统,而不是粘在 Controller 里的一坨代码。
-
8.3 不推荐硬上 KM 的情况
也要实话实说,有些场景硬上 KM 反而是“用力过猛”:
-
单机脚本,生命周期可能就几天;
-
完全离线、不需要服务化;
-
没有后续维护压力,脚本写烂一点自己看得懂就行。
这种时候,一个简简单单的 faiss + openai 脚本也许更合适。等你哪天真决定要做一个“长期运营的产品”,再来考虑 KM 也不迟。
九、结语:先给大模型一座“记忆宫殿”
很多团队在做 AI 应用时,第一反应是选模型、调 Prompt、降成本。
这些当然都重要,但如果把整个系统想象成一个“人”:
-
模型是大脑;
-
Prompt 是你跟它说话的方式;
-
工程代码是它的“肌肉”;
-
而 Memory,才是它的“记忆宫殿”。
一个天天失忆的天才,终归不如一个有条理、有长期记忆的“普通高手”。
Kernel Memory 做的,就是帮你先把这座记忆宫殿架起来:
-
让你的 AI 应用能 记住 它应该记住的东西;
-
也能 忘掉 它不该再看到的内容;
-
更能在需要的时候,准确地从记忆里翻出那一页。
如果你正计划打造自己的 Copilot、企业知识库问答、智能文档分析平台, 不妨抽个周末,把这个仓库 clone 下来跑一跑 examples,
也许你下一版架构图里,“Memory” 那一块,就不再是一句含糊的“向量库 + 一些脚本”,而是一个清晰、可演进、可复用的 Kernel Memory。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)